






@

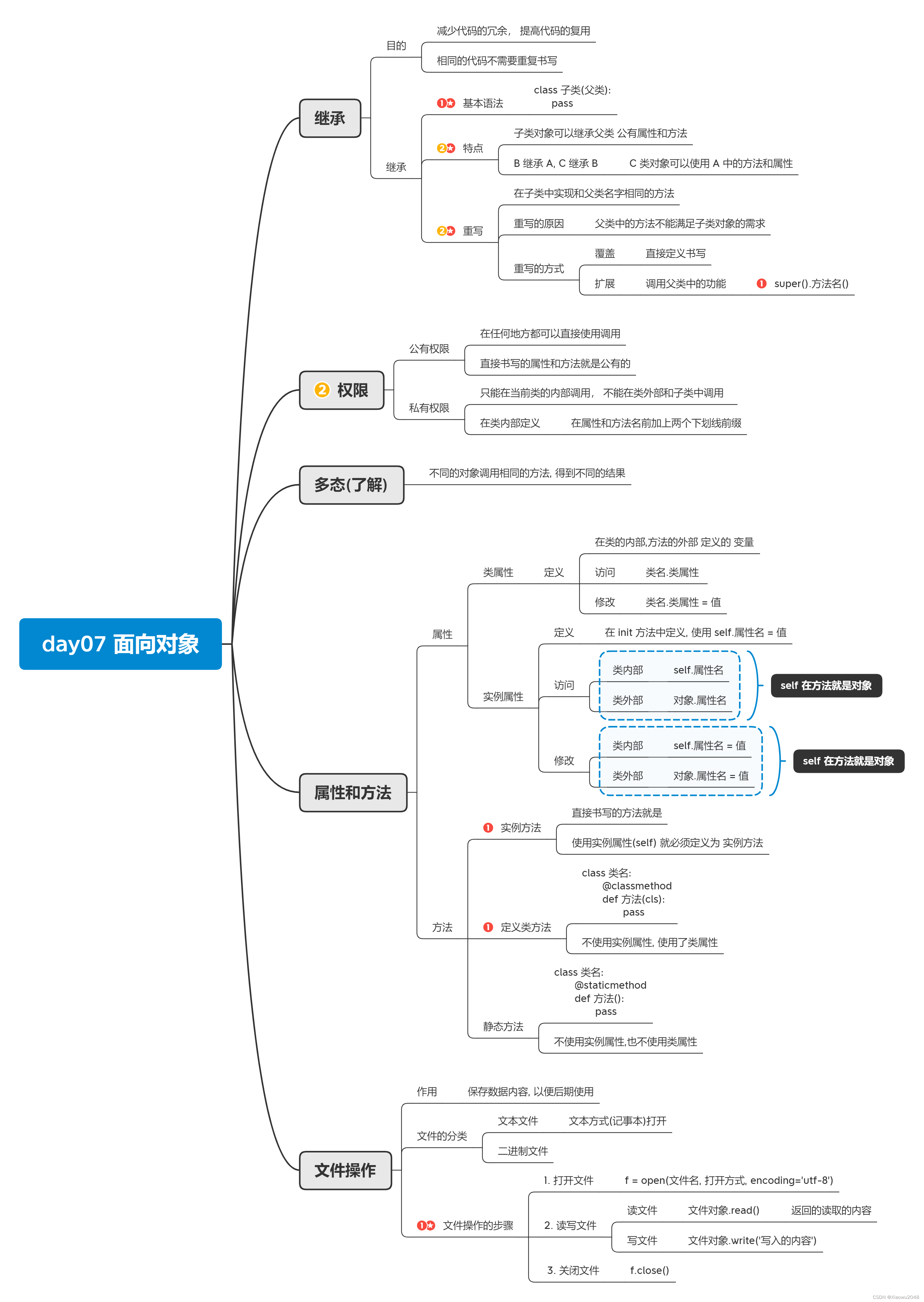
环境搭建
python 的版本: python2 和 Python3(主流)
python 是解释型语⾔,在执⾏的时候, 需要解释器⼀边解释(翻译)⼀边执⾏.
从上到下执⾏,下⽅代码出现的错误, 不会影响上⽅代码的执⾏
1、下载解释器安装包
链接:https://pan.baidu.com/s/1OoeM1ncul75covyQm8l5wQ
提取码:91rh
–来自百度网盘超级会员V6的分享
双击安装包进行安装
选择自定义安装
勾选添加环境变量(添加环境变量之后在任何路径都可直接使用,可以让程序在任意的目录去执行)
安装目录:
1.不要使用中文目录
2.选择一个空目录进行安装
3.安装在之后,不要自己移动文件
在官网all release下可以找到下载所有的历史版本
2.pycharm环境
是python最好用的ide(集成开发环境)之一,(写代码,查看结果等功能)
pycharm创建项目
下载安装包
双击安装包选择默认选项即可完成安装
3.pycharm中编写helloworld程序
操作步骤:
1、启动软件
2、创建项目
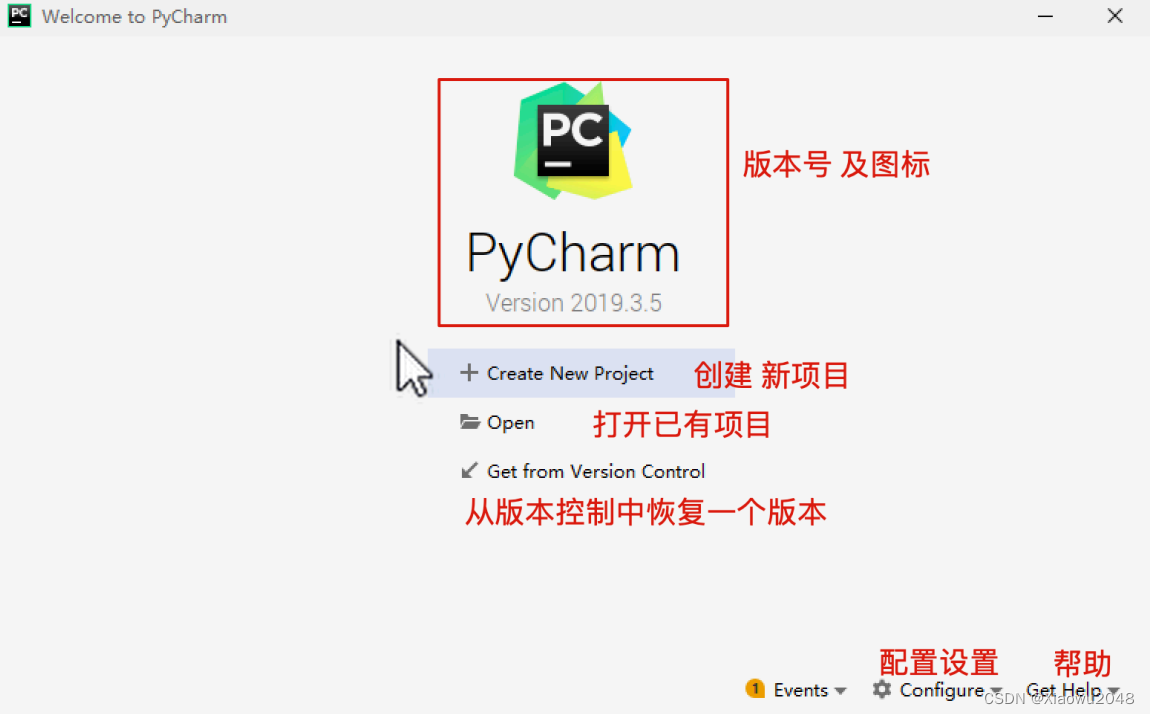
3、配置代码路径和解释器路径
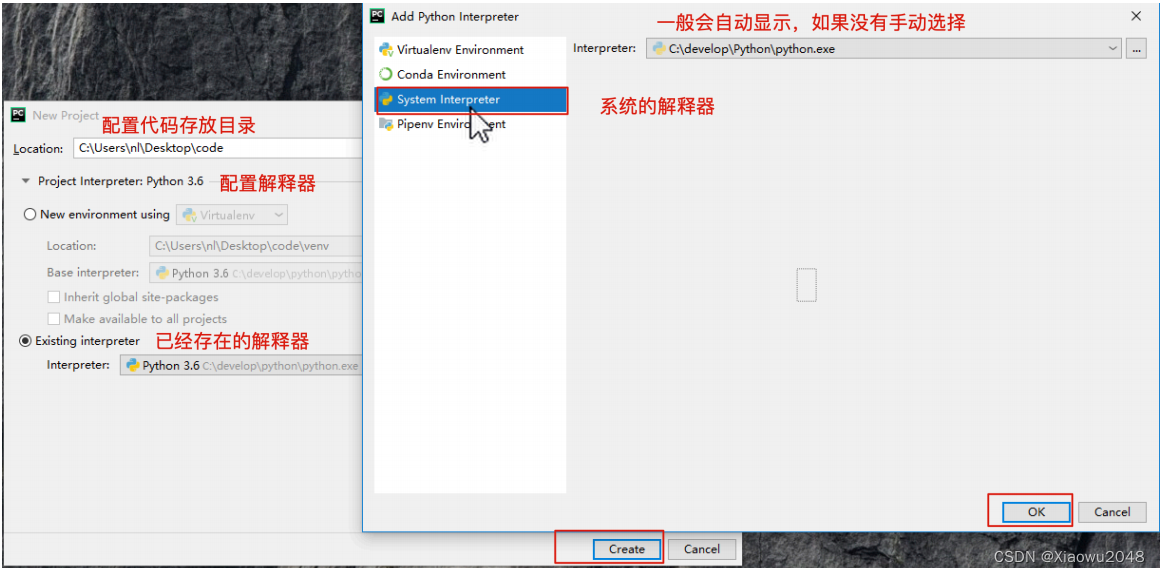
4、在项目目录下创建python文件

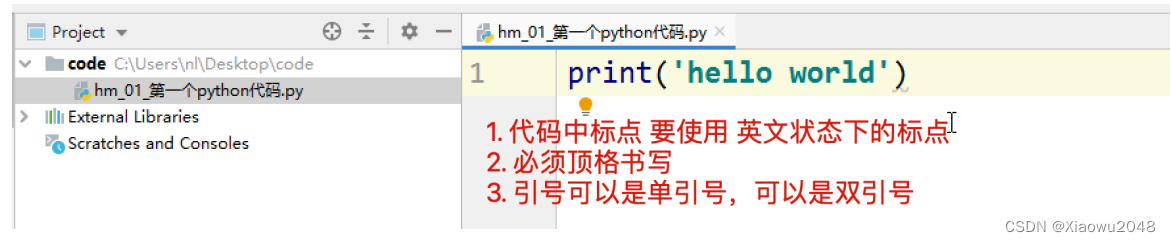
5、编写代码
6、在当前文件编辑区直接点击鼠标右键,选择run
在下方控制台中即可看到打印的内容
cmd终端执行代码

代码执行的原理:python解释器加上python代码的路径

pycharm常见操作
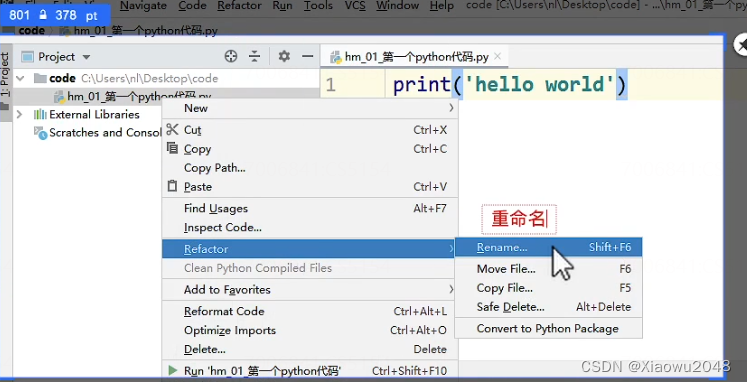
重命名
新打开项目的方式

附加会附加在当前目录下
设置背景色

设置字体大小

配置解释器

print解析
print()是python中的函数,在控制台中输出内容,主要用途,验证结果是否正确
想要在控制台进行输出,就必须有print()
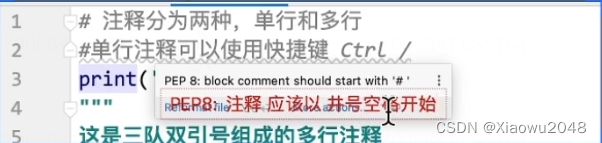
注释
对代码的解释和说明,特点是不会被解释器执行
分类:
单行注释:
快捷键:ctrl +/
多行注释:
注释的内容可以换行书写,可以是三队单引号或者三队双引号,将注释的内容写在注释之间
波浪线
红色波浪线
是代码中的错误,需要解决,否则会影响代码执行

绿色波浪线
pycharm 认为你写的单词不正确
灰色波浪线
不影响代码执行,是PEP8的代码规范性问题,如果出现了,就是你的代码书写不规范
可以使用代码格式化进行解决 ,快捷键ctrl alt L


变量
定义:
1.变量的作用 是用来保存数据的
2.变量必须先定义后使用,(必须存入数据才能获取数据)
3.定义的语法 变量名= 数据值
4.使用,直接使用变量名,即可使用变量中存储的数据
# 需求1,定义一个变量,保存你的名字
name = '小明' # 简单认为变量name中保存了数据'小明' 变量名 = 变量值
# 需求2 使用变量打印你的名字
print(name) # 小明,变量中存储的数据 使用变量中存储的数据,直接使用变量名
# 需求3,定义一个变量,保存你的年龄 并打印
age = 18
print(age)
练习:
# 需求1,定义一个变量,保存你的名字
name = '小明' # 简单认为变量name中保存了数据'小明'
# 需求2 使用变量打印你的名字
print(name) # 小明,变量中存储的数据
# 需求3,定义一个变量,保存你的年龄 并打印
age = 18
print(age)
# 性别
sex = '男'
# 身高
height = 170.1
print(sex,height)
变量命名规范
变量名要遵循标识符的规则
标识符的规则
1.只能有字母,数字和下划线组成,不能以数字开头
2.不能使用python关键字
关键字是python预先定义好的标识符,具有特殊作用
3.区分大小写
变量名命名规范:
1.要遵循标识符的规则
2.见名知意
3.命名习惯
驼峰命名法:
大驼峰 ,每个单词的首字母,都大写 MyName,常用于类名,函数名,属性,命名空间
小驼峰,第一个单词的首字母小写,其余单词首字母大写 myName,变量一般用小驼峰法标识
下划线连接
单词与单词之间使用下划线连接

数据类型
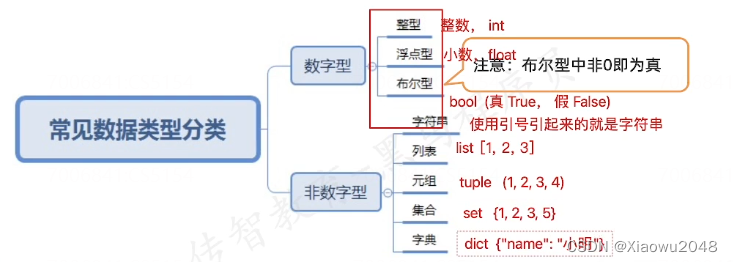
list列表,中括号
tuple元组 ,小括号
set 集合,大括号
dict字典,大括号+键值对
查看数据类型:
语法:type(数据/变量名)
注意:该函数本身不具备输出功能,需要配合print()函数使用
# int 整型
age = 18
print(type(age)) # int整型变量
# float 浮点型 小数
height = 1.71 # 浮点型,小数
print(type(height))
# bool类型,True真和False假,都是关键字
is_men = True
print(type(is_men)) # 布尔变量
# 字符串 str
name = '小明'
print(type(name)) # 字符串
num = '20' # 用引号引起来的都是字符串
print(type(num))
输入
获取键盘的输入,使用input()
变量 = input(’给使用者的提示信息,即告诉被人输入什么内容’)
1.代码从上到下执行,当代码执行到input的时候,会暂停代码的执行,等待用户的输入
2.在输入过程中,如果遇到回车键,会暂停代码的执行,等待用户的输入
3.使用input获取的内容,都是字符串类型,即str
# 需求,从键盘录入你的名字
name = input('请输入你的姓名:')
print(type(name),name) # 打印类型和变量的值
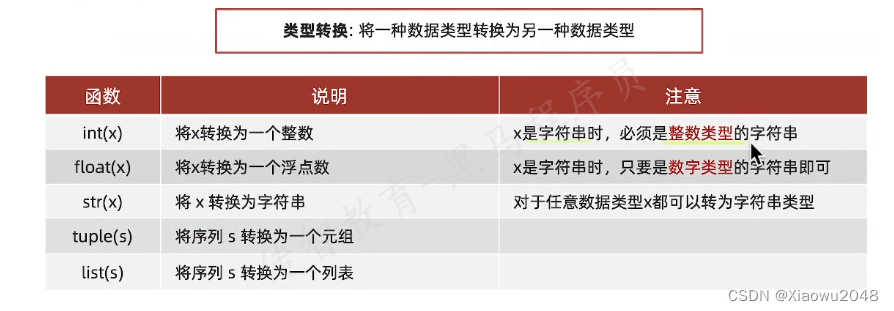
数据类型转换
/一种数据类型转换为另一种数据类型
1.原数据是什么类型
2.要转换为什么类型吗
变量 = 要转换的类型(原数据)# 数据类型转换不会改变原数据类型,会生成一个新的变量
age = input('请输入你的年龄:')
print(type(age),age)
# 需求,将字符串的18转换为int类型的18
new_age = int(age) # 数据类型转换不会改变age的类型,生成一个新的数据保存到new_age
print(type(age),age)
print(type(new_age),new_age)
int()将其他类型转换为int类型
float类型可以转换成int类型 # 小数可以转换成整型
整数类型的字符串才可以转换为int类型 3,18
float()将其他类型转换为float类型
int类型可以转换成float类型
数字类型的字符串都可以转换成float类型
str()将其他任意类型转换为字符串类型加引号
python交互式执行代码
打开consle
进行小的代码验证,每行代码都会有一个执行结果
格式化输出
python中想要进行输出,使用的函数是print
按照一定的格式,在字符串中使用变量,将变量的值进行输出
name = "小明"
age = 18
sex = "男"
# 我的名字是XX,年龄是XX,性别为XX
print(f'我的名字是{name},年龄是{18},性别为{sex}')
字符串.forma()
1.可以在任意的python版本中使用
2.字符串中需要使用变量的地方,使用{}进行占位
3.在format的括号中,按照占位的顺序,将变量写上去
F-string
1.3.6版本开始使用
2.在字符串前加上f或者F
3.字符串中需要使用变量的地方,使用{}进行占位
4.将变量直接写在占位的大括号中
name = "小明"
age = 18
sex = "男"
# 我的名字是XX,年龄是XX,性别为XX
print(f'我的名字是{name},年龄是{18},性别为{sex}') # F-string 先写f'',在引号内输出格式文字,变量用大括号填写补充
print('我的名字是{},年龄是{},性别为{}.'.format(name,age,sex)) # foramt,先写'',内部文字格式加大括号占位,大括号里面不写变量,最后一个大括号加·,引号外.format加大括号,填上占位的变量名
练习
# 提示用户输入两个数字 inptu --> str
a = float(input('请输入两个数字,第一个数字为:'))
b = float(input('请输入第二个数字:'))
# 输出计算结果
sum = a + b
print(f'{a}+{b} = {sum}')
转义字符
将两个字符进行转义,表示一个特殊的字符
\n 换行,回车
\t 制表符,tab键
print('hello')
print('hello\nworld')
print('hello\tpython')
hello
hello
world
hello python
Process finished with exit code 0
print( end = ‘\n’) print函数中默认有一个"end = ‘\n’,所以,每个print结束后,都会输出一个换行
运算符
算术运算符

** 幂、次方 2**3 = 2的三次方
优先级
() >** > */÷>+、-
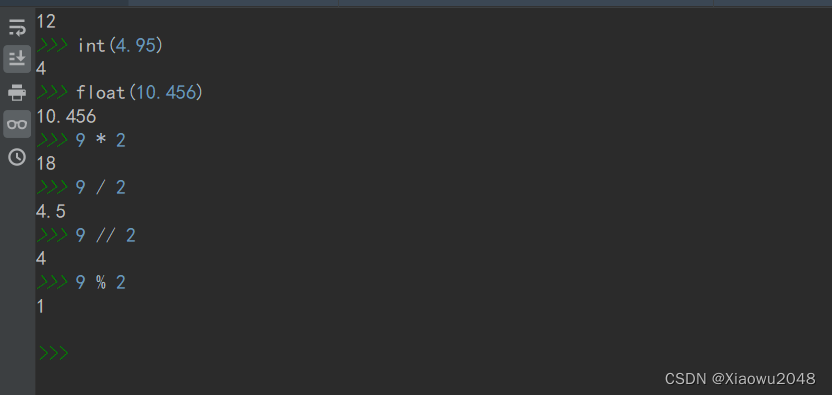
除法运算得到的都是浮点数
%的使用场景:判断一个数是不是偶数,能被二整除的数是偶数
数字除以2余数是0
比较运算符

得到的结果是bool类型

大于,小于,大于等于,小于等于只能是相同类型之间比较(数字和字符串之间不能比较)

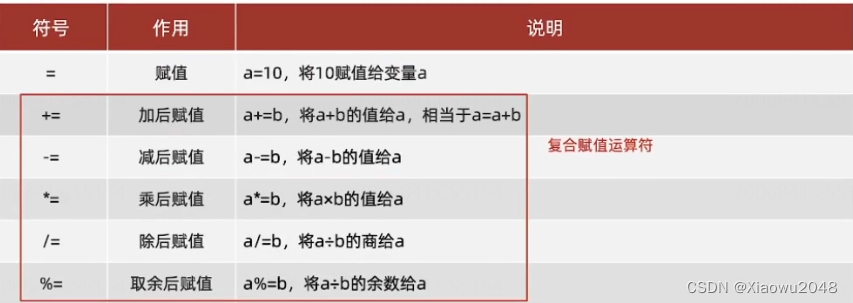
赋值运算符

逻辑运算符
and or not 是关键字
and 逻辑与并且,连接两个条件,只有都为TRUE结果才为True,一假为假
==or ==逻辑或 或者,连接两个条件,只要一个条件是true为true,结果就为true,一真为真
not 逻辑非 取反,本来是true,加上not 变为false

不同的运算符默认具备不同的优先级
小括号的优先级最高,当无法确定谁的优先级高时,加一个小括号就解决了
练习
# 提示用户输入值,保存到变量中
name = input('请输入姓名:')
age = int(input('请输入年龄:'))
height = float(input('请输入身高:'))
print(f'姓名{name},年龄{age},身高{height}')
new_age = age + 5
print(f'张三5年之后的年龄是{new_age}')
print(f'张三是否成年:{new_age > 18}')
流程控制:
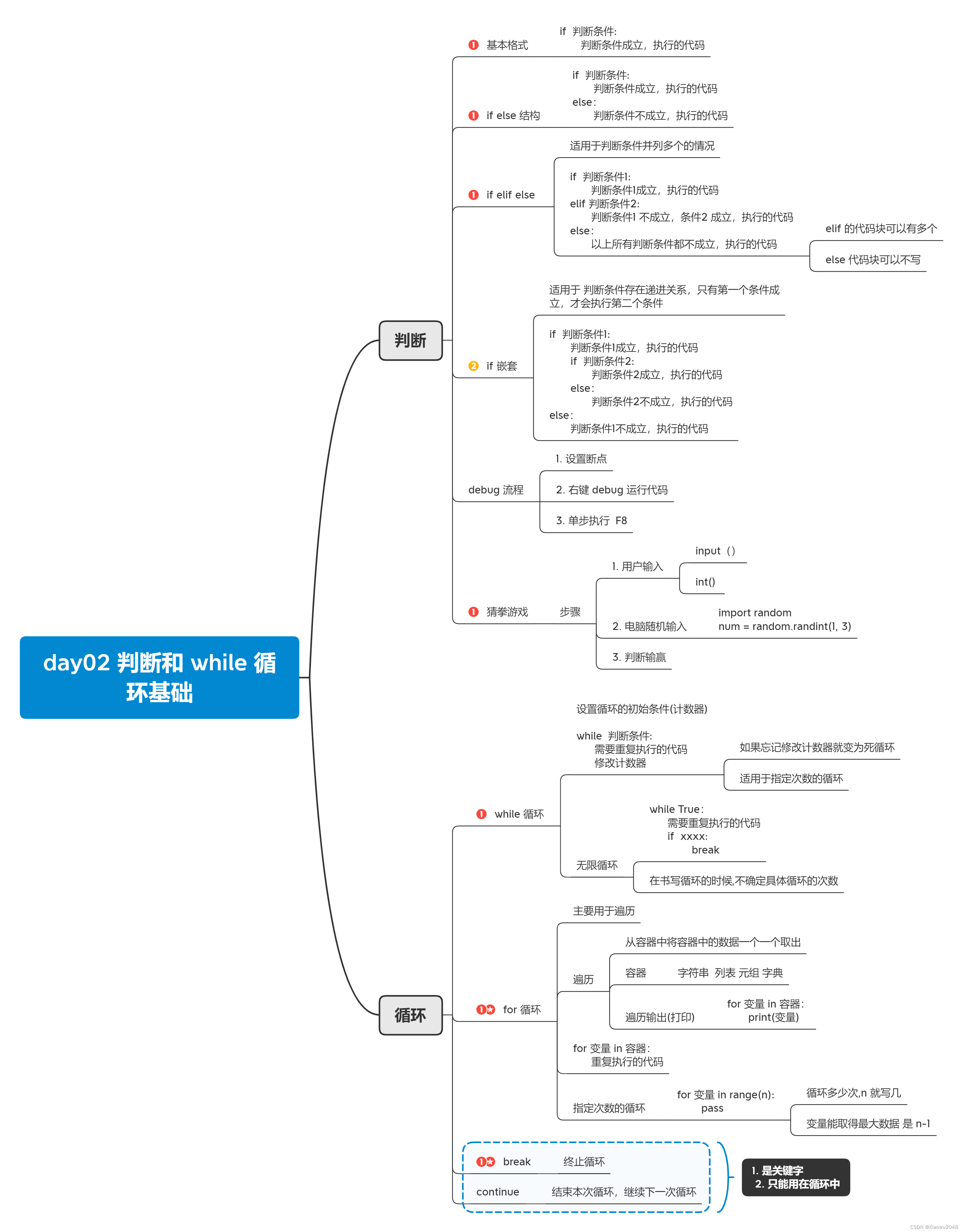
判断(如果。。。否则。。。):if(如果)elif(如果)else(否则)
循环(重复做某些事):while(直到)for in(在)break(终止) continue(继续)
pass 空语句,可以占位
if 判断的基本结构
程序执行的三大结构
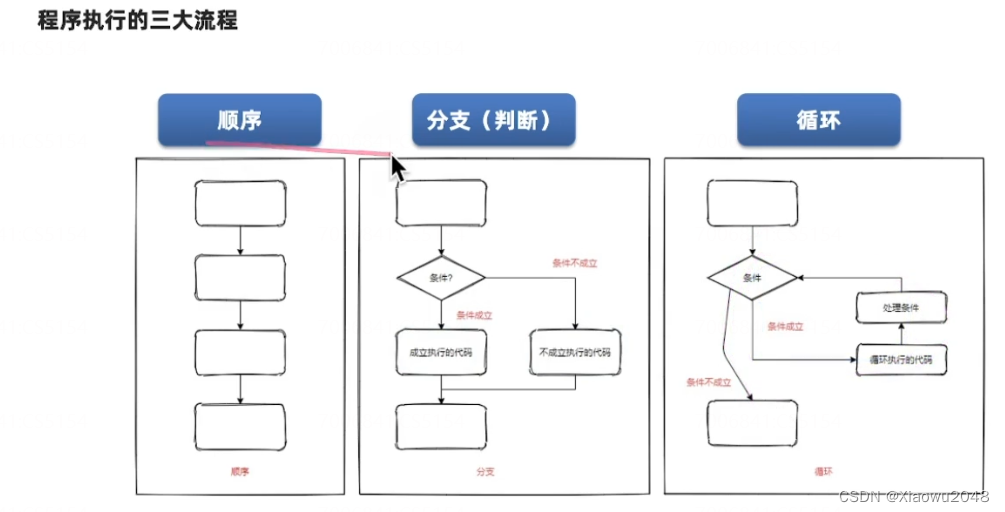

if语句的基本结构
介绍
单独的if语句,即是如果条件成立,做什么事
语法
if 判断条件:
判断条件成立,执行的代码
判断条件成立,执行的代码
这行代码和if判断无关 # 在if的代码结构外
1,if 语句后面需要一个冒号
2,冒号之后需要回车缩进
3,处在if语句的缩进中的代码可以称为是if语句的代码快(多行代码)
4,if语句代码块中的代码,要么执行,要么不执行
5,如果某行代码和if的判断无关,就不需要写在if的缩进中

age = int(input('请输入年龄:'))
# 判断年龄是否满18岁 >=
if age >= 18:
print('允许进入网吧嗨皮')
else:
print('好好学习')
print('在缩进之外,这行代码和if无关')
练习

name = input('请输入用户名:')
if name == 'admin':
print('欢迎admin登录')
if-else结构
if 判断条件:
判断条件成立,执行的代码
else:
判断条件不成立,执行的代码
1.else是关键字,后面需要冒号
2.存在冒号,就需要回车和缩进
3.处于else缩进中的代码,称为else语句的代码块
4.else不能单独使用,必须配合if使用,并且else要和if对齐
5.if和else之间不能有顶格书写的东西

age = int(input('请输入年龄'))
if age >= 18:
print('允许进入网吧哈皮')
else:
print('回家写作业')

name = input('请输入名字:')
if name == 'admin':
print('欢迎admin登录')
else:
print('用户名错误!')
if和逻辑运算符结合
逻辑运算符 and not or

name = input('请输入名字:')
password = int(input('请输入密码'))
if name == 'admin' and password == 123456:
print('登陆成功')
else:
print('登录信息错误!')

python_score = float(input('python_score成绩为:'))
c_score = float(input('c_score成绩为:'))
if python_score > 60 or c_score > 60: # 使用逻辑运算符连接,一真全真
print('合格')
else:
print('不合格')

name = input('请输入用户名:')
if name == 'admin' or name == 'test':
print(f'欢迎{name}登录')
else:
print('查无此人')
name = input('请输入用户名:')
if name == 'admin':
print('欢迎admin登录')
elif name == 'test':
print('欢迎test登录')
else:
print('查无此人')
多重判断
if elif else 结构
如果。。。如果。。。否则。。。
if 判断条件1:
判断条件1成立,执行的代码
elif:
判断条件2成立,执行的代码
elif:
pass
else:
以上 判断条件都不成立,才会执行的代码
1.elif是关键字,后面需要冒号,回车和缩进
2.if elif else 的代码结构,如果某一个条件成立,其他的条件就都不会判断

score = float(input('请输入考试成绩:'))
if score >= 90:
print('优')
elif score >= 80 and score < 90:
print('良')
elif score >= 70 and score < 80:
print('中')
elif score >= 60 and score < 70:
print('差')
else:
print('不及格')
debug的使用
使用debug的目的,认为就是查看代码的执行过程
步骤:
1.打断点
断点的意义,debug运行的时候,代码会在断点的地方停下来
如果想要查看代码的执行过程,建议将断点放在第一行
在代码和行号之间点击,出现的红色圆圈,就是断点,再次点击,可以取消
pycharam软件存在的问题,想要debug运行,可能会至少需要两个断点
2.右键debug运行
3.单步执行,查看执行过程
切换到console界面

if 嵌套
在一个if语句中嵌套另一个if (elif,else)语句
判断条件关系存在递进关系才会使用,即只有第一个条件成立,才会判断第二个条件
语法
if 判断条件1:
判断条件1成立时,执行的代码
if 判断条件2:
判断条件2成立时,执行的代码
else:
判断条件2不成立时。执行的代码
else:
判断条件1不成立,执行的代码

# xiaowu
password =input('请输入密码是:')
if password == '123456' :
print('密码正确')
money = float(input('请输入取款金额:'))
if money <= 1000:
print('取款的金额小于存款金额')
else:
print('取款的金额大于存款')
else:
print('密码错误,请重试')
if的循环嵌套
pwd = input('请输入密码:')
if pwd == '123456':
print('密码正确')
money = int(input('请输入取款金额:'))
if money > 1000:
print('余额不足')
else:
print('取款中。。。。')
print('请收好现金。。。。')
else:
print('密码错误,请重新输入')
案例-石头剪刀布

import random
player = int(input('请出拳 石头1、剪刀2,布3'))
computer = random.randint(1,3)
if (player == 1 and computer == 2) or (player == 2 and computer == 3 ) or (player == 3 and computer == 1) :
print('玩家胜利')
elif player == computer:
print('平局')
else:
print('电脑胜利')
循环的基本结构
让·指定的代码重复的执行
while 循环
1.循环的初始条件(计数器)
循环的终止条件
while 判断条件:
判断条件成立执行的代码
判断条件成立执行的代码
判断条件成立执行的代码
计数器加1
1.处于while缩进中的代码,称为while的循环体
2.执行循序123 23 23 2(条件不成立,结束)
代码
# 1、定义计数器
i = 0
# 2、循环的终止条件
while i < 100:
print('哈哈哈')
# 3.计数器加1
i = i + 1
无限循环和死循环
死循环和无限循环 在程序执行层面看起来是一样的,都是代码一直执行不能停止
死循环:是由于写代码的人不小心造成的
无限循环:是写代码的人故意这么写的
无限循环中,一般会存在if判断语句,当这个判断语句条件成立,执行break语句,来终止循环
关键字:break:当程序代码遇到break,break所在的循环都会被终止执行
关键字:continue 当程序代码遇到continue.continue后续的代码不会执行,但会继续下一次的循环(结束本次循环,继续下一次循环)
break 和continue 只能用在循环中
无限循环:
while True:
XXXX
XXXX
if XXX:
break
XXX
#while True 无限循环,后面加上循环的代码,if后面加上满足什么条件退出循环
循环版本的石头剪刀布
import random
while True:
player = int(input('请出拳 石头1、剪刀2,布3、退出0:'))
computer = random.randint(1,3)
if player == 0: # if判断,如果输入0,直接break,终止循环,退出
break
if (player == 1 and computer == 2) or (player == 2 and computer == 3 ) or (player == 3 and computer == 1) :
print('玩家胜利')
elif player == computer:
print('平局')
else:
print('电脑胜利')
import random
count = 0
while True:
player = int(input('请出拳 石头1、剪刀2,布3、退出0:'))
computer = random.randint(1,3)
if player == 0:
break
if (player == 1 and computer == 2) or (player == 2 and computer == 3 ) or (player == 3 and computer == 1) :
print('玩家胜利')
count += 1
if count == 3:
print('赢了三次,退出')
break
elif player == computer:
print('平局')
else:
print('电脑胜利')
1-100之间的累加和;
# 1、定义计数器
i = 1
num = 0
while i <= 100:
num = num + i
i += 1
print(num) # 求和的结果只需要打印1次,所以放在循环的外面
# 累乘
i = 1
num = 1
while i <= 3:
num = num * i
i += 1
print(num)
循环的使用
for 循环 – for遍历
遍历:从容器中将数据逐个取出的过程,也可以做指定字数的循环
容器:字符串、列表、元组、字典
for 循环遍历字符串
for 变量 in 字符串:
重复执行的代码
1,字符串中存在多少个字符,代码就执行多少次
2.每次循环会从字符串中取出一个字符保存到前面的变量中
3,for 和in都是关键字
str1 = 'abcd'
for i in str1:
print('hahha') # 打印4次,因为字符串内有四个(有多少内容,循环多少次)
for 指定次数的循环:
for 变量 in range(n): n就是要循环的次数
重复执行的代码
1,range(n)可以生成【0,n)的序列 左闭右开
for i in range(5): # [0,1,2,3,4]
print('haha')
for 循环实现0-100数的累加
num = 0
for i in range(101):
num = num + i
i += 1
print(num)

while True:
name = input('请输入登录名:')
if name == 'exit':
break
pwd = input('请输入登录密码:')
if name == 'admin' and pwd == '123456':
print('登录成功')
break
else:
print('用户名或密码错误,请重新输入')
字符串的定义
使用引号(单引号,双引号,三引号)引起来的内容,就是字符串
# 1.使用单引号
str1 = 'hello'
# 2、使用双引号
str2 = "hello"
# 3、使用三引号
str3 = """hello"""
str4 = '''hello'''
print(type(str1),type(str2),type(str3),type(str4))
<class ‘str’> <class ‘str’> <class ‘str’> <class ‘str’>
如果字符创本身就包含单引号,定义的时候不能使用单引号
如果字符串本身包含双引号,定义的时候不能使用双引号
str5 = "I'am 小明"
print(str5)
# 5、转义字符 \n \t \
str6 = 'I\'am 小明'
print(str6)
I’am 小明
I’am 小明
# 6、I\'m 小明 \\ --> \
str7 = 'I \\\'m 小明'
print(str7)
# 7、原生字符串在字符串的前面加上r"",字符串中的\就不会进行转义
str8 = r'I\\\'m 小明'
print(str7)
I 'm 小明
I 'm 小明
下标(索引)
1、下标(索引),是数据在容器(字符串,列表,元组)中的位置,编号
2、一般来说,使用的是正数下标,从0开始
3、作用:可以通过下标来获取具体位置的数据,使用的语法为容器【下标】
4、python中支持负数下标,-1表示最后一个位置的数据

str1 = 'abcdef'
# 需求:打印输出字符串中的a字符
print(str1[0])
print(str1[-6])
str1 = 'abcdef'
# 需求:打印输出字符串中的a字符
print(str1[0])
print(str1[-6])
# 需求:打印输出最后一个字符(-1)
print(str1[-1])
# 打印下标为3的位置的字符
print(str1[3])
切片
1、使用切片操作,可以一次性获取容器中的多个数据(多个数据之间存在一定的规律,数据的下标是等差数列(相邻的两个数字之间的差值是一样的))
2、语法 容器【start: end:step】 # 【开始下标:结束下标:隔几个再取】
start 表示开始位置的下标
end 表示结束位置的下标,但是end对应的下标位置的数据是不能取到的
step 步长,表示的意思是相邻两个坐标的差值
start,start+step,start+step*2,,,end(取不到)
步长是1,可以省略不写
开始下标为0可以省略不写
如果取到最后一个数据,end可以不写,但是冒号不可以少,且end下标的元素取不到
my_str = 'abcdefg'
# 打印字符串abc start 0,end 3 ,step 1
print(my_str[0:3:1]) # 从下标为0的元素a开始取,取到下标为3,但是3取不到,相邻两个下标的差是1
# 如果步长是1,可以不写
print(my_str[0:3])
# 如果start开始的位置下标为0,可以不写,但是冒号不能少
print(my_str[:3])
# 打印字符串中的efg,start 4,end 7 ,step 1
print(my_str[4:7])
# 如果取到最后一个字符,end可以不写,但是冒号不能少
print(my_str[4:])
# 打印字符串中的aceg,start 0,end 7(最后),步长2
print(my_str[::2])
# 特殊情况,步长为-1,反转字符串
print(my_str[::-1])
abc
abc
abc
efg
efg
aceg
gfedcba
字符串查找方法 find()
字符串.find(sub_str)# 在字符串中查找是否存在sub_str这样的字符串,返回值(这行代码执行的结果)
1、如果存在sub_str,返回第一次出现sub_str位置的下标
2、如果不存在sub_str,返回-1
my_str = '哈哈程序员'
sub_str = '哈哈'
result = my_str.find(sub_str)
if result == -1 :
print('哈哈不存在')
else:
print(f'{sub_str}存在,下标位置为:',result)
哈哈存在,下标位置为: 0
字符串替换方法 replace()
字符串.replace(old,new,count) # 将字符串中的old字符串替换为new字符串
- old 原字符串,被替换的字符串
- new 新字符串,要被替换的字符串
- count 一般不写,表示全部替换,可以指定替换的次数
返回:会返回一个替换后的完整的字符串
注意:原字符串不会改变
my_str = 'good good study'
# 需求:将good替换为GOOD
my_str1 = my_str.replace('good','GOOD')
print(my_str)
print(my_str1)
# 将第一个good替换为GOOD
my_str2 = my_str.replace('good','GOOD',1)
print(my_str2)
# 将第二个goog换成GOOD
# 先整体替换为GOOD,再将第一个GOOD替换为good
my_str3 = my_str.replace('good','GOOD').replace('GOOD','good',1)
print(my_str3)
good good study
GOOD GOOD study
GOOD good study
good GOOD study
字符串的拆分split()
- 字符串.split(sep)# 将字符串按照指定的字符串sep进行分隔
- 不传入分隔符,默认以空格进行拆分
返回:列表,列表的每个数据就是分隔后的字符串
str1 ='hello python\t and itcast and \n hahha'
# 默认按照空白分隔
list1 = str1.split()
print(list1) # ['hello', 'python', 'and', 'itcast', 'and', 'hahha']
# 按照空格进行划分
list2 = str1.split(' ')
print(list2) # ['hello', 'python\t', 'and', 'itcast', 'and', '\n', 'hahha']
# 按照and进行划分
list3 = str1.split('and')
print(list3) # ['hello python\t ', ' itcast ', ' \n hahha']
字符串连接join()
字符串.join(容器) # 容器一般是列表,将字符串插入列表相邻的两个数据之间,组成新的字符串
注意点:列表中的数据必须都是字符串才可以
list1 = ['hello', 'python', 'and', 'itcast', 'and', 'hahha']
# 将列表中的数据使用空格组成新的字符串
str1 = ' '.join(list1)
print(str1) # hello python and itcast and hahha
# 使用逗号连接
str2 = ','.join(list1)
print(str2) # hello,python,and,itcast,and,hahha
点出来的都是方法,均可使用

列表的定义
1、列表 list 使用【】
2、列表可以存放任意多个数据
3、列表中可以存放任意类型的数据
4、列表中的数据按照逗号分隔
# 方式1 使用类实例化的方式
# 1.1 定义空列表 变量 = list()
list1 = list()
print(type(list1),list1) # <class 'list'> []
# 1.2 定义非空列表,也称为类型转换 list(可迭代类型) 可迭代类型,能够使用for循环就是可迭代类型(比如 容器)
list2 = list('abcd')
print(list2) # ['a', 'b', 'c', 'd']
# 方式2 直接使用[]进行定义(使用较多)
# 定义空列表
list3 = [] # []
print(list3)
# 定义非空列表
list4 = [1,3.14,'hello',False] # [1, 3.14, 'hello', False]
print(list4)
列表支持下标和切片
列表的切片得到的是新的列表
字符串的切片得到的是新的字符串
如果下标不存在,会报错
# 获取列表的第一个数
print(list4[0])
# 获取列表的最后一个数
print(list4[-1])
# 获取中间两个数
print(list4[1:3:1]) # 步长为1,可省略不写
列表查找方法
index()方法
index()这个方法的作用和字符串中的find()的作用是一样的
列表中没有find()方法,只有index()方法
字符串中同时存在find和index方法
index()
1、找到返回下标
2、没有找到,直接报错
count()
列表.count() # 统计指定数据在列表中存在的次数
list1 = ['hello',2,3,2,3,4]
# 查找2出现的下标
num = list1.index(2)
print(num) # 1
# 统计数据2出现的次数
num1 = list1.count(2)
print(num1) # 2
# 统计20出现的次数
num2 = list1.count(20)
print(num2) # 0
列表添加和删除方法
列表.appen(数据) # 想列表的尾部添加数据
返回:none ,所以不用使用 变量 = 列表.append()
直接在原列表中添加数据,不会生成新的列表,如果想要查看田间后的数据,直接print()打印原列表
删除数据pop()
列表.pop(index) # 根据下标删除列表中的数据
index可以不写,默认删除最后一个
返回,删除的数据
# 定义空列表
list1 = []
print(list1)
# 添加数据
list1.append('张三')
print(list1)
list1.append('李四')
list1.append('王五')
print(list1)
# 删除最后一个数据
list1.pop()
print(list1)
#删除列表中第二个数据
name = list1.pop(1)
print(f'删除的对象为:',name)
print(list1)
列表的修改和反转方法
想要修改列表中的数据,直接是所有下标即可
列表【下标】 = 新数据
my_list = [1,2]
my_list[0] =10
print(my_list) # [10, 2]
my_list[-1] = 20
print(my_list) # [10, 20]
my_list[10] = 34
print(my_list) # IndexError: list assignment index out of range
列表的反转reverse
字符串 反转 字符串【::-1】
列表反转:
1、列表【::-1】得到一个新的列表,原列表不会改动
2
列表reverse()直接修改原列表的数据
my_list = ['a','b','c','d','e']
# 1、切片
my_list1 = my_list[::-1]
print('my_list',my_list)
print('my_list1',my_list1)
# 2 reverse
my_list.reverse()
print('my_list:',my_list)
my_list [‘a’, ‘b’, ‘c’, ‘d’, ‘e’]
my_list1 [‘e’, ‘d’, ‘c’, ‘b’, ‘a’]
my_list: [‘e’, ‘d’, ‘c’, ‘b’, ‘a’]
列表的排序
前提:列表中的 数据要一样
列表.sort() # 升序,从小到大,直接在原列表中进行排序
列表.sort(reverse= True)# 降序,从大到小,直接在原列表中排序
my_list = [1,4,7,2,5,8,3,6,9]
# 排序 升序
my_list.sort()
print(my_list)
# 降序
my_list.sort(reverse=True)
print(my_list)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[9, 8, 7, 6, 5, 4, 3, 2, 1]
列表嵌套
列表的嵌套就是指列表中的数据都是列表
student_list = [["张三","18","功能测试"],["李四","20","自动化测试"]]
# 张三
print(student_list[0][0])
# 李四
print(student_list[1][0])
# 张三的信息添加一个性别男
student_list[0].append('男')
print(student_list)
# 删除
student_list[0].pop()
print(student_list)
# 打印所有人员的年龄
for info in student_list: # info是列表
print([info[1]])
张三
李四
[[‘张三’, ‘18’, ‘功能测试’, ‘男’], [‘李四’, ‘20’, ‘自动化测试’]]
[[‘张三’, ‘18’, ‘功能测试’], [‘李四’, ‘20’, ‘自动化测试’]]
[‘18’]
[‘20’]
元组的操作tuple
1、元组tuple,使用()
2、元组和列表非常相似,都可以存储多个数据,都可以存储任意类型的数据
3、区别是元组的数据不能修改,列表的元素可以修改
4、因为元组中的数据不能修改,所以只能查询方法,如index,count,支持下标和切片
5、元组,主要用于传参和返回值
# 类实例化方式
# 定义空元组(不用)
tuple1 = tuple()
print(type(tuple1),tuple1) # <class 'tuple'> ()
# 类型转换,将列表(其他可迭代类型)转换为元组
tuple2 = ([1,2,3])
print(tuple2)
# 直接用()定义
# 定义空元组
tuple3 = ()
# 非空元组
tuple4 = (1,2,'3,14',True)
print(tuple4)
print(tuple4[2])
# 定义只有一个数据的元组,数据后必须有一个逗号
tuple5 = (10,)
print(tuple5)
交换两个变量的值
1、在定义元组的时候,小括号可以省略不写
2.组包(pack),将多个数据值组成元组的过程 a= 1,2 # a =(1,2)
3、拆包(解包unpack),将容器中多个数据分别给到多个变量,需要保证容器中元素的个数和变量个数保持一致
a = 10
b = 20
c = b,a # 组包
print(c)
a,b = c # 拆包
print(a,b)
a,b = b,a
print(a,b)
# m,n = (1,2,3) # ValueError: too many values to unpack (expected 2)
m,n,x = (1,2) # ValueError: not enough values to unpack (expected 3, got 2)
字典
1、dict,使用{}表示
2、字典由键key值value对组成,key:value
3、一个键值对是一组数据,多个键值对之间用逗号隔开
4、在一个字典中,字典的键是不能重复的
5、字典中的键主要使用字符串类型,可以是数字
6、字典中没有下标
# 类实例化的方式
my_dict1 =dict()
print(type(my_dict1),my_dict1)
# 直接使用{}定义
# 定义空字典
my_dict2 ={}
print(my_dict2)
# 定义非空字典,姓名,年龄,身高,性别
my_dict = {"name":'小明',"age":"18","height":1.78,"ismen":True}
print(my_dict)
<class ‘dict’> {}
{}
{‘name’: ‘小明’, ‘age’: ‘18’, ‘height’: 1.78, ‘ismen’: True}
字典的添加和修改
字典【‘键’】 = 值
1,键存在,修改
2,键不存在,添加
# 将年龄改为20
my_dict['age'] = 20
print(my_dict)
# 添加体重weight
my_dict['weight'] = 65
print(my_dict)
字典的删除
字典的删除是根据字典的键删除键值对
my_dict.pop('weight')
print(my_dict)
字典获取数据
根据key获取对应的value值
方法1:
字典【‘键’】 # 键不存在,会报错
方法2
字典.get(键) # 键不存在,发那会none
my_dict = {"name":'小明',"age":"18","height":1.78,"ismen":True}
# 获取name
print(my_dict['name'])
print(my_dict.get('name'))
# 获取性别
print(my_dict['sex']) # KeyError: 'sex'
print(my_dict.get('sex'))
字典的遍历
字典存在键,值,遍历分为三种情况
遍历字典的键
方式1:
for 变量 in 字典:
print(变量)
方式2:
for 变量 in 字典.keys(): # 字典.keys()可以获取字典所有的键
print(变量)
遍历字典的值
for 变量 in字典.values(): # 字典.values()可以获取字典中所有的值
print(变量)
遍历字典的键和值
for 变量1,变量2 in字典.items() : # 字典。item()获取的是字典的键值对
print(变量1.变量2)
my_dict = {"name":'小明',"age":"18","height":1.78,"ismen":True}
for key in my_dict:
print(key)
print('*' * 30)
for k in my_dict.keys():
print(k)
print('*' * 30)
for v in my_dict.values():
print(v)
print('*' * 30)
for k,v in my_dict.items():
print(k,v)
name
age
height
ismen
name
age
height
ismen
小明
18
1.78
True
name 小明
age 18
height 1.78
ismen True

in 操作符
in是python关键字
数据in容器,可以用来判断容器中是否包含这个元素,如果包含返回true,如果不包含返回false
对于字典来说,判断的是字典中是否含这个键
集合说明
集合 set,{数据,数据,。。。}
1、集合中的数据是不能重复的
2、应用,对列表进行去重操作,就是类型转换,可以将列表转换为集合,然后将集合转换为列表

列表去重案例
my_list = [1,2,1,2,5,6,7,2,3,6,7,8,4]
# 方式一 先转集合再转列表
list1 = list(set(my_list))
print(list1)
# 方式2
new_list = [] # 定义新列表,保存去重后的数据
#遍历原列表
for i in my_list:
# 判断是否存在新列表
if i in new_list:
# 什么都不做
pass
else:
# 追加到新列表
new_list.append(i)
print(new_list)
函数
print() 在控制台输出
input() 获取控制台输出的内容
type() 获取变量的数据类型
len() 获取容器的长度(元素的个数)
range() 生成一个序列 【0,n)
函数可以实现一个特定的功能
函数:将多行代码放在一块(可以实现一个特定的功能),并给他起个名字,在需要使用多行代码的时候,可以使用名字代替
定义函数的好处:减少代码的冗余(重复的代码不需要多次书写),提高编程的效率
def login():
print('1.输入用户名:')
print('2.输入密码:')
print('3.点击登录')
login()
login()
函数必须先定义好,再调用
定义:
1、函数定义,就是给多行代码取名字的过程
2、函数的定义需要使用关键字 def
def 函数名():
函数中的代码
函数中的代码
1、处在def缩进中的代码,都属于这个函数
2、函数名要满足标识符的规则,见名知意
3、def这行代码的最后需要一个冒号
4、函数定义不会执行函数中的代码,想要执行,需要调用
调用
1、就是使用多行代码的过程
2.语法 函数名()
定义函数的小技巧
1、先不使用函数,将多行代码写完
2、在多行代码的上方使用def起名字
3、使用tab键,将多行代码进行缩进

def say_hello():
print('say hello')
print('say hello')
print('say hello')
# 函数调用
say_hello()
say_hello()
say_hello()
函数的文档注释
1、函数的文档注释,本质就是主食,只不过作用和书写的位置有特定的要求
2、作用:是对函数的作用和使用方法进行说明,比如有哪些参数,返回值是什么
3、书写位置:在函数定义的下方。使用三对双引号书写
查看
1、在函数名上使用ctrl+q查看
2、在函数名上,使用快捷键ctrl B跳转导函数定义的地方查看
3、在函数名上,按住ctrl键,点击函数名,跳转到函数定义的地方查看
定义带参数的函数
参数:在函数定义的时候,在括号中写入变量,这个变量就称为是函数的参数,形式参数(形参)
在函数调用时,可以给定义时候的形参传递具体的数据值,供其使用,实际参数(实参)
即:在函数调用的时候,会将函数的实参值传递给形参
好处:可以让函数更加的通用,函数的数据值是不固定的,是调用的时候,你传递的
使用场景:判断函数中 数值是不是固定不变的,如果是变化的,就可以使用参数传递
注意点:目前书写的函数,如果存在形参,必须传递相同个数的实参

def sum_2num():
a = 10
b = 20
sum = a + b
print(sum)
sum_2num()
def sum_2_num(a,b):
sum = a + b
print(sum)
sum_2_num(12,34)
函数的嵌套使用
在一个函数中调用另一个函数
1、代码从上到下执行的
2、函数定义不会执行函数代码
3、函数调用会进入函数中执行函数的代码
4、函数中的代码执行结束,会回到调用的地方继续执行下去
def test01():
print(1)
print('func01')
print(2)
def test02():
print(3)
print('func02')
test01()
print(4)
print(5)
test02()
print(6)
5
3
func02
1
func01
2
4
6
函数返回值
返回值:函数执行的结果
print() --> none
input --> 键盘输入的内容,类型 字符串
type() -->变量的数据类型
len() -->容器长度
1、在一个函数中,想要返回一个数据(想要有返回值),需要使用return关键字
2、为什么要有返回值?在函数中可能通过各种代码,得到数据结果,想要在函数外部使用,就需要使用返回值
3、如果函数有返回值,一般在调用的时候,会使用变量来接收(保存)返回值,以便后续使用
4、return关键字作用
将一个数据值返回到调用的地址
函数遇到return会结束函数的执行
5、return关键字只能用在函数中
6、如果一个函数没有写return,可以认为返回none

def get_max(a,b):
if a > b:
return a
else:
return b
get_max(12,30) # 返回调用的结果,想要看到结果,需要用变量接收在输出
num =get_max(12,30)
print(num)
案例:

def input_username():
return input('请输入姓名:') # 想要在外部使用,就需要返回值
def input_password():
return input('请输入密码:')
def login():
if input_username() == 'admin' and input_password()== '123456':
print('登录成功')
else:
print('用户名或密码错误')
login()
模块的导入

模块
1、在python中每个代码文件都可以称为一个模块
2、在模块中别人书写号的功能(变量、函数、类),我们可以拿过来直接使用
3、我们自己写的代码文件,想要作为模块让别人使用,你的代码文件名(模块名)满足标识符的规则
4、想要是用别人写好的功能,需要导入别人写好的功能
5、as关键字,可以进行取别名操作

模块导入的方法
方法一
import 模块名 # 模块名 就是代码文件名
使用其中的功能
模块名.功能名 # 功能可以使变量。函数。类
多用于导入系统中的常用功能和模块
’方式二
from 模块名 import 功能名 # 导入指定的功能
使用
功能名()
多用于导入自己书写的,或者是第三方的模块
可以使用快捷键alt 回车

# import random
# num = random.randint(1,10)
# print(num)
from random import randint
num = randint(1,10)
print(num)

def sum_2_num(a,b):
sum = a + b
return sum
from tools import sum_2_num
num = sum_2_num(10,20)
print(num)
_name_的使用
1、导入模块的时候,会执行模块中的代码
2、如果在导入模块的时候,模块中的部分代码不想被执行,可以使用__name__来解决(两个下划线)
3、__name__变量,是python解释器内置的变量(变量的值是自动维护的),每个代码文件中,都有这个变量
在模块中直接运行 name 的值是 ‘main’
如果是被导入运行代码文件,__name__变量的值是模块名(文件名)


if name == ‘main’:
# 在这个if缩进中书写的代码,导入的时候不会被执行
模块的导入顺序
1、在导入模块的时候,先会从代码所在的目录进行导入
2、如果没有找到,会去pyhon系统的目录查找
3、如果没有找到,报错
– —注意:自己定义的代码文件名,不要和导入的系统的名称一致
包的介绍
包:将多个模块放在一个目录中几种管理,并在这个目录中创建一个__init__.py文件(可以什么都不写),就一个包
包的创建

包的导入
方式一:
import 包名.模块名
使用
包名.模块名.工具名
方式二:
from 包含 import 模块名
使用
模块名.工具名
方式三
from 包名.模块名 import 工具名
使用
直接使用工具名
使用快捷键导包

# from hm_message.send_message import send_msg
# from hm_message.receive_message import receive_msg
#
# msg1 = send_msg()
# msg2 = receive_msg()


range函数的补充
range(n)---->【0,n}
range(start,end,step) ---->[start,end) 步长是step,默认1
range(1,5,2)_ # [1,3]
range(1,101) # 1-100
引用
1、定义变量的时候,变量和数据都会在内存中开辟空间
2、变量所对应的内存空间中存储的是数据所在内存的地址(平时理解为将数据存储到变量中即可)
3、变量中保存的地址,就是称为引用
4、python中所有数据的传递,传递的都是引用(即地址)
5、赋值运算符(=),会改变变量的引用,即只有 = 可以修改变量的引用
6、可以使用id(变量),查看变量的引用
a = 1 # 本质:将数据1的地址保存到变量a中,通常理解:将1保存到a
b = a # 本质:将变量a中的引用保存到变量b中,通常理解为将a的值给到b
print(a,b)
print(f"a:{a},{id(a)}")
print(f"b:{b},{id(b)}")
a = 2 # 本质:将数据2的地址保存到变量a中,只是改变a的引用,即改变a的值,没有改变b的引用
print(f"a:{a},{id(a)}")
print(f"b:{b},{id(b)}")
1 1
a:1,1893625312
b:1,1893625312
a:2,1893625344
b:1,1893625312
my_list = [1,2,3] # 将数据[1,2,3]保存到my_list地址中
my_list1 = my_list # my_list1引用my_list地址
print(f'my_list:{my_list},{id(my_list)}')
print(f'my_list1:{my_list1},{id(my_list1)}') # 二者一致
my_list[1] = 10 # 修改了my_list地址中的变量
print(f'my_list:{my_list},{id(my_list)}')
print(f'my_list1:{my_list1},{id(my_list1)}') # my_list:[1, 10, 3],2689510535880 my_list1:[1, 10, 3],2689510535880
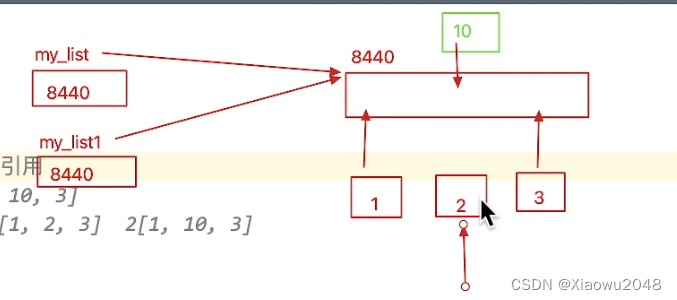
可变类型与不可变类型
根据内存中的数据是否允许修改,将数据类型分为可变类型与不可变类型
简单理解:不使用等号,能不能修改数据值
可变类型:可以修改
列表list lsit.append()
字典dict dict.pop()
集合set
不可变类型:不允许修改
数字类型:int flaot bool
字符串:str
元组 tuple
my_tuple = (1,2,[10,20])
print(my_tuple,id(my_tuple))
my_tuple[-1][-1] = 0
print(my_tuple,id(my_tuple)) # 元组内嵌套的列表,修改的是列表的值,列表是可修改变量
(1, 2, [10, 20]) 1867546109272
(1, 2, [10, 0]) 1867546109272
局部变量
1、在函数内部定义的变量,称为是局部变量
2、特点
局部变量,只能在当前函数内部使用
在不同函数内定义的名字可以相同
3、生命周期
在函数执行(调用)的时候被创建
函数执行结束被销毁
4、形参可以认为是局部变量
5、局部变量可以在外部被调用
def func1():
num = 10 # 局部变量
print(num)
def func2():
num = 20 # 不同的函数可以定义名称相同的局部变量
print(num)
if __name__ == '__main__':
func1()
func2() # 每个函数使用自己的局部变量
全局变量
1、在函数外部定义的变量
2、特点
全局变量可以在任意函数内访问(读取)
想要在函数内部修改全局边亮亮的引用,需要使用global关键字申明(使用关键字global可以申明为全局变量)
如果在函数内部出现和全局变量相同的局部变量,在函数内部使用的是局部变量
3、生命周期
代码执行的时候开始,执行结束时销毁
# 定义全局变量
g_num = 10
def func_1():
print(g_num) # 函数内部无同全局变量相同的局部变量,可以直接使用全局变量
def func_2():
g_num = 20 # 有和全局变量名相同的局部变量,使用局部变量
print(g_num)
def func_3():
global g_num # 声明为全局变量
g_num = 30 # 修改全局变量
print(g_num)
if __name__ == '__main__':
func_1()
func_2()
print(g_num) # 此处还未调用方法3,打印出来的还是全局变量
func_3() # 调用方法3,修改全局变量为30
func_1() # 此处调用时,全局变量已修改
10
20
10
30
30
def func1():
list1.append(10)
def func2():
list1 = [1,1] # 定义的局部变量
list1.append(0)
def func3():
global list1 # 申明全局变量
list1.pop() # 删除最后一个元素
# def func_5():
# list1.pop() # 上面申明了全局变量,这里使用的也还是全局变量
def func4():
global list1 # 全局变量
list1 = [1]
if __name__ == '__main__':
list1 = [1,2]
func1() # [1, 2, 10]
print(list1)
func2()
print(list1) # 此时的list1还是全局变量 [1, 2, 10]
func3()
print(list1) # 此时全局变量已经被global进行修改了
# func_5()
print(list1)
func4()
print(list1)
函数返回多个数据值
return 关键字两个作用:
1、返回数据值
2、结束函数的运行
函数中想要返回多个数据值,一般是组成元组·的格式
def calc(a,b):
"""返回两个数的和以及差"""
return a+b,a-b
result = calc(30,7)
print(result)
(37, 23)
函数传参的方式
是指如何将实参的值传递给形参
位置传参
在函数调用的时候按照形参的顺序将实参的值传递给形参
关键字传参
在函数调用的时候,指定将实参传递给哪个形参
混合使用
1、位置参数必须写在关键字参数的前面
2、同一个形参只能接收一个实参值(不能即使用位置传参和关键字传参给同一个形参传参)
def show_info(name,age):
print(f"name:{name},age:{age}")
# 位置传参
show_info('小明',18) # 按照位置顺序,将实参传递给形参
# 关键字传参
show_info(age = 18,name = '张三') # 将指定的实参传递给形参
# 混合使用
show_info('李四',age=17) # 李四实参通过位置传参传递给name ,后面的age =17 通过关键字将实参传递给形参
缺省参数(默认参数)
在函数定义的时候,给形参一个默认的数据值,这个参数就是缺省参数(默认参数)
特点:
在函数调用的时候,缺省参数可以不用传递实参值
1、如果不传递实参值,使用的就是默认值
2、如果传递的是实参值,使用的就是传递的实参值
注意点:
缺省参数必须写在普通参数的后边
"""定义show_info参数 姓名,年龄,性别,将"年龄设置为默认值18,性别默认保密"""
def show_info(name,age = 18,sex = "保密"):
print(name,age,sex)
# 调用
show_info('张三',18,'男')
show_info("小明")
show_info('王五',19)
show_info('赵六',sex= '男') # 根据位置传参的话,男会传递给age,所以这里只能使用关键字传参
多值参数(可变参数/不定长参数)
1、在函数调用时,不确定在调用时,实参有多少个,此时可以使用多值参数
2、在普通参数的前面加上一个*,这个参数就会变成多值参数
3、这个参数可以接收任意多个位置传参的数据,类型元组
4、这个形参一般写作agrs(arguments),即* args
例:
print(1)
print(1,2)
print(1,2,3)
参数顺序:
普通 缺省 多值
def 函数名(普通,*args,缺省):
pass
def func(*args):
print(args)
func() # 空元组
func(1,2,3,4) # (1, 2, 3, 4)
在函数调用时拆包
定义一个函数,可以对多个任意数字进行求和计算
def my_sum(*args):
num = 0 # 定义初始变量0
for i in args: # args是元组,利用for循环遍历取出里面的元素
num += i
return num
result = my_sum(1,2,3,4)
print(result)
def my_sum(*args):
num = 0 # 定义初始变量0
for i in args: # args是元组,利用for循环遍历取出里面的元素
num += i
return num
result = my_sum(1,2,3,4)
print(result)
my_tuple = [1,2,3,4,5]
# 需求对列表中的所有数据使用my_sum函数求和
# 想要把列表(元组)中的数据作为位置参数进行传递,只需要在列表(元组)前面加上一个*,进行拆包即可
print(my_sum(*my_tuple))
匿名函数
使用lambda关键字,定义的表达式,称为匿名函数
语法:
lambda 参数, 参数:一行代码 # 只能实现简单的功能,只能写一行代码
匿名函数一般不直接调用,作为函数的参数使用
"""定义匿名函数,可以对两个数字求和"""
func = lambda a,b:a + b # 匿名函数不接受直接调用,想要调用的话需要命名接收
print(func(1,2))

练习

因为定义的是形参,所以我们说是什么类型就是什么类型,最终的类型是由实参来定义的
匿名函数的应用

user_list = [
{'name':'张三','age':22,'title':'测试工程师'},
{'name':'张四','age':23,'title':'开发工程师'},
{'name':'张五','age':20,'title':'测试工程师'}
]
# user_list.sort()只能对数字,字符串排序
# 根据字典的age键排序
# 列表.sort(key)
# 想要对列表中的字典进行排序,需要key形参来指定根据字典中的什么键排序
# key这个参数需要传递一个函数,使用匿名函数
# 列表.sort(key = lambda x :x['键']
# user_list.sort(key = lambda x :x['age'])
# print(user_list)
# 因为key需要传递一个函数,假设使用def函数定义
def fun(x):
return x['age']
user_list.sort(key = fun)
print(user_list)
案例-学生管理系统


# 定义一个列表,保存所有学生信息
stu_list = []
def make_student():
"""录取单个学生信息"""
name =input('请输入姓名:')
age = input('请输入年龄:')
# 将学生信息存入字典
stu_dict = {"name":name,"age":age}
# 返回单个学生信息
return stu_dict
def show_stu_info():
"""展示学生信息"""
print('-----------学生列表信息----------')
j = 1 # 初始序号
for stu_dict in stu_list: # stu_dict字典
print(f"{j}\t{stu_dict.get('name')}\t{stu_dict.get('age')}")
j += 1 # 修改序号
print('----------------------------------')
def get_student_count():
"""获取学生的数量"""
return len(stu_list)
def search_student():
"""查询学生的信息"""
name = input('请输入要查询的学生信息:')
for stu_dict in stu_list:
if name == stu_dict.get('name'):
# 找到了这个学生
print(f'姓名:{name},年龄:{stu_dict.get("age")}')
# 终止break return
return # 结束函数的执行
# 写在函数的外面
print(f'对不起,没有找到[{name}]的学生')
if __name__ == '__main__':
for i in range(3):
student = make_student()
# 需要将单个学生添加到列表
stu_list.append(student)
show_stu_info()
print('学生总数为:',get_student_count())
search_student()
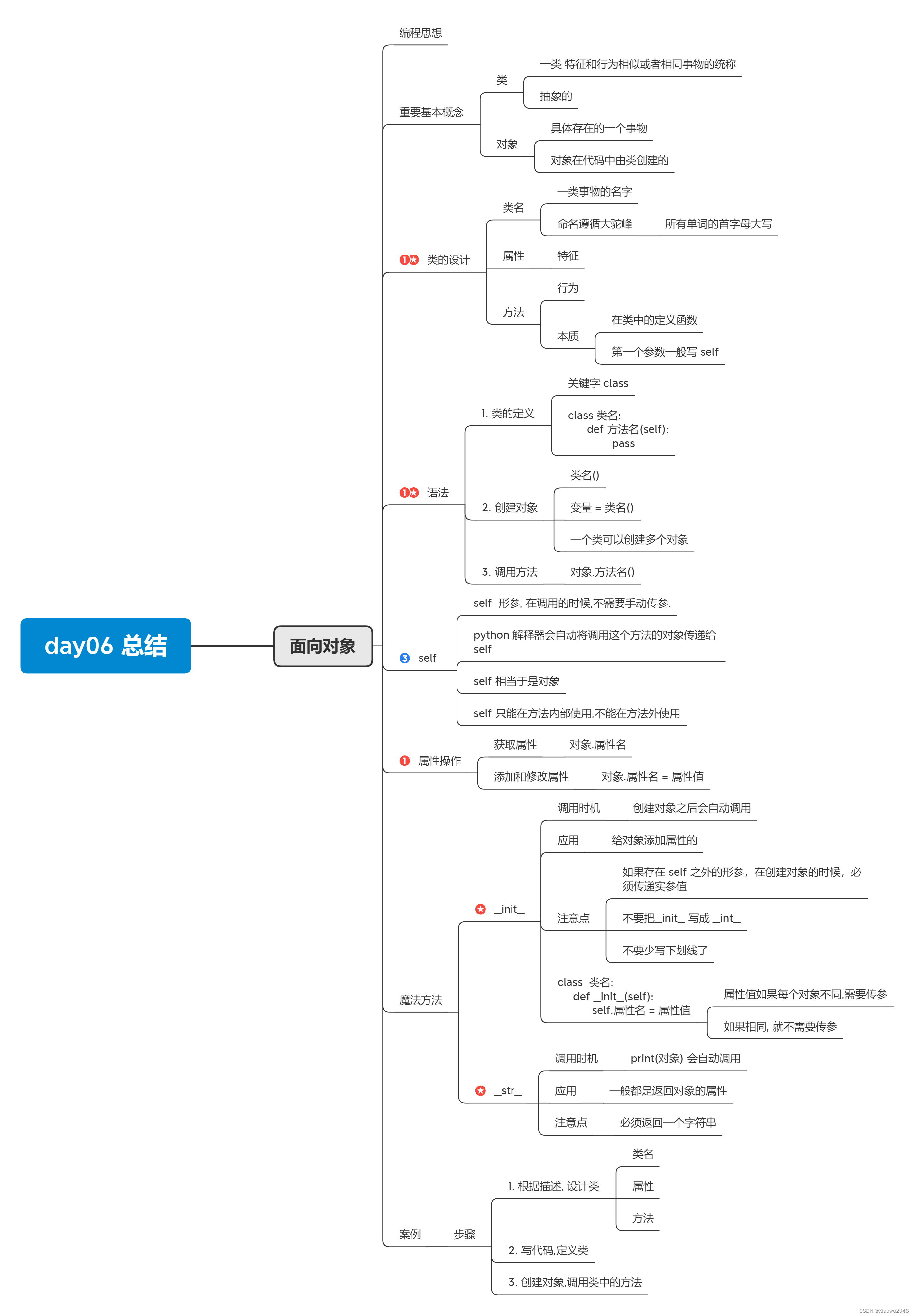
面向对象介绍

面向对象 是一种编程思想(即指导如何写代码的),适用于中大型项目
面相和过程也是一种编程思想,适用于小型项目
面向过程和面向对象,都可以实现某个编程的目的
面向过程考虑的是实现的细节
面向对象考虑的是结果(谁能做这件事)
类与对象
类和对象是面向对象编程最重要的概念
类: 是指具有相同特征或行为的事物的一个统称,是抽象的,不能直接使用
指代多个事物
代码中 类是由关键字class定义
对象:是由类创建出来的一个具体存在的事物,可以直接使用
指代一个具体事物
代码中使用类去创建(实例化)
苹果 --> 类
红苹果 --> 类
小明手里的那个红苹果 —> 对象
狗 —> 类
大黄狗 -->类
李四家的大黄狗 —>对象
类的构成
类的构成,类的三要素
1、类名(多个事物,起一个名字,标识符规则,见名知意,类名满足大驼峰命名法(所有单词的首字母大写))
2、属性(事物的特征)
3、方法(事物的行为)
面向对象的代码步骤
1、设计类(找类的三要素)
2、定义类
3、创建对象(实例化对象)
4、由对象调用类中的方法
类的设计
类的设计就是去找三要素。属性和方法可能会很多,我们只需要找到我们需要的就可以
类名的提取:使用名词提取法。分析整个业务流程,得出的名词,通常就是类名
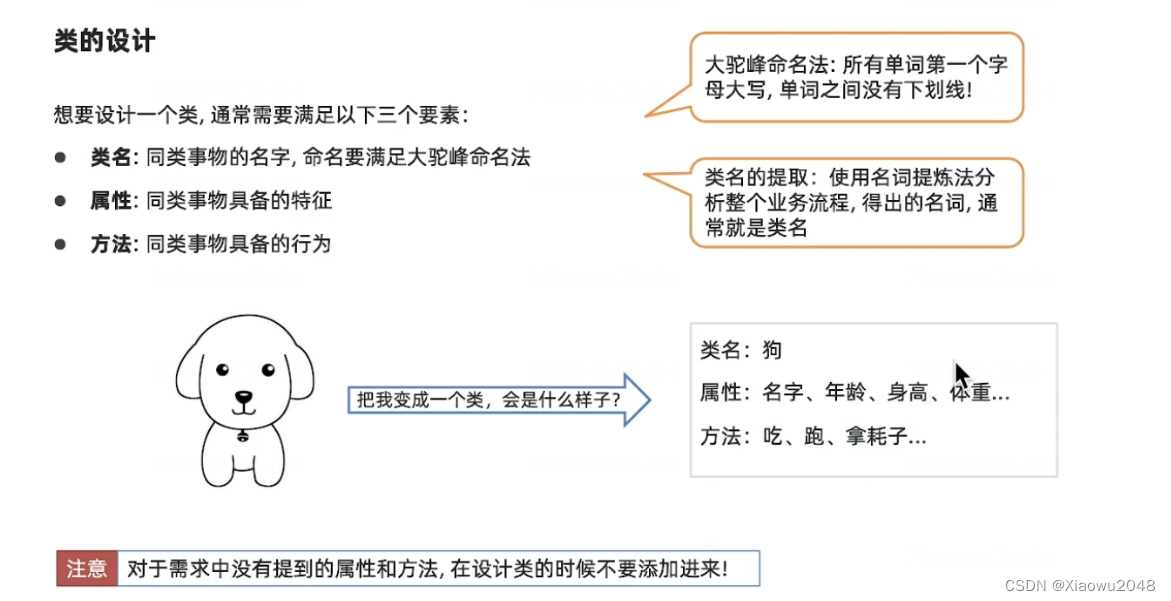

类名:人类 Person People Human
属性:姓名(name),年龄(age),身高(height)
方法:跑(run)、吃(eat)

类名:狗类
属性:颜色(color),名字(name)
方法:叫(bark),摇尾巴(shake)

类名:LoginPage
属性:用户名(username),密码(password),验证码(verify_code),登录按钮(login_btu)
方法:登录方法(login)
定义基本的类
定义类
在python中定义类使用关键字class
class 类名:
# 在class的缩进中定义类的属性和
def 方法名(self):# 方法的本质是函数
pass
创建对象
在底阿妈中,对象是由类对象.
类名() # 就是创建对象
一般使用变量将创建的对象保存起来
变量 = 类名() # 一般将这个变量称为是对象,本质,变量中保存的是对象的引用地址
调用类中的方法
由类创建的对象,可以调用类中的方法
语法
对象.方法名()
案例
需求:小猫 爱吃鱼 小猫要喝水
类的设计:
类名:猫(cat)
属性:暂无
方法:吃鱼(eat),喝水(drink)
class Cat:
def eat(self):
"""吃鱼的方法"""
print('小猫爱吃鱼。。。。')
def drink(self):
"""喝水的方法"""
print('小猫要喝水')
# 创建对象
# 对象创建没有办法直接使用,需要用变量进行接收
tom = Cat()
# 通过对象调用类中的方法
tom.eat()
tom.drink()
self的说明
1、从函数的语法上来看,self是形参,名字是可以任意的变量名,只是我们习惯性叫self
2、特点:self是一个普通的参数,按照函数的语法,在调用的时候,必须传递实参值,原因是python解释器自动的将调用这个方法的对象作为参数传递给self
所以self就是调用这个方法对象
class Cat:
def eat(self):
"""吃鱼的方法"""
print('小猫爱吃鱼。。。。')
print(id(self))
def drink(self):
"""喝水的方法"""
print('小猫要喝水')
# 创建对象
# 对象创建没有办法直接使用,需要用变量进行接收
tom = Cat()
# 通过对象调用类中的方法
print(f'tom:{id(tom)}')
tom.eat()
tom.drink()
blue_cat = Cat()
print(f'blue:{id(blue_cat)}')
blue_cat.eat()
# self 谁调用就是谁
属性的使用
属性表示事物的特征
可以给对象添加属性 或者获取对象的属性值
给对象添加属性
对象.属性名 = 属性值 # 添加或者修改
获取对象的属性值:
对象.属性名
在方法中操作属性(self是对象):
self.属性名 = 属性值
self.属性名
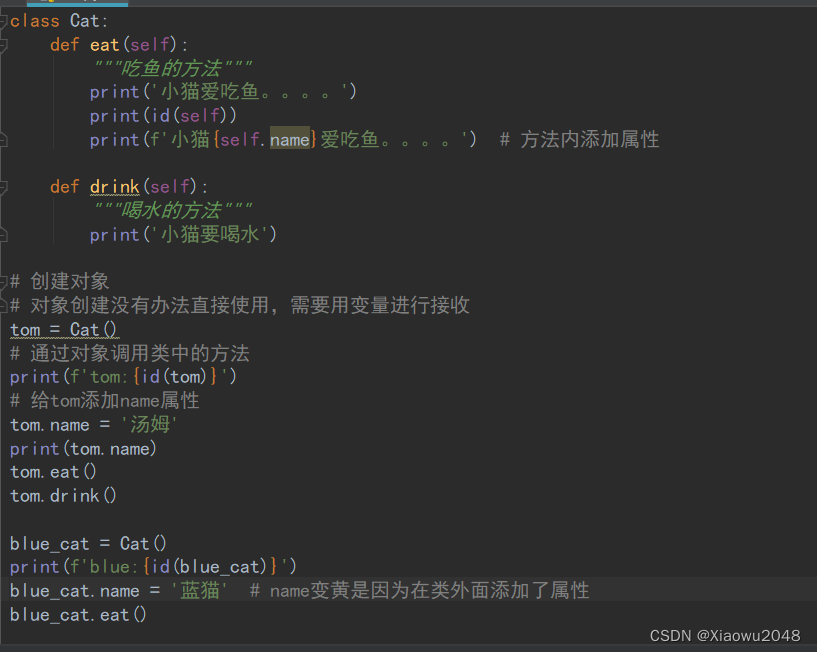

class Cat:
def eat(self):
"""吃鱼的方法"""
print('小猫爱吃鱼。。。。')
print(id(self))
print(f'小猫{self.name},{self.age}岁·爱吃鱼。。。。') # 方法内添加属性
def drink(self):
"""喝水的方法"""
print('小猫要喝水')
# 创建对象
# 对象创建没有办法直接使用,需要用变量进行接收
tom = Cat()
# 通过对象调用类中的方法
print(f'tom:{id(tom)}')
# 给tom添加name属性
tom.name = '汤姆'
tom.age = 18
print(tom.name,tom.age)
tom.eat()
tom.drink()
blue_cat = Cat()
print(f'blue:{id(blue_cat)}')
blue_cat.name = '蓝猫' # name变黄是因为在类外面添加了属性
blue_cat.age = 30
blue_cat.eat()
# self 谁调用就是谁
魔法方法__init__
在python中存在的一类方法,以两个下划线开头,两个下划线结尾,在满足某个条件的情况下,会自动调用,这一类方法称为魔方方法
怎么学习:
1.什么情况下会自动调用(自动调用的时机)
2、应用场景
3、注意事项
初始化方法__init__
1、调用时机
在创建对象之后,会自动调用(什么时候创建对象–类名()即创建对象)
2、应用场景
初始化对象,给对象添加属性
3、注意事项
不要写错
如果属性是会变化的,则可以将这个属性的值作为参数传递,在创建对象的时候,必须传递实参值
class Cat:
def __init__(self,name):
print('我是init方法,我被调用了') # 验证使用,正式代码不要
self.name = name
def eat(self):
print(f'小猫{self.name}爱吃鱼')
# init方法创建对象后会自动调用
# Cat # 不是创建对象,不会调用
#
# Cat() # 我是init方法,我被调用了 ,因为是创建对象
# tom = Cat # 不是创建对象,即tom也是类
# blue =Cat() # 创建对象
# b = blue # 没有创建对象,只是引用的传递,只有类名+()才是创建对象
#
# t = tom()# tom 已经是类了,类名()就是创建对象
blue_cat = Cat('blue')
blue_cat.eat()
black_cat = Cat('black')
black_cat.eat()
__str__方法
1、调用时机
使用print(对象),打印的时候,会自动调用
1、如果没有定义__str__方法,默认打印的是对象的引用地址
2、如果定义__str__方法,打印的是方法的返回值
应用场景:
使用print(对象)打印输出对象的属性信息
注意事项:
必须返回一个字符串
"""
定义cat类,包含属性name和age,打印对象的时候,可以输出对象的姓名和年龄
类名:Cat
属性:name,age
方法:__str__,__init__
"""
class Cat:
def __init__(self,name,age):
self.name = name # 添加name属性
self.age = age # 添加age属性
def __str__(self): # 一般不使用print,直接返回
return f'姓名:{self.name},年龄:{self.age}'
# 创建对象
tom = Cat('汤姆',3)
print(tom) # <__main__.Cat object at 0x000001C6133593C8> 直接使用打印的是引用的地址
dir ()函数的说明

print(dir(tom))
[‘class’, ‘delattr’, ‘dict’, ‘dir’, ‘doc’, ‘eq’, ‘format’, ‘ge’, ‘getattribute’, ‘gt’, ‘hash’, ‘init’, ‘init_subclass’, ‘le’, ‘lt’, ‘module’, ‘ne’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ‘str’, ‘subclasshook’, ‘weakref’, ‘age’, ‘name’]
封装的两个案例
封装:将对象的属性和方法定义到类中(定义类)

类名:人类(Persion)
属性:体重(weight),姓名(name)
方法:跑步(run) —>修改属性值
吃东西(eat) —>修改属性值
init 定义属性信息
__str__打印属性信息
class Persion:
def __init__(self, name, weight):
self.name = name
self.weight = weight
def __str__(self):
return f"{self. name}目前的体重为{self.weight}kg"
def run(self):
"""跑步的方法"""
# 体重减少o,5千克
self.weight -= 0.5
print(f'{self.name}跑步减少了0.5千克')
def eat(self):
"""吃东西的方法"""
# 体重增加1千克
self.weight += 1
print(f'{self.name}大餐一顿,胖了1千克')
if __name__ == '__main__':
# 创建对象
xming = Persion('小明', 48)
print(xming)
xming.run()
print(xming)
xming.eat()
print(xming)
# 创建新对象,不需要改动类中的信息
xmei = Persion('小美',78)
print(xmei)
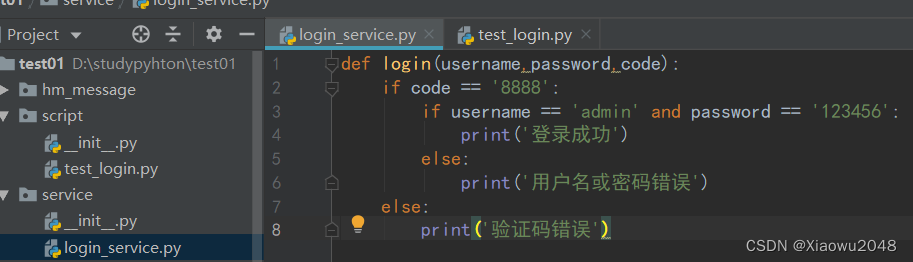
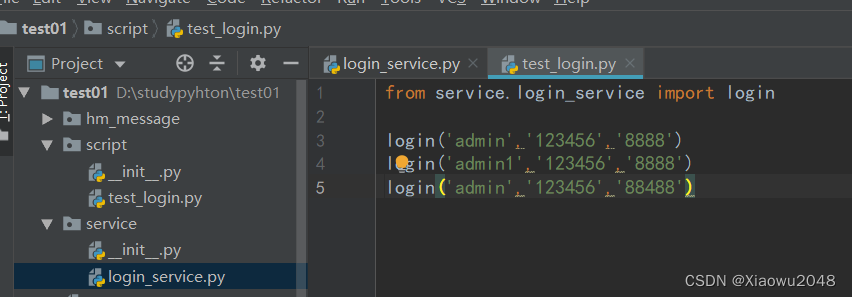
案例二:
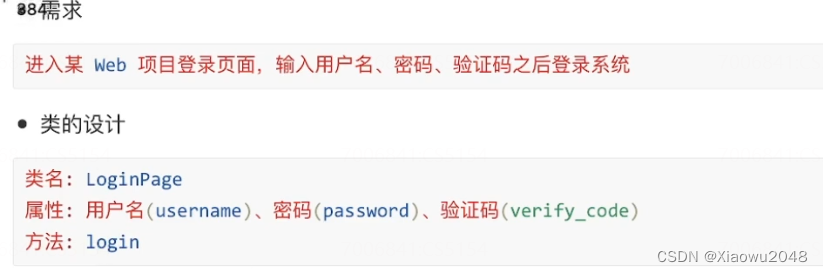
class LoginPage:
def __init__(self,name,password,code):
self.name= name
self.password = password
self.verify_code = code
def login(self):
print(f'1.输入用户名:{self.name}')
print(f'2.输入密码:{self.password}')
print(f'3.输入验证码:{self.verify_code}')
print(f'4.点击登录')
if __name__ == '__main__':
admin = LoginPage('admin','123456','8888')
admin.login()
案例三:


继承的介绍

1、继承描述的是类与类之间的关系 is…a
2、继承的好处:减少代码冗余,重复代码不需要多次书写,提高编程效率
语法
class类 A(object)
calss 类A: # 默认继承object类,object类是python中最原始的类
pass
class 类B(类A): # 就是继承,类B继承类A
pass
类A:父类或基类
类B:子类或派生类
子类继承父类后,子类对象可以直接使用父类中的属性和方法
继承案例
# 1.定义动物类,动物具有姓名和年龄属性,具有吃和睡的行为
class Animal:
"""动物类"""
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
"""吃"""
print(f'{self.name}吃东西')
def sleep(self):
"""睡"""
print(f'{self.name}睡觉')
# 2.定义猫类,猫类具有动物类的所有属性和方法,并且具有抓老鼠的特殊行为
class Cat(Animal):
"""猫类"""
def catch(self):
print(f'{self.name}会抓老鼠') # 此处的name继承与父类
# 3.定义狗类,狗类具有动物类的所有属性和方法,并具有看门的特殊属性
class Dog(Animal):
"""狗类"""
def look_the_door(self):
print(f'{self.name}正在看门。。。')
# 4.定义哮天犬具有狗类的所有属性和方法,并且具有在天上飞的属性
class XTQ(Dog):
"""哮天犬类"""
def fly(self):
print(f'{self.name}在天上飞')
if __name__ == '__main__':
ani = Animal('佩奇',2)
ani.eat()
ani.sleep()
cat = Cat('TOM',4)
cat.catch()
cat.sleep()
cat.eat()
dog = Dog('旺财',5)
dog.eat()
dog.sleep()
dog.look_the_door()
xtq = XTQ('哮天犬',10000)
xtq.eat()
xtq.sleep()
xtq.look_the_door()
xtq.fly()
继承具有传递性:C继承A,B继承A,C可以使用A类中的属性和方法
对象调用方法的顺序:对象.方法名()
1、会先在自己的类中去查找,找到直接使用
2、没有找到,去父类中查找,找到直接使用
3、没有找到,在父类的父类中去找,找到直接使用
4、没有找到
5、直到object类中,找到直接使用,没有找到,报错
重写-覆盖
1、什么是重写?
重写是在子类中定义了和父类中名字一样的方法
2、重写的原因?为什么重写
父类中的代码不能满足子类对象的需要
3、重写的方式
覆盖式重写
扩展式重写
覆盖式重写
父类中的功能全部不要,
直接在子类中定义和父类中方法名字一样的方法接口,直接书写新的代码
点击左侧的小图标可实现快速跳转
扩展式重写
父类中的功能还需要,只是添加了新的功能:
1、先在子类中定义和父类中名字相同的方法
2、在子类的代码中,使用super().方法名调用父类中的功能
3、书写新的功能
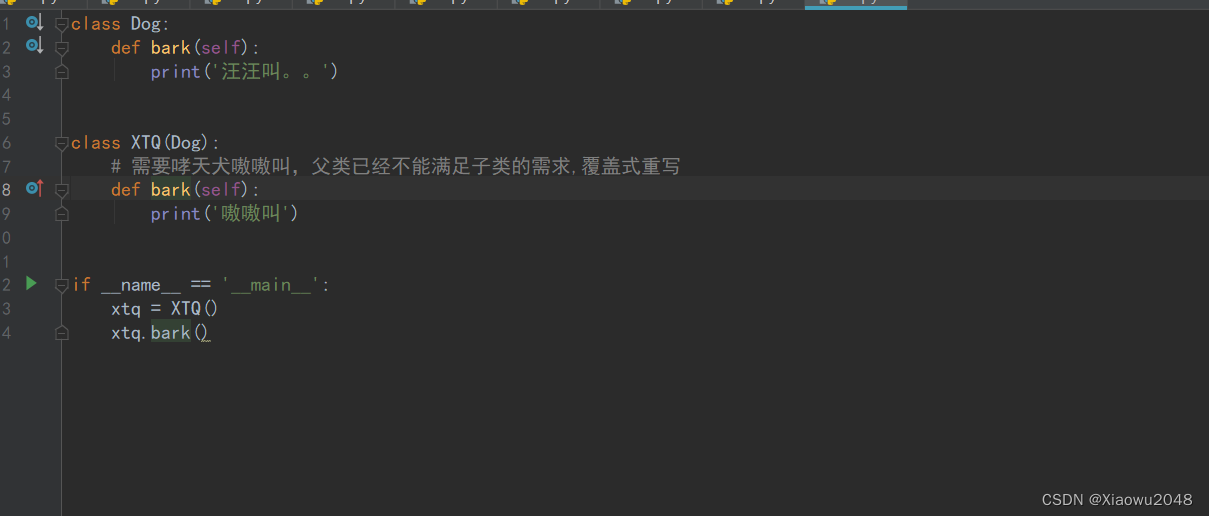
class Dog:
def bark(self):
print('汪汪叫。。')
class XTQ(Dog):
# 需要哮天犬嗷嗷叫,父类已经不能满足子类的需求,覆盖式重写
def bark(self):
# 调用父类中的功能
super().bark()
print('嗷嗷叫')
print('嗷嗷叫')
if __name__ == '__main__':
xtq = XTQ()
xtq.bark()
汪汪叫。。
嗷嗷叫
嗷嗷叫
Process finished with exit code 0
多态
多态:调用代码的技巧
不同的子类对象调用相同的方法,产生不同的执行结果
class Dog:
def game(self):
print('简单的玩耍')
class XTQ(Dog):
def game(self):
print('哮天犬在天上玩耍')
class Preson:
def play_with_dog(self,dog):
"""dog是狗类或者其子类的对象"""
print('人和狗在玩',end = " ")
dog.game()
if __name__ == '__main__':
dog1 = Dog()
xtq = XTQ()
xw = Preson()
xw.play_with_dog(dog1)
xw.play_with_dog(xtq)
人和狗在玩 简单的玩耍
人和狗在玩 哮天犬在天上玩耍
私有和共有
在python中,定义类的时候,可以给属性和方法设置访问权限,即规定在什么地方可以使用
共有属性
直接定义的属性和方法就是公有的
特点:在任何地方访问和使用,只要有对象就可以访问和使用
私有属性
1.只能在类内部定义(class关键字的缩进中)
2、只要在属性名或者方法名前面加上两个下划线,这个方法或者属性就会变成私有的
特点:
私有属性只能在当前类的内部使用,不能在类外部和子类直接使用
应用场景:
一般来说,定义的属性和方法,都为共有的
某个属性不想再外部直接使用,定义为私有
某个方法,是内部的方法(不想在外部使用),定义为私有
"""定义人类,name属性,age属性(私有)"""
class Person:
def __init__(self,name,age):
self.name = name # 公有
self.__age = age # 公有 -->私有,在属性前面加上两个下划线
def __str__(self):# 公有方法
return f"{self.name},{self.__age}"
def set_age(self,age): # 定义公有方法,修改私有属性
if age < 0 or age > 120:
print('提供的信息不对')
return
self,__age = age
if __name__ == '__main__':
xw = Person('小屋',19)
print(xw)
xw.__age = 10000 # 添加一个共有属性 __age
print(xw)
xw.set_age(1000)
print(xw)
对象划分
对象分类
python中一切皆对象:
类对象
类对象就是类,就是使用class定义的类
在代码执行的时候,解释器会自动创建
作用:
1、使用类对象创建实例对象
2、存储一些类的特征值(类属性)
实例对象
1、创建对象也称实例化。所以由类对象(类)创建的对象称为是实例对象,简称实例
2、一般来说,没有特殊强调,我们所说的对象都是指实例对象(实例)
3、实例对象可以保存实例的特征值(实例属性)
4、就是使用类名()创建的对象
属性划分
使用 实例对象.属性 访问属性的时候,会先在实例属性中查找,如果找不到去类属性中查找,找到就使用,找不到就报错
即:每个实例对象都有可能访问类属性值(前提、实例属性和类属性不同名)
实例属性
概念:
实例属性是每隔实例对象具有的特征(属性)
定义:
一般都是在init方法中,使用self.属性名 = 属性值 来定义的
特征(内存)
每个实例对象都会保存自己的实例属性,即内存中存在多份
访问和修改:
#可以认为是通过self
实例对象.属性 = 属性值 # 修改
实例对象.属性 #访问
类属性
概念:
是类对象具有的特征,是整个类的特征
定义:
一般是在类的内部(class缩进中),方法的外部(def的缩进外部)定义的变量
特征(内存):
只有类对象保存一份,即在内存中只有一个
访问和修改:
#即通过类名
类对象.属性 = 属性值
类对象.属性
什么时候定义类属性:
代码中基本上都是使用实例属性,即通过self定义
当某个属性值描述的信息是整个类的特征(这个值变动,所有的这个类的对象的这个特征都会改变)
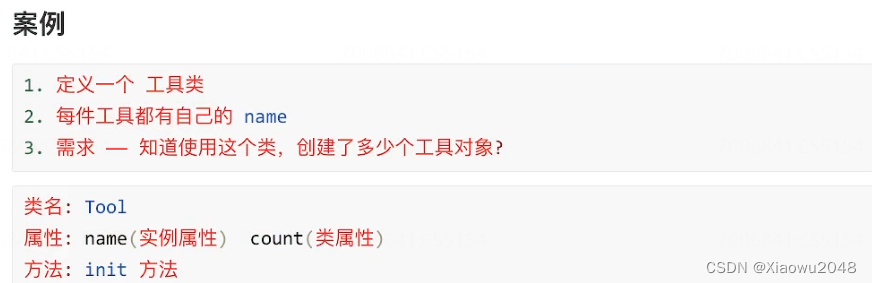
class Tool:
# 定义类属性
count = 0
def __init__(self,name):
self.name = name # 实例属性,工具的名字,每创建一次对象,就会调用一次init方法
# 修改类属性的值
Tool.count += 1
if __name__ == '__main__':
# 查看创建对象的个数
print(Tool.count) # 查看类属性
tool1 = Tool('锤子')
print(Tool.count)
tool2 = Tool('定子')
print(Tool.count)
print(tool2.count)# 先找实例属性count,找不到,找类属性count,找到使用
方法分类
实例方法
定义时机
如果方法中需要使用实例属性,则这个方法必须定义为实例方法
定义:
#直接定义的方法就是实例方法
class 类名:
def 方法名(self):
pass
参数:
参数一般写作self,表示 实例对象
调用:
实例对象.方法名()
类方法
定义时机
如果方法中不需要使用实例属性,但需要使用类属性,则这个方法,可以定义为类方法(建议)
定义:
#定义类方法,需要在方法名上书写@classmethod,即使用@classmethod装饰器
class 类名:
@classmethod
def 方法名(cls):
pass
参数一般写作cls,表示类对象,即类名,同样不需要手动传递,Python解释器会自动进行传递
调用:
类名.方法名()
实例对象.方法名()
静态方法
定义时机:
方法中既不需要使用实例属性,也不需要使用类属性,可以将整个方法定义为静态方法
定义:
定义静态方法,需要使用装饰器@staticmethod装饰方法
class 类名:
@staticmethod
def 方法名():
pass
参数:静态方法,对参数没有要求,一般没有
调用
类名.方法名()
实例对象.方法名()
方法的使用
class Tool:
# 定义类属性
count = 0
def __init__(self,name):
self.name = name # 实例属性,工具的名字,每创建一次对象,就会调用一次init方法
# 修改类属性的值
Tool.count += 1
@classmethod
def show_tool_count(cls): # cls就是类对象,类名
return cls.count
if __name__ == '__main__':
# 查看创建对象的个数
print(Tool.show_tool_count())
print(Tool.count) # 查看类属性
tool1 = Tool('锤子')
print(Tool.count)
tool2 = Tool('定子')
print(Tool.count)
print(tool2.count)# 先找实例属性count,找不到,找类属性count,找到使用
类对象使用场景

静态方法

案例:

import random
class Game:
# 定义类属性,保存历史最高分
top_score = 0
def __init__(self,name):
self.play_name = name # 实例属性
# 静态方法
@staticmethod
def show_help():
print('这个是游戏的帮助信息')
# 类方法
@classmethod
def show_top_score(cls):
print(f'历史最高分为:{cls.top_score}')
def start_game(self):
score = random.randint(10,100) # 本次游戏得分
print(f'玩家{self.play_name}本次游戏得分{score}')
if score > Game.top_score:
Game.top_score = score
if __name__ == '__main__':
Game.show_help()
#Game.show_top_score()
player = Game('xiaowang')
player.start_game()
player.start_game()
Game.show_top_score()
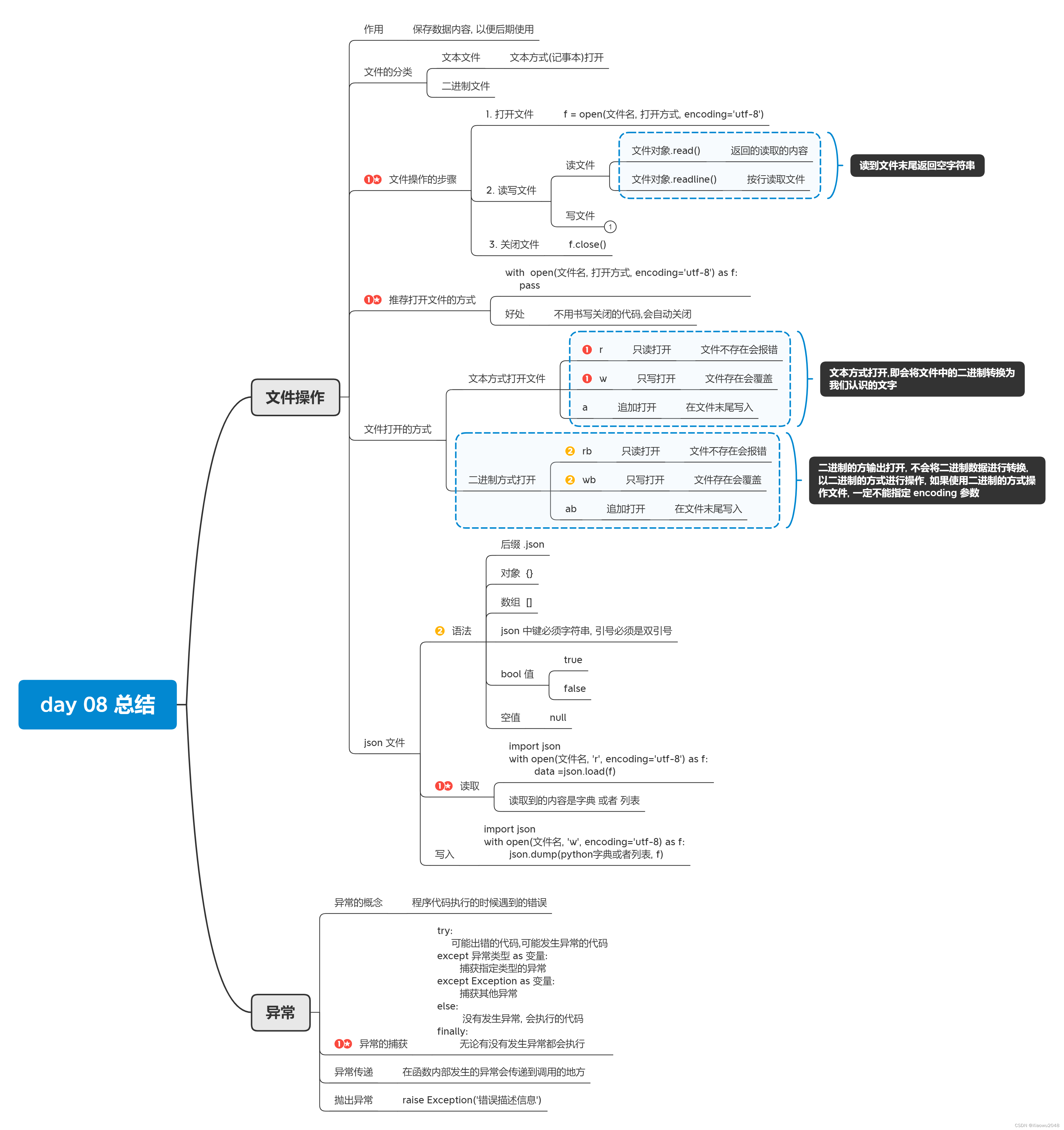
文件引入
文件操作,使用代码来读写文件
1.game案例,最高分不能保存,可以将最高分保存到文件中
2.自动化,测试数据在文件中,从文件中读取数据,进行自动化执行
文件介绍
可以存储在长期存储设备上的一段数据即为文件
1、计算机只认识二进制
2、所有的文件在计算机中存储的形式都是二进制即0和1,打开文件看到的不是0和1,原因是打开文件的软件会自动的将二进制转换为文字
文件的分类(根据能否使用文本软件(记事本打开)打开文件):
文本文件
二进制文件
文本文件:
可以使用记事本软件打开
txt,py,md.json
二进制文件:
音频文件,视频文件,图片,EXE
打开和关闭文件
打开文件open
open(file, mode=‘r’, buffering=None, encoding=None)
将硬盘中的文件加载到内存中

关闭文件
文件对象.close() #关闭文件,如果是写文件,会自动保存,即将内存中的数据同步到硬盘中
读取和写入文件
读文件read()
文件对象.read()
返回值:返回读取到的文件内容,类型是字符串
写文件 write()
文件对象.write()
参数:写入文件的内容,类型 字符串
返回值:写入文件的字符数,字符串的长度,一般不关注
# 1.打开文件
f = open('a.txt','w',encoding='utf-8')
# 2.写文件
# f.write('hello world')
f.write('好好学习\n天天向上') # 使用w会进行覆盖
# 3.关闭文件
f.close()
文件打开的另一种写法(推荐)
with open(file,mode,endcoding) as 变量 # 变量就是文件对象
pass
使用这种写法打开文件,会自动进行关闭,不用手动书写关闭的代码
出了with的缩进之后,文件就会自动关闭
文件写入
# with open('a.txt',encoding='utf-8') as f:
# buf = f.read()
# print(buf)
# f = open('a.txt',encoding='utf-8')
# data = f.read()
# print(data)
# f.close()
with open('a.txt','a',encoding='utf-8') as f: # 追加写入
f.write('\ngood good student\n')
按行读取文件readline()
文件对象.readline() 一次读取一行内容
返回读取到的内容
read和readline如果读到文件末尾,返回的都是空字符串
一次读取一行,读完之后就不能再读了

模拟读取大文件
with open('a.txt',encoding='utf-8') as f:
while True:
buf =f.readline()
if buf =="":
break
else:
print(buf,end ='')
文件读完了返回空字符串
with open('a.txt',encoding='utf-8') as f:
while True:
buf =f.readline() # 文件读完了返回空字符串
if buf :
print(buf,end ='') # 空字符串是false,非空字符串是true
else:
break
打开文件的方式

r w a 称为文本方式打开,适用于文本文件,会对二进制进行编码切换
rb wb ab 称为二进制方式打开,可以打开文本文件和二进制文件,但是二进制文件只能用二进制方式打开,不能传递encoding参数
with open('a.txt','rb') as f:
buf = f.read()
print(buf)
b’\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0\r\n\xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8agood good student\r\n\r\ngood good student\r\n’
json文件的介绍
1、json文件的本质也是文本文件,就可以直接使用read和write去操作
2、json文件比较特殊,比较像python中字典和列表
3、json使用比较频繁,按照read和write的操作,比较麻烦,专门的方法来操作json文件,可以直接得到python中的列表和字典

json文件,是一种基于文本,独立于语言的轻量级数据交换格式

json的语法
1、json中的数据类型
对象{} —》python字典
数组[] ----》python列表
字符串,必须使用双引号 -----》str
数字类型 ----》 int,float
bool类型 ----》True False
空值null ----》none
2、json文件是一个对象或者数组,对象和数组可以相互嵌套
3、json中的对象,由键值对组成的,键必须是字符串类型
4、json中的数据直接使用逗号隔开,最后一个数据后面不能加逗号
5、json文件的后缀是.json
json文件定义
我叫小明,我今年18岁,性别男,爱好,听歌,吃饭,打豆豆,我的居住地是国家中国,城市广州
右键新建文件,选择file,后缀json
{
"name":"小明",
"age": 18,
"isMan": true,
"school": null,
"like": ["听歌","吃饭","打豆豆"],
"address": {
"country": "China",
"city": "广州"
}
}
读取json文件
1、可以直接使用read进行读取
with open('info.json',encoding='utf-8') as f:
buf =f.read()
print(buf)
print(type(buf))
{
“name”:“小明”,
“age”: 18,
“isMan”: true,
“school”: null,
“like”: [“听歌”,“吃饭”,“打豆豆”],
“address”: {
“country”: “China”,
“city”: “广州”
}
}
<class ‘str’>
2、使用专门的方法去读
1,导包 import json
2,json.load(文件对象) —》得到的是列表或者字典
import json
with open('info.json',encoding='utf-8') as f:
buf = json.load(f)
print(type(buf))
print(buf)
# 姓名
print(buf.get('name'))
<class ‘dict’>
{‘name’: ‘小明’, ‘age’: 18, ‘isMan’: True, ‘school’: None, ‘like’: [‘听歌’, ‘吃饭’, ‘打豆豆’], ‘address’: {‘country’: ‘China’, ‘city’: ‘广州’}}
小明
import json
with open('info.json',encoding='utf-8') as f:
buf = json.load(f)
print(type(buf))
print(buf)
# 姓名
print(buf.get('name'))
# 获取第二个爱好
print(buf.get("like")[0])
# 获取学校
print(buf.get('school'))
听歌
None
练习

import json
with open('info2.json',encoding='utf-8') as f:
data_list = json.load(f) # 列表
print(data_list)
for data in data_list:
print(f"姓名:{data.get('name')},"
f"年龄:{data.get('age')},"
f"爱好:{data.get('like')},"
f"城市:{data.get('address').get('city')}")
# 条件为true执行的代码,if判断条件 条件为false执行的代码
a = 'a' if 3 >1 else 'b'
json文件的写入
将python中的列表或者字典转换为json文件
导包
使用json.dump(python中的数据,文件对象)
import json
info = {'name': '小明','age':18}
with open('info3.json','w',encoding= 'utf-8') as f:
json.dump(info,f,ensure_ascii=False,indent=2) # ensure_ascii=False以中文显示 indent=2 缩进2个字符
方法后有*,表示后面的参数必须使用关键字传参

异常的介绍
1、程序运行时,Python解释器遇到一个错误,则会停止程序的执行,并且提示一些错误信息,这就是异常
2、程序停止并且提示错误信息这个动作,通常称之为:抛出(raise)异常
捕获异常的基本语法
1、程序代码在执行的时候,如果遇到异常,程序就会终止,不会继续执行
2、需求:程序遇到异常之后,不会结束,可以继续执行
3、实现需求:就需要使用异常捕获
try:
可能发生异常的代码
except:
发生了异常执行的代码
# 1、获取用户从键盘输入的数据
num = input('请输入数字:')
# 2、转换数据类型为整数
try:
num = int(num)
# 3、数据转换类型正确时,输出数据内容
print(num)
except:
# 4、数据转换类型错误是,提示输入正确数据
print('请输入正确的数字')
捕获指定类型的异常
发生的异常可能存在多种,针对不同类型的异常,解决处理的方法不一样
try:
可能发生异常的代码
except 异常类型1:
发生了异常类型1,执行的代码
except 异常类型2:
发生了异常类型2,执行的代码
except。。。。
pass
try:
num = int(input('请输入一个整数数字:'))
num1 = 8/num
print(num1)
except ValueError: # 捕获指定类型的异常
print('输入的内容非数字,请重新输入')
except ZeroDivisionError:
print('不能输出数字0,请重新输入')
捕获未知类型的异常
try:
可能发生异常的代码
except Exception as 变量: # except常见异常类的父类,变量 异常对象,print()可以打印异常信息
发生异常执行的代码
try:
num = int(input('请输入一个整数数字:'))
num1 = 8/num
print(num1)
except Exception as e:
print(f'发生了异常,{e}')
请输入一个整数数字:e
发生了异常,invalid literal for int() with base 10: ‘e’
捕获异常的完整结构
try :
可能发生异常的代码
except 异常类型:
发生指定类型的异常执行的代码
except Exception as e:
发生了其他类型的异常执行的代码
else:
没有发生异常,会执行的代码
finally:
不管发生什么异常,都会执行的代码

方式一
使用异常捕获
方式二
if 判断
字符串.isdigit()判断数字是否是纯数字,如果是纯数字,返回true,否则返回false
num = input('请输入数字:')
try:
num = int(num) # 没有发生异常,说明是整数,如果发生异常,说明不是整数
except Exception as e:
print('输入错误',e)
else:
if num%2 == 0:
print('偶数')
else:
print('奇数')
finally:
print('程序运行结束')
方式2
num = input('请输入数字:')
if num.isdigit():
# 如果是True,表示是整数
# 类型转换
num = int(num)
if num % 2 == 0:
print('偶数')
else:
print('奇数')
else:
print('输入错误')
print('程序运行结束')
异常的传递
1、异常传递,是python中已经实现好的功能,不需要我们写代码实现
2.、异常传递是指,在函数的嵌套调用过程中,如果发生了异常,没有进行铺货,会将这个异常传递到函数调用的地方,直到被捕获为止,如果一直没有捕获,才会报错,中止执行
# 1、定义函数demo1()提示用户输入一个整数并且返回
def demo1():
num = int(input('请输入一个整数:'))
return num
# 2、定义demo2调用demo1
def demo2():
demo1()
# 在主程序中调用demo2
if __name__ == '__main__':
demo2()
请输入一个整数:k
Traceback (most recent call last):
File “D:/studypyhton/test01/59.py”, line 11, in < module>
demo2()
File “D:/studypyhton/test01/59.py”, line 7, in demo2
demo1()
File “D:/studypyhton/test01/59.py”, line 3, in demo1
num = int(input(‘请输入一个整数:’))
ValueError: invalid literal for int() with base 10: ‘k’
# 1、定义函数demo1()提示用户输入一个整数并且返回
def demo1():
num = int(input('请输入一个整数:'))
return num
# 2、定义demo2调用demo1
def demo2():
demo1()
# 在主程序中调用demo2
if __name__ == '__main__': # 在最外层进行异常的捕获
try:
demo2()
except Exception as e :
print(e)
抛出异常
1、在执行代码的过程中,之所以会发生异常,终止代码执行,是因为代码执行遇到了raise关键字
2、raise关键字的作用,就是来抛出异常,让代码终止执行
3、应用场景:自己书写的代码模块,让别人使用,为了让别人按照你的规定使用你的代码,你就可以在他不满足你条件的情况下,使用raise抛出异常

可进行异常的捕获

unittest的介绍

框架:
1、framework
2、为了解决一类事情的功能集合
unittest框架是python自带的单元测试框架
自带的,可以直接使用,不需要额外安装
测试人员用来做自动化测试,作为自动化测试的执行框架,即管理和执行用例
使用的原因:
1、能够组织多个用例去执行
2、提供丰富的断言方法
3、能够生成测试报告
核心要素(组成)

TestCase的使用
书写真正的用例代码(脚本)
步骤
1、导包 unitest
2、定义测试类
3、书写测试方法
4、执行
注意事项:
代码文件名字要满足标识符的规则
名字不要使用中文
'''学习TestCase(测试用例)的使用'''
# 1、导包unittest
import unittest
# 2、定义测试类,只要继承unittest.TestCase类,就是测试类
class TestDemo(unittest.TestCase):
# 3、书写测试方法,方法中的代码就是真正的用例代码,方法名必须以test开头
def test_method1(self):
print('测试方法1')
def test_method2(self):
print('测试方法2')
# 4、执行
# 方式1 在类名或者方法名后面右键运行
# 在类名后面,执行类中的所有测试方法
# 在方法名后面,只执行当前的测试方法
# 方式2
# 使用unitest.main()来执行
if __name__ == '__main__':
unittest.main()
TestCast常见问题
1、文件名包含中文
2、右键没有unittest for ,
解决方法一:
新建一个代码文件,将之前的代码复制过来
方法二:
if name == ‘main’:
unittest.main()
方法3:

TestSuite和TestRunner的使用
TestSuite(测试套件)
将多条用力脚本集合在一起,即用来组装用例的
1,导包 unittest
2,实例化套件对象 unittest.TestSuite()
3,添加用例方法
TestRunner(测试执行)
用来执行套件对象
1、导包 unittest
2、实例化执行对象 unitt.TextTestRuuner()
3、执行对象执行 套件对象 执行对象.run(套件对象)
整体步骤
1、导包 unittest
2、实例化套件对象 unittest.TestSuite()
3、实添加用例方法
4、实例化执行对象 unitt.TextTestRuuner()
5、执行对象执行 套件对象 执行对象.run(套件对象)
代码案例
套件可以用来组装用例,创建多个代码文件
# 1、导包 unittest
import unittest
from lx_testcase01 import TestDemo
from lx_testcase02 import TestDemo2
# 2、实例化套件对象 unittest.TestSuite()
suite = unittest.TestSuite()
# 3、添加用例方法
# 套件对象.addTest(测试类名(’测试方法名‘)) 建议复制
suite.addTest(TestDemo('Test_method1'))
suite.addTest(TestDemo('Test_method2'))
suite.addTest(TestDemo2('test_method1'))
suite.addTest(TestDemo2('test_method2'))
# 4、实例化执行对象 unitt.TextTestRuuner()
runner = unittest.TextTestRunner()
# 5、执行对象执行 套件对象 执行对象.run(套件对象)
runner.run(suite)
测试方法1-1
测试方法1-2
测试方法2-1
测试方法2-2
…
Ran 4 tests in 0.000s
OK
添加整个测试类中的方法

# 1、导包 unittest
import unittest
from lx_testcase01 import TestDemo
from lx_testcase02 import TestDemo2
# 2、实例化套件对象 unittest.TestSuite()
suite = unittest.TestSuite()
# 3、添加用例方法
# 套件对象.addTest(测试类名(’测试方法名‘)) 建议复制
suite.addTest(TestDemo('Test_method1'))
suite.addTest(TestDemo('Test_method2'))
suite.addTest(TestDemo2('test_method1'))
suite.addTest(TestDemo2('test_method2'))
# 添加整个测试类
# 套件对象.addTest(unittest.makeSuite(测试类名)) # 在不同的python版本中,没有提示
suite.addTest(unittest.makeSuite(TestDemo))
suite.addTest(unittest.makeSuite(TestDemo2))
# 4、实例化执行对象 unitt.TextTestRuuner()
runner = unittest.TextTestRunner()
# 5、执行对象执行 套件对象 执行对象.run(套件对象)
runner.run(suite)
查看测试结果

TestLoader 测试加载
作用TestSuite作用一样,组装用例代码,同时也需要使用TextTestRunner()去执行
10个用例脚本 makeSuite()
1、导包 unitt
2、实例化加载对象并加载用例 —>得到的是套件对象
3、实例化执行对象并执行
import unittest
# 实例化加载对象并加载用例,得到套件对象
# suite = unittest.TestLoader().discover('用例所在的目录','用例代码文件名*.py')
suite = unittest.TestLoader().discover('.','lx_01*.py')
# 实例化执行对象并执行
# runner = unittest.TextTestRunner()
# runner.run(suite)
unittest.TextTestRunner().run(suite)
练习:
1、创建一个目录case,作用就是用来存放用例脚本
2、在这个目录中创建5个用例代码文件,test_case.py…
3、使用TestLoad去执行用例
将来的代码 用例都是单独的目录中存放

练习二:
‘
import unittest
from tools import add
class TestAdd(unittest.TestCase):
def test_1(self):
"""1,1,2"""
if 2 == add(1, 1):
print(f'用例 {1}, {1}, {2}通过')
else:
print(f'用例 {1}, {1}, {2}不通过')
def test_2(self):
if 3 == add(1, 2):
print(f'用例 {1}, {2}, {3}通过')
else:
print(f'用例 {1}, {2}, {3}不通过')
def test_3(self):
if 7 == add(3, 4):
print(f'用例 {3}, {4}, {7}通过')
else:
print(f'用例 {3}, {4}, {7}不通过')
def test_4(self):
if 9 == add(4, 5):
print(f'用例 {4}, {5}, {9}通过')
else:
print(f'用例 {4}, {5}, {9}不通过')
suite代码
import unittest
from hm_06_test_add import TestAdd
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestAdd))
unittest.TextTestRunner().run(suite)
Fixture说明
代码结构,在用例执行前后会自动执行的代码结构
tpshop登录
1、打开浏览器(一次)
2、打开网页,点击登录(每次)
3、输入用户名密码验证码,点击登录(每次)
4、关闭页面(每次)
5、关闭浏览器(一次)

方法级别Fixture
在每个用例前后都会自动调用,方法名是固定的
def setUp(self): # 前置
每个用例执行前后都会自动调用
pass
def tearDown(self): #后置
# 每个用例执行完之后,都会自动调用
pass
类级别Fixture
在类中所有的测试方法执行前后,会自动执行的代码,只执行一次
#类级别的fixture需要写作类方法
@classmethod
def setUpClass(cls): 类前置
pass
@classmethod
def tearDownClass(cls) :#后置
pass
模块级别Fixture
模块,就是代码文件
模块级别
fixture实现
import unittest
class TestLogin(unittest.TestCase):
def setUp(self) -> None:
print('2. 打开网页, 点击登录')
def tearDown(self) -> None:
print('4. 关闭网页')
@classmethod # 类级别
def setUpClass(cls) -> None:
print('1. 打开浏览器')
@classmethod
def tearDownClass(cls) -> None:
print('5. 关闭浏览器')
def test_1(self):
print('3. 输入用户名密码验证码1,点击登录 ')
def test_2(self):
print('3. 输入用户名密码验证码2,点击登录 ')
def test_3(self):
print('3. 输入用户名密码验证码3,点击登录 ')
断言
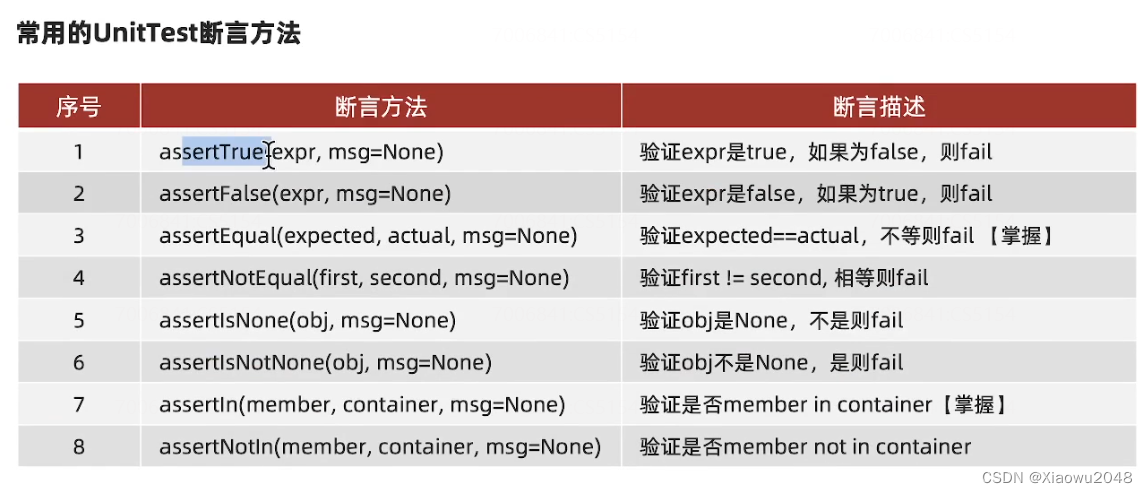
使用代码自动判断预期结果和实际结果是否相符
assertEqual(预期结果,实际结果)
判断预期结果和实际结果是否相等,结果相等,用例通过,如果不相等,抛出异常,用例不通过
assert(预期结果,实际结果)
判断预期结果是否包含在实际结果中,如果存在,用例通过,如果不存在,抛出异常,用例不通过
assert
import unittest
class TestAssert(unittest.TestCase):
def test_equal_1(self):
self.assertEqual(10, 10) # 用例通过
def test_assert_2(self):
self.assertEqual(10, 11) # 用例不通过
def test_in(self):
# self.assertIn('admin', '欢迎 admin 登录') # 包含 通过
# self.assertIn('admin', '欢迎 adminnnnnnnn 登录') # 包含 通过
# self.assertIn('admin', '欢迎 aaaaaadminnnnnnnn 登录') # 包含 通过
# self.assertIn('admin', '欢迎 adddddmin 登录') # 不包含 不通过
self.assertIn('admin', 'admin') # 包含 通过
suite
import unittest
from hm_02_assert import TestAssert
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestAssert))
unittest.TextTestRunner().run(suite)
练习
import unittest
from tools import add
class TestAdd(unittest.TestCase):
def test_1(self):
self.assertEqual(2, add(1, 1))
def test_2(self):
self.assertEqual(3, add(1, 2))
def test_3(self):
self.assertEqual(7, add(3, 4))
def test_4(self):
self.assertEqual(9, add(4, 5))
参数化 环境安装


pip list查看已经安装的插件

参数化
1.导包 from para… import para…
2、修改测试方法,将测试方法中的测试数据使用变量表示
3、组织测试数据,格式【(),(),()】一个元组就是一组测试数据
4、参数化,在测试方法上使用装饰器@parameterized.expand(测试数据)
5、运行(直接TestCase)或者使用suite运行
import unittest
from tools import add
from parameterized import parameterized
data = [(1, 1, 2), (1, 2, 3), (2, 3, 5), (4, 5, 9)]
class TestAdd(unittest.TestCase):
@parameterized.expand(data)
def test_add(self, a, b, expect):
print(f'a:{a}, b:{b}, expect:{expect}')
self.assertEqual(expect, add(a, b))
if __name__ == '__main__':
unittest.main()
import unittest
from common.read_data import build_add_data_2
from tools import add
from parameterized import parameterized
data = [(1, 1, 2), (1, 2, 3), (2, 3, 5), (4, 5, 9)]
class TestAdd(unittest.TestCase):
# @parameterized.expand(build_add_data())
# @parameterized.expand(build_add_data_1())
@parameterized.expand(build_add_data_2())
def test_add(self, a, b, expect):
print(f'a:{a}, b:{b}, expect:{expect}')
self.assertEqual(expect, add(a, b))
if __name__ == '__main__':
unittest.main()
测试报告

import unittest
from htmltestreport import HTMLTestReport
from hm_04_pa1 import TestAdd
# 套件
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestAdd)) # TestAdd类名
# 运行对象
# runner = HTMLTestReport(报告的文件路径后缀.html, 报告的标题, 其他的描述信息)
# runner = HTMLTestReport('test_add_report.html', '加法用例测试报告', 'xxx')
# runner = HTMLTestReport('./report/test_add_report.html', '加法用例测试报告', 'xxx')
runner = HTMLTestReport('report/test_add_report.html', '加法用例测试报告', 'xxx')
runner.run(suite)

#使用绝对路径
import unittest
from tools import login
class TestLogin(unittest.TestCase):
def test_username_password_ok(self):
"""正确的用户名和密码"""
if "登录成功" == login('admin', '123456'):
print('用例通过')
else:
print('用例不通过')
def test_username_error(self):
"""错误的用户名"""
if "登录失败" == login('root', '123456'):
print('用例通过')
else:
print('用例不通过')
def test_password_error(self):
"""错误的密码"""
if "登录失败" == login('admin', '123123'):
print('用例通过')
else:
print('用例不通过')
def test_username_password_error(self):
"""错误的用户名和密码"""
if "登录失败" == login('aaa', '123123'):
print('用例通过')
else:
print('用例不通过')
suite:
import unittest
from hm_01_test_login import TestLogin
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestLogin))
runner = unittest.TextTestRunner()
runner.run(suite)
跳过

import unittest
version = 29
class TestSkip(unittest.TestCase):
@unittest.skip('没什么原因,就是不想执行')
def test_1(self):
print('方法一')
@unittest.skipIf(version >= 30, '版本号大于等于 30, 测方法不用执行')
def test_2(self):
print('方法二')
def test_3(self):
print('方法三')
if __name__ == '__main__':
unittest.main()
suite
import unittest
from hm_06_skip import TestSkip
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestSkip))
unittest.TextTestRunner().run(suite)















 2369
2369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









