









文章目录
- Combining Policy Gradient and Q-learning, O’Donoghue et al, 2016. Algorithm: PGQL.
- The Reactor: A Fast and Sample-Efficient Actor-Critic Agent for Reinforcement Learning, Gruslys et al, 2017. Algorithm: Reactor.
- Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning, Gu et al, 2017. Algorithm: IPG.
- Equivalence Between Policy Gradients and Soft Q-Learning, Schulman et al, 2017. Contribution: Reveals a theoretical link between these two families of RL algorithms.
Combining Policy Gradient and Q-learning, O’Donoghue et al, 2016. Algorithm: PGQL.

PGQL,顾名思义,是PG(Policy Gradient)方法和QL(Q-Learning)方法的结合。在该论文中,作者分析了值函数和策略之间的关系。
首先,把对Q的估计定义为:
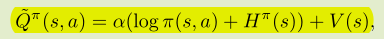
这里的H就是当前状态下的策略熵(负数),log项就是所有动作分量概率的对数值。两者相加乘上一定权重加在策略价值的估计上,可以避免策略过快地收敛,从而保证一定的探索。
另外,对于贝尔曼方程有不动点:
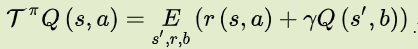
在不动点处行为值函数的参数 θ 在熵正则化的梯度方向上将不会再更新。
在参数更新的时候,考虑值函数的参数 θ 和策略网络参数 w :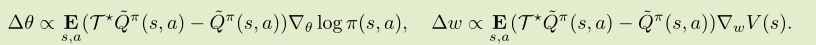
这是适用于特定形式的 Q 值的 Q 学习,也可以解释为具有批评家(有偏)的AC算法。
可以把参数更新公式写作:
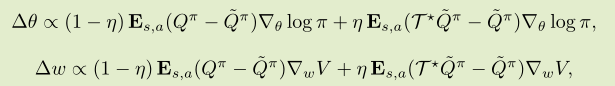
这里的 η 是一个0到1的可以调节的参数。当其为0时,方案简化为 entropy regularized policy gradient。当其为1时,方案简化为与 dueling 结构相似的 Q-learning。
这样,就相当于把PG与QL成功结合在了一起。下图为网络结构:

论文在一些环境和 atari 游戏中测试发现,PGQL的表现比 A3C 和 Q-learning 要好。
The Reactor: A Fast and Sample-Efficient Actor-Critic Agent for Reinforcement Learning, Gruslys et al, 2017. Algorithm: Reactor.

作者在模型中使用了多个技术,包括:新的策略梯度算法beta-LOO,多步off-policy分布式强化学习算法Retrace,prioritized replay方法以及分布式训练框架。
Reactor模型四个贡献的组合,除了最近改进的基于深值的RL和策略梯度算法。每一次贡献都推动Reactor模型朝着高效采样的目标前进。
-
β-LOO
LOO( leave-one-out):
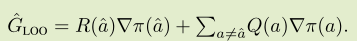
这个估计方差很小,但是有偏。因此将他与PG估计相结合:
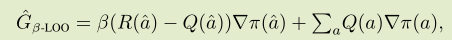
-
DISTRIBUTIONAL RETRACE
将发发重写为 n 步贝尔曼回溯,可以把公式重写如下:
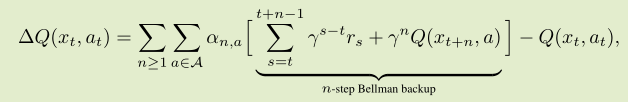
-
PRIORITIZED SEQUENCE REPLAY
使用 TD error 作为历史数据的优先级。对于 TD error 高的经验进行优先重放。 -
AGENT ARCHITECTURE
相比A3C, reactor的learner、actor都在不同的线程上运行.

总结一下就是,本文提出了Reactor模型,该模型结合了off-policy经验回放的低样本复杂度和异步算法的高训练效率两方面优点,比Prioritized Dueling DQN和Categorical DQN有更低的样本复杂度,同时比A3C有更低的运行时间。
Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning, Gu et al, 2017. Algorithm: IPG.

论文思路比较清晰,就是使用插值法,将PG方法和AC方法的梯度简单相加。一方面控制因为AC引入的偏差,一方面减小PG带来的误差。并且在论文的第四章给出了较为具体的理论分析。
论文提出的算法如图:

其中插值步骤就在第14行。当插值为0时方法退化为普通的PG算法,而当插值为1时则为AC算法。
IPG梯度计算公式:
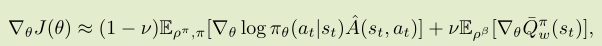
并且,在之后的理论分析中,根据β是否与v相同进行了理论上的分析,说明两种情况下的方差都是可以控制在有界范围内的。
Equivalence Between Policy Gradients and Soft Q-Learning, Schulman et al, 2017. Contribution: Reveals a theoretical link between these two families of RL algorithms.

论文主要解释了PG方法和Soft Q-learning之间的理论联系。这里的soft其实就是entropy-regularized 的意思。
从理论的角度,soft Q-learning 其实就是等价于策略梯度方法,同时论文给出了 Q-learning 和 natural policy gradient 方法的联系。
公式推理过程:

等效策略梯度方法将策略梯度乘以因子 t 导入价值函数的误差。实际上,值函数误差的系数为 1/t,比实际中通常使用的系数要大。这在论文给出的实验中进行了分析。
















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











