







文章链接:https://arxiv.org/pdf/2402.01176v2
Paper的任务
处理各种知识密集型任务
任务的科学问题
本文任务虽然是:提出一个统一的语言模型来处理各种知识密集型任务,但其实其本质科学问题是:如何提高LLMs在知识密集型任务中的检索效率。
原因是:LLMs在生成文本时容易出现错误信息,特别是在知识密集型任务中,因此需要一种方法来增强模型对知识的准确检索和应用。
所以,只要是涉及到需要提高在知识密集型任务的背景下的检索效率的问题,都可以试试本文的方法。
challenges
- LLM在知识密集任务中易产生错误信息的幻觉问题;
- 传统检索模块与生成任务脱节,两者间优化不同步;
- 现有的生成式检索模型在生成排名靠前的文档标识符(DocIDs)时表现良好,但对于排名靠后的DocIDs准确性不足;
- 如何增强模型对DocIDs结构和语义的理解。
文章在Argue什么?
- 以往的方法主要关注于检索任务中的单个最佳DocID,对于排名靠后的DocIDs准确性不足;
- 传统检索模块与生成任务之间的分离,导致两者不能有效联合优化,限制了对检索和生成任务关系的理解。
- 生成式检索的潜力未被充分利用:尽管生成式检索(GR)在检索任务中表现出色,但其与下游任务的整合潜力尚未被充分探索。
- 现有的预训练语言模型缺乏对DocIDs的深入理解,限制了模型在检索和生成任务中的表现。
- 需要一个统一的多任务学习框架来同时优化检索和生成任务,并通过辅助任务来增强模型对DocIDs的理解。
motivation
- 考虑一种新的方法来提高检索阶段的质量,特别是生成相关文档标识符(DocIDs)的准确性和排名。
- 设计辅助任务来增强模型对DocIDs结构和语义的理解,从而提升检索和生成任务的性能。
- 统一检索和生成任务:应该采用一个统一的语言模型框架来整合检索增强生成(RAG)和闭卷生成任务,以实现端到端的优化。
方法及框架图
-
方法 ——CorpusLM
-
- 多任务学习框架:CorpusLM采用多任务学习架构,将生成式检索、闭卷生成和检索增强生成整合到一个统一的模型中,通过共享表示和优化过程来提高各个任务的性能。
- 生成式检索(Generative Retrieval, GR):通过直接生成文档标识符(DocIDs)来进行检索,CorpusLM引入了排名导向的DocID列表生成策略,允许模型从整个DocID排名列表中学习,而不是单一的查询-DocID对。
- 闭卷生成(Closed-book Generation):在没有外部信息辅助的情况下,仅依靠输入的查询来生成答案,类似于传统的自回归语言模型。
- 检索增强生成(Retrieval-Augmented Generation, RAG):首先检索相关内容,然后通过连续的贪婪解码生成参考文献和最终答案,CorpusLM提出了一种连续的DocIDs-参考文献-答案生成策略,以提高RAG的效率和准确性。
- 辅助DocID理解任务:引入一系列无监督的DocID理解任务,包括从伪查询生成DocID列表、从文档摘要预测DocID列表、从DocID生成内容摘要以及预测与给定DocID相关的DocID列表。
- 损失函数设计:CorpusLM使用了一个组合损失函数,包括生成式检索的排名损失、闭卷生成的损失、RAG的损失以及辅助DocID理解任务的损失,给它们赋予不同的权重系数来平衡这些任务。
-
框架图

-
- Generative Retrieval:生成式检索部分,它通过直接生成文档标识符(DocIDs)来检索相关文档。
- Ranking-oriented DocID List Generation:排名导向的DocID列表生成策略,模型学习生成一个按相关性排名的DocID列表。
- Closed-book Answer Generation:闭卷答案生成,不依赖外部信息,仅使用问题本身来生成答案。
- RAG: Continuous DocIDs-References-Answer Generation:检索增强生成,通过连续解码DocIDs、参考文献和答案来生成最终的响应。
- Document Summary, Open QA等:不同知识密集型任务类型
- Aux Task:辅助任务,用于增强模型对DocID的理解,包括预测伪查询的DocIDs、从文档摘要预测DocIDs。
- Greedy Decode:贪婪解码,指的是在解码过程中,每一步都选择概率最高的输出,而不是使用束搜索(beam search)。

-
-
- 排名导向的DocID列表生成策略 (a部分):
- 解码相关DocIDs,并根据前缀树的约束生成一个排名列表
-
-
-
- 这个策略利用了从文档集合中构建的DocID前缀树,以动态添加约束条件,确保生成的DocID列表是有效且不重复的。
- 连续的DocIDs-参考文献-答案生成策略 (b部分):
-
-
-
- 这个策略包括三个连续的解码步骤:
-
-
-
-
- 解码相关的DocIDs,并将它们映射到相应的文档。
- 对文档中的细粒度引用进行解码。
- 继续解码最终答案。
-
-
-
-
- 这种连续解码过程在统一的贪婪解码过程中实现,避免了多次输入输出迭代的需要。
-
-
结果

-
-
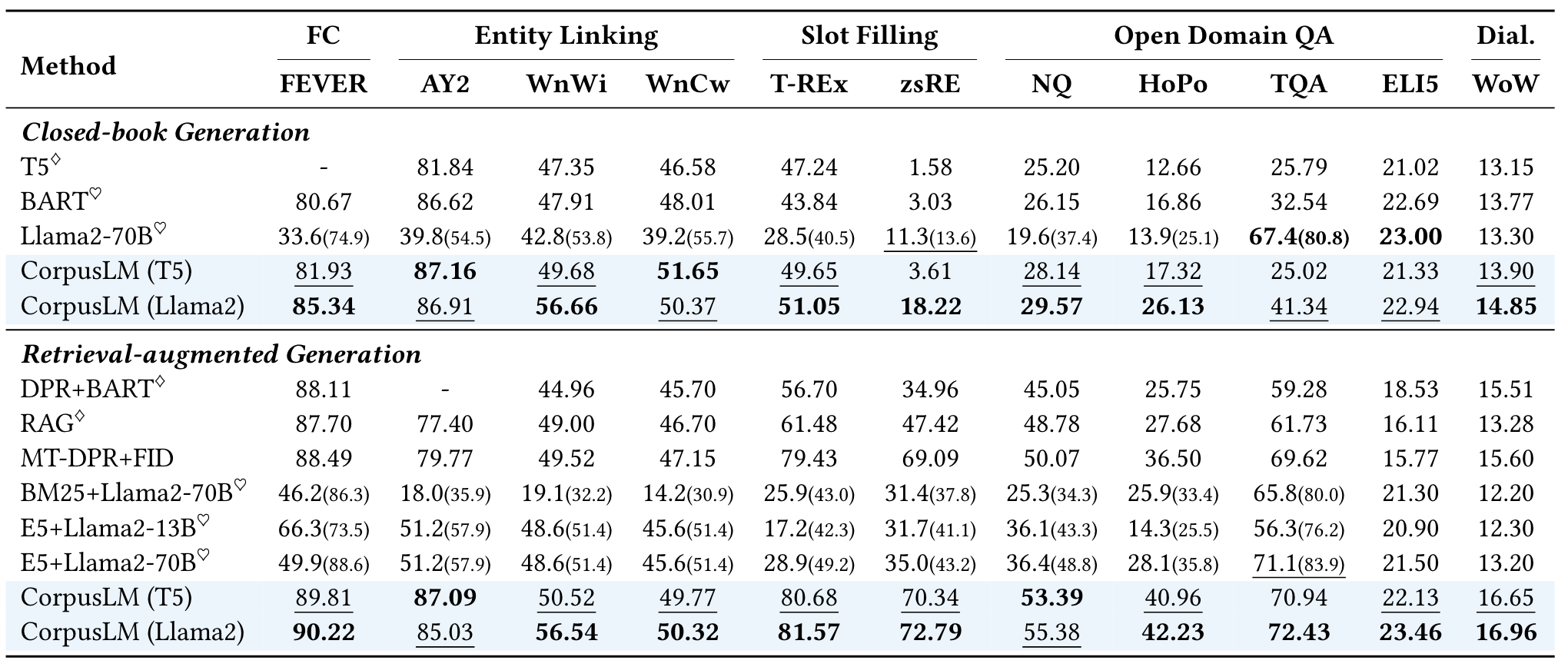
- 在KILT dev数据集上的整体检索性能
-
-
-
- 在KILT dev设置下,综合考虑闭本和RAG设置的整体下游性能
-
-
-
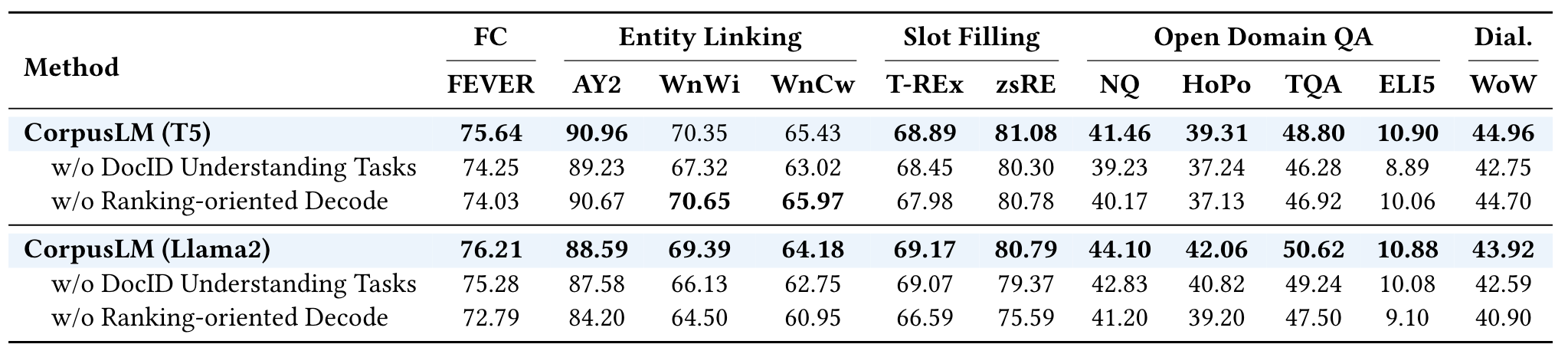
- 消融对检索性能的研究。最好的结果分别出现在基于T5和Llama2的模型中。
- w/o DocID Understanding Tasks: 表示在CorpusLM模型中移除了DocID理解任务。
- w/o Ranking-oriented Decode: 表示在CorpusLM模型中移除了排名导向的解码策略。
-

-
-
- RAG设置下的下游性能消融研究。最好的结果分别出现在基于T5和Llama2的模型中。
- w/o Decode Reference: 移除了参考文献解码步骤
- w/o Noise Sampling: 移除了噪声采样策略。噪声采样是在训练过程中引入随机性,以防止模型过度依赖于检索到的参考文本。
- w/o Pipeline Decode: 移除了流水线解码方式。流水线解码是指在生成过程中将检索和生成任务分开处理,而不是连续解码。
-
-
-
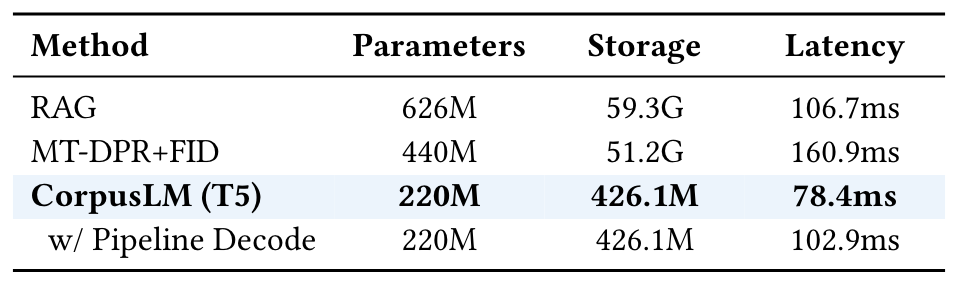
- RAG模型的效率分析
- MT-DPR+FID: 多任务密集型通道检索(Multi-Task Dense Passage Retriever)加上融合解码器(Fusion-in-Decoder)的模型,这是一种集成了检索和生成的模型。
- w/ Pipeline Decode: 表示CorpusLM (T5)模型使用流水线解码(将检索和生成任务分开处理,而不是在一个连续的过程中完成)。
-
实验是怎么做的?
-
设置了哪些实验?
-
- KILT(Knowledge-Intensive Language Tasks)基准测试,包含11个数据集,涵盖5种知识密集型自然语言处理任务
- 比较稀疏和密集检索模型:BM25、DPR、MT-DPR、RAG、E5、SimLM;比较生成式检索模型:T5、BART、SEAL、CorpusBrain、Llama2。
- 消融实验
-
消去实验都消去了什么?
-
- 移除了DocID理解任务
- 比较排名导向的DocID列表生成策略与传统的束搜索解码策略。
-
文章有什么用?
- 总体结论:为了处理知识密集型任务并提高大型语言模型在这些任务中的表现,可以通过整合生成式检索、闭卷生成和检索增强生成到一个统一的框架中来实现。
- 贡献点结论:
-
- 使用CorpusLM的设计和架构,包括排名导向的DocID列表生成策略和连续的DocIDs-参考文献-答案生成策略,是可以增强模型在检索质量和检索增强生成任务中的性能的。
- 通过辅助DocID理解任务,可以加强模型对DocIDs的语义理解,进而提升知识检索和答案生成的准确性和效率。
注释/笔记
- 知识密集型任务(Knowledge-Intensive Tasks):
-
- 这类任务要求模型不仅要理解自然语言,还要能够访问和整合外部知识库中的信息。例如,在问答系统中,模型可能需要回答关于历史事件的问题,这就需要它能够检索并理解相关的历史文档。
- 知识密集型任务通常包括但不限于:
-
-
- 问答系统(Question Answering): 根据给定的问题和上下文,模型需要找到或生成答案。
- 事实核查(Fact Checking): 模型需要验证陈述或声明的真实性,通常需要比较不同来源的信息。
- 实体链接(Entity Linking): 将文本中提到的实体与知识库中的相应实体对应起来,例如,识别文本中提到的“London”是指英国的首都。
-
- 检索增强生成(Retrieval-Augmented Generation, RAG):
-
- RAG是一种结合了检索和生成的方法。首先,模型检索与输入问题或任务相关的文档或信息片段。然后,它使用这些检索到的信息来生成回答或完成任务。
- 这种方法的优势在于它结合了检索系统的广泛覆盖和生成模型的灵活性,可以提高答案的准确性和相关性。
- 多任务学习(Multi-Task Learning):
-
- 在多任务学习中,模型被训练来同时执行多个任务。这通常通过共享表示层来实现,这样模型就可以在一个任务上学到的知识转移到其他任务上。
- 例如,一个多任务模型可能同时学习语言翻译、问题回答和文本摘要。
- 自回归模型(Autoregressive Models):
-
- 自回归模型在生成文本时,每个词的预测都依赖于之前已经生成的词。这种模型在生成序列数据时非常常见,如文本或语音。
- 它们通常使用概率分布来建模词序列,每次生成一个词,并逐步构建整个序列。
- DocID和文档索引:
-
- DocID: 是文档的唯一标识符,用于在数据库或检索系统中准确地引用和检索文档。
- 文档索引: 是一种优化检索过程的数据结构,它可以快速定位到包含特定信息的文档。例如,倒排索引就是一种常见的文档索引结构,它将单词映射到包含这些单词的文档列表。
- R-precision:
-
- R-precision是评估检索系统性能的一个指标,特别是在需要评估系统检索到的相关文档的准确性时。
- 它是排名最高的正确文档的比例,通常在事实核查和知识问答任务中使用。例如,如果检索系统返回了10个文档,其中前5个是相关的,那么R-precision就是50%(5/10)。
- 闭卷生成(Closed-book Generation):是一种自然语言处理任务,其中模型必须仅依赖于其预训练中获得的知识和内部表示来生成回答或完成语言生成任务,而不是访问外部信息或数据源。这个术语通常用于区分那些在生成答案时可以访问外部文档或数据库的开放域问答系统。
-
- 在闭卷生成中,模型的训练和评估都是在没有外部参考或搜索能力的情况下进行的。这意味着模型必须在训练阶段学习并记忆足够的信息,以便在评估或应用阶段生成相关和准确的输出。
- 内部知识: 模型依赖于其内部知识库或在预训练阶段获得的信息。
- 无外部搜索: 在生成回答时,模型不能搜索或检索外部文档、网页或数据库。
- 自回归生成: 模型通常使用自回归方法来生成文本,即每个词的生成依赖于之前生成的词序列。
- 语言模型能力: 需要在没有额外信息的情况下生成连贯和准确的回答。
- 应用场景: 适用于那些需要模型独立于外部数据源进行操作的场景,例如在没有网络连接的环境中。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











