






 优势函数在强化学习中衡量特定动作相对于当前策略的平均收益。它通过Q(s,a)和V(s)定义,帮助策略梯度算法如REINFORCE、PPO、TRPO精确调整动作选择。正值表示优于平均,负值表示较差。
优势函数在强化学习中衡量特定动作相对于当前策略的平均收益。它通过Q(s,a)和V(s)定义,帮助策略梯度算法如REINFORCE、PPO、TRPO精确调整动作选择。正值表示优于平均,负值表示较差。
优势函数(Advantage Function)在强化学习中是一个衡量在给定状态下执行某个动作相比按照当前策略执行任意动作平均而言有多大的优势的概念。它量化了执行某个特定动作相比“基准”行为的额外好处或损失。
具体来说,优势函数 A(s,a) 定义为:
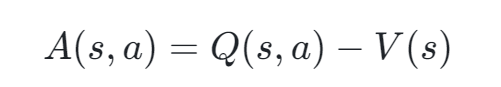
其中:
- Q(s,a) 是动作值函数(Action-Value Function),表示在状态 s 下执行动作 a 后获得的未来期望累积奖励。
- V(s) 是状态值函数(State-Value Function),表示在状态 s 下,按照当前策略行动所能期待的平均累积奖励,不考虑具体采取哪个动作。
这样一来,优势函数 A(s,a) 描述了在状态 s 下执行动作 a 相对于仅按照当前策略行动的平均收益而言的增益或亏损。如果 A(s,a)>0,说明执行动作 a 相比于当前策略的平均表现更有利;反之,如果 A(s,a)<0,则表明执行该动作不如当前策略的平均表现。
在强化学习算法中,特别是那些基于策略梯度的方法(如REINFORCE、PPO、TRPO等),优势函数是一个非常重要的工具,因为它可以帮助算法更精确地定位应该优先改进哪些动作的选择,从而优化策略。
通过优势函数,我们可以区分出在当前状态下执行某个动作是否优于当前策略的平均表现。
如果优势函数的值为正,则说明执行该动作比当前策略的平均水平更好;如果为负,则说明执行该动作相对较差。优势函数在策略梯度方法中扮演着重要角色,因为它可以帮助算法更准确地识别出哪些动作应当被鼓励,哪些动作应当被抑制,从而更有效地优化策略。















 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









