







 本文探讨了多类目标检测、人脸检测及行人检测的最新进展。介绍R-FCN+Resnet-101、PVANET等模型在提高速度与准确率方面的优势,并讨论了在人脸检测中使用hardnegativemining技术提升模型表现的方法。
本文探讨了多类目标检测、人脸检测及行人检测的最新进展。介绍R-FCN+Resnet-101、PVANET等模型在提高速度与准确率方面的优势,并讨论了在人脸检测中使用hardnegativemining技术提升模型表现的方法。
一、效果简介
1 多类目标检测,基于VOC2012数据集

MAC :The number of adds andmultiplications
mAP:Mean average precision
GPU:NVIDIA Titan X
我们目前的人脸检测模型是:Faster R-CNN + VGG_CNN_M_1024,即VGG-16的简化版。
注:PVANET+的MAC为十亿级别,即约37亿。
2 人脸检测,基于fddb数据集
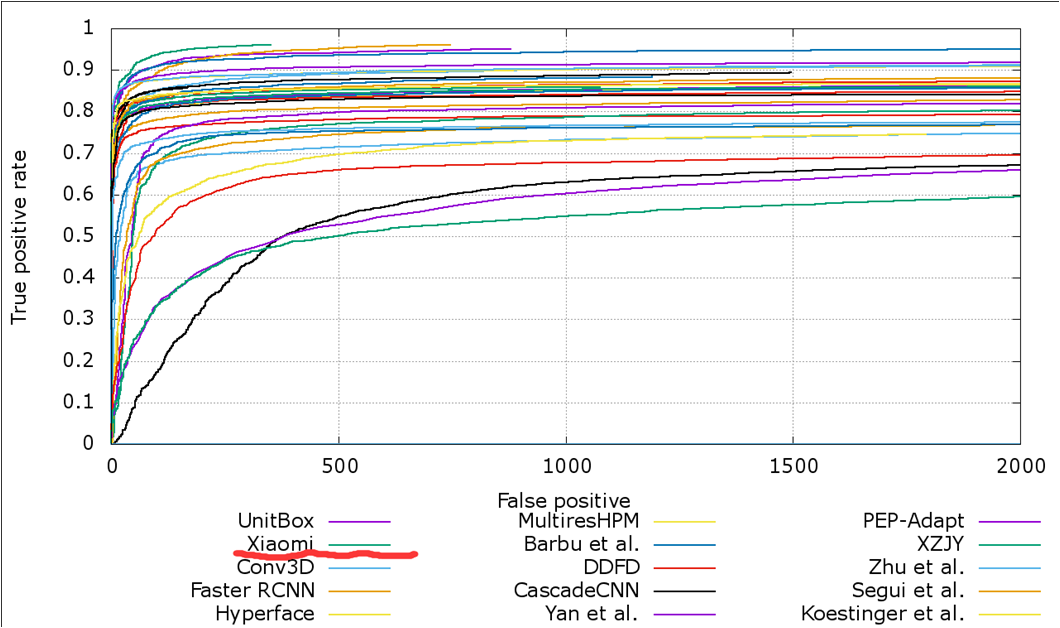
Xiaomi方法得分最高,Faster rcnn方法紧随其后。
3 行人检测,基于KITTI数据集
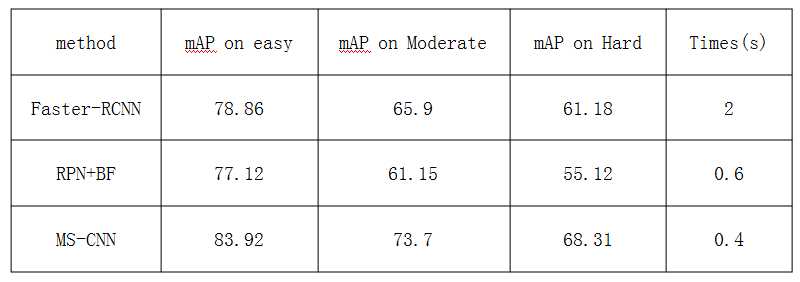
KITTI数据集:包含汽车、行人和骑自行车人三类目标,分为容易、适中和难三个难易程度。包含7481张训练验证图片(已标注),7518张测试图像(未标注) 。
二、文章思路分析
1 多类目标检测
(1) R-FCN +Resnet-101
原文:R-FCN: Object Detection via Region-based Fully Convolutional Networks
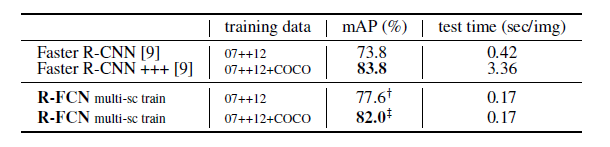
Faster R-CNN +++:即R-FCN + Resnet-101;速度快了2.5倍。
主要思路: R-FCN主要通过移除最后的全连接层进行加速,使得结构中所有可学习参数都是卷积,且可共享,并且用到了最新的residual network。
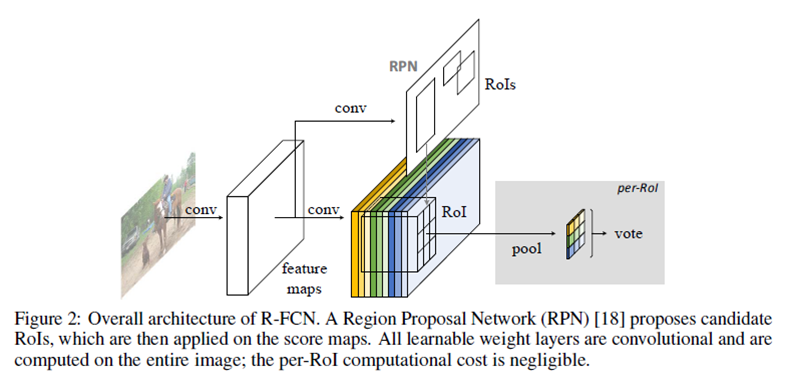
如上图,RPN用于生成候选窗口,ROI池化层用于计算目标窗口得分,通过设定阈值,最终可以将ROIs(region of interest)分成目标或背景。
(2) PVANET
原文:PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
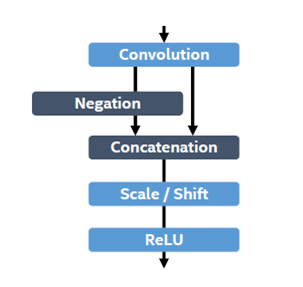
PVANET,即pva-faster-rcnn;计算成本降低了十倍,速度降至46ms。
核心部分:C.ReLU(concatenatedrelu)结构,在conv和ReLU中间添加Negation,concatenation,scale/shift部分,达到‘lesschannels with more layers’的目的,从而减少网络参数、降低计算量。
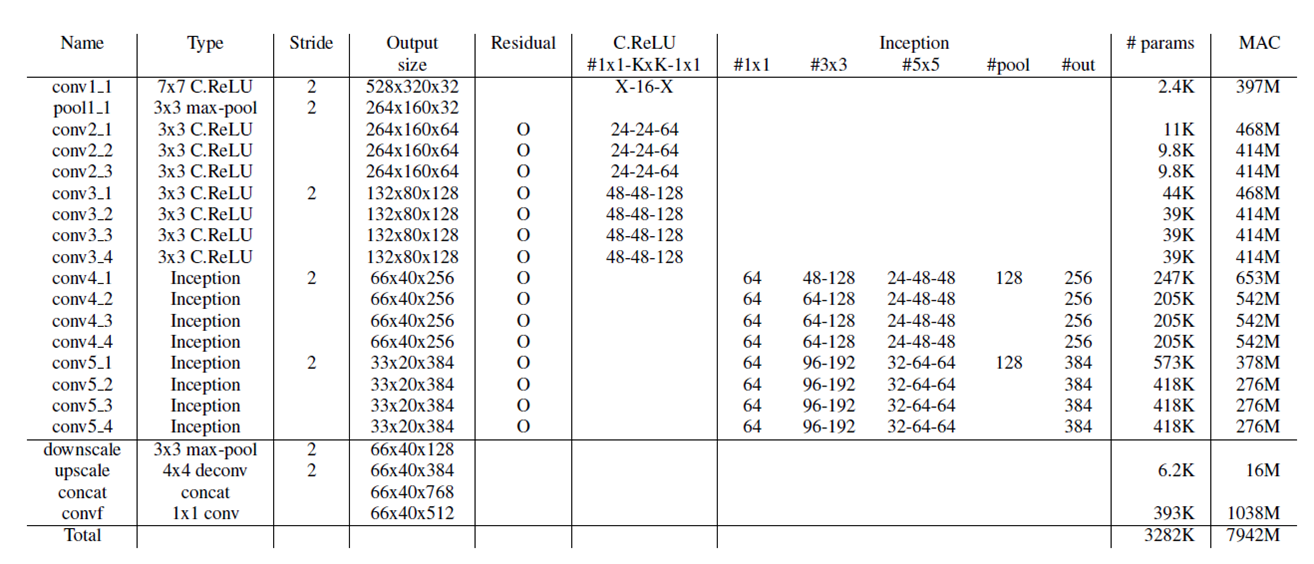
PVANET结构如上图所示,包含C.ReLU,Residual,inception等部分。Inception适用于不同尺寸,大小的接收域,并在接收域获得多尺度目标。在Inception层中增加Residual,解决较深网络的训练问题。
RPN部分生成25个chchors,对应5种尺寸(3,6,9,16,25),5种宽高比(0.5,0.667,1.0,1.5,2.0),可见包含尺度更加丰富。
2 人脸检测
(1) xiaomi
原文:Bootstrapping Face Detection with Hard Negative Examples
在faster-rcnn上做改进,运用较难检测的负样本,残差网络,目前FDDB得分最高。
主要思路:
1、hard negative mining:负样本挖掘技术,用初始训练的caffe模型,检测训练负样本(faster rcnn中负样本随机产生),得到难检测的负样本。将难负样本加入到训练集负样本中,重新训练,如此重复训练,直到caffe模型效果不再提高。
注意:训练时保持正负样本1:3,将难负样本加入重新训练时,保持正负样本1:3,但保证加入的难负样本在里面。
2、难负样本选择:当检测区域和任何一个人脸标注位置的maximunIOU(intersection over union,交并比)小于0.5时,认为是难负样本。
3 行人检测
(1) RPN+BF
原文:Is Faster R-CNN Doing Well for Pedestrian Detection?
主要思路:
1、解决输入到分类器中的特征图(小目标)分辨率不高问题:采用‘a trous’策略,将特征图放大,从而增加分辨率。

2、解决难负样本较难检测的问题:采用cascaded Boosted Forest(BF),训练分为6个阶段,每个阶段有不同个trees,开始训练正负样本相同,之后每个阶段不断添加难负样本(数量为正样本的10%)到训练集中。
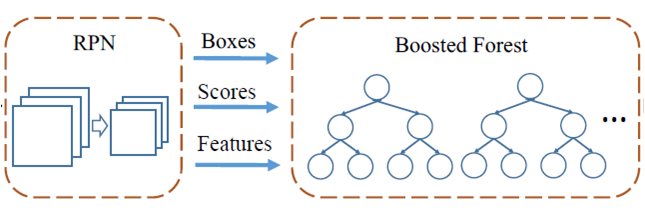
整体结构如上图,RPN(宽高比统一为0.4,9种尺度,在高40基础上不断扩大1.3倍)用于生成候选窗口,ROI池化层可以同时提取多个卷积层特征(conv3_3,conv4_3,conv5_3),并将这些特征级联;BoostedForest实现分类功能。
(1) MSCNN
原文: AUnified Multi-scale Deep Convolutional Neural Network for Fast ObjectDetection

主要解决问题:如上图,自然场景(黄色框)目标存在多种尺度大小,所以单一的RPNanchors(阴影部分)无法完满匹配目标。
主要思路:
1、网络结构中,在较浅层检测小目标,在较深层检测大目标,最后检测器联合,形成多尺度检测器。
2、用反卷积层实现特征图上采样代替输入图片上采样,提高了特征图分辨率,可以较好地检测小目标,同时减少了计算。
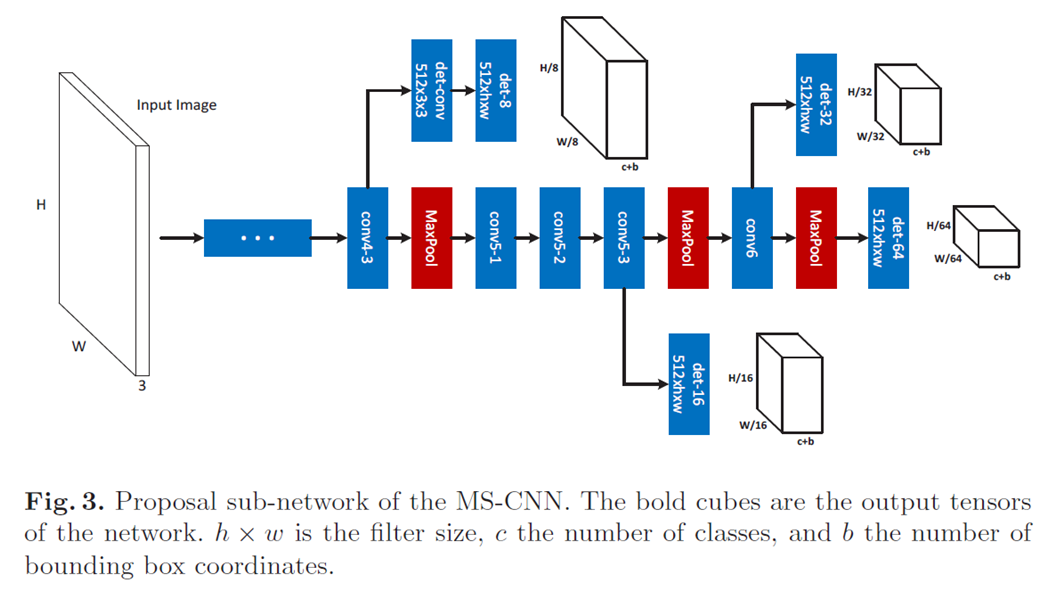
整体结构包括:proposal子网络+ detection子网络。
proposal子网络如上图所示。
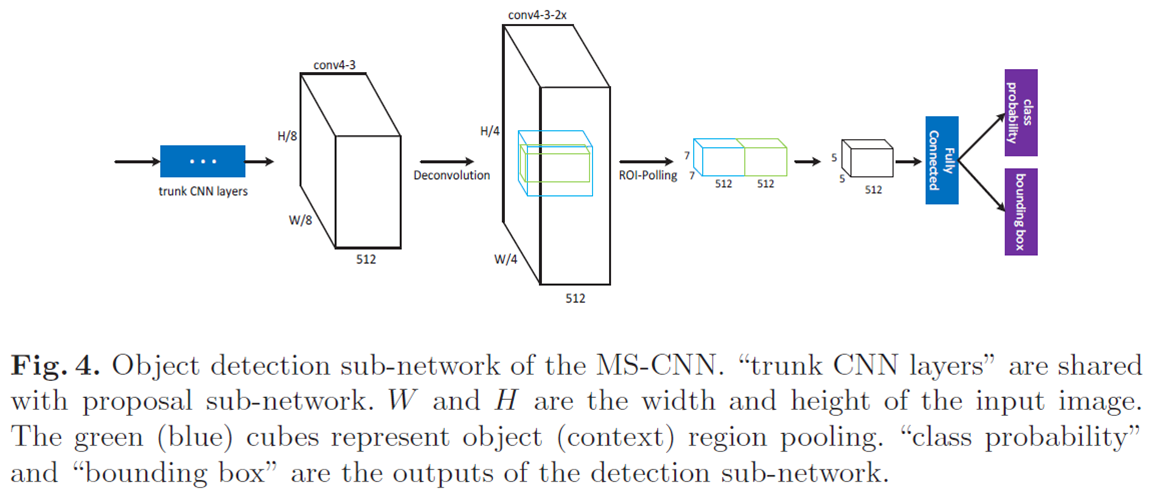
proposal子网络如上图所示。
三、研究结论及意义
结论:
1、proposal与目标尺寸不匹配问题:(1)更改RPN尺寸,宽高比,以适应自然场景;(2)在神经网络中采取分层(深层,浅层)检测策略,最后级联检测器,形成多尺度检测器。
2、检测小目标难的问题:将特征图放大,提高分辨率,如a trous’、反卷积策略。
3、加速:(1)移除最后的全连接层,实现更多计算资源共享;(2)减少特征图channels数量,以减少参数个数,从而减少计算量。
4、提高准确率:(1) hard negative mining;(2)使用更深的网络,如residualnetwork。
意义:
针对**环境下人脸检测改进策略的思考:
1、将RPN宽高比统一为1:1,9种尺度,在高40基础上不断扩大1.3倍;
2、采取hard negative mining策略+ residual network ;
3、用PVANET网络重新训练。















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









