







1 模型评估常用方法?
一般情况来说,单一评分标准无法完全评估一个机器学习模型。只用good和bad偏离真实场景去评估某个模型,都是一种欠妥的评估方式。下面介绍常用的分类模型和回归模型评估方法。
分类模型常用评估方法:
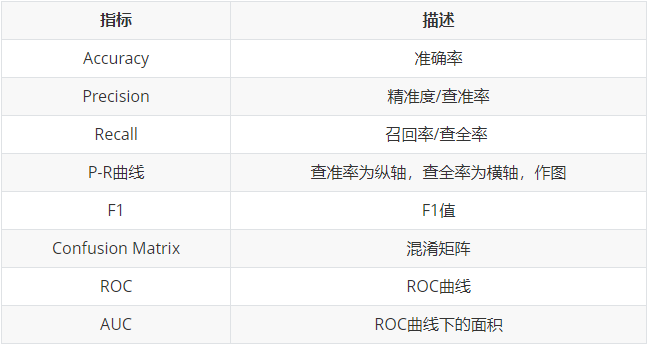
回归模型常用评估方法:
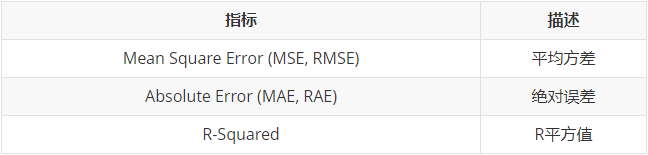
2 混淆矩阵

3 错误率及精度
- 错误率(Error Rate):分类错误的样本数占样本总数的比例。
- 精度(accuracy):分类正确的样本数占样本总数的比例。
4 查准率与查全率
将算法预测的结果分成四种情况:
- 正确归为正样本(True Positive,TP):预测为真,实际为真
- 正确归为负样本(True Negative,TN):预测为假,实际为假
- 错误归为正样本(False Positive,FP):预测为真,实际为假
- 错误归为负样本(False Negative,FN):预测为假,实际为真
则:
查准率(Precision)=TP/(TP+FP)
理解:预测出为阳性的样本中,正确的有多少。区别准确率(正确预测出的样本,包括正确预测为阳性、阴性,占总样本比例)。
例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)
理解:正确预测为阳性的数量占总样本中阳性数量的比例。
例,在所有实际上有恶性肿瘤的病人中,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2908
2908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









