







1.样本不均衡
过采样或者下采样
下采样:
让样本同样少
过采样:
生成数据使得样本一样多
SMOTE算法:
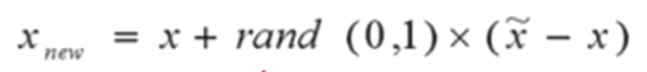
2.保持各特征分布有差不多的范围:
保证不同特征的取值跨度相同,保持重要程度相同
3.交叉验证
训练集
验证集
测试集
交叉验证:求稳
比如,训练集拆成3份,1+2-》训练,3验证,1+3-》训练,2验证,2+3训练,1验证
再求平均
4.模型评估方法
精度 num(y^=y)/num(all)
Recall 召回率: TP/(TP+TF)
TP:正类判为正类
FP:负类判为正类
FN:正类判为负类
TN:负类判为负类
5.正则化惩罚项
希望泛化能力强,避免过拟合
则加入正则化惩罚项,一般用L2正则化方法
6.混淆矩阵
X轴是predicted label
Y轴是real label
分成四个块,就是个看recall值的图















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









