






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**已学习完Pytorch部分,Tensorflow部分着重了解二者的不同,且熟悉这边框架的操作
前期准备
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()数据导入
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
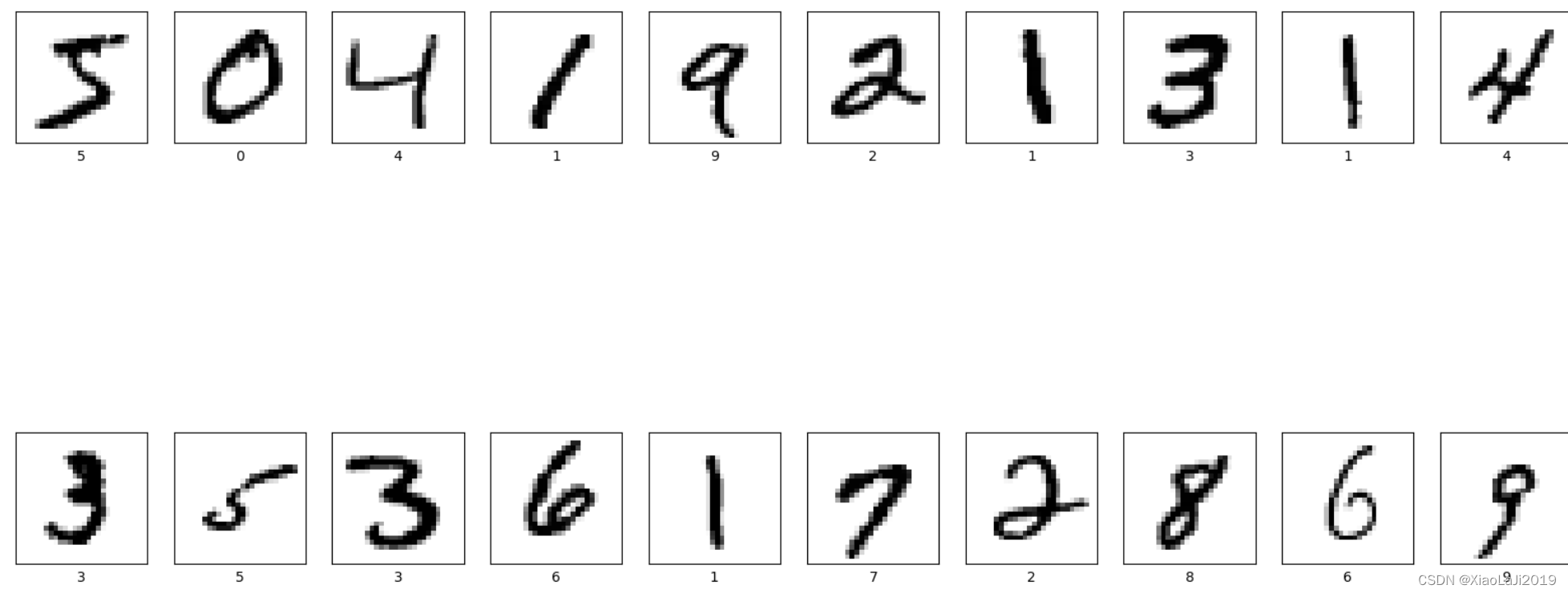
# 将数据集前20个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):
# 将整个figure分成5行10列,绘制第i+1个子图。
plt.subplot(2,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
""" 
模型构建
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)
# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层
# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
#池化层1,2*2采样
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数
layers.Conv2D(64, (3, 3), activation='relu'),
#池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) #输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary() 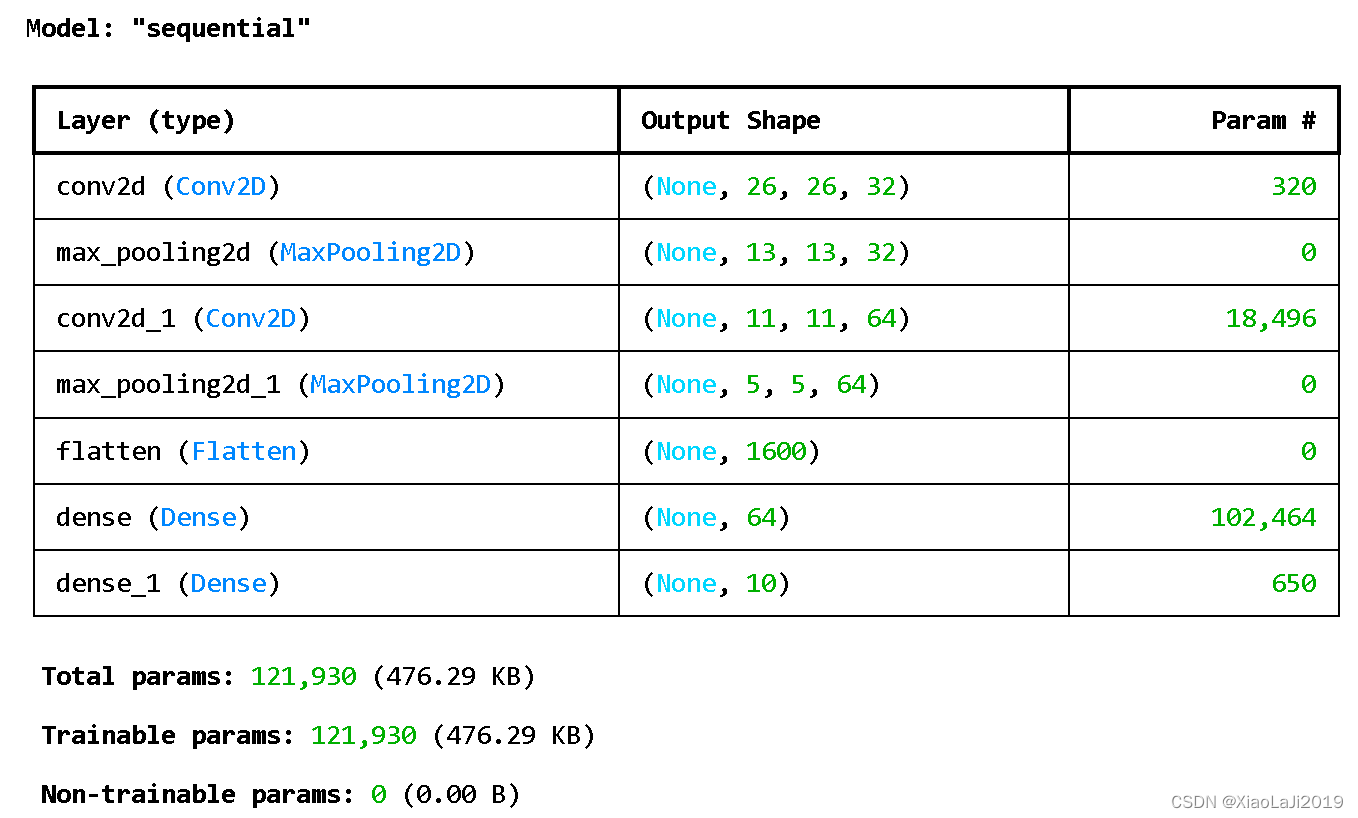
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))迭代结果
Epoch 1/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 25s 12ms/step - accuracy: 0.9014 - loss: 0.3245 - val_accuracy: 0.9839 - val_loss: 0.0525
Epoch 2/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - accuracy: 0.9858 - loss: 0.0461 - val_accuracy: 0.9880 - val_loss: 0.0388
Epoch 3/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9896 - loss: 0.0332 - val_accuracy: 0.9901 - val_loss: 0.0308
Epoch 4/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9938 - loss: 0.0205 - val_accuracy: 0.9906 - val_loss: 0.0318
Epoch 5/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9953 - loss: 0.0145 - val_accuracy: 0.9912 - val_loss: 0.0309
Epoch 6/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9962 - loss: 0.0114 - val_accuracy: 0.9914 - val_loss: 0.0297
Epoch 7/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - accuracy: 0.9970 - loss: 0.0091 - val_accuracy: 0.9914 - val_loss: 0.0286
Epoch 8/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9974 - loss: 0.0081 - val_accuracy: 0.9916 - val_loss: 0.0307
Epoch 9/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9975 - loss: 0.0077 - val_accuracy: 0.9920 - val_loss: 0.0334
Epoch 10/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 23s 12ms/step - accuracy: 0.9980 - loss: 0.0059 - val_accuracy: 0.9926 - val_loss: 0.0344预测
plt.imshow(test_images[6])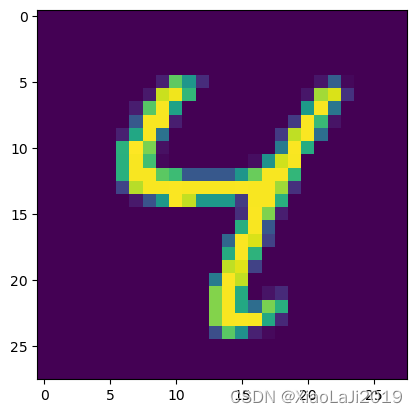
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[6] # 输出第六张图片的预测结果313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 5ms/step
array([-28.310648 , -10.524958 , -25.035824 , -22.129251 , 20.225563 ,
-13.313466 , -17.900633 , -8.566347 , 7.214013 , 5.9358835],
dtype=float32)总结
Pytorch和Tensorflow优劣势对比
PyTorch 优势
-
动态计算图(Define-by-Run):
- 易用性:动态计算图使得代码在运行时构建,非常接近Python本身的编程风格,便于调试和实验。
- 灵活性:可以在模型运行时改变图结构,方便处理复杂和动态的模型。
-
直观的调试:
- 集成调试:可以使用标准的Python调试工具,如pdb,直接调试模型代码。
- 错误易于定位:由于动态图的性质,错误发生在具体的代码行,便于追踪和修复。
-
社区和发展:
- 学术支持:广泛应用于学术界,许多研究论文和教程以PyTorch为基础。
- 更新速度:活跃的开发社区,快速迭代,最新的研究成果和功能更新迅速集成。
-
API设计:
- Pythonic风格:API设计简洁,风格与Python一致,降低学习成本。
- 可读性:代码结构清晰,便于理解和维护。
PyTorch 劣势
-
生产部署支持:
- 工具链相对较弱:虽然有TorchServe等工具,但整体生态系统不如TensorFlow成熟。
- 企业应用较少:在大规模企业应用中的使用案例相对较少。
-
兼容性和稳定性:
- 快速更新:频繁的更新可能导致版本不兼容和依赖问题。
-
移动和嵌入式设备支持:
- 移动端部署:虽然有PyTorch Mobile,但相比TensorFlow Lite,工具和支持相对较少。
TensorFlow 优势
-
全面的生产部署支持:
- 丰富的工具链:包括TensorFlow Serving、TensorFlow Lite、TensorFlow.js等,覆盖服务器、移动端和浏览器等多种环境。
- 企业级应用:广泛应用于企业级项目,支持大规模生产部署。
-
性能优化:
- XLA编译器:通过加速线性代数(XLA)编译器进行优化,提高执行速度。
- 硬件加速支持:对TPU、GPU等硬件加速设备有良好的支持,性能优化效果显著。
-
生态系统:
- 丰富的扩展库:如TensorFlow Extended(TFX)、TensorFlow Hub等,提供数据处理、模型管理、部署等全方位支持。
- 社区和资源:庞大的用户社区,丰富的文档和教程资源,方便学习和问题解决。
-
兼容性:
- 长期支持(LTS):提供长期支持版本,确保生产环境的稳定性和兼容性。
TensorFlow 劣势
-
学习曲线:
- 复杂性:早期版本的静态图计算模式使得上手较为困难,代码复杂度高。
- 调试困难:静态图模式下调试不直观,错误定位较为困难。
-
灵活性:
- 动态图支持较晚:虽然TensorFlow 2.x 引入了Eager Execution,接近PyTorch的动态图计算,但仍然没有PyTorch那么灵活。
-
代码冗长:
- 可读性:相比PyTorch,TensorFlow的代码较为冗长,不够直观,增加了开发难度。
大模型适配性
PyTorch 更加适配的场景:
- 研究和实验:
- PyTorch因其动态计算图的特性,非常适合需要频繁调整和实验的研究工作。
- 大型语言模型的许多研究论文和开源实现(如BERT、GPT等)最初都是基于PyTorch开发的。
- 社区支持和资源:
- PyTorch在学术界和研究界有着广泛的支持,大量的开源项目和资源使得使用PyTorch进行大模型开发更加方便。
TensorFlow 更加适配的场景:
- 生产部署:
- TensorFlow因其强大的生产环境支持,适合在企业和工业界中大规模部署大型语言模型。
- TensorFlow Serving、TensorFlow Lite等工具能够方便地将模型部署到服务器、移动设备等多种环境中。
- 性能优化:
- TensorFlow的XLA编译器和TPU支持使得它在性能优化方面具有优势,适合需要高效运行的大规模模型。
上述总结由GPT生成,目的是对比一下两种框架各自的优劣势,实际学习工作中一般根据具体需求进行选取,并且两者对目前流行的大模型方向都能适配。















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









