







Recovery问题排查
Android Recovery问题排查
Android Recovery问题排查是一个关键的过程,它主要集中在找出触发Recovery模式的原因。Recovery模式是一个特殊的引导模式,通常是因为系统出现严重错误或者需要进行系统更新等操作时被触发。了解触发Recovery模式的原因有助于我们有效地进行问题排查和解决。
以下是一些可能触发Recovery模式的常见原因:
- 系统更新:当Android设备进行系统更新时,设备通常会自动进入Recovery模式。这是因为更新过程通常需要在系统级别进行,需要关闭用户界面。在Recovery模式下,系统能够在没有用户干预的情况下完成更新操作,完成更新后设备会自动重启。
- 系统恢复:如果系统出现严重错误,设备可能会自动进入Recovery模式进行系统恢复。这种情况下,Recovery模式允许系统在没有加载用户界面的情况下运行,这样就能够避免用户界面可能会引起的任何问题,从而更好地解决系统级别的错误。
- 手动操作:用户也可以手动触发Recovery模式,例如进行系统重置或者从USB或SD卡安装更新等。当用户需要对设备进行一些高级操作时(比如刷机,恢复出厂设置等),通常需要进入Recovery模式。在这种模式下,用户可以在不影响设备正常运行的情况下进行一些操作。
了解以上触发Recovery模式的原因,可以帮助我们更深入地理解Android系统的工作方式,从而更有效地进行问题的排查和解决。
问题背景:
部分S10设备会在运行一段时间后进入到Recovery状态,时间周期长,大概在25~30天中会复现,且无法明确复现场景,发生后通过日志大部分已经是系统异常前的日志,分析不到根因。
先抛出结论:
是由于内存不足导致关键service无法正常启动,导致在执行方法getService时抛出异常,zygote强制重新forkSystemServer进程后仍在短时间内重复触发导致设备进入Recovery。
结论依据和推断过程:
-
搞明白这50份tombstone日志
我们在设备异常进入到recovery后,通过pull获取tombstones文件夹(
/data/tombstones),可以看到进入Recovery模式的设备中会有且只有50份文件,why?这是因为墓碑文件数量有上限的,达到上限时会删除最旧的墓碑文件,可以通过配置属性tombstoned.max_tombstone_count来修改默认的墓碑文件数量,也可以通过adb查看。*rk3566_r:/ # getprop | grep max_tombstone_count [tombstoned.max_tombstone_count]: [50] rk3566_r:/ #*但之前了解的进入Recovery不是只需要达到
*LEVEL_FACTORY_RESET*(4)便会触发吗?为什么这里会多达50份文件?虽然文件有五十份,但分析后发现共性,通过filter,可以看到:
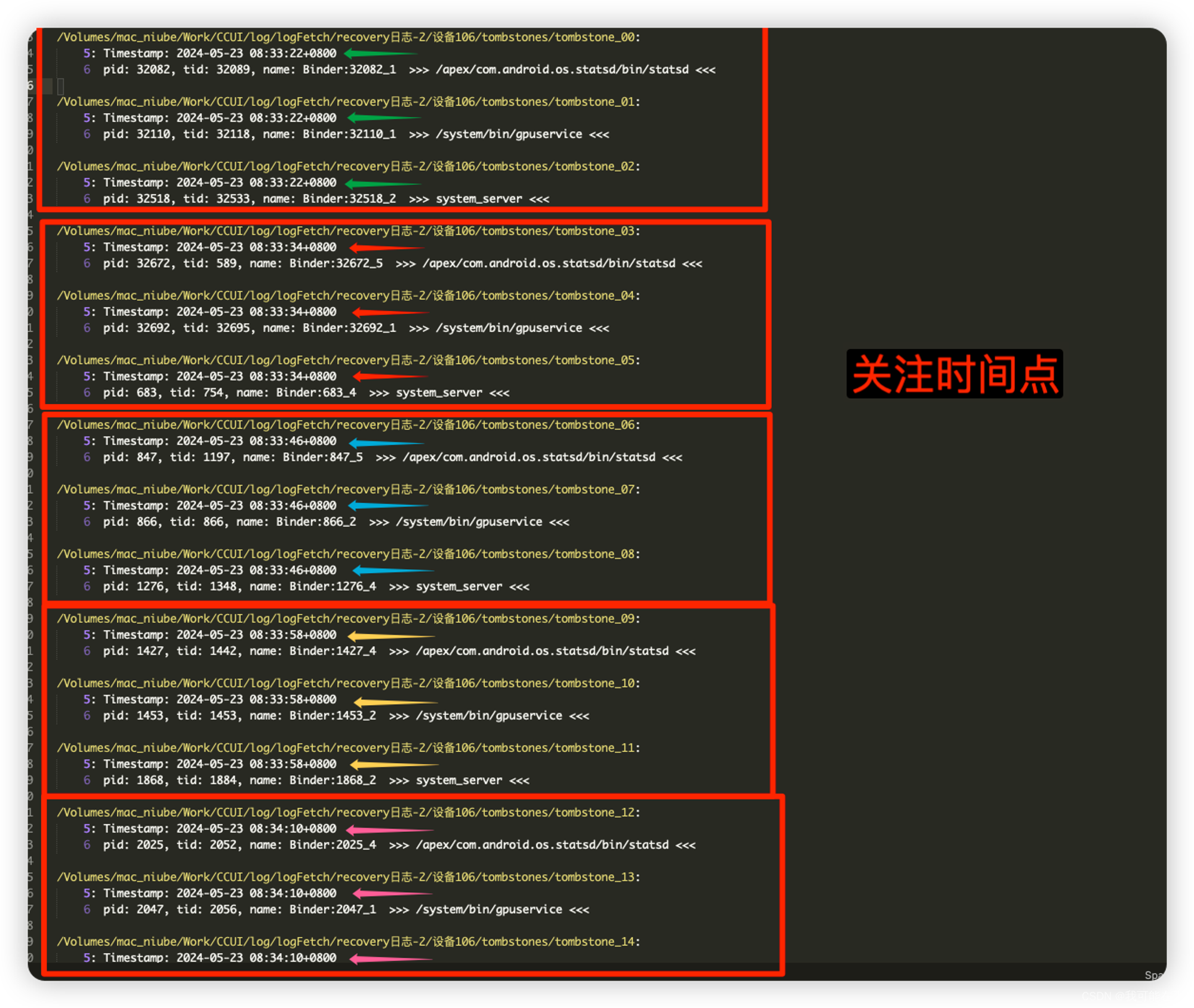
注意:并不一定是三个一组,可以看这个:
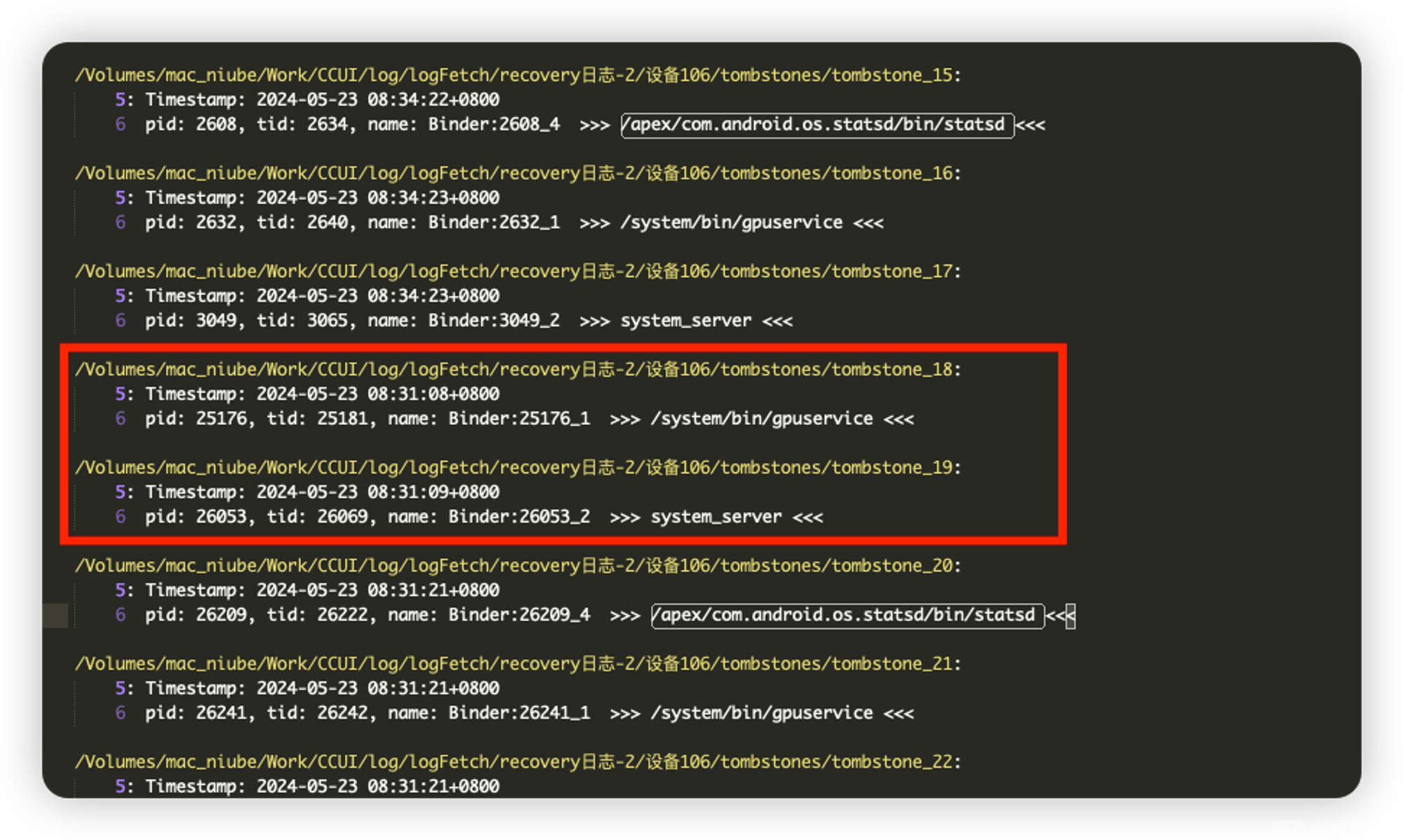
(Linux kernel会发送相应的
signal给异常进程,debuggerd捕获这些signal,做出相应处理的同时(一般来说是退出异常进程),在/data/tombstones目录下生成一个tombstone。)也就是说,虽然生成了
tombstone,但其实只有在system_server在挂了之后,才会通过RescueParty进行increaseLevelCount(这一点后面通过代码和日志结合看也可以证实),所以,我们重点关注计数连续阶段(非连续触发会重置level)的system_serve最后和首次发生异常的时间,但首次已经无法关注,因为被覆盖了,所以我们就关注最后一次即可。 -
锁定案发时间点和日志现场
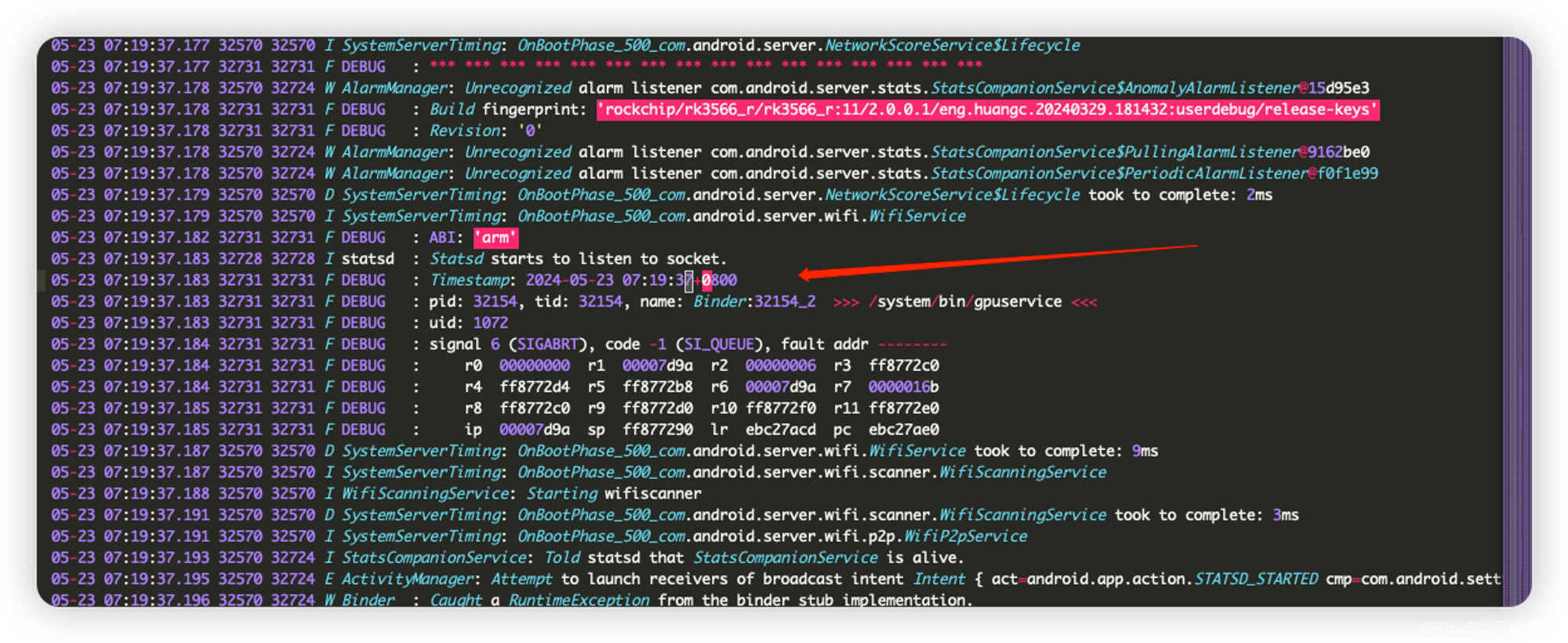
OK,接着我们可以通过排序的方法得到tombstone的最晚时间,再结合该时间点,通过日志查看对应的Rescue-Tag相关日志,相互验证是否为触发Recovery的原因。
# sort -t ' ' -k4,4: 使用空格作为分隔符(-t ' '),并按第四列(时间部分)排序。 ❯ cat all | grep '2024-05-23' | sort -t ' ' -k4,4 5: Timestamp: 2024-05-23 07:16:18+0800 5: Timestamp: 2024-05-23 07:16:18+0800 5: Timestamp: 2024-05-23 07:16:30+0800 5: Timestamp: 2024-05-23 07:16:30+0800 ... 5: Timestamp: 2024-05-23 07:19:37+0800 //↑这个就是最晚的时间点,基本锁定案发时间点,那么我们再通过android log去到日志现场在目录
/data/vendor/logs下可以看到捕获到的日志文件目录有如下这些bash-3.2$ tree -d . ├── logs ├── 17-08-04-17-00-10-0001 ├── 17-08-04-17-00-24-0002 ├── 24-04-01-12-04-14-0000 ├── 24-04-28-10-41-27-0003 ←←←这里 └── 24-05-23-10-09-19-0004这里的文件夹名称是文件创建时的时间,通过比对, 2024-05-23 07:19:37时间点就在文件夹**
24-04-28-10-41-27-0003** 中。查找到日志:
-
为什么我们在tombstone中看到的都是getService错误?
由于我们的tombstones目录下批量出现两个服务和system_serveer错误,那么我们再往前看看,是否有
/apex/com.android.os.statsd/bin/statsd的相关日志(不一定有,可以看看),我们可以看到确实在2024-05-23 07:19:36时,/apex/com.android.os.statsd/bin/statsd已经发生异常并且写入到tomestone目录下了,这里指向的是pid:32128,这个服务会在系统启动后被系统拉起,在frameworks/base/apex/statsd/statsd.rc下定义
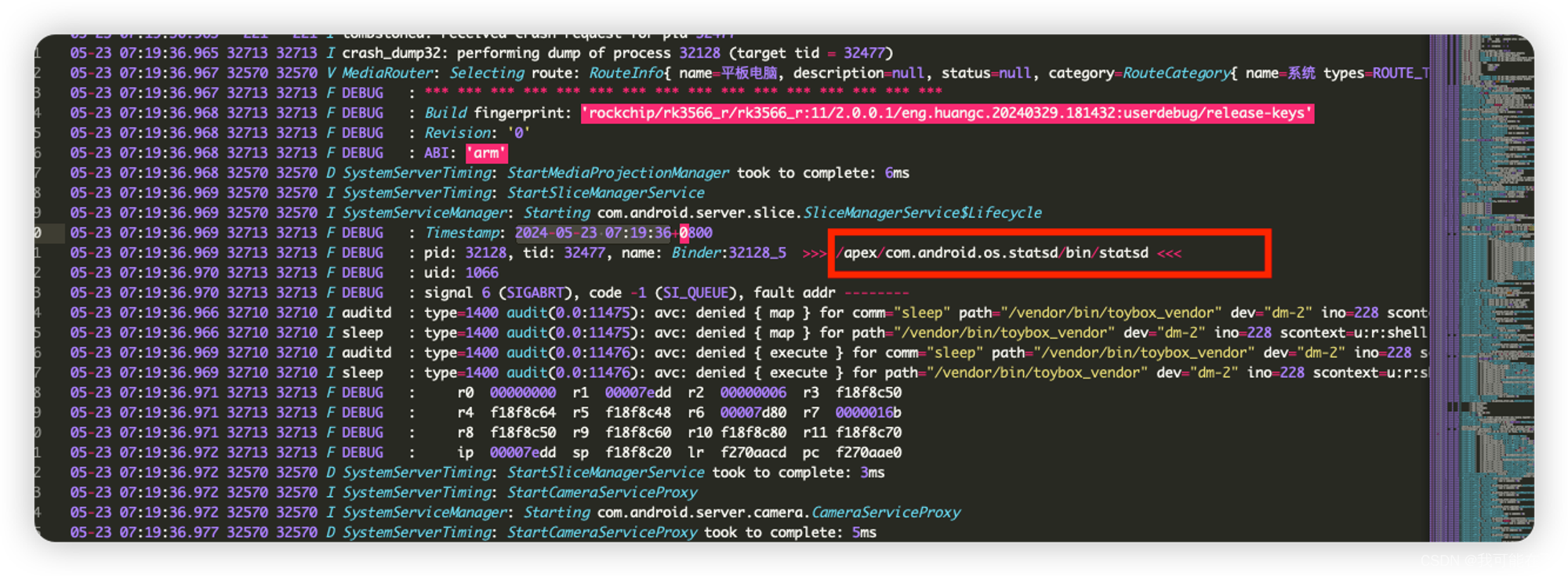
这里我们不去关注这个服务是干嘛的先,关注这个进程id和tid,
pid: 32128,tid: 32477,往上看。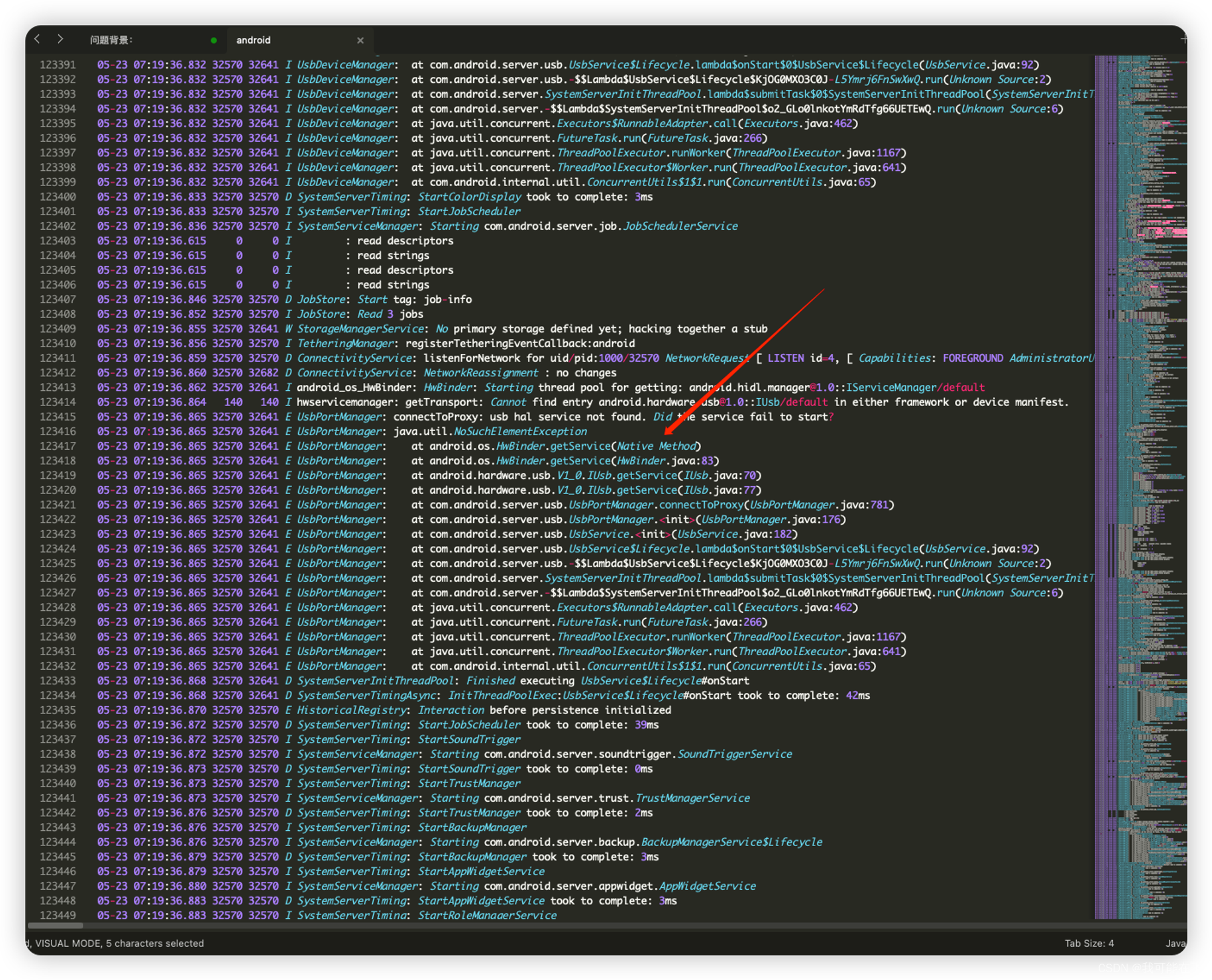
这里的
HwBinder.getService看着很眼熟,就是对应到我们的tombstone中的错误
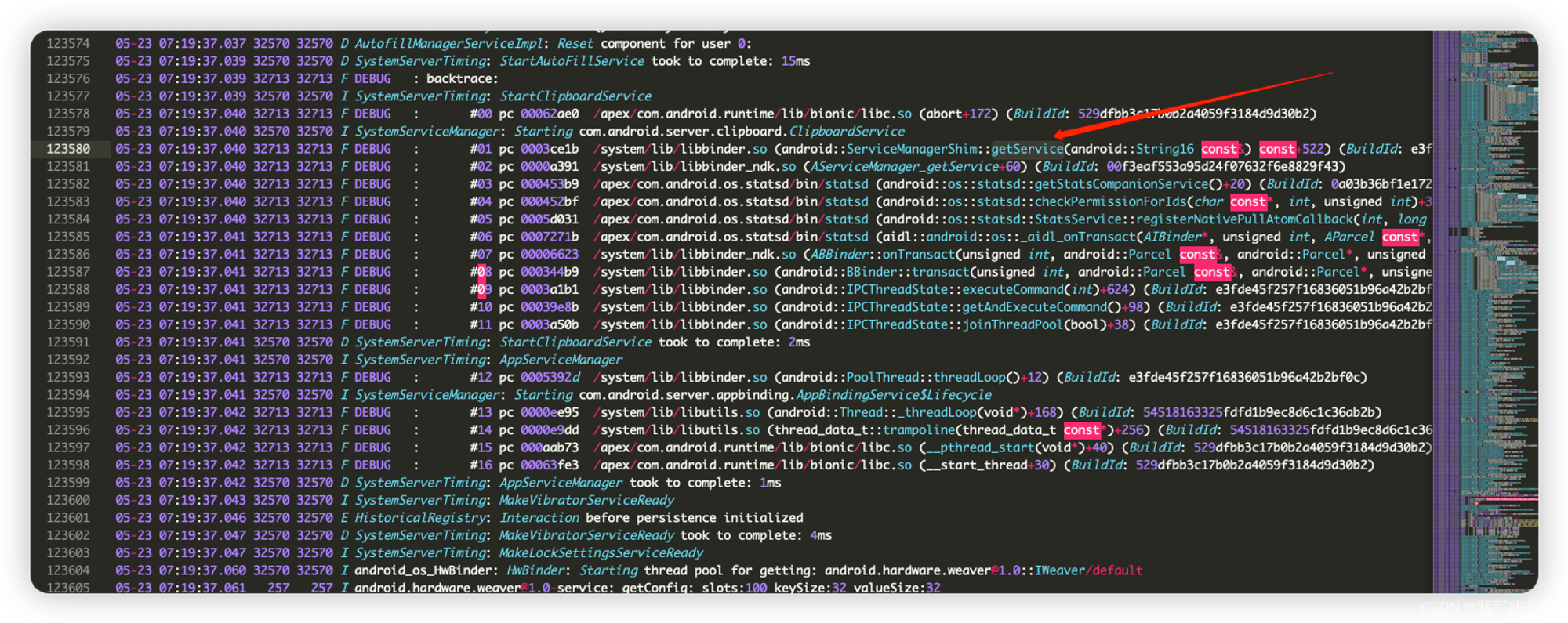
那这个为什么会getService报错呢,我们可以看到报错的错误类型是
NoSuchElementException,结合源码推测是不是服务获取失败导致的.
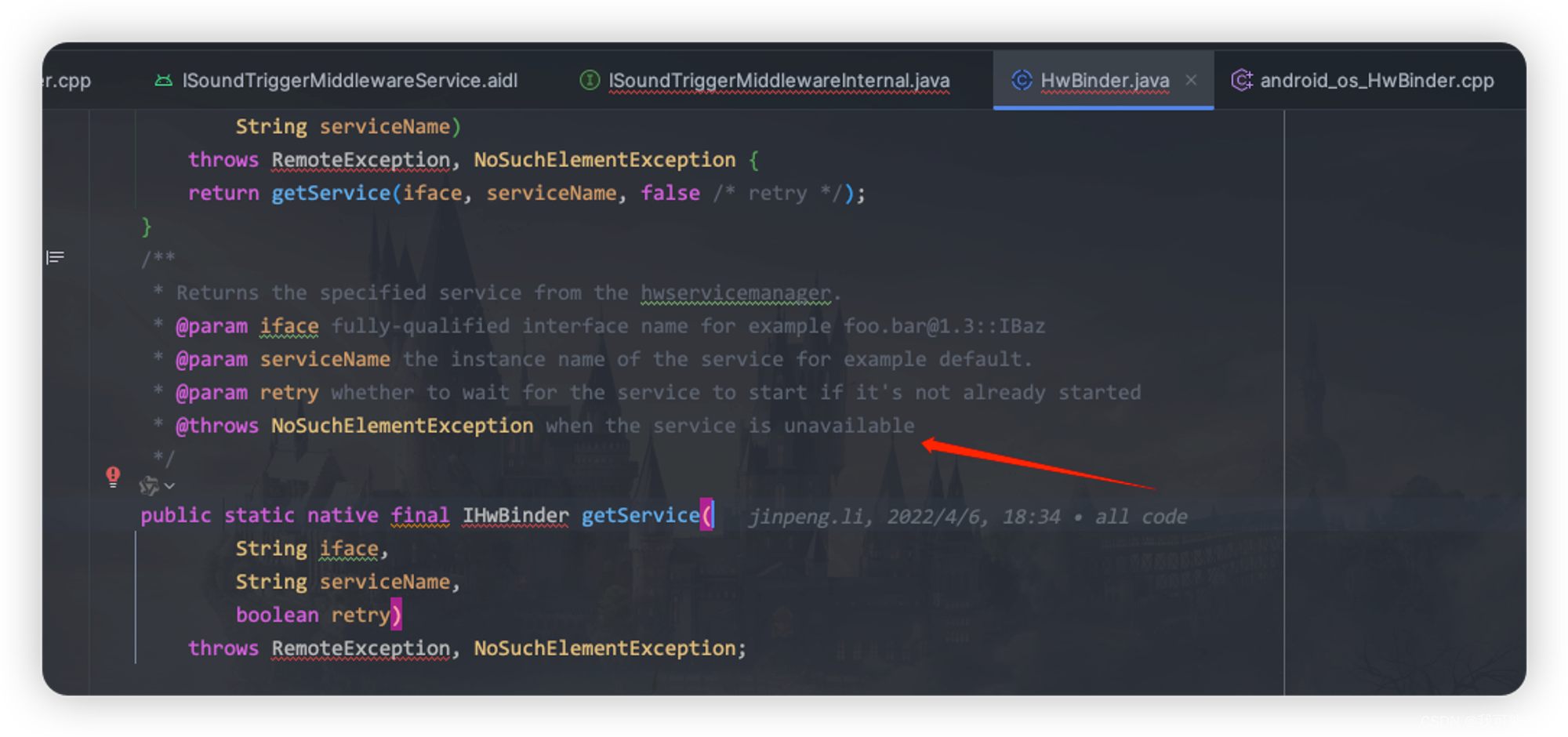
再继续跟踪源码,可以在文件
android_os_HwParcel.cpp的signalExceptionForError()中看到: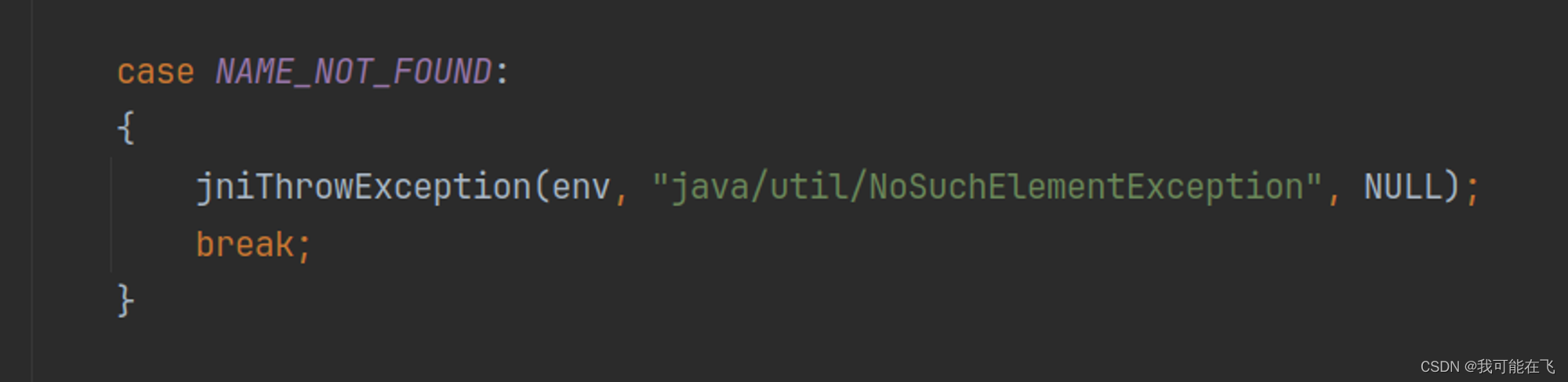
再结合
android_os_HwBinder.cpp的JHwBinder_native_getService方法中确实是由于service不存在发出signalNAME_NOT_FOUND抛出了NoSunchElementException错误
-
服务为何启动失败?
在
getService异常发生前,我们能够通过过滤正则条件low.*mem看到以下这些日志内容: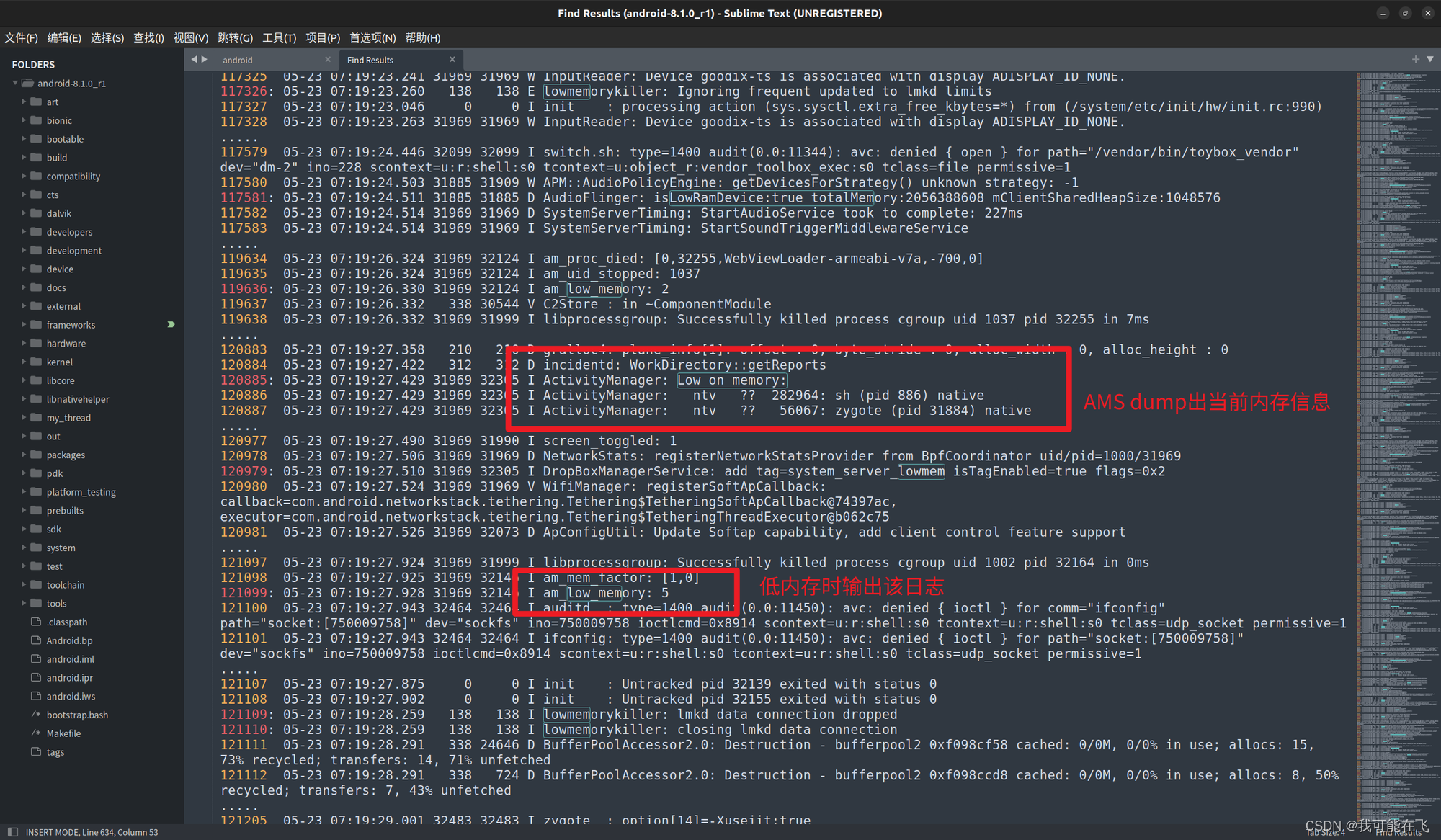
report的file是
system_server_lowmem@,我们可以取任意一个看下这些文件的内容(都类似):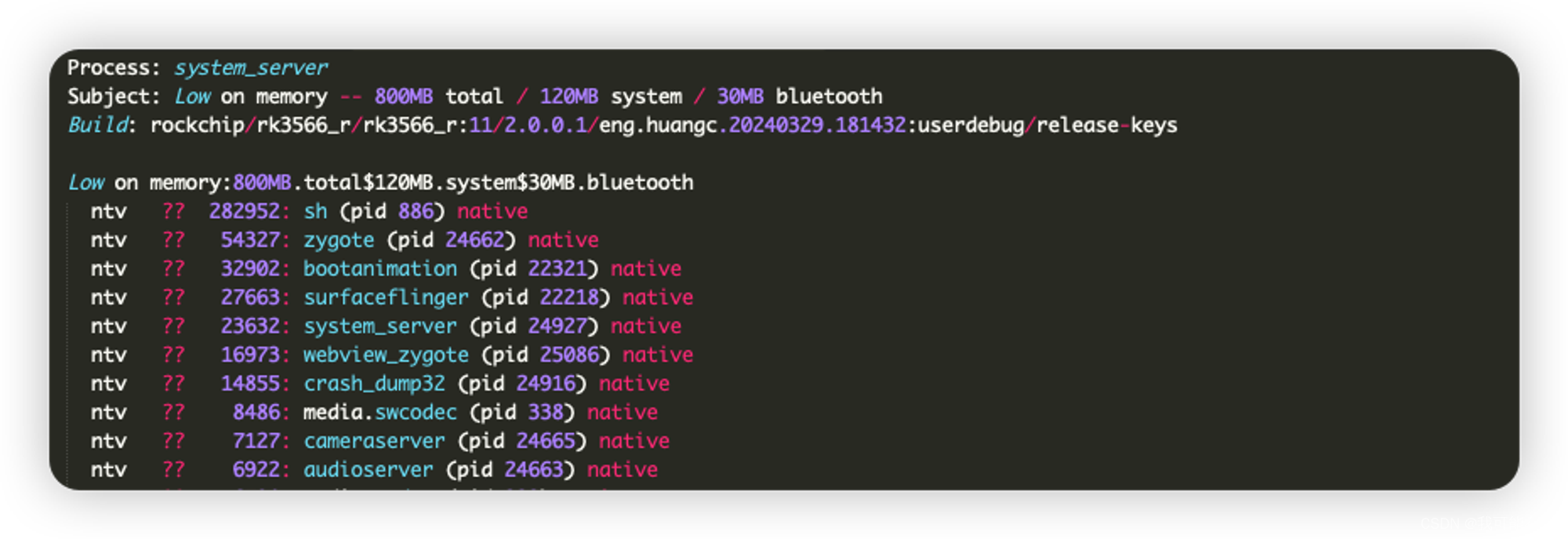
由于内容较多,我这边只截取了本次分析用到部分
上面的Low on memory — 800MB total中的
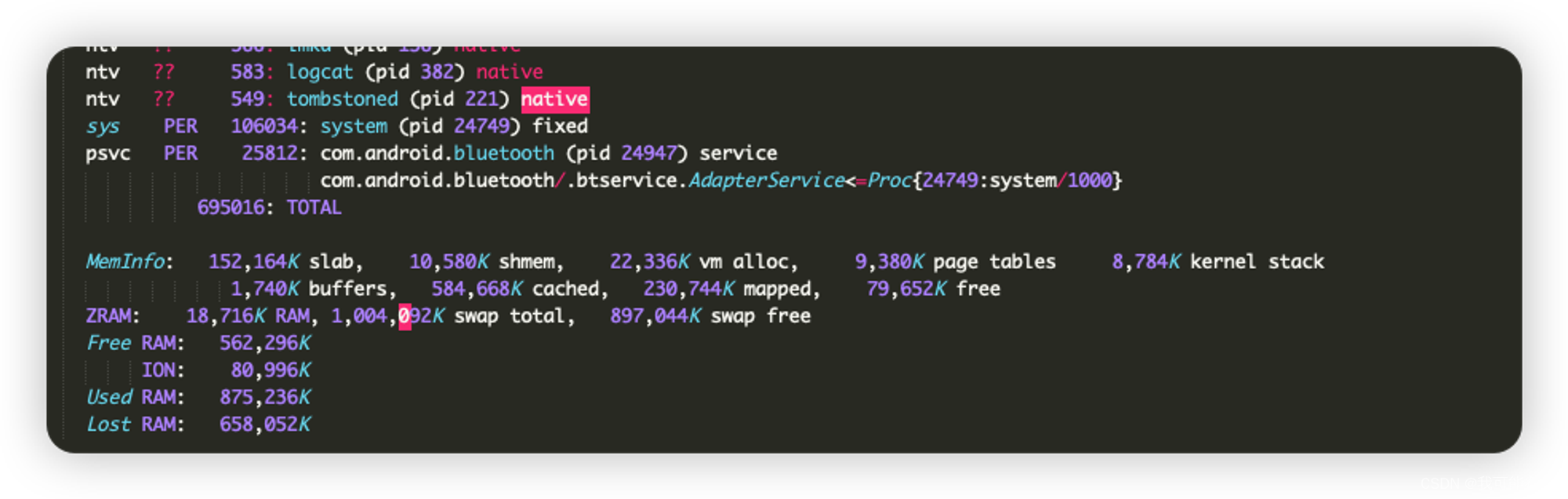
800MB,取决于当前系统中VSS>0的应用进程所占用的pss之和,是通过ProcessCpuTracker进行获取,通过读取/proc文件系统中的进程信息来更新现有进程的统计数据或添加新进程的数据和移除不存在的进程。补充知识:TOTAL 是695016 KB, 所以这里显示的是800MB….What?怎么算都不会是800MB啊,原因就是在AMS中的
reportMemUsage方法中,我们本次分析该文本也是通过该方法进行深度分析: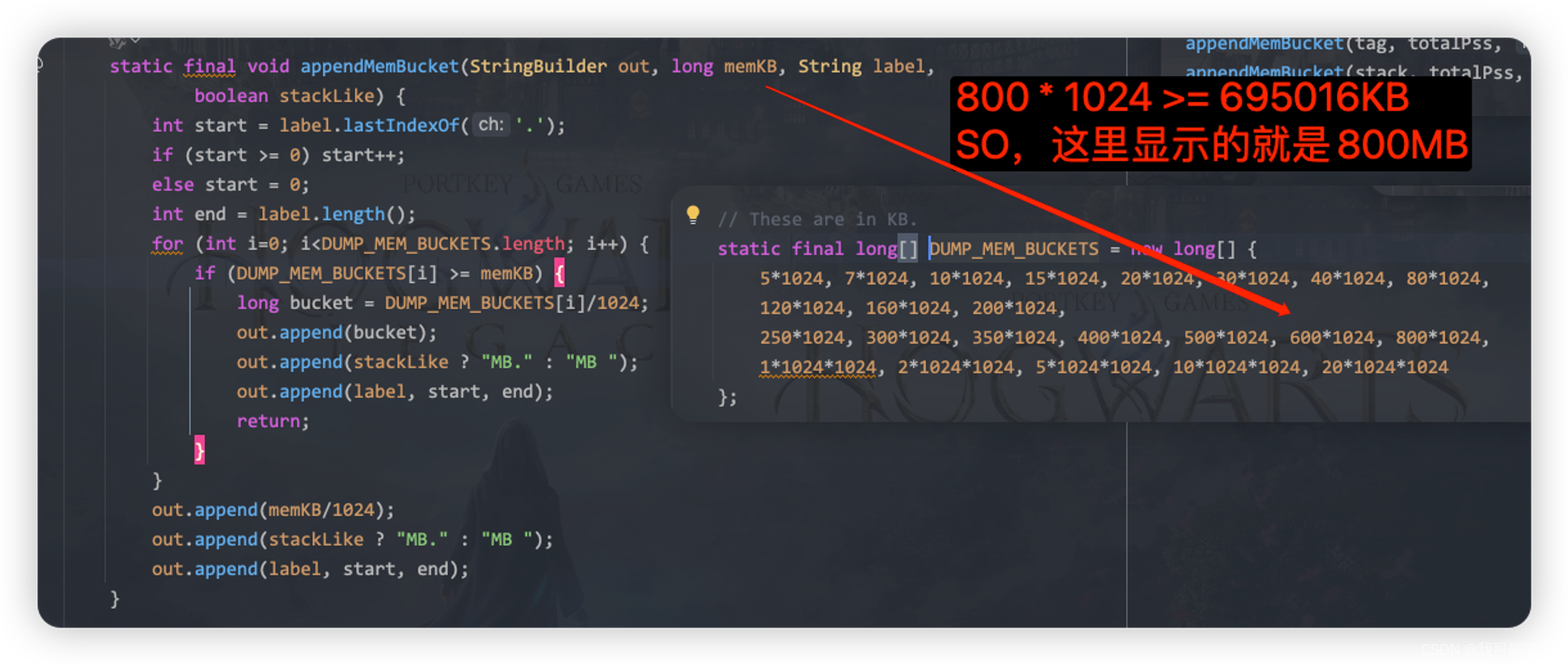
下面是我们重点关注的地方:
-
Lost Ram,定义如下:
memInfoBuilder.append(" Lost RAM: "); memInfoBuilder.append(stringifyKBSize(memInfo.getTotalSizeKb() - (totalPss - totalSwapPss) - memInfo.getFreeSizeKb() - memInfo.getCachedSizeKb() - kernelUsed - memInfo.getZramTotalSizeKb())); memInfoBuilder.append("\n"); -
Free RAM,定义如下:
memInfoBuilder.append(stringifyKBSize(cachedPss + memInfo.getCachedSizeKb() + memInfo.getFreeSizeKb()));
具体的内存获取,大家可以去看看
Debug.java#getMemInfo()方法。- am_low_memory:2后会报一次LowMemory,并且dump进程状态,此时后续继续打印多一次am_low_memory:5后就会看到打印日志:
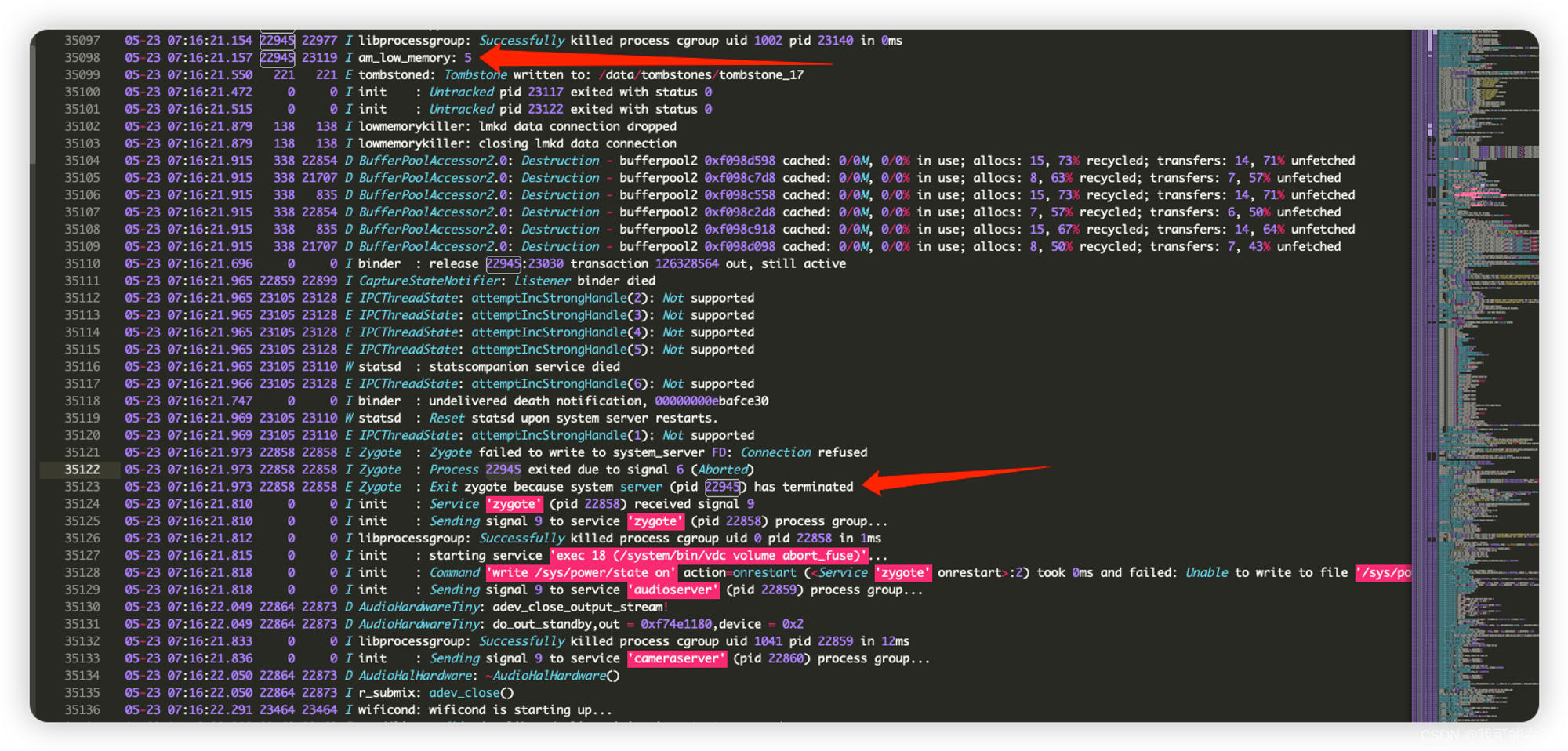
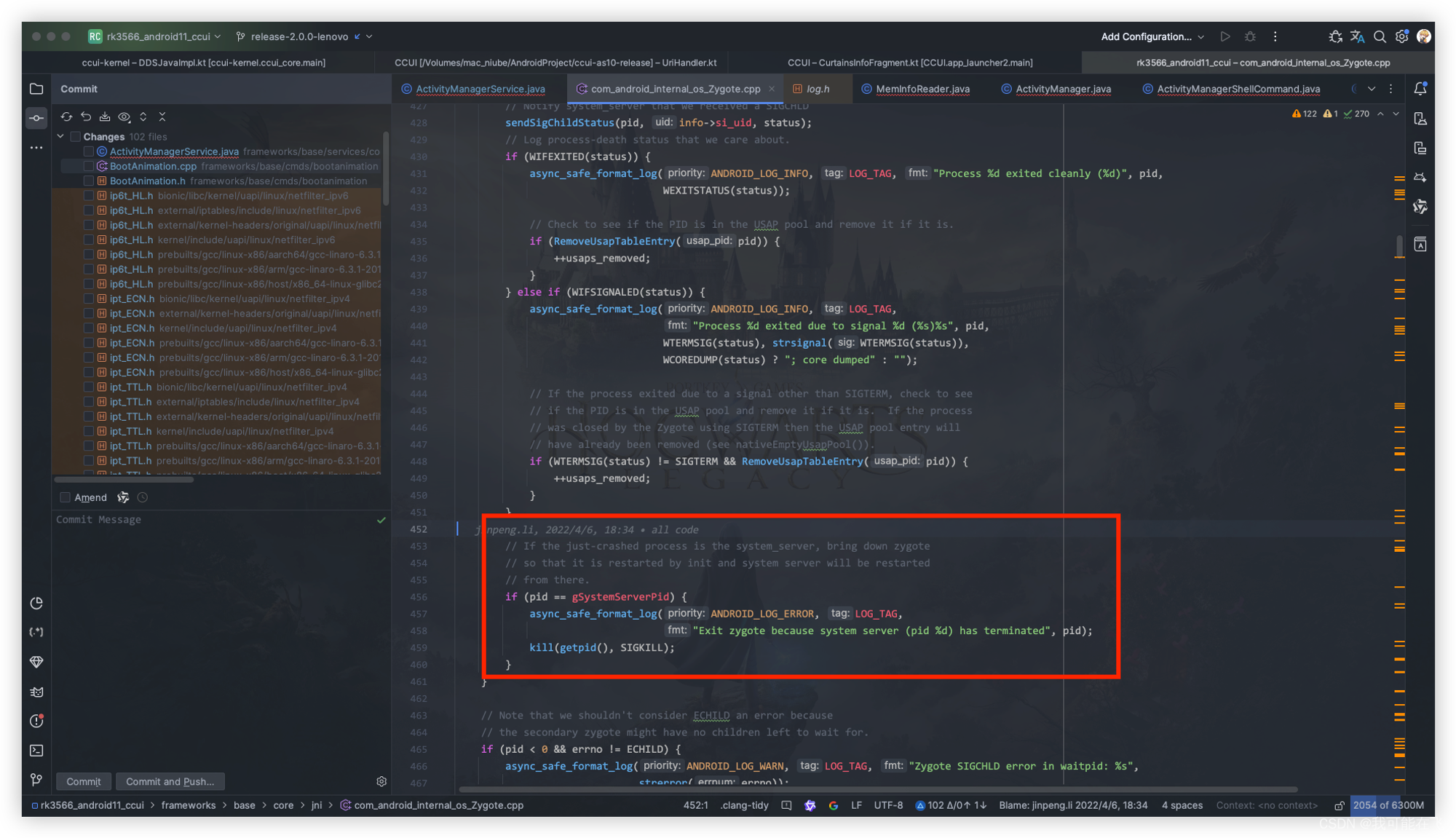
从源码也可以看出,当
system_servercrashed后,则关闭zygote,以便由init重新启动,系统服务器将从那里重新启动。那
system_server是什么时候crashed的呢?以pid为22945的system_servercrash来看,往上继续跟踪,可以看到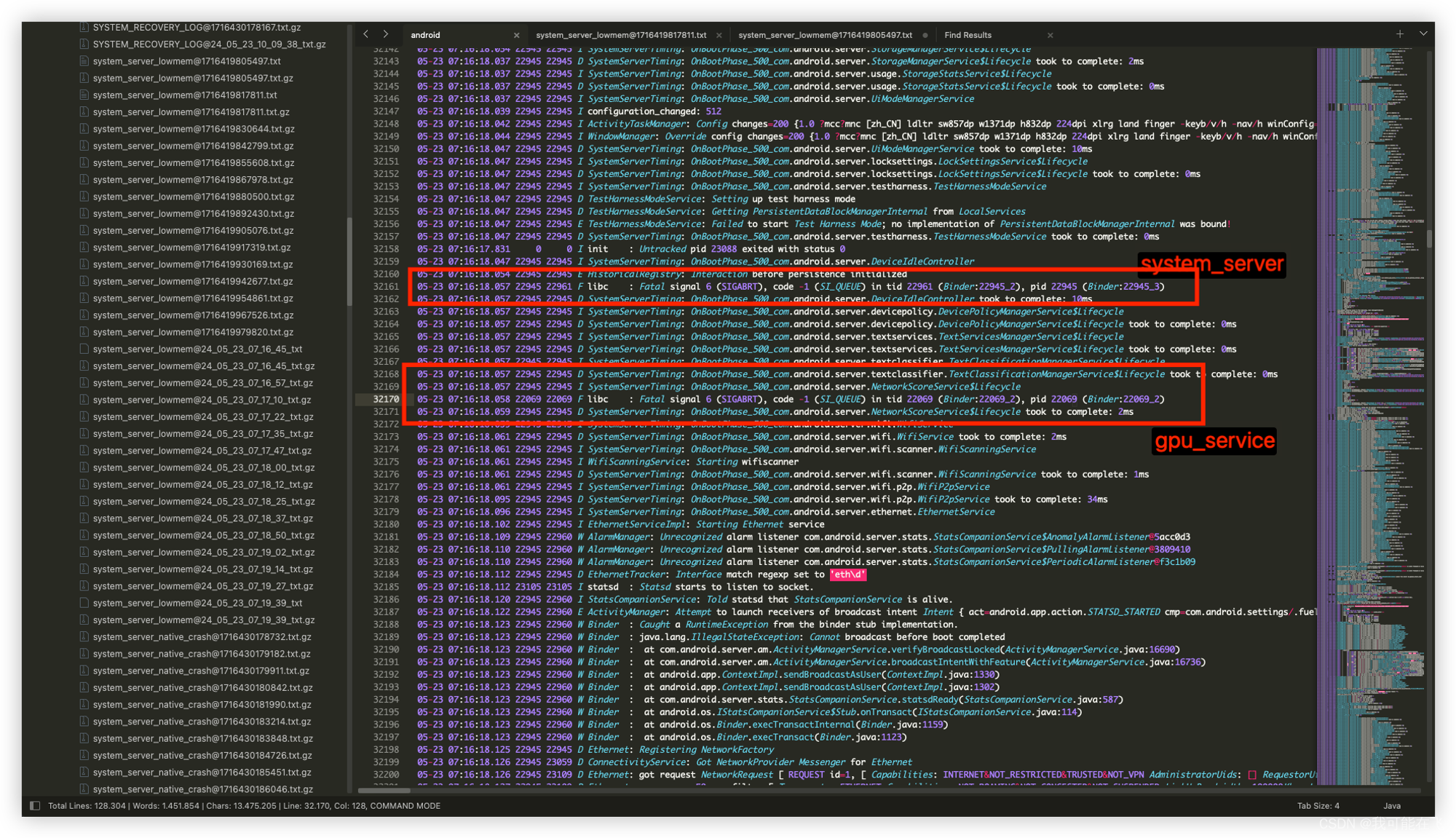
再继续往上看,我们来看看这个
statsd服务到底被拉起后发生了什么,再继续往上看可以看pid: 32128的存活日志,发现就只有几行了,除了main.cpp中打印的ALOGI("Statsd starts to listen to socket.");被打印外,在下面就是
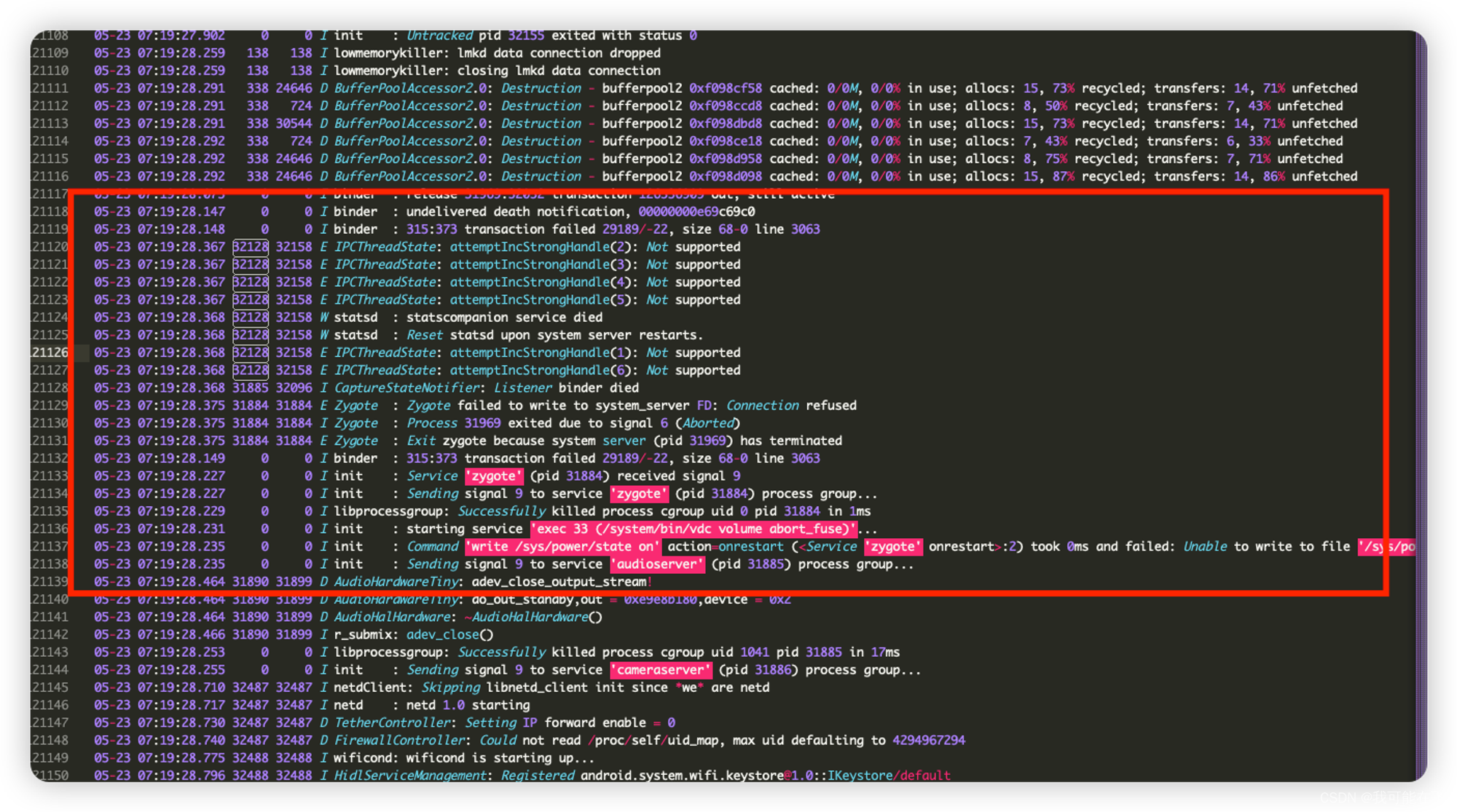
这些错误日志来自
IPCThreadState,表示在尝试增加某个句柄的强引用计数时遇到了问题。attemptIncStrongHandle(N): Not supported表示对于句柄N的操作不被支持。这通常与进程间通信(IPC)系统的内部问题有关,通常是由于资源不足导致无法分配或权限问题。statscompanion service died表示statscompanion服务已崩溃。崩溃链路通过日志可以看到:statds获取失败→system_server getSignal → gpu_service getSignal → Zygote Exit and restart.
到这我们
getService异常的原因就找到了。 -
-
重启进入Recovery的证据
先抛结论:system_server在{
triggerWindow}内异常退出20次,导致sys.rescue_level达到等级*LEVEL_FACTORY_RESET*从而进入Recovery。接下来,我们会从源码的角度再结合日志来验证我们的推断。

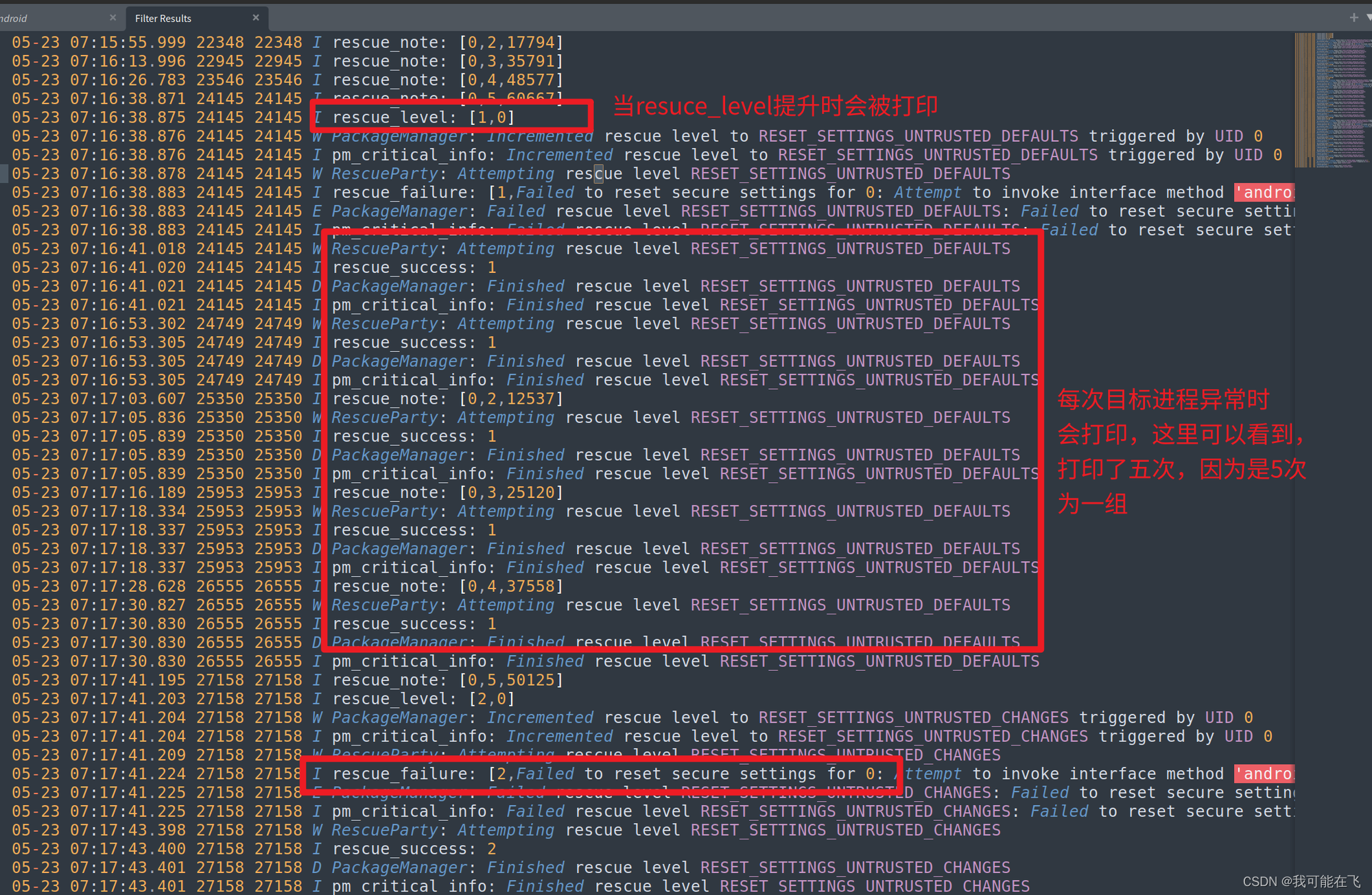
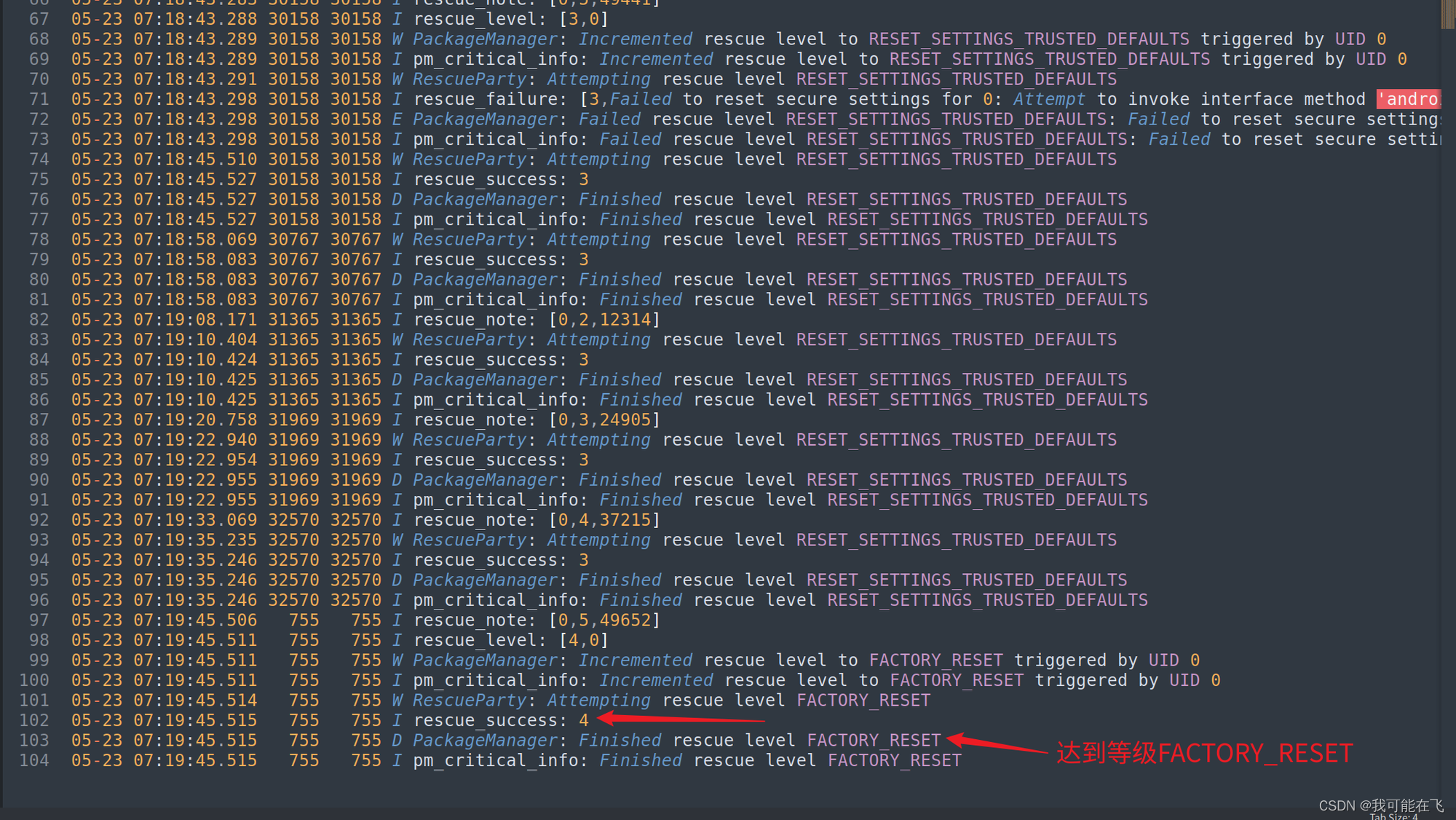
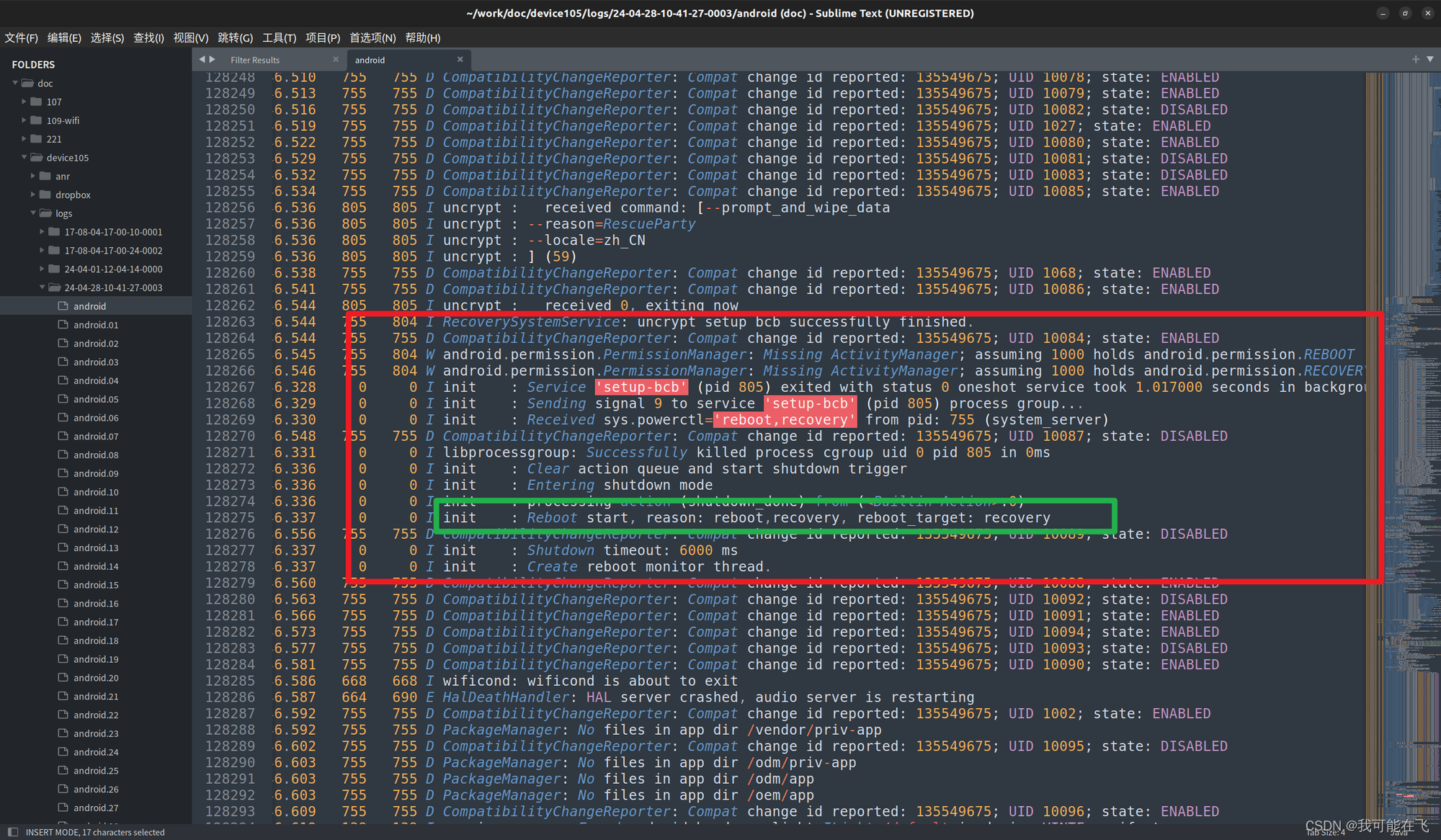
我们可以通过上方的日志可以看出等级是如何一步一步到达等级FACTORY_RESET的.并且也可以确认在触发后便执行了reboot,且显示出reason为recovery! -
Recovery的真相
由于涉及的流程较多,我会list出涉及到的角色,并且介绍其作用(注意,这里的作用重点介绍其在流程中的,不发散),通过画图的方式方便大家理解。
-
RescueParty:此类将通过几次救援操作缓慢升级,然后最终重新启动并提示用户是否要擦除数据作为最后的手段。 -
RescueParty#Threshold(android11后,这个逻辑也移到了
PackageWatchdog):
记录触发次数,设定触发窗口时间,设定触发阈值(这里需要注意,是升级的触发阈值,不是进入Recovery的阈值,目前android11系统下,rescue_level是固定的,分为5个级别,如下):
BootThreshold:触发于SystemServer#startBootstrapServices,关注system_server的异常,triggerCount为5,triggerWindow为300s。AppThreshold:触发于AppErrors对象中,关注persistent 级别的应用异常,triggerCount为5,triggerWindow为30s。
-
ActivityManagerService:持有AppErrors,在异常时除了通知AppErrors之外,还会通过方法addErrorToDropBox()将异常信息输出到/data/system/dropbox文件夹中 -
AppErrors:对application异常时进行处理,包括dump消息(我们看到的/data/anr/trace.txt文件就是它给输出的),anr弹窗拉起,调度RescueParty等工作。在该流程中,起到了判断是否为persistent应用,直接调用或通过PackageWatchdog调用RescueParty进行记录。 -
PackageWatchdog:在android11版本后出现,顾名思义,就是对Package进行观测,可以在/data/system/pacakge-watchdog.xml中找到对应的观测者.rk3566_r:/data/system # cat package-watchdog.xml <?xml version='1.0' encoding='utf-8' standalone='yes' ?> <package-watchdog version="1"> <observer name="rescue-party-observer" /> <observer name="rollback-observer" /> </package-watchdog> -
RecoverySystem:可通过Context.*RECOVERY_SERVICE获取,调用PMS执行重启*
这里我们只需要知道程序异常时,AMS会调用
handleApplicationCrash,之前的链路暂不追溯(停不下来,就不在本次分析中继续深耕)。RescueParty工作流程图如下:
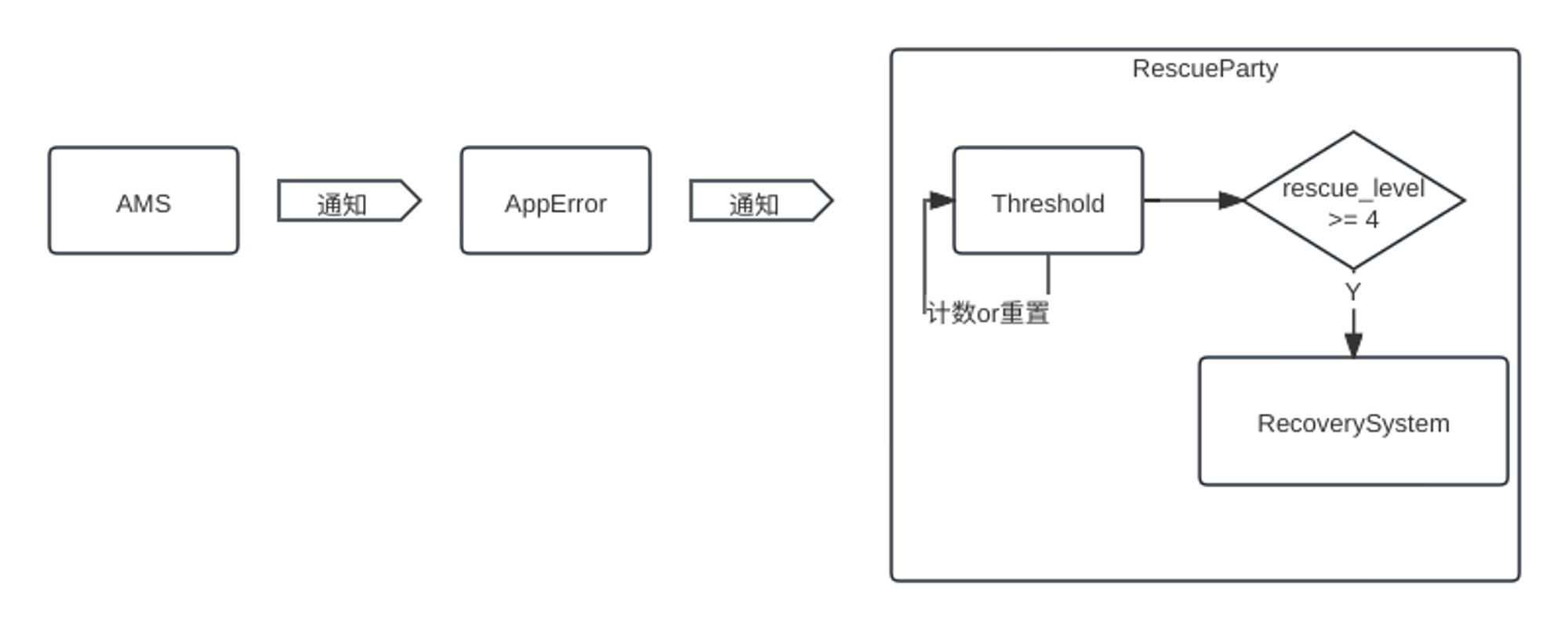
-
尝试复现:
- 设备105:
- 设备119:
下一步和反思?
在分析过程中发现了LostRam的增长,目前并无法掌握该值的释放和增长规律,如何排查
- 为什么问题会分析那么久?
- 有没有什么措施可以避免以后这种情况的出现?

















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









