






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**前期准备
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")数据导入和预处理
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.0
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(20,10))
for i in range(20):
plt.subplot(5,10,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i][0]])
plt.show() 
模型构建
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)), #卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), #卷积层3,卷积核3*3
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取
layers.Dense(10) #输出层,输出预期结果
])
model.summary() # 打印网络结构 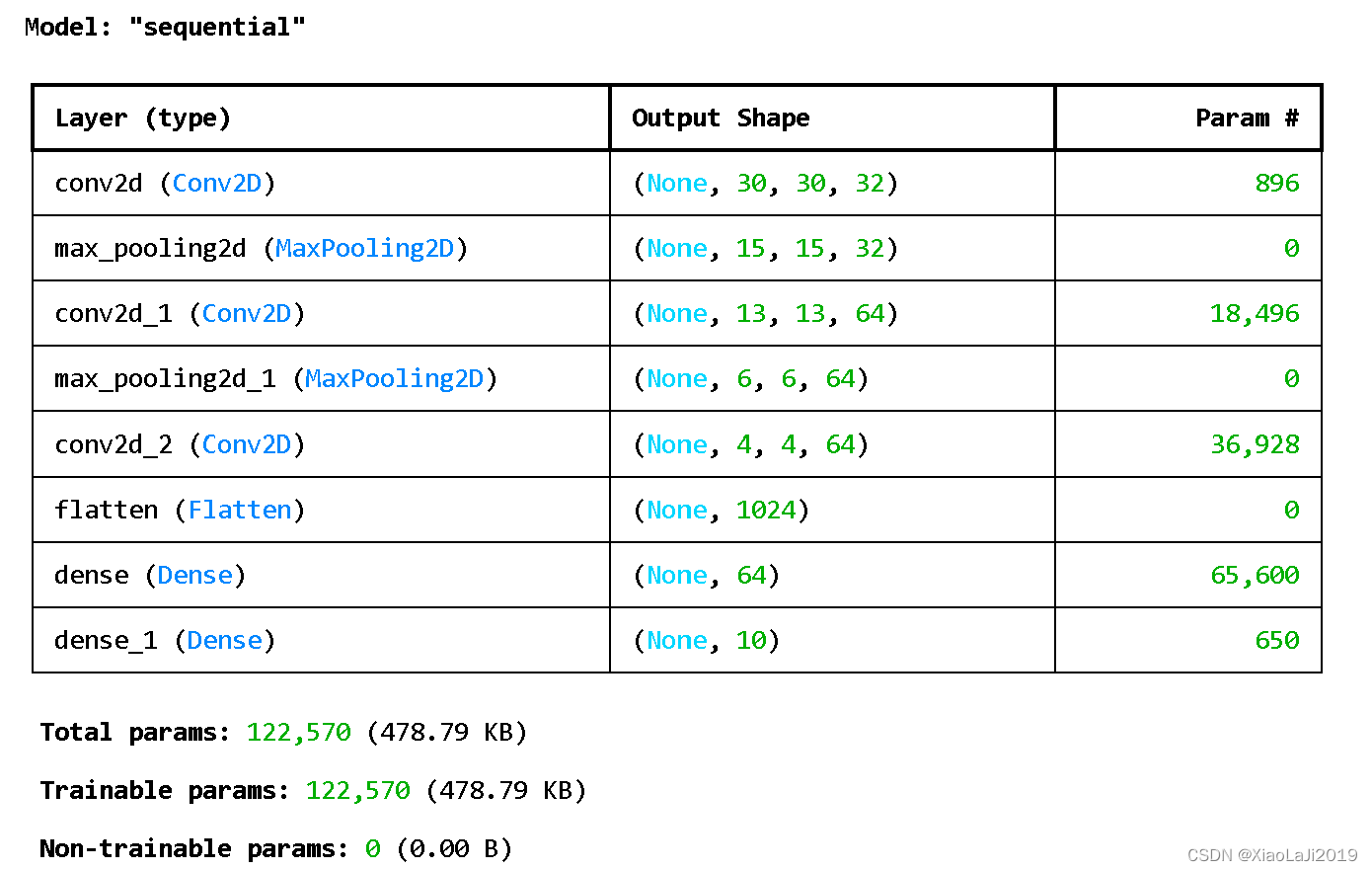
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))Epoch 1/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 27s 15ms/step - accuracy: 0.3360 - loss: 1.7789 - val_accuracy: 0.5505 - val_loss: 1.2390
Epoch 2/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.5681 - loss: 1.2194 - val_accuracy: 0.6064 - val_loss: 1.1047
Epoch 3/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.6331 - loss: 1.0414 - val_accuracy: 0.6359 - val_loss: 1.0205
Epoch 4/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 16ms/step - accuracy: 0.6694 - loss: 0.9425 - val_accuracy: 0.6626 - val_loss: 0.9626
Epoch 5/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 25s 16ms/step - accuracy: 0.6965 - loss: 0.8638 - val_accuracy: 0.6594 - val_loss: 0.9963
Epoch 6/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.7158 - loss: 0.8050 - val_accuracy: 0.6987 - val_loss: 0.8853
Epoch 7/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.7379 - loss: 0.7534 - val_accuracy: 0.6984 - val_loss: 0.8878
Epoch 8/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.7512 - loss: 0.7107 - val_accuracy: 0.7012 - val_loss: 0.8954
Epoch 9/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.7660 - loss: 0.6718 - val_accuracy: 0.6970 - val_loss: 0.9158
Epoch 10/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.7770 - loss: 0.6342 - val_accuracy: 0.6992 - val_loss: 0.9094结果评估和指定预测
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)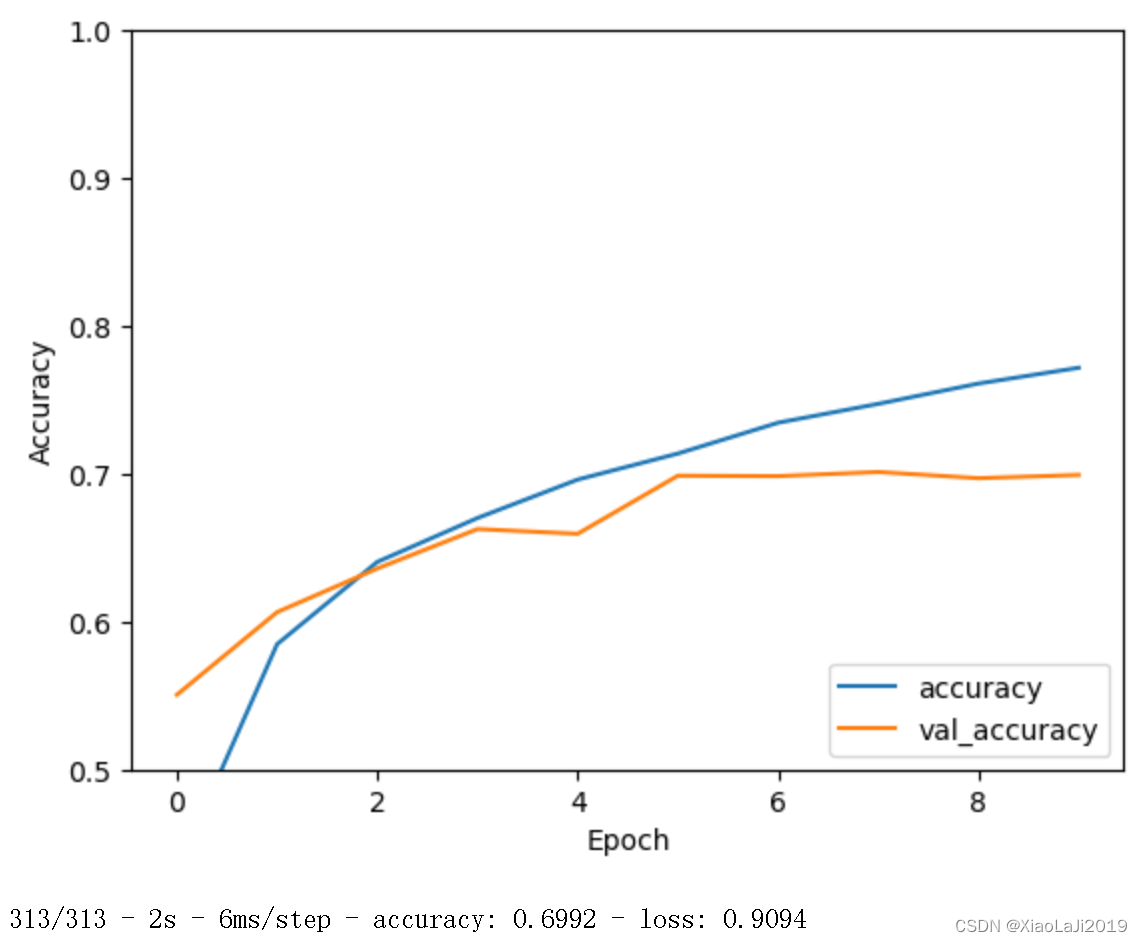
plt.imshow(test_images[8])
plt.imshow(test_images[8])313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 7ms/step
cat总结
彩色图片和灰度图片的区别
在卷积神经网络(CNN)中,处理彩色图片和灰度图片有几个关键的区别。这些区别主要体现在输入数据的维度、信息量和计算复杂度等方面。
1. 输入数据的维度
- 彩色图片:通常以 RGB 格式表示,每个像素有三个通道(红色、绿色和蓝色)。因此,彩色图片的形状通常是
(height, width, 3)。 - 灰度图片:每个像素只有一个通道(灰度值),表示为一个单一的强度值。灰度图片的形状通常是
(height, width, 1),有时也简写为(height, width)。
2. 信息量
- 彩色图片:包含更多的视觉信息,因为每个像素有三个不同的值(RGB),能够表达更丰富的颜色和细节。
- 灰度图片:只有一个强度值,信息量较少,只能表达明暗变化,但在某些任务中(如某些医学影像或二值化任务),灰度图片已经足够。
3. 计算复杂度
- 彩色图片:处理彩色图片需要更多的计算资源,因为每个卷积核需要对三个通道进行操作,这增加了卷积操作的计算量和内存需求。
- 灰度图片:处理灰度图片相对较简单,因为只需要处理一个通道,计算量和内存需求较低。
可以发现,彩色图片的处理是一个升级,但是基于Tensorflow框架直接调整其实并不复杂
准确率提升优化
根据最终的图像可以看出,训练准确率(蓝线)和验证准确率(橙线)之间存在一定的差距,且验证准确率在训练后期趋于平稳甚至有所下降,这表明模型可能存在一定的过拟合现象。这种情况使用dropout层效果比较好
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.5), # Dropout层,丢弃50%的节点
layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 27s 15ms/step - accuracy: 0.2838 - loss: 1.8969 - val_accuracy: 0.5229 - val_loss: 1.3253
Epoch 2/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.5097 - loss: 1.3745 - val_accuracy: 0.5984 - val_loss: 1.1390
Epoch 3/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.5779 - loss: 1.2010 - val_accuracy: 0.6411 - val_loss: 1.0099
Epoch 4/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.6201 - loss: 1.0929 - val_accuracy: 0.6525 - val_loss: 1.0054
Epoch 5/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.6464 - loss: 1.0217 - val_accuracy: 0.6718 - val_loss: 0.9395
Epoch 6/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 25s 16ms/step - accuracy: 0.6693 - loss: 0.9597 - val_accuracy: 0.6885 - val_loss: 0.9036
Epoch 7/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.6835 - loss: 0.9086 - val_accuracy: 0.6978 - val_loss: 0.8786
Epoch 8/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.6964 - loss: 0.8709 - val_accuracy: 0.7048 - val_loss: 0.8619
Epoch 9/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 23s 15ms/step - accuracy: 0.7119 - loss: 0.8367 - val_accuracy: 0.7134 - val_loss: 0.8525
Epoch 10/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 24s 15ms/step - accuracy: 0.7202 - loss: 0.7971 - val_accuracy: 0.7082 - val_loss: 0.8683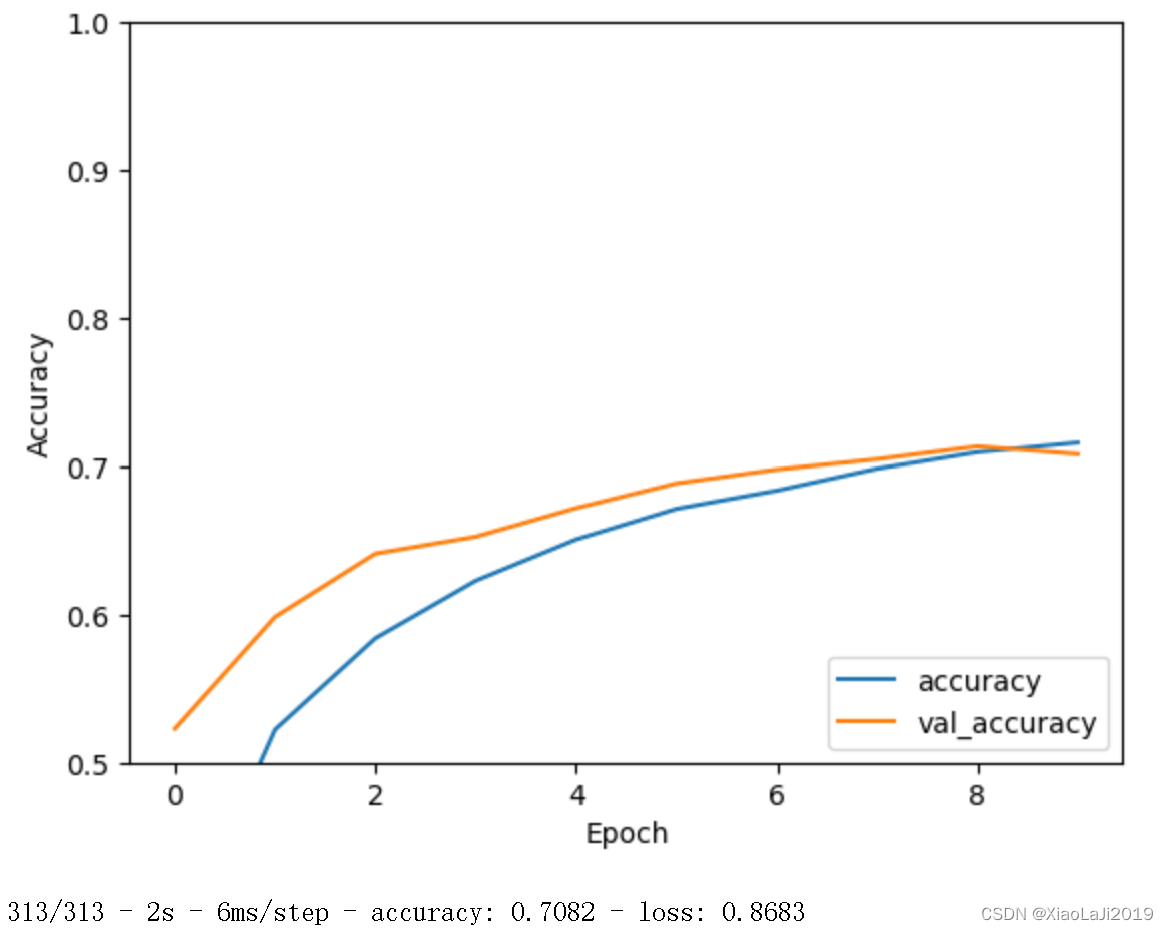
可以看到优化后准确率有了一定提升,进一步提升可能需要调整学习率和模型结构
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









