







Paper的任务
解决在不断变化的文档集合中,更新和维护一个可微搜索索引(Differentiable Search Index, DSI)的问题。
任务的科学问题
本文任务虽然是:在动态文档集合中更新和维护可微分搜索索引(DSI),但其实其本质科学问题是:如何在模型持续学习新信息的同时减少对旧知识的遗忘。
原因是:当模型面对新文档时如何有效地整合新知识而不丢失之前学习到的相关信息是持续学习中的一个核心问题。
所以,只要是涉及到如何在模型学习新任务时减少对旧任务知识遗忘的问题,都可以试试本文的方法。
challenges
- 如何在模型不断学习新文档的同时,最小化对旧知识的遗忘。这涉及到在持续学习环境中,模型在面对新文档数据时,需要有效地整合新知识而不丢失之前学习到的信息,特别是在没有访问先前文档查询的条件下。
文章在Argue什么
- 计算成本高昂:当文档集合发生变化时,现有的DSI模型需要重新训练,这导致了非常高的计算成本。
- 灾难性遗忘:现有方法在不断索引新文档的同时,会导致之前索引的文档信息被严重遗忘,这影响了模型对历史数据的检索能力。
- 持续学习的挑战:DSI模型缺乏有效的机制来应对持续学习的场景,即在不断学习新任务的同时保留旧任务的知识。
- 缺乏对动态数据集的适应性:现有模型没有考虑到实际应用中数据集持续增长和更新的情况,缺乏对动态数据集的适应性和灵活性。
motivation
- 持续学习的需要:现实世界的数据是不断变化的,模型需要能够适应这种变化,持续学习新信息,同时保留对旧信息的记忆。
- 减少遗忘:在不断学习新文档的过程中,现有的DSI模型会遗忘旧文档,这对于信息检索系统来说是不可接受的。因此,需要一种机制来减少或避免这种灾难性遗忘。
- 提高计算效率:重新训练一个DSI模型来适应文档集合的更新成本高昂。需要一种更高效的增量学习方法,以减少计算资源的消耗。
方法
-
方法 ——DSI++
-
- Sharpness-Aware Minimization (SAM): 为了减少在记忆过程中的遗忘现象,作者采用了SAM技术来优化训练动态。SAM通过寻找更平坦的损失盆地,帮助模型更稳定地记忆文档,减少遗忘。
- 生成式记忆(Generative Memory): 为了解决新文档带来的显式遗忘问题,作者引入了一个生成式记忆模块。这个模块可以为已经索引的文档生成伪查询(pseudo-queries),并在持续索引过程中使用这些伪查询来辅助训练,从而减少对旧文档的遗忘。
- 经验重放(Experience Replay): 利用生成式记忆生成的伪查询,作者实现了一种经验重放机制。这允许模型在索引新文档的同时,通过重放旧文档的伪查询来复习和保持对旧知识的记忆。
- 增量索引(Incremental Indexing): DSI++支持增量索引,这意味着模型可以逐步整合新文档到索引中,而不需要对整个文档集合进行重新训练。
- 半监督学习(Semi-Supervised Learning): 通过生成式记忆,DSI++能够在没有标签的新文档上进行半监督学习,提高模型对新信息的适应能力。
-
结果
-
-
-
-
-
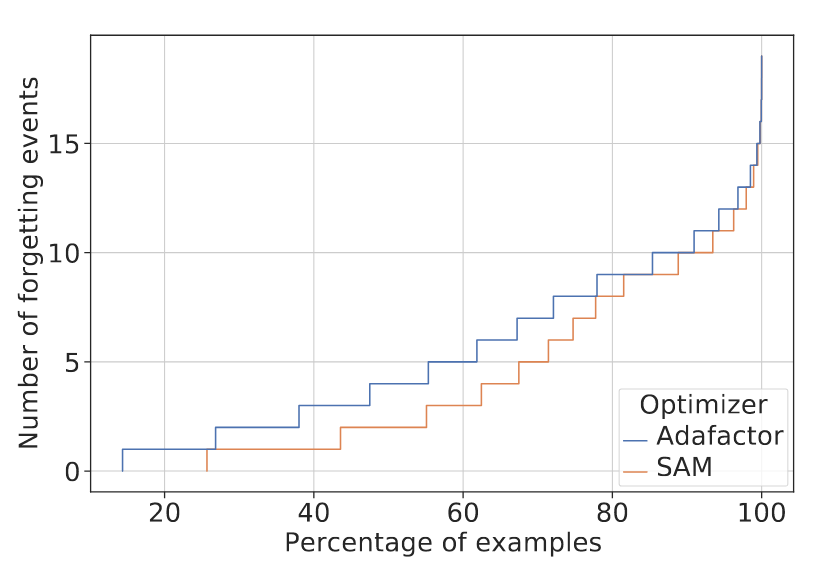
- SAM(Sharpness-Aware Minimization)在减轻T5-Base模型隐式遗忘方面的有效性,通过可视化遗忘事件的累积直方图
-
-
-
-
-
-
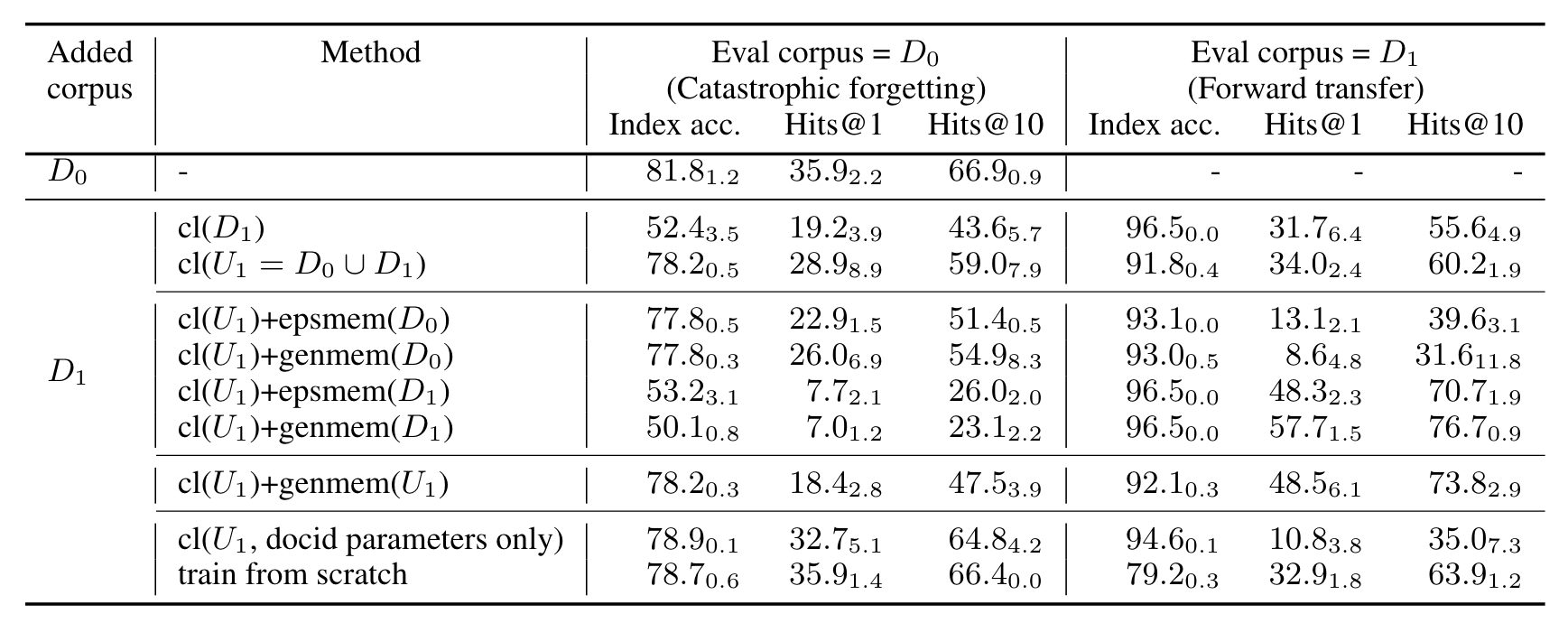
- 比较了不同方法(包括持续索引(cl(Dn))、持续索引加生成式记忆(cl(Un)+genmem(Un))等)在D1文档集合增量索引上的性能
-
-
-
-
-
-
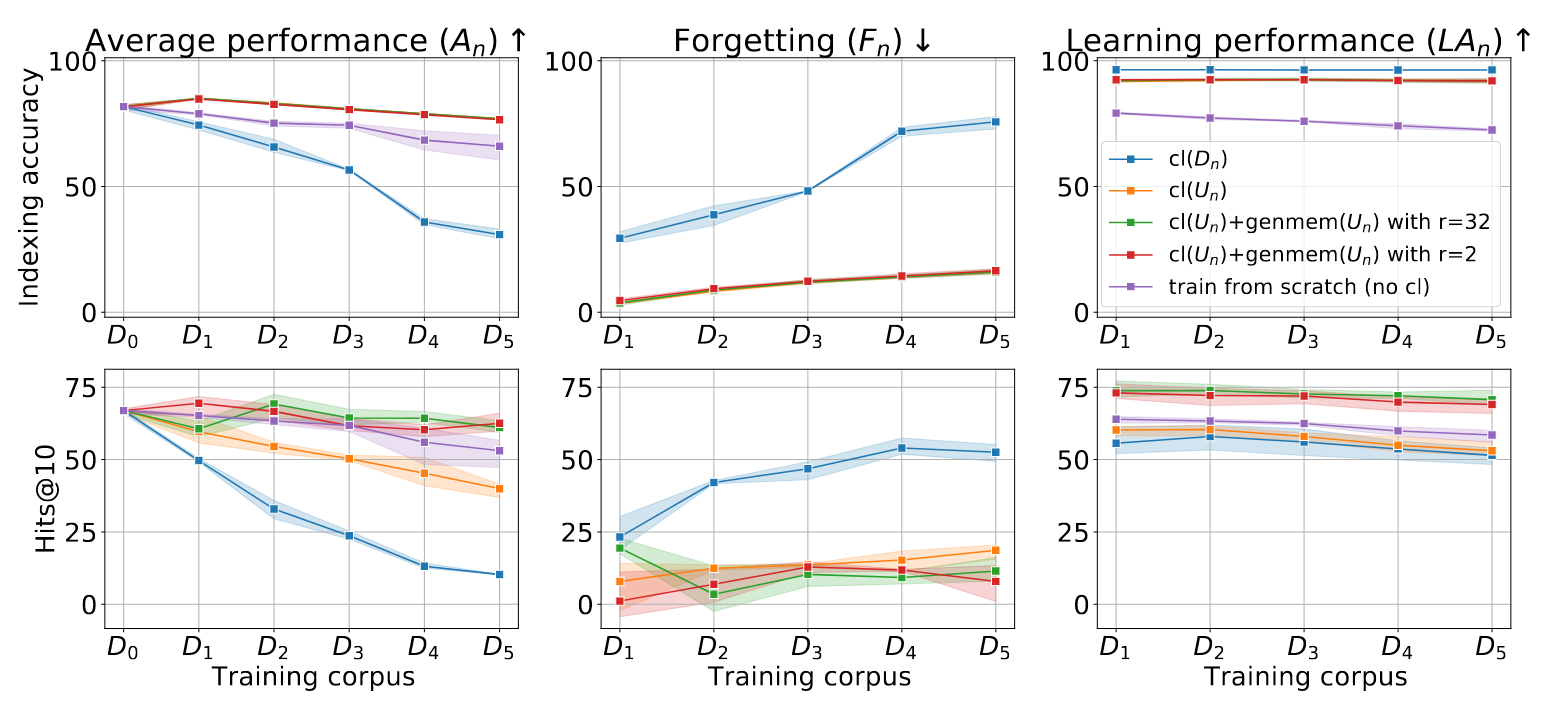
- 在连续索引新文档集合Dn时,生成式记忆减轻遗忘的有效性,针对NQ数据集,使用T5-Base模型和原子docid表示
-
实验是怎么做的?
-
设置了哪些实验?
-
- 基准模型性能评估:使用不同规模的模型(T5-Base, T5-Large, T5-XL)和文档标识符(docid)表示方法来评估DSI模型在索引准确性和检索任务(Hits@1, Hits@10)上的性能。
- 遗忘和前向迁移研究:通过增量索引新文档集合来研究模型在遗忘(Forgetting)和学习表现(Learning performance, LAn)上的行为。
- SAM优化器的影响:比较SAM(Sharpness-Aware Minimization)优化器与Adafactor优化器在减少隐式遗忘方面的效果。
- 生成式记忆的有效性:评估引入生成式记忆来生成伪查询,并在持续索引中使用这些伪查询来减轻检索任务遗忘的效果。
- 不同数据集的泛化能力:在Natural Questions (NQ)和MS MARCO数据集上测试所提方法,以展示其泛化能力。
-
文章有什么用?
- 总体结论:为了有效地更新和维护在动态变化的文档集合中的可微分搜索索引(DSI),DSI++方法提供了一种有效的解决方案。
- 贡献点结论:通过引入SAM(Sharpness-Aware Minimization)优化和生成式记忆机制,DSI++能够减少在学习新文档时对旧文档的遗忘,并且提高了检索任务的性能。
















 3297
3297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











