






-
使用IPEX-LLM开发本项目的技术总结或心得
硬件与环境适配
-
硬件选择:IPEX-LLM针对Intel的CPU和GPU进行了深度优化,能够充分发挥Intel硬件的性能优势。在项目开发过程中,我们选择了搭载Intel酷睿处理器的机器,该处理器具备强大的多核并行计算能力,能够高效处理复杂的计算任务。同时,我们也利用了Intel的集成显卡,如Xe架构及以上的集成显卡和Arc A系列独立显卡,它们在图形计算和深度学习推理方面表现出色,为模型的高效运行提供了有力支持。
-
环境配置:项目开发环境主要在Windows系统上进行,对于Windows用户,在软件环境方面,我们使用了Python 3.11.9,并安装了必要的依赖库,如PyTorch、LangChain等,确保了开发环境的一致性和兼容性。
模型部署与优化
-
模型加载与转换:IPEX-LLM支持直接加载HuggingFace格式的模型,并自动将其转换为低位格式以进行推理。在项目中,我们使用了
IpexLLM.from_model_id方法加载预训练模型,该方法能够简化模型加载的过程,提高加载效率。通过模型的save_low_bit方法将模型保存为低位格式,可以有效减少模型文件的大小,提高后续加载速度和推理效率。 -
我们使用的是Qwen2-7B-Instructhttps://huggingface.co/Qwen/Qwen2-7B-Instruct
-
-
推理性能优化:为了提升模型的推理性能,我们采取了多种优化措施:
-
模型预热:在部署前对模型进行充分预热,以减少首次推理时的延迟。预热过程能够使模型的参数和计算图缓存到内存中,从而在后续的推理过程中能够快速响应。
-
批处理优化:合理设置批量大小,以提升模型的吞吐量。我们根据实际的硬件资源和模型特性,经过多次实验,找到了合适的批量大小。较大的批量大小可以提高GPU的利用率,但过大的批量大小可能会导致显存不足,因此需要在二者之间找到平衡。
-
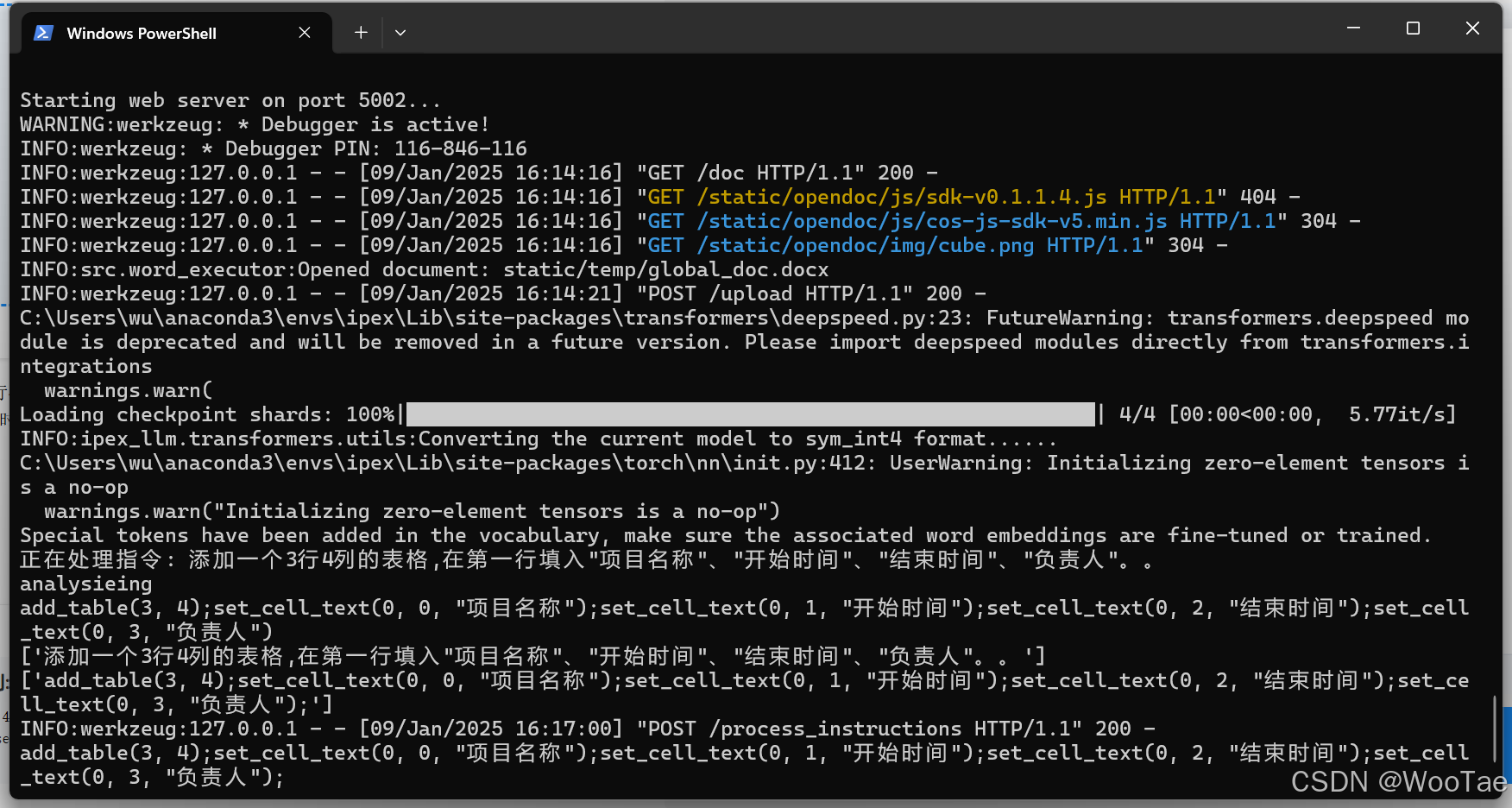
内存管理:适当使用量化技术降低模型的内存占用,缓解显存压力。IPEX-LLM支持多种量化方案,如INT4量化等,我们在项目中尝试了不同的量化策略,最终选择了适合我们模型和数据的量化方法,有效减少了模型的内存占用。
-
缓存优化:定期清理显存缓存,避免不必要的内存占用。在推理过程中,显存缓存可能会逐渐积累,导致显存不足。我们编写了脚本来监控显存使用情况,并在适当的时候清理缓存,确保模型在推理过程中能够稳定运行。
-
-
资源监控与调整:持续监控系统资源的使用情况,如CPU、GPU的利用率、内存占用等。当发现GPU利用率较低时,我们会适当增加批量大小或优化模型的计算图;当内存占用过高时,我们会检查内存泄漏问题并进行修复。
-
故障排查与解决
-
比如显存不足问题:在模型推理过程中,我们遇到了显存不足的问题。为了解决这个问题,我们尝试了多种方法:
-
减小批处理大小,以减少每次推理所需的显存。虽然这会降低吞吐量,但可以有效缓解显存不足的问题。
-
启用模型量化,降低模型的内存占用。通过量化技术,可以将模型的权重和激活值从浮点数转换为整数,从而减少内存占用。
-
使用CPU处理部分计算密集的嵌入层,减轻GPU的负担。对于一些计算量较大但对实时性要求不高的任务,可以将其转移到CPU上执行。
-
-
性能表现不佳:当模型的推理性能不理想时,我们首先检查了硬件驱动程序是否为最新版本,并更新了驱动程序,以确保硬件能够正常工作。然后,我们检查了环境变量的配置是否正确,如CUDA_VISIBLE_DEVICES等,并根据需要进行了调整。此外,我们还监控了设备的温度,确保其在合理的范围内,以避免因温度过高导致的性能下降。
-
模型加载失败:在加载模型时,我们遇到了模型文件不完整或损坏的问题。为了解决这个问题,我们重新下载了模型文件,并验证了文件的完整性。同时,我们也检查了IPEX-LLM的版本是否与模型兼容,并在必要时升级了IPEX-LLM,以确保模型能够顺利加载和运行。
-
-
-
项目经验与反思
-
持续优化的重要性:在项目开发过程中,我们深刻体会到了持续优化的重要性。随着项目需求的变化和技术的发展,我们需要不断地对模型和系统进行优化,以满足更高的性能要求和更复杂的应用场景。优化是一个持续的过程,需要不断地学习和尝试新的技术和方法,如新的量化策略、模型压缩技术等,以保持项目的竞争力。
-
团队协作与沟通:项目的成功离不开团队成员之间的紧密协作和有效沟通。在项目开发过程中,我们定期召开会议,讨论项目进展、技术难题和优化方案。通过良好的团队协作,我们能够及时解决问题,提高项目的开发效率。同时,我们也注重团队成员之间的知识分享和技术交流,以提升整个团队的技术水平。
-
关注硬件与软件的协同:IPEX-LLM作为一个专门为Intel硬件优化的库,其性能在很大程度上依赖于硬件与软件的协同工作。在项目中,我们不仅要关注软件层面的优化,还要充分了解硬件的特性,合理地利用硬件资源,以实现最佳的性能表现。例如,我们需要根据CPU和GPU的架构特点,优化模型的计算图和内存访问模式,以充分发挥硬件的并行计算能力和带宽优势。
-
对IPEX-LLM的使用理解和部署心得
使用理解
-
硬件加速优势:IPEX-LLM充分利用了Intel硬件的特性,如CPU的多核并行计算能力和GPU的向量计算能力,为大语言模型的推理提供了强大的硬件加速支持。这使得在Intel硬件上运行大型语言模型时,能够显著降低延迟,提高推理速度,满足实时推理的需求。例如,在处理自然语言处理任务时,IPEX-LLM能够快速地进行文本生成、文本分类等操作,为用户提供流畅的交互体验。
-
易用性与兼容性:IPEX-LLM提供了丰富的API和工具,使得在Intel硬件上部署和使用大语言模型变得简单易行。它支持多种模型格式,如HuggingFace格式的模型,并能够自动进行模型转换和优化。此外,IPEX-LLM还与PyTorch、LangChain等主流的深度学习框架和自然语言处理库兼容,方便开发者快速集成和使用。这意味着开发者可以利用现有的模型和工具,轻松地在Intel硬件上实现大语言模型的应用。
-
灵活性与扩展性:IPEX-LLM不仅支持模型的推理,还支持模型的微调和训练。它提供了多种优化策略和量化方案,开发者可以根据实际需求灵活地选择和调整。例如,可以根据模型的精度要求和硬件资源情况,选择不同的量化策略,以在性能和精度之间取得平衡。此外,IPEX-LLM还支持在多个Intel GPU上运行推理服务,具有很好的扩展性,能够满足大规模部署和应用的需求,适用于不同的业务场景和用户需求。
部署心得
-
环境准备的重要性:在部署IPEX-LLM之前,充分的环境准备工作至关重要。需要确保硬件配置满足要求,操作系统和GPU驱动程序为最新版本,并安装好所有必要的依赖库。良好的环境基础能够为后续的部署和运行提供有力的保障。例如,确保操作系统稳定且兼容,可以避免因系统问题导致的部署失败或运行异常;安装好依赖库,如PyTorch等,可以确保IPEX-LLM能够正常运行和调用相关功能。
-
安装过程中的注意事项:在安装IPEX-LLM时,要根据具体的处理器型号和操作系统选择合适的安装命令。对于不同地区的用户,还需要注意使用正确的镜像源,以加快下载速度和提高安装成功率。在安装过程中,要仔细阅读安装指南,按照步骤进行操作,避免因安装错误导致的问题。例如,注意检查安装命令中的参数是否正确,如版本号、路径等,确保安装过程顺利进行。

















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









