







4.7 练习题
1. 选用算法
如果数据有百万个特征,可以使用随机梯度下降和小批量梯度下降。如果训练集适合容纳于内存,可以使用批量梯度下降;但是不能使用标准方程法和SVD方法,因为随着特征数量的增加,复杂度会指数级增长。
2. 受到影响的算法
如果训练集的特征具有不同的尺寸比例,则成本函数有细长碗的形状,梯度下降收敛的时间很长。因此需要在训练前缩放数据,其中标准方程和SVD方法不需要缩放即可正常工作。此外如果特征没有按比例缩放,正则化模型会收敛至次优解:由于正则化会惩罚较大的权重,因此与具有较大值的特征相比,具有较小值的特征往往会被忽略。
3. 是否卡在局部最小值
不会,因为成本函数是凸函数。
4. 是否得到相同的模型
如果优化问题是凸的,并假设学习率不是太高,那么所有梯度下降算法都将接近群居最优解产生相似的模型,但是除非逐步降低学习率,否则永远不会真正收敛,相反会在全局最优值周围跳跃。
5. 验证错误上升的原因
学习率过高,且算法在发散。如果训练错误也增加了,那么应该降低学习率;如果训练错误没有增加,则已经过拟合。
6. 是否立即停止小批量梯度下降
可能在在达到最优值之前就停止,更好的选择是定时保存模型,当其长时间没有改善时,恢复到最佳的模型。
7. 哪种梯度下降算法
随机梯度下降具有最快的训练迭代速度,通常是第一个达到全局最优解附近的算法。但在给足训练时间的情况下,实际上只有批量梯度下降会收敛。随机梯度下降和小批量梯度下降会在最优值附近反弹,除非降低学习率。
8. 解决问题的三种方法
如果验证误差远高于训练误差。可能是因为模型过拟合。可以降低多项式阶数:较小的自由度的模型不太可能拟合。可以降低多项式阶数:因为较小自由度的模型不太可能过拟合;另一种方式是正则化。
9. 使用岭回归
说明模型很可能欠拟合数据集,有很高的偏差,应该减小正则化超参数a。
10. 为什么要使用
(a)正则化模型要比没有正则化的模型好,因此通常优先选择岭回归
(b)Lasso回归会导致权重降低为0,成为稀疏模型。如果在不确定特征是否有用的情况下,优先使用岭回归
(c)Lasso在几个特征强相关或当特征比训练实例更多时可能发生异常,但是缺失增加了额外需要调整的超参数,如果希望Lasso没有不稳定的行为,使用l1_ratio→1的弹性网络
11. 图片分类
因为他们不是排他的类,所以需要训练两个逻辑回归分类器。
12. 实现提前停止
用Softmax回归进行批量梯度下降训练,实现提前停止法(不使用Scikit-Learn)。
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
# 引入鸢尾花数据集
iris = datasets.load_iris()
X = iris["data"][:,(2,3)]
y = iris["target"]
# 为每个实例增加偏置项
X_with_bias = np.c_[np.ones([len(X), 1]), X]
# 设置随机的种子
np.random.seed(42)
# 分割数据集
test_ratio = 0.2
validation_ratio = 0.2
total_size = len(X_with_bias)
test_size = int(total_size * test_ratio)
validation_size = int(total_size * validation_ratio)
train_size = total_size - test_size - validation_size
rnd_indices = np.random.permutation(total_size)
X_train = X_with_bias[rnd_indices[:train_size]]
y_train = y[rnd_indices[:train_size]]
X_valid = X_with_bias[rnd_indices[train_size:-test_size]]
y_valid = y[rnd_indices[train_size:-test_size]]
X_test = X_with_bias[rnd_indices[-test_size:]]
y_test = y[rnd_indices[-test_size:]]
# 转化为喊onehot向量的矩阵
def to_one_hot(y):
n_classes = y.max()+1
m = len(y)
Y_one_hot = np.zeros((m, n_classes))
Y_one_hot[np.arange(m), y]=1
return Y_one_hot
Y_train_one_hot = to_one_hot(y_train)
Y_valid_one_hot = to_one_hot(y_valid)
Y_test_one_hot = to_one_hot(y_test)
# 实现softmax函数
def softmax(logits):
exps = np.exp(logits)
exp_sums = np.sum(exps, axis=1, keepdims=True)
return exps / exp_sums
n_inputs = X_train.shape[1]
n_outputs = len(np.unique(y_train))
# 用python代码模拟出数学公式
# 添加正则化
# 实现提前停止
eta = 0.1
n_iterations = 5001
m = len(X_train)
epsilon = 1e-7
alpha = 0.1 # regularization hyperparameter
best_loss = np.infty
Theta = np.random.randn(n_inputs, n_outputs)
for iteration in range(n_iterations):
logits = X_train.dot(Theta)
Y_proba = softmax(logits)
error = Y_proba - Y_train_one_hot
gradients = 1/m * X_train.T.dot(error) + np.r_[np.zeros([1, n_outputs]), alpha * Theta[1:]]
Theta = Theta - eta * gradients
logits = X_valid.dot(Theta)
Y_proba = softmax(logits)
xentropy_loss = -np.mean(np.sum(Y_valid_one_hot * np.log(Y_proba + epsilon), axis=1))
l2_loss = 1/2 * np.sum(np.square(Theta[1:]))
loss = xentropy_loss + alpha * l2_loss
if iteration % 500 == 0:
print(iteration, loss)
if loss < best_loss:
best_loss = loss
else:
print(iteration - 1, best_loss)
print(iteration, loss, "early stopping!")
break
# 输出模型参数
print(Theta)
# 对验证集做预测并检查准确性
logits = X_valid.dot(Theta)
Y_proba = softmax(logits)
y_predict = np.argmax(Y_proba, axis=1)
accuracy_score = np.mean(y_predict == y_valid)
print('验证集精确度', accuracy_score)
# 对测试集做预测并检查准确性
logits = X_test.dot(Theta)
Y_proba = softmax(logits)
y_predict = np.argmax(Y_proba, axis=1)
accuracy_score = np.mean(y_predict == y_test)
print('测试集机精确度',accuracy_score)
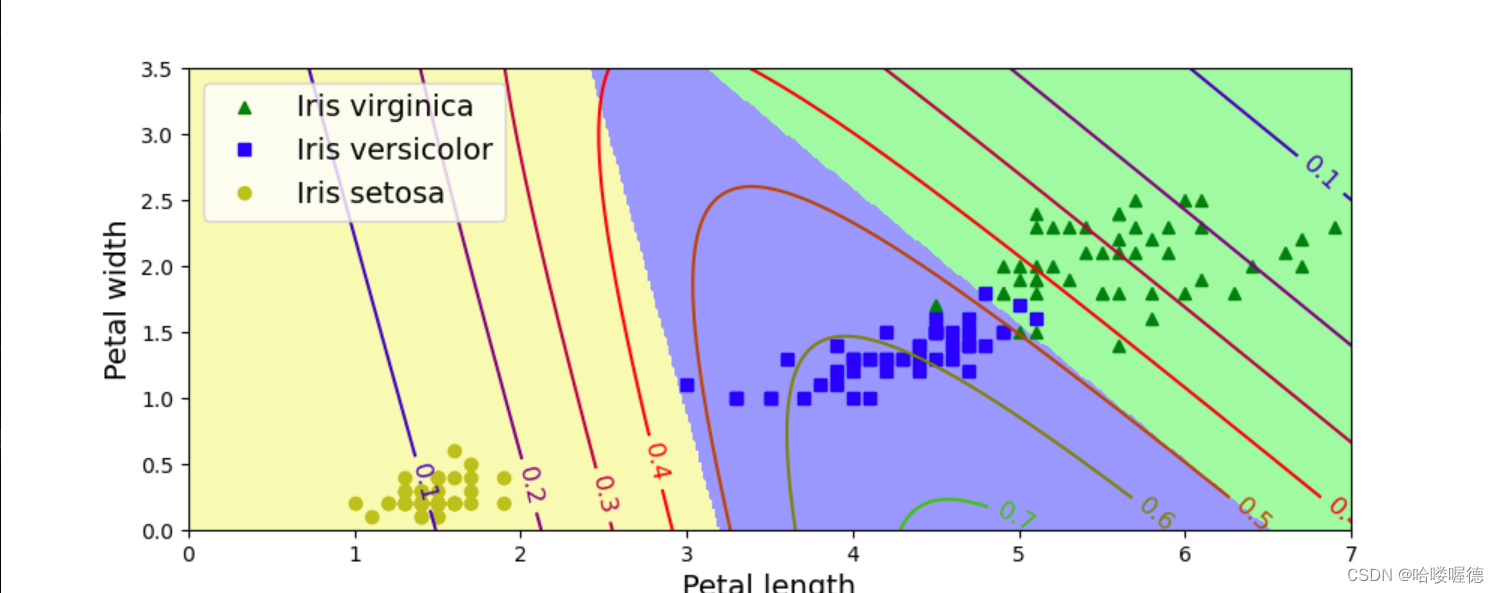
# 绘制模型预测图
x0, x1 = np.meshgrid(
np.linspace(0, 8, 500).reshape(-1, 1),
np.linspace(0, 3.5, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
X_new_with_bias = np.c_[np.ones([len(X_new), 1]), X_new]
logits = X_new_with_bias.dot(Theta)
Y_proba = softmax(logits)
y_predict = np.argmax(Y_proba, axis=1)
zz1 = Y_proba[:, 1].reshape(x0.shape)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
plt.plot(X[y==2, 0], X[y==2, 1], "g^", label="Iris virginica")
plt.plot(X[y==1, 0], X[y==1, 1], "bs", label="Iris versicolor")
plt.plot(X[y==0, 0], X[y==0, 1], "yo", label="Iris setosa")
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
contour = plt.contour(x0, x1, zz1, cmap=plt.cm.brg)
plt.clabel(contour, inline=1, fontsize=12)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="upper left", fontsize=14)
plt.axis([0, 7, 0, 3.5])
plt.show()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









