







RDMA官方文档学习笔记(一)
RDMA 编程
此文当分为
1.RDMA结构概述(介绍支持RDMA的几种网络技术)
2.RDMA编程概述
3.4.介绍了IB结构提出的两个底层函数库API,通过这些API,我们可以实现数据传输
5.介绍了RDMA API
6.介绍了VPI API各种报错内容
7.8.提供了RDMA编程的两个例子
本笔记讨论第一二章内容,笔记(二)讨论编程例子
笔记格式为,标题下加点的归自己的理解,下文为官方文档翻译。
对RDMA官方文档前两章内容基本没有做任何阉割
我基本在每一个难理解的概念上会加一篇大佬写的解析
本文格式为:
1.概念(标题)
2.参考详解
3.个人笔记
4.文档翻译
1.RDMA Architecture Overview&Glossary
1.1 InfiniBand
- infiniband是随着CPU高速发展,为摆脱I/O设备制约性能,多家领头企业牵头提出的新的系统互联的标准,是一种新的技术,基于此技术(架构),我们得以实现RDMA操作,但RDMA操作是一个更简单,更上层的操作,多种技术(架构)都支持。
- infiniband架构核心就是将I/O系统从服务器主机中分离出来
- infiniband架构核心部件分为HCA,TCA,infiniband link,交换机和路由器
- infiniband提供了两种函数库(非常底层)VPI verbs API和RDMA_CM verbs API,通过调用这两个函数库中的内容,我们可以实现设备之间的数据传输。包括构建RDMA
HCA链接内存和TCA,TCA将I/O设备的数据发送给HCA,infinband link它是连接HCA和TCA的光纤。
InfiniBand(IB)是一种服务器和存储器的互联技术,它具有高速、低延迟、低 CPU 负载、 高效率和可扩展的特性。InfiniBand 的关键特性之一是它天然地支持远程直接内存访问(RDMA) 。InfiniBand 能够让服务器和服务器之间、服务器和存储设备之间的数据传输不需要主机的 CPU 的参与。InfiniBand 使用 I/O 通道(每个主机最多可有 16M 个)进行数据传输,每个I/O 通道提供虚拟的 NIC 或 HCA 语义(安全,隔离等)。
1.2 VPI (Virtual Protocol Interface)
- 此VPI同时支持IB与ethernet网络模式,既可以在两种网络模式下配置端口传输方式
- IB与ethernet是两种网络连接模式
- 一般若要使用infiniband架构,一般需要一个infiniband网卡,这张网卡支持IB模式与传统ethernet模式,我认为这里提到的配置应该是指在一个IB网卡上进行的配置。
Mellanox(高性能计算、数据中心端到端互连方案提供商Mellanox) 的 VPI 架构为同时支持 IB 和 Ethernet (以太网)的网络提供了高性能、低延迟和高可靠性,保障了适配器和交换机这些设备之间的数据传输。一个 VPI适配器或交换机可以通过使用 IB 语义或者 Ethernet 语义在每个端口设置传输方式。例如,一个双端口的 VPI 适配器可以进行如下设置:
一个适配器(HCA)(IB结构之一)配置两个 IB 端口;
一个网卡(NIC)配置两个 Ethernet 端口;
一个适配器同时配置一个 IB 端口和一个 Ethernet 端口。
类似地,一个 VPI 交换机可以配置为仅有 IB 的端口、仅有 Ethernet 的端 口或者有 IB 端口和 Ethernet 端口同时工作。 Mellanox 支持的 VPI 适配器和交换机既支持 IB 的 RDMA 也支持 Ethernet 的RoCE 方案。
1.3 RDMA over Converged Ethernet (RoCE)
- 在以太网中支持RDMA的技术
- 被称作IB协议的低成本解决方案,但一些情况下性能有一些损失
RoCE 是基于以太网(Ethernet)的 RDMA 的技术标准,它也是由 IBTA 组织制定的。RoCE 为以太网ᨀ供了 RDMA 语义,并且不需要复杂低效的 TCP 传输 (例如,iWARP 则需要)。 RoCE 是现在最有效的以太网低延迟方案。它消耗很少的 CPU 负载,它在数据中心桥接以太网中利用优先流控制(PFC)来达到网络的无损连通。自从 OFED1.5.1 版本开始,Open Fabrics Software 就已经对 RoCE 有很好的支持。
1.4 Comparison of RDMA Technologies
https://zhuanlan.zhihu.com/p/361740115
- 目前有三种支持RDMA的技术,分别是IB、以太网 RoCE、以太网 iWARP,三种技术均使用本文中定义的同一API(三种技术有着不同的物理层链接,但应该是定义了功能相同的API,方便实使用)
- 在以太网解决方案中RoCE相比iWARP有更大的优势
- 以下文档内容讲的RDMA基础知识基本重复概括为:
- RDMA利用栈旁路和零拷贝技术提供了低延迟的特性,同时,减少了 CPU 占用,减少了内存带宽瓶颈, 提供了很高的带宽利用率。
- TCP/IP 在所有操作中都需要操作系统的干预,包括网络两终端结点 的缓冲区拷贝。即应用程序想要发送数据,需要先将数据存入一个匿名缓冲区
- IB发送数据的方式为:将数据分解成数个数据包,大小取决于网络路径的做大传输单元,直接发送大接受机器虚拟内存中。
目前,有三种支持 RDMA 的技术:IB、以太网 RoCE、以太网 iWARP。这三种技术使用本文中定义的同一 API,但它们有着不同的物理层和链路层。
在以太网解决方案中,RoCE 相对于 iWARP 来说有着明显的优势,这些优势体现在延时、吞吐率和 CPU 负载。RoCE 被很多主流的方案所支持,并且被包含在 Windows 服务软件中(IB 也是)。
RDMA 技术基于传统网络的概念,但与 IP 网络又有些不同。最关键的不同是RDMA 提供了一种消息服务, 利用这种服务,应用程序可以直接访问远程计算机上的虚拟内存。消息服务可以用来进行网络中进程 的通信(IPC)、与远程服务器进行通信和在一些上层协议(ULPs)的协助下与存储设备进行数据传递。上层 协议(ULPs)有很多,例如:iSCSI 的 RDMA 扩展(iSER)、SCSI RDMA 协议(SRP)、SMB、Samba 、Lustre、ZFS 等等。
RDMA 利用栈旁路和零拷贝技术提供了低延迟的特性,同时,减少了 CPU 占用,减少了内存带宽瓶颈, 提供了很高的带宽利用率。RDMA 所带来的关键好处得益于 RDMA 消息服务呈现给应用的方式,和底层用来 发送和传递这些消息的技术。RDMA 提供了基于 IO 的通道。这种通道允许一个应用程序通过 RDMA 设备对 远程的虚拟内存进行直接的读写。
在传统的套接字网络中,应用程序要向操作系统申请使用网络资源时,要通过特定的 API 来管理程序的 相关行为。但是,RDMA 使用操作系统仅仅建设一个通道,然后就可以在不需要操作系统的干预下,应用 程序之间就能够进行直接的消息传递。一个消息可以是 RDMA 读或写操作,也可以是发送/接收操作。IB 和 RoCE 也都支持多播模式。
IB 在链路层提供的特性有:基于信任的流控制机制用来进行拥塞控制。它也支持使用虚拟局域网(VLs), 虚拟局域网能够使高层协议简单化,并且提供高质量服务(QoS)。VL 中严格保证数据在一条路径中能够 按序到达。IB 的传输层提供可靠性和交付性保障。
IB 网络层拥有的特性使它能够很简单地在应用程序的虚拟内存之间传递消息,尽管应用参与通信的应用程序运行在不同的物理服务器上。因此,将 IB 传输层和软件传输接口组合起来,可以看成是一种 RDMA 消息传输服务。包括软件传输接口的整个协议栈,包含了 IB 消息服务。
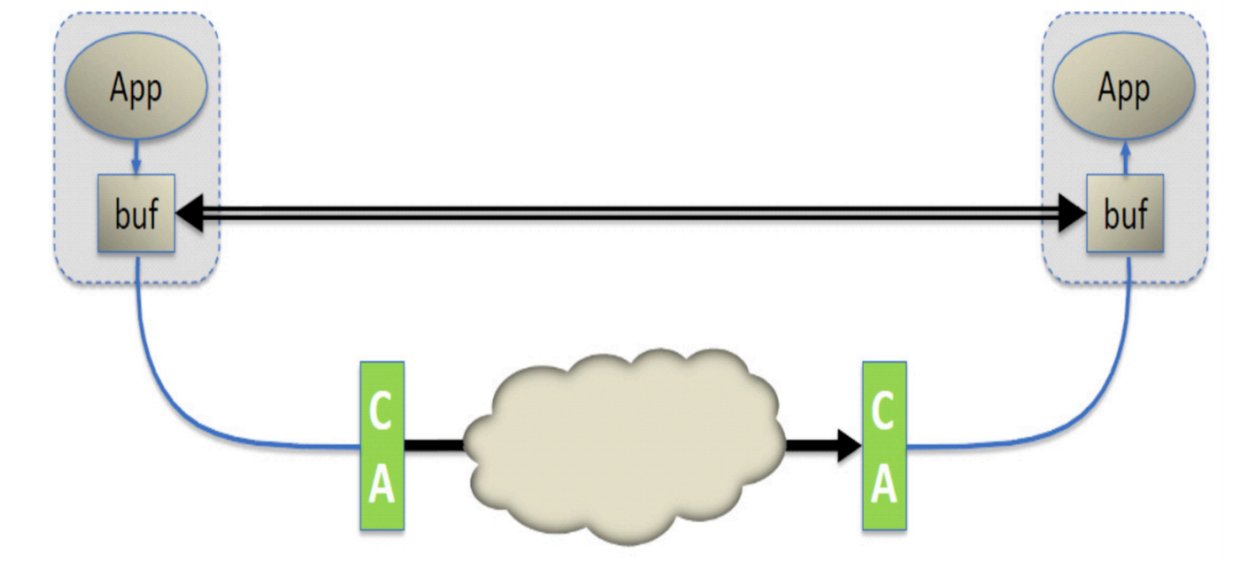
最重要的一点是,每个应用程序都能直接访问集群中的设备的虚拟内存。这意味着,应用程序 传输消息时不需要向操作系统发出请求。与传统的网络环境相比,传统网络中共享的网络资源归操作所有,不能由用户态程序直接使用,所以,一个应用程序必须在操作系统的干预下将数据从应用程序的虚拟内
存通过网络栈传送到网线上。类似地,在另一端,应用程序必须依靠操作系统获取网线上的数据,并将数据放到虚拟缓冲区中。
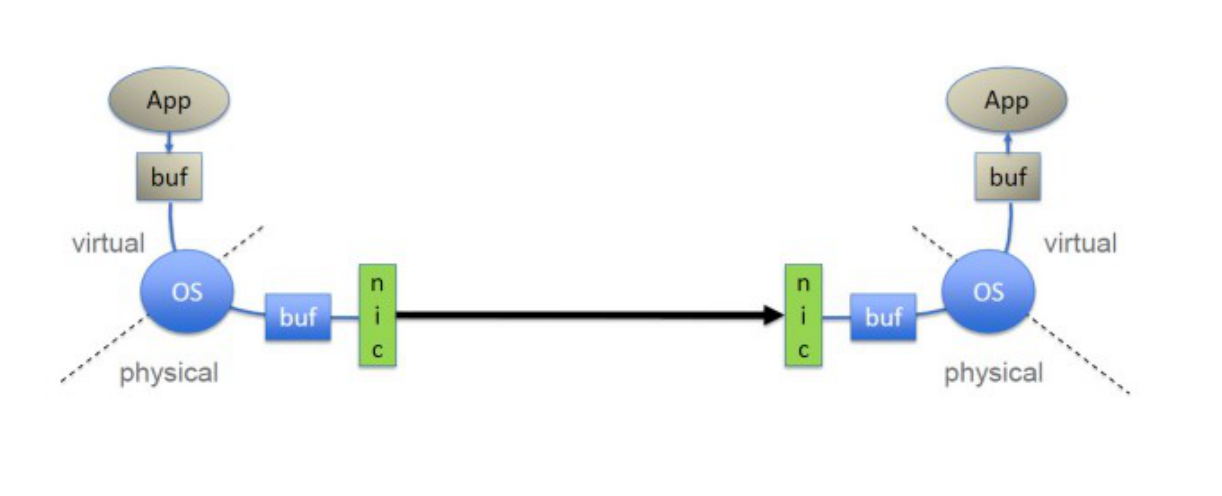
TCP/IP/Ethernet 是一种面向字节流的传输方式 ,信息以字节的形式在套接字应用程序之间传递。TCP/IP 本身是不可靠的(传输过程中数据可能丢失或者失序),但是它利用传输控制协议 (TCP)来实现可靠性机制。TCP/IP 在所有操作中都需要操作系统的干预,包括网络两终端结点 的缓冲区拷贝。在面向字节流的网络中,没有消息的边界概念。当一个应用想要发送一个数据包, 操作系统把这些字节数据放入内存中属于操作系统的一个匿名缓冲区,当数据传输完毕时,操作 系统把它缓冲区中的数据拷贝到应用程序的接收缓冲区。这个过程在每个包到达时都会重复执行, 直到整个字节流被接收到。TCP 负责将任何因拥塞导致的丢包进行重发。
在 IB 中,一个完整的消息被直接发送到一个应用程序。一旦一个应用程序请求了 RDMA 的读或写传输, IB 的硬件将需要传输的数据按照需要分割成一些数据包,这些数据包的大小取决于网络路径的最大 传输单元。这些数据包通过IB 网络,被直接发送到接收程序的虚拟内存中,并在其中被组合为一个完整的消息。当整个消息都到达时,接收程序会接收到提示。这样,发送程序和接收程序在直到整个消息被发送到达接收程序的缓冲区之前都不会被打扰中断。
1.5 RDMA_CM (Remote Direct Memory Access Communication Manager)
- 通过调用更底层的VPI,更方便的给用户使用RDMA
- infiniband提供了两种函数库(非常底层)VPI verbs API和RDMA_CM verbs API之一
API used to setup reliable, connected and unreliable datagram data transfers. It provides an RDMA transport neutral interface for establishing connections. The API is based on sockets, but adapted for queue pair (QP) based semantics: communication must be over a specific RDMA device, and data transfers are message based.
用来建立可靠性连接和不可靠性数据报传输的 API。 它为建立连接ᨀ供了 RDMA 传输接口。 此 API 基于套接字,同时又适用于基于 QP 的语义:信息传递必须通过专门的 RDMA 设备, 并且数据传输是基于消 息机制。
2.RDMA-Aware Programming Overview
- 通过使用VPI建立基础QP机制实施RDMA操作
VPI 架构允许在用户态下直接对硬件进行访问。Mellanox 提供了一个动态链接库,通过 verbs 的 API 对硬件进行访问。本文档包含 verbs 和与之相关的输入、输出、描述和被暴露在操作系统编程接口的功能。
标注:此编程手册和它的 verbs 仅适用于用户态,如果想查看内核态的verbs,可以查看头文件。
使用 verbs 进行编程可以定制和优化支持 RDMA 的网络程序。这种定制和优化只有对 VPI 系统有着丰富 知识和经验的程序员才能胜任。
为了执行 RDMA 操作,首选需要建立与远程主机的连接和适当的认证。实现这些的机制是队列对(QP) 。与标准的 IP 协议栈类似,一个 QP 大概等同于一个套接字(socket)。QP 需要在连接两端进行初始化。 连接管理器(CM)用来在 QP 建立之前进行 QP 信息的交换。
一旦一个 QP 建立起来,verbs API 就可以用来执行 RDMA 读/写和原子操作。与套接字的读/写类似的连续收/发操作也能执行。
2.1 Available Communication Operations
详解:
https://zhuanlan.zhihu.com/p/142175657
2.1.1 Send/Send With Immediate
- 这里所展示的SEND与RECEIVE操作为普通的双端操作,即在发送时需要调用发送与接收两个对象的CPU,与RDMA读写具有差别
发送操作允许你把数据发送到远程 QP 的接收队列里。接收端必须已经事先注册好了用来接收数据的缓冲 区。发送者无法控制数据在远程主机中的放置位置。
可选的,一个 4 字节的即时数可以和数据缓冲一起被传送。这个即时数发送到接收端是作为接收的通知,不包含在数据缓冲之中。
2.1.2 Receive
这是与发送操作想对应的操作。接收主机被告知接收到数据缓冲,还可能附带一个即时数。接收端应用 程序负责接收缓冲区的维护和发布。
2.1.3 RDMA Read
- 一旦远端的内存区域被注册,则对那片区域的读写将不受远端CPU的控制,即将其释放了
从远程主机读取部分内存。调用者指定远程虚拟地址,像本地内存地址一样用来拷贝。在执行 RDMA 操作 之前,远程主机必须提供适当的权限来访问它的内存。一旦权限设置完成,RDMA 读操作就可以在对远程 主机没有任何通知的条件下执行。不管是 RDMA 读还是 RDMA 写,远程主机都不会意识到操作正在执行 (除了权限和相关资源的准备操作)。
2.1.4 RDMA Write / RDMA Write With Immediate
与 RDMA 读类似,只是数据写到远程主机中。RDMA 写操作在执行时不通知远程主机。然而,带即时数的 RDMA 写操作会将即时数通知给远程主机。
2.1.5 Atomic Fetch and Add / Atomic Compare and Swap
这些是 RDMA 操作的原子操作扩展。原子取和加操作原子性地将特定虚拟地址中的数加上特定的值。被加之前的数返回给调用者。
原子比较和交换操作,原子性地将特定虚拟地址中的数与另一个特定的数对比,如果它们相等,那么这一特定的数将会被存在上述的特定虚拟地址中。
2.2 Transport Modes
详细解析:
https://zhuanlan.zhihu.com/p/144099636
在建立一个 QP 的时候,有几种不同的传输模式可供选择。每种模式中可用的操作如下表所示。 RD 操作在此 API 中不支持。
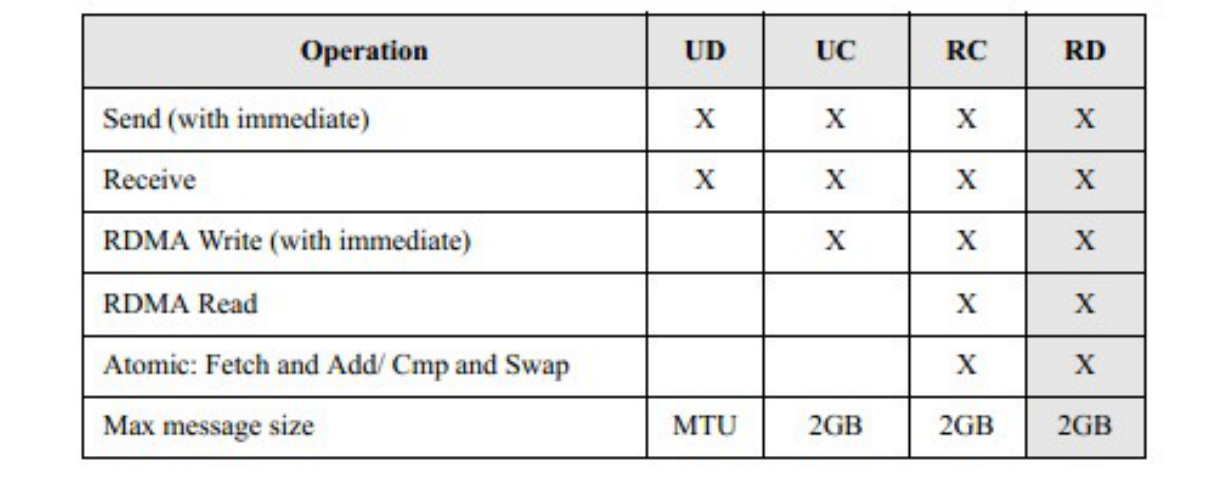
2.2.1 Reliable Connection (RC)
一个 QP 只和一个另外的 QP 相连。消息通过一个 QP 的发送队列可靠地传输到另一个 QP 的接收队列。数据包按序交付。 RC 连接很类似于 TCP 连接。
2.2.2 Unreliable Connection (UC)
一个 QP 只和一个另外的 QP 相连。
连接是不可靠的,所以数据包有可能会丢失。
2.2.3 Unreliable Datagram (UD)
一个 QP 可以和其它任意的 UD QP 进行数据传输和单包数据的接收。不保证按序性和交付性。交付的数据包可能被接收端丢弃。支持多播消息(一对多)。
UD 连接很类似于 UDP 连接。
2.3 Key Concepts
- 一下关键词都是一些结构,在这些结构中存储各种信息,看代码再理解效果好一些
2.3.1 Send Request (SR)
SR 定义了数据的发送量、从哪里、发送方式、是否通过 RDMA、到哪里。 结构 ibv_send_wr 用来描述 SR。
2.3.2 Receive Request (RR)
RR 定义用来放置通过非 RDMA 操作接收到的数据的缓冲区。如没有定义 缓冲区,并且有个传输者 尝试执行一个发送操作或者一个带即时数的 RDMA写操作,那么接收者将会发出接收未就绪的错误(RNR)。结构 ibv_recv_wr 用来描述 RR。
2.3.3 Completion Queue
https://zhuanlan.zhihu.com/p/259650980
(CQ)完成队列包含了发送到工作队列(WQ)中已完成的工作请求(WR)。每次完成表示一个特定的 WR 执行完毕(包括成功完成的 WR 和不成功完成的 WR)。
完成队列是一个用来告知应用程序已结束的工作请求的信息(状态、操作码、大小、来源)的机制。CQ 有 n 个完成队列实体(CQE)。CQE 的数量在 CQ 创建的时候被指定。 当一个 CQE 被轮询到,它就从 CQ 中被删除。
CQ 是一个 CQE 的先进选出(FIFO)队列。CQ 能服务于发送队列、接收队列或者同时服务于这两种队列。多个不同 QP 中的工作请求(WQ)可联系到同一个 CQ 上。结构 ibv_cq 用来描述 CQ。
2.3.4 Memory Registration
https://zhuanlan.zhihu.com/p/156975042
- 内存注册的意思是在远端申请一片用于RDMA读写的内存
内存注册机制允许应用程序申请一些连续的虚拟内存空间或者连续的物理内存空间,将这些内存空间ᨀ供给网络适配器作为虚拟的连续缓冲区,缓冲区使用虚拟地址。
内存注册进程锁定了内存页。(为了防止页被替换出去,同时保持物理和虚拟内存的映射)
在注册期间,操作系统检查被注册块的许可。
注册进程将虚拟地址与物理地址的映射表写入网络适配器。
在注册内存时,对应内存区域的权限会被设定。权限包括本地写、远程读、远程写、原子操作、绑定。
每个内存注册(MR)有一个远程的和一个本地的标志(r_key,l_key)。本地标志被本地的 HCA 用来访问本地内存,例如在接收数据操作的期间。远程标志提供给远程 HCA 用来在 RDMA 操作期间允许远程进程访问本地的系统内存。
同一内存缓冲区可以被多次注册(甚至设置不同的操作权限),并且每次注册都会生成不同的标志。
结构 ibv_mr 用来描述内存注册。
2.3.5 Memory Window
https://zhuanlan.zhihu.com/p/353590347
内存窗口使应用程序对来自远程对本地的内存访问有更灵活的控制。内存窗口(MW)作用于以下 应用场景:
动态地授予和收回已注册缓冲区的远程访问权限,这种方式相比较与将缓冲区取消注册/再注册或者重注册,有些更低的性能损耗代价。
想为不同的远程代理授予不同的远程访问权限,或者在一个已注册的缓冲区中的不同范围内授予那些权限。
内存窗口和内存注册之间的关联操作称为绑定。
不同的 MW 可以作用于同一个 MR(即使有着不同的访问权限)。
2.3.6 Address Vector - 描述节点之间的路由,调用函数时会用到
地址向量用来描述本地节点到远程节点的路由。
在 QP 的每个 UC/RC 中,都有一个地址向量存在于 QP 的上下文中。
在 UD 的 QP 中,每个提交的发送请求(SR)中都应该定义地址向量。
结构 ibv_ah 用来描述地址向量。
2.3.7 Global Routing Header (GRH)
- https://community.mellanox.com/s/article/lrh-and-grh-infiniband-headers
- 类似于一种协议吧,官网也跳过了
GRH 用于子网之间的路由。当用到 RoCE 时,GRH 用于子网内部的路由,并用是强制要使用的。强制使用 GRH 是为了保证应用程序即支持 IB 又支持 RoCE。
当全局路由用在基于 UD 的 QP 时,在接收缓冲区的前 40 字节会包含有一个 GRH。这个区域是专门用来存储全局路由信息的,为了回应接收到的数据包,会产生出一个合适的地址向量。如果 GRH 用在 UD 中, 接收请求(RR)应该总是有额外的 40 字节用来存储 GRH。
结构 ibv_grh 用来描述 GRH。
2.3.8 Protection Domain
https://zhuanlan.zhihu.com/p/159493100 - 建立的目的是为了防止远端机器访问错误QP,MR等
- 条件是一台机器与多个远端机器进行通信,为防止远端机器错误放到到其他数据,建立PD
一种集合,它的内部元素只能与集合内部的其它元素相互作用。这些元素可以是 AH,QP,MR 和 SRQ。
保护域用来队列对(QP)与内存注册和内存窗口想关联,这是一种授权和管理网络适配器对主机系统 内存的访问。
PD 也用来将基于不可靠数据报(UD)的 QP 关联到地址处理(AH),这是一种对 UD 目的端的访问控制。
结构 ibv_pd 用来描述保护域。
2.3.9 Asynchronous Events
网络适配器可能会发送异步事件来通知子网管理器(SW)系统中发生的事件。
有两种异步事件:
附属事件:这些事件在私有对象(CQ,QP,SRQ)中发生的事件。这些事件会被发送到特定的进程。
非附属事件:这些事件在全局对象(网络适配器,端口错误)中发生的事件。这些事件会被发送到所有进程 。
2.3.10 Scatter Gather
- 便于使用目的主机内存的一种方式
- 通过将内存聚集到一块,每一块称为SGE,即Scatter Gather Element
用分散聚合元素来分散和聚合数据。这些元素包括:
地址:本地数据缓冲区的地址,是数据聚合的终点或者是数据分散的源头。
大小:数据的大小会写到这个地址或者从这个地址读取。
L_key:注册到这个缓冲区的 MR 的本地标志。
结构 ibv_sge 用来描述分散聚合元素。
struct ibv_sge
{
uint64_t addr;
uint32_t length;
uint32_t lkey;
};
addr: 数据段所在的虚拟内存的起始地址 (Virtual Address of the Data Segment (i.e. Buffer))
length: 数据段长度(Length of the Data Segment)
lkey: 该数据段对应的L_Key (Key of the local Memory Region)
2.3.11 Polling
- 轮询的概念是不断的去访问CQE与WQE,去剔除已经完成的任务,并观察是否有异常
轮询 CQ 中的完成信息是为了获取已ᨀ交的 WR(发送或者接收)的详细信息。如果我们在 WR 中发现一个异常状态的完成,接下来的完成都会异常(同时 WQ 会被移至错误状态)。
每个没有完成(被轮询到)的 WR 都属于待处理状态。
只有在 WR 完成之后,发送/接收缓冲区才可能被使用/再使用/释放。
应该经常检测完成状态。当一个 CQE 被轮询,那么它就被从 CQ 中移除。
轮询通过 ibv_poll_cq 操作来实现。
下一笔记将直接写关于7.8章内容(RDMA变成例子)或者写环境配置















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









