







修改自组会报告ppt。
文章目录
- Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic, Gu et al, 2016. Algorithm: Q-Prop.
- Action-dependent Control Variates for Policy Optimization via Stein’s Identity, Liu et al, 2017. Algorithm: Stein Control Variates.
- The Mirage of Action-Dependent Baselines in Reinforcement Learning, Tucker et al, 2018. Contribution: interestingly, critiques and reevaluates claims from earlier papers (including Q-Prop and stein control variates) and finds important methodological errors in them.

这种方法的基本思想就是,使用Action-Dependent Baseline来减小PG方法的方差。
Baseline 是 policy gradient 类方法的一个重要的减小方差的手段。并且,baseline的引入并不会导致bias。
在REINFORCE with baseline算法中,就引入了基准值b作为baseline。
这一系列研究方向主要都是针对找到b的估计。
最优的baseline理论上是存在的。出于practical的考虑,一般使用当前状态动作对的价值作baseline。或者选择一个方便计算的action-dependent baseline。
论文列表:
[22] Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic, Gu et al, 2016. Algorithm: Q-Prop.
[23] Action-dependent Control Variates for Policy Optimization via Stein’s Identity, Liu et al, 2017. Algorithm: Stein Control Variates.
[24] The Mirage of Action-Dependent Baselines in Reinforcement Learning, Tucker et al, 2018. Contribution: interestingly, critiques and reevaluates claims from earlier papers (including Q-Prop and stein control variates) and finds important methodological errors in them.
参考:
Policy Gradient Methods for Reinforcement Learning with Function Approximation and Action-Dependent Baselines,arXiv:1706.06643v1
VARIANCE REDUCTION FOR POLICY GRADIENT WITH ACTION-DEPENDENT FACTORIZED BASELINES,arXiv:1803.07246
Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic, Gu et al, 2016. Algorithm: Q-Prop.

这篇论文主要思想就是用用off-policy的方式估计一个baseline。用到技巧就是在AC模型中,将Critic的一阶泰勒展开作为控制变量 。
。
对比REINFORCE(方差大、无偏)和(方差大、无偏),可以发现两者的梯度公式可以结合。
Q-prop算法就是这样的:

Q-Prop同时有在线更新和离线更新,在线更新的是策略,离线更新的是Q函数估计,算是很巧妙地将二者融合在一起。
Action-dependent Control Variates for Policy Optimization via Stein’s Identity, Liu et al, 2017. Algorithm: Stein Control Variates.

这篇论文的主要思想是使估计的baseline和原策略分布近似相等,使用了数学上的Stein’s identity 。Stein’s identity 是统计学里面判断两个分布是否相等的方法。给定策略, Stein’s identity写作:
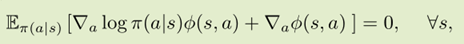
这篇论文最初的想法就是对于无偏估计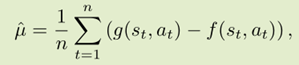 ,
,
方差就能减小为

如果g,f同分布,那么方差将大大变小。因此优化目标就是求出一个Φ(s,a),使用Stein’s identity使它尽量和g同分布。
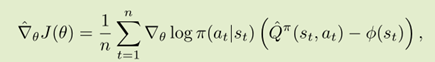
这篇论文代表了一类基于Action-Dependent Baselines的探索。
The Mirage of Action-Dependent Baselines in Reinforcement Learning, Tucker et al, 2018. Contribution: interestingly, critiques and reevaluates claims from earlier papers (including Q-Prop and stein control variates) and finds important methodological errors in them.

本文主要批评和重新评估早期论文,指出方法上的错误。提出了两个结论:
- 代码训练时 “subtle implementation decisions”使得算法真正无偏
- 提出了一个地平线感知值函数参数化

在上面三张实验图中可以看出,如果采用公正的方式,不使用映入bias的方式训练,并没有特别显著的效果提升(蓝色和红色线)。但是根据论文后面的开源代码看来,这些都是因为引入了一定的bias才得到的结果(绿线)。其中偏差就是在优势函数正则化的时候引入的。

在前面研究的基础上,论文提出了地平线感知值函数。前面一部分预测未来几步收益之和,再加上当前状态估计的价值函数。这样子可以有效避免,一幕游戏最后几步的时候值函数会特别低的问题。
通过实验发现,引入这种模式的方法比TRPO稍好一些。其它方法均不能优于TRPO。















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











