






机器语言:
机器语言是计算机硬件能够直接理解和执行的最基础的编程语言,它由二进制代码组成,直接对应于处理器的指令集。由于它的低级性和硬件依赖性,机器语言在现代编程实践中很少直接使用,通常被更高级的编程语言所取代。
汇编语言:
汇编语言"是一种低级编程语言,它使用助记符来代表机器语言的操作码,比机器语言更易于理解和编写。它是介于机器语言和高级语言之间的一种语言。


1 、在C语言中,整型int所占字节数与数值范围分别是:
A.4; −231~231
B.4; −231~231−1
C.4; −232~232
D.4; −232~232−1
解答:int 通常是32位的,占用4个字节。一个32位的整数可以表示的范围是从 -2^31 到 2^31 - 1(因为整数包括负数、零和正数)。
2 、(不定项)
在C语言中,以下哪些整数常量(const)是合法的:
A.123
B.0xFFF
C.0b101
D.0678
解答:
A. 123 - 这是一个合法的十进制整数常量。
B. 0xFFF - 这是一个合法的十六进制整数常量。在C语言中,十六进制常量以 0x 或 0X 开头。
C. 0b101 - 这表示一个二进制数。虽然标准的ANSI C语言没有定义二进制字面量的表示法,但是一些编译器(如GCC)作为扩展支持以 0b 或 0B 开头的二进制表示法。因此,它可能在某些编译器中是合法的,但并非标准C语言的一部分。
D. 0678 - 这是一个不合法的八进制数,因为八进制数只能包含数字0-7。在C语言中,八进制数以0开头,但这个常量包含了一个非法的八进制数字8。
3、在C语言中,以下哪些浮点常量(const)是合法的:
A. .1415
B. 3.
C. .e5
D. 1e-5
解答:
在C语言中,浮点常量可以以多种形式表示,包括使用小数点、指数部分,或两者的组合。根据您给出的选项,我们可以分析每个常量的合法性:
A. .1415 - 这是一个合法的浮点常量。在C语言中,浮点常量可以没有整数部分,只有小数部分。
B. 3. - 这也是一个合法的浮点常量。它有一个整数部分和一个小数点,尽管小数部分后没有数字,但它仍然是有效的。
C. .e5 - 这不是一个合法的浮点常量。虽然它试图使用指数表示法(e表示10的幂),但它既没有整数部分也没有小数部分,只有指数部分。
D. 1e-5 - 这是一个合法的浮点常量。它使用了指数表示法,表示 1×10−51×10−5。
综上所述,选项A(.1415)、B(3.)和D(1e-5)是合法的浮点常量,而C(.e5)不是。
4、在C语言中,若有以下代码段,则变量(variable)c, d的值分别为:
#define a 1+2
const int b=1+2;
int c, d;
c=2*a*2;
d=2*b*2;
A.12;12
B.12;6
C.6;12
D.6;6
解答:
#define 是一个预处理指令,用于定义宏。它进行的是文字替换,而不是计算表达式的值。在这个例子中,a 被定义为宏 1+2。这意味着在代码中每次出现 a,它就会被替换为 1+2。
所以,当你写 c = 2*a*2;,它实际上会被预处理器展开为 c = 2*1+2*2;。根据C语言的运算符优先级,乘法会先于加法执行,所以这个表达式等价于 c = 2*1 + 4,计算结果是 c = 6。
const int b = 1+2;
这行代码定义了一个整型常量 b,其值为 1+2 的计算结果,也就是 3。
因此,d = 2*b*2; 将会正确计算 b 的值,然后执行乘法。这个表达式相当于 d = 2*3*2,计算结果是 d = 12。
\\用于转义出来\
5、以下代码的输出是:
int a=10, b=4;
double c=0.5, d, e;
d=a/b/c;
e=(double)a/b/c;
printf("%.2f %.2f", d, e);A.4.00 5.00
B.4.00 4.00
C.5.00 4.00
D.5.00 5.00
解答:
在这段代码中,我们需要注意整型和浮点型的运算规则,以及如何在它们之间进行类型转换。
-
d = a / b / c;- 在这个表达式中,
a和b是整数(int类型),而c是一个双精度浮点数(double类型)。 - 首先,
a / b会执行整数除法。因为a和b都是整数,结果也是整数。所以,10 / 4的结果是2,而不是2.5,因为小数部分在整数除法中被舍弃。 - 接着,
2 / c(即2 / 0.5)将会执行浮点除法,因为现在的运算涉及到了一个浮点数。结果是4.0。
- 在这个表达式中,
-
e = (double)a / b / c;- 这里,
(double)a强制将a转换为double类型。 - 因此,整个表达式变成了浮点数的除法。
10.0 / 4 / 0.5等于5.0。
- 这里,
-
printf("%.2f %.2f", d, e);- 这将以两位小数的格式打印
d和eA
- 这将以两位小数的格式打印
A
6、在C语言中,以下说法不正确的是:
A.变量定义时给变量分配存储空间
B.使用extern修饰的变量声明时,引用已有的变量,不分配存储空间
C.变量只能有一次定义
D.变量只能有一次声明
在C语言中,一个变量的声明和定义是有区别的,这对于理解变量是否可以多次声明很重要:
-
声明(Declaration):声明一个变量是告诉编译器该变量的存在和类型,但不分配存储空间。例如,
extern int x;是一个声明,它告诉编译器变量x是一个int类型的变量,但它并不创建这个变量。 -
定义(Definition):定义一个变量是声明它的同时为它分配存储空间。例如,
int x;是一个定义,因为它不仅声明了x是一个int类型的变量,同时也为x分配了存储空间。
在C语言中,一个变量可以被多次声明,但只能被定义一次。多次声明同一个变量是合法的,只要这些声明是兼容的。例如,你可以在一个程序的多个地方使用 extern int x; 来声明同一个变量,但只能在一个地方使用 int x; 来定义它。
如果一个变量在同一个作用域内被多次定义,那么会引发编译错误。然而,如果变量的多个声明中有一个是定义(例如,一个文件中有 int x; 而另一个文件中有 extern int x;),这是允许的,因为 extern 关键字用于指示变量在其他地方定义。
总结来说,一个变量可以在C语言中多次声明,但只能定义一次。
解答:
在这些选项中,不正确的说法是:
D. 变量只能有一次声明
解释如下:
A. 变量定义时给变量分配存储空间 - 这是正确的。在C语言中,当变量被定义时,编译器会为该变量分配存储空间。
B. 使用extern修饰的变量声明时,引用已有的变量,不分配存储空间 - 这也是正确的。extern 关键字用于声明一个变量,表示其存储空间在程序的其他部分定义。这种声明不会分配存储空间。
C. 变量只能有一次定义 - 这是正确的。在C语言中,一个变量在任何给定的作用域内只能被定义一次,以避免存储空间的重复分配和潜在的冲突。
D. 变量只能有一次声明 - 这是不正确的。在C语言中,变量可以被多次声明。特别是使用extern关键字时,你可以在程序的多个地方声明同一个变量。重要的是变量只有一次定义,但可以有多次声明。
因此,选项D是不正确的。
在C语言中,除了 extern,还有其他几种方式可以声明变量,主要通过以下关键字:
-
类型修饰符:如
int,float,double,char等。这些都是基本的数据类型关键字,在声明变量时用来指定变量的类型。 -
static:这个关键字用于声明静态变量。静态变量与普通变量的区别在于它们的生命周期。静态局部变量在函数调用之间保持其值不变。
-
register:这个关键字用来建议编译器尽量将变量存储在CPU的寄存器中,以加快其运行速度。然而,这只是一个建议,编译器可以选择忽略它。
-
volatile:这个关键字告诉编译器,变量的值可能以程序未明确指定的方式被改变(例如,由操作系统、硬件或另一个线程修改)。这防止编译器对这些变量进行某些类型的优化。
-
const:这个关键字用于声明常量变量。一旦赋值后,程序中的常量变量的值就不能被改变。
-
typedef:尽管不是直接用来声明变量,
typedef用于为数据类型定义新的名称,之后这个新名称可以用来声明变量。
7、在C语言中,char, short, int, 和 long 是基本的整型数据类型,它们用于存储整数。这些类型有不同的大小和范围,但它们之间的确切大小关系并不是严格定义的,而是依赖于编译器和所运行的平台。以下是一般规则:
-
char:
char类型通常用于存储单个字符。在大多数的现代编译器和平台上,char的大小通常是 1 字节(8位)。 -
short:
short类型用于存储短整数。通常,short至少为 16 位。 -
int:
int类型用于存储整数。标准规定int至少和short一样长。 -
long:
long类型用于存储更大的整数。标准规定long至少为 32 位,并且至少和int一样长。
8、在C语言中,输出一个单引号',正确的语句是:
A.printf("'");
B.printf("\'");
C.printf(""");
D.printf("\"");
解答:在C语言中,打印特殊字符(如单引号和双引号)通常需要考虑转义字符的使用,这是因为某些字符在C语言中具有特殊的含义。然而,对于单引号 ' 来说,情况稍有不同。我们来看看各个选项:
A. printf("'");
- 这个语句是有效的。在C语言中,单引号
'不需要被转义,当它出现在双引号内时,它被视为普通字符。
B. printf("\'");
- 这个语句也是有效的。尽管单引号不需要被转义,使用
\'依然是正确的,这将打印出一个单引号。
C. printf("""");
- 这是不合法的语法。在C语言中,不能使用三个连续的双引号来表示任何东西。
D. printf("\"");
- 这个语句会打印一个双引号
",而不是单引号'。
综上所述,正确的语句是 A 和 B,因为它们都可以正确地打印出单引号 '。选项 C 是语法错误,而选项 D 打印的是双引号而非单引号。
9、
unsigned int a = 0X17E 和unsigned int b = 0412,a和b谁的值更大?
A.a大
B.b大
C.a=b
D.无法比较
解答:
要比较 unsigned int a = 0X17E 和 unsigned int b = 0412 的值,我们需要了解这两个值的表示方法:
0X17E是一个十六进制(Hexadecimal)数,其中0x或0X前缀表示十六进制。0412是一个八进制(Octal)数,以0开头表示八进制。
我们首先将这两个数转换为十进制形式,然后进行比较。
0X17E在十进制中是1 * 16^2 + 7 * 16^1 + 14 * 16^0 = 256 + 112 + 14 = 3820412在十进制中是4 * 8^2 + 1 * 8^1 + 2 * 8^0 = 256 + 8 + 2 = 266
比较这两个十进制数,我们可以看到 382 (a的值) 大于 266 (b的值)。
所以答案是:
A. a大
10、下面代码的输出是:
char a =255;
unsigned char b = 255;
b+=1;
printf("%u %d\n",b,a);
return 0;
A.256 255
B.256 -128
C.0 -1
D.0 -128
解答:
这个问题涉及到 C 语言中的字符类型和整型溢出的概念。我们来逐步分析这段代码的行为:
-
char a = 255;:由于char在 C 语言中通常是一个 8 位的数据类型,其范围取决于编译器和系统架构。在大多数现代系统上,char是有符号的,范围从 -128 到 127。当你尝试将 255 赋值给char类型时,会发生溢出,通常会转换为 -1(因为 255 对应的二进制表示为 11111111,在有符号字符类型中通常表示为 -1)。 -
unsigned char b = 255;:在这里,b被声明为unsigned char,其范围是从 0 到 255。因此,赋值 255 是有效的。 -
b += 1;:将b的值增加 1。由于b是无符号字符,所以它的范围是 0-255。当你增加 1 到 255 时,会发生回绕(wrap around),导致b变为 0。 -
printf("%u %d\n",b,a);:这里,b作为无符号整数打印,所以打印出来是 0。a作为有符号整数打印,它的值是 -1。
因此,代码的输出应该是:
D. 0 -1
11、不定项选择题
以下说法正确的是
A.位是计算机内部数据储存的最小单位,一个二进制位只能表示0和1两种状态。
B.字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成。
C.计算机进行数据处理时,一次存取、加工和传送的数据长度称为字。一个字通常由一个或多个字节构成。
D.在16位计算机种:1字=2字节=16位
解答:
A. 正确。位(bit)确实是计算机内部数据存储的最小单位,一个二进制位只能表示 0 或 1 两种状态。
B. 正确。字节(byte)是计算机中常用的数据处理单位。在大多数现代计算机系统中,一个字节由八个二进制位(bits)构成。
C. 正确。字(word)是计算机处理和传输数据的基本单位,其长度取决于特定的计算机体系结构。一个字可以由一个或多个字节组成,但具体的字节数取决于计算机的体系结构。
D. 正确。在 16 位计算机中,“字”通常是指 16 位的数据单位。由于每个字节由 8 位构成,因此一个 16 位的字等于 2 个字节。
因此,所有的选项 A、B、C 和 D 都是正确的。
12、下方代码的输出为:
#include <stdio.h>
int main()
{
char x= 0xff;
x = x + 1;
printf("%d\n", x);
return 0;
}
A.0
B.255
C.-1
D.-255
解答:char x= 0xff;这一步溢出就把x储存成-1了,选A.
浮点数的表示方法:
在 C 语言中,printf 函数用于格式化输出,包括浮点数。这里是一些常用的格式控制符,用于控制浮点数的输出格式:
-
%f:用于输出十进制浮点数(例如:3.141593)。默认情况下,它会输出六位小数。 -
%.nf:这里n是一个整数,指定了小数点后的数字数量。例如,%.2f会将浮点数格式化为两位小数。 -
%e或%E:用科学记数法格式输出浮点数。%e使用小写的 'e' 表示指数(例如:3.141593e+00),而%E使用大写的 'E'。 -
%g或%G:自动选择%f和%e(或%E)中更短的一种方式来输出。无意义的零会被省略。例如,%g会在适当的时候省略小数点后的零。 -
%a或%A:用十六进制表示法输出浮点数(例如:0x1.921fb54442d18p+1)。%a使用小写的 'p' 和十六进制数字,而%A使用大写的 'P' 和十六进制数字。 -
字段宽度和精度:你可以通过在
%和转换字符之间添加数字来指定字段宽度(例如,%10f会用至少10个字符宽度来输出浮点数,右对齐)。通过添加一个点和数字可以指定精度(例如,%10.2f会输出一个至少10个字符宽度,小数点后有两位数字的浮点数)。 -
左对齐:在
%和转换字符之间添加-符号可以使输出左对齐(例如,%-10f)。
char是从-128--127
unsigned char是从0--255
这样设计是由于0也占了一个数,故上限比理论少1。
关于c语言运算优先级看下文(转载)
https://blog.csdn.net/yuliying/article/details/72898132
关于手动进制转化(转载)
https://zhuanlan.zhihu.com/p/159127499
13、设 c='w', a=1, b=2, d=-5, 则表达式 'x'+1>c, 'y'!=c+2, -a-5*b<=d+1, b==(a=2)的值分别为_________、________、__________ 、 ________ 。
A.1 0 1 1
B.1 0 1 0
C.0 1 1 0
D.0 0 1 1
解答: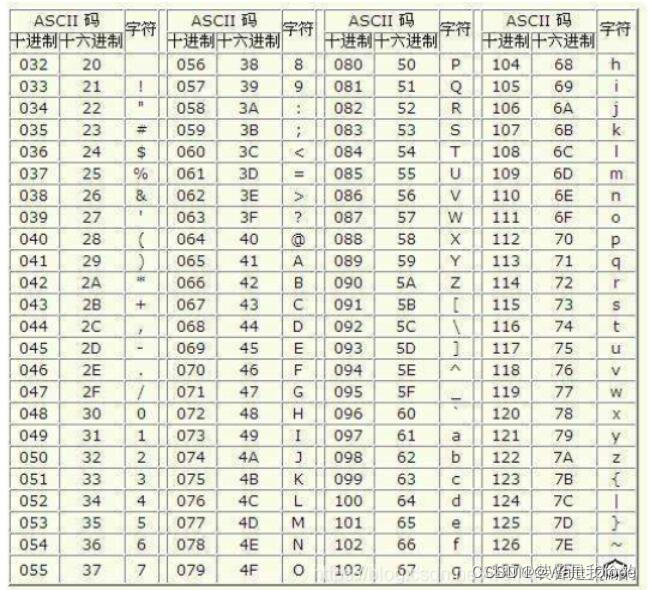
14、下面代码示例的输出结果是什么:
int main() {
int a = 0;
int result = ++a > 0 && ++a > 1;
printf("%d %d", a, result);
}
A.1 1
B.2 1
C.1 0
D.2 0
解答:
-
int a = 0;初始化a为 0。 -
++a > 0是表达式的第一部分。++a将a的值增加 1,然后返回增加后的值。所以这时a变为 1,++a > 0的结果是true。 -
由于
&&运算符使用短路逻辑,当第一个操作数为true时,它会继续评估第二个操作数。因此,接下来评估++a > 1。 -
++a > 1是表达式的第二部分。再次++a将a的值增加 1,变为 2。然后判断2 > 1,这是true。 -
因此,整个逻辑表达式
++a > 0 && ++a > 1的结果是true,或者在 C 语言中表示为 1。 -
所以,最终
printf("%d %d", a, result);将打印出a的值(2)和result的值(1)。
所以正确的答案是:
B. 2 1
但是值得注意的是如果A&&B中A错了,B语句是不会运行的。
15、判断char型变量s是否为小写字母的正确表达式是
A.'a'<=s<='z'
B.(s>='a')&(s<='z')
C.(s>='a') and (s<='z')
D.(s>='a')&&(s<='z')
解答:D明显是对的,但是B若一方错则必为结果必为0,全对则为1,因此和&&是一样的效果。
16、下列关于switch语句叙述正确的是
A.语句中,case的冒号后面允许没有语句。
B.switch语句中,每一个case的冒号后面都允许跟有多条语句。
C.在与switch语句配套的case语句中所使用的表达式可以是变量或常量。
D.switch语句中,可以没有default语句。
解答:
在 C 语言中,switch 语句是一种控制结构,用于基于不同的情况执行不同的代码块。下面是关于 switch 语句的正确叙述:
A. 正确。在 switch 语句中,case 的冒号后面可以没有语句。这意味着可以有一个“空”case,它什么也不做,直接跳到下一个 case 或 default。
B. 正确。switch 语句中,每一个 case 的冒号后面可以跟有多条语句。这允许在一个 case 中执行一系列的操作。
C. 错误。在 switch 语句的 case 标签中使用的必须是整型或枚举类型的常量表达式。不能使用变量。
D. 正确。在 switch 语句中,default 语句是可选的。如果所有的 case 都不匹配,并且没有 default,那么 switch 语句不会执行任何 case 或 default 下的代码。
17、C语言发生死循环可以通过以下哪些操作可以强制终止?
A.CTRL+BREAK
B.CTRL+L
C.CTRL+C
D.CTRL+V
解答:A,C
18、(不定项)以下哪些是数组类型的变体:
A.已知常量大小的数组
B.变长度数组
C.未知大小数组
D.有序数组
解答:
在 C 语言中,数组的变体主要是由它们如何定义和使用的方式来区分的。根据您给出的选项,我们可以对每种类型进行分析:
A. 已知常量大小的数组:这是标准的数组类型,在定义时其大小是已知且不变的。例如,int a[10]; 定义了一个有 10 个整数的数组。
B. 变长度数组(Variable Length Array, VLA):在 C99 标准中引入。这种数组的长度不是在编译时确定的,而是在运行时确定。例如,int n; scanf("%d", &n); int a[n]; 这里 a 就是一个变长度数组。
C. 未知大小数组:在某些情况下,可以声明一个未知大小的数组,特别是在结构体中作为最后一个成员时。这通常用于所谓的“柔性数组成员”,其长度可以在运行时确定。
D. 有序数组:这不是一个由 C 语言本身定义的数组类型,而是对数组内容的描述。一个数组是否有序,取决于它的内容和如何被程序处理,而不是数组的类型。
综上所述,A(已知常量大小的数组)、B(变长度数组)和C(未知大小数组)可以被视为数组类型的变体,而D(有序数组)是关于数组内容的描述,而非类型的变体。
因此,正确的选项是 A、B 和 C。
19、(多选)
对于下列函数及其形参表述错误的是:
void vadd (int a[const], const int b[], const size_t sz)
A.形参数组a的每一项元素都不可以修改
B.形参a本身不可以被修改
C.形参数组b的每一项元素都不可以修改
D.形参b本身不可以被修改
解答:在 C 语言中,当数组作为参数传递给函数时,实际上传递的是数组的首元素地址。因此,形参数组实际上是指向数组元素类型的指针。让我们分析给定的函数 void vadd (int a[const], const int b[], const size_t sz) 的参数:
A. 形参数组a的每一项元素都不可以修改:这是错误的。int a[const] 实际上等同于 int *const a,这意味着 a 是一个指向 int 的常量指针,指针本身不能改变,但是它指向的值(数组元素)可以修改。
B. 形参a本身不可以被修改:这是正确的。正如上所述,int a[const] 可以被解释为 int *const a,意味着指针 a 不能被重新指向其他地址。
C. 形参数组b的每一项元素都不可以修改:这是正确的。const int b[] 表示 b 是一个指向 const int 的指针,这意味着它指向的元素(数组元素)不能修改。
D. 形参b本身不可以被修改:这是错误的。const int b[] 中的 const 修饰的是 b 所指向的元素,而不是指针 b 本身。b 作为指针可以改变其指向的地址,但不能修改所指向地址的内容。
因此,错误的表述是 A 和 D。
非常有意思的补充

20、下列关于数组作为参数传入函数表述有误的是
A.数组形参可保存数组的地址,通常用不定长数组表示
B.一维数组作为形参即便定义了长度,也会被编译忽略
C.多维数组形参若定义了各个维度的长度,均会被编译忽略
D.多维数组形参第一维可以不用指定长度,其他维则必须是常量
解答:
在 C 语言中,当数组作为参数传递给函数时,数组会退化为指向其首元素的指针。这种行为对于一维数组和多维数组都适用,但有一些细节区别。下面是对每个选项的解析:
A. 数组形参可保存数组的地址,通常用不定长数组表示:这个说法部分正确。数组形参确实保存数组的地址,但它们通常表示为指针,而不是不定长数组。不定长数组(VLA)是 C99 标准引入的一个特性,它允许在运行时确定数组长度。这个选项的表述有些混淆。
B. 一维数组作为形参即便定义了长度,也会被编译忽略:这是正确的。当一维数组作为参数传递给函数时,数组长度信息会被忽略,函数只接收到一个指向数组首元素的指针。例如,函数定义 void func(int arr[10]) 实际上等同于 void func(int *arr)。
C. 多维数组形参若定义了各个维度的长度,均会被编译忽略:这是错误的。对于多维数组,除了第一维之外的所有维度的大小是必需的,并且会被编译器使用。这些维度信息用于正确地计算索引位置。
D. 多维数组形参第一维可以不用指定长度,其他维则必须是常量:这是正确的。在多维数组作为参数传递给函数时,除了第一维(它会退化为指针),其他维度的大小必须指定,且必须是常量表达式。这些大小用于在内存中定位元素。
因此,有误的表述是 C。
21、若要求从键盘读入含有空格字符的字符串,应使用函数()
A.getc()
B.gets()
C.getchar()
D.scanf()
解答:
在 C 语言中,如果你需要从键盘读入包含空格的字符串,你应该选择一个能够处理空格的输入函数。我们来看看每个选项:
A. getc():这个函数用于从文件或标准输入(如键盘)读取单个字符。它不适合用于读取包含空格的整个字符串。
B. gets():虽然 gets() 函数可以读取含有空格的字符串,但它是不安全的,因为它不检查目标缓冲区的大小,容易造成缓冲区溢出。实际上,在最新的 C 标准中,gets() 已经被废弃。
C. getchar():这个函数也是用来读取单个字符。它同样不适合用于读取包含空格的整个字符串。
D. scanf():scanf() 函数可以用来读取字符串,但默认情况下它在遇到空格、制表符或换行符时会停止读取。你需要使用特定的格式字符串来让 scanf() 读取包含空格的字符串,比如 scanf("%[^\n]", str);。
因此,虽然 gets() 和修改过的 scanf() 都可以用来读取含空格的字符串,但由于 gets() 的安全问题,更推荐使用 scanf(),或者使用其他安全的字符串读取方法,如 fgets()。在给出的选项中,scanf() 是最合适的选择,但需要注意其正确的使用方式以避免安全问题。
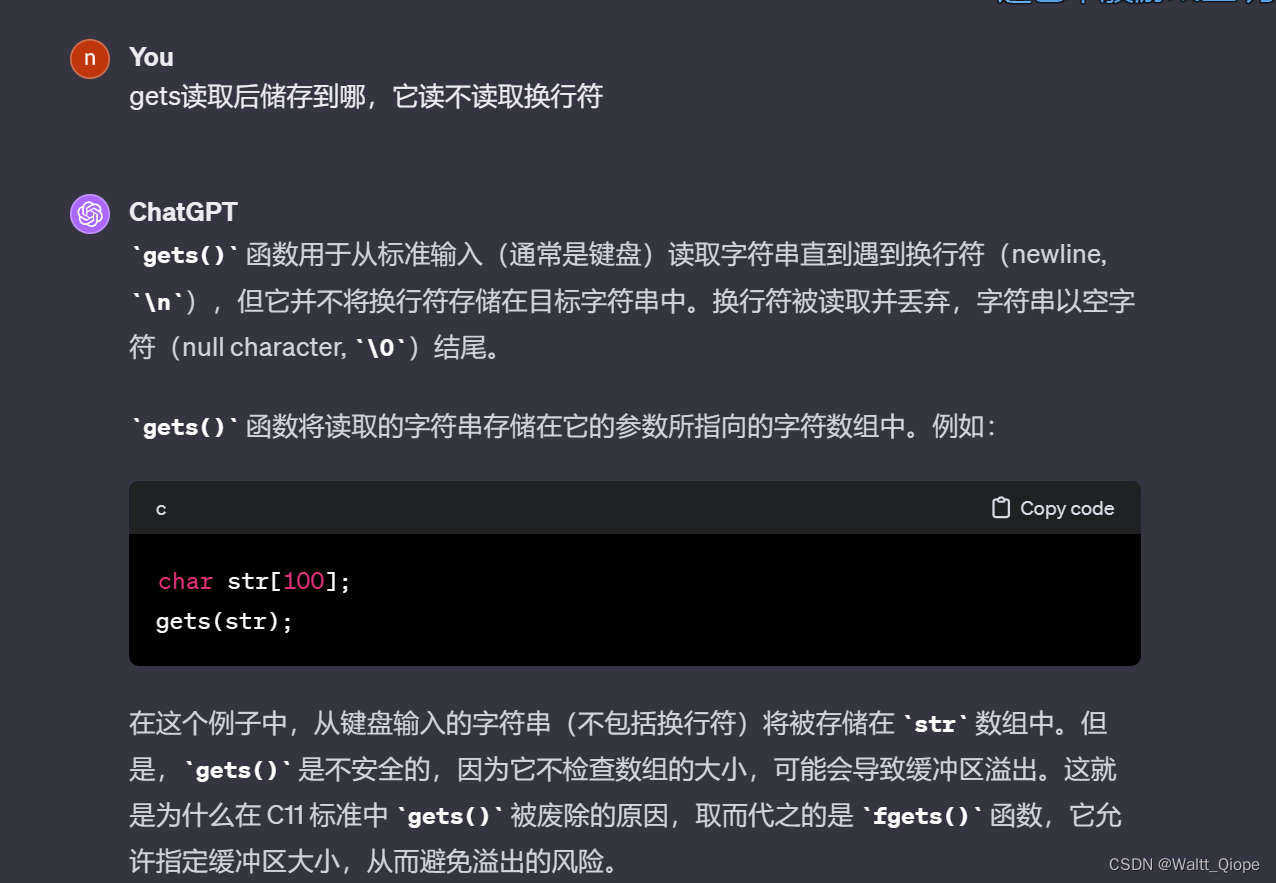
但是标准答案给的B。
值得注意的是gets的用法
22、若已定义char s[10]; 则在下面表达式中不能表示s[1]的地址的是()
A.s+1
B.s++
C.&s[0]+1
D.&s[1]
解答:
在 C 语言中,获取数组元素的地址通常可以通过几种不同的方式来实现。让我们分析每个选项:
A. s + 1:这是表示 s[1] 的地址的有效方式。s 是数组名,它在大多数上下文中被解释为指向数组首元素的指针。因此,s + 1 是指向数组第二个元素(s[1])的指针。
B. s++:这是不合法的。虽然 s++ 似乎表示指向 s[1] 的指针,但实际上 s 是数组名,不是一个可以自增的变量。在 C 语言中,数组名是常量指针,不能进行自增或自减操作。
C. &s[0] + 1:这是表示 s[1] 的地址的另一种有效方式。&s[0] 是指向数组第一个元素的指针,因此 &s[0] + 1 指向下一个元素,即 s[1]。
D. &s[1]:这直接表示 s[1] 的地址,是一种明确且正确的方法。
因此,不能表示 s[1] 的地址的是选项 B(s++)。
23、int (*fun)( )表示的含义是:
A.一个用于指向整型数据的指针变量;
B.一个用于指向一维数组的行指针;
C.一个用于指向函数的指针变量;
D.一个返回值为指针的函数名;
解答:int (*fun)( ) 表示的含义是:
C. 一个用于指向函数的指针变量;
这个声明定义了一个名为 fun 的指针,它指向一个没有参数并返回整型值的函数。在 C 语言中,函数指针是一种特殊类型的指针,用于存储函数的地址。在这个例子中,fun 可以被赋值为任何无参数且返回类型为 int 的函数的地址。
让我们来解释其他选项为何不正确:
A. 一个用于指向整型数据的指针变量; 这个描述对应的声明是 int *var;,其中 var 是一个指向 int 类型数据的指针。
B. 一个用于指向一维数组的行指针; 这个描述对应的声明可能是 int *array;,其中 array 是一个指向一维整型数组首元素的指针。
D. 一个返回值为指针的函数名; 这个描述对应的声明是 int* func();,其中 func 是一个函数,返回一个指向整型数据的指针。
24、下面程序段的输出是:
static char *s[] = {"black", "white", "pink", "violet"};
char **ptr[] = {s+3, s+2, s+1, s}, ***p;
p = ptr;
++p;
printf("%s", **p+1);
A.ink;
B.pink;
C.iolet;
D.violet;
解答:
-
static char *s[] = {"black", "white", "pink", "violet"};这行代码创建了一个字符串数组s,包含四个字符串。 -
char **ptr[] = {s+3, s+2, s+1, s};这里创建了一个指针数组ptr,其中每个元素都是指向s数组中某个元素的指针。s+3指向 "violet",s+2指向 "pink" 等。 -
char ***p; p = ptr;声明了一个三级指针p并将其指向ptr。 -
++p;这个操作使p指向ptr的下一个元素,即原本指向 "pink" 的指针。 -
printf("%s", **p+1);最后这行代码首先解引用p两次(**p)得到 "pink",然后+1操作使指针移动到 "pink" 的第二个字符,即指向 "ink"。
因此,这段代码的输出应该是 "ink"。您的误解在于,您认为 **p+1 指向一个单独的字符 'i',而不是指向字符串 "ink" 的开始。在 C 语言中,字符串是通过字符指针处理的,所以 **p+1 实际上是一个指向 'i' 的指针,但是 printf 会从这个指针开始,打印直到遇到字符串结束符 '\0' 为止的所有字符。
25、下面程序段的输出是:
int a[] = {2, 4, 6, 8, 10};
int *p = a;
*p++;
printf("%d ", *p);
(*p)++;
printf("%d ", *p);
A.3 4;
B.4 5;
C.4 6;
D.5 6;
解答:
int a[] = {2, 4, 6, 8, 10}; // 声明并初始化一个整型数组 a
int *p = a; // 声明一个指针 p,指向数组 a 的第一个元素
*p++; // 增加指针 p,使其指向数组的下一个元素
printf("%d ", *p); // 打印 p 指向的元素,此时是 a[1],即 4
(*p)++; // 增加 p 指向的元素的值,即将 a[1] 从 4 增加到 5
printf("%d ", *p); // 再次打印 p 指向的元素,现在是 5
最后贴下健✌的笔记















 5879
5879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









