







三方接口如何解决
使用mock
mock说明
什么是mock–模拟接口
什么场景下会使用mock?
1、依赖的接⼝未实现
2、依赖的接⼝响应速度慢
3、针对接⼝模拟各种异常
如何去实现?
1、使⽤mock现有⼯具–>moco
2、⾃定义mock
① 编写⼀个函数 直接return 模拟的值
② 使⽤接⼝开发框架编写要模拟的接⼝ flask
要模拟哪些内容?
1、响应数据
2、响应状态码
需求场景:
模拟⼀个:登录接⼝
1、在API⽂档中说明如果登录成功,返回:状态码:200 {“status”:200,“msg”:“登录成
功!”,“token”:“XXX1213123123”}
2、登录失败反馈:状态码:200 {“status”:100,“msg”:“⽤户名或密码错误!”}
问题:开发还未实现登录接⼝,那么依赖登录如何解决?
from flask import Flask
app = Flask(__name__)
# 定义接⼝ 模拟返回结果
@app.route("/login", methods=["post"])
def login():
return {"status": 200, "msg": "登录成功!", "token": "xxxx123123123"}
# 定义接⼝ 模拟异常响应状态码
@app.route("/login/lgy", methods=["get"])
def lgy():
return "haha",407,"xiaoxi"
# 运⾏
app.run()
扩展
from flask import Flask,request
app = Flask(__name__)
"""
需求: ⽤户名为admin 密码为:123456 返回登录成功!否则返回⽤户名或密码错误,请求参数
格式为:form
"""
# 定义接⼝ 模拟返回结果
@app.route("/login", methods=["post"])
def login():
# 提取数据
userrname = request.form.get("username")
pwd = request.form.get("password")
# 判断
if userrname == "admin" and pwd == "123456":
return {"status": 200, "msg": "登录成功!", "token": "xxxx123123123"}
else:
return {"status": 100, "msg": "⽤户名或密码错误!"}
# 运⾏
app.run()
构造测试数据
方式
通过系统⻚⾯构造
通过接⼝构造
通过数据库构造
脚本编写
获取图⽚验证码、获取短信验证码
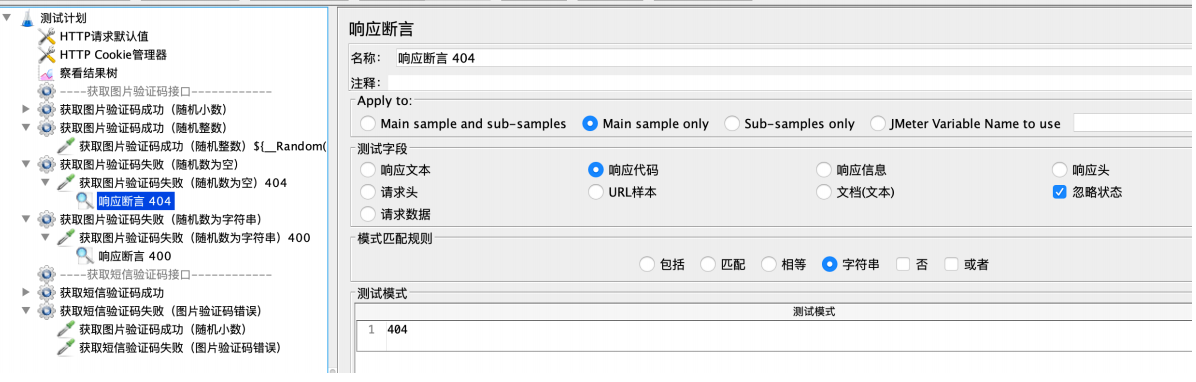
注意:
1、随机数为空、随机数为字符串,响应状态码为400、404,如果需要变绿,就需要加断⾔且勾选“忽
略状态”
2、获取短信验证码依赖图⽚验证码,需要先请求图⽚验证码,添加cookie管理器进⾏关联。
注册脚本
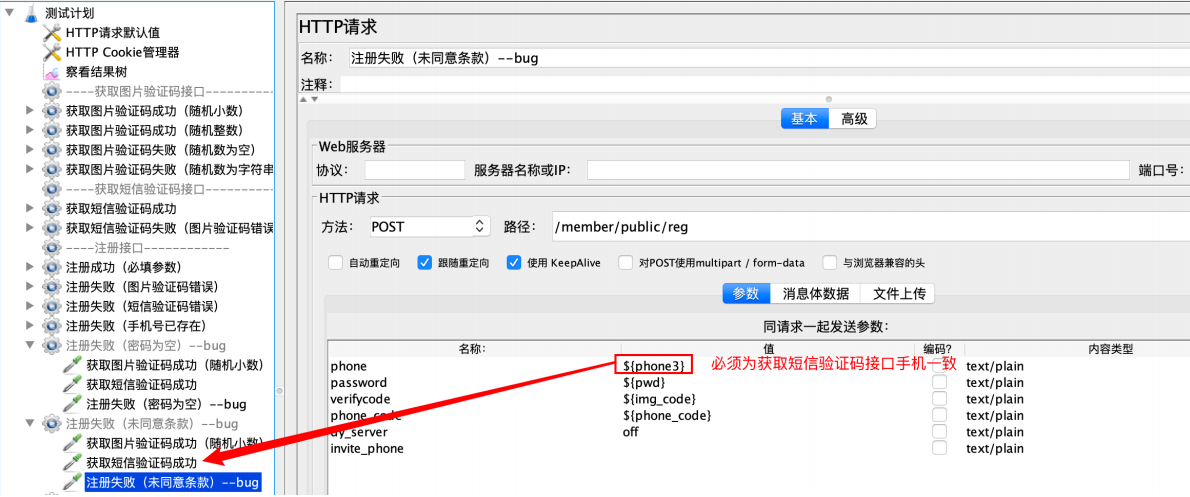
提示:
1、密码为空、未同意条款为缺陷
2、注册接⼝中⼿机号必须和获取短信验证码接⼝⼿机号⼀致
登录脚本
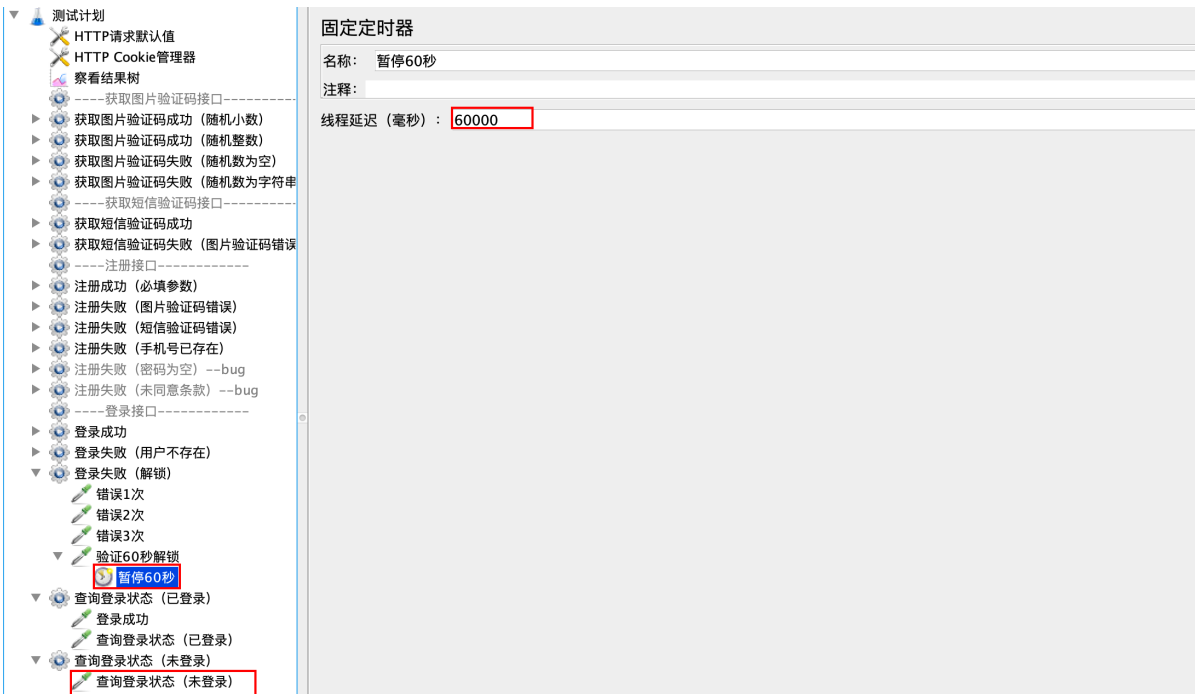
提示:
1、解锁需要使⽤固定定时器登录60秒 (60000毫秒)
2、查询登录状态(未登录)需要把登录请求删除
multipart/form-data
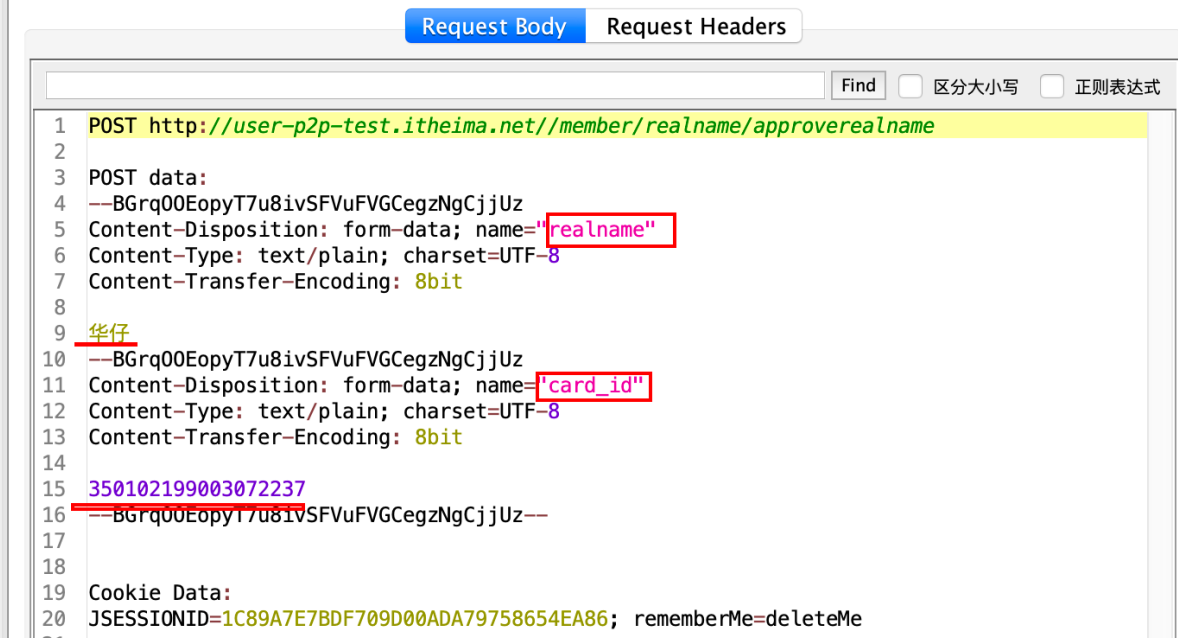
普通form
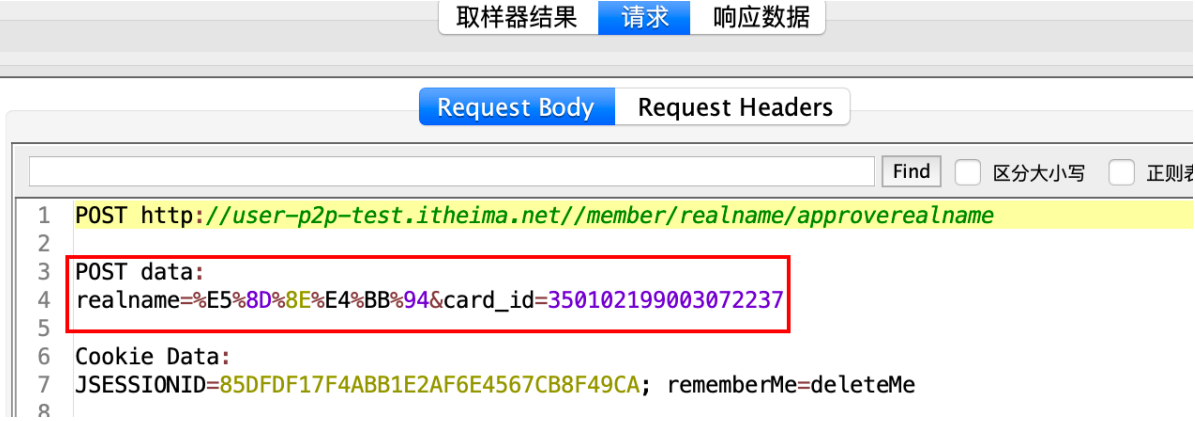
认证
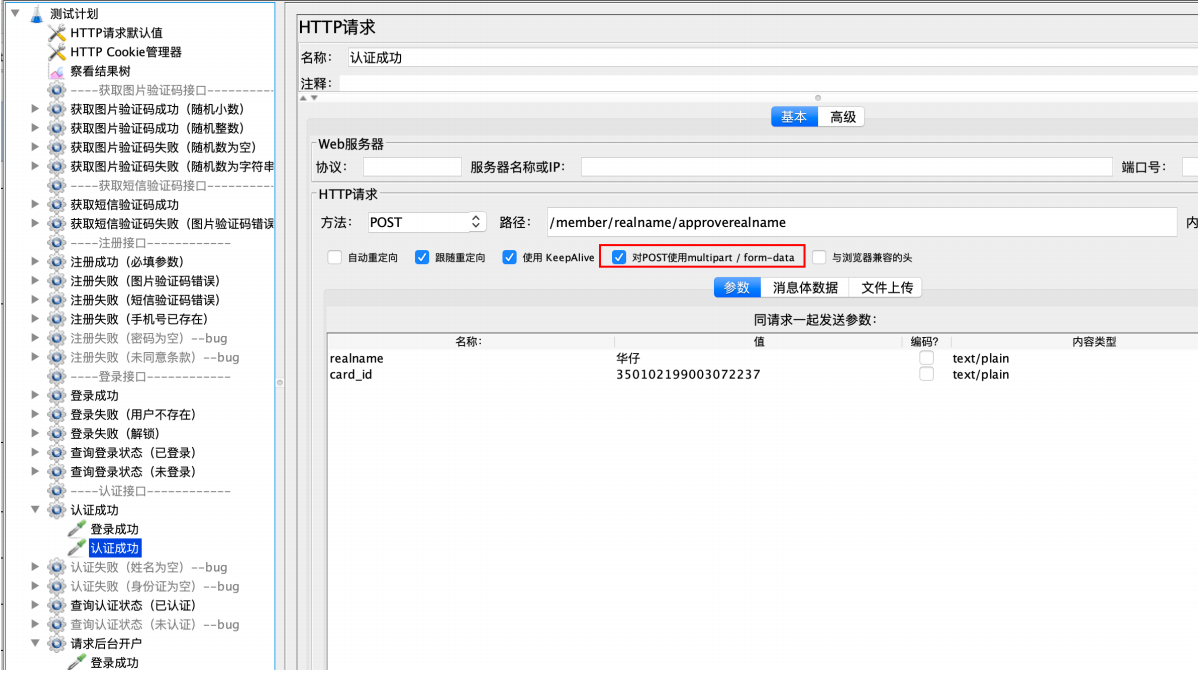
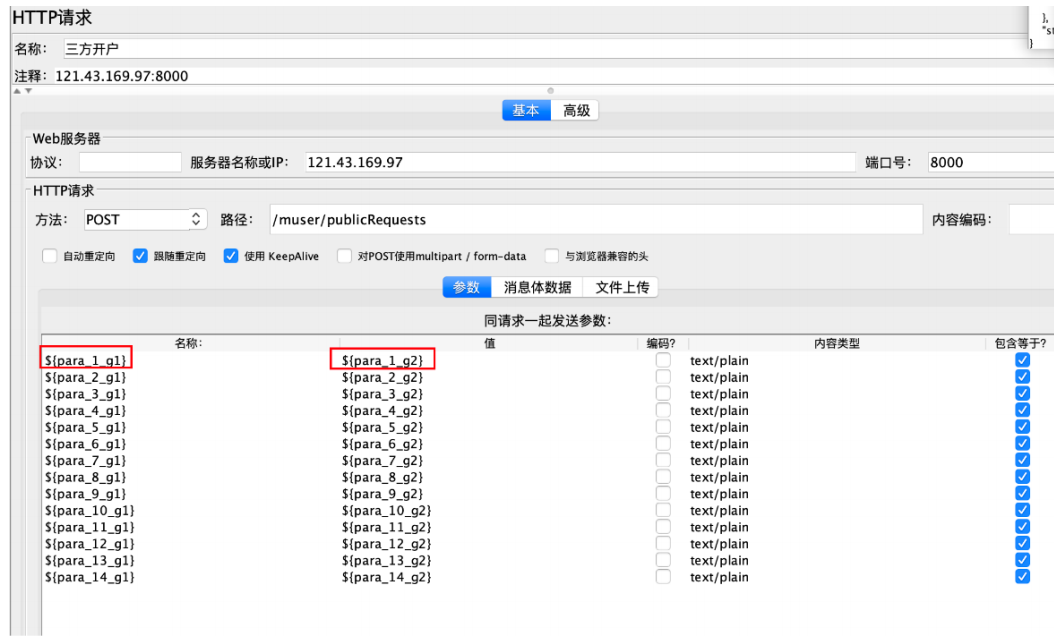
三⽅开户

结论:提取的数据不⼀样,其他都⼀样
表达式编写:
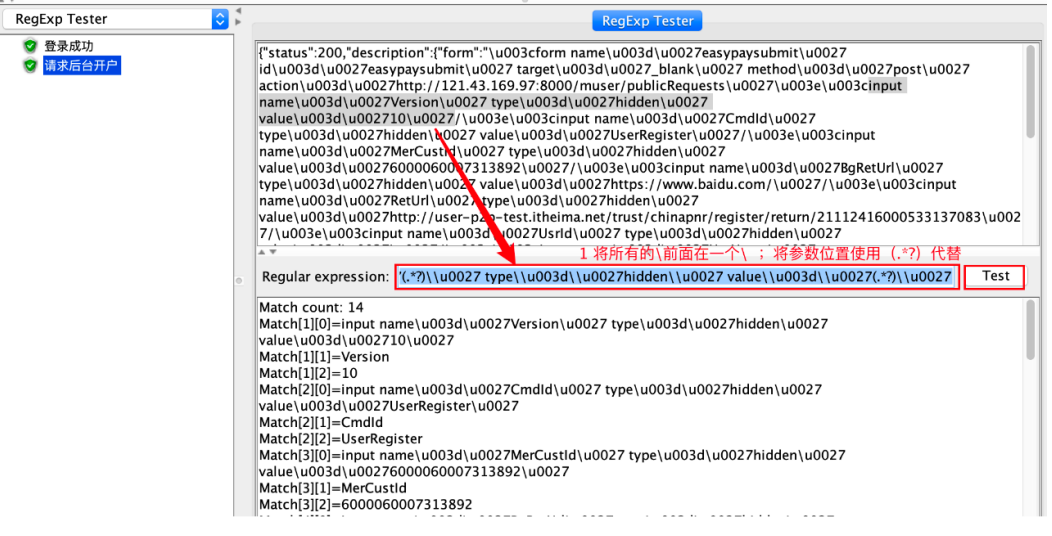
请求引⽤
自动化脚本
添加断言
注册、登录
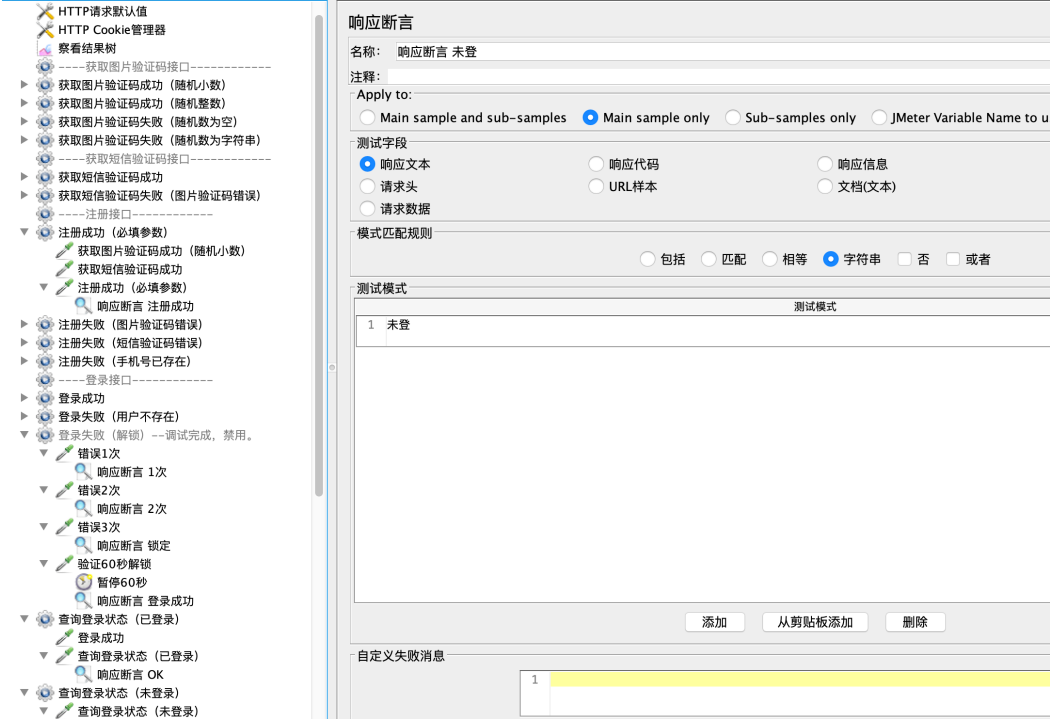
提示:
1、图⽚验证码使⽤响应断⾔->断⾔状态码
2、其他全部使⽤响应断⾔
3、依赖接⼝不⽤断⾔,只需断⾔被测接⼝。(如:注册依赖图⽚验证码、短信验证码,只需要断⾔注册
即可。)
认证、充值、开户、投资
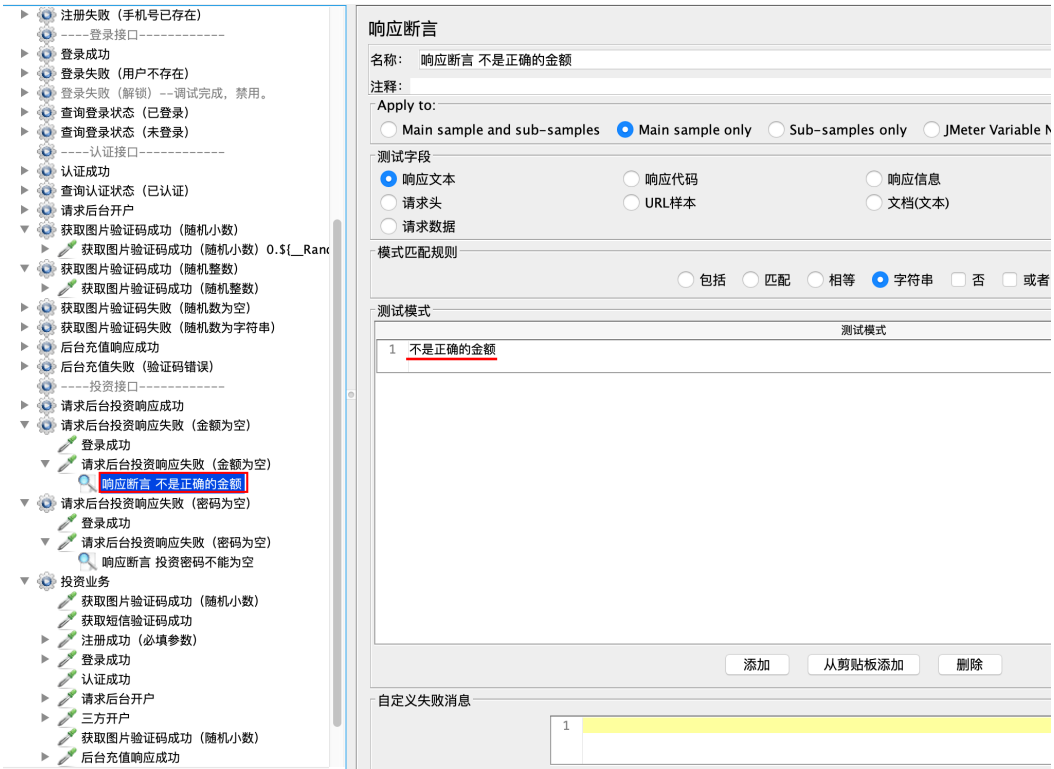
提示:
1、断⾔内容来源预期结果,预期结果⼀般情况与实际结果⼀致。⽂字偏差看⼤概意思是否⼀样,如果不
⼀样,那就是缺陷。
2、看实际结果是否有明确提示错误原因和引导信息。如果有就通过,否则就是失败
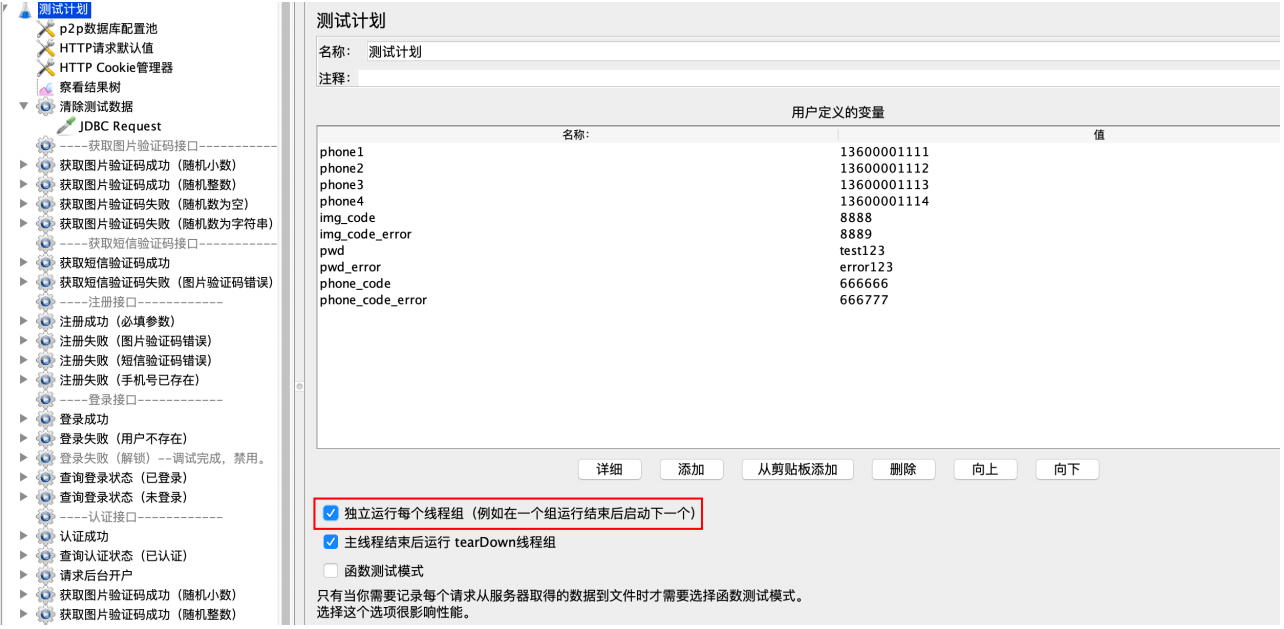
可重复执行
如何可以做到可重复执⾏?
1、清除测试数据(已注册数据、造借款数据)
2、脚本按指定顺序执⾏
清除测试数据
明确清除那些数据?
1、删除已注册的⼿机号
2、造数据(借款标)
提示:在⼯作中找开发确认。
这些数据在那个库、那个表?
库:czbk_member
表:
mb_member(会员主表)
mb_member_info(信息表)
mb_member_login_log(登录⽇志)
mb_member_register_log(注册⽇志)
确定sql语句
分析
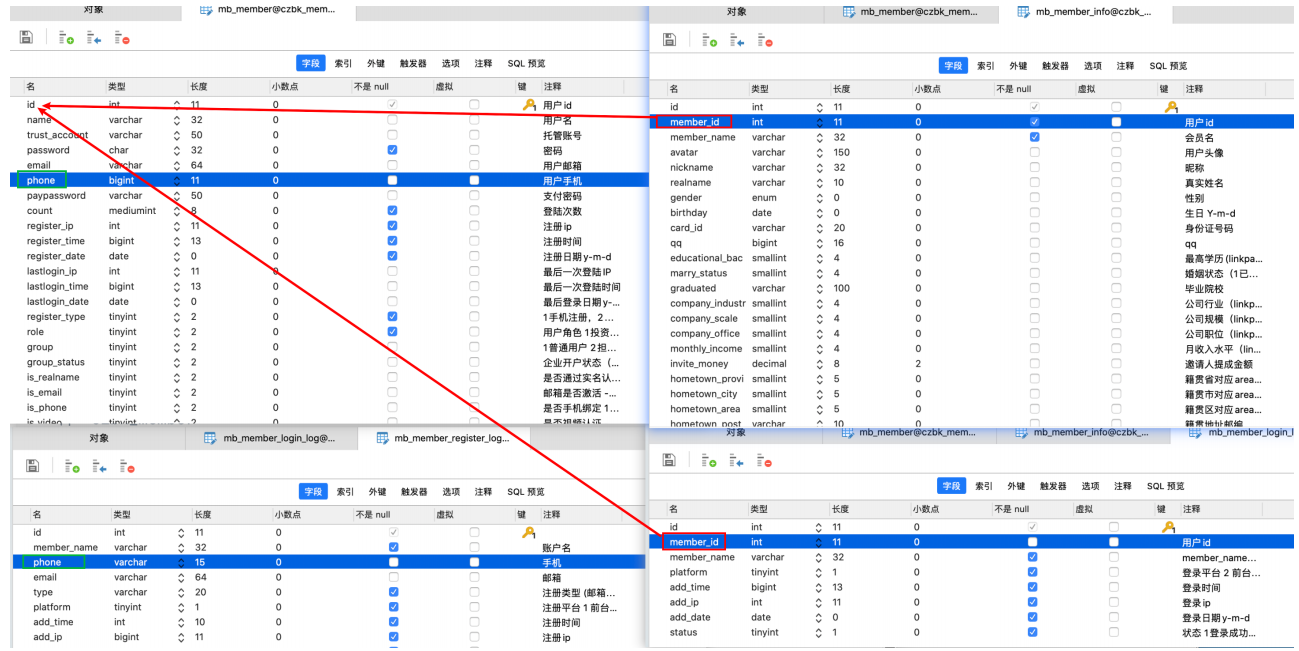
1、mb_member、mb_member_register_log直接使⽤phone字段进⾏过滤删除
2、mb_member_info、mb_member_login_log必须配合mb_member表的id进⾏关联查询,在删
除。
查询sql(确认sql语句是否正确)
删除sql
1、使⽤jmeter连接数据库,执⾏sql语句
添加数据库连接池并配置
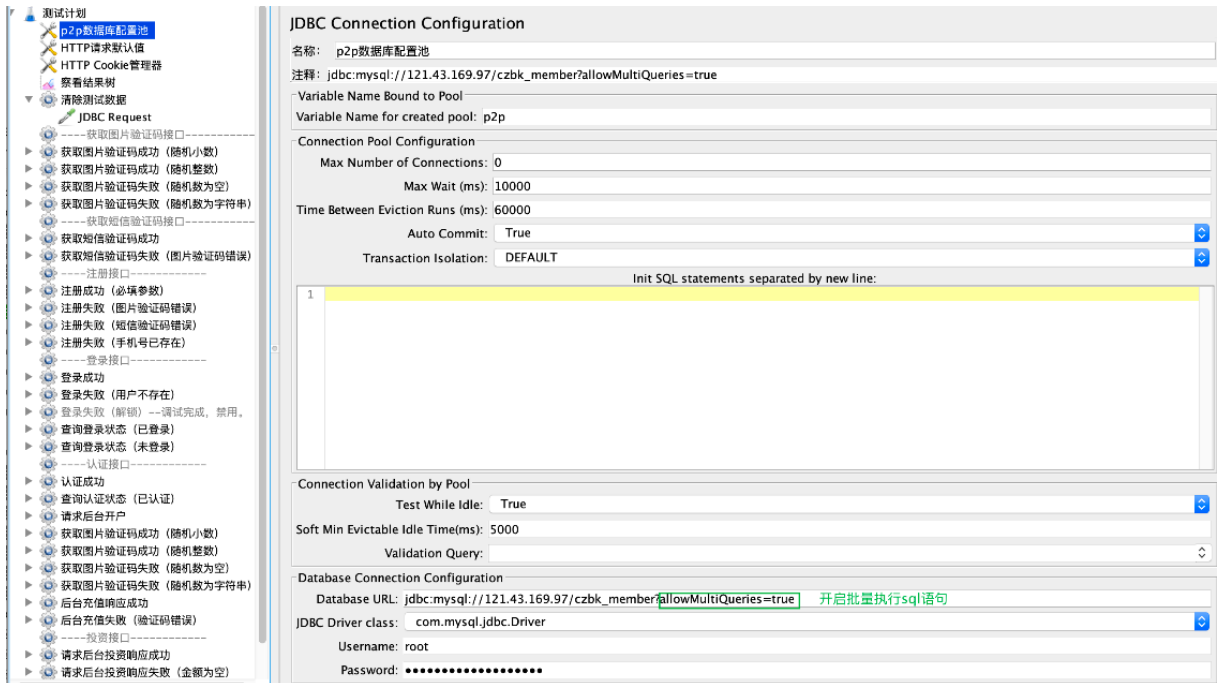
jdbc:mysql://121.43.169.97/czbk_member?allowMultiQueries=true
allowMultiQueries=true:开启批量执⾏sql语句。
添加 jdbc请求执⾏sql语句
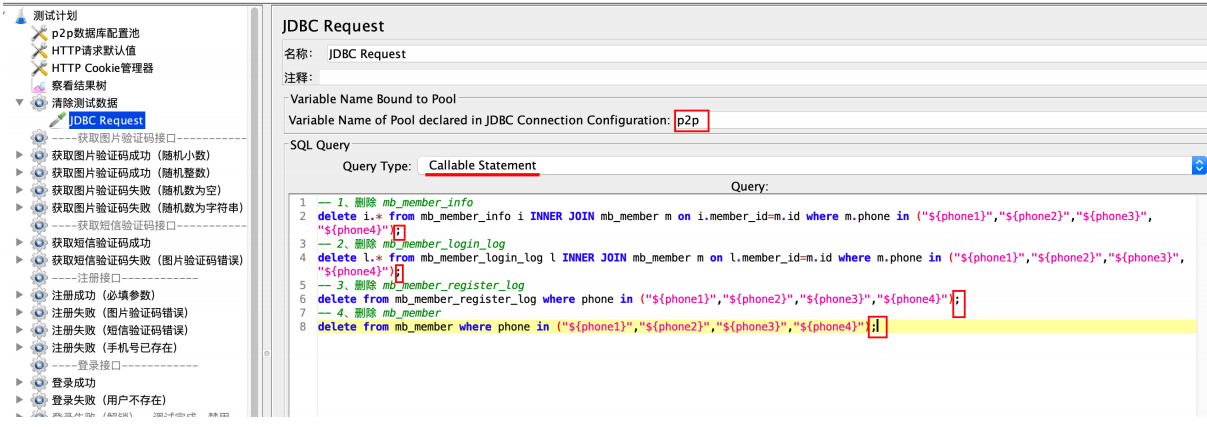
注意:
1、每个sql语句结尾需要使⽤;
2、Query Type:选择Callable Statement
2、脚本按指定顺序执⾏
持续集成
持续集成理论
什么持续集成?
通过⼀款⼯具(jenkins)持续⾃动集成代码。
CI⼯具最常⽤啥?
Jenkins
通过jenkins⼯具运⾏脚本的本质啥?
运⾏脚本的命令
jmeter -n -t 脚本.jmx -l 结果.txt -e -o ⽬录
持续集成所依赖的环境是啥?
1、jenkins环境:jdk jenkin.war
2、运⾏脚本本环境:newman 、jmeter、jkd、python、pytest
持续集成运⾏脚本的⽅式有哪些?–脚本在哪⾥放?
1、项⽬托管平台(github、gitree、gitlabe)
2、jenkins服务器(将脚本从托管平台下载到jenkins服务器本地,调⽤命令去执⾏)
脚本管理
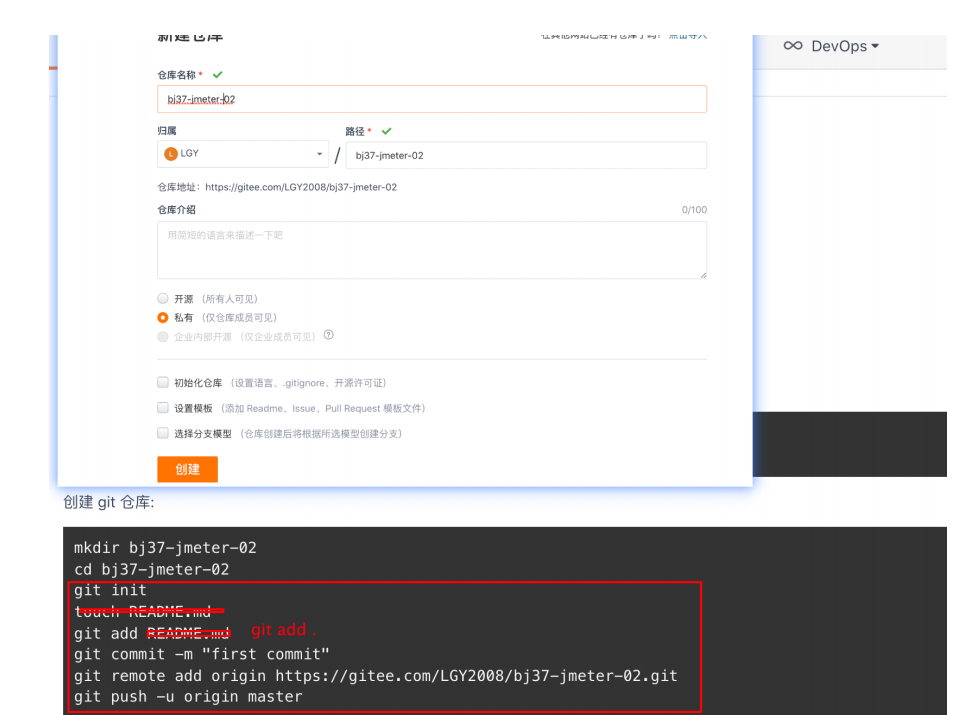
通过⼯具上传托管平台
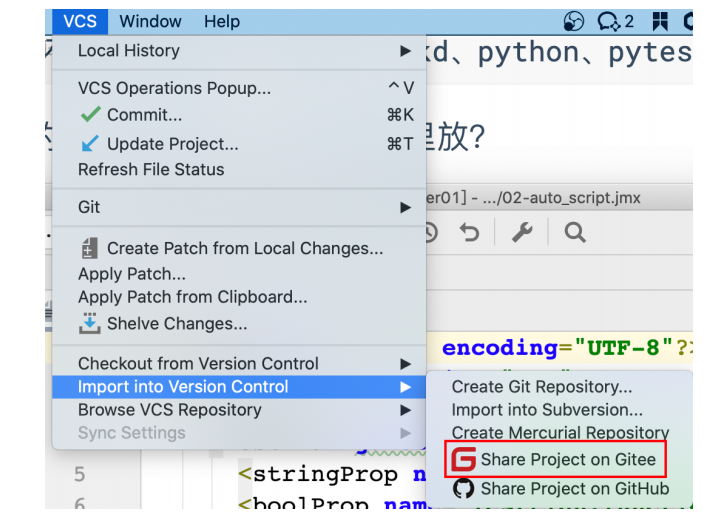
通过命令上传
配置
执行脚本
配置:
1、源码管理(将脚本下载到jenkins服务器)
2、构建(在jenkins本地服务器执⾏脚本的命令)
1、执⾏删除报告⽬录和结果⽬录命令
mac/linux:rm -rf re*
windows: del result.txt rmdir /Q/S report
2、x:/xx/apache-jmeter-5.1.1/bin/jmeter.bat -n -t 02-auto_script.jmx -l
resut.txt -e -o rep
测试报告
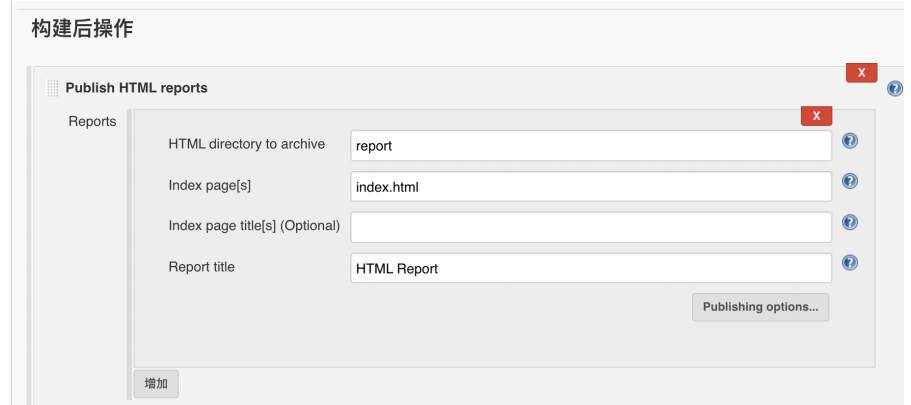
报告⽆内容或⽆样式:
jenkins管理->执⾏命令
System.setProperty(“hudson.model.DirectoryBrowserSupport.CSP”, “”)
发送邮件
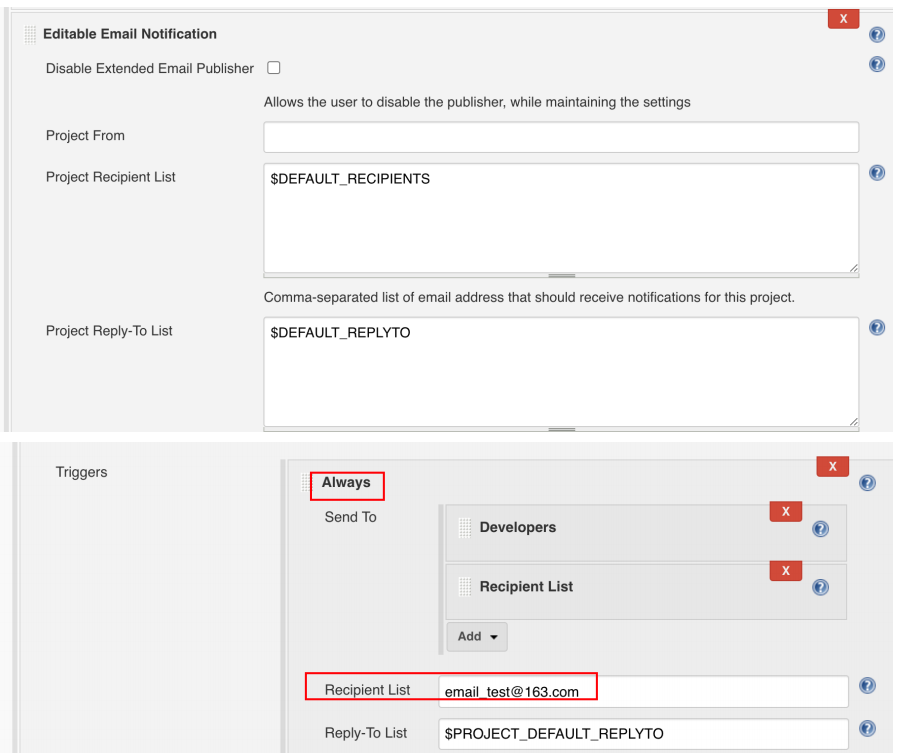
使用python编写注册登录模块脚本
代码接⼝⾃动化怎么做的?
第⼀步:python+request+unittest;
能具体描述下吗?
第⼆步:封装、调⽤、数据驱动、⽇志、报告;
能在详细举个示例:
第三步:api\scripts\data\log\report\until…
使用代码自动化脚本的流程
1、抽取功能⽤例转为⾃动化⽤例。
2、搭建环境(测试⼯具)
3、搭建⽬录结构
4、编写脚本
5、执⾏脚本
6、配置持续集成
抽取功能转为⾃动化⽤例
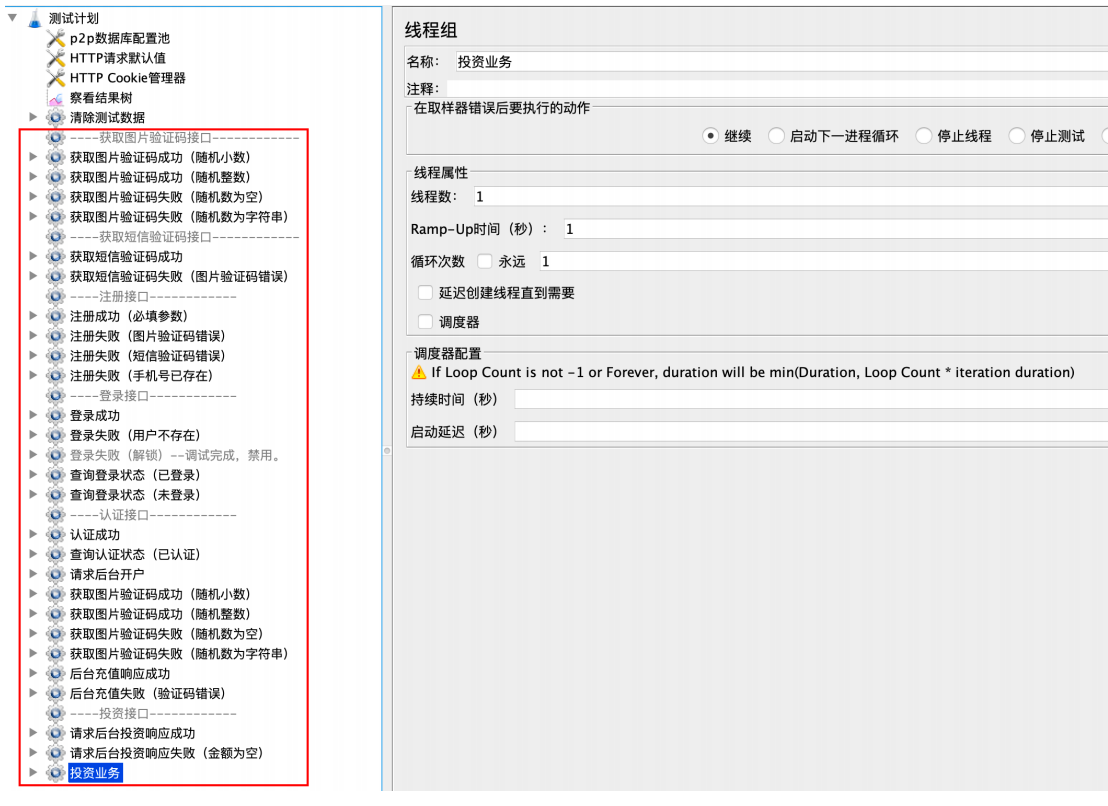
搭建环境(测试⼯具)
1、python、pycharm、requests、pymysql、parametrize
2、jenkins、jdk
提示:由于编写的⾃动化脚本,⽽⾃动化脚本编写之前功能已测试完毕,所以不需要在单独搭建项⽬环境
搭建⽬录结构
代码编写
api(api_register_login.py)
from config import HOST 1
2
3
class ApiRegisterLogin:
# 初始化
def __init__(self, session):
# 获取session对象
self.session = session
# url
# 1、获取图⽚验证码接⼝ 封装
def api_img_code(self):
pass
# 2、获取短信验证码接⼝ 封装
def api_phone_code(self):
pass
# 3、注册接⼝ 封装
def api_register(self):
pass
# 4、登录接⼝ 封装
def api_login(self):
pass
# 5、查询登录状态接⼝ 封装
def api_login_status(self):
pass
# 1、获取图⽚验证码接⼝ 封装
def api_img_code(self, random):
# 调⽤get⽅法 返回响应对象
return self.session.get(url=self.__url_img_code.format(random))
# 2、获取短信验证码接⼝ 封装
def api_phone_code(self, phone, imgVerifyCode):
# 1、定义请求参数
data = {
"phone": phone,
"imgVerifyCode": imgVerifyCode,
"type": "reg"
}
# 2、调⽤请求⽅法
return self.session.post(url=self.__url_phone_code, data=data)
# 3、注册接⼝ 封装
def api_register(self, phone, password, verifycode, phone_code):
# 1、定义请求参数
data = {
"phone": phone,
"password": password,
"verifycode": verifycode,
"phone_code": phone_code,
"dy_server": "on",
script(test01_register_login.py)
"invite_phone": ""
}
# 2、调⽤请求⽅法
return self.session.post(url=self.__url_register, data=data)
# 4、登录接⼝ 封装
def api_login(self, keywords, password):
# 1、定义请求参数
data = {
"keywords": keywords,
"password": password
}
# 2、调⽤请求⽅法
return self.session.post(url=self.__url_login, data=data)
# 5、查询登录状态接⼝ 封装
def api_login_status(self):
return self.session.post(url=self.__url_login_status)
script(test01_register_login.py)
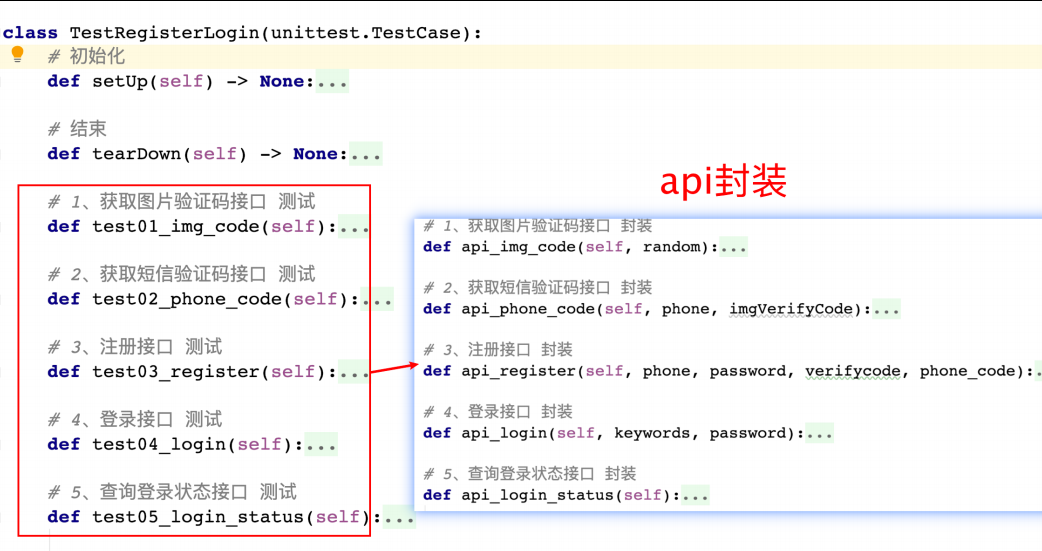
import unittest
import requests
from api.api_register_login import ApiRegisterLogin
class TestRegisterLogin(unittest.TestCase):
# 初始化
def setUp(self) -> None:
# 获取session对象
self.session = requests.session()
# 获取ApiRegisterLogin实例
self.reg = ApiRegisterLogin(self.session)
2.5 断⾔
说明:判断程序执⾏实际结果是否符合预期结果
示例:
2.6 参数化
步骤
# 结束
def tearDown(self) -> None:
# 关闭session对象
self.session.close()
# 1、获取图⽚验证码接⼝ 测试
def test01_img_code(self):
pass
# 2、获取短信验证码接⼝ 测试
def test02_phone_code(self):
pass
# 3、注册接⼝ 测试
def test03_register(self):
pass
# 4、登录接⼝ 测试
def test04_login(self):
pass
# 5、查询登录状态接⼝ 测试
def test05_login_status(self):
pass
断言
说明:判断程序执⾏实际结果是否符合预期结果
示例:
try:
# 调⽤登录接⼝
self.reg.api_login(keywords="13600001111", password="test123")
# 调⽤查询登录状态接⼝
r = self.reg.api_login_status()
# 看结果
self.assertIn(expect_text, r.text)
except Exception as e:
# ⽇志
print(e)
# 抛异常
raise
# 提示:捕获异常的⽬的是为了将错误信息记录下来,捕获信息完成后,必须抛出异常
参数化
1、编写数据存储⽂件 json
2、编写读取⼯具⽅法 read_json()
3、使⽤参数化组件进⾏引⽤ parametrize
1、编写参数化⽂件
⼼得:
1、根据模块来新建json⽂件(1个模块1个json⽂件)
2、最外侧使⽤{},模块下⼏个接⼝,编写⼏个key,值为列表
3、列表值中,有⼏组数据,就写⼏个{}.
4、每组数据{}中,组成格式:说明+参数+预期结果
{
"img_code": [
{
"desc": "获取图⽚验证码成功(随机⼩数)",
"random": 0.123,
"expect_code": 200
},
{
"desc": "获取图⽚验证码成功(随机整数)",
"random": 123,
"expect_code": 200
},
{
"desc": "获取图⽚验证码失败(随机数为空)",
"random": "",
"expect_code": 404
},
{
"desc": "获取图⽚验证码失败(随机数为字符串)",
"random": "123hello",
"expect_code": 400
}
],
"phone_code": [
{
"desc": "获取短信验证码成功",
"phone": "13600001111",
"imgVerifyCode": 8888,
"expect_text": "发送成功"
},
{
"desc": "获取短信验证码成功",
"phone": "13600001111",
"imgVerifyCode": 8889,
"expect_text": "验证码错误"
}
],
"register": [
{
"desc": "注册成功(必填参数)",
"phone": 13600001111,
"password": "test123",
"verifycode": 8888,
"phone_code": 666666,
"expect_text": "注册成功"
},
{
"desc": "注册失败(图⽚验证码错误)",
"phone": 13600001112,
"password": "test123",
"verifycode": 8889,
"phone_code": 666666,
"expect_text": "验证码错误"
},
{
"desc": "注册失败(短信验证码错误)",
"phone": 13600001112,
"password": "test123",
"verifycode": 8888,
"phone_code": 666667,
"expect_text": "验证码错误"
},
{
"desc": "注册失败(⼿机号已存在)",
"phone": 13600001111,
"password": "test123",
"verifycode": 8888,
"phone_code": 666666,
"expect_text": "已存在"
}
],
"login": [
{
"desc": "登录成功",
"keywords": 13600001111,
"password": "test123",
"expect_text": "登录成功"
},
{
"desc": "登录失败(密码为空)",
"keywords": 13600001111,
"password": "",
"expect_text": "不能为空"
},
{
"desc": "登录失败(解锁)",
"keywords": 13600001111,
"password": "error123",
"expect_text": "登录成功"
}
],
"login_status": [
2、编写读取数据⼯具
3、参数化引⽤
难点1:错误次数锁定
难点2: 查询登录状态,不同结果。
{
"desc": "查询登录状态(已登录)",
"status": "已登录",
"expect_text": "OK"
},
{
"desc": "查询登录状态(已登录)",
"status": "未登录",
"expect_text": "未登"
}
]
}
2、编写读取数据⼯具
def read_json(filename, key):
# 拼接读取⽂件的完整路径 os.sep动态获取/ \
file_path = DIR_PATH + os.sep + "data" + os.sep + filename
arr = []
with open(file_path, "r", encoding="utf-8")as f:
for data in json.load(f).get(key):
arr.append(tuple(data.values())[1:])
return arr
3、参数化引⽤
难点1:错误次数锁定
# 如果 password == "error123":
i = 1
while i<=3:
# 调⽤登录
r = self.xxxxlogin()
# 改变计数器
i+=1
# 断⾔锁定
# 暂停60秒
# 调⽤登录(注意:登录时必须给正确密码)
else:
# 调⽤登录(参数数据)
# 断⾔
难点2: 查询登录状态,不同结果。
# 如果 status=="已登录":
# 调⽤登录
# 调⽤查询登录状态接⼝
# 断⾔
日志的基本使用
# 1、导包
import logging
# 2、调⽤⽇志⼊⼝
logging.error("出错啦,错误原因:{}".format(e))
import logging
# 设置⽇志级别 及保存⽂件名
logging.basicConfig(level=logging.DEBUG, filename="../log/p2p.log")
# 调⽤⽇志
logging.debug("调试信息")
logging.info("信息级别")
logging.warning("警告")
logging.error("断⾔错误!")
logging.critical("严重错误")
测试⼈员使⽤的⽇志的⼊⼝
info:记录运⾏步骤
error:记录运⾏错误
⽇志底层组成介绍
说明:logging库底层有4⼤组件(⽇志器、处理器、格式器、过滤器)
1、⽇志器:接受⽇志信息,设置⽇志显示级别
2、处理器:控制⽇志显示位置或⽂件
3、格式器:控制⽇志输出的显示样式
关系:
格式器必须关联处理器
处理器必须关联⽇志器
⽇志封装应⽤
重组封装的⽬的:解决⽇志显示的样式、存储⽅式
import logging.handlers
# ⽇志⼯具
class GetLog:
@classmethod
def get_log(cls):
cls.log = None
if cls.log is None:
# 1、获取⽇志器
cls.log = logging.getLogger()
# 设置⽇志级别 info
cls.log.setLevel(logging.INFO)
filepath = DIR_PATH + os.sep + "log" + os.sep + "p2p.log"
# 2、获取处理器 TimedRotatingFileHandler:⽇志保存到⽂件且根据时间去分割
tf =
logging.handlers.TimedRotatingFileHandler(filename=filepath,
when="midnight",
interval=1,
backupCount=3,
encoding="utf-8")
# 3、获取格式器
fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%
(lineno)d)] - %(message)s"
fm = logging.Formatter(fmt)
# 4、将格式器添加到处理器中
tf.setFormatter(fm)
# 5、将处理器添加到⽇志器中
cls.log.addHandler(tf)
# 返回⽇志器
return cls.log
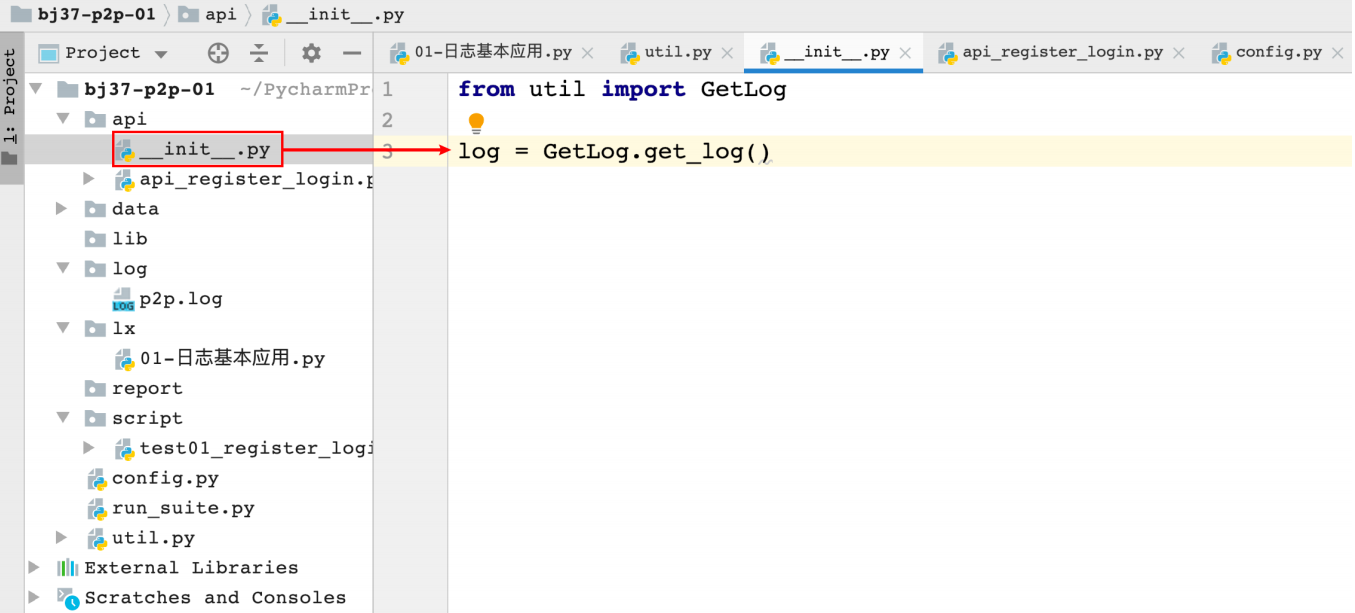
标注地⽅:api和script
api层:记录程序步骤
script:记录程序执⾏结果、断⾔结果、错误原因
# 1、获取图⽚验证码接⼝ 测试
@parameterized.expand(read_json("register_login.json", "img_code"))
def test01_img_code(self,random,expect_code):
try:
# 1、调⽤图⽚验证码接⼝
r = self.reg.api_img_code(random)
log.info("执⾏图⽚验证码响应状态码为:{}".format(r.status_code))
# 2、查看响应状态码
self.assertEqual(expect_code, r.status_code)
log.info("执⾏图⽚验证码断⾔通过")
except Exception as e:
# ⽇志
log.error("断⾔失败,原因:{}".format(e))
# 抛异常
raise
BeautifulSoup库
说明:⼀个python解析html/xml的三⽅库
安装: pip install beautifulsoup4
应⽤步骤:
1、导包
2、实例化
3、调⽤⽅法
# 1、导包
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>⿊⻢程序员</title>
</head>
<body>
<p id="test01">软件测试</p>
<p id="test02">2020年</p>
<a href="/api.html">接⼝测试</a>
<a href="/web.html">Web⾃动化测试</a>
<a href="/app.html">APP⾃动化测试</a>
</body>
</html>
"""
# 2、获取bs对象 告诉BeautifulSoup类,你要解析的是hmtl格式
bs = BeautifulSoup(html, "html.parser")
# 3、调⽤⽅法
"""
重点:
1、查找所有标签 bs.find_all("标签名") == 元素的集合 == ["元素1","元素2"]
2、查找属性 元素.get("属性名")
"""
for a in bs.find_all("a"):
print(a.get("href"))
1、查找所有标签 bs.find_all(“标签名”) == 元素的集合 == [“元素1”,“元素2”]
2、查找属性 元素.get(“属性名”)
其他⽅法
# 4、扩展其他⽅法
# 获取单个元素 bs.标签名
print(bs.a)
# 获取⽂本
print(bs.a.string)
# 获取属性
print(bs.a.get("href"))
# 获取标签名
print(bs.a.name)
提取html数据⼯具封装
# 提取html
# 获取BeautifulSoup对象
# 提取url
# 遍历查找所有的input标签
# 提取name和value的值,并组装到新的字典中
# 返回url和字段
def parser_html(result):
# 1、提取html
html = result.json().get("description").get("form")
# 2、获取bs对象
bs = BeautifulSoup(html,"html.parser")
# 3、提取url
url = bs.form.get("action")
data = {}
# 4、查找所有的input标签
for input in bs.find_all("input"):
data[input.get("name")]=input.get("value")
return url, data
安全测试
安全测试理论
什么是安全测试?
安全测试:发现系统安全隐患的过程
什么是渗透测试?
渗透测试:已成功⼊侵系统为⽬标的攻击过程。
如何进⾏安全测试(安全测试常⽤⽅法)
1、代码⾛读:检查代码是否有安全隐患
2、动态渗透
3、扫描程序缓存数据
安全测试维度

客户端安全
常⻅分类:
XSS:跨站攻击
CSRF:跨站请求伪造
XSS
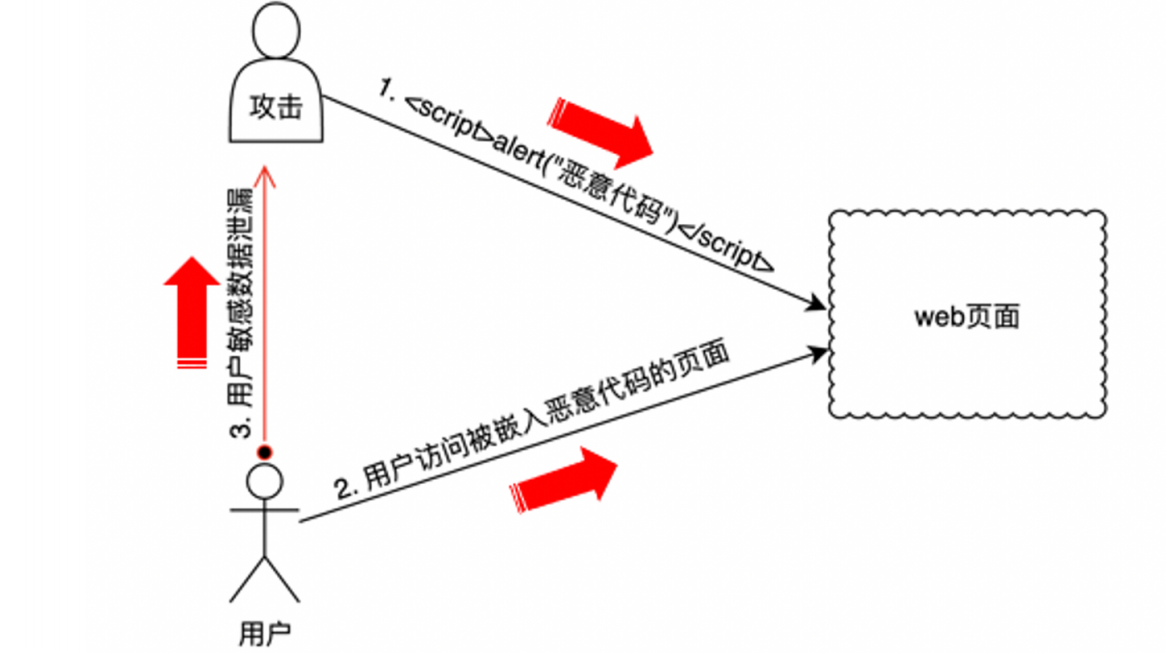
跨站脚本(cross site script)为了避免与前端css混淆,改名为xss
攻击者通过改变前端⻚⾯元素请求地址或注⼊JS,来获取⾮法数据(cookie)
攻击原理:
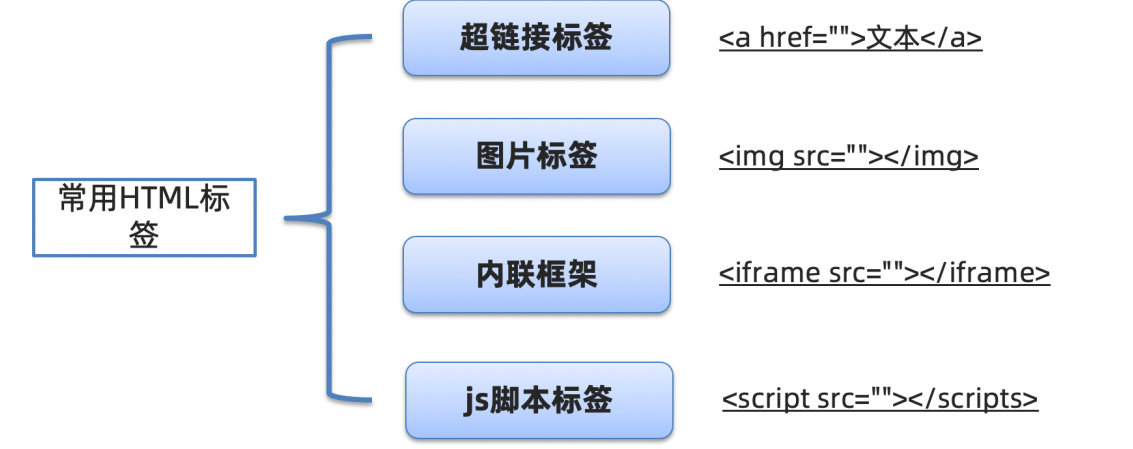
xss可⽤攻击⻚⾯标签
攻击⽅式分类
存储型:将攻击代码存储到数据库,每次打开指定的⻚⾯⾃动加载执⾏
场景:留⾔板、注册
反射型:临时修改⻚⾯代码,⽤户打开⻚⾯中招
场景:图⽚、连接
xss攻击步骤
核⼼:查找是否有XSS漏洞
执⾏:< script>alert(123)< /script>,证明可以执⾏JS或没有对<进⾏过滤。
⽬的:盗取敏感数据,如:cookie
xss防护策略
将cookie设置只读(HttpOnly)
输⼊控制:禁⽌输⼊特殊符号(< ’ >等)
输出控制:过滤或转义特殊符号的输出
解决什么问题?
避免客户端被注⼊恶意JS程序或修改标签链接地址,导致数据丢失或访问⿊客⽹站
步骤
1、验证⻚⾯是否屏蔽了JS的注⼊
2、如果存在JS注⼊,提醒开发防护策略
CSRF(跨站攻击)
CSRF(Cross-site request forgery)是指跨站请求伪造攻击
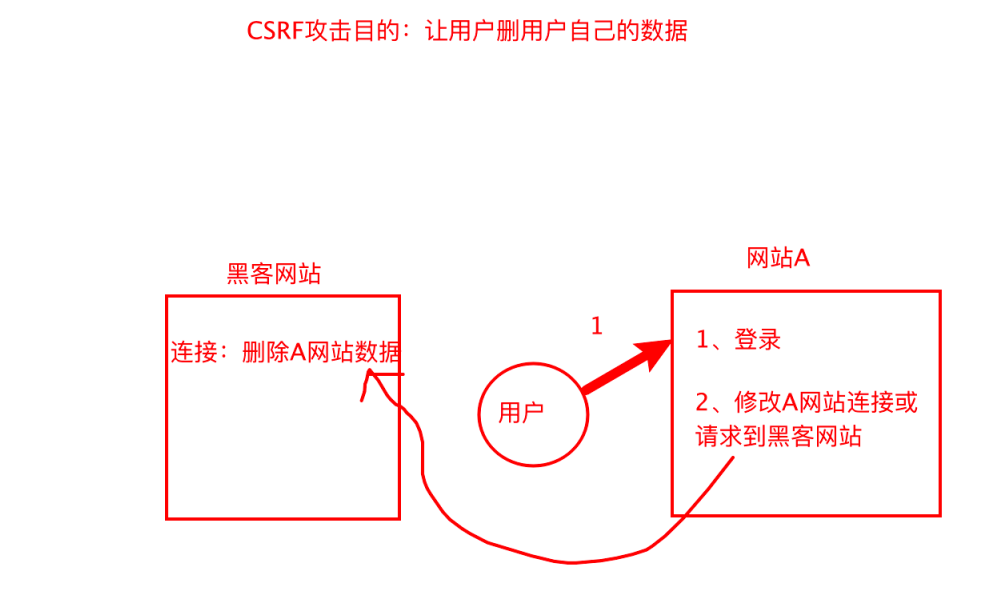

攻击操作步骤:
1、获取删除或修改⽹站数据的接⼝
2、在⿊客⽹站上⽣成⼀个删除或修改连接(领取优惠券)
3、⿊客在要攻击的⽹站上⽣成⼀个跳转到⿊客⽹站的链接(优惠活动)
4、⽤户在⿊客⽹站上点击领取优惠券。
检查项⽬是否对请求头->HTTP Referer做校验。后台判断是操作请求来源只能是⾃⼰的⽹站
防御
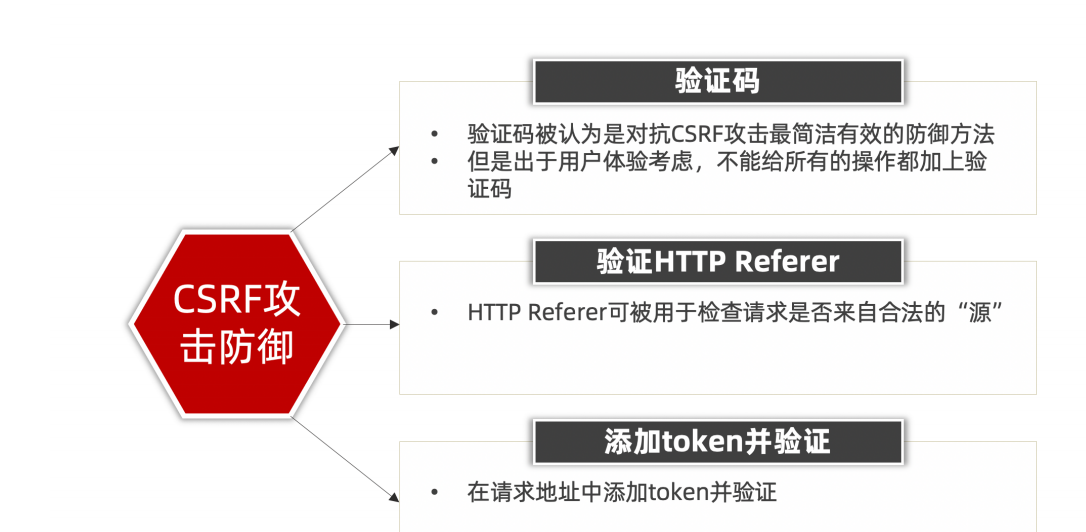
HTTP Referer:请求头来源的显示,从哪个点击链接访问,会记录链接访问的地址
网络安全
协议加密
数据加密
数据签名
DOS攻击
协议加密:常⽤HTTPS协议(基于HTTP协议之上进⾏加密传输和证书策略)
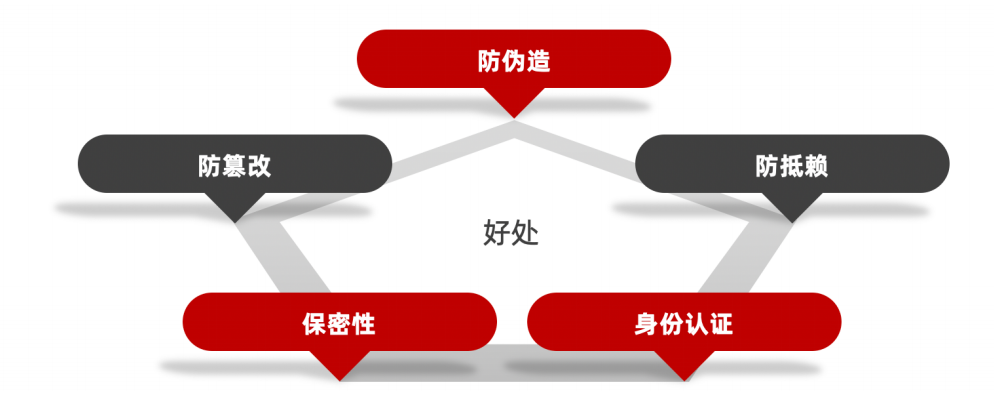
1、数据完整性
2、数据保密性
3、安全校验
数据加密
数据加密:md5/AES/DES/⾃定义 1
数据签名:
特点:对请求数据⽣成⼀个⽆法伪造的字符串,发送给服务器
Dos攻击
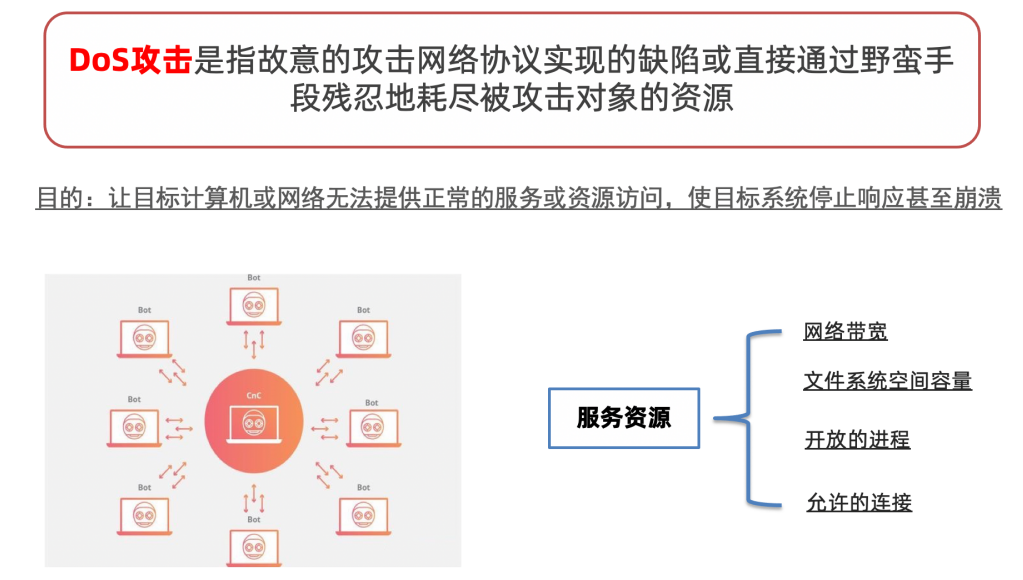
防御:
1、请求添加访问时间戳,服务器进⾏判断是否在有效期内,如果在处理,否则不处理。
2、指定时间内控制请求参数(百度->1秒之内3次)
3、流量限制(验证码->越模糊越好。)
用户认证安全策略
1、密码登录
①:session
②:token
2、其他登录
提示:
1、密码纯6位数字,有106
2、密码纯8位数字,有108
session
说明:密码登录成功后,服务器可以⽣成session|token|cookie等认证⽅式来进⾏后续认证处理
特点:session:⼀次会话(会话结束session关闭)
危害:如果在session会话有效期内,session被盗取,那么后果是很可怕的(相当于账号密码
泄漏)
防护策略:
在⼀定时间后后台关闭session
相同⽤户只能⽣成1个对象。
当⽤户客户端发⽣变化(浏览器、ip发⽣改变)时,要求⽤户重新登录
养成好的习惯,⽤户退出后,及时清除session信息
暴力破解
说明:理论来说,是密码就⼀定可以通过多次尝试来进⾏破译,这种称为暴⼒破解
提示:暴⼒破解⼀般使⽤密码字典结合⾃动化程序来实施。
防护:

权限安全漏洞
危害:容易出现越权操作(查看别⼈信息、删除他⼈的信息、查看核⼼数据)
分类
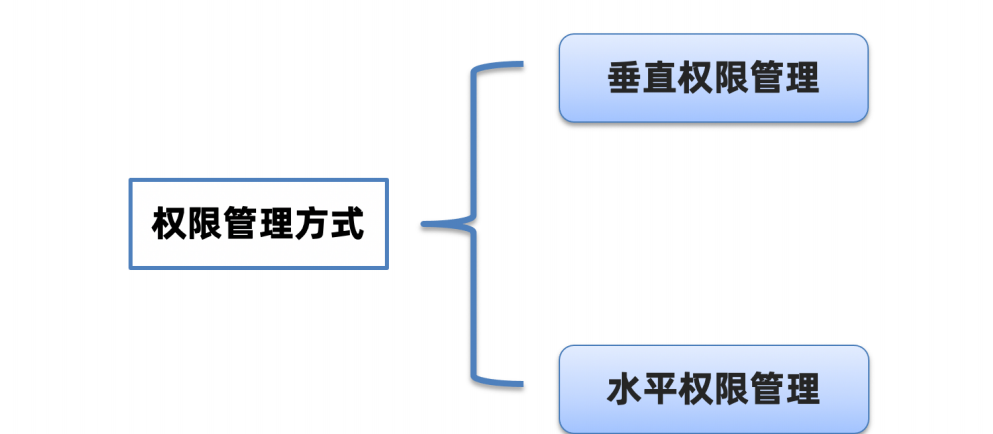
提示:权限漏洞主要验证垂直权限(基于⽤户⻆⾊设置权限),⽔平权限暂时⽆法验证
应用服务器安全
1、sql注⼊(项⽬数据库)
2、⽂件上传(针对应⽤服务器代码)
sql注⼊
说明:sql注⼊,顾名思义就是通过⻚⾯输⼊sql语句,达到特定的⽬的。
危害: 数据库丢失,意味攻击者可以⽤任何⼈的账号进⾏违规操作
原理:
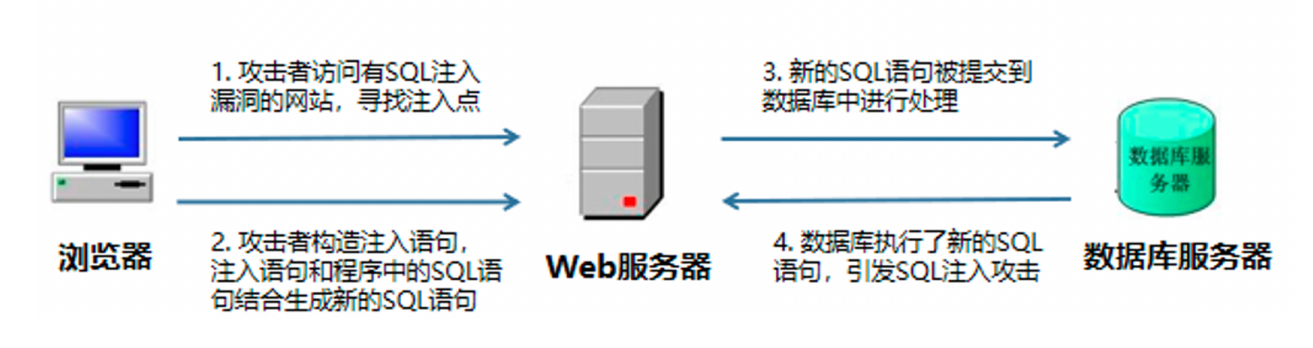
步骤:
1、在⻚⾯输⼊框中查找注⼊点
2、注⼊sql语句
3、通过sql语句获取项⽬库名、表名、字段名
4、通过mysql数据库⾃⼰的库,获取项⽬库中所有的表、字段、数据。
安全测试(sql注⼊),查找注⼊点
1、⽅式1:⼿动,在输⼊框中输⼊’,看提示信息。如果提示相关sql报错信息且是语句拼接⽅式,说明可
以sql注⼊。
2、⽅式2:使⽤专业的⼯具进⾏扫描。
sql注入防护:
1、对⽤户的输⼊数据进⾏校验
2、不要动态拼装SQL,使⽤参数化语句
3、不要使⽤管理员权限的数据库连接,为每个应⽤使⽤单独的权限进⾏数据库连接
4、不要把敏感数据直接保存到数据库中
5、应⽤的异常信息应该给出尽可能少的提示,最好使⽤⾃定义的错误信息对原始错误信息进⾏包装
应⽤服务器(⽂件上传漏洞)
危害: 获取正向web项⽬的⽬录和⽂件(源代码暴露)
原理:
1、利⽤上传功能,上传恶意⽂件
2、执⾏恶意⽂件
3、获取项⽬源代码
防护:
数据库安全
安全防护策略
数据备份和恢复
敏感数据加密
审计追踪机制
认证和权限控制
数据备份和恢复
数据库必须有备份,正常1天1个备份
敏感数据加密
审计追踪机制(对数据库操作,尤其是(删除、修改、新增)操作,必须有⽇志记录)
认证和权限控制
不能给root权限。
⽂件操作必须有权限控
接口加解密
加解密说明

1、找开发拷⻉加密和解密⼯具
2、确定⼯具如何使⽤(如何加密、如何解密)
3、明确请求示例(请求参数格式及使⽤
接⼝-案例
接⼝说明:登录接⼝
请求⽅法:POST
请求参数类型:form
url:“http://mobile-p2p-test.itheima.net/phone/member/login”
请求参数
data = {
“member_name”: “13012345678”,
“password”: “test123”
}
未加密解密
import requests
url = "http://mobile-p2p-test.itheima.net/phone/member/login"
data = {
"member_name": "13012345678",
"password": "test123"
}
result = requests.post(url,data=data)
print(result.json())
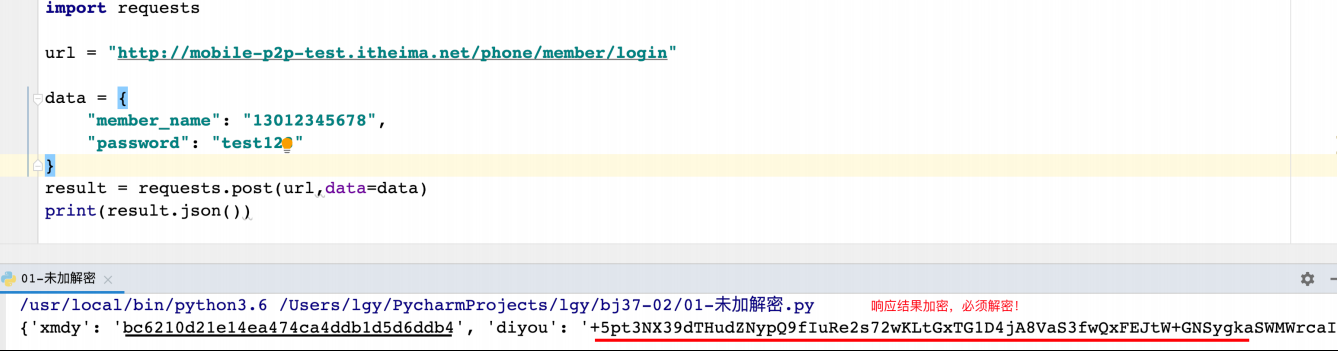
加解密应⽤示例
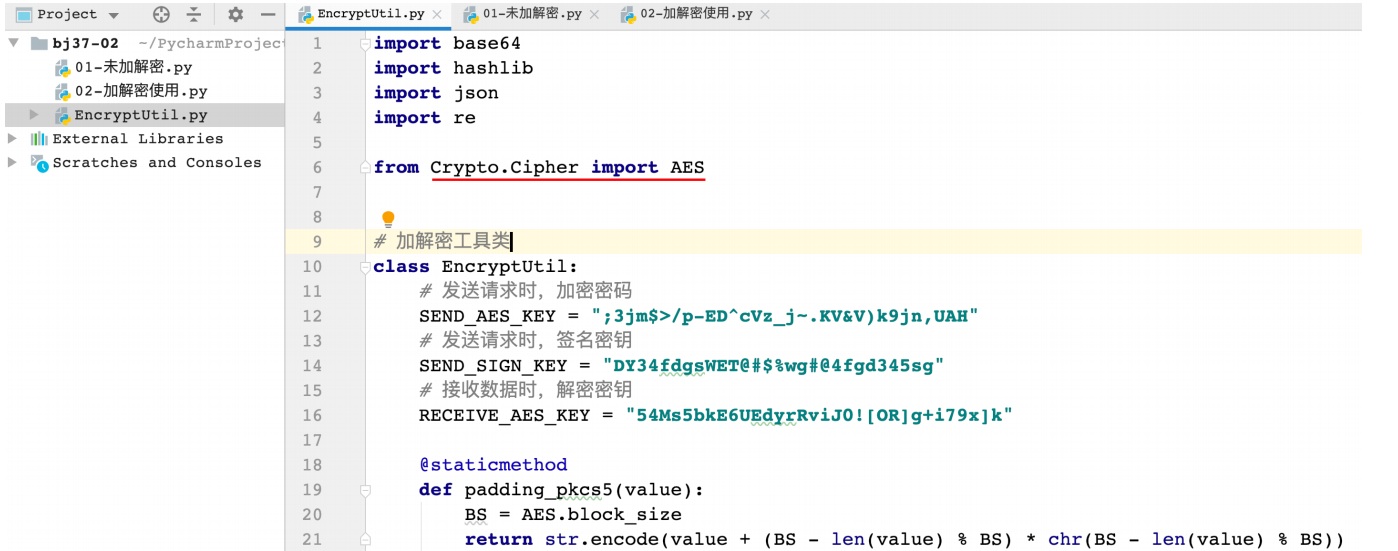
1、加解密工具
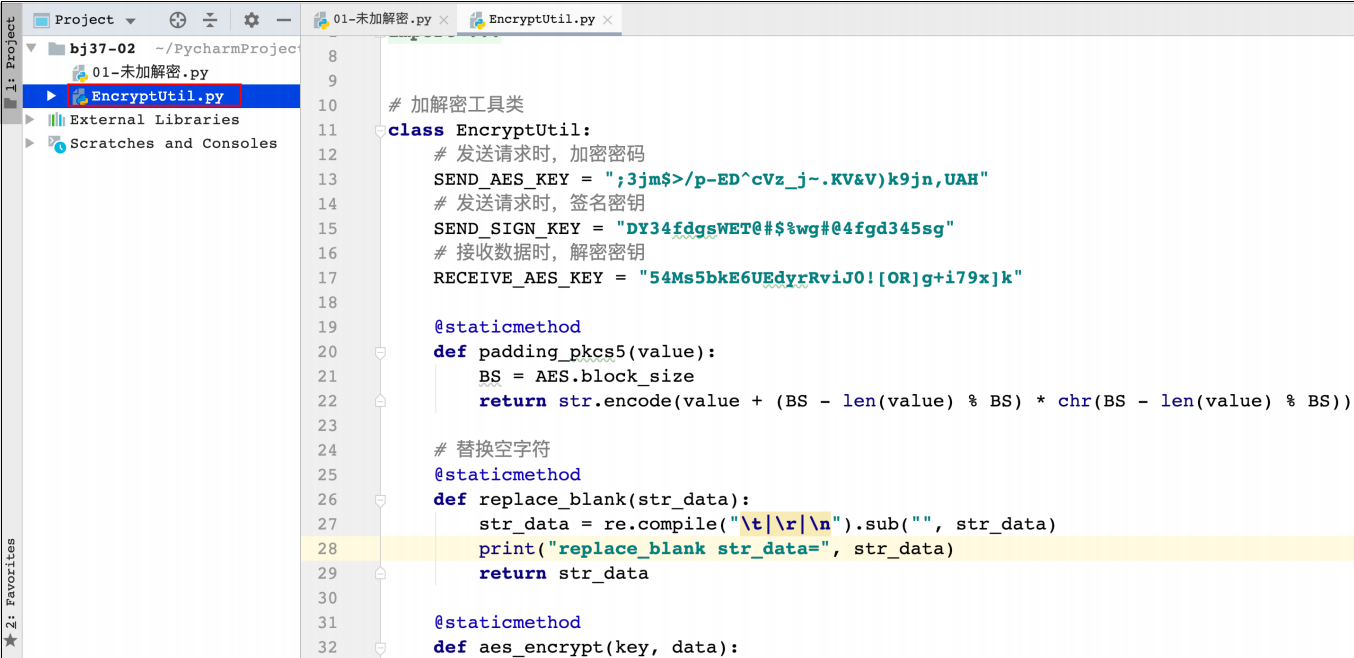
2、确定⼯具如何使⽤
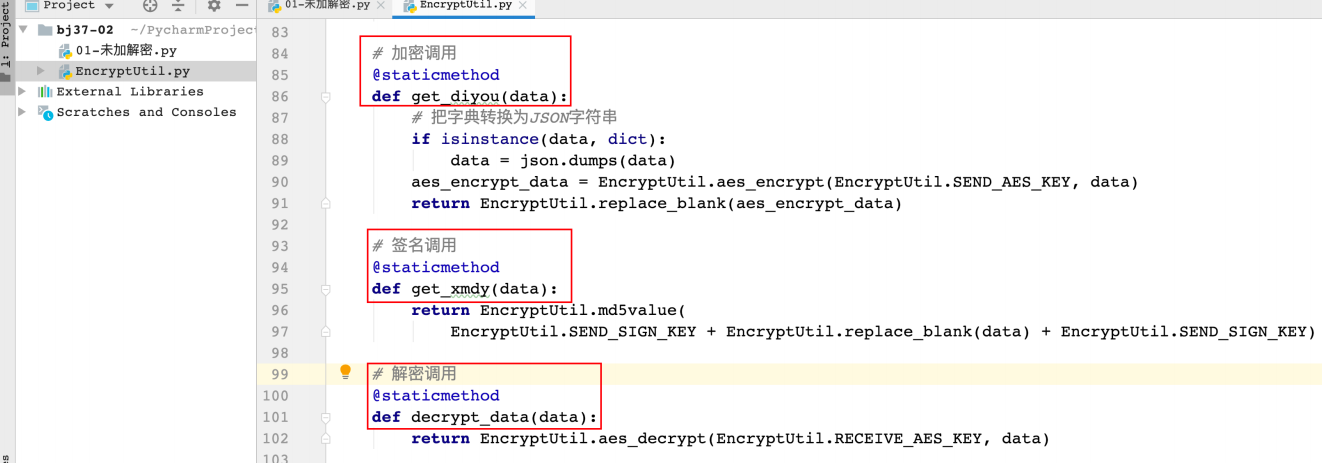
3、明确请求示例

import requests
from EncryptUtil import EncryptUtil
url = "http://mobile-p2p-test.itheima.net/phone/member/login"
data = {
"member_name": "13012345678",
"password": "test123"
}
# 1、对请求参数进⾏加密
diyou = EncryptUtil.get_diyou(data)
# 2、对加密后的数据进⾏签名
xmdy = EncryptUtil.get_xmdy(diyou)
# 3、调⽤请求 参数格式 {"xmdy":"签名","diyou":"加密后数据"}
result = requests.post(url,data={"xmdy":xmdy,"diyou":diyou})
# 4、响应数据解密
diyou = result.json().get("diyou")
print("--" * 50)
print("解密后的数据",EncryptUtil.decrypt_data(diyou))
加密解密标准
说明:加密标准常⽤美国联邦政府⾼级密码标准(AES)
安装:
pip install pycryptodome==3.9.6 -i https://pypi.douban.com/simple 1
提示:拿到⼯具如果报错提示缺少库,需要跟开发确定安装的依赖库














 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









