







【文档链接】Taskflow Algorithms » Parallel Iterations | Taskflow QuickStart
Taskflow 提供了模板函数,用于创建任务以对项目范围进行并行迭代。
包含头文件
要使用并行迭代算法,你需要包含头文件 `taskflow/algorithm/for_each.hpp`。
#include <taskflow/algorithm/for_each.hpp>创建基于索引的并行迭代任务
基于索引的并行循环(parallel-for)会在给定的范围 [first, last) 内,按照指定的步长(step size)执行并行迭代。
通过 tf::Taskflow::for_each_index(B first, E last, S step, C callable, P part) 创建的任务,表示对以下循环进行并行执行:
// positive step
for(auto i=first; i<last; i+=step) {
callable(i);
}
// negative step
for(auto i=first; i>last; i+=step) {
callable(i);
}我们仅支持基于整数的范围。该范围可以是正向递增的,也可以是负向递减的。
taskflow.for_each_index(0, 100, 2, [](int i) { }); // 50 loops with a + step
taskflow.for_each_index(100, 0, -2, [](int i) { }); // 50 loops with a - step请注意,无论是正向还是负向的迭代方向,都是基于范围 `[first, last)` 来定义的,其中 `last` 是不包含在内的。
在正向情况下,50 个元素为:0, 2, 4, 6, 8, ..., 96, 98。
而在负向情况下,50 个元素为:100, 98, 96, 94, ..., 4, 2。
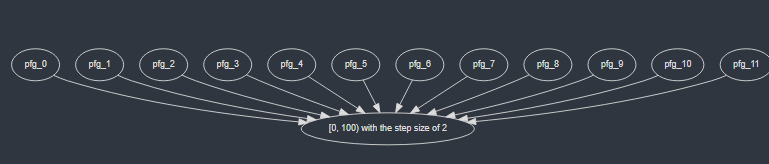
下面展示了在 12 个工作线程下,正向情况所生成的 Taskflow 图结构示意图:
tf::Taskflow::for_each_by_index(R range, C callable, P part) 提供了一种更灵活的方式遍历索引的子范围,而不是为每个索引调用显式地指定索引范围和可调用对象。此重载使用 tf::IndexRange 将范围划分为多个子范围,从而允许对每个子范围的处理方式进行更精细的控制。例如,下面的代码展示了使用两种不同的方法达到相同的效果:
std::vector<int> data1(100), data2(100);
// Approach 1: initialize data1 using explicit index range
taskflow.for_each_index(0, 100, 1, [&](int i){ data1[i] = 10; });
// Approach 2: initialize data2 using tf::IndexRange
tf::IndexRange<int> range(0, 100, 1);
taskflow.for_each_by_index(range, [&](tf::IndexRange<int> subrange){
for(int i=subrange.begin(); i<subrange.end(); i+=subrange.step_size()) {
data2[i] = 10;
}
});两种方法产生的结果相同,但第二种方法在如何遍历每个被划分的子范围方面提供了更大的灵活性。这对于可以从 SIMD 优化或其他基于范围的处理策略中受益的应用程序特别有用。
通过引用捕获索引
你可以使用 `std::ref` 按引用传递索引,从而在依赖任务之间传递参数的更新。当在创建 `for-each-index` 任务时尚未知道范围索引,而需要通过另一个任务进行初始化时,这种方法尤其有用。
int* vec;
int first, last;
auto init = taskflow.emplace([&](){
first = 0;
last = 1000;
vec = new int[1000];
});
auto pf = taskflow.for_each_index(std::ref(first), std::ref(last), 1,
[&] (int i) {
std::cout << "parallel iteration on index " << vec[i] << '\n';
}
);
// wrong! must use std::ref, or first and last are captured by copy
// auto pf = taskflow.for_each_index(first, last, 1, [&](int i) {
// std::cout << "parallel iteration on index " << vec[i] << '\n';
// });
init.precede(pf);当 init 任务完成后,parallel-for 任务 pf 将会看到 first 为 0、last 为 1000,并对这 1000 个元素进行并行迭代。
创建基于迭代器的并行迭代任务
基于迭代器的并行循环(parallel-for)会对由两个符合 STL 风格的迭代器 first 和 last 所指定的范围进行并行迭代。通过调用 tf::Taskflow::for_each(B first, E last, C callable, P part) 创建的任务,表示对以下循环进行并行执行:
for(auto i=first; i<last; i++) {
callable(*i);
}`tf::Taskflow::for_each(B first, E last, C callable, P&& part)` 会同时对范围 `[first, last)` 中的每一个迭代器所指向的对象应用该可调用对象(`callable`)。在执行并行循环任务期间,用户有责任确保该迭代器范围是有效的。 此外,所使用的迭代器必须定义了后置自增运算符 `operator++`。
std::vector<int> vec = {1, 2, 3, 4, 5};
taskflow.for_each(vec.begin(), vec.end(), [](int i){
std::cout << "parallel for on item " << i << '\n';
});
std::list<std::string> list = {"hi", "from", "t", "a", "s", "k", "f", "low"};
taskflow.for_each(list.begin(), list.end(), [](const std::string& str){
std::cout << "parallel for on item " << str << '\n';
});通过引用捕获迭代器
与 tf::Taskflow::for_each_index 类似,tf::Taskflow::for_each 的迭代器也支持模板化,允许通过引用捕获范围参数。这样,一个任务可以在另一个任务执行并行循环算法之前设置好迭代器范围。例如:
std::vector<int> vec;
std::vector<int>::iterator first, last;;
tf::Task init = taskflow.emplace([&](){
vec.resize(1000);
first = vec.begin();
last = vec.end();
});
tf::Task pf = taskflow.for_each(std::ref(first), std::ref(last), [&](int i) {
std::cout << "parallel iteration on item " << i << '\n';
});
// wrong! must use std::ref, or first and last are captured by copy
// tf::Task pf = taskflow.for_each(first, last, [&](int i) {
// std::cout << "parallel iteration on item " << i << '\n';
// });
init.precede(pf);当 init 任务完成后,parallel-for 任务 pf 将会看到 first 指向 vec 的起始位置,last 指向 vec 的末尾,并对这 1000 个元素进行并行迭代。这两个任务形成一个端到端的任务图,其中 parallel-for 的参数是在运行时计算得出的。
配置分割器
你可以为并行迭代任务配置不同的分割器,以使用不同的调度方法,如引导式分割、动态分割和静态分割。下面的例子展示了如何使用两种不同的分割器创建两个并行迭代任务,其中一个使用静态分割算法,另一个使用引导式分割算法:
std::vector<int> vec(1024, 0);
// create two partitioners with a chunk size of 10
tf::StaticPartitioner static_partitioner(10);
tf::GuidedPartitioner guided_partitioner(10);
// create a parallel-iteration task with static partitioner
taskflow.for_each(
vec.begin(), vec.end(), [&](int i) {
std::cout << "parallel iteration on item " << i << '\n';
},
static_partitioner
);
// create a parallel-iteration task with guided partitioner
taskflow.for_each(
vec.begin(), vec.end(), [&](int i) {
std::cout << "parallel iteration on item " << i << '\n';
},
guided_partitioner
);【注意】
默认情况下,如果没有指定分割器,并行迭代任务将使用 tf::DefaultPartitioner。这意味着在创建并行迭代任务时,如果未明确指定一个分割器,系统会自动采用默认的分割策略来分配任务。这有助于简化代码编写,同时确保了合理的性能表现。然而,在特定应用场景下,根据实际需求选择合适的分割器可以进一步优化并行执行的效率。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









