









文章目录
- 什么是Transfer and Multitask RL
- Progressive Neural Networks, Rusu, et al, 2016. Algorithm: Progressive Networks.
- Universal Value Function Approximators, Schaul et al, 2015. Algorithm: UVFA.
- Reinforcement Learning with Unsupervised Auxiliary Tasks, Jaderberg et al, 2016. Algorithm: UNREAL.
- The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously, Cabi et al, 2017. Algorithm: IU Agent.
- PathNet: Evolution Channels Gradient Descent in Super Neural Networks, Fernando, et al, 2017. Algorithm: PathNet.
- Mutual Alignment Transfer Learning, Wulfmeier, et al, 2017. Algorithm: MATL.
- Learning an Embedding Space for Transferable Robot Skills, Hausman et al, 2018.
- Hindsight Experience Replay, Andrychowicz et al, 2017. Algorithm: Hindsight Experience Replay (HER).
什么是Transfer and Multitask RL
顾名思义,迁移学习(transfer Learning)、多任务学习( Multi-task Learning)。
- 之前关注的是single agent在single task中怎么train的好,现在关注的是single agent如何在multi-task中迅速train好
- 缩短训练时间,引入多样性(diversity or variety)到agent的探索与利用使性能更好的分布式训练
Progressive Neural Networks, Rusu, et al, 2016. Algorithm: Progressive Networks.

https://www.cnblogs.com/zeze/p/8268388.html
思路就是说我不能忘记第一个任务的网络,同时又能使用第一个任务的网络来做第二个任务。
为了不忘记之前的任务,他们的方法简单暴力:对所有的之前任务的网络,保留并且fix,每次有一个新任务就新建一个网络(一列)。
而为了能使用过去的经验,他们同样也会将这个任务的输入输入进所有之前的网络,并且将之前网络的每一层的输出,与当前任务的网络每一层的输出一起输入下一层。
以三个任务为例:

Step 1:构造一个多层的神经网络,训练某一个任务,上图第一列
Step 2:构建第二个多层的神经网络,然后固定第一列也就是上一个任务的神经网络,将上一列的神经网络的每一层(注意是每一层)都通过a处理连接到第二列的神经网络的每一层作为额外输入。也就是第二个神经网络每一层除了原始的输入,还加上经过a处理的之前的神经网络对应层的输入。
Step 3:构建第三个多层神经网络,训练第三个任务,将前两列的神经网络固定,然后同上一样的方法连接到第三个神经网络中。
上图的线很清楚的表示了这个过程。

图中a的作用其实主要是为了降维和输入的维度统一(与原始输入匹配),用简单的MLP来表示!
总的来说,就是抽取之前的神经网络的信息与当前的输入信息融合,然后训练!训练的效果就可以和没有加前面的神经网络的方法对比,如果效果好很多说明前面的神经网络有用,知识有迁移!
这种方法的好处就是之前的训练都保留,不至于像fine tune那样更改原来的网络!而且每一层的特征信息都能得到迁移,并且能够更好的具化分析。
缺点就是参数的数量会随着任务的增加而大量增加!并且不同任务的设计需要人工知识。
Universal Value Function Approximators, Schaul et al, 2015. Algorithm: UVFA.

文章中采用之前工作中提出的Genaral Value Function(GVF),通过引入目标goal,定义了广义值函数 Vg(s) (Sutton et al., 2011) ,表达了局部目标goal的奖励,能更好的利用当前环境的知识。文章提出了一种Universal Value Function Approximator(UVFA), V (s, g; θ) 用来近似值函数。

这张图很好看。图中s为state,g为goal。左中右依次为传统连结结构(一个神经网络)、双流结构(使用两个互相独立的神经网络)、分别训练双流结构中的两个结构再将两者结合。
直观地理解一下,就是在s对应的Φ网络训练时,它是不知道goal是什么的,这个网络的作用就是尽可能地提取状态的信息,比如在房间里瞎转悠,熟悉一下环境。这样一来,在给定具体的goal(比如在房间里找东西)以后,就能学得又快又好了。用这种方法得到的网络,在不同的goal下也可以很快地Transfer。
本论文算法框架如下:

优点
给出了一种较好的近似GVF的方法,具有较好的扩展性,可以通过学习已知的goal来迁移到未知任务中。
采用矩阵的方法,给出了一个很好的状态state的embbeding方法,可以用在各种强化学习算法中。
模型可以用在很多需要临时决策的场景,比如一个目标可能只用一次的场景。
存在的问题
实验中采用29个goal来训练,5个未知的goal来进行验证,且在相同任务环境下,只是设置了不同的位置来定义goal。能否用于迁移到其他任务,仍有待商榷。
targetQ的选取较复杂,是否具有更快速有效的计算targetQ的方法。
Reinforcement Learning with Unsupervised Auxiliary Tasks, Jaderberg et al, 2016. Algorithm: UNREAL.

https://gyh75520.github.io/2018/08/30/Unreal/
作者通过添加辅助任务增强了A3C(Asynchronous Actor Critic)算法。这些辅助任务共享网络参数,但是它们的价值函数是通过 n-step 的 off-policy 的 Q-Learning 来学习的。辅助任务只用于学习更好的表示,而不直接影响主任务的任务control。这种改进被称为UNREAL(Unsupervised Reinforcement and Auxiliary Learning),在性能和训练效率方面优于A3C。
A3C 算法充分使用了 Actor-Critic 框架,是一套完善的算法,因此,我们很难通过改变算法框架的方式来对算法做出改进。UNREAL 算法在 A3C 算法的基础上,另辟蹊径,通过在训练 A3C 的同时,训练多个辅助任务来改进算法。UNREAL 算法的基本思想来源于我们人类的学习方式。人要完成一个任务,往往通过完成其他多种辅助任务来实现。比如说我们要收集邮票,可以自己去买,也可以让朋友帮忙获取,或者和其他人交换的方式得到。UNREAL 算法通过设置多个辅助任务,同时训练同一个 A3C 网络,从而加快学习的速度,并进一步提升性能。
UNREAL 算法本质上是通过训练多个面向同一个最终目标的任务来提升行动网络的表达能力和水平,符合人类的学习方式。值得注意的是,UNREAL 虽然增加了训练任务,但并没有通过其他途径获取别的样本,是在保持原有样本数据不变的情况下对算法进行提升,这使得 UNREAL 算法被认为是一种无监督学习的方法。基于 UNREAL 算法的思想,可以根据不同任务的特点针对性地设计辅助任务,来改进算法。

图为网络结构,分别包含了Pixel Control、Reward Prediction、Value Function Replay等辅助任务,因此总的损失函数为
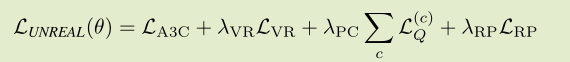
其中 VR = Value Function Replay, PC = Pixel Control, RP = Reward Prediction。
在实际的训练中,Loss被拆分成单独的部分训练。
实验也证明,这种方法训练出来的结果更加鲁棒。在迷宫游戏中agent的能力翻了一倍多。
The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously, Cabi et al, 2017. Algorithm: IU Agent.

本文介绍了IU 。该智能体使用深度决策策略梯度 (DDPG) 用于持续控制,同时解决多个任务。学习同时解决许多任务一直是人工智能的长期核心目标,受到婴儿发育的启发,并受到建立能够进行多种行为的灵活机器人操纵器的激励。我们表明,IU 不仅能够同时学习解决许多任务,而且还比同时针对单个任务的智能体学习得更快。在某些情况下, DDPG 方法完全失效,但 IU 成功解决了任务。为了证明这一点,使用 MuJoCo 物理引擎构建了一个游戏室环境,并引入了形式化语言来自动生成任务。

IU的网络结构。左侧网络根据观察到的状态输出动作向量,右侧是Critic,根据动作向量和状态输出各动作的Q值。
在更新参数时,论文使用minibatch结合随机策略梯度下降。将Actor、Critic的损失函数结合,得到参数更新公式:
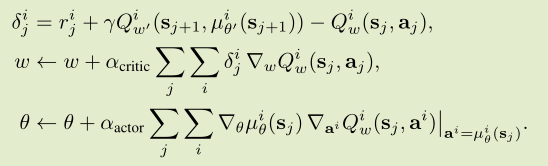
论文使用基于PG的理论方法,在探索时给动作分量加上了随机变量Z。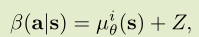
并且在场景中不断地变化随机任务。当一个任务完成后切换到下一个。
从探索的角度来看,使最艰巨的任务变得足够困难并不难,即使是IU代理也失败了。例如,如果增加游戏场所的大小,并要求执行器将十个方块聚集在一起,所有现有的控制代理都可能失败。解决这一艰巨的探索问题似乎是任务分解,要么通过分层强化学习,要么通过对对象和关系的理解。
结果表明,通过增加任务数量,所有演员和评论家学习得更快。事实上,在某些环境中,学习许多目标对于解决困难的多体控制任务至关重要。
结论:论文提出了一个新的架构,可以同时学习几个任务。在实验所处的连续的物理动作空间中,身体、物体和物理定律在任务间时共享的。在这些领域,任务越多,IU agent 的许欸小速度就越快。并且能够解决 DDPG agent无法学会的环境。
PathNet: Evolution Channels Gradient Descent in Super Neural Networks, Fernando, et al, 2017. Algorithm: PathNet.

PathNet是一种旨在通过结合迁移学习,持续学习和多任务学习的各方面来实现artificial general intelligence (AGI)的多任务强化学习方法。它将多智能体嵌入神经网络中,每个智能体的目标是在学习新任务时确定要重用网络的哪些部分。 智能体是神经网络内的路径(也称为genotypes),它决定了学习过程中使用的参数子集。 这些用于正向传播的参数通常在PathNet算法的反向传播阶段被修改。 在学习过程中,tournament selection genetic algorithm将被用于通过神经网络选择路径。 智能体在神经网络内执行动作,并逐步建立关于如何有效将神经网络环境中现有参数重用于新动作(任务)的知识。 智能体通常与正在学习其他任务并共享参数以进行积极知识迁移的其他智能体并行工作; 否则,他们将更新导致消极知识迁移的不相交参数。
PathNet体系结构由具有L层的DNN组成,每层有M个模块。来自每一层模块的集成输出将被传递到下一层的活动模块中。 神经网络中每个任务的最后一层是唯一的,不会与环境中任何其他任务共享。


图五是游戏pong中训练得到的路径(红色加粗),图九是之后转移到Alien训练得到的路径(蓝色加粗)。其余均为tournament selection genetic algorithm算法的中间过程。
PathNet的优点之一是神经网络可以非常有效地重用现有知识,而不必为每个任务从头开始学习,这在状态空间存在许多相互关联任务的场景中十分有用。 实验中PathNet对于MNIST,CIFAR-100和SVHN数据集监督学习分类任务、以及Atari和Labyrinth强化学习任务的知识迁移展示了积极成果。
Mutual Alignment Transfer Learning, Wulfmeier, et al, 2017. Algorithm: MATL.

实际机器人的研究无法与类似的进展相匹配,而模拟培训策略可以降低样本的复杂性。所以使用模拟环境中训练的机器人来对正式平台上进行调优。利用辅助奖励来指导虚拟环境中的 agent 对真实世界的探索,反之亦然。

相互对齐转移学习的简化模式。这两个系统都经过培训,不仅能够最大限度地提高各自的环境奖励,还能获得辅助对齐奖励,鼓励这两个系统在访问过的状态中占据类似的分布。此外,仿真策略的训练数量级比实际平台仅基于其环境奖励要快。
Learning an Embedding Space for Transferable Robot Skills, Hausman et al, 2018.

这篇文章的目标是学习一个基于任务的策略 Π(a|s,t(i)),其中 t(i) 属于一个离散的任务列表。与学习K个不同的策略不同,更好的方式是学习一个潜在的技巧空间,以便每个任务都可以用技巧分布来表示,从而可以在任务之间复用技巧。

我们以多任务设置对代理进行培训,任务 ID 作为嵌入网络(左下角)的一热输入。嵌入网络生成嵌入分布,该分布与当前观察进行采样和串联,作为对策略的输入。在与环境交互后,将部分状态收集并输入推理网络(右下角)。推理网络经过培训,可对状态段产生的嵌入载体进行分类。
Hindsight Experience Replay, Andrychowicz et al, 2017. Algorithm: Hindsight Experience Replay (HER).

https://zhuanlan.zhihu.com/p/51357496
https://zhuanlan.zhihu.com/p/403527126
HER是Hindsight Experience Replay的简称,hindsight大概就是“事后诸葛亮”的意思。奖励稀疏是导致强化学习困难的一个重要的原因,本专栏前面讲过一些reward shaping方法或者intrinsic reward的设计方法,都是解决奖励稀疏的一个途径。
这篇文章开发了解决奖励稀疏的另一个途径,大致思想是奖励稀疏的时候可能绝大多数的探索都是失败的,这里考虑把这些失败的探索都利用起来。比如智能体想去食堂,某一次探索失败了,没去到食堂,但是走到操场了,与其认为这一次失败的探索,不如记下来这样走可以到操场,这样更加充分地利用了经历的失败。这篇文章就是在讲如何构建这样一个经验池。
举一个非常简单的例子,就比如说在这个sparse reward,机器人去踢球,发现在这个非常大的空间里,他很难踢进这个球框,所以他在反复的尝试中,都获得不了reward。具体来说,当对于智能体而言,他踢到任何一个不理想的状态,他都是等同视之的,觉得这是一个失败的经验,然后并不能从中推导出怎么去成功?而人类,他对失败经验的想法是,如果我想把球踢到a位置,但是我现在把球踢到B位置,那么虽然我失败了,我就会知道,如果球框在B位置的时候,我怎么去发力踢这个球。

文章其实是做了这样几个假设:
- 映射函数: 表示在这个目标g下面任意一个状态是否能够达到g这个目标
- 二值奖励的函数,只要没有达到目标,就返回-1,是一个sparse reward
- state space到goal space的映射: 任意一个状态,能找到其对应的目标,为一一映射的关系
Space reward会导致采样到的轨迹大概率来说,对于所完成的任务是失败的。所以本文最关键的一步,就是在采样一条轨迹之后,对轨迹上每一个transition都计算一下,如果换做是其他目标,这个transition会怎么样?当然其实这里有一个比较显然的设定,就是他认为这个系统的dynamics是相同的,也就是说这种多目标任务之间的话,他经历了这些transitions是不变的。
那么如何去选这个新目标呢?文章提供了四种方法:
Final: 每次选择这一条轨迹的最后一个状态,作为新目标
Future: 随机选这个轨迹上,当前transition之后的K个状态作为新目标
Episode: 每次选择轨迹上的k个状态作为新目标,这里是在这个整个轨迹上可以任意选取
Random的话,其实是在每次所有出现过的状态中选择k 个就可以了,这里其实都不要求在这个轨迹里面进行采样
这篇文章选择在三个任务上做实验,主要就是mujoco上面七自由度的二指爪,做pushing,sliding,和pick and fetch(就是推动方块到固定位置,或者说把物体滑动到平台上的指定位置,第三个就是要求机械臂捡起一个方块,并且把它放置到指定的某个位置)。包括之前的四种goal sampling的策略,它都进行了测试。最终实验结果表明,是final和future的效果比较好。

文章有以下几个优点:
- HER可以结合任意的off-policy算法:文中使用了DDPG
- 效果好:由于这个任务需要机械臂把物体挪动到随机产生的不同位置,其本身就是一个多目标的任务,如果只设置一个稀疏的奖励,本身就很难学习到有效的东西。因此实验中DDPG+HER相比于纯DDPG的结果有了本质上的提升。(相比于其他count-based exploration策略也有很大的提升)
- 对于单目标任务也适用:虽然这个方法自然地适用于多目标强化学习问题,但是如果对于单目标任务来说,在训练中只使用这个单一的目标也对于性能提升有帮助;不过文章还是推荐即使最后的任务是单目标,在训练的时候也使用多目标来训练;
- 效果甚至好于一些reward shaping的尝试:文中简单尝试了几种手工的reward shaping,效果没有直接这样使用系数的目标更好。文章给出的解释是稀疏的奖励最能够反映任务目标,加了shaping之后其实是为了引导智能体学习从而牺牲了对于目标的正确表述;同时,shaping其实惩罚了先验规定的一些不想要的行动,这可能阻碍了智能体的探索。
都看到这里了,就动动手点个赞吧~
















 3777
3777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











