






模型链接:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
一、概述
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
1、更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示, ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
2、更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
3、更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
二、前期准备
准备数据集 大模型时代,数据为王,在哪里寻找开源数据集?_开源数据集网站-CSDN博客
参考数据集:
在这个基础上进行修改后使用
模型下载:魔搭社区
三、使用工具
1、OpenVINO
Openvino是由Intel开发的专门用于优化和部署人工智能推理的半开源的工具包,主要用于对深度推理做优化。
OpenVINO是用于快速开发应用程序和解决方案的综合工具包,可用于解决各种任务,包括模拟人类视觉,自动语音识别,自然语言处理,推荐系统等。该工具包基于最新一代人工神经网络,包括卷积神经网络(CNN),循环和基于注意力的网络,可在Intel硬件上扩展计算机视觉和非视觉工作负载,从而最大额度地提高性能。通过从边缘到云的高性能,人工智能和深度学习推理来加速应用程序。
OpenVINO具有以下优势:
- 优化模型,提高性能。OpenVINO在模型部署前,首先会对模型进行优化,模型优化器会对模型的拓扑结构进行优化,去掉不需要的层,对相同的运算进行融合、合并以加快运算效率,减少 内存拷贝;FP16,INT8也可以在保证精度损失很小的前提下减少模型体积,提高模型的性能。
- 开发简单。提供了C,C++和python 3种语言编程接口。
- 部署方便。在Intel的不同硬件平台上进行移植部署很便捷。推理引擎对不同的硬件提供统一的接口,底层实现直接调用硬件指令集的加速库,应用程序开发人员不需要关心底层的硬件实现,即可在不用的硬件平台上加速模型推理。
Openvino内部集成了Opencv、TensorFlow模块,除此之外它还具有强大的Plugin开发框架,允许开发者在Openvino之上对推理过程做优化。
Openvino整体框架为:Openvino前端→ Plugin中间层→ Backend后端
Openvino的优点在于它屏蔽了后端接口,提供了统一操作的前端API,开发者可以无需关心后端的实现,例如后端可以是TensorFlow、Keras、ARM-NN,通过Plugin提供给前端接口调用,也就意味着一套代码在Openvino之上可以运行在多个推理引擎之上,Openvino像是类似聚合一样的开发包。
2、阿里云
阿里云是阿里巴巴集团旗下的云计算服务提供商,成立于2009年,总部位于中国杭州。阿里云提供的云计算服务包括基础设施、数据库、存储、人工智能、大数据分析等方面的支持,帮助企业实现数字化转型和业务拓展。
阿里云拥有全球领先的云计算技术和服务能力,其自主研发的飞天操作系统和分布式架构技术已经达到了国际领先水平,阿里云还拥有全球最大的云计算数据中心之一,覆盖了全球多个国家和地区,致力于为用户提供更加稳定、高效、安全的云计算服务。 阿里云的成功应用场景包括多个领域,如金融、制造、医疗、零售等。其应用的案例包括国内多个大型银行、证券公司、保险公司等金融机构,以及诸多大型制造企业、零售连锁企业等。通过阿里云的云计算服务,这些企业实现了数字化转型和业务创新,提高了生产力和效率,也确保了数据安全和隐私保护。
阿里云的成功不仅得益于其卓越的技术和服务能力,还得益于其在中国及全球市场的领先地位和品牌影响力。阿里云已经成为亚太地区最大的云计算服务提供商之一,并在全球范围内拥有越来越多的用户和合作伙伴。未来,阿里云将继续致力于技术创新和业务拓展,为用户提供更加优质的云计算服务,帮助企业实现数字化转型和业务创新。
四、模型部署
我们可以选择阿里云平台或者利用 OpenVINO 来部署模型。
(一)首先介绍使用 OpenVINO 部署大语言模型
1. 在魔搭社区的 notebook 中打开终端,克隆 ChatGLM3 仓库并打开该文件:
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM32. pip 安装依赖:
pip install -r requirements.txt 3. git 下载本地模型
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git4. 修改变量路径:打开 chatglm3-6b 的 config.json 文件(右键选择 open with editor 进行修改),修改为 chatglm3-6b 文件的地址:

5. 克隆 OpenVINO GLM3 推理仓库并安装依赖:
git clone https://github.com/OpenVINO-dev-contest/chatglm3.openvino.git
cd chatglm3.openvino python3 -m venv openvino_env
source openvino_env/bin/activate
python3 -m pip install --upgrade pip
pip install wheel setuptools
pip install -r requirements.txt 6. 转换模型:
python3 convert.py --model_id THUDM/chatglm3-6b --output {your_path}/chatglm3-6b THUDM/chatglm3-6b为模型所在目录的绝对路径,{your_path}/chatglm3-6b 为转换后的模型保存的地址。例如: python3 convert.py --model_id /mnt/workspace/ChatGLM3/chatglm3-6b --output /mnt/workspace/ChatGLM3/chatglm3.openvino/chatglm3-6b
7. 运行模型:
python3 chat.py --model_path {your_path}/chatglm3-6b --max_sequence_length 4096 --
device CPU{your_path}/chatglm3-6b为转换后的模型目录的位置,例如: python3 chat.py --model_path /mnt/workspace/ChatGLM3/chatglm3.openvino/chatglm3-6b --max_sequence_length 4096 --device CPU
最后出现下面的内容则说明模型部署完成!
8、响应时间对比
未加速的模型需要1到2秒的时间才能够给出解答,在经过加速后,模型响应时间显著缩短,基本可以认为无停顿,人机交互的流畅度提高。
(二)使用阿里云平台
1、拉取仓库
git clone https://github.com/THUDM/ChatGLM3 2、进入目录
cd ChatGLM3 3、安装依赖
pip install -r requirements.txt4、下载本地模型
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git5、修改变量路径
chatglm3-6b的 config.json文件 改为 chatglm3-6b文件所在的位置
方便以后的微调,在 ChatGLM3文件下的 finetune_demo文件夹中新建了一个 THUDM文件夹,并将 chatglm3-6b放入了该文件夹下 ,需要将 ChatGLM3文件中 basic_demo文件夹下的 cli_demo.py文件中的 chatglm3-6b路径梗概
6、部署运行
在 ChatGLM3文件下打开一个终端运行模型,向模型提出问题可得到相应的回答。
python basic_demo/cli_demo.py 五、微调(在 finetune_demo文件夹下打开一个终端
1、安装依赖
pip install -r requirements.txt 2、加入数据集
在 finetune_demo下创建一个文件夹 data,为了方便最好在 data下再新建一个文件夹 AdvertiseGen用来存储数据集,将群文件 train.json和 dev.json下载并上传到 AdvertiseGen文件夹中(其中 train为训练集,dev为验证集)
格式如下
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"}, {"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿到夏天也很舒适。"}]} 第一个“content”后接关键词或问题,第二个“content”后接回答。
3、模型微调
python finetune_hf.py data/AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml在执行该语句时,遇到了以下报错。
是因为内存不足,可能是因为数据集比较大或者训练步数太多。
于是删减了数据集中的内容,并在finetune_demo中 config文件夹下 lora.yaml文件中调整参数
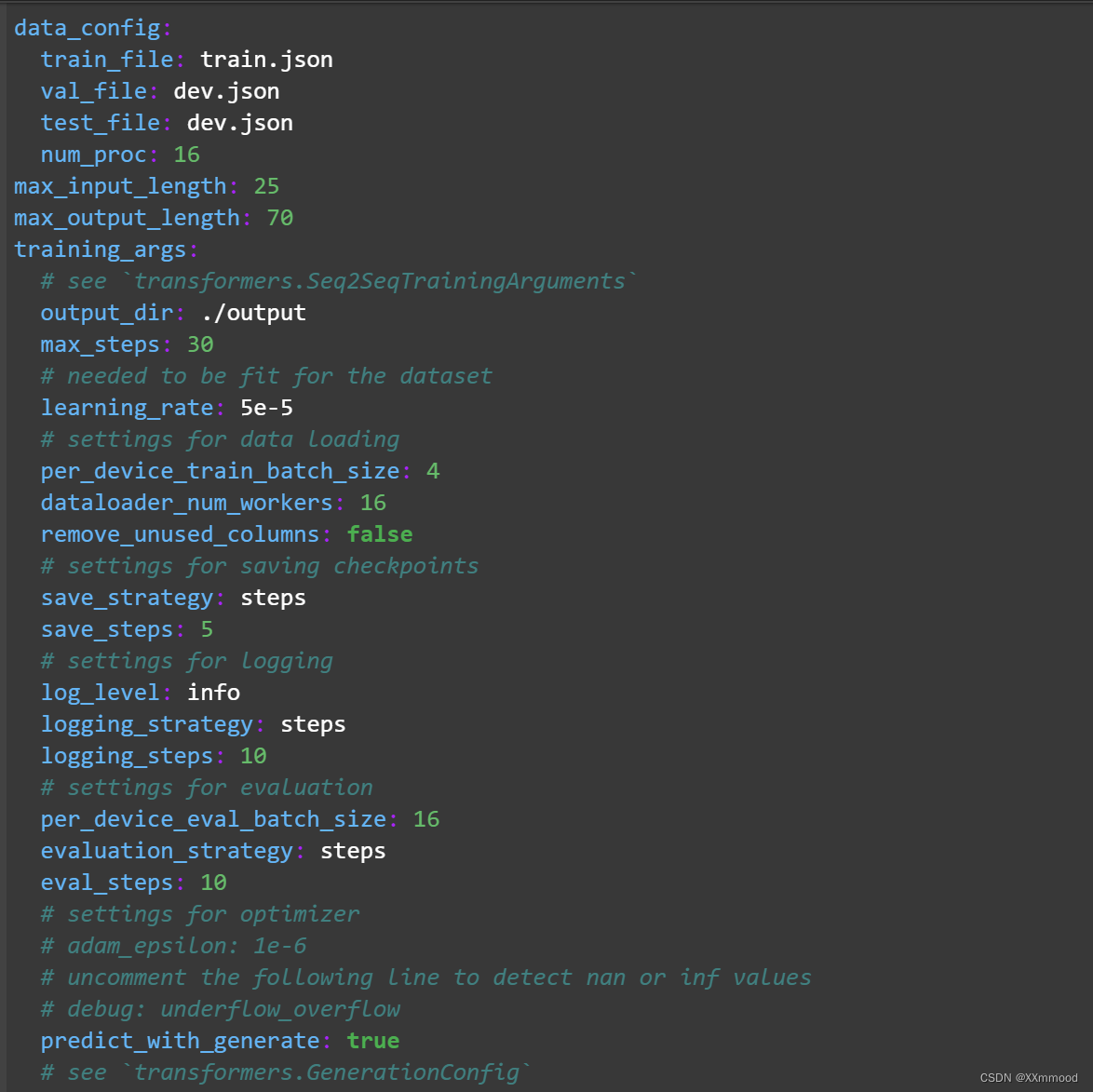
max_input_length: 256(最大输入字长)
max_output_length: 512(最大输出字长)
max_steps: 3000(训练步数)可以根据自己的数据集大小进行更改
save_steps: 500( 保存步数) 即每 500步保存一次,所以 3000步训练完后会保存 6次,也就是 output文件夹里有六个模型文件,我们要用到的是最后一次保存的模型文件地址。
output_dir: ./output(微调后的模型地址,在微调下程中会自动生成一个 output文件夹,里面保存微调后的模型文件)
上图中根据情况已经修改了前四个参数
max_input_length: 25
max_output_length: 70
max_steps: 30
save_steps: 5
根据实际情况进行修改
再执行语句就可出现下面界面
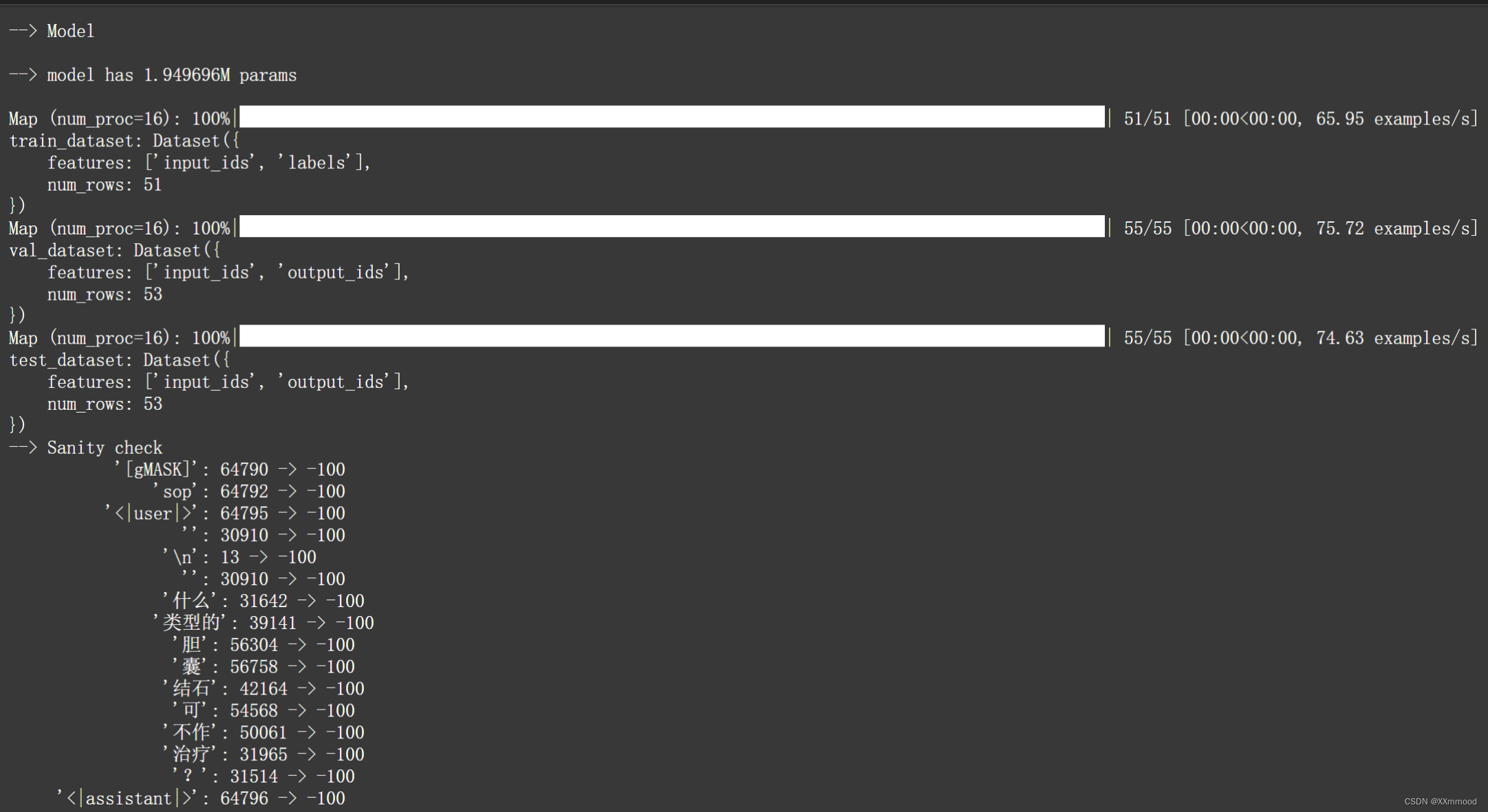

训练完后输入:
python inference_hf.py output/checkpoint-30/ --prompt 中医中的微热是指什么?python inference_hf.py 【your_finetune_path】 --prompt 【your prompt】
【】中分别为微调后的模型地址和问题

与ChatGLM3文件下打开一个终端运行模型的结果一致

微调成功,可根据需要继续微调。
六、设计交互界面
1、打开ChatGLM3文件夹下basic_demo文件夹中的web_demo_gradio.py,进行以下修改:
将第69行代码注释掉,增加第70、71行代码:
finetune_path= '/mnt/workspace/ChatGLM3/finetune_demo/output/checkpoint-30'
model, tokenizer = load_model_and_tokenizer(finetune_path)
其中红色部分为最后一次保存的微调模型文件的绝对路径
将checkpoint-30中的adapter_config.json文件作以下修改:
"base_model_name_or_path": "/mnt/workspace/ChatGLM3/finetune_demo/THUDM/chatglm3-6b",
2、修改最后一次保存的微调模型文件地址

3、运行web_demo_gradio.py文件:
cd ChatGLM3
python basic_demo/web_demo_gradio.py
运行结果:

4、点击链接(http:....)即可进入交互页面。

5、在如图第152行代码中替换大字标题,并适当调整其他参数。
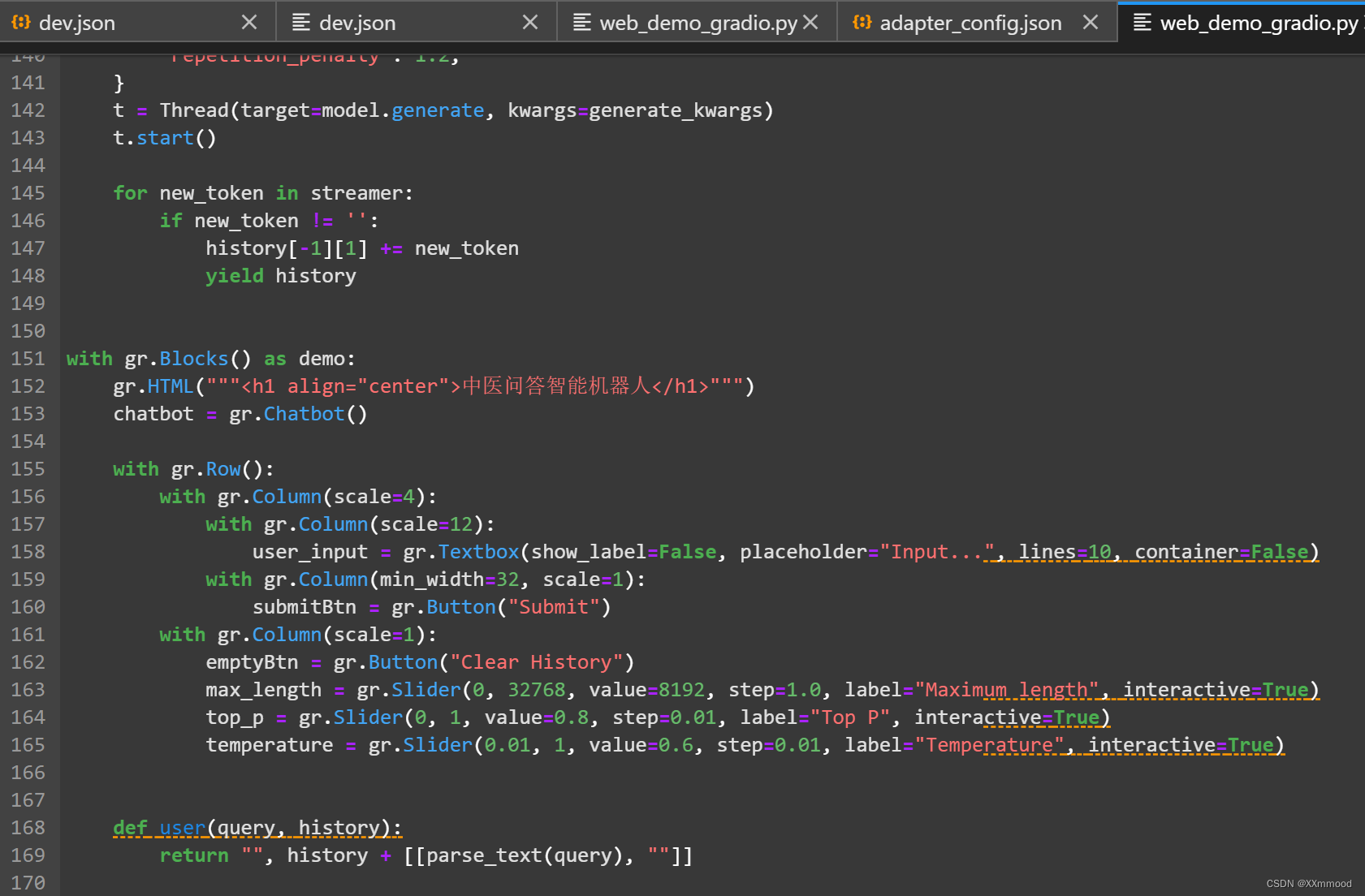
得到以下交互界面:

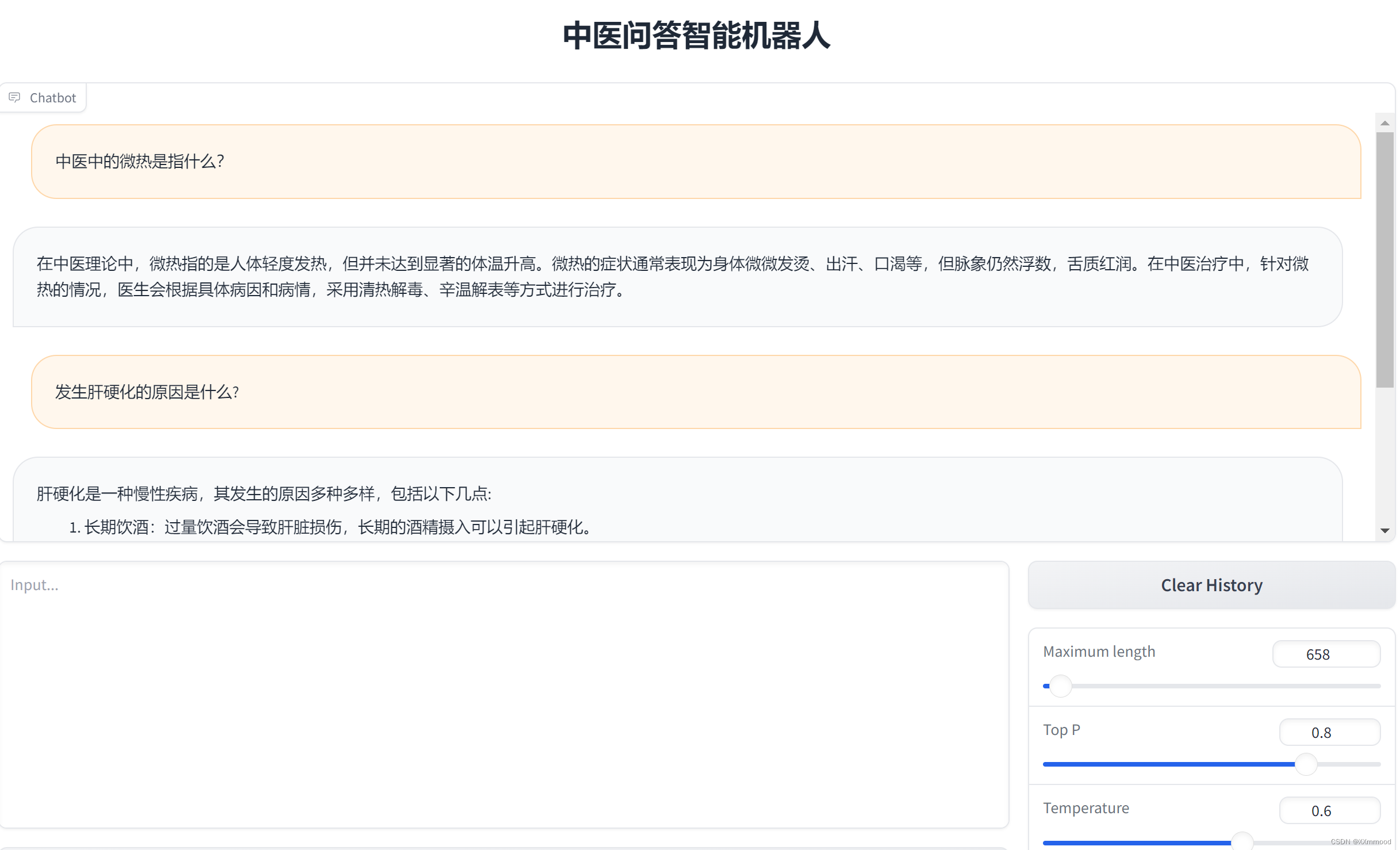
6、进行对话















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









