






LangChain提供了一套强大的文档加载器,简化了从PDF、网站、YouTube视频和专有数据库(如Notion)等不同来源加载和标准化数据的过程。这篇博文我们将学习LangChain的文档加载功能,涵盖了各种加载器类型、实际应用和代码示例,使你能够轻松地将数据集成到你的机器学习工作流程中。
一、什么是文档加载器
文档加载器是LangChain生态系统提供的基本构建块,负责访问来自各种格式和来源的数据并将其转换为标准化格式,无论您的数据是 PDF、网站还是专有数据库,文档加载器都可以非常轻松地加载和处理数据。

文档加载器的主要用途是获取这些不同的数据源数据,并将它们加载到一个标准文档对象中,该对象由内容本身和关联的元数据组成。通过这样做,它们为处理数据提供了一致的接口,使您能够专注于构建智能应用程序的其他方面。
二、文档加载类型
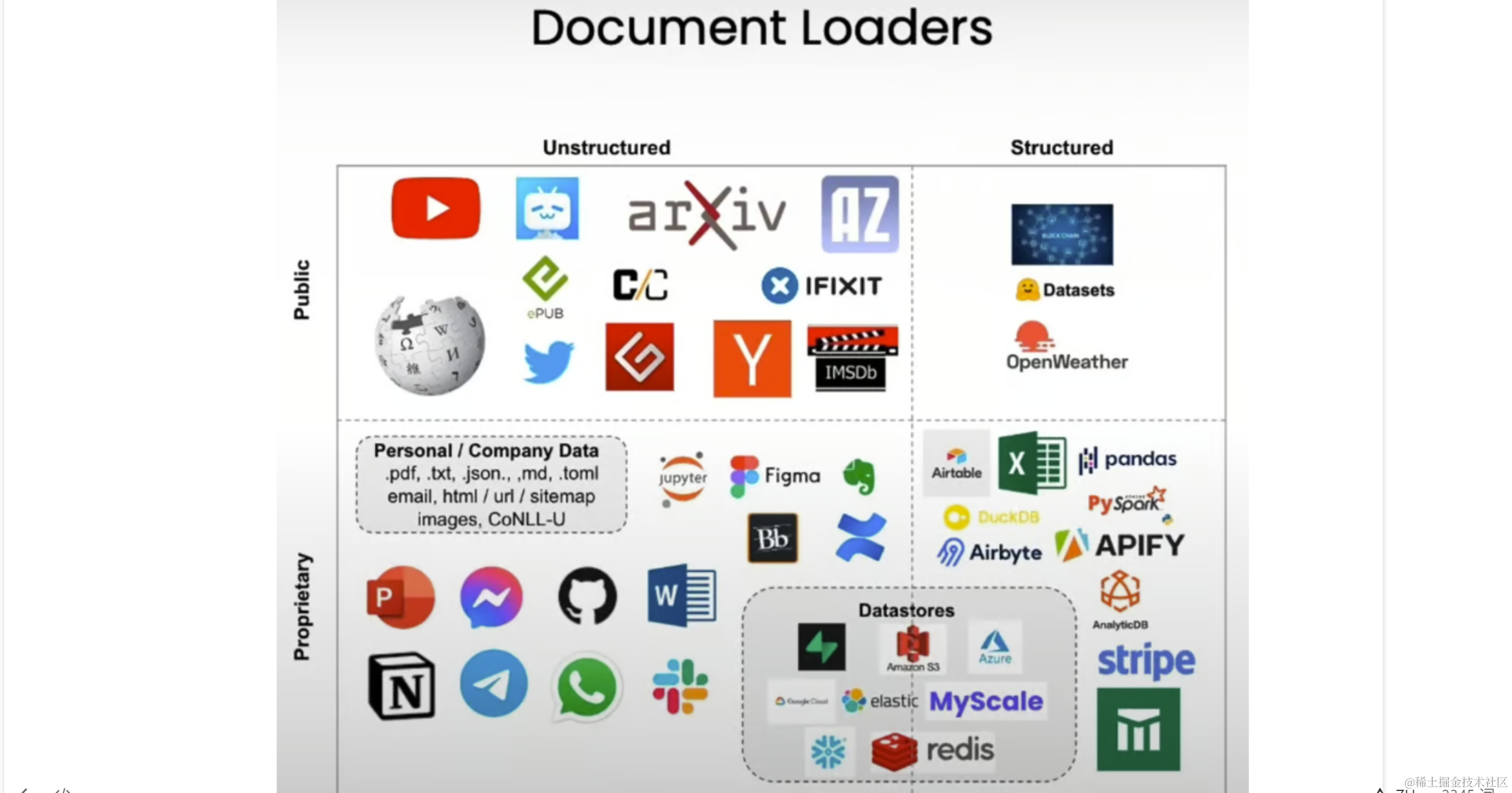
LangChain拥有80多种不同类型的文档加载器,可满足各种数据源和格式的需求。简单分类如下:
- 非结构化数据加载器:这些加载器旨在处理原始非结构化形式的数据,例如文本文件、YouTube、Twitter 和 Hacker News 等公共数据源。
#! pip install langchain
# Loading data from a PDF
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("path/to/your/pdf_file.pdf")
docs = loader.load()
- 专有数据源的加载器:如果您依赖于 Figma 或 Notion 等专有数据源,LangChain 为您提供了专门设计用于处理这些格式的加载器。
# Loading data from Notion
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("path/to/notion/export")
docs = loader.load()
- 结构化数据加载器:虽然 LangChain 通常与非结构化数据相关联,但它也为 Airbyte、Stripe 和 Airtable 等结构化数据源提供加载器,允许您对这些结构化格式中包含的文本数据执行问答和语义搜索。
# Loading data from Airtable
from langchain_community.document_loaders import AirtableLoader
# Your airtable variables
api_key = "xxx"
base_id = "xxx"
table_id = "xxx"
loader = AirtableLoader(api_key, table_id, base_id)
docs = loader.load()
三、使用文档加载器
现在我们已经介绍了文档加载器的基础知识及其类型,让我们深入了解一些如何使用它们从各种来源加载数据的实际示例。
1.加载PDFs
让我们从一个常见场景开始:从 PDF 文件加载数据,以下是使用 LangChain 的 PyPDF 加载器实现此目的的方法:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
# Access the content of the first page
page = pages[0]
print(page.metadata)
# Output
# {'page': 0, 'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf'}
print(page.page_content[:500])
>>>
MachineLearning-Lecture01
Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine
learning class. So what I wanna do today is ju st spend a little time going over the logistics
of the class, and then we'll start to talk a bit about machine learning.
By way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so
I personally work in machine learning, and I' ve worked on it for about 15 years now, and
I actually think that machine learning is th e most exciting field of all the computer
sciences. So I'm actually always excited about teaching this class. Sometimes I actually
think that machine learning is not only the most exciting thin g in computer science, but
the most exciting thing in all of human e ndeavor, so maybe a little bias there.
在此示例中,我们将 PDF 脚本加载到 LangChain 中,这会产生一个对象列表,每个对象代表 PDF 的一个页面。然后,我们可以访问每个页面的内容和元数据。
2.加载视频
想象一下,你是一个喜欢参加在线讲座和会议的人,如果您可以与这些 YouTube 视频的内容聊天,那不是很神奇吗?LangChain通过组合 使这成为可能,您可以稍后将此数据加载到RAG应用程序中,代码如下:
# ! pip install yt_dlp
# ! pip install pydub
# ! pip install ffmpeg
# ! pip install ffprobe
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
url = "https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir = "docs/youtube/"
loader = GenericLoader(YoutubeAudioLoader([url], save_dir), OpenAIWhisperParser())
docs = loader.load()
# [youtube] Extracting URL: https://www.youtube.com/watch?v=jGwO_UgTS7I
# [youtube] jGwO_UgTS7I: Downloading webpage
# [youtube] jGwO_UgTS7I: Downloading ios player API JSON
# [youtube] jGwO_UgTS7I: Downloading android player API JSON
# WARNING: [youtube] Skipping player responses from android clients (got player responses for video "aQvGIIdgFDM" instead of "jGwO_UgTS7I")
# [youtube] jGwO_UgTS7I: Downloading m3u8 information
# [info] jGwO_UgTS7I: Downloading 1 format(s): 140
# [download] docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a has already been downloaded
# [download] 100% of 69.76MiB
# [ExtractAudio] Not converting audio docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a; file is already in target format m4a
# Transcribing part 1!
# Transcribing part 2!
# Transcribing part 3!
# Transcribing part 4!
print(docs[0].page_content[:500])
>>>
Welcome to CS229 Machine Learning. Uh, some of you know that this is a class that's taught at Stanford for a long time. And this is often the class that, um, I most look forward to teaching each year because this is where we've helped, I think, several generations of Stanford students become experts in machine learning, got- built many of their products and services and startups that I'm sure, many of you or probably all of you are using, uh, uh, today. Um, so what I want to do today was spend some time talking over, uh, logistics and then, uh, spend some time, you know, giving you a beginning of an intro, talk a little bit about machine learning. So about 229, um, you know, all of you have been reading about AI in the news, uh, about machine learning in the news. Um, and you've probably heard me or others say AI is the new electricity.
在此示例中,我们加载了一个 YouTube 视频并使用 OpenAI 的 Whisper 模型转录其音频,从而可以与视频内容聊天。想象一下,能够就 Andrew Ng 的讲座或 YouTube 上的任何其他教育视频提出问题!
3.加载网站
互联网上到处充满着有用的信息,LangChain基于Web的加载器允许您利用这些丰富的信息。假设你遇到了一个有趣的 GitHub 存储库,其中包含一个您想与之聊天的 README 文件:
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://raw.githubusercontent.com/RutamBhagat/code_wizard_frontend/main/README.md")
docs = loader.load()
print(docs[0].page_content[:500])
>>>
# Code Wizard: LangChain Documentation AI Chatbot
Code Wizard is a super cool AI chatbot that helps you learn and use the LangChain Documentation in an interactive way. Just ask it anything about LangChain concepts or code, and it'll break it down for you in an easy-to-understand way. Built with Next.js, FastAPI, LangChain, and a local LLaMA model.
**Link to project:** https://code-wizard-frontend.vercel.app/
https://github.com/RutamBhagat/code_wizard_frontend/assets/72187009/353ced90-f408-44ae-b633-c30f20dbd28f
在此示例中,我们将加载的内容存储在对象列表中,我们可以通过打印.code_wizard_frontendWebBaseLoaderDocumentdocs[0]来访问第一个文档的文本内容.page_content。虽然加载的内容可能包含一些格式或空格问题,但此示例演示了LangChain的多功能性,允许您加载和处理来自各种在线源的数据。
4.加载Notion
Notion 已成为个人和专业知识管理的流行工具,使其成为许多用户的宝贵数据来源。LangChain使您能够从Notion数据库加载数据并无缝地使用它。
首先,您需要以兼容的格式导出 Notion 数据。下面是一个如何使用LangChain从Notion数据库加载数据的示例:
from langchain.document_loaders import NotionDirectoryLoader
# Export your Notion data and save it in a directory
loader = NotionDirectoryLoader("path/to/your/notion/export")
docs = loader.load()
# Print the content of the first document
print(docs[0].metadata)
# {'source': "docs/Notion_DB/Blendle's Employee Handbook e367aa77e225482c849111687e114a56.md"}
print(docs[0].page_content[:500])
>>>
# Blendle's Employee Handbook
This is a living document with everything we've learned working with people while running a startup. And, of course, we continue to learn. Therefore it's a document that will continue to change.
**Everything related to working at Blendle and the people of Blendle, made public.**
These are the lessons from three years of working with the people of Blendle. It contains everything from [how our leaders lead](https://www.notion.so/ecfb7e647136468a9a0a32f1771a8f52?pvs=21) to [how we increase salaries](https://www.notion.so/Salary-Review-e11b6161c6d34f5c9568bb3e83ed96b6?pvs=21), from [how we hire](https://www.notion.so/Hiring-451bbcfe8d9b49438c0633326bb7af0a?pvs=21) and [fire](https://www.notion.so/Firing-5567687a2000496b8412e53cd58eed9d?pvs=21) to [how we think people should give each other feedback](https://www.notion.so/Our-Feedback-Process-eb64f1de796b4350aeab3bc068e3801f?pvs=21) — and much more.
在这个例子中,我们从 Notion 数据库导出数据,并将加载的内容存储在对象列表中,我们可以通过打印来访问第一个文档的文本内容。NotionDirectoryLoaderDocumentdocs[0].page_content。
通过使用LangChain的文档加载器,您可以充分利用您的Notion数据库并与他们聊天,从而获得见解并做出更明智的决策。
小节
本节我们学习了LangChain的文档加载器,LangChain的文档加载器允许您从PDF、YouTube视频、网站和专有数据库等不同来源加载数据,使您能够构建真正理解数据并与之交互的智能应用程序。通过简化数据加载和标准化,这些加载器可以充分利用您的数据,让您提出问题,获得见解。本节的内容就到这里了,希望对同学们有所帮助。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
四、AI大模型商业化落地方案
阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
















 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









