






前序:
在介绍最大熵之前,我们先要提一下逻辑回归,严格意义上将,最大熵并不是一个模型,而是一个处理问题时的一种手段。逻辑回归其实就理解为一个带sigmoid激活函数的方法就可,常用在二分类问题中;说白了就是把数据映射到(0,1)范围内。具体公式如下:

其实逻辑回归是一个标准的判别式模型,给定输入x,然后计算出属于类别1和0概率,比较数值大小,最后得到最后所属类别!标准的sigmoid公式为下面表示,只是逻辑回归在分子分母同时乘以了
优化方式:
既然有了判定二分类的方法,那我们要做的就是确定该条件概率中的参数w和b的具体取值情况,然后再来新的数据时,直接计算->得出结果;我们的训练数据是(x,y)的集合,显然我们直接极大似然估计就可以确定参数取值。也就是让训练数据的出现的概率最大化!!!下面我们来点具体的推导过程:
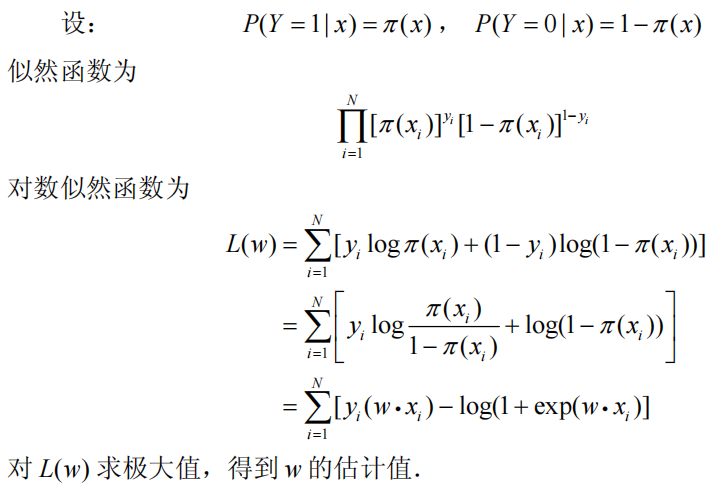
其中为上述的P(Y=1|x)
咳咳~逻辑回归介绍完了,跟最大熵模型有什么关系呢?实际上,在进行二分类时,所满足条件的概率模型(逻辑回归)有很多个,但是最大熵模型认为,熵最大的概率模型为最优的模型。我们知道熵是描述不确定性的量,因此最大熵认为在满足约束条件的情况下,其它模型中熵最大,也就意味着不确定性越大(超链接我们之前有介绍熵的概念);显然当我们在没有任何其它假设,把其它发生情况设置为等可能概率发生,这是非常合理的!可能这个时候有童鞋跳出来说:那为啥用熵来描述呢?其实呢,等可能这件事不好量化,我们总不能每次都手动均分其它情况吧,而熵正好是一个满足该特性可优化的数值指标,当熵达到最大就越平均。
举个简单的小栗子李姐一下:

重点留意最后一句话,“等概率表示了对事实的无知,因为没有更多的信息,这种判断是合理的”,换言之,这种假设是最合理的,那么得到的最大熵模型也一样很核理咯!
上面都是感性化的描述,接下来进行形式化的推导,上一上强度对抗;我们目前已经了解最大熵模型是处理分类问题的判别模型(很多模型都可以熵最大,这里专门指代分类问题),然后所有的判别模型里熵要最大并且要满足既定事实(约束条件);判别模型意味着我们需要建模P(Y|X)。我先把总体的优化目标放这里:

可能看到这个公式,熟悉的童鞋可能既面熟又来气呀,毕竟几乎所有的讲解都是把这晦涩公式列出来,然后复制一段最大熵的概念,告诉你这就是最大熵;往往公式上还带着不知名出处的水印。没关系沉住气,接下来我们一段一段的来说:
(1)判别模型里熵要最大:
对于熵的概念,之前的文章我们有说过,直接列出它的公式,既然这里我们是判别模型,意味着求P(Y|X)的熵,准确的说,我们要求这个条件熵,下面我们试着推一推:
根据上面的推导,我们得到了条件熵,而让这个熵最大,自然是求解来最大化熵值,即
(2)满足既定事实(约束条件):
何为既定事实呢?看看我们手头存在的事物吧,不就是那一堆堆训练数据嘛,这就是既定事实,可是我们应该怎么定量的描述这些数据呢?就用到了两个概率分布。
(1)联合分布P(X,Y)
(2)边缘分布P(X)

下一个要解决的问题就是,既定事实有了,怎么引入到优化目标中作为约束条件呢?我们前面说了,最大熵是在满足特定约束条件下,熵最大的模型。举个简单的小例子来说:

P(A)+ P(B)=3/10表示随机变量两个取值所应满足的条件,在最大熵这里,通过引入特征函数来表示变量之间满足的某种关系,具体说来:

当有了特征函数和经验分布之后,将二者引入到约束条件比较直接的方式就是对特征函数在经验分布上求期望,这时候看官们可能很迷惑,书上或者其它博客讲解都是直接列出两个不同概率分布对特征函数的期望相同(图一);然后告诉你这就是约束条件--->然后完了。读者后续要做的可能就是一波强行记忆了,有点狗血~接下来我们就聊聊这一块的盲区,强行解释一波,以自洽的方式初步了解,不至于让读者对某个点钻牛角尖,我个人认为有时候,在学习的过程中不是我们想要钻牛角尖,而是有些资料确实没讲明白!好了,废话不多说,继续正文。我们知道即使我们手头的训练数据再多,其实都是真实理论数据下的子集而已,因此我们的训练数据只是慢慢接近于真实数据集,而不等同。来来来,还得上个栗子:抛一枚硬币,对于上帝视角,我们知道正面和反面向上的概率为0.5;可是对于我们真实的实验,往往达不到这个效果,可能正面0.49/反面0.51;此时,我们称0.5/0.5为真实概率分布,0.49/0.51为经验概率分布。然后,最大熵说了,要满足既定事实下的约束呀!因此我们希望在经验概率分布下的特征函数总体取值【特征函数是0或者1,然后我们的数据对特征函数的拟合程度,会计算出一个常数】和真实概率分布下的特征函数取值应该相同,可是事实上,我们无法做到面面俱到,点对点的成立这种情况,但是随着数据的增多,我们可以做到的是让两个概率分布取值,在平均意义上取值去接近,因此很自然的引入了期望。说到这里,是不是有一点点敞开心扉的感觉!经验分布的期望,很自然就是图1所述了,真实分布的期望也应该对真实分布P(X,Y)求期望;我们知道,P(X,Y)=P(X)P(Y|X),其中P(X)可以用经验分布近似代替(图2),P(Y|X)是我们要求解的目标对象。至此该约束就描述完毕。
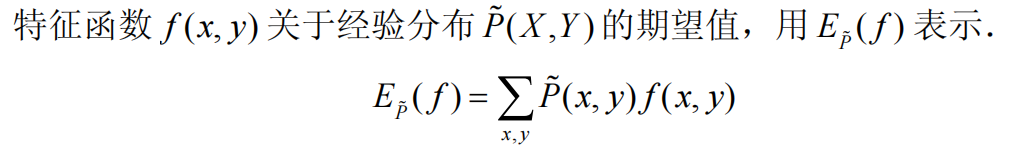
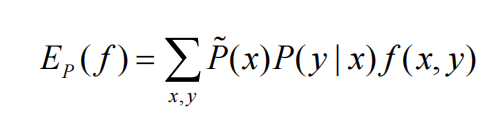
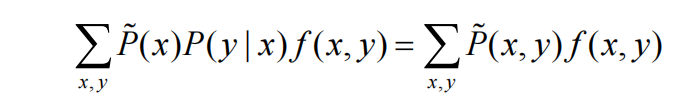
经过上述的分析,我们已经把最大熵的关键点说完了,接下来,我们具体对优化目标进行推导和求解,体验感受一下,这样优化下来,最后得到的最大熵判别模型长什么样呢?

根据上述的描述及公式,我们最终要求解的目标是;在给定6.15-6.16两个约束条件下,求最优的P(y|x)使得6.14的值最小(熵最大)。既然是带约束的最优值问题,直接无脑一波拉格朗日乘子法,将约束条件引入到最优目标函数中(回忆下高数的内容,带约束条件的多项式极值问题),可得下式:
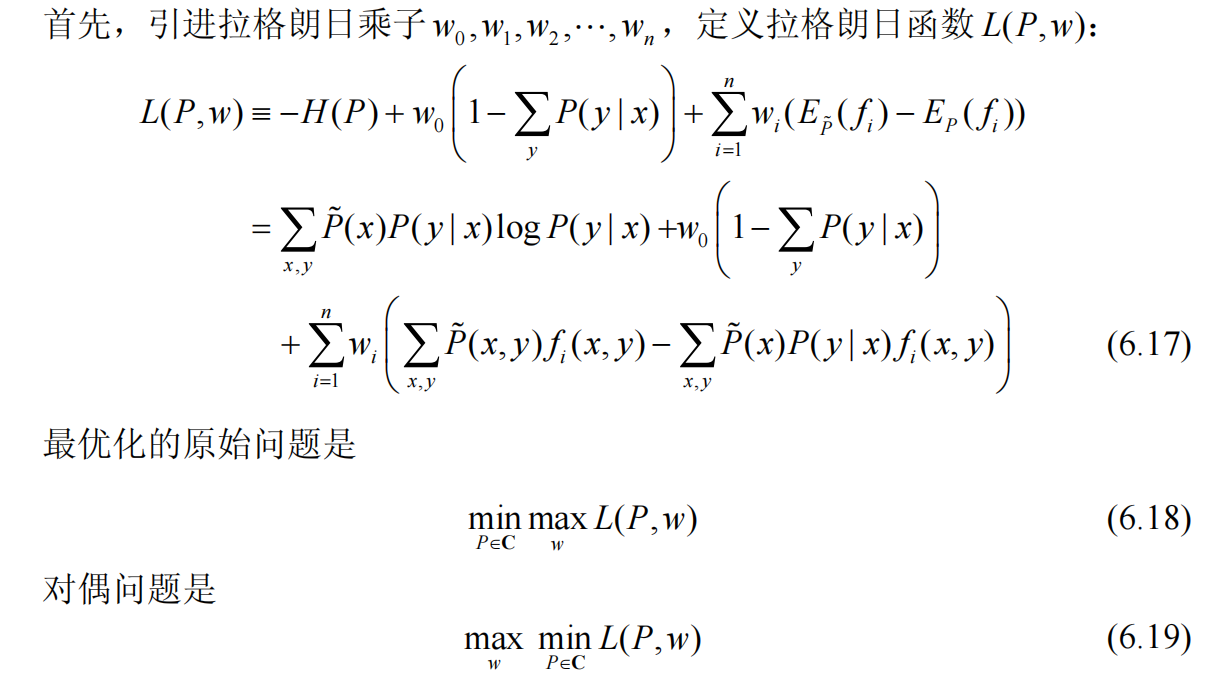
我们可以看到6.19,先对L(P,w)在P上求最小值,再在w上求最大值,对于求minL(P,w),那自然直接对P求偏导数来求解:
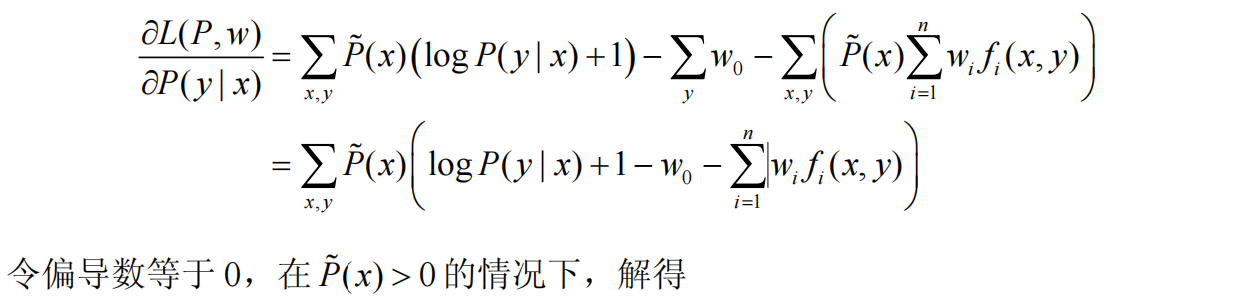

根据上面的推导过程其实并不难理解,我们直接关注6.22,整个就是我们最终求得的最大熵判别模型,只不过只是架起的框架,至于特征函数f的权重向量w,需要进一步的确定【直接把计算的P(y|x)回代公式,对每个w在求偏导数就ok】,我们知道一个判别模型的特征函数集合,可能有很多;其中w表示了不同特征函数在判别过程中的重要程度;从宏观上来看最大熵模型就是特征函数的线性组合的比值,至于判别结果如何,需要根据所有类别y相关的计算结果比较来进行判定。咦~是不是有点熟悉感了,还记得我们上文的伏笔嘛,这不就是和逻辑回归的目标一致嘛,实质上比较的是不同类别计算结果的大小比值来进行决策!
下面我们来个小栗子巩固一哈,压压惊:
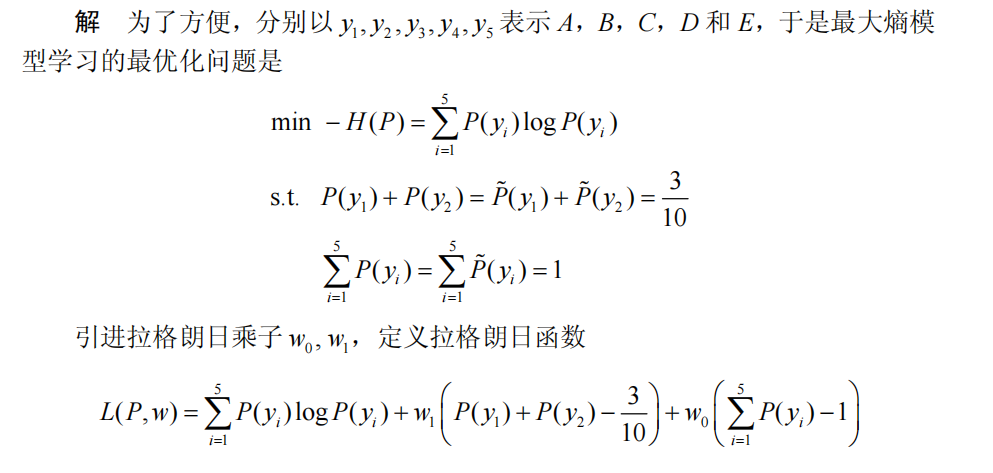


综上,我们对最大熵模型的介绍就到这里了,每一道开胃小菜都需要我们去慢慢品尝!
















 3718
3718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











