







考完试无聊,下载了新冠肺炎的一些数据做了数据可视化,当作练练手。
数据集下载链接
此次使用了covid_19_data.csv数据
注:因为这个数据隔段时间会更新因此不同时间下载的统计日期会不同。该篇文章的数据统计日期截止到2020/07/08。
相关知识点:pandas分组,折线图、堆叠图、饼图的绘制。
一、GDP前十国家的确诊人数变化图
思路
covid_19_data.csv:
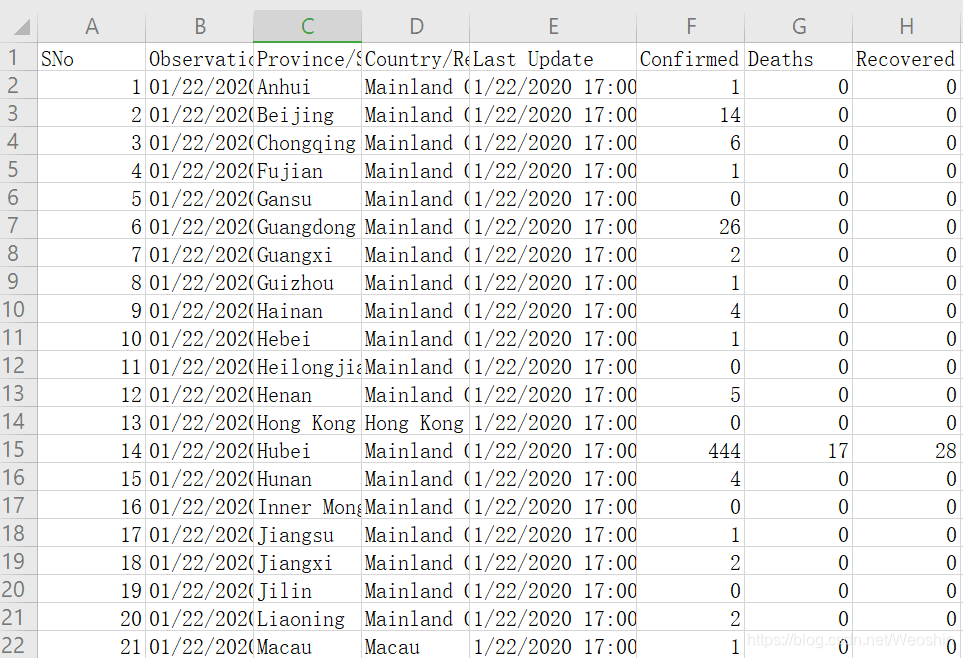
读入数据是pandas类型数据,这是比较常见的类型。
要统计美国、中国、日本、德国、法国、英国、印度、意大利、巴西、加拿大十个国家的确诊人数的变化图,首先需要生成每个国家的确诊人数列表。
观察数据可知一个国家经常包含多个省份/州,而这些应该加在一起作为一个国家的数据,因此首先对国家进行分组:
df_Country = df.groupby(['Country'])
制作date列表
date = df['Date'].drop_duplicates().values.tolist() # drop_duplicates(),去掉重复行
date_list = [str(x) for x in date] #将list中的数字型转为str型
接下来制作单个国家的数据列表
以Mainland China为例,首先用get_group()获取Mainland China数据,在此基础上按Date分组并求和,获得每天的总数据。
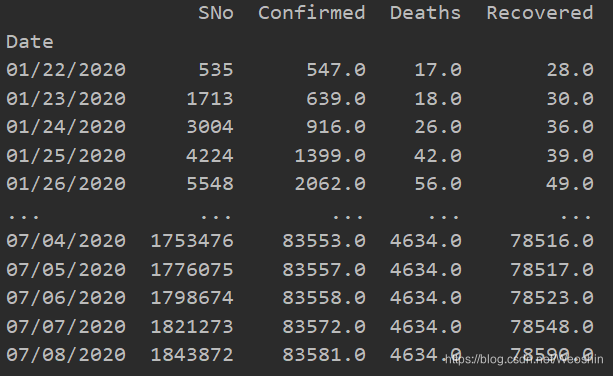
最后单独提取出Confirmed数据,转为list。
grouped = df_Country.get_group('Mainland China')
china_data = grouped.groupby('Date').sum()
china_confirmed = china_data['Confirmed'].tolist()
Code
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib.ticker as ticker
path = "D:/Kaggle/Covid-2019/covid_19_data/covid_19_data.csv" #路径自行设定
df = pd.read_csv(path)
#重命名列名
df = df.rename(columns={'Country/Region':'Country'})
df = df.rename(columns={'ObservationDate':'Date'})
df_Country = df.groupby(['Country']) #按Country分组
date = df['Date'].drop_duplicates().values.tolist() # drop_duplicates(),去掉重复行
date_list = [str(x) for x in date] #将list中的数字型转为str型
#-----Mainland China
grouped = df_Country.get_group('Mainland China')
china_data = grouped.groupby('Date').sum()
china_confirmed = china_data['Confirmed'].tolist()
#-----US
grouped = df_Country.get_group('US')
us_data = grouped.groupby('Date').sum()
us_confirmed = us_data['Confirmed'].tolist()
#-----Brazil
grouped = df_Country.get_group('Brazil')
brazil_data = grouped.groupby('Date').sum()
brazil_confirmed = brazil_data['Confirmed'].tolist()
#-----UK
grouped = df_Country.get_group('UK')
uk_data = grouped.groupby('Date').sum()
uk_confirmed = uk_data['Confirmed'].tolist()
#-----India
grouped = df_Country.get_group('India')
india_data = grouped.groupby('Date').sum()
india_confirmed = india_data['Confirmed'].tolist()
#-----France
grouped = df_Country.get_group('France')
france_data = grouped.groupby('Date').sum()
france_confirmed = france_data['Confirmed'].tolist()
#-----Germany
grouped = df_Country.get_group('Germany')
germany_data = grouped.groupby('Date').sum()
germany_confirmed = germany_data['Confirmed'].tolist()
#-----Italy
grouped = df_Country.get_group('Italy')
italy_data = grouped.groupby('Date').sum()
italy_confirmed = italy_data['Confirmed'].tolist()
#-----Canada
grouped = df_Country.get_group('Canada')
canada_data = grouped.groupby('Date').sum()
canada_confirmed = canada_data['Confirmed'].tolist()
#-----Japan
grouped = df_Country.get_group('Japan')
japan_data = grouped.groupby('Date').sum()
japan_confirmed = japan_data['Confirmed'].tolist()
#因为每个国家确诊人数统计开始日期不同,所以以统计时间最早的为准,时间短的在列表前补len(date_list)-len(country)个0
countries_confirmed = [china_confirmed,us_recovered,brazil_confirmed,uk_confirmed,india_confirmed,france_confirmed,
germany_confirmed,italy_confirmed,canada_confirmed,japan_confirmed]
for country in countries_confirmed:
if len(country) < len(date_list):
for i in range(len(date_list) - len(country)):
country.insert(0, 0)
#画图
plt.plot(date_list,china_confirmed,color = 'red',label="China")
plt.plot(date_list,us_confirmed,color = 'blue',label="US")
plt.plot(date_list,brazil_confirmed,color = 'green',label="Brazil")
plt.plot(date_list,uk_confirmed,color = 'black',label="UK")
plt.plot(date_list,india_confirmed,color = 'pink',label="India")
plt.plot(date_list,france_confirmed,color = 'yellow',label="France")
plt.plot(date_list,germany_confirmed,color = 'orange',label="Germany")
plt.plot(date_list,italy_confirmed,color = '#00FFFF',label="Italy")
plt.plot(date_list,canada_confirmed,color = '#C0C0C0',label="Canada")
plt.plot(date_list,japan_confirmed,color = '#808000',label="Japan")
plt.title("Confirmed number")
plt.xlabel("Date")
plt.ylabel("Number")
plt.grid(axis='y') #水平线显示
ax = plt.gca() #获取坐标信息
ax.set_facecolor('#FFFAF0') #设置背景颜色
#调整x轴刻度密度,相隔tick_spacing个刻度显示一个,有效防止刻度太多显示重合
tick_spacing = 10
ax.xaxis.set_major_locator(ticker.MultipleLocator(tick_spacing))
plt.xticks(rotation=30) #旋转x轴坐标刻度,有效防止xlabel太长显示重合
plt.legend()
plt.tight_layout()
plt.show()
效果图
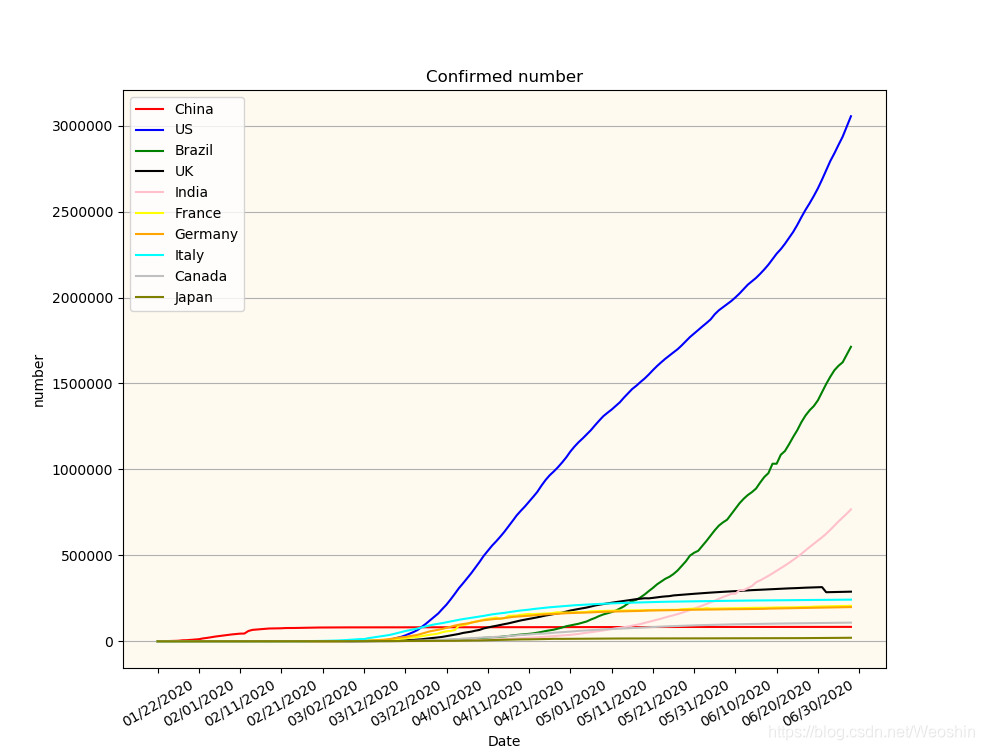
果然美国一骑绝尘,巴西印度紧跟上。
二、美国三个指标变化图
思路
思路较简单,在第一部分组思路上将生成deaths_list和recovered_list即可。此部分因注意堆叠图的画法。
Code
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib.ticker as ticker
path = "D:/Kaggle/Covid-2019/covid_19_data/covid_19_data.csv" #自行设定
df = pd.read_csv(path)
df = df.rename(columns={'Country/Region':'Country'})
df = df.rename(columns={'ObservationDate':'Date'})
df_Country = df.groupby(['Country']) #按Country分组
date = df['Date'].drop_duplicates().values.tolist() # drop_duplicates(),去掉重复行
date_list = [str(x) for x in date] #将list中的数字型转为str型,实用。
print(date_list)
grouped = df_Country.get_group('US')
us_data = grouped.groupby('Date').sum()
print(us_data)
us_confirmed = us_data['Confirmed'].tolist()
us_deaths = us_data['Deaths'].tolist()
us_recovered = us_data['Recovered'].tolist()
if len(us_confirmed)<len(date_list):
for i in range(len(date_list)-len(us_confirmed)):
us_confirmed.insert(0,0)
print(len(us_confirmed))
#画图(堆叠图)
info = ['deaths','recovered','confirmed'] #标签
color = ['#FF4040','#87CEFA','#FFF68F',] #颜色
plt.stackplot(date_list,us_deaths, us_recovered,us_confirmed, labels=info, colors = color) #堆叠图
plt.legend(loc='upper left')
tick_spacing = 10
ax = plt.gca() #获取坐标信息
ax.xaxis.set_major_locator(ticker.MultipleLocator(tick_spacing))
plt.xticks(rotation=30) #旋转x轴坐标刻度,有效防止xlabel太长显示重合
plt.grid(axis='y') #水平线显示
plt.title("US data")
plt.xlabel("date")
plt.ylabel("number")
plt.tight_layout()
plt.show()
效果图
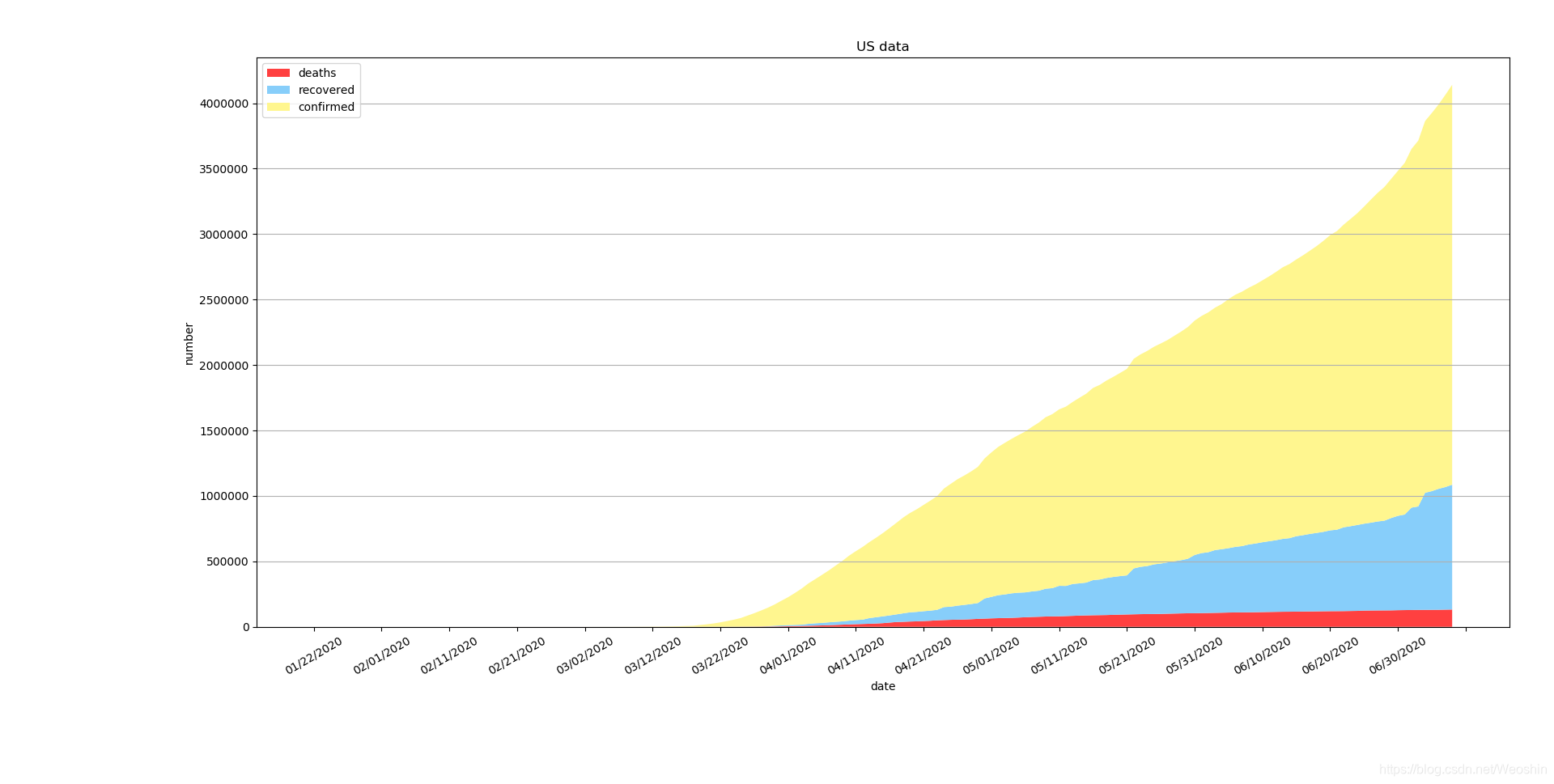
美国确诊人数上升加速度有增大趋势,所幸的是死亡率也在降低。
GDP前十国家确诊人数占全球数据的比例
思路
思路和第一部分类似,不同的是这次统计最后截止日期的确诊人数,以及需要计算出全球确诊人数,因此分类标准不同。
首先对Date分组
df_lastday = df.groupby(['Date'])
然后对每一个Date组求和,提取07/08/2020的数据,可以得到07/08/2020的每个国家的数据。
求Confirmed列所有数据总和可以得到全球确诊人数,但由于sum()得到的数据是pandas类型,因此转为list型并取第一个数,得到全球确诊人数。
grouped = df_lastday.get_group('07/08/2020')
confirmed_number = grouped.groupby('Date').sum()
confirmed_number = confirmed_number['Confirmed'].tolist()
confirmed_number = confirmed_number[0]
print(confirmed_number)
之后生成每个国家的confirmed列表,与第一部分相同。此部分应注意饼状图的画法。
Code
import pandas as pd
from matplotlib import pyplot as plt
path = "D:/Kaggle/Covid-2019/covid_19_data/covid_19_data.csv"#自行设定
df = pd.read_csv(path)
df = df.rename(columns={'Country/Region':'Country'})
df = df.rename(columns={'ObservationDate':'Date'})
df_lastday = df.groupby(['Date']) #按Date分组
date = df['Date'].drop_duplicates().values.tolist() # drop_duplicates(),去掉重复行
date_list = [str(x) for x in date] #将list中的数字型转为str型
#计算截至2020.7.8确诊总人数
grouped = df_lastday.get_group('07/08/2020')
confirmed_number = grouped.groupby('Date').sum()
confirmed_number = confirmed_number['Confirmed'].tolist()
confirmed_number = confirmed_number[0]
df_Country = df.groupby(['Country']) #依次按Country分组
grouped = df_Country.get_group('US')
us_data = grouped.groupby('Date').sum()
us_confirmed = us_data['Confirmed'].tolist()[-1] #取列表最后一个数据:最后一天数据
grouped = df_Country.get_group('Mainland China')
china_data = grouped.groupby('Date').sum()
china_confirmed = china_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('Japan')
japan_data = grouped.groupby('Date').sum()
japan_confirmed = japan_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('Germany')
germany_data = grouped.groupby('Date').sum()
germany_confirmed = germany_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('UK')
uk_data = grouped.groupby('Date').sum()
uk_confirmed = uk_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('France')
france_data = grouped.groupby('Date').sum()
france_confirmed = france_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('Brazil')
brazil_data = grouped.groupby('Date').sum()
brazil_confirmed = brazil_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('India')
india_data = grouped.groupby('Date').sum()
india_confirmed = india_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('Italy')
italy_data = grouped.groupby('Date').sum()
italy_confirmed = italy_data['Confirmed'].tolist()[-1]
grouped = df_Country.get_group('Canada')
canada_data = grouped.groupby('Date').sum()
canada_confirmed = canada_data['Confirmed'].tolist()[-1]
#求全球剩余国家的确诊人数
other = confirmed_number-us_confirmed-china_confirmed-japan_confirmed-germany_confirmed-uk_confirmed-france_confirmed-brazil_confirmed-india_confirmed-italy_confirmed-canada_confirmed
#创建字典
info = {'US':us_confirmed,
'Mainland China':china_confirmed,
'Japan':japan_confirmed,
'Germany':germany_confirmed,
'UK':uk_confirmed,
'France':france_confirmed,
'Brazil':brazil_confirmed,
'India':india_confirmed,
'Italy':italy_confirmed,
'Canada':canada_confirmed,
'other':other}
#为了饼状图美观,对数据进行排序
info = sorted(info.items(),key=lambda x:x[1],reverse=True) #按照字典value排序,生成一列表,列表元素为元组,元组元素为国家(key),确诊人数(value)。
#单独对国家、对应的确诊人数生成列表,方便画图
sizes=[]
labels=[]
for i in range(len(info)):
labels.append(info[i][0])
sizes.append(info[i][1])
#画图
colors = ['#87CEFF','#FF7256','#FFE7BA','#B3EE3A','#E6E6FA','#FFC0CB','#CDC0B0','#C1CDCD','#FFFF00','#54FF9F','#F5F5F5'] #颜色
explode = (0,0,0,0,0,0,0,0,0,0,0) #突出显示设定
patches,l_text,p_text = plt.pie(sizes,
explode=explode,
labels=labels,
colors=colors,
autopct = '%3.1f%%', #数值保留固定小数位
shadow = False, #无阴影设置
startangle =90, #逆时针起始角度设置
pctdistance = 1.2) #数值距圆心半径倍数距离
#l_text :饼图外文本,p_text:饼图内文本
for t in l_text:
t.set_size(0)
for t in p_text:
t.set_size(8)
plt.legend(labels)
plt.title('proportion')
plt.show()
效果图
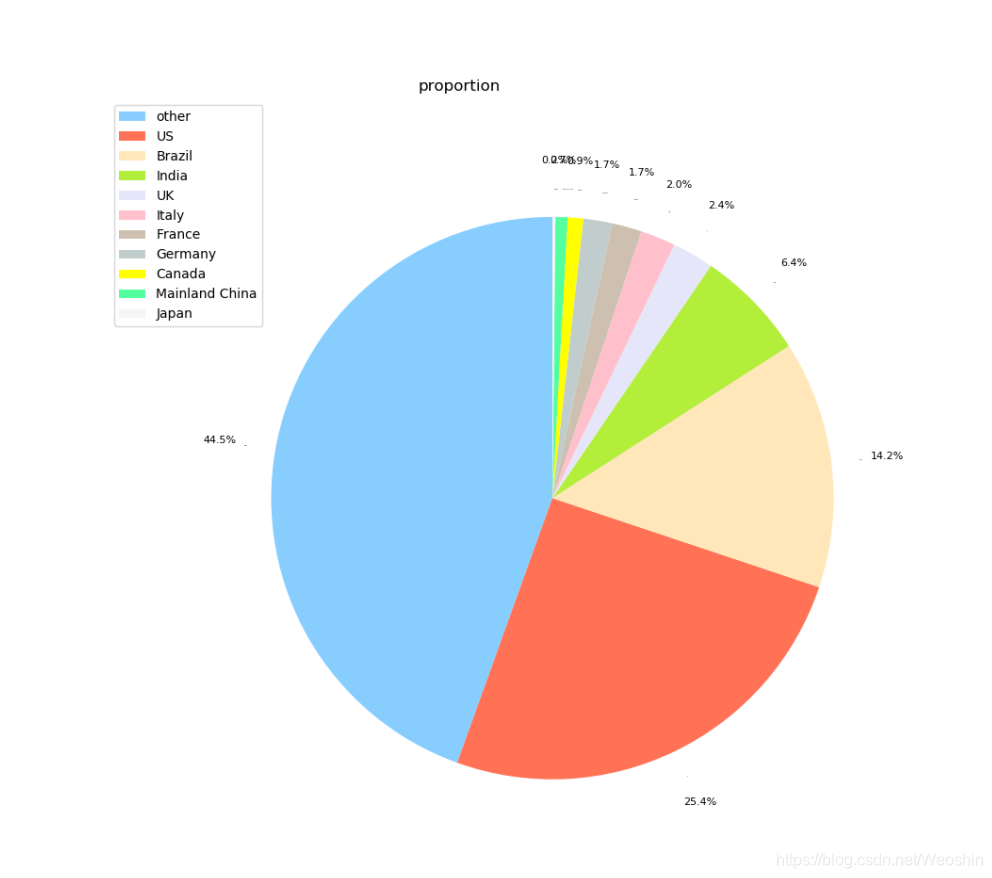
美国、印度、巴西占据近半壁江山,中国大陆相比控制的很好。
此次练手,学习了pandas的分组方法,增强了对数据的整理能力,熟悉了折线图、堆叠图和饼状图的绘制以及相关细节调整,要牢记在确保准确的同时还不能忘记可视化的美观。














 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









