









论文链接:Conservative Q-Learning for Offline Reinforcement Learning
代码:代码
源文件在幕布做的思维导图,内容按照原论文标题进行编写。
小徐读研以来精读的第1️⃣篇文献,记录自己成长的每一步(●'◡'●)
个人拙见,如有错误,欢迎指正!
CQL
-
Abstract
-
❌challenge1:large-scale real-world applications
-
How to effectively leverage large, previously collected datasets in RL?
-
-
✅solution:offline RL
-
without further interaction
-
learn policy from previously-collected, static dataset
-
-
❌challenge2:distribution shift——>overestimation
distribution shift:收集数据的策略产生的action分布与需要评估的策略产生的action的分布之间可能是有一个很大的差异,这会导致当需要评估的策略产生一个不在数据集中的action时,会对这个action的Q值产生一个错误的估计,如果错误一直累积的话还会产生其他影响.
-
✅solution:CQL
1.theoretically: we can get 2.in practice: the standard Bellman error objective with a simple Q-value regularizer 3.conclusion:On both discrete and continuous control domains, CQL attain 2-5 times higher final return, especially when learning from complex and multi-modal data distributions.
-
a conservative Q-function
-
the expected value of a policy under this Q-function lower-bounds its true value.
-
-
-
1.Introduction
-
-
(introduction内容和abstract内容有些重复,大致就是存在什么问题,然后提出什么方法改进,本文就是引出CQL的概念,这里看可能会有一些抽象,云里雾里,别慌,往后看)
-
❌RL's disadvantage-->offlinen RL'schallenge
-
✅solution:CQL
-
1.learn a conservative estimate of the value function, which provides a lower bound on the true values
学习的Q函数是真实Q函数的一个下界
-
2.learn a less conservative lower bound Q-function, only the expected value of Q-function under the policy is lower-bounded,as opposed to a point-wise lower bound
为了防止Q函数过于保守,希望达成的目标是对于某个策略其价值函数的期望是一个下界,而不是价值函数的每个点对都是下界
-
step1: minimize values under an appropriately chosen distribution over state-action tuples,
-
step2: further tighten this bound by also incorporating a maximization term over the data distribution
-
-
-
work in paper(这部分看了几篇论文下来感觉就是套话,就是说自己论文的工作具体做了些啥)
-
theoretical analysis……
-
empirically demonstrate……
-
CQL outperforms……
-
2-5x on many benchmark tasks
-
outperform simple behavioral cloning on a number of realistic datasets collected from human interaction.
-
implemented with less than 20 lines of code
-
-
-
In experiments……
-
-
-
2.Preliminaries
-
-
(这部分是预备知识,就是学习1+1=2之前,你需要认识+,=是啥意思)
-
(如果你觉得这部分太抽象,你就记住1.πβ(a|s) 是behavior policy,产生dataset,他里边的actions都是在replay buffer里边的 2.μ策略是我们要学习的policy,可能会产生OOD行为,我们需要处理)记住了这两点,可以跳过Preliminaries,往后看,遇到看不懂的再回来找概念和含义。
-
2.1NOTES
-
2.1.1The goal in RL
-
learn a policy that maximizes the expected cumulative discounted reward in a Markov decision process (MDP)
-
-
2.2.2 (S, A, T, r, γ)
-
S, A represent state and action spaces
-
T(s‘|s, a) and r(s, a) represent the dynamics Probs and reward function
-
γ ∈ (0, 1) represents the discount factor
-
-
2.2.3 dataset D
sampled from dπβ (s)πβ(a|s).
-
πβ(a|s) represents the behavior policy(behavior policy是非常重要的概念)
-
discounted state distribution dπβ (s) is the discounted marginal state-distribution of πβ(a|s)
-
-
机器学习中的数学—经验分布(Empirical分布)the empirical behavior policy πˆβ(a|s)
在历史数据的 state s 下有多少次选择了 action a。
-
-
assume :|r(s, a)| ≤ Rmax
假设 reward 有 bound
-
-
-
2.2 Off-policy RL algorithms
-
a parametric Q-function Qθ(s, a)
2.2.1 Q-Learning方法训练Q函数通过
-
Bellman optimality operator
贝尔曼最优算子
-
-
use exact or an approximate maximization scheme, such as CEM to recover the greedy policy
使用CEM最大化策略来执行greedy policy,选择使得Q值最大的action
-
-
a parametric policy πφ(a|s)
2.2.2 在AC算法中
-
policy evaluation
迭代更新Q函数
-
Bellman operator
-
Pπs the transition matrix coupled with the policy
过渡矩阵transition matrix
-
-
-
-
-
2.2.3 BUT!!!
-
empirical Bellman operator Bˆπ
由于 dataset D 不会包含所有的 transition tuple (s,a,s'),所以 policy evaluation 步骤事实上用的是 empirical Bellman operator,,它只备份(backs up)单个样本
-
policy evaluation
-
-
policy improvement
-
-
-
-
-
2.3 Offline RL algorithms
-
-
(我们知道了一些基础符号的含义NOTES部分,和在off-policy中Q函数的更新方法,那么应用到offline中又双遇到了challenge,然后作者阐述之前算法为解决OOD问题做的努力,并说明其存在问题)
-
❌challenge:action distribution shift
直接使用evalution&improvement学习的策略可能学习到生成数据集的策略中没有的行为OOD,从而也就没有与之对应的Q值。由于 policy 的训练目标是最大化 Q 值,可能会倾向于 Q 值被高估的 out-of-distribution 行为 致估计的Q值过大
-
the target values for Bellman backups in policy evaluation use actions sampled from the learned policy, πk
-
Q-function is trained only on actions sampled from the behavior policy that produced the dataset D, πβ.
-
-
✅❌solution:constrain the learned policy away from OOD actions
之前方法的解决
-
Q-function training in offlineRL does not suffer from state distribution shift, as the Bellman backup never queries the Q-function on out-of-distribution states.
-
However, the policy may suffer from state distribution shift at test time.
-
-
-
-
3.The Conservative Q-Learning Framework
通过打压OOD(out of distribution)的q值的同时,去适当的鼓励已经在buffer(训练集)中的q值,从而防止q值被高估
-
3.1Conservative Off-Policy Evaluation
首先提出保守CQL(1)对于逐点无脑保守,及对于数据集内外Q都进行打压min 然后突出CQL(2),增加了一个放大约束,及对于数据集中的Q放大,仅约束V(Q的期望) 定理3.1和3.2 分别对于CQL(1)(2)进行论证
-
lower-bounds Qπ at all (s, a)
Qˆπ := limk→∞ Qˆk, 对每一个状态动作对(s,a)都形成真实值的下界 (无脑降低所有Q值,数据集内&数据集外)
-
Our choice of penalty is to minimize the expected Q value under a particular distribution of state-action pairs, µ(s, a).
µ(s, a)是训练的actor,s是replay buffer中,a是在这个state下,actor做出的新的action
-
加号右边
-
通过经验贝尔曼算子进行Q值更新,再通过MSE进行更新
-
-
加号左边
-
penalty,需要对这个Q值进行打压,所以是minmize
-
-
-
-
the expected value of the Qˆπ under π(a|s) lower-bound Vπ
只希望期望值是一个下界,即仅约束Vπ (对于数据集内的action的Q值增大)
-
最小化负值=最大化原值
-
红色部分
-
s和a均来自replay buffer,需要鼓励(最大化)
-
-
-
-
Theorem 3.1
-
说明通过(1)式获得的价值函数是真实函数每一个点对(s,a)的下界
-
-
-
Theorem 3.2
-
当 µ = π时,Q函数的期望是真实值的下界
-
-
-
-
3.2Conservation Q-Learning for Offline RL
经过上述一系列分析,作者提出了一个用于离线RL的CQL优化算法CQL(R),在CQL(2)加一个正则化,其中正则化项选择不同,可以得到不同CQL(H)、CQL(p) 定理3.3证明了在α比较大时,CQL RL算法可以得到真实Q值的下限 定理3.4证明了Q-function is gap-expanding,即Qestimate-Qtrue逐渐扩大(这是一个负值,因为Qtrue是存在数据集中的Q,我们要逐渐放大,Qestimate是数据集外的,我们要逐渐打压)
-
CQL(R)
-
defining a family of optimization problems over µ(a|s)
-
If we choose R(µ) to be the KL-divergence against a prior distribution,ρ(a|s),
比较两个概率分布的方法,称为Kullback-Leibler散度(通常简称为KL散度)。通常在概率和统计中,我们会用更简单的近似分布来代替观察到的数据或复杂的分布。KL散度帮助我们衡量在选择近似值时损失了多少信息。
-
if ρ = Unif(a)
均匀分布
-
CQL(H)
-
-
-
if ρ(a|s) is chosen to be the previous policy πˆk−1(a|s)
前一轮训练得到的策略作为p
-
CQL(p)
-
⭐more stable with high-dimensional action spaces
-
-
-
-
-
当前policy u 和某个先验分布 p的KL divergence
-
-
-
-
-
-
Theorem 3.3
-
CQL学习到真实Q值的lower-bound
-
-
-
Theorem 3.4
-
CQL更加保守,扩大了 Qestimate-Qtrue
-
-
-
-
3.3Safe Policy Improvement Guarantees
安全策略提升(safe policy improvement, SPI)就是实现安全强化学习的一种方案,这里安全的含义简单来说是:“更新后的策略,其性能不会比原策略差”。
-
Theorem 3.5
-
CQL优化的是带有惩罚的经验性目标,它表明不仅最大化经验MDP下的回报,同时约束训练的策略离产生数据集的行为策略较近(隐式的由gap-expanding引入)
-
-
-
Theorem 3.6
-
CQL导出的策略满足 ζ -safe策略提升
-
-
-
-
-
4.Practical Algorithm and Implementation Details
-
overall algorithm
-
-
Implementation details
-
continuous control experiments
-
20 lines of code on top of soft actor-critic (SAC)
-
learning rate for the policy is chosen to be 3e-5 (vs 3e-4 or 1e-4 for the Q-function)
-
α via Lagrangian dual gradient descent
-
-
discrete control experiments
-
20 lines of code on top of QR-DQN
-
α fixed at constant values
-
-
-
-
5.Related Work
-
Off-policy evaluation (OPE)
之前的方法容易OOD问题
-
Earlier works
-
used per-action importance sampling on Monte-Carlo returnsto obtain an OPE return estimator
-
-
Recent approaches
-
use marginalized importance sampling by directly estimating the state-distribution importance ratios via some form of dynamic programming and typically exhibit less variance than per-action importance sampling at the cost of bias.
-
-
-
Offline RL
-
Theoretical results.
-
the regularizer in CQL explicitly addresses the impact of OOD actionsdue to its gap-expanding behavior
-
CQLdoes not require estimating the behavior policy
-
CQL does not underestimate Q-values for all state-action tuples.
-
more robust to estimation error in online RL.
-
-
-
6.Experimental Evaluation
-
数据集
-
D4RL 是离线强化学习(offline Reinforcement Learning)的开源 benchmark,它为训练和基准算法提供标准化的环境和数据集。数据集的收集策略包含
-
7个子环境
offline rl 是训练用 d4rl 的数据集,测试是用具体的 RL 环境来交互,比如 Mujoco. 每个子环境有5个小环境
-
-
mujoco
旨在促进机器人、生物力学、图形和动画等需要快速准确模拟领域研究和开发的物理引擎,常来作为连续空间强化学习算法的基准测试环境。
-
-
Gym domains
-
-
Adroit tasks
-
-
AntMaze
-
Kitchen tasks
-
Offline RL on Atari games
-
-
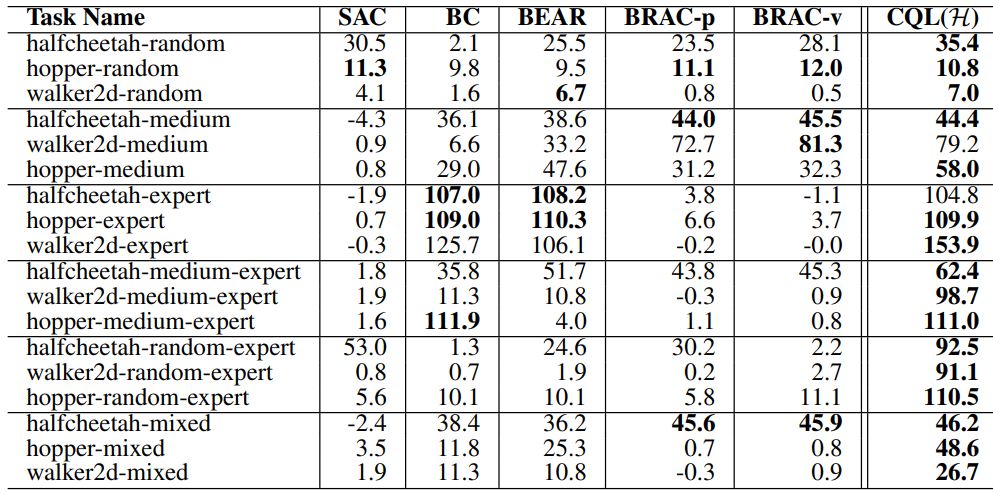
Analysis of CQL
-
只有CQL给出了负值=更保守(表中的数值就是Qestimate-Qtrue)
定理3-4
-
-
-
-
7.Discussion
-
First,We proposed conservative Q-learning (CQL), an algorithmic framework for offline RL that learns alower bound on the policy value.
-
Second,we demonstrate that CQL outperforms prior offline RL methods by 2-5x on a wide range of offline RL benchmark tasks
-
challenge
-
deep neural nets?
-
devise simple and effective early stopping methods?
-
-
-
Ackowledgements
-
Thanks
-
-
References
-
Appendices
-
A-Discussion of CQL Variants
讨论CQL的三种变体
-
CQL(H)
-
R = H(µ)
-
-
- 这里贴了两张推到图,由于当时脑子转的要起飞,所以写的就比较……炸裂,希望能看懂😁

-

-
CQL(ρ)
-
R=KL divergence
-
-
-
CQL(var)
-
training the Q-function that penalizes the variance of Q-function predictions under the distribution Pˆ.
-
-
-
-
B-Discussion of Gap-Expanding Behavior of CQL Backups
CQL gap-expanding 的实验
-
Function approximation may give rise to erroneous Q-values at OOD actions.
使用 Q function approximation 的 lower-bound 证明 函数近似function approximation 在实际应用中,对于大规模问题,状态和动作空间都比较大的情况下,精确获得各种价值函数v(S)和q(s,a)几乎是不可能的。这时候需要找到近似的函数,具体可以使用线性组合、神经网络以及其他方法来近似价值函数。
-
prior work
采用policy constraints技术
-
❌“generalization” or the coupling effects of the function approximator may be heavily influenced by theproperties of the data distribution
-
❌high values than Q-values at in-distribution actions
-
❌the errneous Q-function may push the policy towards OOD actions
-
-
-
How can CQL address this problem?
-
CQL
CQL regularizer解决上述问题
-
✅maximizes Q under the dataset distribution, and minimizes them otherwise.
-
✅by controlling αk, CQL can push down the learned Q-value at out-of-distribution actions as much isdesired, correcting for the erroneous overestimation error in the process.
-
-
-
Empirical evidence on high-dimensional benchmarks with neural networks.
-
• CQL backups are gap expanding in practice,
-
• Policy constraint methods, that do not impose any regularization on the Q-function may observe highly positive ∆ˆ k values during training,
-
• When ∆ˆ k values continuously grow during training, the policy might eventually suffer from an unlearning effect
-
-
-
C-Theorem Proofs
出现在正文中的定理 3.1 - 3.4 的证明
-
Proof of Theorem 3.1
-
老师带着我们推导👇
-

-
Proof of Theorem 3.2
-
划重点!!!!我自己推出来了,虽然课后看的时候有个符号写错了,我竟然会推公式了,我哭😭😭😭
-

-
Proof of Theorem 3.3
-
Proof of Theorem 3.4
-
-
D-Additional Theoretical Analysis
-
D.1 CQL with Linear and Non-Linear Function Approximation
-
D.2 Choice of Distribution to Maximize Expected Q-Value in Equation 2
公式 2 中 arg min α [E_μ Q - E_ΠβQ] ,如果把 Πβ 位置选择别的分布会怎样。
-
D.3 CQL with Empirical Dataset Distributions
公式 2 的 sample-based version
-
D.4 Safe Policy Improvement Guarantee for CQL
Safe Policy Improvement Guarantee for CQL
-
-
E-Extended Related Work and Connections to Prior Methods
-
Relationship to uncertainty estimation in offline RL
-
❌uncertainty-basedmethods are not sufficient to prevent against OOD actions
-
-
How does CQL relate to prior uncertainty estimation methods?
-
CQL strengthens the popular practice of point-wise lower-bounds made by uncertainty estimation methods
-
-
Can we make CQL dependent on uncertainty?
-
-
F-Additional Experimental Setup and Implementation Details
-
Choice of α
-
Computing log Pa exp(Q(s, a)
-
Hyperparameters.
-
Q-function learning rate
-
Policy learning rate
-
Lagrange threshold τ
-
Number of gradient steps
-
Choice of Backup
-
-
-
G-Ablation Studies
- 总结来说我对于CQL的理解就是通过加正则化项使得由behavior policyΠ产生的action的Q放大,learned policy μ产生的OOD actions的Q缩小,从而利用agent总是选择使得cumulated reward最大的action这一特性,让其尽可能选择我们人为将Q值放大的in distribution的行为。而且这种CQL方法是gap-expanding的,就是两个Q值,一个人为放大,一个人为缩小,他们的差距越来越大。妙啊🤖
- 完结撒花💐
-


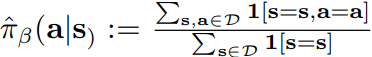







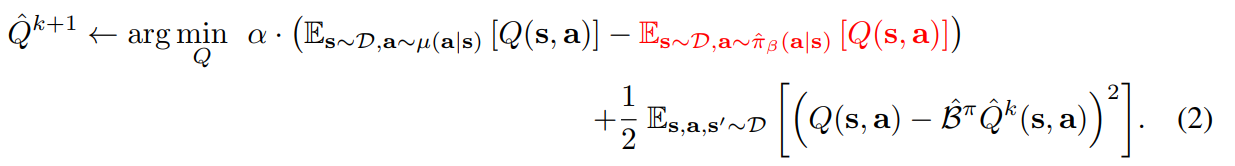


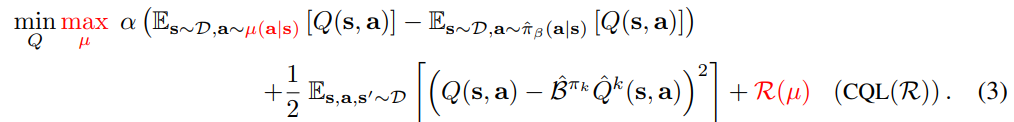
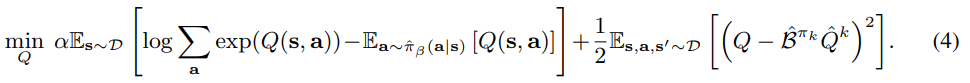
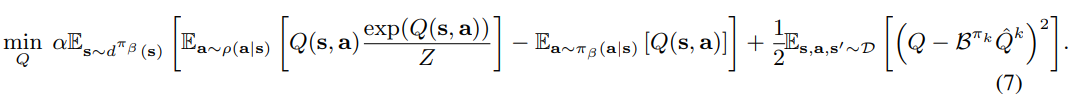


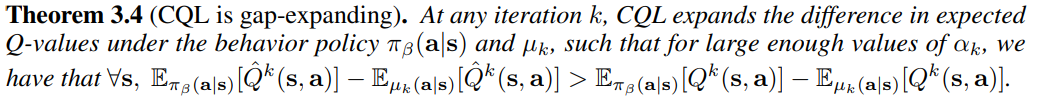

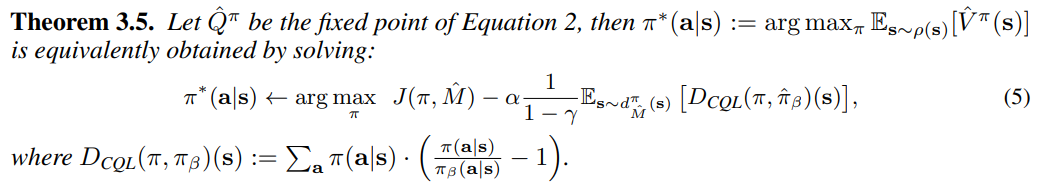





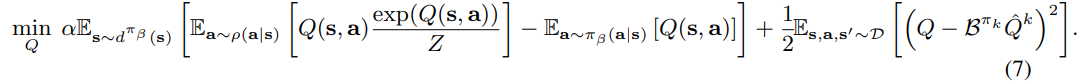
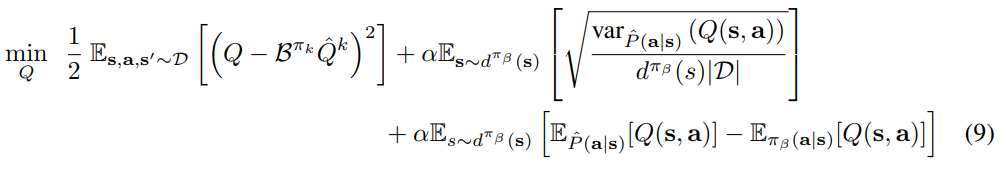
以上内容整理于 幕布文档















 3088
3088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









