






onnx文件的转换以及pt文件的修改
将训练后的pt文件转换为onnx文件
pip install onnx coremltools onnx-simplifier
导出onnx文件
pip install netron
python
import netron
netron.start('xxx.onnx')
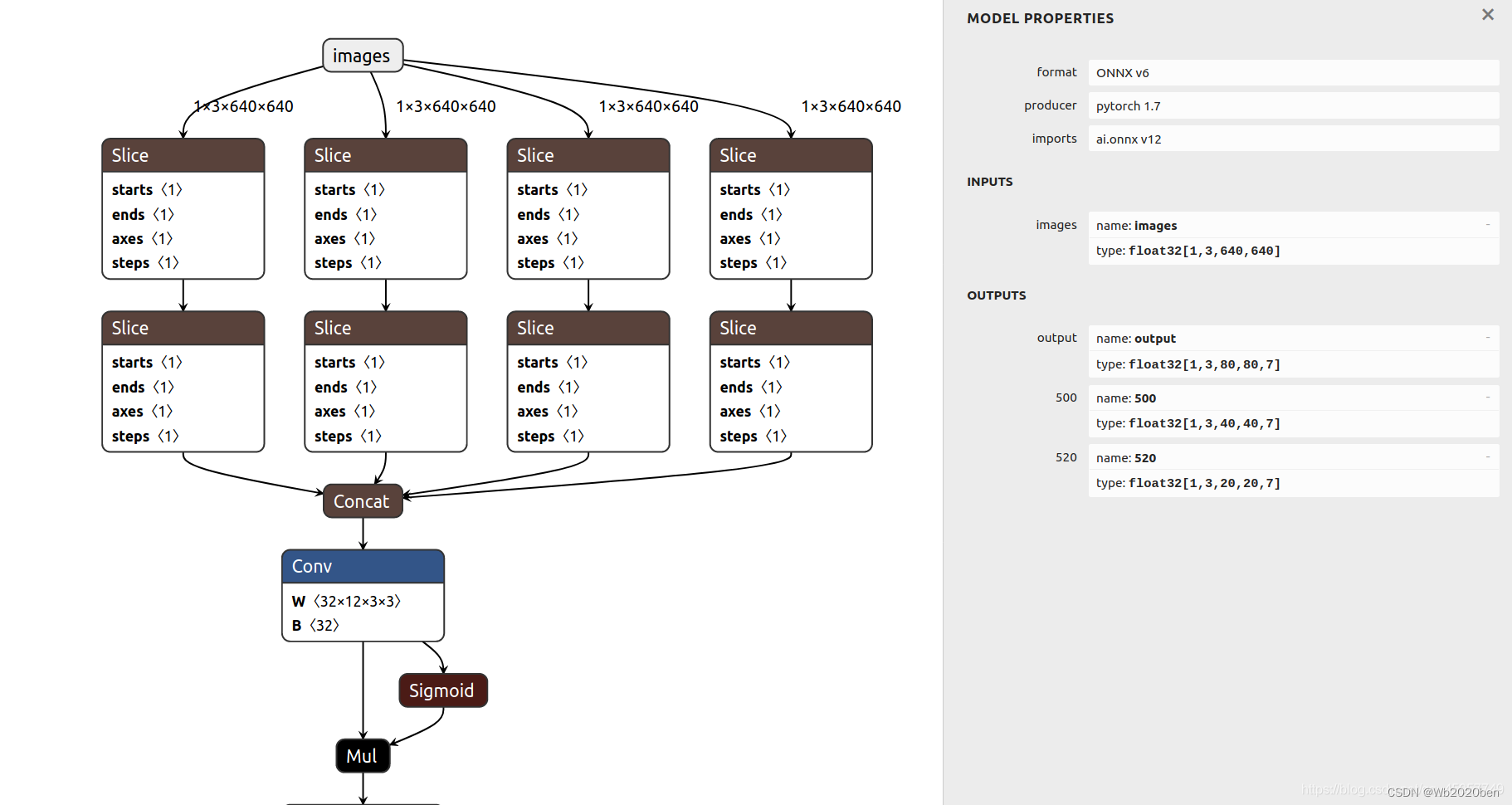
配置Python中的onnx环境
pip install onnxruntime
pip install onnx
Python中一些基础的onnx操作
- onnx模型通常只能拿到最后输出节点的输出数据,若想拿到中间节点的输出数据,需要我们自己添加相应的输出节点信息;首先需要构建指定的节点(层名称、数据类型、维度信息);然后再通过insert的方式将节点插入到模型中。
获取onnx的输出层
import onnx
# 加载模型
model = onnx.load('onnx_model.onnx')
# 检查模型格式是否完整及正确
onnx.checker.check_model(model)
# 获取输出层,包含层名称、维度信息
output = self.model.graph.output
print(output)
获取节点的输出数据
import onnx
from onnx import helper
# 加载模型
model = onnx.load('onnx_model.onnx')
# 创建中间节点:层名称、数据类型、维度信息
prob_info = helper.make_tensor_value_info('layer1',onnx.TensorProto.FLOAT, [1, 3, 320, 280])
# 将构建完成的中间节点插入到模型中
model.graph.output.insert(0, prob_info)
# 保存新的模型
onnx.save(model, 'onnx_model_new.onnx')
# 扩展:
# 删除指定的节点方法: item为需要删除的节点
# model.graph.output.remove(item)
获取查询节点的位置
def find_node(model,name): # 返回节点的序号
for node_id,node in enumerate(model.graph.node):
if node.name == name:
return node_id
删除节点
def del_node(model,name):
if type(name) == list:
for id_ in name:
del_node(model,id_)
else:
id_ = find_node(model,name)
if id_ == None :
print("输入名字错误,请核对信息")
else:
tem_node = model.graph.node[id_]
model.graph.node.remove(tem_node)
onnx前向推理InferenceSession的使用
import onnxruntime
# 创建一个InferenceSession的实例,并将模型的地址传递给该实例
sess = onnxruntime.InferenceSession('onnxmodel.onnx')
# 调用实例sess的润方法进行推理
outputs = sess.run(output_layers_name, {input_layers_name: x})
class InferenceSession(Session):
"""
This is the main class used to run a model.
"""
def __init__(self, path_or_bytes, sess_options=None, providers=[]):
"""
:param path_or_bytes: filename or serialized model in a byte string
:param sess_options: session options
:param providers: providers to use for session. If empty, will use
all available providers.
"""
self._path_or_bytes = path_or_bytes
self._sess_options = sess_options
self._load_model(providers)
self._enable_fallback = True
Session.__init__(self, self._sess)
def _load_model(self, providers=[]):
if isinstance(self._path_or_bytes, str):
self._sess = C.InferenceSession(
self._sess_options if self._sess_options else C.get_default_session_options(), self._path_or_bytes,
True)
elif isinstance(self._path_or_bytes, bytes):
self._sess = C.InferenceSession(
self._sess_options if self._sess_options else C.get_default_session_options(), self._path_or_bytes,
False)
# elif isinstance(self._path_or_bytes, tuple):
# to remove, hidden trick
# self._sess.load_model_no_init(self._path_or_bytes[0], providers)
else:
raise TypeError("Unable to load from type '{0}'".format(type(self._path_or_bytes)))
self._sess.load_model(providers)
self._sess_options = self._sess.session_options
self._inputs_meta = self._sess.inputs_meta
self._outputs_meta = self._sess.outputs_meta
self._overridable_initializers = self._sess.overridable_initializers
self._model_meta = self._sess.model_meta
self._providers = self._sess.get_providers()
# Tensorrt can fall back to CUDA. All others fall back to CPU.
if 'TensorrtExecutionProvider' in C.get_available_providers():
self._fallback_providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
else:
self._fallback_providers = ['CPUExecutionProvider']
- 在_load_model函数,可以发现在load模型的时候是通过C.InferenceSession,并且将相关的操作也委托给该类。
- 从导入语句from onnxruntime.capi import _pybind_state as C可知其实就是一个c++实现的Python接口,其源码在onnxruntime\onnxruntime\python\onnxruntime_pybind_state.cc中。
模型推理run,源码分析
def run(self, output_names, input_feed, run_options=None):
"""
Compute the predictions.
:param output_names: name of the outputs
:param input_feed: dictionary ``{ input_name: input_value }``
:param run_options: See :class:`onnxruntime.RunOptions`.
::
sess.run([output_name], {input_name: x})
"""
num_required_inputs = len(self._inputs_meta)
num_inputs = len(input_feed)
# the graph may have optional inputs used to override initializers. allow for that.
if num_inputs < num_required_inputs:
raise ValueError("Model requires {} inputs. Input Feed contains {}".format(num_required_inputs, num_inputs))
if not output_names:
output_names = [output.name for output in self._outputs_meta]
try:
return self._sess.run(output_names, input_feed, run_options)
except C.EPFail as err:
if self._enable_fallback:
print("EP Error: {} using {}".format(str(err), self._providers))
print("Falling back to {} and retrying.".format(self._fallback_providers))
self.set_providers(self._fallback_providers)
# Fallback only once.
self.disable_fallback()
return self._sess.run(output_names, input_feed, run_options)
else:
raise
以下内容为个人修改onnx文件所用,不是通用版本,请勿使用
import onnx
from onnx import helper
# 删除节点的参考
# https://blog.csdn.net/DazeAJD/article/details/126055822
# https://blog.csdn.net/qq_16792139/article/details/128720432?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EYuanLiJiHua%7EPosition-4-128720432-blog-117163212.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EYuanLiJiHua%7EPosition-4-128720432-blog-117163212.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=5
name = ["Concat_628","Unsqueeze_627","Unsqueeze_626","Unsqueeze_625",] #需要删除节点的名字
# 删除节点的示例
# prob_info = helper.make_tensor_value_info("layer1",onnx.TensorProto.FLOAT,[1,3,416,416])
#model.graph.output.insert(0,prob_info) # 插入输出端
# del_1 = model.graph.output[0]
# model.graph.output.remove(del_1)
names_concat_3 = ["/model.24/Concat","/model.24/Concat_1","/model.24/Concat_2"]
name_concat_1 = ["model.24/Concat_3"]
def del_node(model,name):
if type(name) == list:
for id_ in name:
del_node(model,id_)
else:
id_ = find_node(model,name)
if id_ == None :
print("输入名字错误,请核对信息")
elif id_ > 0 and id_ + 1 < (len(model.graph.node) - 1):
# pre,past = [model.graph.node[id-1].name,model.graph.node[id+1].name]
# 首先将上下节点位置的输入输出对接起来
# model.graph.node[id_ + 1].input = model.graph.node[id-1].output
# 删除节点
tem_node = model.graph.node[id_]
model.graph.node.remove(tem_node)
else:
tem_node = model.graph.node[id_]
model.graph.node.remove(tem_node)
def find_node(model,name): # 返回节点的序号
id_list = []
tem_list = []
for node_id,node in enumerate(model.graph.node):
if node.name == name:
return node_id
if __name__=="__main__":
model = onnx.load(r"C:\yolo\1\yolov5s_new_2.onnx")
del_node(model,"/model.24/Concat_3")
# 创建节点使用 onnx.helper.make_node("type_name",name = "your node name",other_property)
# 插入新的节点请使用 model.graph.node.insert(find_node(model,"your delet node last input name") + 1, new_node)
onnx.save(model,r"C:\yolo\1\yolov5s_new.onnx")
"""
ben_1 = onnx.helper.make_node("Concat",name = "/model.24.Concat_ben_1",axis = 4,inputs =["/model.24/Mul_1_output_0","/model.24/Mul_3_output_0"],outputs =["ben_1"] )
ben_2 = onnx.helper.make_node("Concat",name = "/model.24.Concat_ben_2",axis = 4,inputs =["/model.24/Split_output_2","ben_1"],outputs =["ben_2"] )
ben_3 = onnx.helper.make_node("Concat",name = "/model.24.Concat_ben_3",axis = 4,inputs = ["ben_1","ben_2"],outputs = ["output_0"])
"""















 3892
3892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









