







Python 爬虫验证码识别
免责声明:自本文章发布起, 本文章仅供参考,不得转载,不得复制等操作。浏览本文章的当事人如涉及到任何违反国家法律法规造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。以及由于浏览本文章的当事人转载,复制等操作涉及到任何违反国家法律法规引起的纠纷和造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。
1. 百度智能云
我用的是百度智能云, 云打码平台估计已无几人在用.
https://cloud.baidu.com/
进行登录和注册.
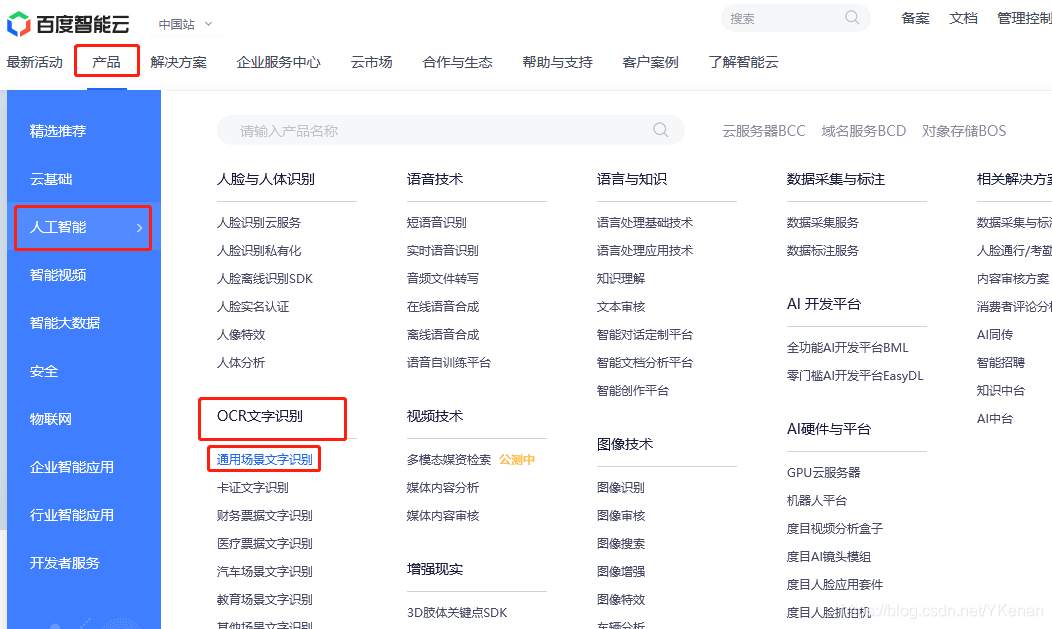
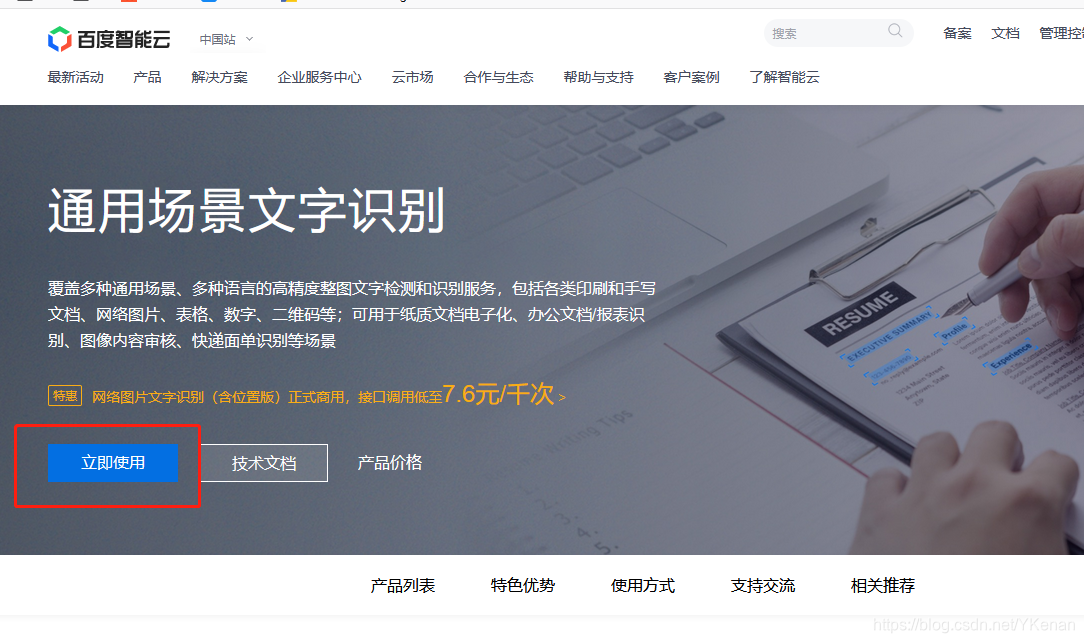
开始用都是免费的, 对于仅供学习 OCR 文字识别够用的.
尝试了三个, 各有利弊.
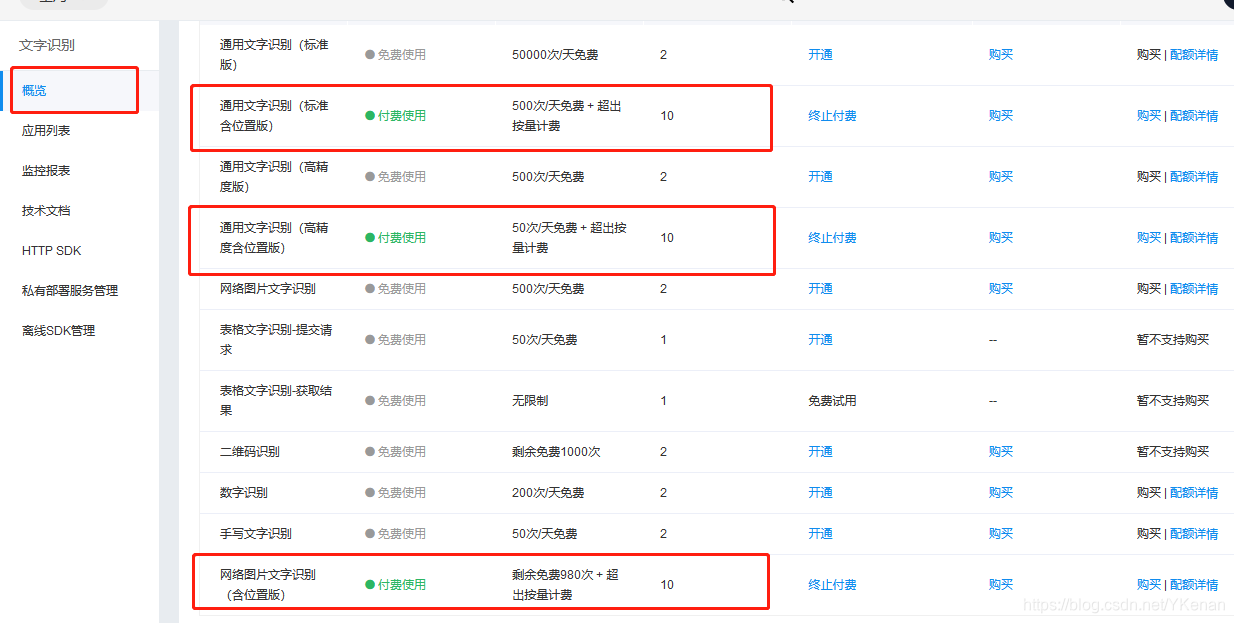
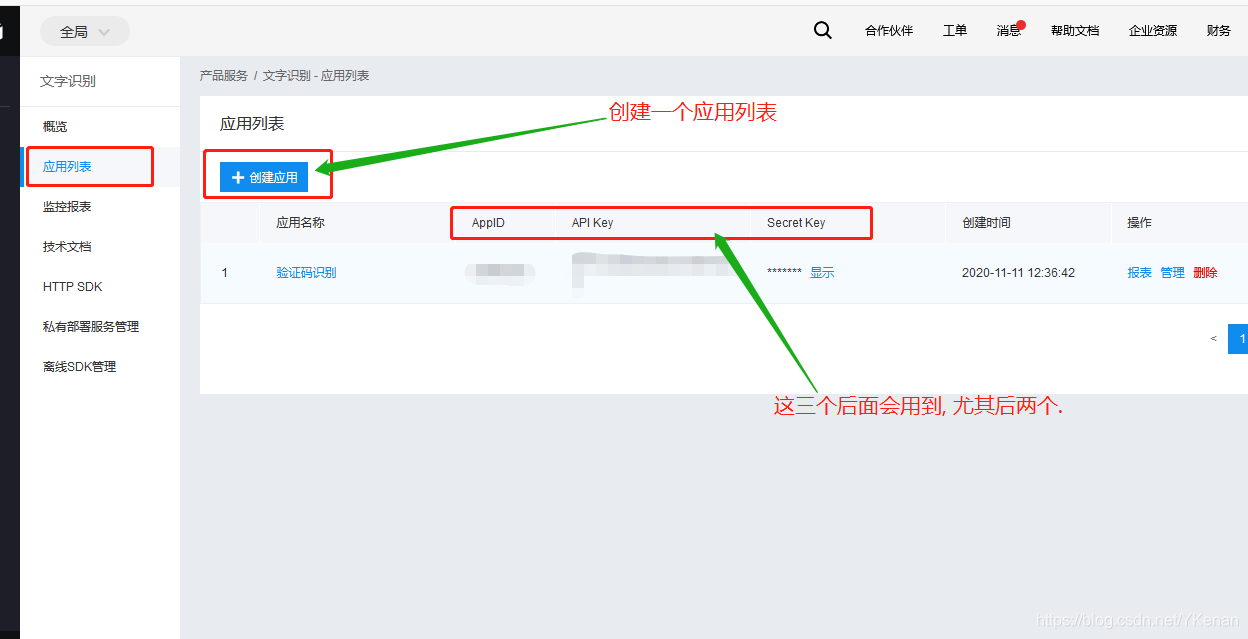
2. 使用
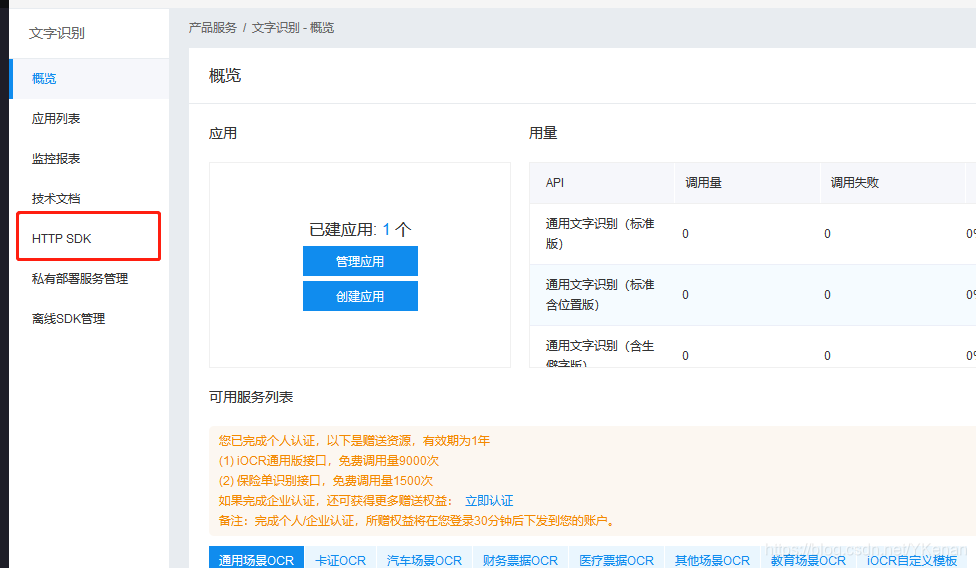
两个使用, SDK 支持多种语言.
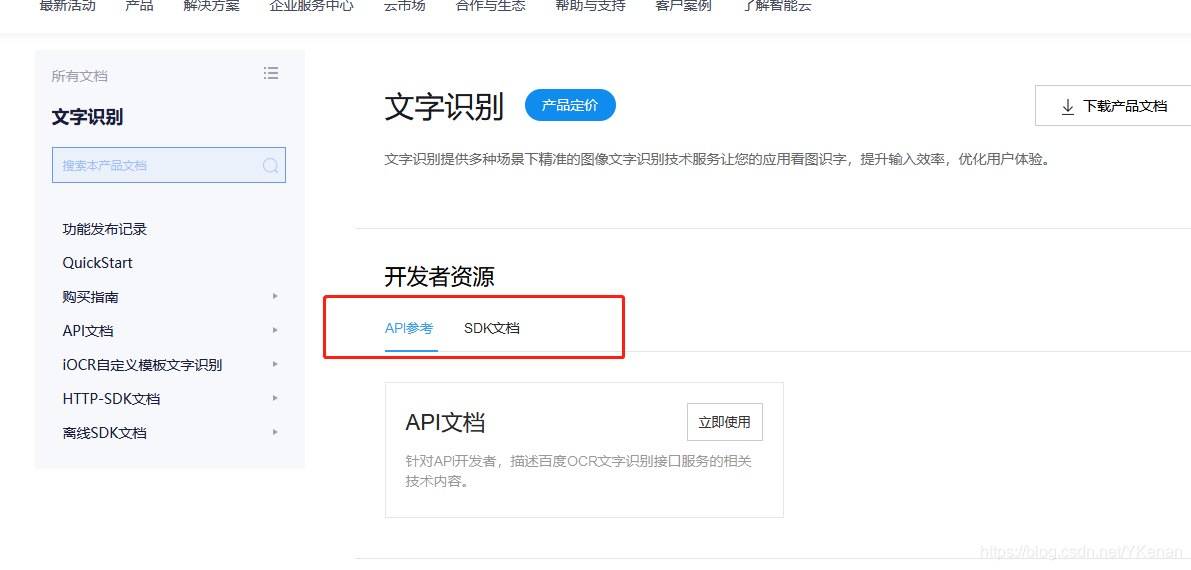
2.1 API 文档使用
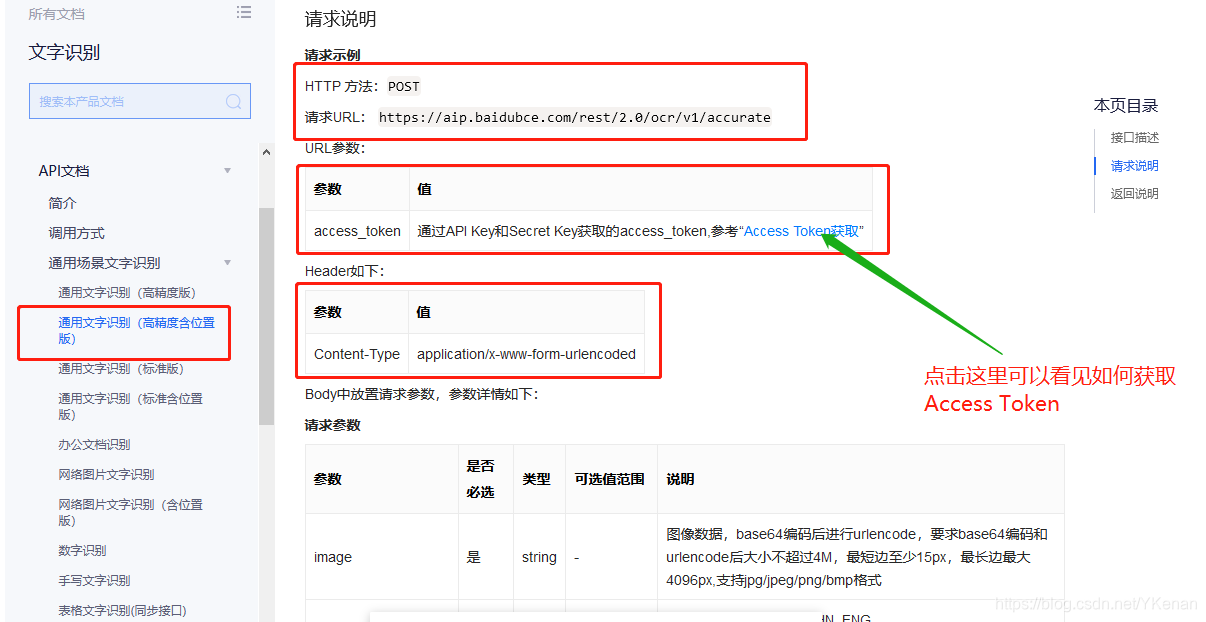
跳转到 Access Token获取 的连接中.
下面有关于 Python 的使用方法.
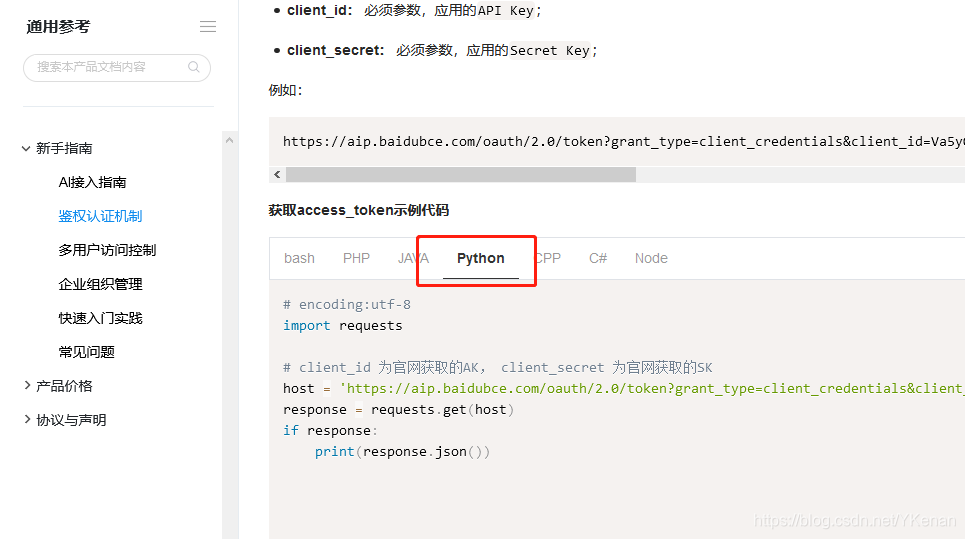
通过官方文档总结了一个:
下面的为ocr.py文件.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
import base64
'''
百度 ocr 提供了模板
验证码识别
'''
# 得到 access_token
def get_access_token(client_id, client_secret):
# client_id 为官网获取的 AK, client_secret 为官网获取的 SK.
host = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={client_id}&client_secret={client_secret}'
response = requests.get(host)
if response:
print(response.json())
return response.json()["access_token"]
'''
client_id: API Key
client_secret: Secret Key
url_img: 照片的 URl
type_: 选择识别的方式, 默认为 webimage_loc.
- general: 通用文字识别(标准含位置版)
- accurate: 通用文字识别(高精度含位置版)
- webimage_loc: 网络图片文字识别(含位置版)
'''
# 得到结果
def baidu_OCR(client_id, client_secret, url_img, type_="webimage_loc"):
request_url = f"https://aip.baidubce.com/rest/2.0/ocr/v1/{type_}"
# url
request_url = request_url + "?access_token=" + get_access_token(client_id, client_secret)
# 图片文件的二进制形式
b_img = requests.get(url_img).content
# b_img = open('./data/4.png', 'rb').read()
img = base64.b64encode(b_img)
# 参数
params = {
"image": img
}
headers = {
'content-type': 'application/x-www-form-urlencoded'
}
# 请求
response = requests.post(request_url, data=params, headers=headers)
# 返回结果
if response:
print(response.json())
return response.json()["words_result"][0]["words"]
引用上面的方法
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import ocr
if __name__ == '__main__':
# API Key
client_id = "client_id"
# Secret Key
client_secret = "client_secret"
# 照片的路径
url_img = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1605085260223&di=f3ac8274fc8d8aa5830cfdd0e75e5586&imgtype=0&src=http%3A%2F%2Fimg3.itboth.com%2F11%2F96%2FM3Enmm.jpg"
# 输出识别后的结果
# print(baidu_OCR(client_id, client_secret, url_img))
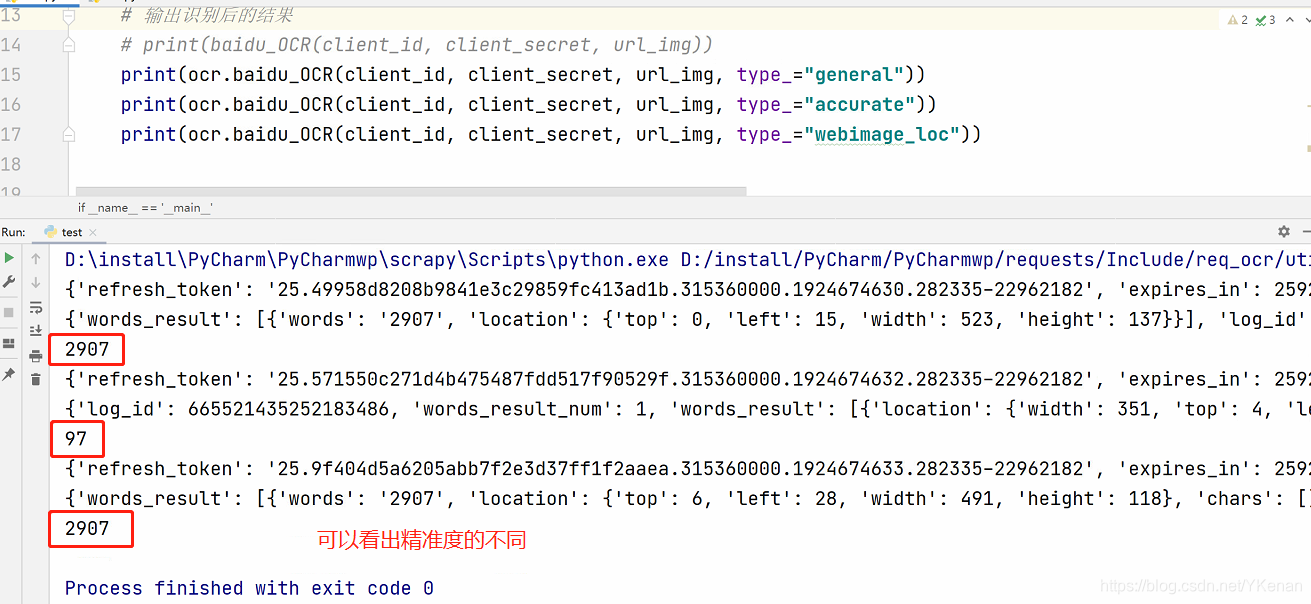
print(ocr.baidu_OCR(client_id, client_secret, url_img, type_="general"))
print(ocr.baidu_OCR(client_id, client_secret, url_img, type_="accurate"))
print(ocr.baidu_OCR(client_id, client_secret, url_img, type_="webimage_loc"))
2.2 SDK 文档使用
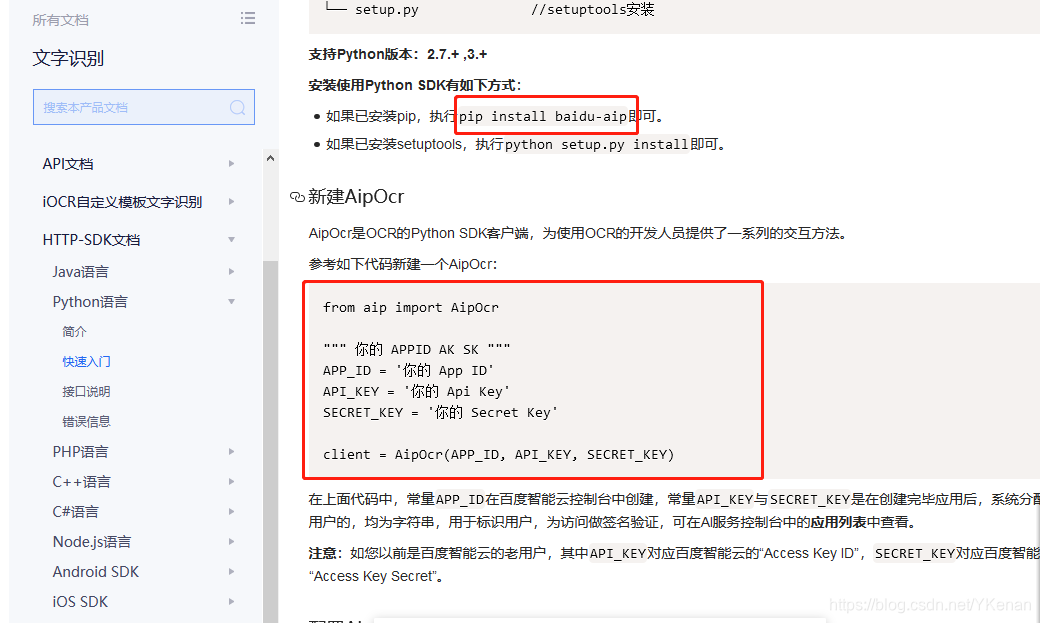
在 PyCharm 下直接安装完
baidu-aip即可.
下面就有使用方法.
按照文档:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
from aip import AipOcr
'''
调用百度 ocr 接口
验证码识别
'''
# 读取图片
def get_file_content(url_img):
# 图片文件的二进制形式
return requests.get(url_img).content
if __name__ == '__main__':
""" 你的 APPID AK SK """
APP_ID = 'APP_ID'
API_KEY = 'API_KEY'
SECRET_KEY = 'SECRET_KEY'
# SDK客户端
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 照片连接
url_img = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1605085260223&di=f3ac8274fc8d8aa5830cfdd0e75e5586&imgtype=0&src=http%3A%2F%2Fimg3.itboth.com%2F11%2F96%2FM3Enmm.jpg"
# 读取图片
image = get_file_content(url_img)
# 如果有可选参数
options = {
"recognize_granularity": "big",
"detect_direction": "true",
"vertexes_location": "true",
"probability": "true"
}
# 调用通用文字识别(含位置信息版), 图片参数为远程 url 图片
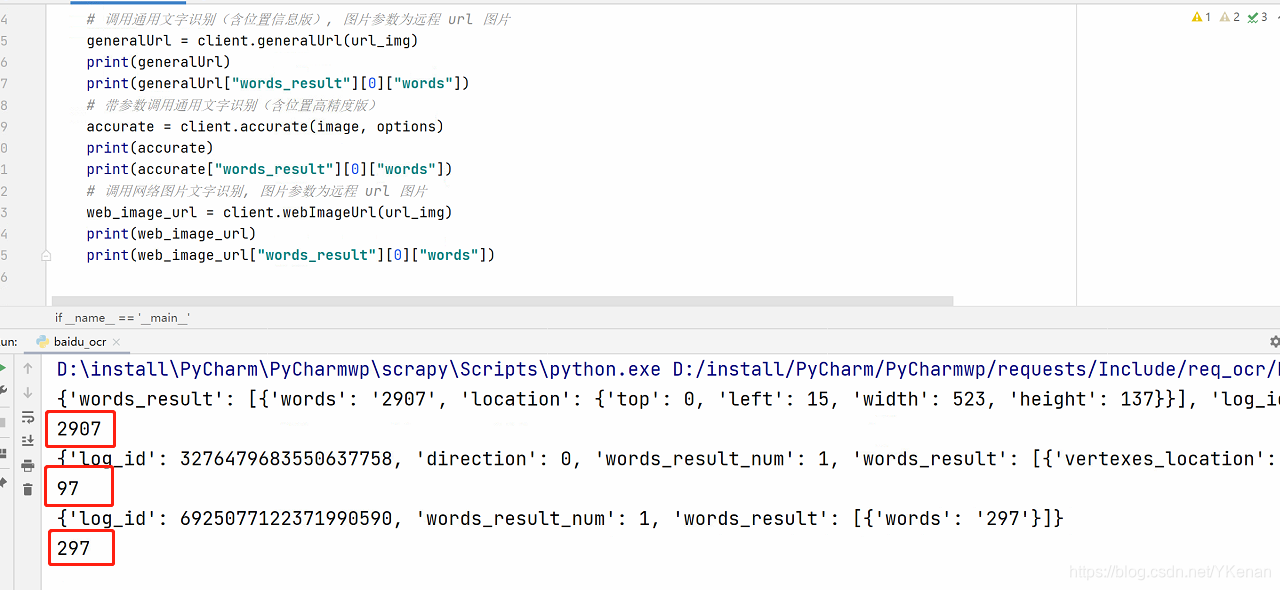
generalUrl = client.generalUrl(url_img)
print(generalUrl)
print(generalUrl["words_result"][0]["words"])
# 带参数调用通用文字识别(含位置高精度版)
accurate = client.accurate(image, options)
print(accurate)
print(accurate["words_result"][0]["words"])
# 调用网络图片文字识别, 图片参数为远程 url 图片
web_image_url = client.webImageUrl(url_img)
print(web_image_url)
print(web_image_url["words_result"][0]["words"])
3. 获取古诗文网验证码
古诗文网
https://so.gushiwen.cn/user/login.aspx
这里只获取验证码, 登录在后面.
需要 gif 转 png 格式, 需要安装 pillow
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
from lxml import etree
from aip import AipOcr
from PIL import Image
# gif 转化为 png
def gif_png(img_path, img_name):
im = Image.open(img_path)
# gif 转化为 png
def iter_frames(image):
try:
j = 0
while 1:
image.seek(j)
image_frame = image.copy()
palette = image_frame.getpalette()
if j > 0:
image_frame.putpalette(palette)
yield image_frame
j += 1
except EOFError:
pass
for i, frame in enumerate(iter_frames(im)):
frame.save(img_name, **frame.info)
# 读取文件
def get_file_content(file_path):
with open(file_path, 'rb') as fp:
return fp.read()
# 得到验证码
def getCode(url_image):
# 保存照片
with open("./data/login.gif", 'wb') as f:
f.write(requests.get(url_image).content)
""" 你的 APPID AK SK """
APP_ID = 'APP_ID'
API_KEY = 'API_KEY'
SECRET_KEY = 'SECRET_KEY'
# SDK客户端
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 转化
gif_png("./data/login.gif", "./data/login.png")
url_content = get_file_content("./data/login.png")
# 调用通用文字识别(含位置信息版)
general_url = client.general(url_content)
return general_url["words_result"][0]["words"]
if __name__ == '__main__':
# url, UA
url = "https://so.gushiwen.cn/user/login.aspx"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
# 爬取
text = requests.get(url=url, headers=headers).text
# 解析
tree = etree.HTML(text, etree.HTMLParser(encoding="utf-8"))
# 得到照片 url
url_img = "https://so.gushiwen.cn" + tree.xpath("//img[@id='imgCode']/@src")[0]
# 得到验证码
login_code = getCode(url_img)
print(login_code)
效果如下, 个人感觉精度不算太高, 但免费的也可以了.
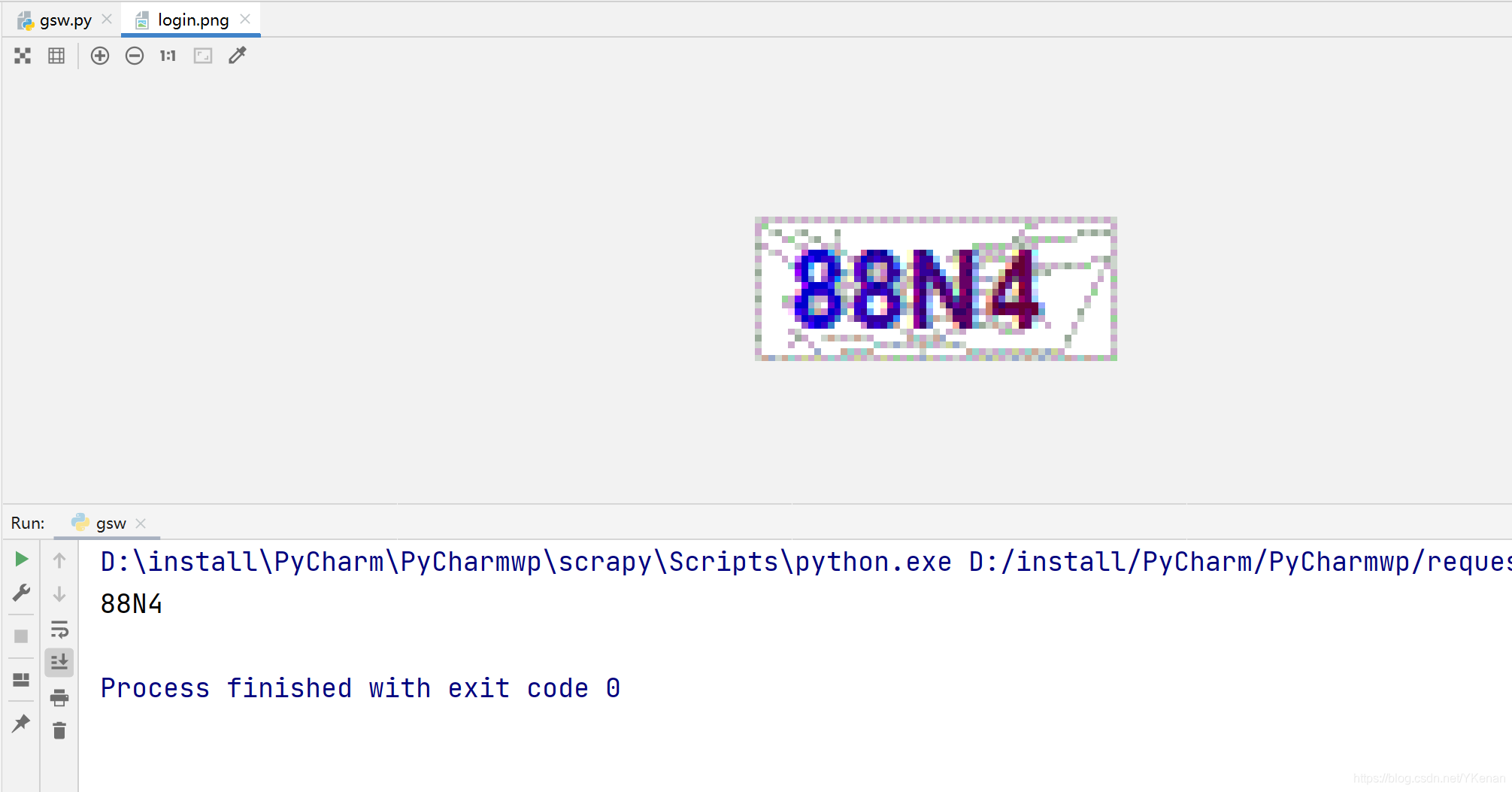














 7202
7202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









