









目录
赔率
浔阳江畔艄公张横和张顺正进行400米自由泳比赛, 宋江开赌场做庄,规定:张横赢赔率为3,张顺赢 赔率为2。假定不存在平局。赌徒李逵为张横下注 10两。比赛结束后,若最终张横赢,则宋江付赌徒李逵30两(10×3),赌资10两归庄家宋江所有,即李逵赚20两。若张顺赢,赌资10两归庄家宋江所有,即李逵赔10两。

假定所有赌徒中,共有a元买张横,b元买张 顺,则开赛前宋江收入为a+b元,开赛后的赔付期望为:![]()
从上述结论知:使用y=1/p作为赔率,会使 得庄家在期望上不赔不赚。
这即“公平赔率”:yfair
——没有利润,这显然是庄家不希望看到的
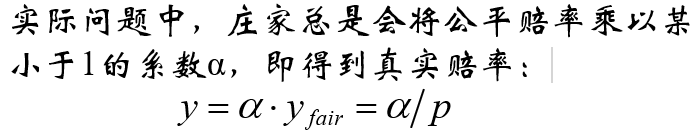
案例


计算赔率
拼团人数当时是1026人,尚有两天结束,根据历史先验,假定1天参团人数为100人,则最终参团人数为1226左右。考虑到3月12日为星期日,参团人数或许略低,因此大体参 团区间可能是[1180,1230]。

Pandas
1.Fuzzywuzzy - Levenshtein distance 做数据清洗,尤其是做字符串的替换。
2.模糊查询与替换。
鸢尾花数据集
鸢尾花数据集或许是最
有
名的
模
式识
别
测试
数
据。
早在1936
年,模式识别的先驱
Fisher
就在论文“
The
use
of multiple
measurements
in
taxonomic problems”
中使用了它
(
直至今日该论文仍然被频繁引
用
)
。
该数据集包括
3
个鸢
尾
花类
别
,每
个
类别
有
50
个样 本。其中一个类别是与
另
外两
类
线性
可
分的
,
而另 外两类不能线性可分。
由于Fisher
的最原始数据集存在两个错
误
(35
号和
38
号样本)
,实验中我们使用的是修正过
的
数据。
数据清洗和数据处理



车辆数据描述


代码区
判断1-10万间是否为素数
#!/usr/bin/python
# -*- coding:utf-8 -*-
import operator
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from time import time
import math
def is_prime(x):
return 0 not in [x % i for i in range(2, int(math.sqrt(x)) + 1)]#整除比自己的数,除数#从2开始。
def is_prime3(x):
flag = True
for p in p_list2:
if p > math.sqrt(x):
break
if x % p == 0:
flag = False
break
if flag:
p_list2.append(x)
return flag
if __name__ == "__main__":
a = 2
b = 100000
# 方法1:直接计算
t = time()
p = [p for p in range(a, b) if 0 not in [p % d for d in range(2, int(math.sqrt(p)) + 1)]]
print time() - t
print p
# 方法2:利用filter
t = time()
p = filter(is_prime, range(a, b))
print time() - t
print p
# 方法3:利用filter和lambda
t = time()
is_prime2 = (lambda x: 0 not in [x % i for i in range(2, int(math.sqrt(x)) + 1)])
p = filter(is_prime2, range(a, b))
print time() - t
print p
# 方法4:定义
t = time()
p_list = []
for i in range(2, b):
flag = True
for p in p_list:
if p > math.sqrt(i):
break
if i % p == 0:
flag = False
break
if flag:
p_list.append(i)
print time() - t
print p_list
# 方法5:定义和filter
p_list2 = []
t = time()
filter(is_prime3, range(2, b))
print time() - t
print p_list2
print '---------------------'
a = 1180
b = 1230
a = 1600
b = 1700
p_list2 = []
p = np.array(filter(is_prime3, range(2, b+1)))
p = p[p >= a]
print p
p_rate = float(len(p)) / float(b-a+1)
print '素数的概率:', p_rate, '\t',
print '公正赔率:', 1/p_rate
print '合数的概率:', 1-p_rate, '\t',
print '公正赔率:', 1 / (1-p_rate)

模拟环形公路堵车
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
def clip(x, path):
for i in range(len(x)):
if x[i] >= path:
x[i] %= path
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
path = 5000 # 环形公路的长度
n = 100 # 公路中的车辆数目
v0 = 50 # 车辆的初始速度
p = 0.3 # 随机减速概率
Times = 3000
np.random.seed(0)
x = np.random.rand(n) * path
x.sort()
v = np.tile([v0], n).astype(np.float)
plt.figure(figsize=(10, 8), facecolor='w')
for t in range(Times):
plt.scatter(x, [t]*n, s=1, c='k', alpha=0.05)
for i in range(n):
if x[(i+1)%n] > x[i]:
d = x[(i+1) % n] - x[i] # 距离前车的距离
else:
d = path - x[i] + x[(i+1) % n]
if v[i] < d:
if np.random.rand() > p:
v[i] += 1
else:
v[i] -= 1
else:
v[i] = d - 1
v = v.clip(0, 150)
x += v
clip(x, path)
plt.xlim(0, path)
plt.ylim(0, Times)
plt.xlabel(u'车辆位置', fontsize=16)
plt.ylabel(u'模拟时间', fontsize=16)
plt.title(u'环形公路车辆堵车模拟', fontsize=20)
plt.tight_layout(pad=2)
plt.show()















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









