






NVIDIA NeMo 是一个端到端云原生框架,无论是在本地还是在云上,用户可以灵活地构建、定制和部署生成式 AI 模型,更多内容可点击查看:NVIDIA Nemo——用于构建和部署生成式 AI 模型的端到端云原生框架_nv生态下的模型部署、迁移、调试
本期旨在了解和探讨使⽤ NVIDIA NeMo 框架实现 TTS 的训练和推理应⽤。
NVIDIA NeMo 的 ASR (Automatic Speech Recognition)、NLP (Nature Language Processing) 和 TTS(Text-to-Speech) 预训练模型是在多数据集上训练的(包括⼀些语⾔,如中⽂普通话),针对准确性进⾏了优化,可以⽤于训练、微调新模型或在现有预训练模型上进⾏迁移学习。
模型的每个模块(如编码器、解码器)的预训练权重有助于加速特定领域数据的模型训练,同时对于推理⽽⾔,训练好的模型可以很容易地转换为可部署推理的格式。NeMo 也提供了教程帮助⽤户训练或微调⽤中⽂普通话进⾏对话 AI 的模型。
现代 TTS 系统相当复杂,“端到端”(指从原始⽂本到⾳频输出)pipeline 由多个组件组成,每个组件都需要⾃⼰的模型或启发式⽅法。⼀个标准的 pipeline ⼀般包含以下步骤:
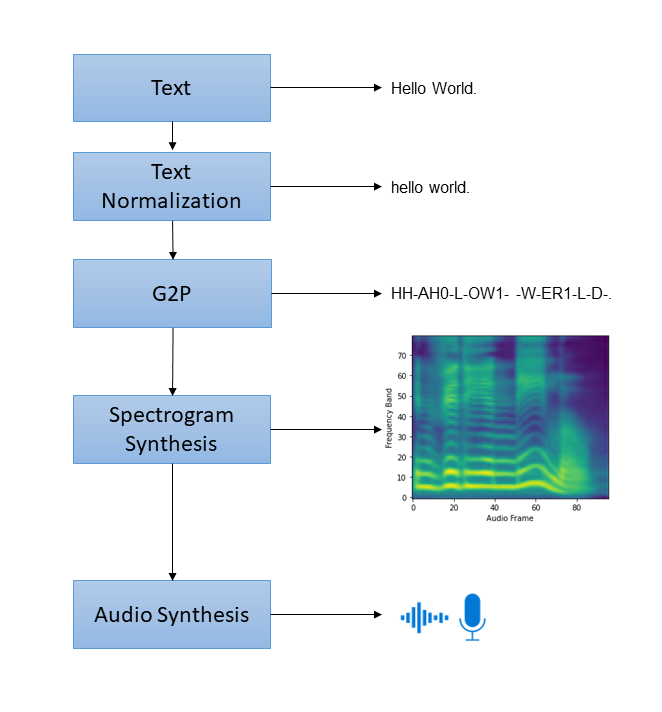
图片来源于NVIDIA
1. ⽂本规范化:将原始⽂本转换为⼝语⽂本。
2. 词素到⾳素转换(G2P):将规范后⽂本的基本单位(即词素/字符)转换为⼝语的基本单位(即⾳素)。
3. 谱图合成:将⽂本/⾳素转换为频谱图。
4. ⾳频合成:使⽤声码器将频谱图转换为⾳频,也称为频谱图反转。
对于后两步(谱图合成、⾳频合成),⽬前⽐较常⽤两步组合的 pipeline,⽐如 Tacotron2 + WaveGlow 的组合,前者是从⽂本⽣成梅尔频谱的模型,后者是从梅尔频谱⽣成⾳频的模型,NeMo的较新进展是基于 FastPitch + HiFi-GAN 的组合。
FastPitch 是基于 FastSpeech 完全并⾏的⽂本到语⾳合成模型,以基频轮廓为条件。该模型在推理过程中预测⾳⾼轮廓,通过改变这些预测,⽣成的语⾳可以更具表现⼒,更符合语句的语义,最终更能吸引听众。
HiFi-GAN 专注于设计⼀种声码器模型,能有效地从中间旋律谱图合成原始波形⾳频。它由⼀个发⽣器和两个鉴别器(多尺度和多周期)组成。⽣成器和鉴别器采⽤对抗训练,并增加了两个损失,以提⾼训练稳定性和模型性能。
NeMo 的“端到端”的模型还在开发中,TTS 推理部署⽅案建议使⽤我们之前分享过的 Triton 的 Ensemble Model 功能以零代码的⽅式组合同时运⾏的多个模块,如⽂本规范化、G2P、编码器等预处理
Triton Ensemble 可以将它们⽆缝组合在⼀起,⽽⽆需编写任何串联代码,实现了零代码的模型串联功能。对于声学模型的解码器、vocoder 以及最后的 Chunk 拼接的 Blender,Triton ensemble 也能以零代码的⽅式将它们组合在⼀起。前述模型包括Mel-Spectrogram Generator和 Vocoder,都可以使⽤ TensorRT 来加速推理。

图⽚来源于NVIDIA
使⽤ NeMo 可以快速实现以上步骤集成 TTS pipeline,NeMo 对于 TTS 训练有完整的⽀持包括:
-
Model Recipes,模型配⽅包括⽤于训练和评估模型的步骤和⽅法
-
Configuration Files,训练配置⽂件
-
Pre-trained Model Checkpoints,预训练模型权重
接下来我们将使⽤ NVIDIA NeMo FrameWork 容器实践 TTS 的训练,特别是频谱模型和⾳频合成器模型的训练和微调。
一、系统环境准备
⼿动安装可以参考 NeMo 的安装指南(https://github.com/NVIDIA/NeMo/blob/stable/docs/source/starthere/intro.rst#installation) ,这⾥采⽤更简便的官⽅容器⽅式(镜像查询和下载可能需要⼀定的权限,请⾃⾏检查NGC账号权限)。
# pull latest NeMo Framework container
docker pull nvcr.io/nvidia/nemo:24.01.framework
docker run -it -d
--cap-add=SYS_PTRACE --cap-add=SYS_ADMIN \
--security-opt seccomp=unconfined --gpus=all \
--shm-size=16g --privileged --ulimit memlock=-1 \
--name=nemo_test -v /home/docker/mnt:/home \
-p 28888:8888 -p 16006:6006 \
nvcr.io/nvidia/nemo:24.01.frameworkNeMo 部分组件版本信息:
-
ndc 0.1.0
-
nemo_toolkit 1.23.0
-
megatron_core 0.5.0rc0
-
transformer-engine 1.4.0.dev0+da30634
-
nemo_aligner 0.1.0rc0
NeMo 容器环境准备好之后,我们看⼀下 FastPitch 和 HiFi-GAN 模型的训练,FastPitch 与⼤多数 NeMo 模型⼀样,是⼀种 LightningModule,⽀持使⽤PyTorch Lightning训练,通过YAML⽂件定义来参数化配置并使⽤Hydra加载。
# NeMo中使用预训练模型生成频谱图
from nemo.collections.tts.models.base import SpectrogramGenerator
from nemo.collections.tts.models import FastPitchModel
from matplotlib.pyplot import imshow
from matplotlib import pyplot as plt
# 查看可使用的 FastPitch pretrained models 列表
print("FastPitch pretrained models:")
print(FastPitchModel.list_available_models())
# 加载 pre-trained Model
pretrained_model = "tts_en_fastpitch"
spec_gen = FastPitchModel.from_pretrained(pretrained_model)
spec_gen.eval();
assert isinstance(spec_gen, SpectrogramGenerator)
if isinstance(spec_gen, FastPitchModel):
tokens = spec_gen.parse(str_input="Hey, welcome to Nvidia NeMo TTS!")
else:
tokens = spec_gen.parse(text="Hey, welcome to Nvidia NeMo TTS")
spectrogram = spec_gen.generate_spectrogram(tokens=tokens)
%matplotlib inline
# 可视化查看生成的频谱图
imshow(spectrogram.cpu().detach().numpy()[0,...], origin="lower")
plt.show()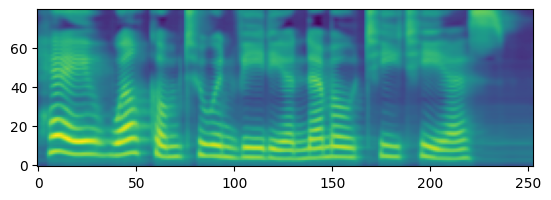
如上代码,我们简单尝试了使⽤ NeMo 框架⼯具利⽤ FastPitch 预训练模型⽣成频谱图。接下来我们按照 NVIDIA 官⽅提供的教程,实现⽀持中英⽂双语的 FastPitch 和 HiFi-GAN 的训练和微调。
二、开启 jupyter notebook
⾸先在docker容器内开启 jupyter notebook,host 主机上访问http://localhost:8888,通过token登⼊,之后的训练过程主要会在 jupyter notebook 上进⾏。
# 开启 jupyter notebook
root@f37a875dac31:/home# jupyter notebook > "jupyter-`date +"%Y%m%d%H%M%S"`.log" 2>&1
[I 06:07:19.341 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
[I 06:07:20.233 NotebookApp] jupyter_tensorboard extension loaded.
[I 06:07:20.538 NotebookApp] JupyterLab extension loaded from /usr/local/lib/python3.10/dist-packages/jupyterlab
[I 06:07:20.538 NotebookApp] JupyterLab application directory is /usr/local/share/jupyter/lab
[I 06:07:20.540 NotebookApp] [Jupytext Server Extension] NotebookApp.contents_manager_class is (a subclass of) jupytext.TextFileContentsManager already - OK
[I 06:07:20.544 NotebookApp] Serving notebooks from local directory: /home
[I 06:07:20.544 NotebookApp] Jupyter Notebook 6.4.10 is running at:
[I 06:07:20.544 NotebookApp] http://hostname:8888/?token=87aeab0595ef72111a234a28cc996da5f35d494707b2c8b0
[I 06:07:20.544 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 06:07:20.547 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-2068-open.html
Or copy and paste this URL:
http://hostname:8888/?token=87aeab0595ef72111a234a28cc996da5f35d494707b2c8b0三、下载相关脚本和⽂件
# 以下命令在容器shell内执行
cd /home
export BRANCH = 'main'
mkdir -p NeMoChineseTTS
cd NeMoChineseTTS
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/scripts/tts_dataset_files/zh/24finals/pinyin_dict_nv_22.10.txt
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/scripts/dataset_processing/tts/sfbilingual/get_data.py
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/scripts/dataset_processing/tts/sfbilingual/ds_conf/ds_for_fastpitch_align.yaml
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/examples/tts/fastpitch.py
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/examples/tts/hifigan_finetune.py
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/scripts/dataset_processing/tts/extract_sup_data.py
wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/scripts/dataset_processing/tts/generate_mels.py
wget https://raw.githubusercontent.com/NVIDIA/NeMo/$BRANCH/examples/tts/conf/zh/fastpitch_align_22050.yaml
wget https://raw.githubusercontent.com/NVIDIA/NeMo/$BRANCH/examples/tts/conf/hifigan/hifigan.yaml
mkdir -p model/train_ds && cd model/train_ds && wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/examples/tts/conf/hifigan/model/train_ds/train_ds_finetune.yaml
mkdir -p model/validation_ds && cd model/validation_ds && wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/examples/tts/conf/hifigan/model/validation_ds/val_ds_finetune.yaml
mkdir -p model/generator && cd model/generator && wget https://raw.githubusercontent.com/nvidia/NeMo/$BRANCH/examples/tts/conf/hifigan/model/generator/v1.yaml四、数据准备
FastPitch的原⽣训练相关代码和资料可查看DeepLearningExample,下⾯我们需要完成本次训练的数据准备⼯作,主要分4步。
1. 下载 SFSpeech 数据集
# 第一步:下载 SFSpeech 数据集
# 依赖 NGC ,请提前安装好 NGC CLI 工具
mkdir DataChinese && cd DataChinese
ngc registry resource download-version "nvidia/sf_bilingual_speech_zh_en:v1" && \
cd sf_bilingual_speech_zh_en_vv1 && \
unzip SF_bilingual.zipSFSpeech 双语数据集发布在NGC,包含约2,740个单⼀⼥性发⾔者的双语⾳频样本及其相应的⽂本转录,每个样本的⾳频时⻓约为5-6秒,总时⻓约为4.5⼩时。
对于⾃定义数据的规范,官⽅给出的相关建议是:
-
最好以22050赫兹的采样率获取语⾳数据,或者以更⾼的采样率获取数据,然后将其降采样⾄22050赫兹。
> 如果低于22050赫兹且⾼于16000赫兹:
-
请在⾃⼰的数据集上重新训练WaveGlow。
-
调整频谱图⽣成参数,即窗⼝⼤⼩和傅⽴叶变换的窗⼝跨度。
> 对于16000赫兹以下的频率,请考虑获取新数据。
-
在⽐特率/量化⽅⾯,⼀般建议越⾼越好。我们还没有进⾏⾜够的实验来说明这对质量有多⼤影响。
-
对于数据量,同样是越多越好,⽽且在⾳素⽅⾯越多样化越好。在过滤静⾳和⾮语⾳⾳频后,⽬标是⼤约20⼩时的语⾳。
-
⼤多数开放语⾳数据集的格式约为10秒,可以认为⽤于训练Tacotron 2的⾳频数据⻓度10秒⾄20秒的是有效的。语⾳样本越⻓,训练就越困难。
-
⾳频⽂件应该是⼲净的,背景噪⾳或⾳乐要少。使⽤⼯作室⻨克⻛录制的数据⽐使⽤⼿机捕获的数据更容易训练。
-
为确保单词的发⾳准确;训练效果与数据集⾮常相关,需要进⾏⽂本到⾳标拼写,使⽤正确发⾳的⾳标字⺟(符号)。
2. 创建数据清单
借助前述下载好的脚本 get_data.py 读取数据集中提供的 DataChinese/SF_bilingual/text_SF.txt为每个数据点⽣成以下字段:
-
audio_filepath: wav⽂件的位置;
-
duration: wav⽂件的时⻓;
-
text: 原始⽂本;
-
normalized_text: 规范化后⽂本。
运⾏以下命令获取最终的清单:train_manifest.json , val_manifest.json 和 test_manifest.json 。命令将 1% 的数据分为验证集,1% 分为测试集,剩余的 98% 分为训练集。这个过程包含了拆分数据集处理和规范化数据两种操作。
cd /home/NeMoChineseTTS
python get_data.py
--data-root ./DataChinese/sf_bilingual_speech_zh_en_vv1/SF_bilingual/ \
--manifests-path ./ \
--val-size 0.005 \
--test-size 0.013. 音素化
⼀个中⽂句⼦的发⾳可以表示为⼀串⾳素,⾸先使⽤ pypinyin 库将句⼦转换为拼⾳序列,然后使⽤预定义的拼⾳到⾳素字典将它们转换为⾳素。对于句⼦中的英⽂单词,我们直接使⽤字⺟作为输⼊单位。例如:
print("text: 我今天去了Central Park逛了逛。")
print("pinyin: 'wo3', 'jin1', 'tian1', 'qu4', 'le5', 'C', 'e', 'n', 't', 'r', 'a', 'l', ' ', 'P', 'a', 'r', 'k', 'guang4', 'le1', 'guang4')从 get_data.py ⽣成的原始 json 数据集拆分仅包含⽂本/字形输⼊,使⽤⾳素可以获得更⾼质量的合成⾳频。根据教程这⾥默认使⽤中⽂⾳素和英⽂字⺟作训练。
4. 创建补充数据
为了优化训练,还需要为每个⾳频提取⾳⾼,估计⾳⾼统计数据(均值、标准差、最⼩值和最⼤值),这⾥通过 extract_sup_data.py 脚本对数据进⾏⼀次迭代完成。注意:这是⼀个可选步骤,如果跳过,将在训练 FastPitch 的第⼀个 epoch ⾃动执⾏。
cd /home/NeMoChineseTTS
python extract_sup_data.py \
--config-path . \
--config-name ds_for_fastpitch_align.yaml \
manifest_filepath=train_manifest.json \
sup_data_path=sup_data \
phoneme_dict_path=pinyin_dict_nv_22.10.txt \
++dataloader_params.num_workers=4五、模型训练
1. 训练FastPitch模型
在训练模型之前先定义模型配置,配置⽂件:fastpitch_align_22050.yaml ,⼤部分模型配置保持不变,此外有两处改动:
-
phoneme_dict_path ⽂件路径指向 pinyin_dict_nv_22.10.txt ;
-
pitch_mean 和 pitch_std 使⽤上述 extract_sup_data.py 脚本估算出的值进⾏更新:
PITCH_MEAN=226.75924682617188,
PITCH_STD=58.773109436035156,
PITCH_MIN=65.4063949584961,
PITCH_MAX=1986.977294921875.
# 单卡训练
cd NeMoChineseTTS
CUDA_VISIBLE_DEVICES=0 python fastpitch.py \
--config-path . \
--config-name fastpitch_align_22050 \
model.train_ds.dataloader_params.batch_size=32 \
model.validation_ds.dataloader_params.batch_size=32 \
train_dataset=train_manifest.json \
validation_datasets=val_manifest.json \
sup_data_path=sup_data \
exp_manager.exp_dir=resultChineseTTS \
trainer.max_epochs=1500 \
trainer.check_val_every_n_epoch=1 \
pitch_mean=226.75924682617188 \
pitch_std=58.773109436035156 \
phoneme_dict_path=pinyin_dict_nv_22.10.txt注意:
> 使⽤ CUDA_VISIBLE_DEVICES=0 来限制训练仅在单个GPU上进⾏;
> 添加FLAGS:HYDRA_FULL_ERROR=1, CUDA_LAUNCH_BLOCKING=1 开启debug模式;
> 从头开始训练,建议使⽤⾄少5000个epochs。
2. 评估:训练好的 FastPitch + 预训练 HiFi-GAN
import IPython.display as ipd
from nemo.collections.tts.models import HifiGanModel, FastPitchModel
from matplotlib.pyplot import imshow
from matplotlib import pyplot as plt
test = "Hotmail会以资料夹方式区分不同邮件来源"
test_id = "com_SF_ce438"
data_path = "NeMoChineseTTS/DataChinese/sf_bilingual_speech_zh_en_vv1/SF_bilingual/wavs/"
seed = 1104
def evaluate_spec_fastpitch_ckpt(spec_gen_model, v_model, test):
with torch.no_grad():
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = False
parsed = spec_gen_model.parse(str_input=test, normalize=True)
spectrogram = spec_gen_model.generate_spectrogram(tokens=parsed)
print(spectrogram.size())
audio = v_model.convert_spectrogram_to_audio(spec=spectrogram)
spectrogram = spectrogram.to('cpu').numpy()[0]
audio = audio.to('cpu').numpy()[0]
audio = audio / np.abs(audio).max()
return audio, spectrogram
# 加载 fastpitch 和 hifigan 模型
import glob, os
# fastpitch_nemo_or_ckpt文件路径
fastpitch_model_path = sorted(glob.glob("NeMoChineseTTS/resultChineseTTS/FastPitch/*/checkpoints/*.*"),key=os.path.getmtime)[-1]
# 预训练模型 hifigan, 来源:https://api.ngc.nvidia.com/v2/models/nvidia/nemo/tts_en_lj_hifigan/versions/1.6.0/files/tts_en_lj_hifigan_ft_mixerttsx.nemo
hfg_ngc = "tts_en_lj_hifigan_ft_mixerttsx"
vocoder_model = HifiGanModel.from_pretrained(hfg_ngc, strict=False).eval().cuda()
if ".nemo" in fastpitch_model_path:
spec_gen_model = FastPitchModel.restore_from(fastpitch_model_path).eval().cuda()
else:
spec_gen_model = FastPitchModel.load_from_checkpoint(checkpoint_path=fastpitch_model_path).eval().cuda()
%matplotlib inline
audio, spectrogram = evaluate_spec_fastpitch_ckpt(spec_gen_model, vocoder_model, test)
# 播放音频
print("原始音频")
ipd.display(ipd.Audio(filename=data_path+test_id+'.wav', rate=22050))
print("预测音频")
ipd.display(ipd.Audio(audio, rate=22050))-
原始⾳频:hotmail-orig.wav
-
预测⾳频(62 epoches): hotmail-generate-62epoches.wav
-
预测⾳频(1594 epoches):hotmail-generate-1594epoches.wav
基于以上代码,我们⼀共⽐较了三个训练模型,分别迭代62、1594、5000 epochs,迭代 62 次合成的⾳频质量是⽐较糟糕的,在训练1594个epochs后有所改善但仍然不理想。因为上述⽐较使⽤的是预训练HiFi-GAN模型,为了进⼀步提⾼质量下⾯我们依照微调 FastPitch 的⽅式对 HiFi-GAN 进⾏微调。
3. 微调预训练 HiFi-GAN 模型
微调数据准备
我们运⾏以下代码使⽤ generate_spectrogram 中定义的⽅法从FastPitch⽣成梅尔频谱图,然⽽⽣成的频谱图与原始⾳频的mel频谱图不同,如下所示:
test_audio_filepath = "NeMoChineseTTS/DataChinese/sf_bilingual_speech_zh_en_vv1/SF_bilingual/wavs/com_SF_ce1.wav"
test_audio_text = "NTHU對面有一條宵夜街。"
from matplotlib.pyplot import imshow
from nemo.collections.tts.models import FastPitchModel
from matplotlib import pyplot as plt
import librosa
import librosa.display
import torch
import soundfile as sf
import numpy as np
from nemo.collections.tts.parts.utils.tts_dataset_utils import BetaBinomialInterpolator
def load_wav(audio_file):
with sf.SoundFile(audio_file, 'r') as f:
samples = f.read(dtype='float32')
return samples.transpose()
def plot_logspec(spec, axis=None):
librosa.display.specshow(
librosa.amplitude_to_db(spec, ref=np.max),
y_axis='linear',
x_axis="time",
fmin=0,
fmax=8000,
ax=axis
)
spec_model = FastPitchModel.load_from_checkpoint(fastpitch_model_path).eval().cuda()
print("加载原始音频梅尔频谱")
y, sr = librosa.load(test_audio_filepath)
# change n_fft, win_length, hop_length parameters below based on your specific config file
spectrogram2 = np.log(librosa.feature.melspectrogram(y=y, sr=sr, n_fft=1024, win_length=1024, hop_length=256))
spectrogram = spectrogram2[ :80, :]
print("spectrogram shape = ", spectrogram.shape)
plot_logspec(spectrogram)
plt.show()
print("加载预测的梅尔频谱")
with torch.no_grad():
text = spec_model.parse(test_audio_text, normalize=False)
spectrogram = spec_model.generate_spectrogram(
tokens=text,
speaker=None,
)
spectrogram = spectrogram.to('cpu').numpy()[0]
plot_logspec(spectrogram)
print("spectrogram shape = ", spectrogram.shape)
plt.show()
原始⾳频梅尔频谱
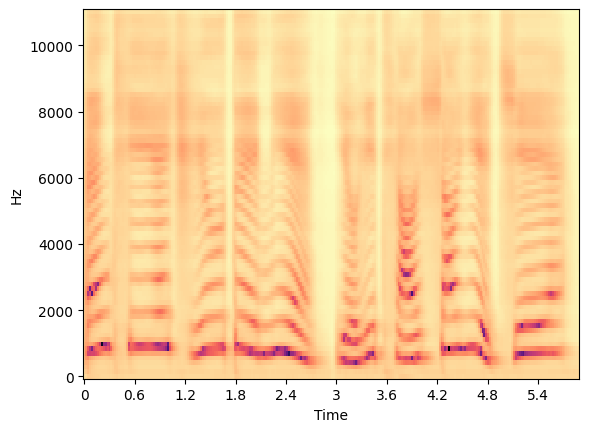
预测⽣成的梅尔频谱
从上图⽐较来看,我们需要将FastPitch预测的梅尔频谱图与真实数据对⻬包括持续时间。为什么不使⽤原始数据的梅尔频谱图呢?使⽤原始数据的梅尔频谱图进⾏微调会引⼊原始⾳频中的噪声伪影,这些噪声伪影会作为输⼊传递到模型,从⽽导致声码器输出中带有噪声。对⻬了的预测梅尔频谱图可以使HiFi-GAN能够不产⽣噪声⼜更接近真实。
具体实现:从FastPitch训练中获取最新的checkpoint,并预测每个输⼊记录的频谱图,这些记录分别位于train_manifest.json , test_manifest.json 和 val_manifest.json 中。
NeMo提供了⼀个⾼效的脚本,在⽬录NeMoChineseTTS/mels中⽣成梅尔频谱,并通过添加新字段 “mel_filepath” 创建具有后缀“_mel” 的新清单。例如, train_manifest.json 对应 train_manifest_mel.json 。值得⼀提的是,此脚本借助于NeMo提供的⼯具,利⽤真实频谱⻓度和插值后数据来⽣成对⻬的预测频谱图。
# 运行以下命令来获取新清单
cd /home/NeMoChineseTTS
python generate_mels.py --cpu \
--fastpitch-model-ckpt {fastpitch_model_path} \
--input-json-manifests train_manifest.json val_manifest.json test_manifest.json \
--output-json-manifest-root ./开始微调
cd /home/NeMoChineseTTS
CUDA_VISIBLE_DEVICES=0 python hifigan_finetune.py \
--config-path . \
--config-name hifigan.yaml \
trainer.max_steps=10 \
model.optim.lr=0.00001 \
~model.optim.sched \
train_dataset=train_manifest_mel.json \
validation_datasets=val_manifest_mel.json \
exp_manager.exp_dir=resultChineseTTS \
+init_from_pretrained_model={hfg_ngc} \
+trainer.val_check_interval=5 \
trainer.check_val_every_n_epoch=null \
model/train_ds=train_ds_finetune \
model/validation_ds=val_ds_finetune4. 评估:训练好的 FastPitch + 微调的预训练HiFi-GAN
hfg_path = sorted(glob.glob("NeMoChineseTTS/resultChineseTTS/HifiGan/*/checkpoints/HifiGan.nemo"), key=os.path.getmtime)[-1]
if ".nemo" in hfg_path:
vocoder_model_pt = HifiGanModel.restore_from(hfg_path).eval().cuda()
else:
vocoder_model_pt = HifiGanModel.load_from_checkpoint(checkpoint_path=hfg_path).eval().cuda()
if ".nemo" in fastpitch_model_path:
spec_gen_model = FastPitchModel.restore_from(fastpitch_model_path).eval().cuda()
else:
spec_gen_model = FastPitchModel.load_from_checkpoint(checkpoint_path=fastpitch_model_path).eval().cuda()
%matplotlib inline
audio, spectrogram = evaluate_spec_fastpitch_ckpt(spec_gen_model, vocoder_model_pt, test)
# 播放音频
print("原始音频")
ipd.display(ipd.Audio(data_path+test_id+'.wav', rate=22050))
print("预测音频")
ipd.display(ipd.Audio(audio, rate=22050))-
原始⾳频:hotmail-orig.wav
-
微调后预测⾳频:hotmail-generate-finetune.wav
至此,我们使⽤ NVIDIA NeMo 框架实现了 TTS 的训练和推理应⽤,接下来,我们还将实践更多模型的训练及推理。欢迎关注我们!















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









