






看了一篇大佬写的文章,里面实现了一个轻量级的帧内编码器,感觉用来学习编码器基础非常好,本文是一些自己的理解。大佬文章:H.265/HEVC 帧内编码详解:CU/TU层次结构、预测、变换、量化、编码、编码端整体流程 - 知乎
整体流程:
1.参数解析,输入文件 输出文件 QP [重构文件]。
2.加载PGM文件,loadPGMfile(),把数据存入char img [8192*8192](二维图片往一维数组存),并且得到图片的宽xsz和高ysz。
3.开始压缩HEVCImageEncoder(),这个函数返回HEVC码流长度,保存码流到pbuffer,保存重构文件img_rcon。
HEVCImageEncoder():
[
1)初始化CABAC编码器,初始化tCtxs上下文参数集,填充高和宽成为CTU的倍数(CTU固定32x32大小)。初始化所有CU大小为CTU大小,所有帧内预测模式为PMODE_DC。
2)putHeaderToBuffer()将头文件信息插入HEVC码流(VPS,SPS,PPS)
3)从左至右、从上到下一个一个CTU的开始编码
for (y=0; y<yszn; y+=CTU_SZ) {
for (x=0; x<xszn; x+=CTU_SZ) {
……参数、重构处理
processCURecurs() 编码一个CTU
……重构处理
写终止位,CABAC缓存区写出到输出缓存区
}
保留上一行CTU的信息可以给下一行做参考
}
]
processCURecurs():
参数:(blk_orig [][CTU_SZ]原始像素块,blk_rcon [][1+CTU_SZ*2]重构像素块
Ctxs、CABAC以及一系列的边框检查标志)
[
一系列初始化,以及获取邻近CU的信息,构造子块信息。
第一步:尝试划分成4个CU
putSplitCUflag()设置划分标志
四个子块再次递归调用processCURecurs(),计算Rdcost(基于SSE的cost),备份重构块。
第二步:CU不划分,对每个帧内预测方向尝试part2Nx2N (no splitting to 4 PUs)模式。
for (pmode=0; pmode<PMODE_COUNT; pmode++) {
predict、transform、quantize、deQuantize、transform系列函数
逆转换后的块存入重构块
设置不划分标志
对blk_quat系数块进行putCU_Part2Nx2N_noTUsplit()编码CU,计算RDcost
更新最佳RDcost,选择最佳帧内预测方向 }
第三步:CU不划分,对每个帧内预测方向尝试part2Nx2N (no splitting to 4 PUs),but splitting to 4 TUs模式,循环同第二步类似,调用putCU_Part2Nx2N_TUsplit()编码CU
第四步:CU大小正好等于8x8时。partNxN (splitting to 4 PUs)模式
循环同第二步类似,这里直接调用putCoef()对四个子PU处理
再给四个PU的Ctx赋值,再调用putCU_PartNxN()编码
最后一步:将最佳重构CU写入blk_rcon
}
]
predict、BLK_SUB、transform0、quantize、deQuantize、transform1系列函数
predict:根据预测角度得到预测块blk_tmp1
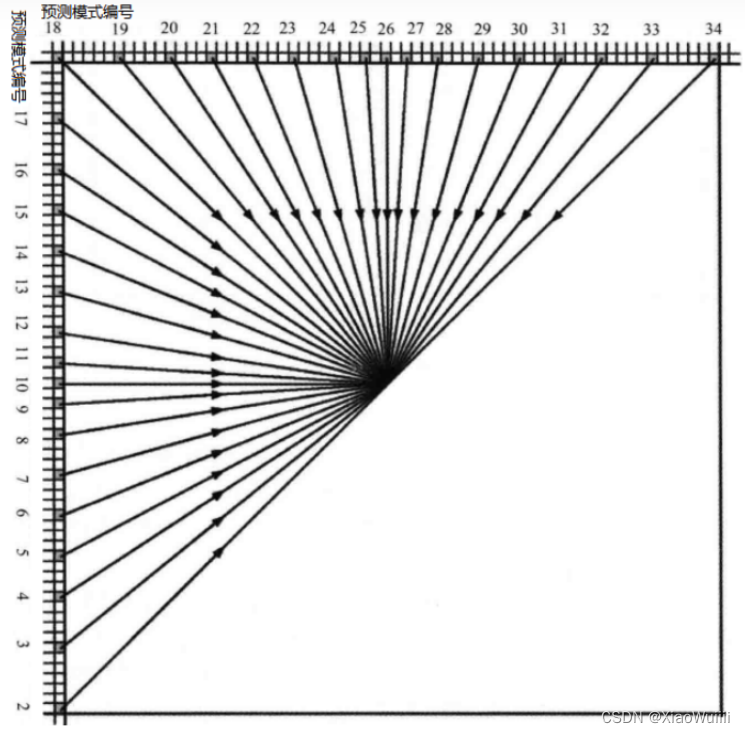
35个角度(Planar、DC、HOR、VER、2~9、11~25、27~34)
BLK_SUB:blk_orig- blk_tmp1得到残差块blk_tmp2
transform0:对残差块blk_tmp2进行转换(DCT or 4x4 DST)
DST4_MAT, DCT8_MAT, DCT16_MAT, DCT32_MAT四个预设好的转换矩阵,根据TU大小来选择矩阵。矩阵相乘函数matMul()。
quantize:简化率失真优化量化(RDOQ),对转换后的blk_tmp2进行量化得到blk_quat块
循环对每个CG块(4x4系数块)进行量化
for (yc=0; yc<sz; yc+=CG_SZ) {
for (xc=0; xc<sz; xc+=CG_SZ) {
……
对一个CG块进行率失真优化得到最优CG块
for (y=yc; y<yc+CG_SZ; y++) {
for (x=xc; x<xc+CG_SZ; x++){
I32 level = COEF_CLIP( (dlevel+add) >> sft );
I32 min_level = MAX(0, level-2);
在这两个范围内寻找最优CG
}}
……if this CG is too weak,clear all items in CG,系数矩阵太弱就直接全部置0
}}
deQuantize:反量化,由blk_quat得到blk_tmp2
transform1:逆转换blk_tmp2
BLK_ADD_CLIP_TO_PIX:把逆回来的blk_tmp2直接存入重构块
后续对量化得到的blk_quat块进行编码
putCU_Part2Nx2N_noTUsplit、putCU_Part2Nx2N_Tusplit、putCU_PartNxN三个编码函数
putCU_Part2Nx2N_noTUsplit():put a CU to HEVC stream, where part_type = part2Nx2N , no splitting to 4 Tus。
系列函数:putPartSize、putYpmode、putUVpmode、putSplitTUflag、putQtCbf(U、V、Y)以及putCoef()均调用CABACputBin()函数来CABAC编码写入码流
putCU_Part2Nx2N_TUsplit()
同putCU_Part2Nx2N_noTUsplit()类似,额外对四个TU进行putCoef()系数编码
putCU_PartNxN()
同上面两个类似,标志位不同,并且对四个TU系数编码
putCoef()
把一个系数块编进码流
调用getScanOrder获得扫描顺序表,调用一系列CABACputBins()进行CABAC编码
附:
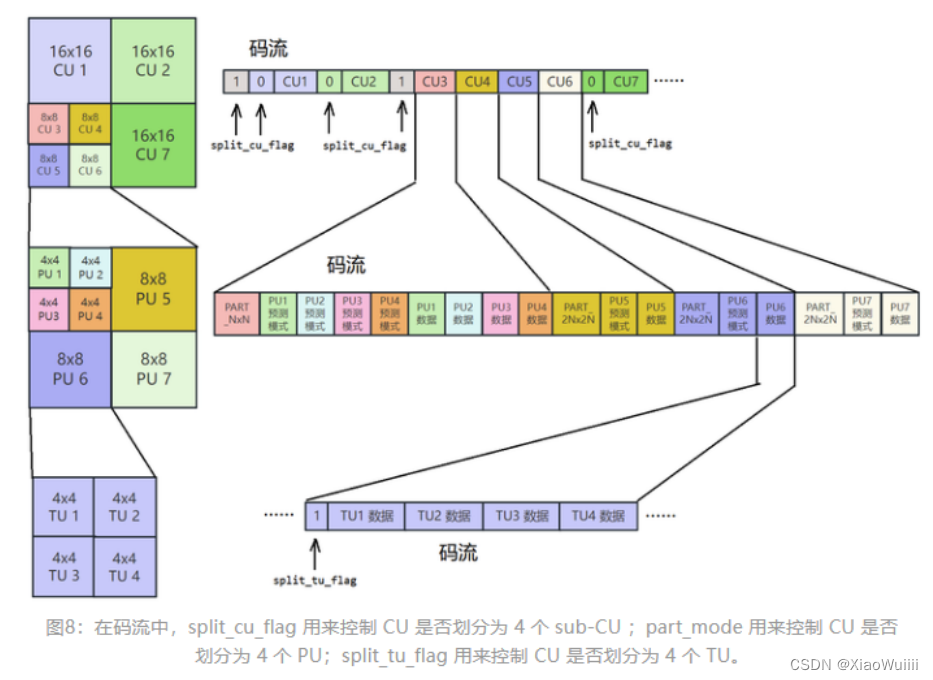
作者的码流分析CU、PU、TU层次编码划分
HEVC的35中帧内预测模式
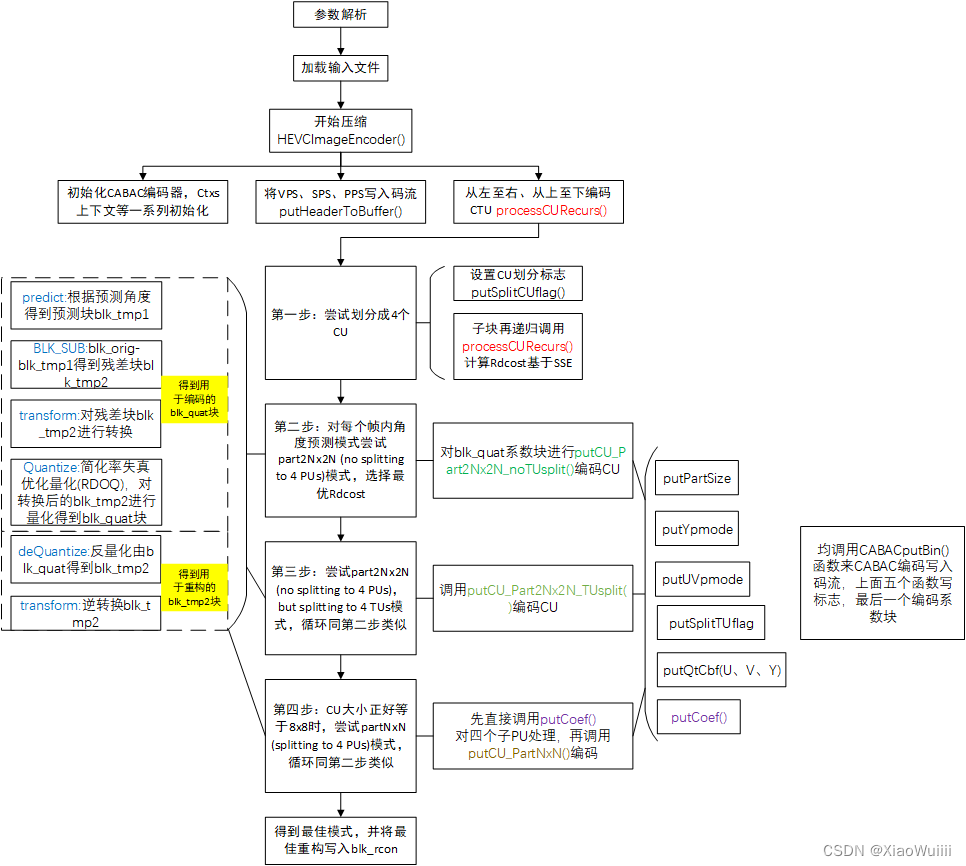
整体流程图:
// 作者分析的编码器搜索一个 CTU 的最优方案的过程日志 -------------------------------------------------------------------------
ProcessCU开始: CU(y= 0 x= 0 size=32) 初始化设置最优RDcost=99999
ProcessCU开始: CU(y= 0 x= 0 size=16) 初始化设置最优RDcost=99999
ProcessCU开始: CU(y= 0 x= 0 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 0 x= 0 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=369), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 0 x= 0 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 1 (RDcost=748), 不小于之前最优RDcost (369)
把 CU(y= 0 x= 0 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 0,19,31,18}, RDcost=801, 不小于之前最优RDcost (369)
ProcessCU结束: CU(y= 0 x= 0 size= 8), 最终 RDcost=369
ProcessCU开始: CU(y= 0 x= 8 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 0 x= 8 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 4 (RDcost=238), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 0 x= 8 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 2 (RDcost=270), 不小于之前最优RDcost (238)
把 CU(y= 0 x= 8 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 3, 2,34, 3}, RDcost=309, 不小于之前最优RDcost (238)
ProcessCU结束: CU(y= 0 x= 8 size= 8), 最终 RDcost=238
ProcessCU开始: CU(y= 8 x= 0 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 8 x= 0 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是26 (RDcost=217), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 8 x= 0 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是26 (RDcost=232), 不小于之前最优RDcost (217)
把 CU(y= 8 x= 0 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={25,17,22,20}, RDcost=291, 不小于之前最优RDcost (217)
ProcessCU结束: CU(y= 8 x= 0 size= 8), 最终 RDcost=217
ProcessCU开始: CU(y= 8 x= 8 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 8 x= 8 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=225), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 8 x= 8 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是10 (RDcost=269), 不小于之前最优RDcost (225)
把 CU(y= 8 x= 8 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={26,24,17, 7}, RDcost=282, 不小于之前最优RDcost (225)
ProcessCU结束: CU(y= 8 x= 8 size= 8), 最终 RDcost=225
已尝试把 CU(y= 0 x= 0 size=16) 拆分成4个CU, 总 RDcost=369+238+217+225=1049 暂时以该方案作为当前最优方案
把 CU(y= 0 x= 0 size=16) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=818), 小于之前最优RDcost (1049), 更新为当前最优方案
把 CU(y= 0 x= 0 size=16) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 2 (RDcost=951), 不小于之前最优RDcost (818)
ProcessCU结束: CU(y= 0 x= 0 size=16), 最终 RDcost=818
ProcessCU开始: CU(y= 0 x=16 size=16) 初始化设置最优RDcost=99999
ProcessCU开始: CU(y= 0 x=16 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 0 x=16 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 1 (RDcost=214), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 0 x=16 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=237), 不小于之前最优RDcost (214)
把 CU(y= 0 x=16 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 2, 3,14,17}, RDcost=370, 不小于之前最优RDcost (214)
ProcessCU结束: CU(y= 0 x=16 size= 8), 最终 RDcost=214
ProcessCU开始: CU(y= 0 x=24 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 0 x=24 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是26 (RDcost=416), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 0 x=24 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=503), 不小于之前最优RDcost (416)
把 CU(y= 0 x=24 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 1,16,19,21}, RDcost=525, 不小于之前最优RDcost (416)
ProcessCU结束: CU(y= 0 x=24 size= 8), 最终 RDcost=416
ProcessCU开始: CU(y= 8 x=16 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 8 x=16 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=216), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 8 x=16 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=247), 不小于之前最优RDcost (216)
把 CU(y= 8 x=16 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 0,26, 7,19}, RDcost=223, 不小于之前最优RDcost (216)
ProcessCU结束: CU(y= 8 x=16 size= 8), 最终 RDcost=216
ProcessCU开始: CU(y= 8 x=24 size= 8) 初始化设置最优RDcost=99999
把 CU(y= 8 x=24 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 8 (RDcost=1986), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y= 8 x=24 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 3 (RDcost=1404), 小于之前最优RDcost (1986), 更新为当前最优方案
把 CU(y= 8 x=24 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 0,16,23, 3}, RDcost=1345, 小于当前最优RDcost (1404), 更新为当前最优方案
ProcessCU结束: CU(y= 8 x=24 size= 8), 最终 RDcost=1345
已尝试把 CU(y= 0 x=16 size=16) 拆分成4个CU, 总 RDcost=214+416+216+1345=2192 暂时以该方案作为当前最优方案
把 CU(y= 0 x=16 size=16) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 3 (RDcost=5377), 不小于之前最优RDcost (2192)
把 CU(y= 0 x=16 size=16) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是15 (RDcost=2717), 不小于之前最优RDcost (2192)
ProcessCU结束: CU(y= 0 x=16 size=16), 最终 RDcost=2192
ProcessCU开始: CU(y=16 x= 0 size=16) 初始化设置最优RDcost=99999
ProcessCU开始: CU(y=16 x= 0 size= 8) 初始化设置最优RDcost=99999
把 CU(y=16 x= 0 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 1 (RDcost=219), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=16 x= 0 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是17 (RDcost=289), 不小于之前最优RDcost (219)
把 CU(y=16 x= 0 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 1,16,22,12}, RDcost=344, 不小于之前最优RDcost (219)
ProcessCU结束: CU(y=16 x= 0 size= 8), 最终 RDcost=219
ProcessCU开始: CU(y=16 x= 8 size= 8) 初始化设置最优RDcost=99999
把 CU(y=16 x= 8 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是24 (RDcost=1300), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=16 x= 8 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=654), 小于之前最优RDcost (1300), 更新为当前最优方案
把 CU(y=16 x= 8 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={17,31,19,22}, RDcost=649, 小于当前最优RDcost (654), 更新为当前最优方案
ProcessCU结束: CU(y=16 x= 8 size= 8), 最终 RDcost=649
ProcessCU开始: CU(y=24 x= 0 size= 8) 初始化设置最优RDcost=99999
把 CU(y=24 x= 0 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是26 (RDcost=181), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=24 x= 0 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=221), 不小于之前最优RDcost (181)
把 CU(y=24 x= 0 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={31,26,19,29}, RDcost=306, 不小于之前最优RDcost (181)
ProcessCU结束: CU(y=24 x= 0 size= 8), 最终 RDcost=181
ProcessCU开始: CU(y=24 x= 8 size= 8) 初始化设置最优RDcost=99999
把 CU(y=24 x= 8 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是28 (RDcost=1302), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=24 x= 8 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是27 (RDcost=907), 小于之前最优RDcost (1302), 更新为当前最优方案
把 CU(y=24 x= 8 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={29,28,23,27}, RDcost=937, 不小于之前最优RDcost (907)
ProcessCU结束: CU(y=24 x= 8 size= 8), 最终 RDcost=907
已尝试把 CU(y=16 x= 0 size=16) 拆分成4个CU, 总 RDcost=219+649+181+907=1958 暂时以该方案作为当前最优方案
把 CU(y=16 x= 0 size=16) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是14 (RDcost=4343), 不小于之前最优RDcost (1958)
把 CU(y=16 x= 0 size=16) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是28 (RDcost=3091), 不小于之前最优RDcost (1958)
ProcessCU结束: CU(y=16 x= 0 size=16), 最终 RDcost=1958
ProcessCU开始: CU(y=16 x=16 size=16) 初始化设置最优RDcost=99999
ProcessCU开始: CU(y=16 x=16 size= 8) 初始化设置最优RDcost=99999
把 CU(y=16 x=16 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 3 (RDcost=1641), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=16 x=16 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 4 (RDcost=1332), 小于之前最优RDcost (1641), 更新为当前最优方案
把 CU(y=16 x=16 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={ 4, 5, 3, 0}, RDcost=1254, 小于当前最优RDcost (1332), 更新为当前最优方案
ProcessCU结束: CU(y=16 x=16 size= 8), 最终 RDcost=1254
ProcessCU开始: CU(y=16 x=24 size= 8) 初始化设置最优RDcost=99999
把 CU(y=16 x=24 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是33 (RDcost=1670), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=16 x=24 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=875), 小于之前最优RDcost (1670), 更新为当前最优方案
把 CU(y=16 x=24 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={34,31, 6, 0}, RDcost=919, 不小于之前最优RDcost (875)
ProcessCU结束: CU(y=16 x=24 size= 8), 最终 RDcost=875
ProcessCU开始: CU(y=24 x=16 size= 8) 初始化设置最优RDcost=99999
把 CU(y=24 x=16 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=322), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=24 x=16 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是27 (RDcost=395), 不小于之前最优RDcost (322)
把 CU(y=24 x=16 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={34,29, 1,28}, RDcost=421, 不小于之前最优RDcost (322)
ProcessCU结束: CU(y=24 x=16 size= 8), 最终 RDcost=322
ProcessCU开始: CU(y=24 x=24 size= 8) 初始化设置最优RDcost=99999
把 CU(y=24 x=24 size= 8) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是26 (RDcost=359), 小于之前最优RDcost (99999), 更新为当前最优方案
把 CU(y=24 x=24 size= 8) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是26 (RDcost=335), 小于之前最优RDcost (359), 更新为当前最优方案
把 CU(y=24 x=24 size= 8) 分成4个PU, 对每个PU分别尝试35种预测模式, 4个最佳的预测模式={24,27,24,26}, RDcost=415, 不小于之前最优RDcost (335)
ProcessCU结束: CU(y=24 x=24 size= 8), 最终 RDcost=335
已尝试把 CU(y=16 x=16 size=16) 拆分成4个CU, 总 RDcost=1254+875+322+335=2787 暂时以该方案作为当前最优方案
把 CU(y=16 x=16 size=16) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 5 (RDcost=5745), 不小于之前最优RDcost (2787)
把 CU(y=16 x=16 size=16) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=4150), 不小于之前最优RDcost (2787)
ProcessCU结束: CU(y=16 x=16 size=16), 最终 RDcost=2787
已尝试把 CU(y= 0 x= 0 size=32) 拆分成4个CU, 总 RDcost=818+2192+1958+2787=7754 暂时以该方案作为当前最优方案
把 CU(y= 0 x= 0 size=32) 当作1个TU, 尝试35种预测模式, 其中最佳预测模式是 0 (RDcost=20321), 不小于之前最优RDcost (7754)
把 CU(y= 0 x= 0 size=32) 分成4个TU, 尝试35种预测模式, 其中最佳预测模式是 3 (RDcost=15969), 不小于之前最优RDcost (7754)
ProcessCU结束: CU(y= 0 x= 0 size=32), 最终 RDcost=7754

















 3496
3496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









