







接上一篇对话系统介绍和基础神经网络模型(一)
2.2.2、长短期记忆网络(LSTM)
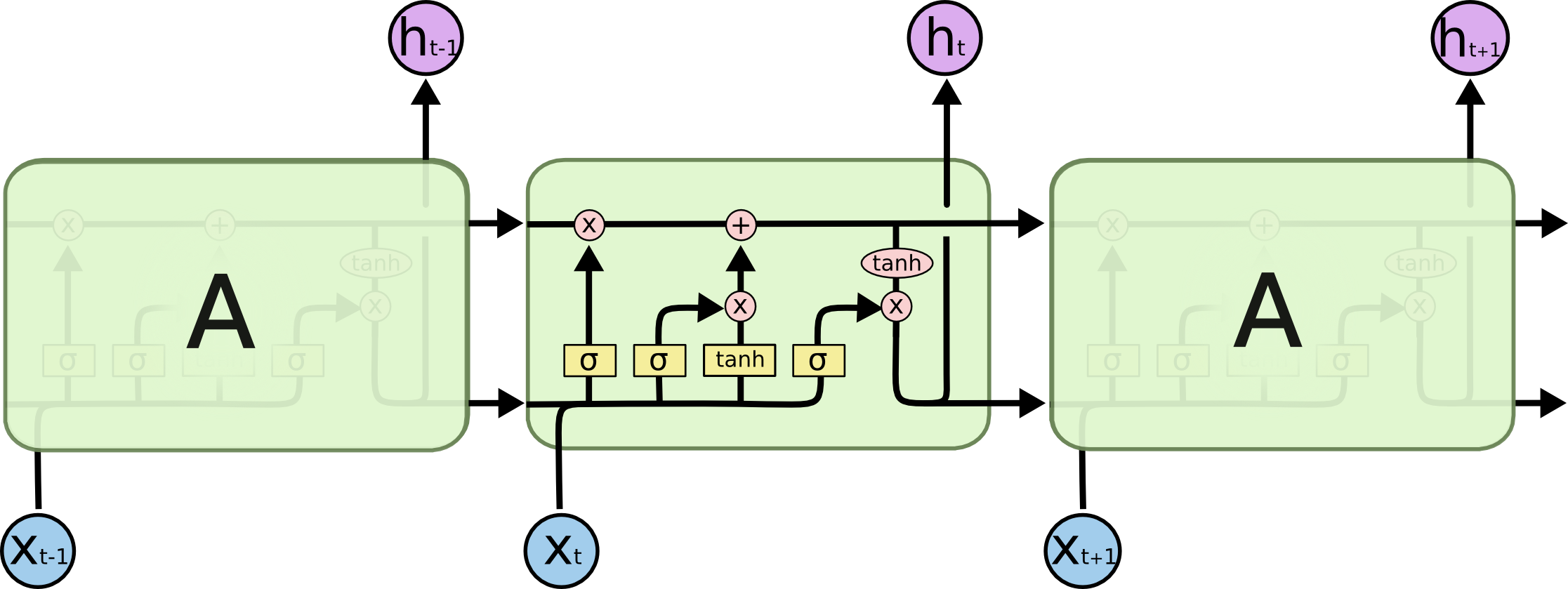
LSTM(如图2-3)通过引入门机制来解决梯度消失问题,输入门、遗忘门、输出门被用来决定从当前输入和过去的记忆中应该保留多少信息。模型可以用以下方程来描述:
其中t表示时间步长;i,f,o为门,分别表示输入门、输出门。x,h,C分别表示输入,长时记忆和短时记忆。“长短时记忆”一词的直观含义是,提出的模型同时应用长短时记忆向量对序列数据进行编码,并使用门机制控制信息流。
2.2.3、门控循环单元(GRU)
受门控机制的启发,GRU用更少数量的门来完成长期记忆的学习,模型可以用以下方程来描述:
LSTM和GRU作为两种门控机制,彼此非常相似。它们之间最突出的共同点时,从时间步t到时间步t+1,引入了一个相加成分来更新状态,而简单的RNN逐渐取代过去激活状态。LSTM和GRU都保留了一些旧的成分,并将其于新的内容混合。这个性质使记忆单元可以记住更远的历史步信息,更重要的是,避免了反向传播时的梯度消失问题。
2.2.4、分层循环编码器-解码器模型(HRED)
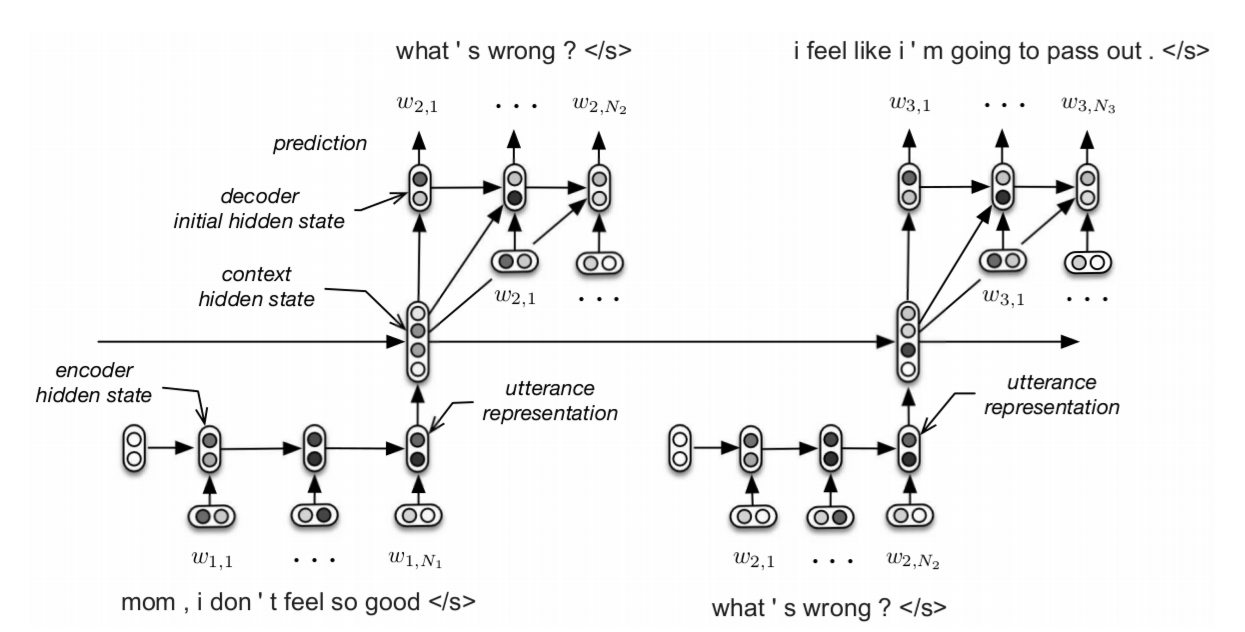
分层循环编码器-解码器(HRED)是一种上下文感知的序列到序列模型,在对话和端到端问题回答方面取得了显著的进步。传统的对话系统基于单回合消息来生成回复,牺牲了对话历史中的信息。HRED既学习了符号级表征,也学习了回合级表征,从而显示发掘潜在对话的情境感知。图2-4展示了HRED使用两级RNN对符号级表征和轮次级表征的建模过程;其中一个RNN用来编码轮次级别的序列信息,然后再将每个轮次级别序列信息传入另一个负责编码上下文信息的RNN。因此,上下文信息的RNN可以迭代的追溯历史的句子信息。第t回合上下文信息的RNN隐藏状态代表了从第t回合开始的所有语句的汇总,用于初始化RNN解码器的第一个隐藏状态。上述三种RNN均采用GRU单元作为循环单元,对每个句子都共享编码器和解码器的参数。
2.3、Attention and Transformer
由前面介绍的内容,传统的端到端的模型通过当前的隐藏层状态和最后一个时间步的输出向量作为条件来解码出响应的字符,公式描述为:
2.3.1、Attention
随着注意力机制在机器翻译任务中的应用,在解码阶段,每个解码状态都会考虑此时与编码后的源句子哪些部分是相关的,而不是只依赖于源句子最后时刻编码的隐藏层状态。公式描述为:
其中i表示时间步,是当前时间步的输出字符,
是当前时间步解码器的隐藏状态,
是加权计算的源句子:
是解码器第i-1个隐藏状态和编码器第j个隐藏状态的相似度分数,其中分数由相似度模型
预测:
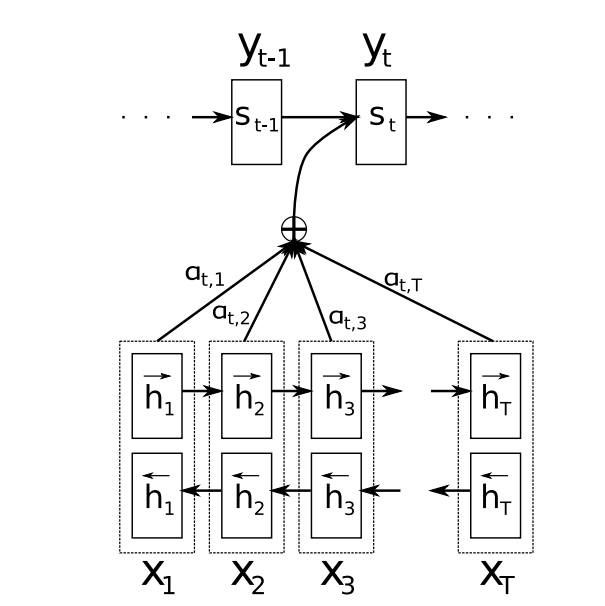
图2-5展示了注意力机制的计算图例,其中t和T分别表示了解码端和编码端的时间步:
2.3.2、Transformer
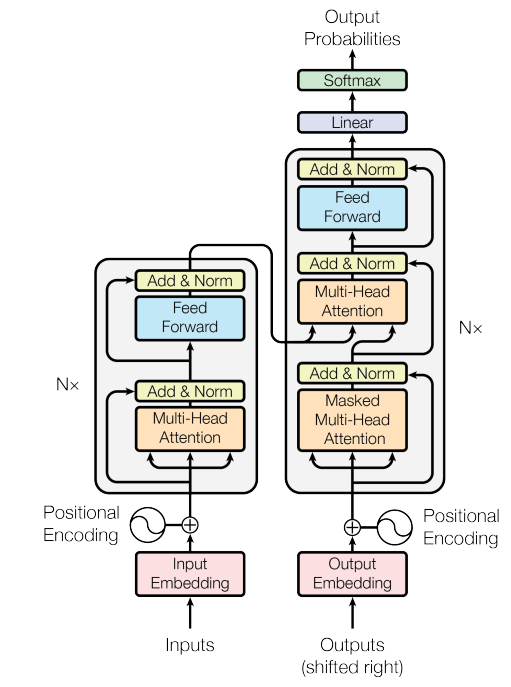
在Transformer引入之前,大多数的模型方法主要将注意力机制和循环单元相结合。然而由于递归模型的连贯性,它们不能并行训练,这严重破坏了它们的潜力。因此Transformer完全利用没有任何循环单元的注意力机制,并部署了更多的并行化来加快训练。它应用自注意力机制和编码端-解码端模型注意力分别实现局部依赖和全局依赖。图2-6展示了Transformer具体架构。
(1) Encoder-decoder
Transformer由一个编码端和一个解码端组成,编码端负责把输入句子映射为对应的隐藏状态表示
。解码端基于编码后的序列进一步生成输出序列
。Transformer由6个相同的编码端和6个相同的解码端堆叠而成,其中编码层由多头注意力机制模块、前馈神经网络、归一化层和残差机制组成;解码层的结构和编码层几乎无异;除了多出一个Encoder-Decoder 注意力层,这一层负责计算当前时间步解码端的隐藏层状态和编码端的输出表示。解码端的输入需要部分掩码操作来保证每次字符的预测都基于先前的字符,从而避免未来序列信息的泄露。值得注意的是,编码端和解码端的输入都需要额外的使用位置编码机制来获得序列之间的位置信息。
(2) Self-attention
面对一个输入序列,每个字符
对应三个向量:查询向量、键向量和值向量。self-attention通过使用
的查询向量来分别和其它字符的键向量计算注意力权重。为了并行计算,所有字符的查询向量、键向量和值向量被分别组成三个矩阵:Q(查询)、K(键)、V(值)。输入句子
的自注意力由以下公式计算:
其中是查询向量或键向量的维度。
(3) Multi-head attention
多头注意力机制联合考虑来自嵌入向量、查询向量、键向量、值向量中不同子空间的信息,通过不同的线性变换将其映射h个形状相同的向量,h标记了head的个数。每个head的注意力向量并行计算,最后顺序拼接起来并完成线性映射。公式描述为:
(4) Positional encoding
由于Transformer架构没有循环单元,这意味着序列的顺序信息将被忽略。而在NLP任务中文本的顺序信息是极其重要的,如果模型缺乏位置信息,“张三打了李四”和“李四打了张三”将是内容含义完全相同的句子,事实上,这是严重不合理的表示。因此Transformer通过引入位置编码来向输入向量中引入位置信息;具体引入余弦函数进行位置编码:
其中pos表示了字符所处的位置,i表示了向量的维度位置。
2.3.3、Attention与对话系统
注意力机制用来发掘目标句子中不同位置的关键信息,是实际应用中,可以使用两级注意力来生成单词。给定对话检索系统选择的用户消息和候选回复,生成器首先单词级别的注意力权重,然后使用句子级别的注意力重新调整权重;这两种级别的注意力帮助生成器在给定编码上下文的情况下捕捉不同的重要性。
2.3.4、Transformer与对话系统
Transformer是一种强大的序列到序列模型,同时,其编码器也是一种良好的对话表示模型。它可以为面向任务的对话系统建立一个基于Transformer的响应检索模型。通过设计一个双通道Transformer编码器,用于对用户信息和响应进行编码,然后应用一个简单的余弦距离来计算用户消息和候选响应之间的语义相似度。还可以构建多个增量Transformer编码器,对多回合对话及其相关文档知识进行编码。前一回合的编码语句和相关文档被视为下一回合Transformer编码器输入的一部分。
2.3.5、基于Transformer的预训练语言模型与对话系统
基于Transformerd的预训练语言模型由于对多种任务的适用性,因此是近些年热点的研究话题。GPT可作为一种序列到序列的模型直接生成语音;有学者首先使用概率模型检索相关新闻语料库,然后将新闻语料库和对话上下文相结合,作为GPT-2生成器的输入,生成响应。并且通过将篇章模式识别和疑问句类型预测作为多任务学习的两个子任务,可以进一步改进对话建模。在基于目标的应答检索系统中可以使用BERT作为上下文和候选应答的编码器;使用BERT和GPT-2共同进行知识选择和响应生成来完成基于知识的对话系统,其中BERT用于知识选择,GPT-2基于对话上下文和选择的知识来生成响应。
总结:本节博客介绍了模型相关的内容,后续具体介绍任务型对话系统~
















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











