







写在前面
LLM零基础,在这篇博客完成打卡记录。
本项目是一个面向小白开发者的大模型应用开发教程,旨在基于阿里云服务器,结合个人知识库助手项目,通过一个课程完成大模型开发的重点入门。
![[图片]](https://img-blog.csdnimg.cn/direct/fc833194d90e4dfe906d02d589f7498d.png)
【教程地址】https://datawhalechina.github.io/llm-universe/
【开源项目仓库】https://github.com/datawhalechina/llm-universe
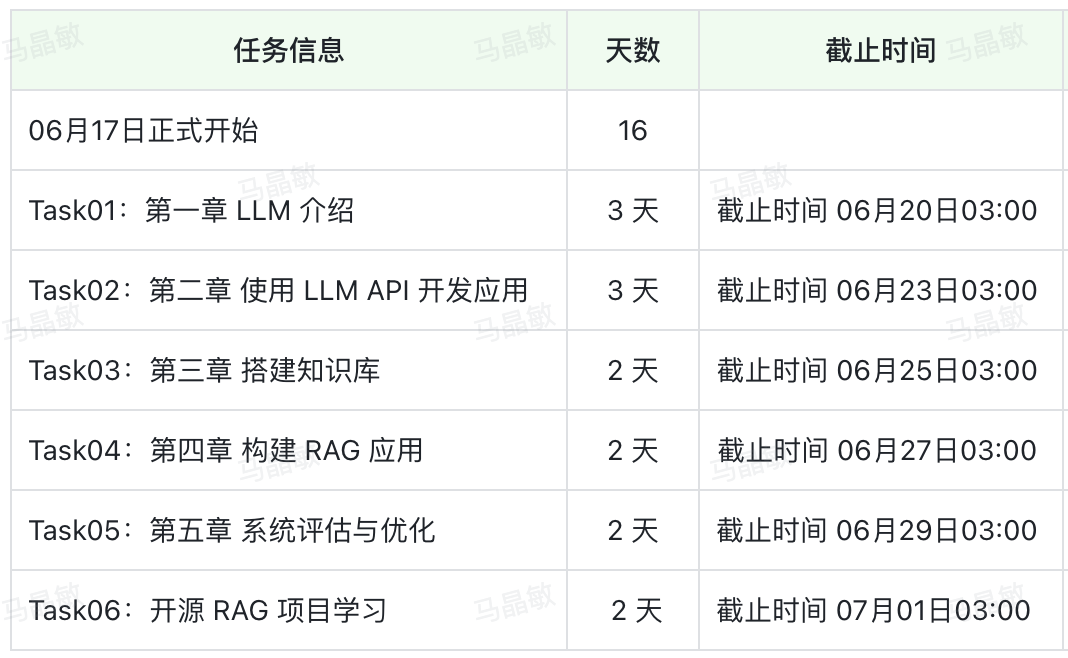
3.搭建知识库
MMR,Maximum marginal relevance,最大边际相关性
chap3.1
- 什么是词向量?
- 使用词嵌入(word embeddings)来表示文本数据,这个向量捕获单词的语义信息。
- 传统数据库?
- 对于传统数据库,搜索功能都是基于不同的索引方式(B Tree、倒排索引等)加上精确匹配和排序算法(BM25、TF-IDF)等实现的。本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
- 例如,如果你搜索“小狗”,那么你只能得到带有“小狗”关键字相关的结果,而无法得到“柯基”、“金毛”等结果,因为“小狗”和“金毛”是不同的词,传统数据库无法识别它们的语义关系。
博客:https://guangzhengli.com/blog/zh/vector-database/#gpt-%E7%9A%84%E7%BC%BA%E9%99%B7
- BM25和TF-IDF如何实现?
- 先不展开……
- 词向量优势?构建方法?
- 向量比文本更适合做检索,因为向量包含了语义信息。
- 通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度。
- 可以调用其他公司Embedding API,也可以本地自己构造。
- 什么是向量数据库?在哪一环使用
- 这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
- 在indexing那一块(本地先将Document向量化)进行向量检索的操作,返回embeddings(Relevant Documents[Chunk1/2/3])连同Query一起返回(Combine Context and Prompts)。
![[图片]](https://img-blog.csdnimg.cn/direct/2aad83f890de45988f5951b84dee950a.png)
图源:https://arxiv.org/pdf/2312.10997
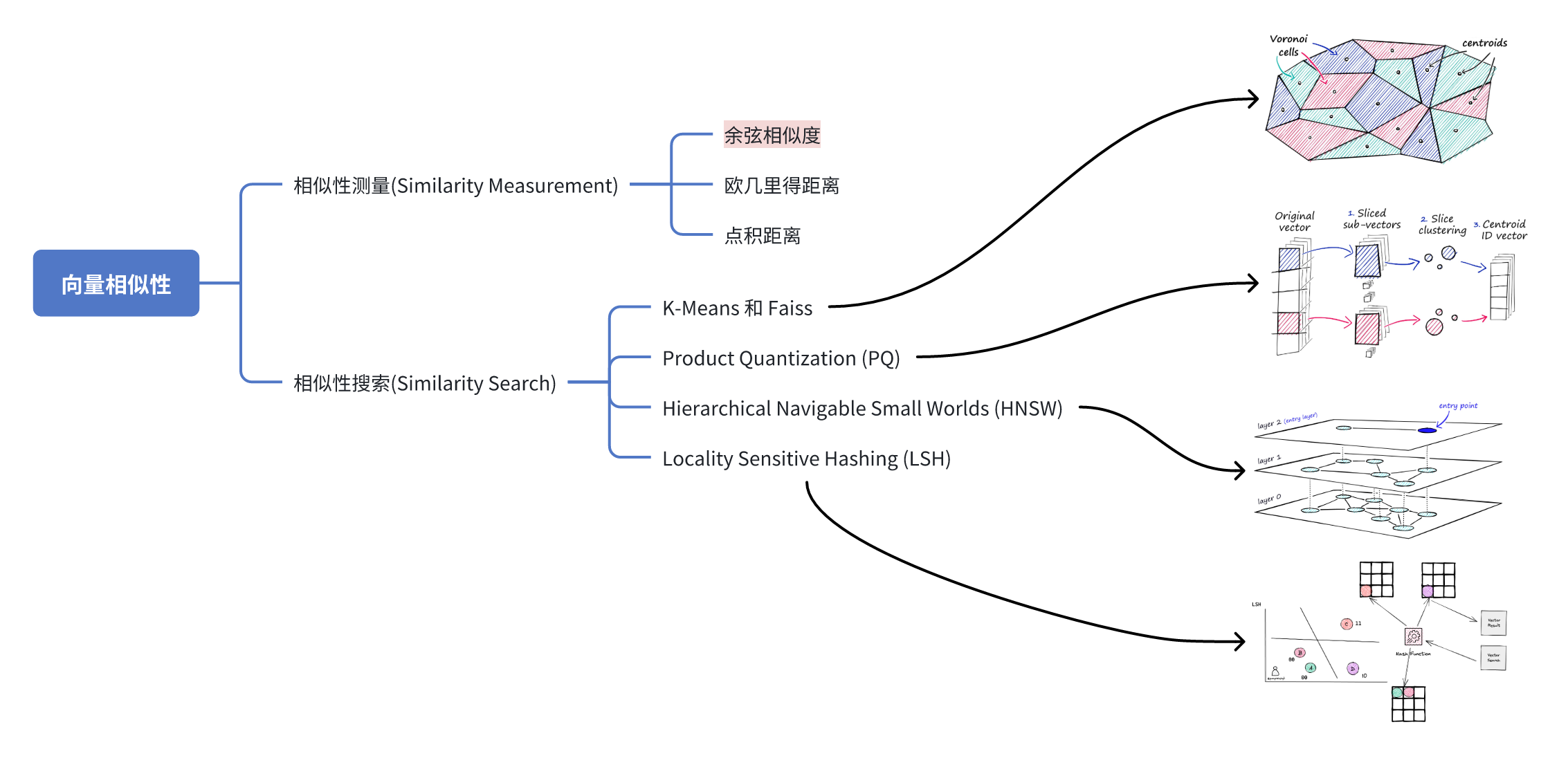
- 向量数据库,常用索引和查询算法有哪些?
- Kmeans:聚类
- Faiss:紧密的聚类。引入一个新的查询向量时,首先测量其与质心 (centroids) 之间的距离,然后将搜索范围限制在该质心所在的单元格内(nprobe=1时只检索最近邻的1个cell)。工业界常常要平衡速度、质量、内存这三者选择方案,也叫近似最相邻(ANN)。
- PQ:有损压缩,拆分成多个子向量。解决内存过大问题,但是精度有所下降。
- HNSW:通过构建树或者构建图的方式来实现近似最近邻搜索。与跳表算法思路相似,空间换时间。
- LSH:使用一组哈希函数将相似向量映射到“桶”中,从而使相似向量具有相同的哈希值。
![[图片]](https://img-blog.csdnimg.cn/direct/65d01f99f1d643a9a18cd5ab5d9f335a.png)
- 一般常用余弦相似度,公式和图象可以参考下边博客。
博客:相似性测量 (Similarity Measurement)
- 常用数据库
- Chroma、Weaviate
chap3.2
-
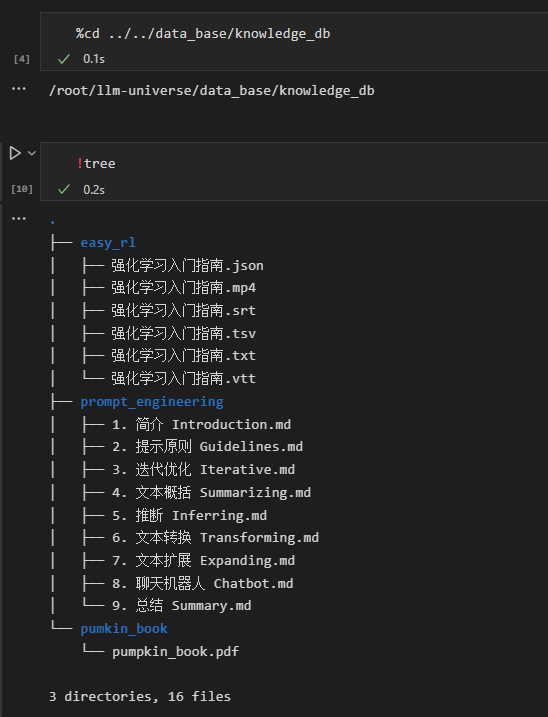
先看下该路径下,文件情况。需要先下载tree相关包(输入tree,会有下载提示)。
-
Os.walk用法:https://blog.csdn.net/qq_41562433/article/details/82995098,看这一篇足够;
- root:当前目录的地址;
- dirs:List,当前路径都有哪些目录(一代,儿子)如果是叶子节点那就为None;
- files:List,所有的文件(一代,儿子);
- List.extend用法:https://blog.csdn.net/weixin_43283397/article/details/104292540,与append区别;
- 单纯把元素加上去;
chap3.3~chap3.4
- 数据处理主要做什么,在哪个环节?
- 上边那一条链路。
![[图片]](https://img-blog.csdnimg.cn/direct/7c4a18864a544c8b82a2f99394826286.png)
图源:https://help.aliyun.com/zh/open-search/search-platform/user-guide/building-knowledge-base-online-q-a-based-on-rag
-
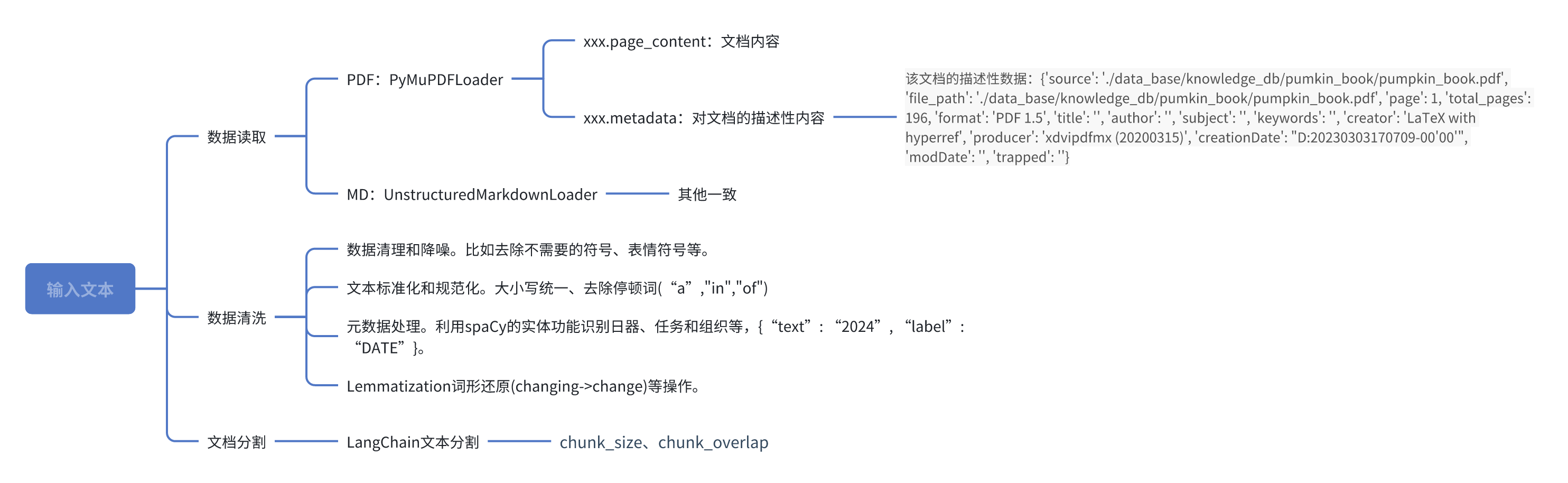
数据读取
-
数据清洗常用方法有哪些?
参考:https://medium.com/intel-tech/four-data-cleaning-techniques-to-improve-large-language-model-llm-performance-77bee9003625(中译版:https://www.atyun.com/59145.html)
- 数据清理和降噪。比如去除不需要的符号、表情符号等。
- 文本标准化和规范化。大小写统一、去除停顿词(“a”,“in”,“of”)
- 元数据处理。利用spaCy的实体功能识别日器、任务和组织等,{“text”: “2024”, “label”: “DATE”}。这样一来在后边数据检索的时候,能够很方便用在“过滤”的环节。比如提问“1980 年拍摄了哪些关于外星人的电影”,那么在数据库做检索的时候就应该过滤“1980”年份的内容。
- Lemmatization词形还原(changing->change)等操作。
- 正则化
import re
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)
print(pdf_page.page_content)
这段代码的主要作用是去除文本中位于非中文字符之外的换行符,保持其他部分不变。
re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)这里使用了正则表达式来定义一个模式。具体解释如下:r'[^\u4e00-\u9fff]':表示除了中文字符(\u4e00-\u9fff范围外)的任意字符。(\n):表示匹配换行符(\n),并将其作为一个捕获组。[^\u4e00-\u9fff]:再次表示除中文字符外的任意字符。re.DOTALL:这个标志使得.特殊字符匹配包括换行符在内的所有字符。- `re.sub(pattern, lambda match: match.group(0).replace(‘\n’, ‘’), pdf_page.page_content):这行代码实现了正则替换操作。
- pattern`:前面编译好的正则表达式模式。
lambda match: match.group(0).replace('\n', ''):用于替换的匿名函数,对每个匹配到的字符串进行处理。match.group(0):表示整个匹配到的字符串。.replace('\n', ''):替换其中的换行符\n为空字符串,从而移除换行符。
- 为什么需要文档分割,怎么分割?
- 单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,所以需要对文档进行切片操作。
- 将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
- LangChain文本分割器调节两个参数:chunk_size和chunk_overlap。
![[图片]](https://img-blog.csdnimg.cn/direct/244ea4f06a3446998b0bf6c94d4c8d12.png)
- 如何构造向量库?
- 项目采用的向量数据库是Chroma,作为LangChain中的向量存储(Vector Store)。Chroma是一个非常简单易用的嵌入式向量数据库,在开发和测试场景非常受欢迎。
- 项目这里是通过Chroma.from_documents指令将我们之前处理好的文档数据,作为数据源;
- 在日常使用中还可以使用 Elasticsearch(处理大规模数据的索引/查询) + MongoDB(数据存储和管理) 的组合方式实现RAG数据检索和管理的工作;
- 介绍下Elasticsearch?
- 用倒排的方式构建索引,内有相关性评分机制,先不展开……
- RAG的MMR是在做什么?
- 思路简单说就是先挑选“fetch_k”个最相似的response(先确保是“相关”的)比如取Top5个,其次再在这5个里边挑选最不相关的“k”个进行融合,送到下一步。
- 以下边的图为例,fetch_k返回了Top5条,k取2,通过MMR算法确定,最终返回第1条和第3条。
- 尽管可能牺牲了一定的相关性,但假如需要融合的答案全都是一模一样的,这样就违背了最初“Top5”的意义,直接返回“Top1”就完事了。所以只需要返回其中的一句就可以了,额外再返回一个与问题相关性弱一点的答案(例如第三句文本),这样似乎增强了答案的多样性,用户也会更加喜欢。
- 插一个题外话,MMR也是推荐系统中打散环节常用的方法,目的恰恰就是为了保证推荐结果的“多样性”,俗称“多样性打散”。
![[图片]](https://img-blog.csdnimg.cn/direct/88f5799b3798492aa62cbc76c2685c15.png)
非图源,但推荐这篇:https://medium.com/@yogeshsakpal59/rag-retrieval-augmented-generation-conversational-ai-60fec3d51cfe
欢迎点赞👍和收藏⭐ 这是对我最大的鼓励!















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









