






目录
一、回归评价指标
思考角度:
1、是否预测到了正确的数值(MSE、MAE)
如果说真实曲线和拟合曲线的前半部分拟合的非常好,后半部分非常不好的话,MSE、MAE因为拟合的数据非常多,数值很小,因为大部分样本完全拟合,少部分样本有巨大差异。这就是没有拟合到足够的信息。
2、是否拟合到了足够的信息(
回归模型有:
1、Linear Regression线性回归
2、Logistic Regression逻辑回归
3、Polynomial Regression多项式回归
4、Stepwise Regression逐步回归
1、MSE(均方差)
Mean squared error
用来衡量预测值和真实值的差异,本质上是在和方差的基础上除以样本总量,得到样本量上胡平均误差。
有了平均误差,就可以将平均误差肯标签的取值范围在一起比较,以此获得一个较为可靠胡评估依据。
使用sklearn中的参数scoring下,均方误差为负,标准时,却是计算负均方误差(neg_mean_squared_error),这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn中,所有损失都用负数表示,因此均方误差也被显示负数了,去掉负号就是正确的值。
from sklearn.metrics import mean_squared_error as MSE
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
MSE(y_true, y_pred)
2、MSE(平均绝对误差)
Mean absolute error
现实中,MSE和MAE选一个来用就好了,MSE更常见。
from sklearn.metrics import mean_squared_error
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
mean_squared_error(y_true, y_pred)
3、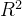 决定系数
决定系数
_score
使用方差来衡量数据上的信息。如果方差越大,代表数据上的信息量越多,而这个信息量不仅包括了数值的大小,还包括了希望模型捕捉的那些规律。
y是真实标签,\hat{y}是预测结果,\bar{y}是均值,y_{i} - \bar{y_{i}如果除以样本量m就是方差。方差的本质是任意一个y值和样本均值的差异,差异越大,这些值所带的信息越多。
分子是真实值和预测值之差的差值,也就是模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以其衡量的是(1-模型没有捕获到的信息量占真实标签中所带的信息量的比例),所以,越接近1越好,但是理论上取值负无穷到1。
越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
越接近0,表明模型拟合的越差
经验值:>0.4, 拟合效果好
缺点:数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差
,随着自变量个数的增加,R将不断增大(或者只是在一部分拟合的好,所以数据集越大,拟合不好的地方越多,R2的表现就会越不一样)
注意:预测值必须在分子,真实值在分母。
from sklearn.metrics import r2_score
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
r2_score(y_true, y_pred)
r2 = reg.score(y_true,y_pred)
print(r2)(R2可用于PCA降维后的模型评估)
4、Adjusted R-squre(矫正决定系数)
n为样本数量,p为特征数量。
优点:抵消样本数量和特征数量对R-square的影响。
from sklearn.metrics import r2_score
def score(a,b,dimension):
# a is predict, b is actual. dimension is len(train[0]).
rr = r2_score(a, b)
adjust_rr = 1 - (1- rr)*(len(a)-1)/(len(a)-dimension-1)
return adjust_rr
y_true, y_pred = [8, -0.5, 2, 7], [2.5, 0.0, 2, 8]
print(len(y_true))
score(y_true,y_pred,0)5、RMSE(平方根误差)
root mean square error
缺点:平均值是非鲁棒性的,对异常点敏感,如果某个异常点目标大,整个RMSE都会很大。
二、分类评价指标
以二分类为例,最后的分类结果为“是”或“否”
| 下面是预测,右面是真实 | 正类+ | 负类- |
| 正类+ | TP | FP |
| 负类- | FN | TN |
TP:预测正确+预测值为正类;FP:预测结果错误+预测值为正类
TN:预测错误+预测值为负类;TN:预测结果正确+预测值为负类
常见指标:
1、正确率和错误率
2、精准度和召回率
预测为正类的样本的正确率。
精准度与正确率的区别在于:精确度单独评估某一类类别的的正确率。
预测为正类且真实为正类的样本数/所有真实为正类的样本
例:采购员去买西瓜,希望把所有好的西瓜都买到。
3、综合精准度和召回率
F-measure :
beta是一个参数,用于确定是更在乎精准率一点还是召回率一点。通常beta为1,表明精准率和召回率比重一样。Fmeasure的存在,是因为我们经常需要在精准度和召回率之间作平衡。
想象一个非常极端的模型,这个模型只把它认为最有可能是正类的样本预测为是正类,其余全部为负类,这个模型的精准度会非常高,而召回率可能会非常低。又或者,一个极端模型把所有的样本都预测为正类,这个时候FN\TN为0,召回率为1,但它的精确度肯定很低。
所以精确度和召回率需要权衡。
4、ROC曲线和AUC值
衡量模型且衡量模型给到测试样本的排序,即有多少可能是这个分类。
举二分类为例,分类过后会出现预测样本正类的概率是多少,用某一个概率a为界对预测出来的样本作区分,大于a就预测为正类,小于a就预测为负类。这样的话,一个概率a就会对应一个混淆矩阵。


ROC曲线的作用就是把所有的混淆矩阵都表示在同一个二维空间里。一个混淆矩阵对应一个TPR(True positive rate)和FPR(Flase positive rate).
,即判断正确的正类占真实正类的比值;
,判断错误的负类占真实负类的比值,或1-判断正确的负类占真实负类的比值;
每一个概率a对应一组TPR和FPR,以TPR为纵坐标,FPR为横坐标作图。

那如何分辨ROC曲线对应的分类器的效果呢?由于TPR是预测正确的正类的概率,FPR是预测错误的正类的概率,我们自然希望是TPR越大越好,所以我们会希望曲线越接近左上角越好。
所以就有了AUC值,AUC表示曲线与横纵轴围成面积。AUC值范围为0-1,越大越好。


如果是N分类,有两种方法——宏观macro,微观micro;
宏观macro:针对每一个类别,画一个ROC曲线,求出对应的AUC值,对所有类别的AUC值求平均,求出所有类别的宏观AUC值;
微观micro:计算预测成每一种类别的概率,如样本1预测成C1的概率为P(1,1),样本1预测称C2的概率为P(1,2),每行所有的概率和为1。橙色方块表示该样本所属的真是类别,如样本一真实类别为C1,样本2真实类别为C3。
这样就可以得到经过转化的整个模型的ROC曲线和AUC值。

from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
import numpy as np
# 假如有一个模型在测试集上得到的预测结果为:
y_true = [1, 0, 0, 2, 1, 0, 3, 3, 3] # 实际的类别
y_pred = [1, 1, 0, 2, 1, 0, 1, 3, 3] # 模型预测的类别
# 使用sklearn 模块计算混淆矩阵
confusion_mat = confusion_matrix(y_true, y_pred)
print(confusion_mat) #看看混淆矩阵长啥样
def plot_confusion_matrix(confusion_mat):
'''''将混淆矩阵画图并显示出来'''
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.gray)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(confusion_mat.shape[0])
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
plot_confusion_matrix(confusion_mat)#画图
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores) #输出auc值学习对象:
http://t.csdn.cn/2uioz 7大回归模型总结
http://t.csdn.cn/x6BqW 机器学习之模型评估方法总结
http://t.csdn.cn/Zopij 模型评估(回归分类)
http://t.csdn.cn/31ZBr 模型评估(有sklearn API)
【【小萌五分钟】机器学习 | 模型评估: ROC曲线与AUC值】 https://www.bilibili.com/video/BV1wz4y197LU/?share_source=copy_web&vd_source=98fbab4e0ff3ef4e18cd477db479634d
http://t.csdn.cn/aMmID 回归分类模型评估(分类代码)
http://t.csdn.cn/2YpWW 模型评估(有sklearn)















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









