







【文档链接】https://taskflow.github.io/taskflow/ExecuteTaskflow.html
在创建任务依赖图后,您需要将其提交给线程以执行。在本章中,我们将向您展示如何执行任务依赖图。
创建执行器
要执行任务流(taskflow),您需要创建一个类型为 `tf::Executor` 的执行器。执行器是一个线程安全的对象,它管理一组工作线程,并通过高效的任务窃取算法来执行任务。调用运行任务流的接口会创建一个拓扑结构(topology),这是一种用于跟踪正在运行的图的执行状态的数据结构。tf::Executor 使用一个无符号整数来构造,表示使用 N 个工作线程。默认值为 std::thread::hardware_concurrency(即硬件支持的最大并发线程数)。
tf::Executor executor1; // create an executor with the number of workers
// equal to std::thread::hardware_concurrency
tf::Executor executor2(4); // create an executor of 4 worker threads一个执行器可以被重复用于执行多个任务流。在大多数工作负载中,您可能只需要一个执行器来运行多个任务流,其中每个任务流代表并行分解的一部分。
理解执行器中的任务窃取机制
Taskflow 设计了一种高效的任务窃取算法,用于在执行器中调度和运行任务。任务窃取是一种动态调度算法,广泛应用于并行计算中,用于在多个线程或核心之间分配和平衡工作负载。具体来说,在一个执行器内部,每个工作线程都维护着自己的本地任务队列。当某个工作线程完成其自身的任务后,它不会闲置或进入休眠状态,而是(作为thief “窃取者”)尝试从另一个工作线程(victim“受害者”)的队列中窃取一个任务。下图展示了任务窃取的基本思想:
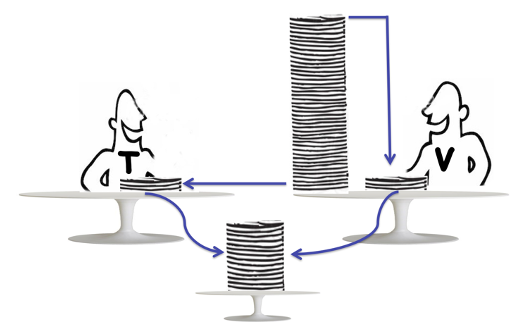
任务窃取的关键优势在于其去中心化特性和高效性。大多数情况下,工作线程在其本地队列上工作,不会发生资源竞争。只有当某个工作线程变为空闲时,才会发生任务窃取,这种机制将与同步和任务分配相关的开销降至最低。这种去中心化的策略能够有效地平衡工作负载,确保空闲的工作线程被充分利用,并使整体计算高效推进。
执行任务流
`tf::Executor` 提供了一组运行任务流的方法:`tf::Executor::run`、`tf::Executor::run_n` 和 `tf::Executor::run_until`,分别用于运行任务流一次、多次或直到给定的条件为真。所有这些方法都接受一个可选的回调函数,在执行完成后调用,并返回一个 `tf::Future` 对象,供用户访问执行状态。以下代码展示了运行任务流的几种方式:
// Declare an executor and a taskflow
tf::Executor executor;
tf::Taskflow taskflow;
// Add three tasks into the taskflow
tf::Task A = taskflow.emplace([] () { std::cout << "This is TaskA\n"; });
tf::Task B = taskflow.emplace([] () { std::cout << "This is TaskB\n"; });
tf::Task C = taskflow.emplace([] () { std::cout << "This is TaskC\n"; });
// Build precedence between tasks
A.precede(B, C);
tf::Future<void> fu = executor.run(taskflow);
fu.wait(); // block until the execution completes
executor.run(taskflow, [](){ std::cout << "end of 1 run"; }).wait();
executor.run_n(taskflow, 4);
executor.wait_for_all(); // block until all associated executions finish
executor.run_n(taskflow, 4, [](){ std::cout << "end of 4 runs"; }).wait();
executor.run_until(taskflow, [cnt=0] () mutable { return ++cnt == 10; });任务分解:
-第6-8行创建了一个包含三个任务(A、B 和 C)的任务流。
-第13-14行运行该任务流一次,并等待其完成。
-第16行运行该任务流一次,并在执行完成后调用一个回调函数。
-第17-18行运行该任务流四次,并使用 `tf::Executor::wait_for_all` 等待所有运行完成。
-第19行运行该任务流四次,并在第四次执行结束时调用一个回调函数。
-第20行持续运行该任务流,直到给定的条件(谓词)返回 true。
在同一任务流上发出多次运行请求时,这些运行会自动按照调用顺序同步为一个顺序执行链。
executor.run(taskflow); // execution 1
executor.run_n(taskflow, 10); // execution 2
executor.run(taskflow); // execution 3
executor.wait_for_all(); // execution 1 -> execution 2 -> execution 3【注意】
在任务流执行期间,该任务流必须保持存活。您有责任确保任务流在运行时不会被销毁。例如,以下代码可能导致未定义行为。
tf::Executor executor; // create an executor
// create a taskflow whose lifetime is restricted by the scope
{
tf::Taskflow taskflow;
// add tasks to the taskflow
// ...
// run the taskflow
executor.run(taskflow);
} // leaving the scope will destroy taskflow while it is running,
// resulting in undefined behavior同样,您应该避免在任务流运行时对其进行修改或操作。
tf::Taskflow taskflow;
// Add tasks into the taskflow
// ...
// Declare an executor
tf::Executor executor;
tf::Future<void> future = executor.run(taskflow); // non-blocking return
// alter the taskflow while running leads to undefined behavior
taskflow.emplace([](){ std::cout << "Add a new task\n"; });您必须始终确保任务流保持存活,并且在它运行于执行器上时不得对其进行修改。
通过转移所有权执行任务流
您可以将任务流的所有权转移给执行器并运行它,从而避免处理该任务流的生命周期问题。上一节讨论的每个 `run_*` 方法都有一个重载版本,可以接受一个被移动的任务流对象。
tf::Taskflow taskflow;
tf::Executor executor;
taskflow.emplace([](){});
// let the executor manage the lifetime of the submitted taskflow
executor.run(std::move(taskflow));
// now taskflow has no tasks
assert(taskflow.num_tasks() == 0);然而,您应该避免移动正在运行的任务流,因为这可能导致未定义行为。
tf::Taskflow taskflow;
tf::Executor executor;
taskflow.emplace([](){});
// executor does not manage the lifetime of taskflow
executor.run(taskflow);
// error! you cannot move a taskflow while it is running
executor.run(std::move(taskflow)); 将任务流以转移所有权的方式提交给执行器的正确做法是,确保所有之前的运行已完成。执行器会在该任务流的执行完成后自动释放其资源。
// submit the taskflow and wait until it completes
executor.run(taskflow).wait();
// now it's safe to move the taskflow to the executor and run it
executor.run(std::move(taskflow)); 同样,您不能移动正在执行器上运行的任务流。必须等待该任务流之前的所有运行完成之后,才能调用移动操作。
// submit the taskflow and wait until it completes
executor.run(taskflow).wait();
// now it's safe to move the taskflow to another
tf::Taskflow moved_taskflow(std::move(taskflow)); 从内部工作线程执行任务流
`tf::Executor` 的每个 `run` 变体都会返回一个 `tf::Future` 对象,它允许您等待结果完成。当调用 `tf::Future::wait` 时,调用方会阻塞并停止任何操作,直到相关状态被标记为就绪。然而,这种设计可能会引入死锁问题,特别是在需要从执行器的内部工作线程运行多个任务流时。例如,以下代码创建了一个包含 1000 个任务的任务流,其中每个任务以阻塞方式运行另一个包含 500 个任务的任务流:
tf::Executor executor(2);
tf::Taskflow taskflow;
std::array<tf::Taskflow, 1000> others;
for(size_t n=0; n<1000; n++) {
for(size_t i=0; i<500; i++) {
others[n].emplace([&](){});
}
taskflow.emplace([&executor, &tf=others[n]](){
// blocking the worker can introduce deadlock where
// all workers are waiting for their taskflows to finish
executor.run(tf).wait();
});
}
executor.run(taskflow).wait();为避免此问题,执行器提供了一个方法 `tf::Executor::corun`,用于从该执行器的某个工作线程中执行任务流。该工作线程不会阻塞,而是会在其任务窃取循环中与其他任务一起协同运行该任务流。
tf::Executor executor(2);
tf::Taskflow taskflow;
std::array<tf::Taskflow, 1000> others;
std::atomic<size_t> counter{0};
for(size_t n=0; n<1000; n++) {
for(size_t i=0; i<500; i++) {
others[n].emplace([&](){ counter++; });
}
taskflow.emplace([&executor, &tf=others[n]](){
// the caller worker will not block but corun these
// taskflows through its work-stealing loop
executor.corun(tf);
});
}
executor.run(taskflow).wait();与 `tf::Executor::corun` 类似,方法 `tf::Executor::corun_until` 是另一种变体,它使调用的工作线程保持在任务窃取循环中,直到给定的条件变为真。您可以使用此方法来避免工作线程被阻塞而无法执行有用的操作,例如在提交未完成的任务时(例如 GPU 操作)被阻塞。
taskflow.emplace([&](){
auto fu = std::async([](){ std::sleep(100s); });
executor.corun_until([](){
return fu.wait_for(std::chrono::seconds(0)) == future_status::ready;
});
});【 注意 】
您必须从调用执行器的某个工作线程中调用 `tf::Executor::corun_until` 和 `tf::Executor::corun`,否则将抛出异常。
执行器的线程安全性
`tf::Executor` 的所有 `run_*` 方法都是线程安全的。您可以安全地从多个线程调用这些方法,以并发运行不同的任务流。然而,提交的任务流的执行顺序是不确定的,具体由运行时调度器决定。
tf::Executor executor;
for(int i=0; i<10; ++i) {
std::thread([i, &](){
// ... modify my taskflow at i
executor.run(taskflows[i]); // run my taskflow at i
}).detach();
}
executor.wait_for_all();查询工作线程
在 `tf::Executor` 中,每个工作线程都会被分配一个唯一的整数标识符,范围为 `[0, N)`,其中 `N` 是执行器中工作线程的数量。您可以使用 `tf::Executor::this_worker_id` 查询调用线程的标识符。如果调用线程不是执行器的工作线程,则该方法返回 `-1`。此功能在建立工作线程与应用程序特定数据结构之间的一对一映射时特别有用。
std::vector<int> worker_vectors[8]; // one vector per worker
tf::Taskflow taskflow;
tf::Executor executor(8); // an executor of eight workers
assert(executor.this_worker_id() == -1); // master thread is not a worker
taskflow.emplace([&](){
int id = executor.this_worker_id(); // in the range [0, 8)
auto& vec = worker_vectors[worker_id];
// ...
});观察线程活动
当工作线程参与执行任务并在离开执行时,您可以通过 tf::ObserverInterface 观察执行器中的线程活动。tf::ObserverInterface 是一个接口类,它提供了一组方法,供您定义线程进入和离开任务执行上下文时需要执行的操作。
class ObserverInterface {
virtual ~ObserverInterface() = default;
virtual void set_up(size_t num_workers) = 0;
virtual void on_entry(tf::WorkerView worker_view, tf::TaskView task_view) = 0;
virtual void on_exit(tf::WorkerView worker_view, tf::TaskView task_view) = 0;
};在您的派生类中,必须定义三个方法:
tf::ObserverInterface::set_up、tf::ObserverInterface::on_entry 和 tf::ObserverInterface::on_exit。
- tf::ObserverInterface::set_up 是一个类似于构造函数的方法,在观察器被构造时由执行器调用。它会传递一个参数,表示执行器中工作线程的数量。您可以利用它来预分配或初始化数据存储,例如为每个工作线程创建一个独立的向量。
- tf::ObserverInterface::on_entry 和 tf::ObserverInterface::on_exit 分别由工作线程在进入和离开任务的执行上下文之前和之后调用。这两个方法通过 tf::WorkerView 和 tf::TaskView 提供对底层工作线程和正在运行的任务的不可变访问。您可以使用它们记录时间点并计算任务的执行耗时。
您可以使用 tf::Executor::make_observer 将执行器与一个或多个观察器(尽管通常是一个)关联起来。我们使用 std::shared_ptr 来管理观察器的所有权。执行器会遍历每个观察器,并相应地调用对应的方法。
#include <taskflow/taskflow.hpp>
struct MyObserver : public tf::ObserverInterface {
MyObserver(const std::string& name) {
std::cout << "constructing observer " << name << '\n';
}
void set_up(size_t num_workers) override final {
std::cout << "setting up observer with " << num_workers << " workers\n";
}
void on_entry(tf::WorkerView w, tf::TaskView tv) override final {
std::ostringstream oss;
oss << "worker " << w.id() << " ready to run " << tv.name() << '\n';
std::cout << oss.str();
}
void on_exit(tf::WorkerView w, tf::TaskView tv) override final {
std::ostringstream oss;
oss << "worker " << w.id() << " finished running " << tv.name() << '\n';
std::cout << oss.str();
}
};
int main(){
tf::Executor executor(4);
// Create a taskflow of eight tasks
tf::Taskflow taskflow;
auto A = taskflow.emplace([] () { std::cout << "1\n"; }).name("A");
auto B = taskflow.emplace([] () { std::cout << "2\n"; }).name("B");
auto C = taskflow.emplace([] () { std::cout << "3\n"; }).name("C");
auto D = taskflow.emplace([] () { std::cout << "4\n"; }).name("D");
auto E = taskflow.emplace([] () { std::cout << "5\n"; }).name("E");
auto F = taskflow.emplace([] () { std::cout << "6\n"; }).name("F");
auto G = taskflow.emplace([] () { std::cout << "7\n"; }).name("G");
auto H = taskflow.emplace([] () { std::cout << "8\n"; }).name("H");
// create an observer
std::shared_ptr<MyObserver> observer = executor.make_observer<MyObserver>(
"MyObserver"
);
// run the taskflow
executor.run(taskflow).get();
// remove the observer (optional)
executor.remove_observer(std::move(observer));
return 0;
}结果输出:
constructing observer MyObserver
setting up observer with 4 workers
worker 2 ready to run A
1
worker 2 finished running A
worker 2 ready to run B
2
worker 1 ready to run C
worker 2 finished running B
3
worker 2 ready to run D
worker 3 ready to run E
worker 1 finished running C
4
5
worker 1 ready to run F
worker 2 finished running D
worker 3 finished running E
6
worker 2 ready to run G
worker 3 ready to run H
worker 1 finished running F
7
8
worker 2 finished running G
worker 3 finished running H可以预期,`std::cout` 的每一行输出会相互交错,因为有四个工作线程参与任务调度。然而,“准备就绪”消息总是出现在对应的任务消息(例如数字)之前,然后才是“完成”消息。
修改工作线程属性
您可以通过执行器更改每个工作线程的属性,例如在工作线程进入调度循环之前分配线程-处理器亲和性,或在工作线程离开调度循环后进行额外信息的后处理。这可以通过向执行器传递一个从 `tf::WorkerInterface` 派生的实例来实现。以下示例演示了如何在 Linux 平台上使用 `tf::WorkerInterface` 将工作线程绑定到与其 ID 相同的特定 CPU 核心:
// affine the given thread to the given core index (linux-specific)
bool affine(std::thread& thread, unsigned int core_id) {
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(core_id, &cpuset);
pthread_t native_handle = thread.native_handle();
return pthread_setaffinity_np(native_handle, sizeof(cpu_set_t), &cpuset) == 0;
}
class CustomWorkerBehavior : public tf::WorkerInterface {
public:
// to call before the worker enters the scheduling loop
void scheduler_prologue(tf::Worker& w) override {
printf("worker %lu prepares to enter the work-stealing loop\n", w.id());
// now affine the worker to a particular CPU core equal to its id
if(affine(w.thread(), w.id())) {
printf("successfully affines worker %lu to CPU core %lu\n", w.id(), w.id());
}
else {
printf("failed to affine worker %lu to CPU core %lu\n", w.id(), w.id());
}
}
// to call after the worker leaves the scheduling loop
void scheduler_epilogue(tf::Worker& w, std::exception_ptr) override {
printf("worker %lu left the work-stealing loop\n", w.id());
}
};
int main() {
tf::Executor executor(4, tf::make_worker_interface<CustomWorkerBehavior>());
return 0;
}结果输出:
worker 3 prepares to enter the work-stealing loop
successfully affines worker 3 to CPU core 3
worker 3 left the work-stealing loop
worker 0 prepares to enter the work-stealing loop
successfully affines worker 0 to CPU core 0
worker 0 left the work-stealing loop
worker 1 prepares to enter the work-stealing loop
worker 2 prepares to enter the work-stealing loop
successfully affines worker 1 to CPU core 1
worker 1 left the work-stealing loop
successfully affines worker 2 to CPU core 2
worker 2 left the work-stealing loop当您创建一个执行器时,它会生成一组工作线程,这些线程使用任务窃取调度算法来运行任务。以下是调度器的执行逻辑以及它通过 `tf::WorkerInterface` 与每个生成的工作线程交互的方式:
for(size_t n=0; n<num_workers; n++) {
create_thread([](Worker& worker)
// pre-processing executor-specific worker information
// ...
// enter the scheduling loop
// Here, WorkerInterface::scheduler_prologue is invoked, if any
worker_interface->scheduler_prologue(worker);
try {
while(1) {
perform_work_stealing_algorithm();
if(stop) {
break;
}
}
} catch(...) {
exception_ptr = std::current_exception();
}
// leaves the scheduling loop and joins this worker thread
// Here, WorkerInterface::scheduler_epilogue is invoked, if any
worker_interface->scheduler_epilogue(worker, exception_ptr);
);
}【注意】
`tf::WorkerInterface::scheduler_prologue` 和 `tf::WorkerInterface::scheduler_epilogue` 会被每个工作线程同时调用。您有责任确保在它们的调用过程中不会发生数据竞争。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









