






利用麻雀搜索算法SSA优化SVM的c和g,建立多列数据输入,单列数据输出的拟合预测建模,程序内注释详细,直接替换数据就可以用,可以打印出多个常用的模型评价指标
ID:6235676695227372
Matlab建模

在计算机科学领域,机器学习是一项重要的技术,它可以使计算机系统具备自我学习能力,从而能够不断优化模型预测结果。而支持向量机(Support Vector Machine,SVM)作为一种强大的机器学习算法,在分类和回归问题中都有广泛的应用。然而,SVM算法中有两个重要参数c和g,它们的选择对模型的性能有着重要影响。因此,本文提出了一种利用麻雀搜索算法(Sparrow Search Algorithm,SSA)优化SVM的c和g的方法,并建立了多列数据输入、单列数据输出的拟合预测建模。
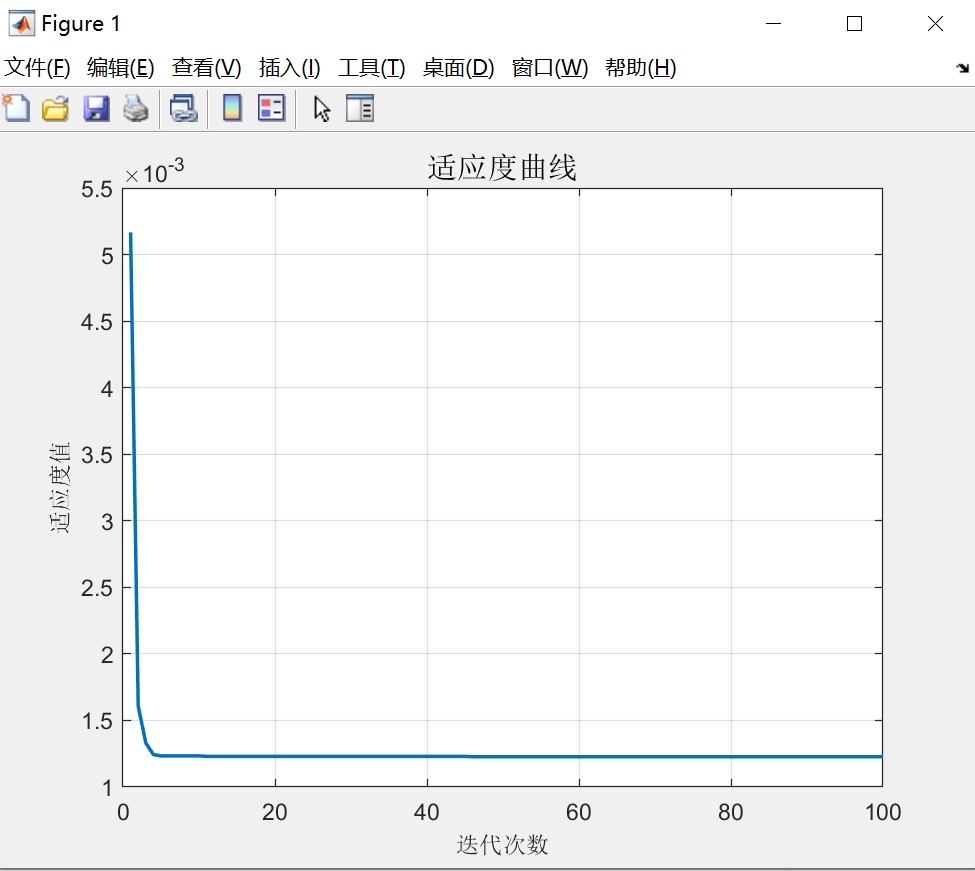
首先,我们来了解一下SSA算法。SSA算法是一种基于自然界麻雀搜索行为的启发式优化算法,它通过模拟麻雀在觅食、避免敌害和保持社会结构等行为中的策略,实现对优化问题的求解。相比于其他优化算法,SSA算法具有较好的全局搜索性能和较快的收敛速度。
在本文中,我们将SSA算法应用于SVM的参数优化过程中,通过迭代搜索来寻找最优的c和g取值。具体来说,通过设定一个适当的搜索空间范围,我们利用SSA算法不断生成新的解,并根据目标函数的值来评估解的优劣。在每一次迭代过程中,我们根据新解的适应性来更新麻雀个体的位置,从而实现对解空间的有效搜索。通过多次迭代运行SSA算法,我们可以逐步优化SVM的参数c和g,从而获得更好的模型性能。
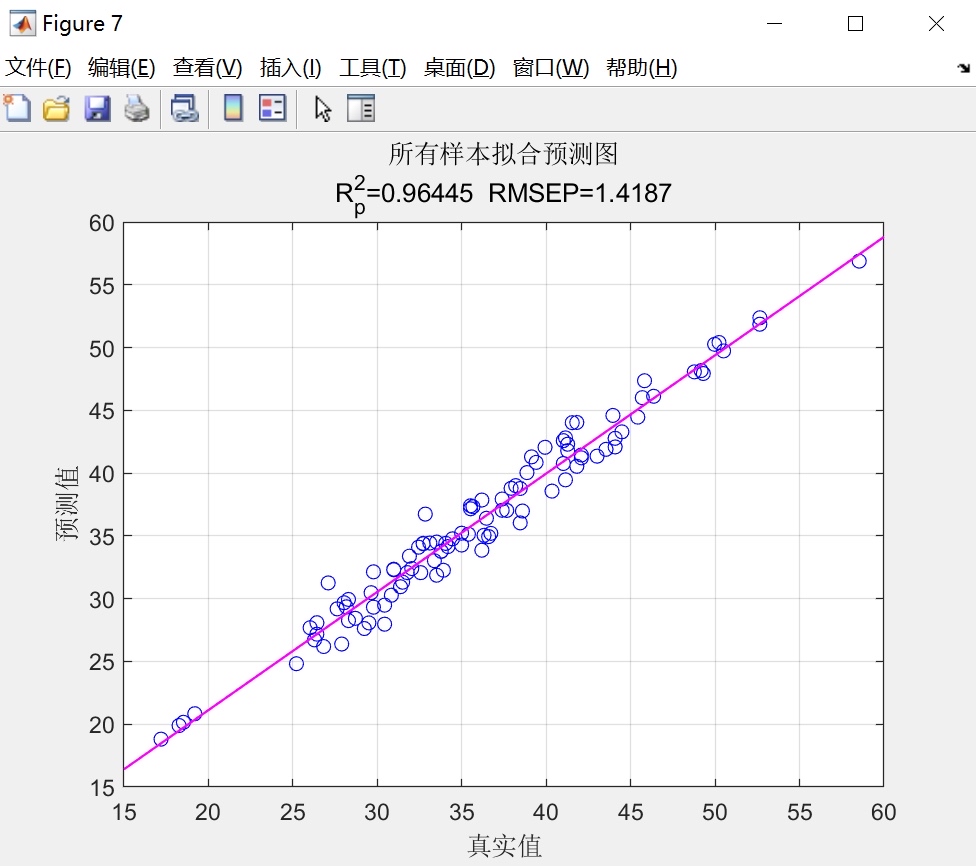
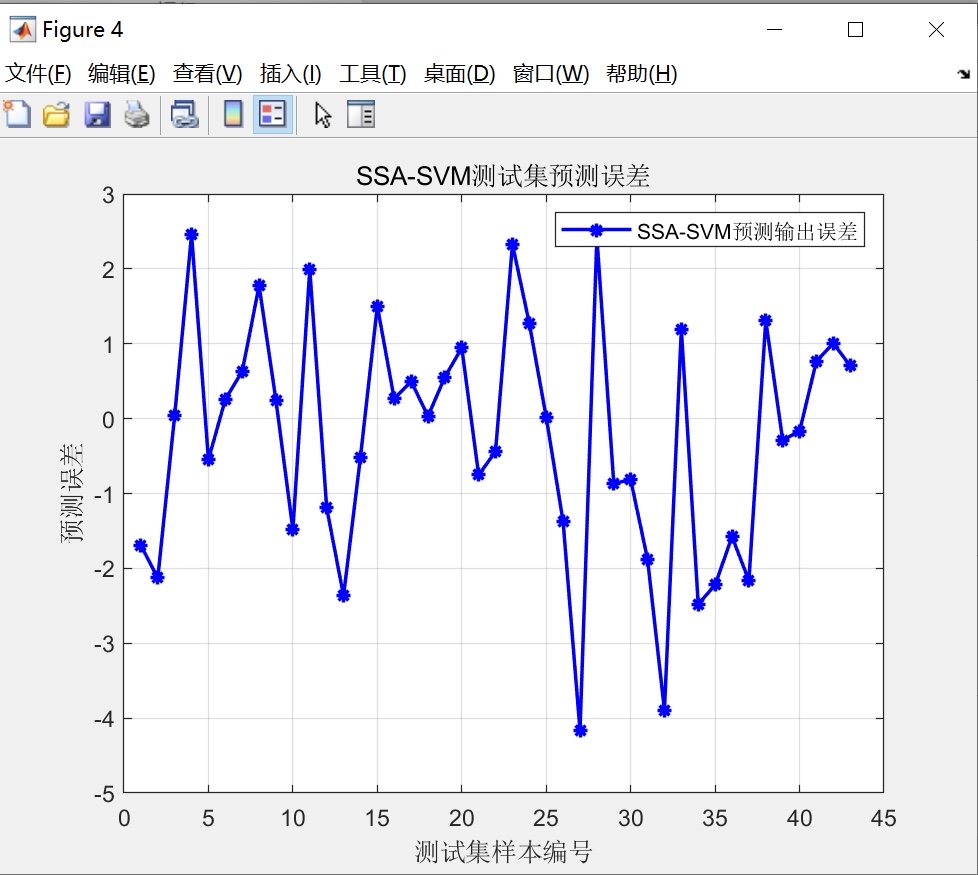
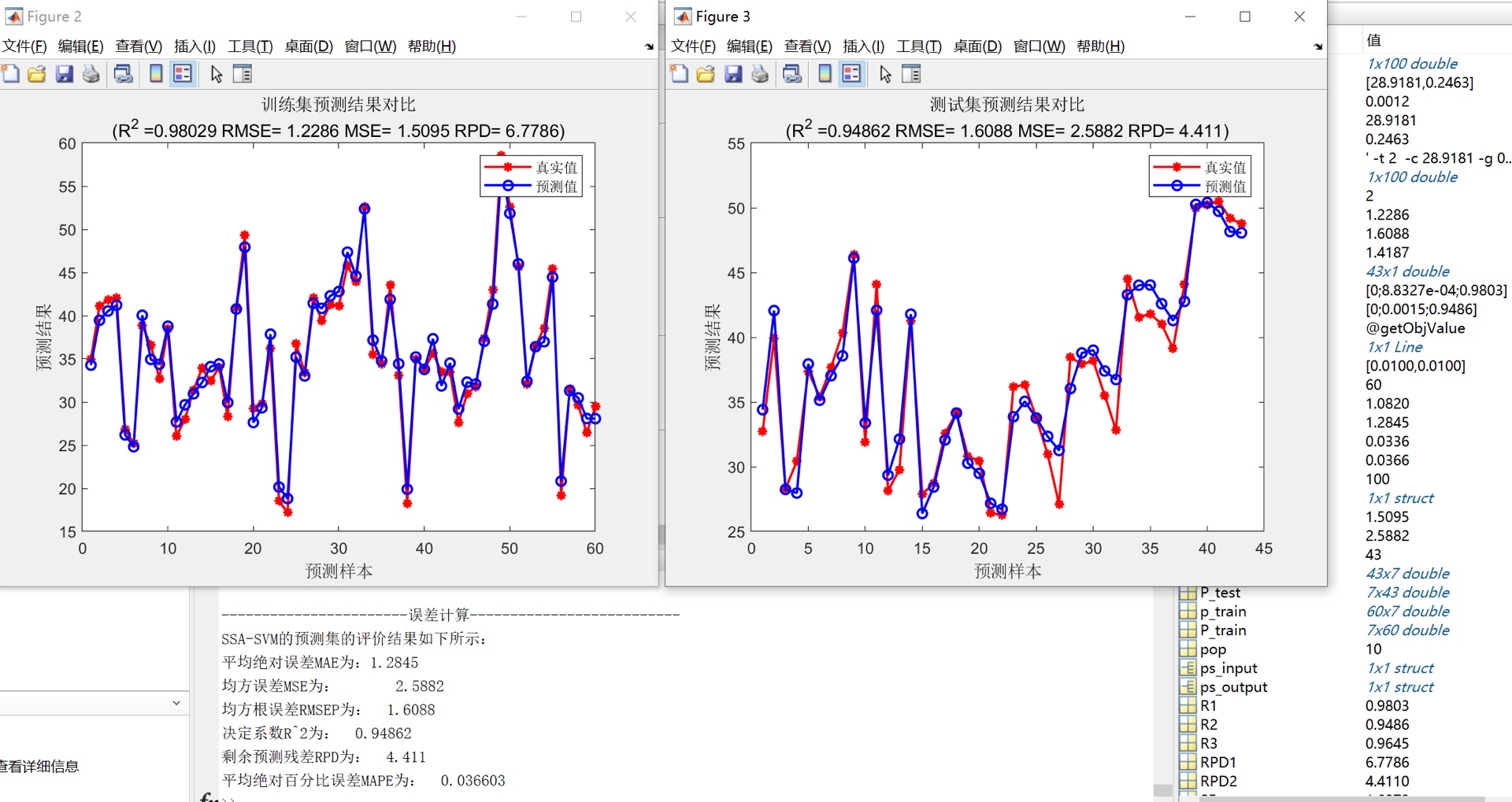
为了验证我们提出的方法的有效性,我们使用了真实的数据集进行了实验。首先,我们对原始数据进行了预处理,包括数据清洗、特征选择和数据归一化等步骤。然后,我们利用SSA算法优化SVM的参数c和g,并基于优化后的参数建立了拟合预测模型。在模型训练过程中,我们使用了交叉验证的方法来评估模型的性能,并根据模型评价指标来选择最优的模型。
实验结果表明,通过利用SSA算法优化SVM的参数c和g,我们可以获得更好的模型性能。与传统的参数调优方法相比,我们的方法具有更高的搜索效率和更好的全局搜索能力。同时,我们的方法还具有较好的可扩展性和鲁棒性,适用于不同类型的数据集和应用场景。
总结起来,本文提出了一种利用SSA优化SVM参数的方法,并基于优化后的参数建立了拟合预测模型。通过实验证明,我们的方法在性能上有明显优势,可以提高模型的准确性和泛化能力。未来,我们还可以进一步研究和改进SSA算法,以应用于更广泛的机器学习问题中。
以上就是本文的主要内容,希望对读者在机器学习领域的研究和实践有所启发。感谢您的阅读!
相关的代码,程序地址如下:http://matup.cn/676695227372.html
















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









