







1.数据集介绍
下载自Kaggle的COVID-19放射学数据库(获得Kaggle社区颁发的COVID-19数据集奖)https://www.kaggle.com/datasets/tawsifurrahman/covid19-radiography-database
来自卡塔尔多哈卡塔尔大学和孟加拉国达卡大学的一组研究人员,以及来自巴基斯坦和马来西亚的合作者,与医生合作,创建了一个COVID-19阳性病例的胸部x射线图像数据库,以及正常肺炎和病毒性肺炎图像。这个COVID-19、正常和其他肺部感染数据集是分阶段发布的。在第一次发布中,我们发布了219张COVID-19胸片、1341张正常胸片和1345张病毒性肺炎胸片(CXR)。在第一次更新中,我们将COVID-19类别增加到1200个CXR图像。在第二次更新中,我们将数据库增加到3616例COVID-19阳性病例,10192例正常病例,6012例肺不透明(非COVID-19肺感染),1345例病毒性肺炎图像和相应的肺口罩。一旦获得新的COVID-19肺炎患者的x射线图像,我们将继续更新该数据库。
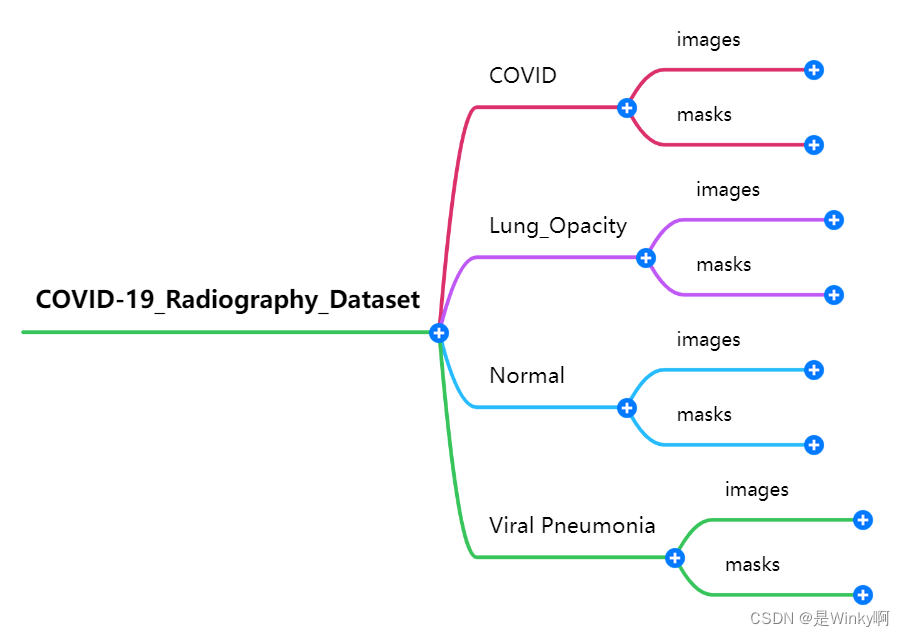
即这个数据集包括四种数据:COVID-19阳性病例,正常病例,肺不透明(非COVID-19肺感染),病毒性肺炎的图像和相应的掩码图像。
2.数据集的处理
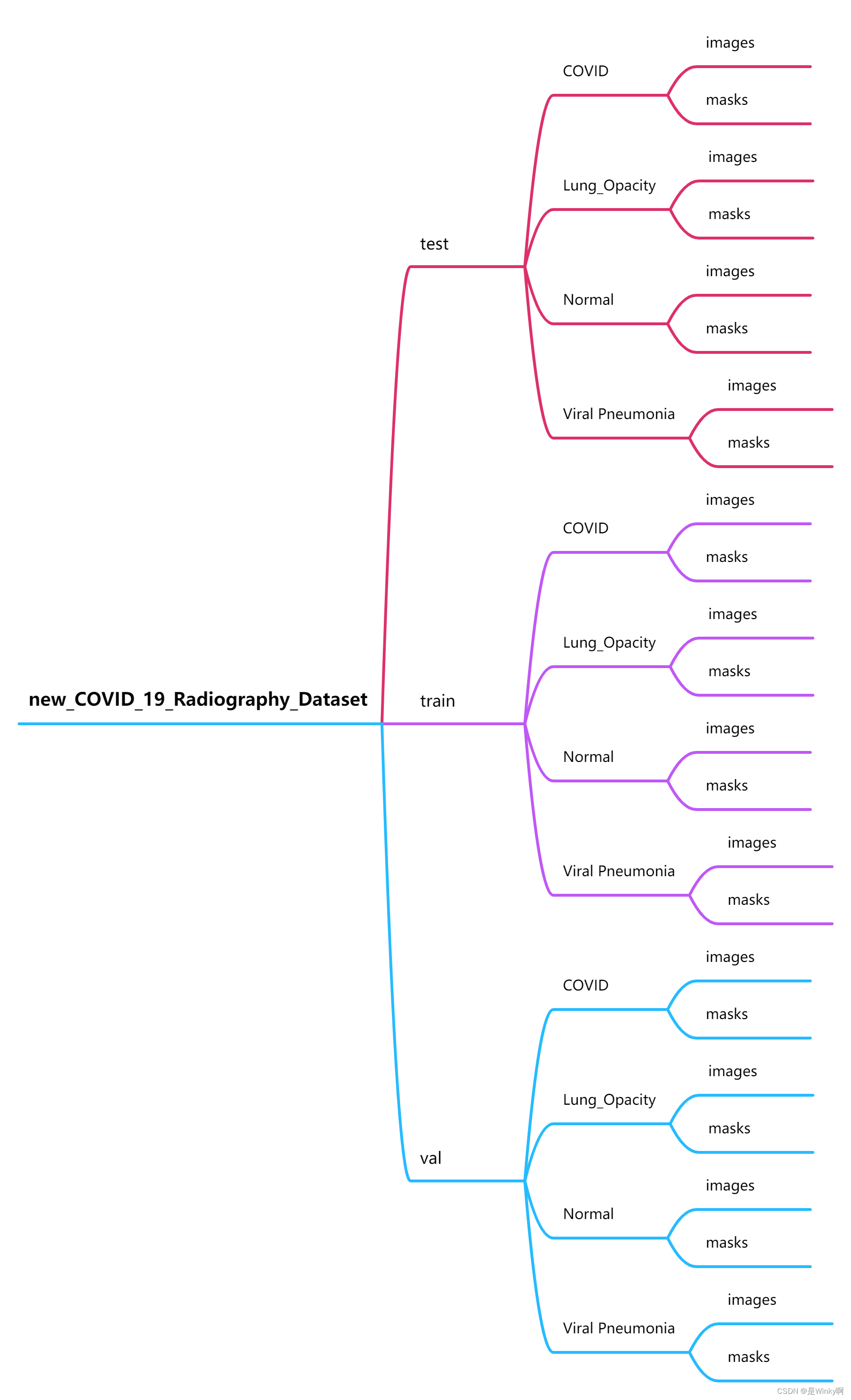
取20%的数据集为test、80%为train,train中再取10%为val(0.72为train、0.08为val)
(要将数据划分为合理形式,才能开始训练)
原数据
划分后的数据
代码
import os
import shutil
dataset_path = "COVID-19_Radiography_Dataset" # 数据集源路径
output_path = "new_COVID_19_Radiography_Dataset" # 数据集的产出路径
# 创建test、train和val文件夹
os.makedirs(os.path.join(output_path, "test"), exist_ok=True)
os.makedirs(os.path.join(output_path, "train"), exist_ok=True)
os.makedirs(os.path.join(output_path, "val"), exist_ok=True)
# 创建类别文件夹
categories = ["COVID", "Lung_Opacity", "Normal", "Viral Pneumonia"]
for category in categories:
os.makedirs(os.path.join(output_path, "test", category, "images"), exist_ok=True) # 创建 new_COVID_19_Radiography_Dataset\test\COVID\images
os.makedirs(os.path.join(output_path, "test", category, "masks"), exist_ok=True)
os.makedirs(os.path.join(output_path, "train", category, "images"), exist_ok=True)
os.makedirs(os.path.join(output_path, "train", category, "masks"), exist_ok=True)
os.makedirs(os.path.join(output_path, "val", category, "images"), exist_ok=True)
os.makedirs(os.path.join(output_path, "val", category, "masks"), exist_ok=True)
for category in categories:
image_folder = os.path.join(dataset_path, category, "images") # COVID-19_Radiography_Dataset\COVID\images
mask_folder = os.path.join(dataset_path, category, "masks") # COVID-19_Radiography_Dataset\COVID\masks
# 获取文件列表
images = sorted(os.listdir(image_folder)) # 返回images文件夹中所有图像组成的列表
masks = sorted(os.listdir(mask_folder))
# print(masks)
# images = sorted(os.listdir(image_folder),key=lambda x: int(x.split('.')[0].split('-')[1])) # COVID-1.png
# masks = sorted(os.listdir(mask_folder))
# print(images)
# 计算划分的索引
total_images = len(images) # covid 3616
test_size = int(0.2 * total_images) # 3616*0.2
val_size = int(0.1 * (total_images - test_size)) # 从80% 中取 10% = 8%
# 划分数据集
test_images = images[:test_size] # 723
val_images = images[test_size:test_size + val_size]
train_images = images[test_size + val_size:]
# 复制图片和mask到对应的文件夹
for img in test_images:
src_img = os.path.join(image_folder, img) # COVID-19_Radiography_Dataset\COVID\images
src_mask = os.path.join(mask_folder, img)
dest_img = os.path.join(output_path, "test", category, "images", img) # new_COVID_19_Radiography_Dataset\test\COVID\images
dest_mask = os.path.join(output_path, "test", category, "masks", img)
shutil.copy(src_img, dest_img)
shutil.copy(src_mask, dest_mask)
for img in val_images:
src_img = os.path.join(image_folder, img)
src_mask = os.path.join(mask_folder, img)
dest_img = os.path.join(output_path, "val", category, "images", img)
dest_mask = os.path.join(output_path, "val", category, "masks", img)
shutil.copy(src_img, dest_img)
shutil.copy(src_mask, dest_mask)
for img in train_images:
src_img = os.path.join(image_folder, img)
src_mask = os.path.join(mask_folder, img)
dest_img = os.path.join(output_path, "train", category, "images", img)
dest_mask = os.path.join(output_path, "train", category, "masks", img)
shutil.copy(src_img, dest_img)
shutil.copy(src_mask, dest_mask)将这段代码放在"COVID-19_Radiography_Dataset"所在的文件夹,成为"COVID-19_Radiography_Dataset"的同级文件,在jupyter中运行即可处理数据集。
3.模型训练
在模型训练之前,要在训练代码的文件夹内创建"model_pth"文件夹,来存储训练生成的权重文件。
代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm import tqdm
import os
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([ # 定义训练集和测试集的图像变换(预处理)操作
transforms.Resize([224, 224]), # 调整图像大小为224x224像素
transforms.ToTensor(), # 将图像转换为PyTorch张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行标准化
])
transform_test = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载训练集和测试集,指定图像变换操作
trainset = datasets.ImageFolder(root=os.path.join('new_COVID_19_Radiography_Dataset', 'train'), # 训练集根目录
transform=transform_train) # 训练集图像变换
testset = datasets.ImageFolder(root=os.path.join('new_COVID_19_Radiography_Dataset', 'val'), # 测试集根目录
transform=transform_test) # 测试集图像变换
# 创建训练数据加载器
train_loader = DataLoader(trainset, batch_size=32, num_workers=0, # 每个批次的样本数为 32 # 使用 0 个额外的子进程来加载数据
shuffle=True, pin_memory=True) # 每个 epoch 开始时,对数据进行洗牌,随机打乱数据集顺序 # 将数据存储在 CUDA 固定内存上,以提高 GPU 加载速度
# 创建测试数据加载器
test_loader = DataLoader(testset, batch_size=32, num_workers=0,
shuffle=False, pin_memory=True)
# 定义基础的 CNN 模型
class SimpleCNN(nn.Module):
def __init__(self, num_classes=4):
super(SimpleCNN, self).__init__()
self.features = nn.Sequential( # 定义卷积层和池化层
# 第一个卷积层:输入通道为3(RGB图像),输出通道为16,卷积核大小为3x3,步长为1,填充为1
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1), # 换为卷积 更好的特征提取 卷积核为3 步长为1 填充为1
nn.ReLU(inplace=True), # 使用ReLU激活函数 # inplace=True 原地进行操作
# 最大池化层:池化核大小为2x2,步长为2
nn.MaxPool2d(kernel_size=2, stride=2), # 将图像大小减半,从224x224变为112x112
# 第二个卷积层:输入通道为16,输出通道为32,卷积核大小为3x3,步长为1,填充为1
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# 最大池化层:池化核大小为2x2,步长为2
nn.MaxPool2d(kernel_size=2, stride=2) # 将图像大小减半,从112x112变为56x56
)
# 定义全连接层
self.classifier = nn.Sequential(
nn.Linear(32 * 56 * 56, 128), # 输入大小为32x56x56,输出大小为128 32 是第二个卷积层的输出通道数
nn.ReLU(inplace=True),
nn.Linear(128, num_classes) # 输入大小为128,输出大小为类别数(默认为4)
)
def forward(self, x):
# 前向传播过程
x = self.features(x) # 应用卷积层和池化层
x = x.view(x.size(0), -1) # 将特征图展平为一维向量
x = self.classifier(x) # 应用全连接层
return x
# 将模型送到GPU上
num_classes = 4
model = SimpleCNN(num_classes).to(device)
# 定义训练函数
def train(model, train_loader, criterion, optimizer, num_epochs=100):
"""
训练模型函数
参数:
- model: 要训练的模型
- train_loader: 训练集数据加载器
- criterion: 损失函数
- optimizer: 优化器
- num_epochs: 训练的总epoch数,默认为100
"""
best_accuracy = 0.0 # 保存最佳准确率
for epoch in range(num_epochs): # 遍历每个 epoch
model.train() # 将模型设置为训练模式
running_loss = 0.0 # 初始化一个变量用于累计每个 epoch 的损失
with tqdm(total=len(train_loader), desc=f'Epoch {epoch+1}/{num_epochs}', unit='batch') as pbar: # 使用 tqdm 库创建一个进度条,显示当前 epoch 的进度
for inputs, labels in train_loader: # 遍历每个 batch 的数据
inputs, labels = inputs.to(device), labels.to(device) # 将数据送到GPU上
optimizer.zero_grad() # 梯度清零,以便后续计算新的梯度
outputs = model(inputs) # 将数据输入模型,获取模型的预测输出
loss = criterion(outputs, labels) # 计算模型的损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() * inputs.size(0) # 更新当前 epoch 的损失
pbar.update(1) # 更新进度条,显示当前 batch 的损失
pbar.set_postfix({'loss': loss.item()})
epoch_loss = running_loss / len(train_loader.dataset) # 计算当前 epoch 的平均损失
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}") # 打印当前 epoch 的损失
# 在每个 epoch 结束后评估模型并保存最佳权重
accuracy = evaluate(model, test_loader ,criterion)
if accuracy > best_accuracy:
best_accuracy = accuracy
save_model(model, save_path)
print("Model saved with best accuracy:", best_accuracy)
# 评估模型在测试集上的性能
def evaluate(model, test_loader, criterion):
model.eval() # 将模型设置为评估模式
test_loss = 0.0 # 初始化测试损失
correct = 0 # 初始化预测正确的样本数
total = 0 # 初始化总样本数
with torch.no_grad(): # 在评估阶段不需要计算梯度
for inputs, labels in test_loader: # 遍历测试集中的每个 batch
inputs, labels = inputs.to(device), labels.to(device) # 将数据送到GPU上
outputs = model(inputs) # 将数据输入模型,获取模型的预测输出
loss = criterion(outputs, labels) # 计算模型的损失
test_loss += loss.item() * inputs.size(0) # 累计测试损失
_, predicted = torch.max(outputs, 1) # 获取模型预测的类别
total += labels.size(0) # 更新总样本数
correct += (predicted == labels).sum().item() # 更新预测正确的样本数
avg_loss = test_loss / len(test_loader.dataset) # 计算平均测试损失
accuracy = 100.0 * correct / total # 计算准确率
print(f"Test Loss: {avg_loss:.4f}, Accuracy: {accuracy:.2f}%") # 输出测试损失和准确率
return accuracy # 返回准确率值
def save_model(model, save_path):
torch.save(model.state_dict(), save_path)
if __name__ == '__main__':
num_epochs = 10 # 设置训练相关的参数
learning_rate = 0.001 # 可调 0.0001 0.01
num_classes = 4
data_dir = "new_COVID_19_Radiography_Dataset"
save_path = r"model_pth\bets.pth"
model = SimpleCNN(num_classes).to(device) # 初始化模型,将模型移至GPU上
criterion = nn.CrossEntropyLoss() # 初始化损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 初始化优化器
train(model, train_loader, criterion, optimizer, num_epochs=num_epochs) # 使用训练数据集训练模型
evaluate(model, test_loader, criterion) # 使用测试数据集评估模型性能训练结果
Epoch 1/10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [05:17<00:00, 3.00batch/s, loss=0.421]
Epoch [1/10], Loss: 0.8031
Test Loss: 0.6113, Accuracy: 75.06%
Model saved with best accuracy: 75.05910165484633
Epoch 2/10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [10:17<00:00, 1.54batch/s, loss=0.304]
Epoch [2/10], Loss: 0.5623
Test Loss: 0.5412, Accuracy: 78.78%
Model saved with best accuracy: 78.78250591016548
Epoch 3/10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [18:32<00:00, 1.17s/batch, loss=0.219]
Epoch [3/10], Loss: 0.4304
Test Loss: 0.5308, Accuracy: 78.99%
Model saved with best accuracy: 78.98936170212765
Epoch 4/10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [15:27<00:00, 1.03batch/s, loss=0.617]
Epoch [4/10], Loss: 0.3056
Test Loss: 0.5977, Accuracy: 78.93%
Epoch 5/10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [09:00<00:00, 1.76batch/s, loss=0.105]
Epoch [5/10], Loss: 0.1932
Test Loss: 0.8195, Accuracy: 77.25%
Epoch 6/10: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [06:09<00:00, 2.58batch/s, loss=0.0199]
Epoch [6/10], Loss: 0.1089
Test Loss: 0.9855, Accuracy: 76.95%
Epoch 7/10: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [07:11<00:00, 2.21batch/s, loss=0.0105]
Epoch [7/10], Loss: 0.0581
Test Loss: 1.1585, Accuracy: 76.51%
Epoch 8/10: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [08:26<00:00, 1.88batch/s, loss=0.11]
Epoch [8/10], Loss: 0.0412
Test Loss: 1.3263, Accuracy: 76.86%
Epoch 9/10: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [14:16<00:00, 1.11batch/s, loss=0.00612]
Epoch [9/10], Loss: 0.0384
Test Loss: 1.5095, Accuracy: 76.86%
Epoch 10/10: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 953/953 [07:34<00:00, 2.10batch/s, loss=0.0751]
Epoch [10/10], Loss: 0.0294
Test Loss: 1.5819, Accuracy: 77.16%
Test Loss: 1.5819, Accuracy: 77.16%4.图像分类结果
代码
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
# 定义图像预处理操作
transform = transforms.Compose([
transforms.Resize([224, 224]), # 调整图像大小为 224x224
transforms.ToTensor(), # 将图像转换为 PyTorch 张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行标准化
])
# 加载模型
class SimpleCNN(nn.Module):
# 定义简单的模型,具体模型的含义可看训练部分
def __init__(self, num_classes=4):
super(SimpleCNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(32 * 56 * 56, 128),
nn.ReLU(inplace=True),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = SimpleCNN(num_classes=4) # 创建模型实例
model.load_state_dict(torch.load(r"model_pth\bets.pth")) # 加载模型权重
model.eval() # 设置模型为评估模式
# 定义类别标签
class_names = ["COVID", "Lung_Opacity", "Normal", "Viral Pneumonia"]
# 图像分类推理函数
def predict_image(image_path):
# 加载图像并进行预处理
image = Image.open(image_path)
image = image.convert("RGB") # 将图像转换为 RGB 彩色图
image = transform(image) # 转换图像为张量形状
image = image.unsqueeze(0) # 添加一个维度,变成形状为 [1, 3, 224, 224] 的张量
# 在推理过程中,使用 torch.no_grad() 上下文管理器,以停止梯度计算,因为在推理时不需要计算梯度。
# 将图像输入模型,获取模型的输出
with torch.no_grad():
outputs = model(image) # 将图像传递给模型进行推理,得到输出
_, predicted = torch.max(outputs, 1) # 从输出中获取预测类别
class_idx = predicted.item() # 获取预测类别的索引
class_label = class_names[class_idx] # 根据索引获取预测类别的标签
# 返回预测的类别标签
return class_label
# 加载并预测图像
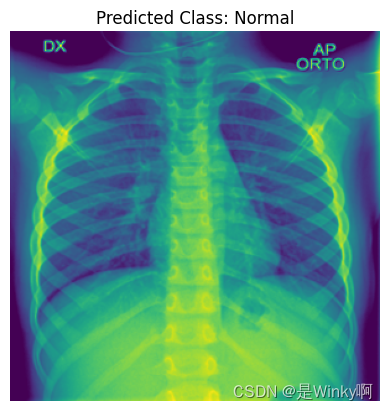
image_path = r"new_COVID_19_Radiography_Dataset\test\COVID\images\COVID-13.png" # 可以换其他类别的数据集
predicted_class = predict_image(image_path)
print("Predicted Class:", predicted_class)
# 可视化图像
image = Image.open(image_path)
plt.imshow(image)
plt.title("Predicted Class: " + predicted_class)
plt.axis("off")
plt.show()预测结果

















 2460
2460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









