







Paper的任务
在下游任务中有效地利用含噪声的预训练基础模型
(与通常说的有噪声的标签学习不同,文章假设标签噪声存在于通常不可访问的预训练数据中,但其目的是在下游任务上理解和缓解标签噪声)
任务的科学问题
本文任务虽然是:在下游任务中有效地利用含噪声的预训练基础模型,但其实其本质科学问题是:如何在存在数据噪声的情况下保持和提升模型的泛化能力。
原因是:尽管预训练模型在特定领域表现出色,但噪声数据可能导致模型学习到错误的模式,从而影响其在新任务上的表现。
所以,只要是涉及从大规模含噪声数据集中学习并提升模型泛化能力的问题,都可以试试本文的方法。
科学问题的challenges
- 噪声数据的识别与影响评估:在大规模预训练数据集中,噪声不可避免的存在,但难以识别这些噪声并评估基于此类数据预训练的模型在下游任务上的可迁移性和泛化性产生的不利影响。
- 黑盒模型的调整:在实际应用中,预训练模型的细节可能对用户不可见(例如,ChatGPT等专有模型只提供了API,无法进行局部微调和诊断),这要求提出的解决方案能够在信息有限的情况下进行有效的模型调整。
文章在Argue什么?
- 现有方法的局限性:以往的研究和实践主要集中在使用干净数据对基础模型进行预训练和微调,而没有充分考虑到大规模预训练数据集中存在的噪声问题。
- 现有实践的局限性:现有的实践(先预训练再微调)直接在大规模数据集上预训练模型,然后将其应用于下游任务,而没有对潜在的噪声问题进行处理。
- 噪声数据的影响:文章指出,噪声不总是负面影响,轻微的噪声在某些情况下可能对领域内(ID)任务的性能有益,但噪声总是损害领域外(OOD)任务的性能(研究者在本文实验中发现的结论)。
motivation
大规模预训练数据集中不可避免地存在噪声,想要提高模型在多样化下游任务中的泛化能力和实用性(实际应用中用户硬件跟不上或模型只开放了api),应该用一种新的、轻量级的调优方法(NMTune),重塑预训练的特征空间,去降低噪声预训练数据的影响。
方法及框架
-
方法 (Noisy Model Tuning(NMTune))
-
- 特征空间转换(调整特征表示):通过在预训练模型的特征提取器之上引入一个可学习的转换层(一个多层感知机,MLP),将原始特征空间映射到一个新的特征空间。
- 正则化技术:NMTune采用了三种正则化策略来优化新特征空间的质量:
-
-
- 一致性正则化(Consistency Regularization):通过最小化原始预训练特征和转换后特征之间的差异,鼓励新特征空间保持与原始预训练知识一致。
- 协方差正则化(Covariance Regularization):通过调整特征空间的协方差矩阵,促使不同特征维度之间的信息更加独立,避免特征冗余。
- 主成分正则化(Dominant Singular Value Regularization):通过最大化特征空间中最大奇异值的比例,提高模型的泛化能力。
-
3.损失函数设计:NMTune的总损失函数结合了下游任务的交叉熵损失和上述正则化项。这允许模型在保持预训练知识的同时,学习适应下游任务的特征表示。
-
框架图
-
-
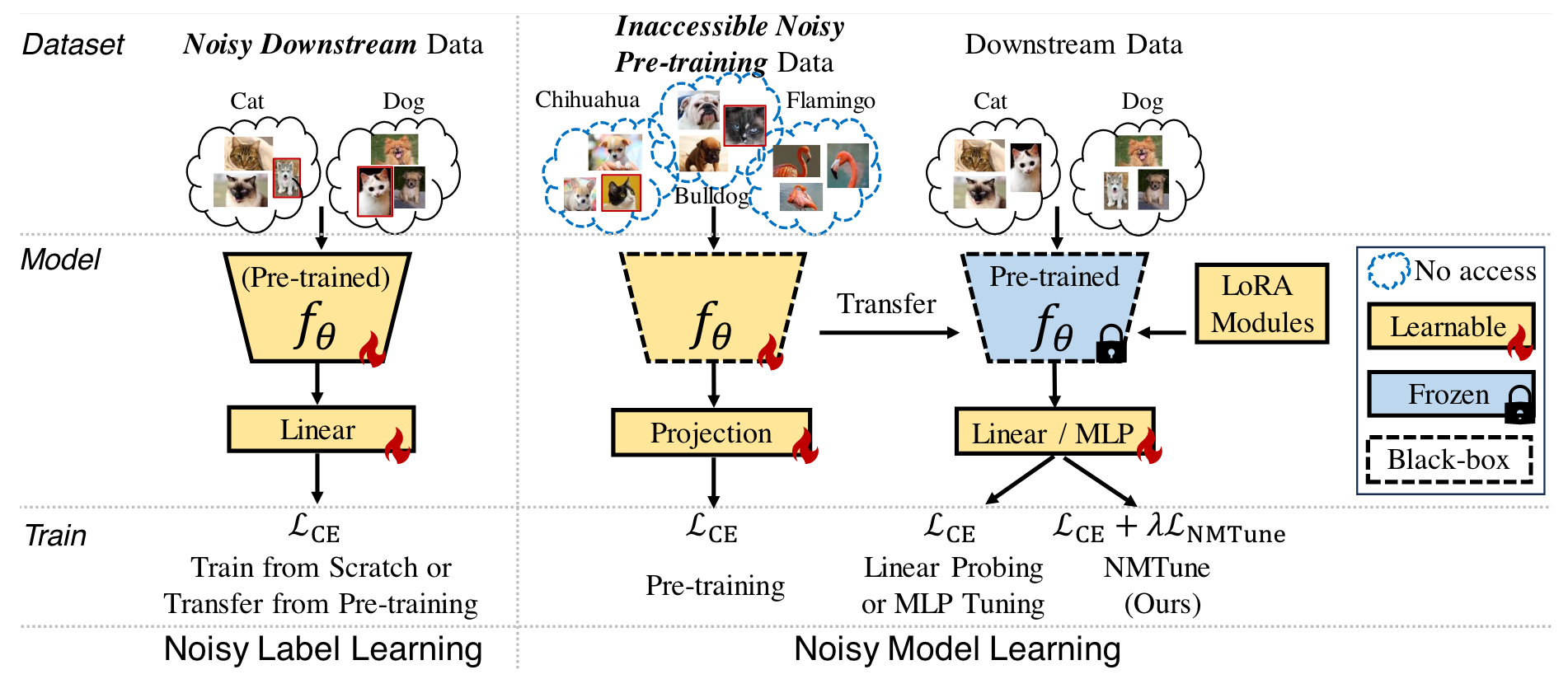
-
-
- 预训练模型(Pre-trained Model):表示在有噪声的数据上预训练得到的模型。
- 下游数据(Downstream Data):预训练模型需要适应的下游任务的数据集,可能也是有噪声的。
- 线性探测(LP):通过训练模型顶部的线性层来适应下游任务。
- 多层感知机(MLP):在预训练模型的特征提取器之上引入一个可学习的转换层(MLP)
- LoRA(Low-Rank Adaptation):一种参数高效的调优方法,通过在模型中间层插入低秩矩阵来调整模型。
- NMTune:作者提出的方法,通过正则化技术调整预训练模型的特征空间,以减轻噪声的影响。
-
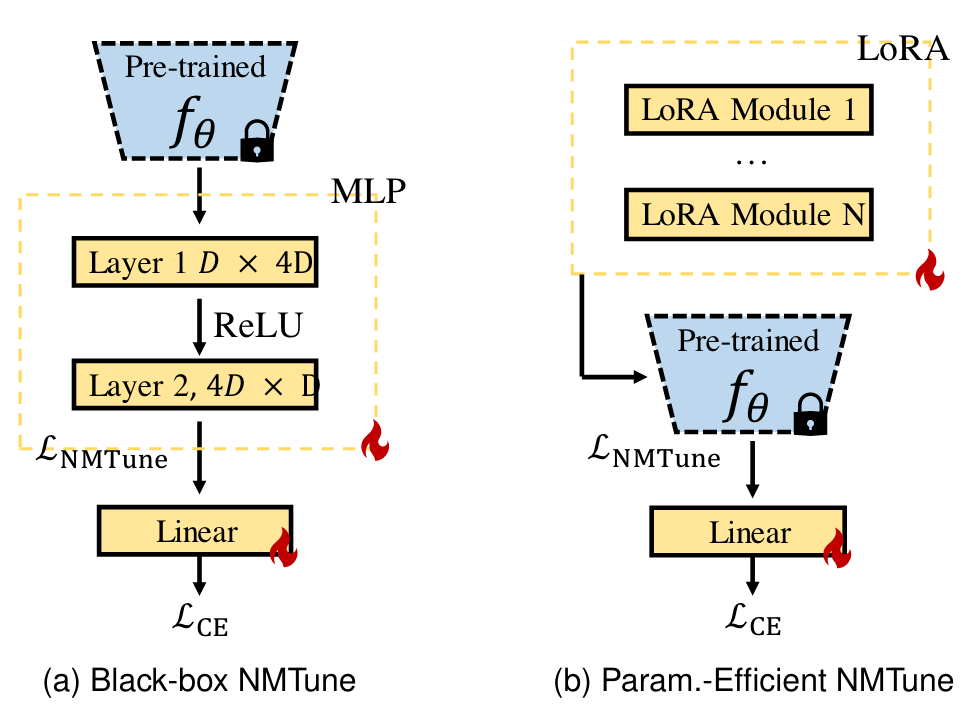
-
-
- 黑盒NMTune(Black-box NMTune):在无法访问预训练模型内部结构的情况下,通过在模型输出上添加一个额外的转换层(MLP)来进行调优
- 参数高效NMTune(Param.-Efficient NMTune):在可以部分访问预训练模型内部参数的情况下,通过在模型内部添加轻量级模块(LoRA)来进行调优。
-
-
结果
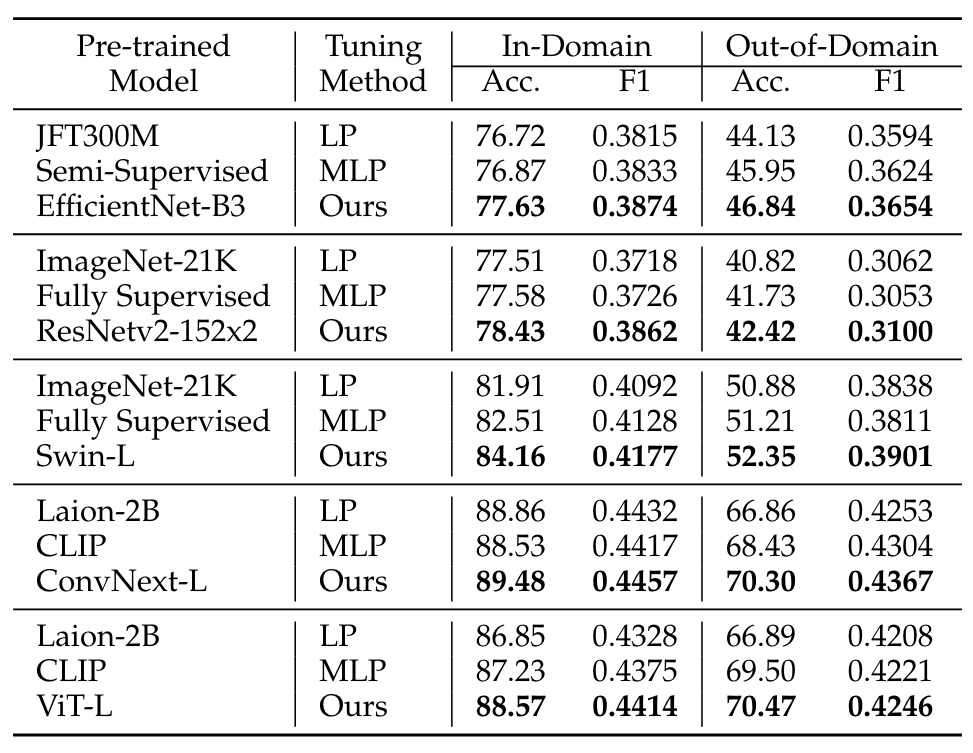
-
-
- 流行视觉模型的结果:在14个领域内(ID)和4个领域外(OOD)任务上,不同预训练模型分别使用LP、MLP和NMTune调优后的平均准确率和F1分数。
-
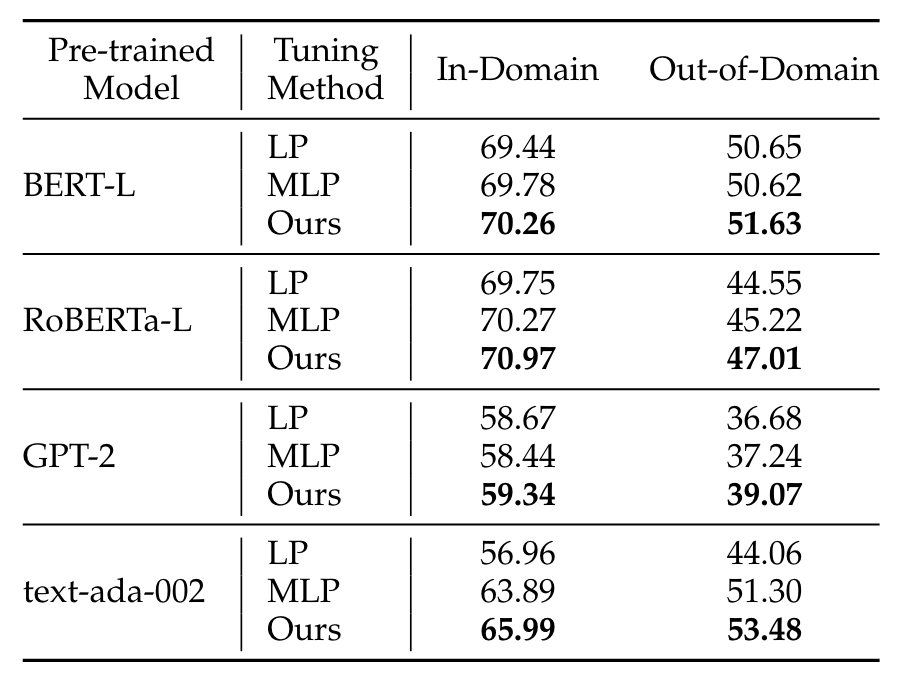
-
-
- 语言模型的评估结果:在GLUE(General Language Understanding Evaluation)和GLUE-X基准测试中,不同语言模型分别使用LP、MLP和NMTune调优后的ID和OOD性能。
-

-
-
- NMTune的平均运行时间:比较了NMTune、MLP调优和线性探测(LP)在视觉和语言任务上的GPU小时数。
-
实验设置
-
- 预训练噪声的影响:在合成的含噪声的ImageNet-1K、YFCC15M和CC12M数据集上进行全监督和图像-文本对比预训练,研究不同程度的噪声对模型性能的影响。
- 下游任务的性能评估:在多个下游任务上评估预训练模型的性能,包括领域内(ID)和领域外(OOD)的分类任务、目标检测和实例分割任务。
- 不同调优方法的比较:比较了线性探测(LP)、参数高效调优(如LoRA)和全参数调优(FT)对含噪声预训练模型性能的影响。
- NMTune方法的评估:在不同的预训练噪声水平下评估NMTune方法的性能,并与其他基线方法进行比较。
- 实际场景中的实验:在实际的大规模视觉和语言模型上测试NMTune,包括对非对称噪声和随机噪声的评估。
-
文章有什么用?
- 总体结论: 为了处理和减轻大规模预训练数据集中的噪声对下游任务性能的不利影响,可以使用本文提出的NMTune方法。
- 贡献点结论:
-
- 噪声模型学习(Noisy Model Learning, NML):提出了一个新的研究领域,专注于理解和减轻预训练数据噪声对下游任务的影响。
- NMTune方法:设计了一种新的调优方法,通过正则化技术调整预训练模型的特征空间,以减少噪声数据的不良影响。
- 正则化策略:引入了一致性正则化、协方差正则化和主成分正则化,这些策略有助于改善特征空间的质量并提高模型的泛化能力。
- 参数高效和黑盒调优:NMTune能够在参数高效和黑盒调优的设置中工作,使其适用于不同的应用场景和模型。
笔记
- GLUE(General Language Understanding Evaluation)基准测试:GLUE是一个多任务评估平台,旨在推动自然语言理解领域的发展。它包含了一系列自然语言处理(NLP)任务,用于测试和比较不同模型在各种语言理解任务上的性能。任务包括:情感分析(Sentiment Analysis)、语义相似度(Semantic Similarity)、命名实体识别(Named Entity Recognition)、句子对分类(Sentence Pair Classification)、文本蕴含(Textual Entailment)、文本分类(Paragraph Classification)、问答(Question Answering)。
- GLUE-X基准测试:GLUE-X是GLUE的一个扩展,它不仅包括GLUE的任务,还增加了额外的任务和挑战,以更全面地评估模型的泛化能力和鲁棒性。包括但不限于:更大的词汇量和更长的文本序列、更多的领域和风格、更复杂的语言现象,如讽刺、双关语等。
- 线性探测(Linear Probing,LP),这是一种在自然语言处理(NLP)和计算机视觉等领域中用于评估预训练模型在下游任务上性能的方法。具体来说,LP涉及以下步骤:
-
- 冻结预训练模型:在LP中,预训练模型的所有层都被冻结,即它们的权重在调优过程中不发生变化。
- 添加线性层:在预训练模型的顶部添加一个或多个线性层(全连接层),这些层是唯一在调优过程中被训练的部分。
- 下游任务训练:使用下游任务的数据集来训练这些新添加的线性层。由于只有这些层的权重会被更新,因此这是一种参数非常高效的调优方法。
- 评估性能:在下游任务的标准测试集上评估模型的性能,以了解预训练模型在特定任务上的泛化能力。
- LP是一种常见的精调(fine-tuning)策略,特别适用于以下情况:
-
-
- 当预训练模型非常大,而下游任务的数据集相对较小时。
- 当计算资源有限,无法对整个预训练模型进行完整的重新训练时。
- 当需要快速适应新任务,而不需要对模型进行大幅度修改时。
- 在本文的研究中,LP被用作基线,与其他调优方法(如NMTune、LoRA等)进行比较,以展示NMTune在处理含噪声预训练数据时的优势。
-
- LoRA,即Low-Rank Adaptation,是一种参数高效的模型调优方法,用于迁移学习场景。这种方法特别适用于大型预训练模型,如深度神经网络,当需要将这些模型适应到特定下游任务时。LoRA的核心思想是在模型的某些层中引入低秩结构,以此来调整模型的参数,而不需要对整个模型的参数进行重新训练。
- LoRA的关键特点包括:
- 参数效率:LoRA通过在模型的中间层插入低秩矩阵来调整模型,这意味着只需要更新模型中的一小部分参数,从而减少了计算和存储需求。
- 保留预训练信息:由于只有部分参数被调整,预训练模型中的大部分信息得以保留,这有助于模型在新任务上快速适应。
- 灵活性:LoRA可以应用于不同的模型结构和不同的层次,提供了一种灵活的调整策略。
- 易于实现:LoRA可以很容易地集成到现有的模型训练流程中,不需要对模型架构进行大规模的修改。
- LoRA的应用场景:
- 大型模型微调:对于像BERT、GPT这样的大型预训练语言模型,LoRA可以有效地进行微调,而不需要大量的计算资源。
- 多任务学习:LoRA允许在同一模型上同时进行多个任务的训练,每个任务可以通过不同的低秩矩阵进行调整。
- 资源受限的环境:在计算资源有限的情况下,LoRA提供了一种高效的模型调优方式。
- 在本文中,LoRA被用作一种调优方法,与NMTune进行比较,以展示NMTune在处理含噪声预训练数据时的性能。
- LoRA的关键特点包括:
- 奇异值(Singular Value):对于一个给定的m×n矩阵A,奇异值是指矩阵ATA或者等价地AAT的非负平方根特征值。这些特征值记为σi(i=1,2,...,min(m,n)),并且满足σ1≥σ2≥...≥σmin(m,n)≥0。
- 奇异值分解(Singular Value Decomposition, SVD)
- 任何矩阵AA都可以分解为三个矩阵的乘积,形式如下: A=UΣVT其中:
- U是一个m×m的单位正交矩阵(即UTU=I),其列向量称为左奇异向量。
- Σ是一个m×n的对角矩阵,对角线上的元素是A的奇异值。
- V是一个n×n的单位正交矩阵(即VTV=I),其列向量称为右奇异向量。
- 奇异值谱(Singular Value Spectrum)
- 奇异值谱是指一个矩阵的所有奇异值按从大到小排列的序列σ1,σ2,...,σmin(m,n)。这个序列提供了矩阵重要特性的信息,如数据的秩、列空间和行空间的维度、以及矩阵的低秩近似等。
- 应用和意义
- 数据降维:通过保留最大的几个奇异值及其对应的左右奇异向量,可以得到数据的低秩近似,这在数据压缩和降维中非常有用。
- 计算机视觉:在计算机视觉中,SVD用于图像压缩和特征提取。
- 非对称预训练噪声(asymmetric pre-training noise):是指在预训练数据集中,噪声分布不均匀,对某些类别或概念的影响大于其他类别的现象。在机器学习中,这通常意味着一些类别的标签错误或噪声比其他类别更常见,而不是所有类别的噪声分布都相同。非对称预训练噪声的特点:
- 类别不均匀性:噪声不是随机或均匀地分布在所有类别上。一些类别可能会有更多的错误标签,而其他类别则相对较少。
- 来源偏差:噪声可能由于数据收集过程中的偏差而产生,例如,某些类别的样本更容易被错误标注,或者标注者对某些类别的理解存在偏差。
- 影响不均:非对称噪声可能会对模型学习的特征表示产生不均匀的影响,导致模型对某些类别的性能下降更为严重。
- 在文档中,作者提到了对非对称噪声的实验,其中噪声只存在于预训练数据的一个受限子集中。例如,他们选择了CIFAR-100数据集中的某些类别,并在ImageNet-1K的相应类别中引入了噪声。这种方法模拟了现实世界中可能遇到的噪声情况,噪声并不是随机分布的,而是与特定的类别或概念相关联。















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









