






这篇博客介绍 PyTorch 中自动微分引擎的实现,主要分为三部分:首先简要介绍一下计算图的原理;然后介绍 PyTorch 中与 autograd 的相关数据结构和 backward()函数的实现,数据结构包括 torch::autograd::Variable, torch::autograd::Function 等;最后讲一下动态建立计算图的实现,这部分代码涉及到动态派发机制,而且都是用脚本生成的,不太容易理解。
计算图简介
计算图是一个有向图,它的每个节点都表示一个函数(如加减乘除等)或者输入数据(叶子节点)。计算图的边代表数据流向:指向某个节点的边为该节点的输入,由该节点流出的边表示它的输出。计算图可以用来描述神经网络的计算,如下图描述了 y=sin(xa+b) 的计算过程:
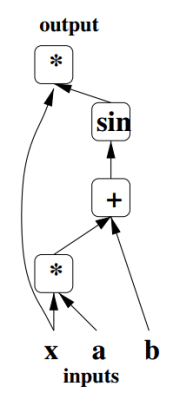
计算图的求值分为前向传播和反向传播,分别用于计算输出和梯度。前向传播的过程就是从叶子节点开始遍历计算图,直到整个图都被遍历过;而反向传播就是从输出节点开始遍历,节点表示的函数也变为原函数对输入的导数。举个栗子,下面是addcmul()函数的计算图的前向和反向计算过程:

Autograd Engine
介绍完了标准的计算图结构,那么PyTorch里面是怎么实现的呢?在回答这个问题之前首先要看几个相关的数据结构,分别是Variable, AutogradMeta, Function和Edge。
Variable
相信用过老版本的PyTorch的小伙伴对Variable一定不会陌生,它是用来实现自动微分的核心数据结构,代码在torch/csrc/autograd/variable.h。Variable可以表示计算图中的叶子节点,如权重,也可以表示图中的中间变量,虽然在新版本中Tensor与Variable合并了,在前端中可以直接用Tensor代替Variable,但是Variable并没有消失。
它的实现确实改变了,但功能依旧。Variable继承自at::Tensor,重载了Tensor里与梯度计算相关的方法,同时也提供了和Tensor隐式转换的构造函数。
Variable的底层实现Variable::Impl也继承at::TensorImpl,这个类在此系列的第一篇中介绍过,它里面有一个成员bool is_variable,用于识别这个 Tensor 到底是at::Tensor还是Variable。TensorImpl里还有一个重要的成员:
std::unique_ptr<c10::AutogradMetaInterface> autograd_meta_=nullptr;
autograd_meta_记录了当前与Variable相关的计算图信息,在Variable::Impl里它被强制转换成AutogradMeta*类型:
Variable::AutogradMeta* get_autograd_meta() const {
return static_cast<Variable::AutogradMeta*>(autograd_meta());
}
其中AutogradMeta类型实现了c10::AutogradMetaInterface接口。
AutogradMeta
AutogradMeta的声明也在variable.h中,它的声明如下:
struct TORCH_API Variable::AutogradMeta : public c10::AutogradMetaInterface {
std::string name;
Variable grad_; // 存储梯度
// 反向传播函数 for 中间节点
std::shared_ptr<Function> grad_fn_;
// 反向传播函数 for 叶节点(权重),只是把梯度累加起来用来更新
std::weak_ptr<Function> grad_accumulator_;
VariableVersion version_counter_;
// 预处理
std::vector<std::shared_ptr<FunctionPreHook>> hooks_;
bool requires_grad_;
bool is_view_;
// 若该Variable是某个函数的输出,那么output_nr_记录它是第几个输出
uint32_t output_nr_;
PyObject* pyobj_ = nullptr; // weak reference
std::mutex mutex_;
void set_requires_grad(bool requires_grad, at::TensorImpl* self_impl) override {
/* check */
requires_grad_ = requires_grad;
}
bool requires_grad() const override {
return requires_grad_ || grad_fn_;
}
Variable& grad() override {
return grad_;
}
const Variable& grad() const override {
return grad_;
}
};
从声明中可以看出AutogradMeta不但存储了梯度,还存储了该Variable对应的反向传播函数,也就是计算图的节点。
PyTorch只建立反向传播的计算图,因为其实前向传播是用户自己定义的,不用PyTorch干什么。但是在用户在定义前向连接的时候,PyTorch需要偷偷建立反向连接,具体怎么操作见下一节。PyTorch里计算图的节点全部都是Function,由于只计算图只用于反向传播,所以 Function 实现都是反向传播函数。对于计算图中的中间结果,对应的grad_fn_是相应的反向传播函数;而对于叶节点(权重),对应的grad_fn_为nullptr,而grad_accumulator_为其相应的处理函数,就是把梯度累加存储到grad_里。除此之外,不需要梯度的输入是不会进入计算图中的。
仔细观察我们会发现,Variable里拥有AutogradMeta,而后者里用有Function,所以实际上Variable和它的grad_fn_是绑定的,也就是说,一个Variable只能有一个grad_fn_,但反过来则不一定,一个grad_fn_也可能属于多个Variable(如果正向传播函数输出很多的话,那么这些输出共享一个反向传播函数)。
Function & Edge
Function和Edge实现是紧密相连的,Function本质是一个函数对象,可以当作反向传播的函数来用。除此之外,Function里还有一个成 edge_list next_edges_;,是与该节点相连的边。PyTorch的计算图中的边其实就是{function, input_nr}pair:前者表示这条边指向哪个节点,后者表示本节点是目标节点的第几个输入(从0开始)。
Function的实现在csrc/autograd/function.h,大致声明如下:
struct TORCH_API Function : std::enable_shared_from_this<Function> {
public:
/* 构造函数略 */
// 不可拷贝或移动
Function(const Function& other) = delete;
Function(Function&& other) = delete;
Function& operator=(const Function& other) = delete;
Function& operator=(Function&& other) = delete;
virtual ~Function() = default;
// 重载()运算符实现函数对象功能,需重载apply函数
// 该函数接收一系列variable,返回一系列variable
variable_list operator()(variable_list&& inputs) {
profiler::RecordFunction rec(this);
return apply(std::move(inputs));
}
// 有关计算图的 API
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/* ... */
const Edge& next_edge(size_t index) const noexcept {
return next_edges_[index];
}
void set_next_edge(size_t index, Edge edge) {
next_edges_[index] = std::move(edge);
}
void add_next_edge(Edge edge) {
next_edges_.push_back(std::move(edge));
}
void set_next_edges(edge_list&& next_edges) {
next_edges_ = std::move(next_edges);
}
const edge_list& next_edges() const noexcept {
return next_edges_;
}
edge_list& next_edges() noexcept {
return next_edges_;
}
uint32_t num_outputs() const noexcept {
return next_edges_.size();
}
/* ... */
protected:
static uint64_t& get_next_sequence_nr();
// 需要重载的apply函数,实现实际功能
virtual variable_list apply(variable_list&& inputs) = 0;
variable_list traced_apply(variable_list inputs);
// 函数序列号
const uint64_t sequence_nr_;
// 保存邻边
edge_list next_edges_;
PyObject* pyobj_ = nullptr; // weak reference
std::unique_ptr<AnomalyMetadata> anomaly_metadata_ = nullptr;
std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_;
std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_;
at::SmallVector<InputMetadata, 2> input_metadata_;
};
Edge的声明在csrc/autograd/edge.h,它的声明就很简单了:
struct Edge {
Edge() noexcept : function(nullptr), input_nr(0) {}
Edge(std::shared_ptr<Function> function_, uint32_t input_nr_) noexcept
: function(std::move(function_)), input_nr(input_nr_) {}
// Convenience method to test if an edge is valid.
bool is_valid() const noexcept {
return function != nullptr;
}
// Required for use in associative containers.
bool operator==(const Edge& other) const noexcept {
return this->function == other.function && this->input_nr == other.input_nr;
}
bool operator!=(const Edge& other) const noexcept {
return !(*this == other);
}
// 目标函数
std::shared_ptr<Function> function;
// 第几个输入
uint32_t input_nr;
};
总结一下,Variable,AutogradMeta,Function和Edge的大致关系如下图所示:

Engine
我们先不看怎么建立计算图,而是先假设图已经建立好,考虑具体怎么执行反向传播。你可能觉得答案已经很明显了,不就是对图进行遍历么,没错,是对图进行遍历,但考虑到效率以及要在不同设备上计算,实际操作起来还是有点麻烦的,这部分代码主要由autograd::Engine实现,声明和实现分别在csrc/autograd/engine.h和csrc/autograd/engine.cpp中。
用 PyTorch 建立神经网络的时候,相信你一定用过loss.backward()来进行反向传播,那就从Variable::backward()函数开始一步一步看反向传播是怎么执行的:
void Variable::backward(
c10::optional<Tensor> gradient,
bool keep_graph,
bool create_graph) const {
// 获取 AutogradMeta
auto autograd_meta = get_autograd_meta();
// 构造起始边,做为遍历的起点(图的root)
std::vector<Edge> edges;
edges.emplace_back(autograd_meta->grad_fn_, autograd_meta->output_nr_);
// 构造输入:variable list
std::vector<Variable> inputs;
inputs.push_back(std::move(as_variable_ref(*gradient)));
// 调用 execute 进行反向传播
Engine::get_default_engine().execute(edges, inputs, keep_graph, create_graph);
}
函数首先构造遍历的起点和输入,然后调用Engine::execute()进行计算,其中Engine::get_default_engine()返回的是Engine的实例。
接着研究Engine::execute():
auto Engine::execute(const edge_list& roots,
const variable_list& inputs,
bool keep_graph,
bool create_graph,
const edge_list& outputs) -> variable_list {
// 启动多线程(每个设备一个线程)
std::call_once(start_threads_flag, &Engine::start_threads, this);
/* 验证outputs */
// 记录计算图的任务
GraphTask graph_task(keep_graph, create_graph);
std::unique_lock<std::mutex> lock(graph_task.mutex);
// 遍历一遍计算图,计算每个函数的依赖
// 所谓某函数的依赖就是有几条边指向该函数,用图的术语说就是节点的入度
// 依赖大于零(入度>0)的节点不能够执行
auto graph_root = std::make_shared<GraphRoot>(roots, inputs);
compute_dependencies(graph_root.get(), graph_task);
if (!outputs.empty()) {
graph_task.init_to_execute(*graph_root, outputs);
}
// 把root加入准备队列,每个设备有一个准备队列,-1代表CPU
ready_queue(-1).push(FunctionTask(&graph_task, std::move(graph_root), InputBuffer(0)));
if (worker_device == NO_DEVICE) {
// 非工作线程:老老实实等待图计算完毕
graph_task.not_done.wait(lock, [&graph_task]{
return graph_task.outstanding_tasks.load() == 0;
});
} else {
// 工作线程:996!
graph_task.owner = worker_device;
lock.unlock();
// 线程主循环
thread_main(&graph_task);
}
/* check exceptions */
return graph_task.captured_vars;
}
最后来看最主要的thread_main():
auto Engine::thread_main(GraphTask *graph_task) -> void {
// 获取当前进程的准备队列
auto queue = ready_queues[worker_device + 1];
// 工作没完成之前不能下班:
while (!graph_task || graph_task->outstanding_tasks > 0) {
// 获取最新工作,pop()是阻塞的,只有来工作了才会继续执行
// 生产者消费者模型
FunctionTask task = queue->pop();
if (task.fn && !task.base->has_error.load()) {
GradMode::set_enabled(task.base->grad_mode);
try {
// 执行该任务
evaluate_function(task);
} catch (std::exception& e) {
thread_on_exception(task, e);
}
}
// 找到发布任务的人
auto base_owner = task.base->owner;
// 若该任务来自非工作线程(i.e.s 领导线程,发号施令):
if (base_owner == NO_DEVICE) {
// 自减剩余任务数
if (--task.base->outstanding_tasks == 0) {
// 所有任务完毕,通知大伙下班
std::lock_guard<std::mutex> lock(task.base->mutex);
task.base->not_done.notify_all();
}
} else {
// 如果任务发布者是自己:
if (base_owner == worker_device) {
// 自减剩余任务数
--task.base->outstanding_tasks;
// 如果任务发布自其他工人:
} else if (base_owner != worker_device) {
// 自减剩余任务数
if (--task.base->outstanding_tasks == 0) {
// 提醒他们那个任务做完了
std::atomic_thread_fence(std::memory_order_release);
ready_queue(base_owner).push(FunctionTask(task.base, nullptr, InputBuffer(0)));
}
}
}
}
}
thread_main()里没有具体执行任务的代码,而是把它单独抽出变成一个方法,下面看该方法都干了什么:
auto Engine::evaluate_function(FunctionTask& task) -> void {
/* exec info blabla... */
// 调用 task 里的函数获取输出,基本相当于 (*task.fn)()
auto outputs = call_function(task);
auto& fn = *task.fn;
// 如果不保留图的话就把当前节点释放了
if (!task.base->keep_graph) {
fn.release_variables();
}
// 获取输出个数
int num_outputs = outputs.size();
// 如果没有输出这个任务就完成了,直接返回
if (num_outputs == 0) return;
/* ... */
std::lock_guard<std::mutex> lock(task.base->mutex);
// 遍历每个输出(遍历与之相邻的节点):
for (int i = 0; i < num_outputs; ++i) {
auto& output = outputs[i];
// 获取第i条边(指向第i个输出所对应的函数)
const auto& next = fn.next_edge(i);
if (!next.is_valid()) continue;
// 检查这条边是否准备好(依赖是否为0)
bool is_ready = false;
auto& dependencies = task.base->dependencies;
// 获取这条边的依赖数
auto it = dependencies.find(next.function.get());
if (it == dependencies.end()) {
/* 没找到,抛出异常 */
} else if (--it->second == 0) {
// 依赖自减后等于零,说明该任务已准备好
dependencies.erase(it);
is_ready = true;
}
// 获取/创建该节点的 input_buffer
auto& not_ready = task.base->not_ready;
auto not_ready_it = not_ready.find(next.function.get());
// 还没有为该节点分配 input_buffer:
if (not_ready_it == not_ready.end()) {
/* 跳过那些不该被执行的函数 */
// 用 output 构造该节点的 input_buffer
InputBuffer input_buffer(next.function->num_inputs());
input_buffer.add(next.input_nr, std::move(output));
if (is_ready) {
// 准备好就加入准备队列
auto& queue = ready_queue(input_buffer.device());
queue.push(FunctionTask(task.base, next.function, std::move(input_buffer)));
} else {
// 没准备好就缓存 input_buffer
not_ready.emplace(next.function.get(), std::move(input_buffer));
}
// 该节点已有 input_buffer:
} else {
// 向已有 input_buffer 里添加新的输入
auto &input_buffer = not_ready_it->second;
input_buffer.add(next.input_nr, std::move(output));
if (is_ready) {
// 准备好就加入准备队列
auto& queue = ready_queue(input_buffer.device());
queue.push(FunctionTask(task.base, next.function, std::move(input_buffer)));
// 从输入缓存里删除该节点
not_ready.erase(not_ready_it);
}
}
}
}
好,至此执行计算图的代码就梳理完了,简单总结一下:
- 把调用backward()的节点设为根节点,从该节点开始遍历
- 首先BFS一遍计算图,计算每个节点的依赖
- 为每个设备建立一个工作线程,每个线程里有一个准备队列
- 每个线程等待任务到来直到任务全部完成
- 完成一个任务后遍历与之相邻的节点,更新他们的依赖(-1),若依赖为0则加入准备队列
动态建立计算图
这一小节介绍 PyTorch 是怎么建立用于反向传播的计算图的。根据前面的分析,计算图一定是在定义前向传播是建立的,那么机密一定是藏在前向传播API里了,这个猜想是没错,但是由于 ATen 复杂的动态派发机制以及使用脚本生成代码,我也是费了九牛二虎之力才找到具体实现以及理解其中的逻辑。
神经网络的具体计算:每一层的前向和反向传播,其实都是在 ATen 里实现的,但回去看 ATen 的API实现,并没有发现其中有任何建立计算图的代码。这其中的机密实际在tools/autograd目录里。这个目录里有derivatives.yaml和用于生成代码的脚本,前者记录了所有需要自动微分的ATen API,后者为它们生成一层wrapper代码,这些代码主要干两件事:
- 把ATen的反向传播API转换成Function
- 在ATen的正向传播API中加入建图过程
举个例子,derivatives.yaml第119行的addcmul()API:
-name: addcmul(Tensor self, Tensor tensor1, Tensor tensor2, *, Scalar value)
self: grad
tensor1: grad * tensor2 * value
tensor2: grad * tensor1 * value
这里指明了函数名、参数、反向计算方法。执行gen_autograd.py可以自动为其生成代码,生成的代码在torch/csrc/autograd/generated中,有 addcmul()的前向传播的代码在VariableType0.cpp中, 反向传播的代码在Functions.h和Functionss.cpp中。
前向传播
Tensor VariableType::addcmul(const Tensor & self, const Tensor & tensor1, const Tensor & tensor2, Scalar value) const
{
profiler::RecordFunction profiler("addcmul", Function::peek_at_next_sequence_nr());
// 获取输入
auto& self_ = unpack(self, "self", 0);
auto& tensor1_ = unpack(tensor1, "tensor1", 1);
auto& tensor2_ = unpack(tensor2, "tensor2", 2);
std::shared_ptr<AddcmulBackward> grad_fn;
if (compute_requires_grad( self, tensor1, tensor2 )) {
// 建立反向传播节点 AddcmulBackward
grad_fn = std::shared_ptr<AddcmulBackward>(new AddcmulBackward(), deleteFunction);
// 新建边指向与 self, tensor1, tensor2 绑定的节点
grad_fn->set_next_edges(collect_next_edges(self, tensor1,
tensor2));
if (grad_fn->should_compute_output(1)) {
grad_fn->tensor2_ = SavedVariable(tensor2, false);
}
grad_fn->value = value;
if (grad_fn->should_compute_output(2)) {
grad_fn->tensor1_ = SavedVariable(tensor1, false);
}
}
/* ... */
// 调用 ATen API 进行实际计算
auto tmp = ([&]() {
at::AutoNonVariableTypeMode non_var_type_mode(true);
return baseType->addcmul(self_, tensor1_, tensor2_, value);
})();
auto result = as_variable(tmp);
/* ... */
// 把 grad_fn 与输出绑定
set_history(flatten_tensor_args(result), grad_fn);
return result;
}
这个函数是前向计算的API,在具体计算之前先建立反向传播函数(节点),并且把该节点与输入的节点相连;然后调用下层API计算结果;最后把结果和新建立的节点绑定,这样用于反向传播的计算图就建立完成了。由于这是反向传播计算图,所以前向传播中的输入节点变成反向的输出,前向的输出节点变成反向的输入,如下图所示。

反向传播
// 声明在 Functions.h
struct AddcmulBackward : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "AddcmulBackward"; }
void release_variables() override {
tensor2_.reset_data();
tensor2_.reset_grad_function();
tensor1_.reset_data();
tensor1_.reset_grad_function();
}
SavedVariable tensor2_;
Scalar value;
SavedVariable tensor1_;
};
// 实现在 Functions.cpp
// 重载 Function::apply 实现梯度计算
variable_list AddcmulBackward::apply(variable_list&& grads) {
IndexRangeGenerator gen;
auto self_ix = gen.range(1);
auto tensor1_ix = gen.range(1);
auto tensor2_ix = gen.range(1);
variable_list grad_inputs(gen.size());
auto& grad = grads[0];
auto tensor2 = tensor2_.unpack();
auto tensor1 = tensor1_.unpack();
// 计算梯度,与 derivatives.yaml 中的定义相同
if (should_compute_output({ self_ix })) {
auto grad_result = grad;
copy_range(grad_inputs, self_ix, grad_result);
}
if (should_compute_output({ tensor1_ix })) {
auto grad_result = grad * tensor2 * value;
copy_range(grad_inputs, tensor1_ix, grad_result);
}
if (should_compute_output({ tensor2_ix })) {
auto grad_result = grad * tensor1 * value;
copy_range(grad_inputs, tensor2_ix, grad_result);
}
return grad_inputs;
}
可以看到这些代码确确实实把 ATen API 转换成了计算图节点Function。
动态派发
最后还有一个问题就是代码中调用的API是torch.addcmul()或variable.addcmul()怎么就会执行到上面的VariableType::addcmul()呢?这就要归功于 ATen 的动态派发了,以第二种调用举例分析一下,也就是通过一个Variable类型变量调用addcmul()。
首先,上一篇说过,ATen 的API都记录在ATen/native/native_functions.yaml里,这些API如果有生成 method 的需求的话,会把声明通过脚本自动添加 at::Tensor类里,这样就可以通过tensor.addcmul()调用该API,而Variable继承自at::Tensor,自然也就拥有了该方法。
但这还没完,如果查看这个方法的实现会发现:
inline Tensor Tensor::addcmul(const Tensor & tensor1, const Tensor & tensor2, Scalar value) const {
return type().addcmul(*this, tensor1, tensor2, value);
}
它调用了type()的相应方法,这个type()返回的是Type类型的实例。Type类型同样声明了所有 ATen API,并且有TensorType VariableType继承自它。根据ATen的动态派发机制,如果调用者是Tensor的话,并且is_variable == False,就会返回TensorType实例;如果调用者是Variable的话,或者is_variable == True,就会返回上述的VariableType实例。所以一个Variable类型的变量调用addcmul()的话实际会执行VariableType::addcmul()。
















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











