






在这一节,我们提出图神经网络的几种变体。首先是在不同图类型上运行的变体,这些变体扩展了原始模型的表示能力。其次,我们列出了在传播步骤进行修改(卷积、门机制、注意力机制和 skip connection)的几种变体,这些模型可以更好地学习表示。最后,我们描述了使用高级训练方法的标题,这些方法提高了训练效率。

图的类型 (Graph Types)
在原始 GNN 中,输入的图由带有标签信息的节点和无向的边组成,这是最简单的图形格式。然而,世界上有许多不同的图形。这里,我们将介绍一些用于建模不同类型图形的方法。

有向图 (Directed Graphs)
图形的第一个变体是有向图。无向边可以看作是两个有向边,表明两个节点之间存在着关系。然而,有向边比无向边能带来更多的信息。例如,在一个知识图中,边从 head 实体开始到 tail 实体结束,head 实体是 tail 实体的父类,这表明我们应该区别对待父类和子类的信息传播过程。有向图的实例有 ADGPM (M. Kampffmeyer et. al. 2018)。
ADGPM(attention dense graph propagation module ):
1.更少的GCN层数,使用两层神经网络进行计算(即GPM)
2.减少层数的同时,一些较远节点将不被考虑在内,为了解决这个问题,作者将一些节点的祖先节点/子孙节点直接与该节点相连,生成了更密集的图,即DGPM,这些直接相连的边按照距离的远近,加入attention进行了加权计算(即ADGPM)
3.提出了在CNN部分根据graph信息进行finetune的计算方式,使得提取图片特征的卷积网络可以根据一些新出现的class进行更新。
参考文章:https://blog.csdn.net/weixin_39505272/article/details/93234700
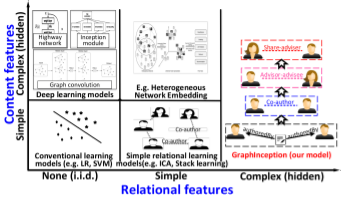
异构图 (Heterogeneous Graphs)
图的第二个变体是异构图,异构图有几种类型的节点。处理异构图最简单的方法是将每个节点的类型转换为与原始特征连接的一个 one-hot 特征向量。异构图如 GraphInception。
a deep convolutional collective classification method, called GraphInception
在这项研究中,我们提出了一种深度卷积集体分类方法,称为GraphInception,以学习异构信息网络(HIN)中的深层关系特征。GraphInception可以自动生成具有不同复杂性的关系特征的层次结构。大量实验表明,我们的方法可以通过考虑HIN中的深层关系特征来提高集体分类性能。
参考文章:https://pdfs.semanticscholar.org/9a85/284e05e1ce6a51aae7b9d44853b761fb5b25.pdf
带边信息的图 (Edge-informative Graph)
图的另外一个变体是,每条边都有信息,比如权值或边的类型。例如R-GCN。
R-GCN 模型,应用于联系预测和实体分类任务上。实体分类器模型在图中每个顶点使用 softmax 分类器,分类器采用 R-GCN 模型提供的节点表示并预测标签,其中包括 R-GCN 参数在内的模型依靠优化交叉熵损失得到。对于联系预测任务,通过在关系图中的多个推理步骤中使用编码器模型来积累信息,可以显著改进链路预测的模型。并且相对于解码模型,在 FB15k-237 数据集上提升了 29.8% 。
GCN模型
R-GCN 和 GCN 等相似的图卷积模型可以通过一个简单的消息传播框架所理解。即如下所示:
h
i
(
l
+
1
)
=
σ
(
∑
m
ϵ
M
i
g
m
(
h
i
(
l
)
,
h
j
(
l
)
)
)
h_i^{(l+1)}=\sigma (\sum_{m_\epsilon M_i} g_m(h_i^{(l)},h_j^{(l)}))
hi(l+1)=σ(mϵMi∑gm(hi(l),hj(l)))
其中,
h
i
(
l
)
h_i^{(l)}
hi(l)是顶点
V
i
V_i
Vi在第
l
l
l层,特征维度为
d
(
l
)
d^{(l)}
d(l)的特征信息,
σ
\sigma
σ则表示将收集到的信息通过激活函数例如 relu,
M
i
M_i
Mi则是表示传递消息给顶点
V
i
V_i
Vi的所有边,通常是顶点
V
i
V_i
Vi的入边。
g
m
g_m
gm则表示选择一个神经元函数或者只是简单的一个线性转换
g
m
(
h
i
,
h
j
)
=
W
h
j
g_m(h_i,h_j)=Wh_j
gm(hi,hj)=Whj。即接受顶点的所有入边传递来的上一层的顶点特征消息,做相应的变换,并将其加和起来,最后通过一个激活函数作为本层的输出。
问题描述

上图中红色字体的边和顶点标签就是我们要预测的边类型和顶点标签,我们在知道“Mikhail Baryshnikov”在“Vaganova Academy”大学上学后,那么对于他和“USA”的关系我们就可以想到是“citizen of”。这就是 R-GCN 模型的联系预测,顶点标签预测也是同理。
R-GCN模型
R-GCN 是对局部图形领域进行操作 GCN 模型的扩展到大规模关系数据,考虑到了边的类型这一特征信息。同时为了使得顶点上一层的特征信息可以传递到下一层中,为每个顶点添加了特殊的自环边。计算公式如下所示。
h
i
(
l
+
1
)
=
σ
(
∑
r
∈
R
∑
j
∈
N
i
r
1
C
i
,
r
w
r
(
l
)
h
j
(
l
)
+
w
0
(
l
)
h
i
(
l
)
)
h_i^{(l+1)}=\sigma(\sum_{r\in R}\sum_{j\in N_i^r}\frac{1}{C_{i,r}}w_r^{(l)}h_j^{(l)}+w_0^{(l)}h_i^{(l)})
hi(l+1)=σ(r∈R∑j∈Nir∑Ci,r1wr(l)hj(l)+w0(l)hi(l))
其中,
N
i
r
N_i^r
Nir是表示与顶点i相邻的关系r下的顶点集合。
C
i
,
r
C_{i,r}
Ci,r则是一个可以学习的参数。对相邻顶点的特征乘以边类型所对应的权值再乘以一个可学习的参数后求和,最后加上自环边所传递的信息。经过激活函数后,作为本层的输出,下一层的输入。

如上图中 R-GCN 的源码所示,在输入层,则是根据边头顶点的 id 号以及边的类型,选择对应的权值,并将其作为第一层的输出,在隐藏层和输出层,将上一层顶点的输出乘以边的权值,作为本层的输出,相同类型的边则共享权值。

上图中则是每个顶点首先对收集到的信息一个加和,再加偏置,并使用 relu 函数激活。
将 R-GCN 这一模型应用于多关系数据的一个核心问题则是图中关系与参数数目的增长,这将会导致对罕见关系的过拟合,以及对大模型的过拟合问题。为了解决上述问题引入了两种独立的规则化 R-GCN 权重的方法:基函数分解和块对角分解。
基分解的公式如下所示。
w
r
(
l
)
w_r^{(l)}
wr(l)作为基变换
V
b
(
l
)
V_b{(l)}
Vb(l)与系数
a
r
b
(
l
)
a_{rb}^{(l)}
arb(l)的线性组合,且只依赖于 r。
W
r
(
l
)
=
∑
b
=
1
B
a
r
b
(
l
)
V
b
(
l
)
W_r^{(l)}=\sum_{b=1}^Ba_{rb}^{(l)}V_b^{(l)}
Wr(l)=b=1∑Barb(l)Vb(l)
然而在块对角分解中,公式如下所示。把每一个
W
r
(
l
)
W_r^{(l)}
Wr(l)定义为低维矩阵的直接求和。
W
r
(
l
)
W_r^{(l)}
Wr(l)为块对角矩阵。
W
r
(
l
)
=
⨁
b
=
1
B
Q
b
r
(
l
)
W_r^{(l)}=\bigoplus _{b=1}^BQ_{br}^{(l)}
Wr(l)=b=1⨁BQbr(l)
基函数分解可以看作是不同关系类型之间权重有效共享的一种形式,而块分解可以看作是每个关系类型的权重矩阵上的稀疏性约束。两种分解都减少了拟合多关系数据所需的参数数量。同时,期望可以减轻对稀有关系的过度拟合,因为参数的更新在稀有关系和频繁关系之间是共享的。
然后,整个 R-GCN 模型采用如下图所示的形式:堆叠层——前一层的输出作为下一层的输入。对于下图中红色的顶点进行一次卷积,通过接受来自邻居顶点(蓝色)的信息,然后根据边类型的不同进行相应的转换,收集的信息经过一个正则化的加和(绿色方块),最后通过激活函数(relu)。整张图上每个顶点的信息更新共享参数,并行计算。

实体分类和联系预测
对于顶点的分类,如下图中(a)所示。我们只需要将 R-GCN 层之后对每个顶点的使用softmax 函数激活,并且使用交叉熵损失在优化模型。并且在实践中,作者使用整批梯度下降来训练模型。
对于联系的类型预测,如下图中(b)所示。作者使用了一个图自编码器模型,包含一个实体编码器和一个评分函数(解码器)组成。作者用负采样训练模型。对于每一个观察到的例子,都进行负采样。通过随机破坏每个正例子的主题或对象来负采样。对交叉熵损失进行了优化,以使得正样例的得分是负样例的三倍。

参考文献:https://zhuanlan.zhihu.com/p/61834680
使用不同训练方法的图变体


一、回顾GCN及其问题
GCN的基本思想: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量表示。
GCN的优点: 可以捕捉graph的全局信息,从而很好地表示node的特征。
GCN的缺点: Transductive learning的方式,需要把所有节点都参与训练才能得到node embedding,无法快速得到新node的embedding。
得到新节点的表示的难处: 要想得到新节点的表示,需要让新的graph或者subgraph去和已经优化好的node embedding去“对齐”。然而每个节点的表示都是受到其他节点的影响,因此添加一个节点,意味着许许多多与之相关的节点的表示都应该调整。这会带来极大的计算开销,即使增加几个节点,也要完全重新训练所有的节点。
因此我们需要换一种思路:既然新增的节点,一定会改变原有节点的表示,那么我们干嘛一定要得到每个节点的一个固定的表示呢?我们何不直接学习一种节点的表示方法。这样不管graph怎么改变,都可以很容易地得到新的表示。
二、GraphSAGE是怎么做的
针对这种问题,GraphSAGE模型提出了一种算法框架,可以很方便地得到新node的表示。
基本思想: 去学习一个节点的信息是怎么通过其邻居节点的特征聚合而来的。 学习到了这样的“聚合函数”,而我们本身就已知各个节点的特征和邻居关系,我们就可以很方便地得到一个新节点的表示了。
GCN等transductive的方法,学到的是每个节点的一个唯一确定的embedding; 而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。
假设我们要聚合K次,则需要有K个聚合函数(aggregator),可以认为是N层。 每一次聚合,都是把上一层得到的各个node的特征聚合一次,在假设该node自己在上一层的特征,得到该层的特征。如此反复聚合K次,得到该node最后的特征。 最下面一层的node特征就是输入的node features。
用作者的图来表示就是这样的:(虽然酷炫,但有点迷糊)

我来画一个图说明:(虽然朴素,但是明明白白)

这里需要注意的是,每一层的node的表示都是由上一层生成的,跟本层的其他节点无关。
聚合函数的选择
Mean aggregator :
直接取邻居节点的平均,公式过于直白故不展示。
GCN aggregator:
这个跟mean aggregator十分类似,但有细微的不同,公式如下:
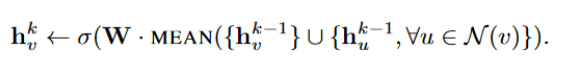
LSTM aggregator:
使用LSTM来encode邻居的特征。 这里忽略掉邻居之间的顺序,即随机打乱,输入到LSTM中。这里突然冒出来一个LSTM我也是蛮惊讶,作者的想法是LSTM的表示能力比较强。但是这里既然都没有序列信息,那我不知道LSTM的优势在何处。
Pooling aggregator:
把各个邻居节点单独经过一个MLP得到一个向量,最后把所有邻居的向量做一个element-wise的max-pooling或者什么其他的pooling。公式如下:
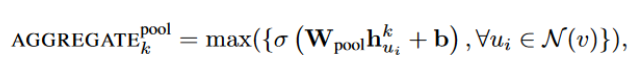
FastGCN
基于图的卷积神经网络模型来自于两个方面,一方面是谱图理论,一方面是表征学习,如node2vec和LINE算法,通过为每个节点学习一个全图特征表示,对图空间进行降维得到低维特征表示。与最近的GraphSAGE相比,GraphSAGE存在对邻居规模的限制,而FastGCN是对节点进行采样,而非邻居。
1. 模型理解
直观上看,计算公式和之前GCN相比,一个是全连接公式,一个是积分公式,但是FastGCN的积分公式,考虑到
s
p
a
c
e
(
V
′
,
F
,
P
)
space(V^{'},F,P)
space(V′,F,P),V’是采样的独立同分布的样本节点集合,F是事件空间,P是采样分布,概率评估矩阵。

左图每一层代表一批抽样节点,相邻层之间的连线代表在图中两点具有相连关系,not全连接;右图是在满足P分布的基础上进行抽样,后一层的embedding函数是前一层函数的积分变换。就是用一个概率矩阵对节点进行抽样,即重要性采样。然后再转化为积分进行层间传播。感觉相比传统GCN,fastgcn之所以快是因为它在每层之间的传播过程做了抽样,而不是用全图去表示。
Self/Co-training GCN
1.Self-training
先训练一个 GCN模型,然后使用这个训练好的模型进行预测,根据预测结果的softmax分数选择可信的样本,加入到训练集中再重新训练,如此反复。
2. Co-training
Co-training需要一个协同的分类器,论文中采取了PARW作为协同。
使用random与GCN一起训练,并进行self-training或者co-training,不需要使用验证集,只要训练集的点到达一定数量就认为全图都被传播遍了。
因为GCN主要受限于局部卷积,所以使用random walk弥补这一短板。
因为标签比较少,不能传播至全图,所以使用self-training或者co-training在训练集中添加数据,增加点的数量,有利于传播至全图,当训练集的点到达一定数量,默认为整张图都被传播到标签了。
学会创建边,目前边的权重不进行改变始终是一个bug,但是如何创建边遗迹确定边的权重依旧是个问题。
self-training将GCN的测试结果较高的数据继续放入训练集。
co-training把GCN和random walk的测试结果搞得加入到对方的训练集。
Union将GCN与random walk测试集置信度最高的点的并集加入到GCN的训练集。
Intersection将GCN与random walk 测试集置信度最高的点的交集加入到GCN的训练集。
在传播步骤进行修改的 GNN 变体

GCN略
MoNet
本文提出一个新的MoNet模型,从帧表示学习和分割细化两个方面深入挖掘运动信息来提高视频目标分割的准确性。MoNet利用计算的运动信息(即光流)通过对齐和整合来自相邻帧的特征来增强目标帧的特征表示。新的特征表示为分割提供了有价值的时间上下文,并提高了对各种常见干扰因素的鲁棒性。通过引入距离转换层(DT),MoNet可以有效地分割运动不一致的区域,并提高分割的准确性。
DCNN(Diffusion-ConvolutionalNeuralNetworks)
对于一张graph而言,有N个node,每个node有F个feature,每个节点关注H hop以内的信息
架构:

对于 node classification:
输入:HNNF
第一层:(其实对于每个node而言,通过这一层的映射,会得到一个H*F的map。对于map上的每个元素,是这么得来的,对于这个node i,取H跳的所有邻居的第F个feature信息求和乘以权值w即可)(权值共享体现在同一跳的同一个feature权值一样)

这一层输出的是HF的map ,然后就是一个全连接层,就得到预测结果。
对于graph classification类似:
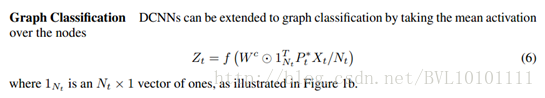
就是在node classification 的基础上,对于每个graph而言,通过这一层的映射,会得到一个H*F的map。对于map上的每个元素,是这么得来的,对于graph上的每个node i,取H跳的所有邻居的第F个feature信息求和,乘以权值w即可。
GAT(graph attention networks)
GAT使用masked self-attention层解决了之前基于图卷积(或其近似)的模型所存在的问题。在GAT中,图中的每个节点可以根据邻节点的特征,为其分配不同的权值。GAT的另一个优点在于,无需使用预先构建好的图。因此,GAT可以解决一些基于谱的图神经网络中所具有的问题。实验证明,GAT模型可以有效地适用于(基于图的)归纳学习问题与转导学习问题。
归纳学习(Inductive Learning): 先从训练样本中学习到一定的模式,然后利用其对测试样本进行预测(即首先从特殊到一般,然后再从一般到特殊),这类模型如常见的贝叶斯模型。
转导学习(Transductive Learning): 先观察特定的训练样本,然后对特定的测试样本做出预测(从特殊到特殊),这类模型如k近邻、SVM等。
GAT基本思想:根据每个节点在其邻节点上的attention,来对节点表示进行更新。
GAT具有以下几个特点:
(1)计算速度快,可以在不同的节点上进行并行计算;
(2)可以同时对拥有不同度的节点进行处理;
(3)可以被直接用于解决归纳学习问题,即可以对从未见过的图结构进行处理。
Model
Graph Attentional Layer
首先来介绍单个的graph attentional layer,单个的 graph attentional layer 的输入是一个节点特征向量集:
h
=
{
h
1
⃗
,
h
2
⃗
,
.
.
.
,
h
N
⃗
}
,
h
i
⃗
∈
R
F
h=\lbrace \vec{h_1} ,\vec{h_2},...,\vec{h_N} \rbrace ,\vec{h_i} \in R^F
h={h1,h2,...,hN},hi∈RF
其中,
N
N
N表示节点集中节点的个数,
F
F
F表示相应的特征向量维度。
每一层的输出是一个新的节点特征向量集:
h
′
=
{
h
1
′
⃗
,
h
2
′
⃗
,
.
.
.
,
h
N
′
⃗
}
,
h
i
′
⃗
∈
R
F
′
h^{'} = \lbrace \vec {h_1^{'}},\vec{h_2^{'}},...,\vec{h_N^{'}} \rbrace ,\vec{h_i^{'}} \in R^{F^{'}}
h′={h1′,h2′,...,hN′},hi′∈RF′
其中,
F
′
F^{'}
F′表示新的节点特征向量维度(可以不等于
F
F
F)。
一个graph attention layer的结构如下图所示:

具体来说,graph attentional layer首先根据输入的节点特征向量集,进行self-attention处理:
e
i
j
=
a
(
W
h
i
⃗
,
W
h
j
⃗
)
e_{ij} = a(W\vec{h_i},W\vec{h_j})
eij=a(Whi,Whj)
其中,a是一个
R
F
′
∗
R
F
′
→
R
R^{F^{'}}*R^{F^{'}}\rightarrow R
RF′∗RF′→R的映射,
W
∈
R
F
′
∗
F
W\in R^{F^{'}*F}
W∈RF′∗F是一个权值矩阵(被所有
h
i
⃗
\vec{h_i}
hi所共享)。一般来说,self-attention会将注意力分配到图中所有的节点上,这种做法显然会丢失结构信息。为了解决这一问题,本文使用了一种masked attention的方式——仅将注意力分配到节点
i
i
i的邻节点集上,即
j
∈
N
i
j \in N_i
j∈Ni(在本文中,节点
i
i
i也是
N
i
N_i
Ni的一部分):
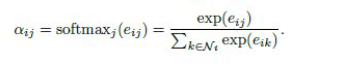
在本文中,
a
a
a使用单层的前馈神经网络实现。总的计算过程为:
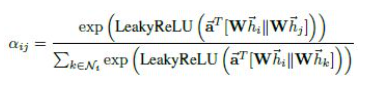


模型比较
本文使用了很大的篇幅将GAT与其他的图模型进行了比较:
 参考文献:https://zhuanlan.zhihu.com/p/34232818
参考文献:https://zhuanlan.zhihu.com/p/34232818
GGNN (门控图神经网络)
基本概念
GGNN是一种基于GRU的经典的空间域message passing的模型
问题描述
一个图 G = (V, E), 节点v ∈ V中存储D维向量,边e ∈ E中存储D × D维矩阵, 目的是构建网络GGNN。
实现每一次参数更新时,每个节点既接受相邻节点的信息,又向相邻节点发送信息。
主要贡献
基于GRU提出了GGNN,利用RNN类似原理实现了信息在graph中的传递。

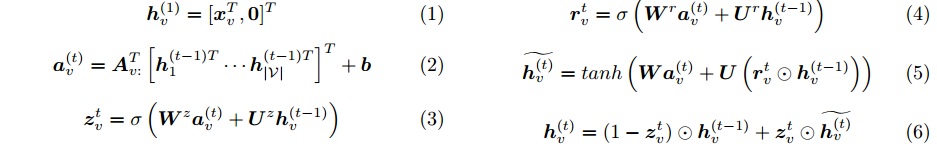

输出模型

Graph LSTMs
抽取句子之间N元关系的基于 graph LSTMs 关系抽取模型,基于graph 制式的方法提供了一种整合不同LSTM模型以及不同类型的关系的能力. 不同类型的关系包括句内关系和句间关系(包括, 序列,句法以及对话关系).模型的某些特征 : 模型的输入是一个基于上下文的健壮词向量.这简化了任意数量的关系的处理.
在序列和树结构上使用LSTM进行端到端关系提取。改进了树状结构的长期短期记忆网络的语义表示。

第一层是输入, 第二层是通过LSTM对每个单词学得一个上下文向量, 其中的几个实体的上下文向量被链接起来, 作为关系分类器的输入. 对于多词汇的实体, 我们的目前的方法是取其每个单词的平均. 这个graph LSTM部分的模型同关系分类器是互相无关系的. 因此, 两个模型分别采用什么,或者说什么样的分类器和这个Graph LSTMs更相配是一个有趣的问题.
document graph—tree LSTM
可以获取句子中各种各样的依存关系,通过选择要包含在文档图中的依赖项,图LSTM自然地包含线性链或树LSTM
不过这样的graph LSTM(以下简称GL)也有两个挑战:
1.容易形成环形结构, 这样的情况使得梯度下降无法进行.
2.由于依存关系的属性很多, 因此不同的依存关系对应不同的参数, 使得参数化成为一個很重要的问题.
Backpropagation in Graph LSTMs
单向LSTM的后向传递过程
对于一个简单的单向LSTM而言, 后向传递的过程是, 记住不同time下的模型, 也就是对于一个有n个输入的模型, 我需要记住n对输入以及输出, 然后依次对前一个时刻的变量做后向传播分析。
cycle LSTM的后向传递
但是在这个模型中, 我们看到LSTMs的不用时刻之间的前向传递关系是混乱的, 也就是说是有内循环的. 上面的那个方法就会造成无法训练的后果.
大概意思就是说, 将内循环的LSTM部分进行展开, 并且这里有一个超参数-展开的层数.
这个方法的缺点
1.使得训练代价过高, 因为每个步骤都要被训练几次.
2.类似于循环置信传播(loopy belief propagation). 会有, 震荡或者无法收敛的缺点.
置信传播是一种在图模型上进行推断的消息传递算法。其主要思想是:对于马尔科夫随机场中的每一个节点,通过消息传播,把该节点的概率分布状态传递给相邻的节点,从而影响相邻节点的概率分布状态,经过一定次数的迭代,每个节点的概率分布将收敛于一个稳态。为了使用置信传播算法,在马尔科夫随机场中定义了两个概念:消息和置信度。
提出的方法
将整个graph分为两个方向的图, 一个向右(包含线性关系和依存关系),一个向左(包含线性关系和依存关系). 如下图所示:

参考文献:https://zhuanlan.zhihu.com/p/46311247
GNN 的三大通用框架
除了图神经网络的不同变体之外,我们还介绍了几个通用框架,旨在将不同的模型集成到一个框架中。
J. Gilmer 等人 (J. Gilmer et. al. 2017) 提出了消息传递神经网络 (message passing neural network, MPNN),统一了各种图神经网络和图卷积网络方法。
把原来普通的message passing的循环过程按照时间或者循环次数展开成一个deep network的形式,各层间的forward更新是按照message passing的方式进行,不过其中的更新函数是学习获得的而不是原始的message passing中的固定的,本质就是个普通的deep network,只不过层间的变换是个特殊的和message passing形式相同的结构。按照这个定义,全连接网络和CNN也都算是MPNN了。
. Wang 等人 (X. Wang et. al. 2017) 提出了非局部神经网络 (non-local neural network, NLNN),它结合了几种 “self-attention” 风格的方法。
Local & non-local
Local这个词主要是针对感受野(receptive field)来说的。以卷积操作为例,它的感受野大小就是卷积核大小,而我们一般都选用33,55之类的卷积核,它们只考虑局部区域,因此都是local的运算。同理,池化(Pooling)也是。相反的,non-local指的就是感受野可以很大,而不是一个局部领域。那我们碰到过什么non-local的操作吗?有的,全连接就是non-local的,而且是global的。但是全连接带来了大量的参数,给优化带来困难。这也是深度学习(主要指卷积神经网络)近年来流行的原因,考虑局部区域,参数大大减少了,能够训得动了。那我们为什么还需要non-local?我们知道,卷积层的堆叠可以增大感受野,但是如果看特定层的卷积核在原图上的感受野,它毕竟是有限的。这是local运算不能避免的。然而有些任务,它们可能需要原图上更多的信息,比如attention。如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息。这是我个人的理解。
Non-local block
好了,那我们来看一下文章是怎么设计non-local运算的。为了能够当作一个组件接入到以前的神经网络中,作者设计的non-local操作的输出跟原图大小一致,具体来说,是下面这个公式:
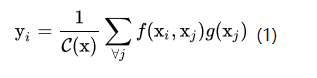
上面的公式中,输入是x,输出是y,i和j分别代表输入的某个空间位置,x_i是一个向量,维数跟x的channel数一样,f是一个计算任意两点相似关系的函数,g是一个映射函数,将一个点映射成一个向量,可以看成是计算一个点的特征。也就是说,为了计算输出层的一个点,需要将输入的每个点都考虑一遍,而且考虑的方式很像attention:输出的某个点在原图上的attention,而mask则是相似性给出。参看下图。

以图像为例,为了简化问题,作者简单地设置g函数为一个11的卷积。相似性度量函数f的选择有多种:

这里有两点需要提一下:
1.后两种选择的归一化系数C(x)选择为x的点数,只是为了简化计算,同时,还能保证对任意尺寸的输入,不会产生数值上的尺度伸缩。
2.Embedding的实现方式,以图像为例,在文章中都采用11的卷积,也就是
θ
\theta
θ和
ϕ
\phi
ϕ都是卷积操作。为了能让non-local操作作为一个组件,可以直接插入任意的神经网络中,作者把non-local设计成residual block的形式,让non-local操作去学x的residual:
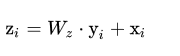
W
z
W_z
Wz实际上是一个卷积操作,它的输出channel数跟x一致。这样以来,non-local操作就可以作为一个组件,组装到任意卷积神经网络中。
具体实现
如果按照上面的公式,用for循环实现肯定是很慢的。此外,如果在尺寸很大的输入上应用non-local layer,也是计算量很大的。后者的解决方案是,只在高阶语义层中引入non-local layer。还可以通过对embedding( )的结果加pooling层来进一步地减少计算量。对于前者,注意到f的计算可以化为矩阵运算,我们实际上可以将整个non-local化为矩阵乘法运算+卷积运算。如下图所示,其中oc为output_channels,卷积操作的输出filter数量。

在tensorflow和pytorch中,batch matrix multiplication可以用matmul函数实现。在keras中,可以用batch_dot函数或者dot layer实现。
跟全连接层的联系
我们知道,non-local block利用两个点的相似性对每个位置的特征做加权,而全连接层则是利用position-related的weight对每个位置做加权。于是,全连接层可以看成non-local block的一个特例:
1.任意两点的相似性仅跟两点的位置有关,而与两点的具体坐标无关,即
f
(
x
i
,
x
j
)
=
w
i
j
f(x_i,x_j)=w_{ij}
f(xi,xj)=wij
2.g是identity函数,
g
(
x
i
)
=
x
i
g(x_i)=x_i
g(xi)=xi
3.归一化系数为1。归一化系数跟输入无关,全连接层不能处理任意尺寸的输入。
跟Self-attention的联系
这部分在原文中也提到了。Embedding的1*1卷积操作可以看成矩阵乘法:
θ
(
x
i
)
=
W
θ
⋅
x
i
;
ϕ
(
x
j
)
=
W
θ
⋅
x
j
⇒
θ
(
x
)
=
W
θ
⋅
x
;
ϕ
(
x
)
=
W
θ
⋅
x
\theta(x_i)=W_\theta \cdot x_i; \phi(x_j) =W_\theta \cdot x_j \Rightarrow \theta(x)=W_\theta \cdot x;\phi(x) =W_\theta \cdot x
θ(xi)=Wθ⋅xi;ϕ(xj)=Wθ⋅xj⇒θ(x)=Wθ⋅x;ϕ(x)=Wθ⋅x
于是,
y
=
s
o
f
t
m
a
x
(
x
T
⋅
W
θ
T
⋅
W
ϕ
⋅
x
)
⋅
g
(
x
)
y=softmax(x^T\cdot W_\theta^T \cdot W_\phi \cdot x)\cdot g(x)
y=softmax(xT⋅WθT⋅Wϕ⋅x)⋅g(x)
跟Gram matrix的联系
Gram matrix第一次被应用到风格迁移任务中,并在后来成为style loss的标配。
Style loss的gram matrix把一个channel看成一个点(坐标就是整个filter,长度等于一个filter大小H*W);而公式(1)则是把每个空间位置看成点(坐标是所有filter在该空间位置上的值,长度等于channel数)。两者都是计算任意两个点之间的内积。内积运算也就这两种处理方式了…
也就是说,它们的差别在于沿着filters的不同方向做内积。
基于gram matrix的style loss可以捕捉到纹理信息;从上一节我们知道,non-local层起到attention的作用。而我们知道,匹配gram matrix相当于最小化feature maps的二次多项式核的MMD距离。而non-local呢?暂时不知道。
P. W. Battaglia 等人 (P. W. Battaglia et. al. 2018) 提出了图网络 (graph network, GN),它统一了统一了 MPNN 和 NLNN 方法以及许多其他变体,如交互网络 (Interaction Networks),神经物理引擎 (Neural Physics Engine),CommNet,structure2vec,GGNN,关系网络 (Relation Network),Deep Sets 和 Point Net。
组合泛化是人工智能实现与人类相似能力的首要任务,而结构化表示和计算是实现这一目标的关键。
几个尚未解决的问题
尽管 GNN 在不同领域取得了巨大成功,但值得注意的是,GNN 模型还不能在任何条件下,为任何图任务提供令人满意的解决方案。这里,我们将陈述一些开放性问题以供进一步研究。
浅层结构
传统的深度神经网络可以堆叠数百层,以获得更好的性能,因为更深的结构具备更多的参数,可以显著提高网络的表达能力。然而,GNN 总是很浅,大多数不超过三层。
实验显示,堆叠多个 GCN 层将导致过度平滑,也就是说,所有顶点将收敛到相同的值。尽管一些研究人员设法解决了这个问题,但这仍然是 GNN 的最大局限所在。设计真正的深度 GNN 对于未来的研究来说是一个令人兴奋的挑战,并将对进一步深入理解 GNN 做出相当大的贡献。
动态图形另一个具有挑战性的问题是如何处理具有动态结构的图形。静态图总是稳定的,因此对其进行建模是可行的,而动态图引入了变化的结构。当边和节点出现或消失时,GNN 不能自适应地做出改变。目前对动态 GNN 的研究也在积极进行中,我们认为它是一般 GNN 的具备稳定性和自适应性的重要里程碑。
非结构性场景
我们讨论了 GNN 在非结构场景中的应用,但我们没有找到从原始数据中生成图的最佳方法。在图像域中,一些研究可以利用 CNN 获取特征图,然后对其进行上采样,形成超像素作为节点,还有的直接利用一些对象检测算法来获取对象节点。在文本域中,有些研究使用句法树作为句法图,还有的研究采用全连接图。因此,关键是找到图生成的最佳方法,使 GNN 在更广泛的领域发挥更大的作用。
可扩展性问题
如何将嵌入式算法应用于社交网络或推荐系统这类大规模网络环境,是几乎所有图形嵌入算法面对的一个致命问题,GNN 也不例外。对 GNN 进行扩展是很困难的,因为涉及其中的许多核心流程在大数据环境中都要消耗算力。
这种困难体现在几个方面:首先,图数据并不规则,每个节点都有自己的邻域结构,因此不能批量化处理。其次,当存在的节点和边数量达到数百万时,计算图的拉普拉斯算子也是不可行的。此外,我们需要指出,可扩展性的高低,决定了算法是否能够应用于实际场景。目前已经有一些研究提出了解决这个问题的办法,我们正在密切关注这些新进展。
结论
在过去几年中,GNN 已经成为图领域机器学习任务的强大而实用的工具。这一进展有赖于表现力,模型灵活性和训练算法的进步。在本文中,我们对图神经网络进行了全面综述。对于 GNN 模型,我们引入了按图类型、传播类型和训练类型分类的 GNN 变体。
此外,我们还总结了几个统一表示不同 GNN 变体的通用框架。在应用程序分类方面,我们将 GNN 应用程序分为结构场景、非结构场景和其他 18 个场景,然后对每个场景中的应用程序进行详细介绍。最后,我们提出了四个开放性问题,指出了图神经网络的主要挑战和未来的研究方向,包括模型深度、可扩展性、动态图处理和对非结构场景的处理能力。
参考文献:https://zhuanlan.zhihu.com/p/53319079
参考论文:https://arxiv.org/pdf/1812.08434v1.pdf















 4989
4989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









