







Title:Translation Embedding for Modeling Muti-relational Data
Accepted:Neural Information Processing Systems,NIPS2013
提要
知识图谱通常是用一个三元组(前件h,关系r,后件t)来表示一条知识,比如:
(清华大学,地点,北京)
要使用向量表示的话,可以是用one-hot向量(实际使用中通常是mulit-hot向量)来表示。但是问题也来了,one-hot向量维度太高,而且无法表示相近的实体或关系之间的相似程度。所以思考,类比NLP词向量的表示方法,使用分布式表示(distributed representation)来表示知识图谱中的实体喝关系,通过学习获得它们的低维稠密表示。
模型
“关系数据”由有向图表示,一个三元组关系由节点和边组成:(head,relation,tail)或(h,r,t)。
该篇论文关系数据来自KBs(Wordnet和Freebase)
该模型目的:构建一个1对1(缺陷,后续模型改进)的关系模型,将关系低维化,向量化。

如图,前件向量h,后件向量t,通过r关系向量连接,即:h+r=t(类似于词向量)
举例:
(北京,首都,中国),这里h为北京,t为中国,r是“is capital of”关系。此r关系也可运用在(巴黎,首都,法国)等三元组中。而(老师,工作地点,学校)这类三元组的关系r向量就与之前的向量不同。
损失函数
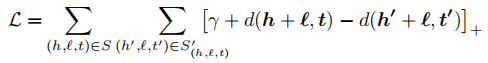
tips:
[ ]+的意思是大于0取原值,小于0则取0。这叫做合页损失函数,训练方法叫做margin-based ranking criterion。此loss函数来自SVM,目的是将正和负尽可能分开。一般margin=1。
其中d是L1或L2的距离,表示h+r向量与t向量之间的距离。
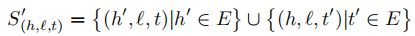
三元组(h’+l, t’)由正例三元组中的头节点、尾节点随机选择替换,并且头尾不能同时被替换(??)。
训练算法

算法理解:

后续源码理解
附加网址:
OpenKE:http://139.129.163.161//index/toolkits?tdsourcetag=s_pctim_aiomsg
TransE论文:http://papers.nips.cc/paper/5071-translating-embeddings-for-modeling-multi-relational-data.pdf















 5624
5624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









