







一、项目介绍
1.1 项目背景
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。本数据集包(UserBehavior.csv)含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。
1.2 分析目的
本次分析的目的是通过对淘宝用户行为进行数据分析,为以下问题提供提供解释和改进建议:
①分析用户在淘宝使用过程常见的电商分析指标,并建立用户转化漏斗模型,确定各个环节的流失率,寻找需要优化的环节。
②分析用户在不同时间维度下的行为,找到用户在不同时间周期下的活动规律,并推出相应的活动策略。
③找到用户的商品偏好,针对不同商品找到对应的营销策略。
④通过RFM模型对用户进行分层,对不同类型的用户行为进行分析,并提出相应的运营策略。
1.3 数据来源
数据来源:淘宝用户购物行为数据集_数据集-阿里云天池
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。
 UserBehavior.csv
UserBehavior.csv
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
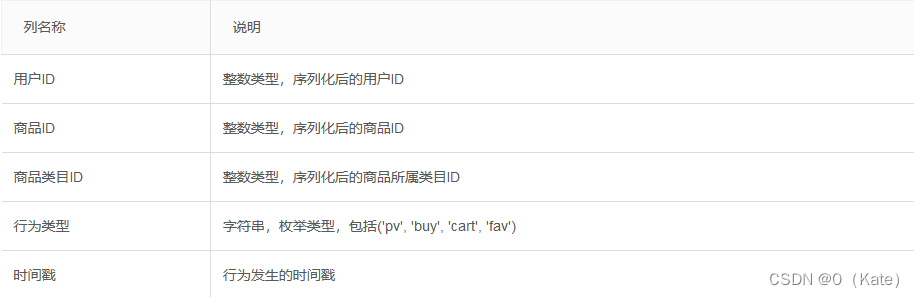 注意到,用户行为类型共有四种,它们分别是
注意到,用户行为类型共有四种,它们分别是
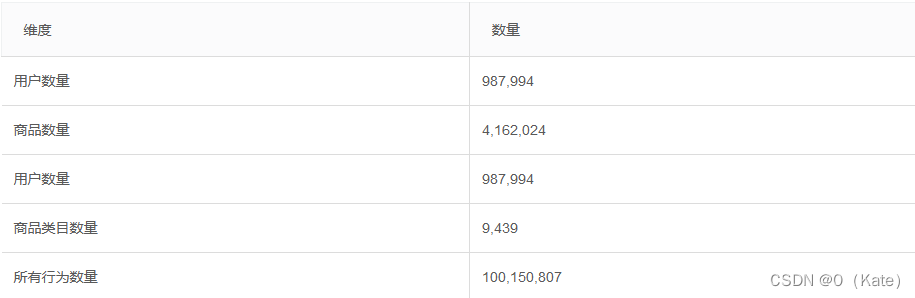
 关于数据集大小的一些说明如下
关于数据集大小的一些说明如下
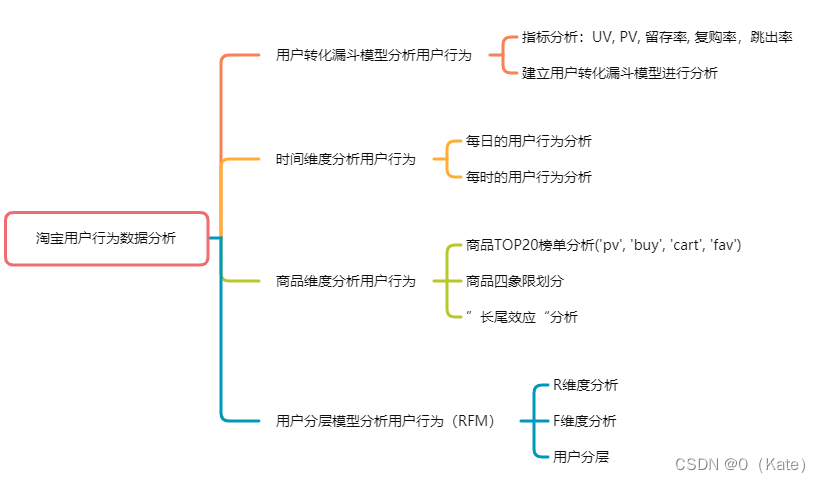
 二、分析框
二、分析框
 三、数据清洗
三、数据清洗
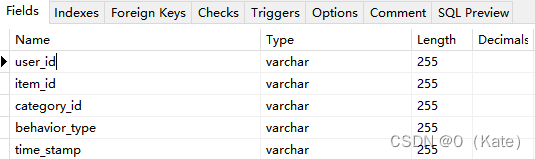
3.1 导入数据,修改表字段
源数据表字段不明确,修改其名称,同时修改对应数据类型:user_id, item_id, category_id, behavior_type, time_stamp
3.2 去除重复值
将各字段‘不是null’打钩,并选定userID,itemID,timestamps作为主键。
这一步可以确保表格中没有空值与重复值。

结果显示没有重复值。
3.3 查找缺失值

对比查询结果,无缺失值,数据集数据质量较高。
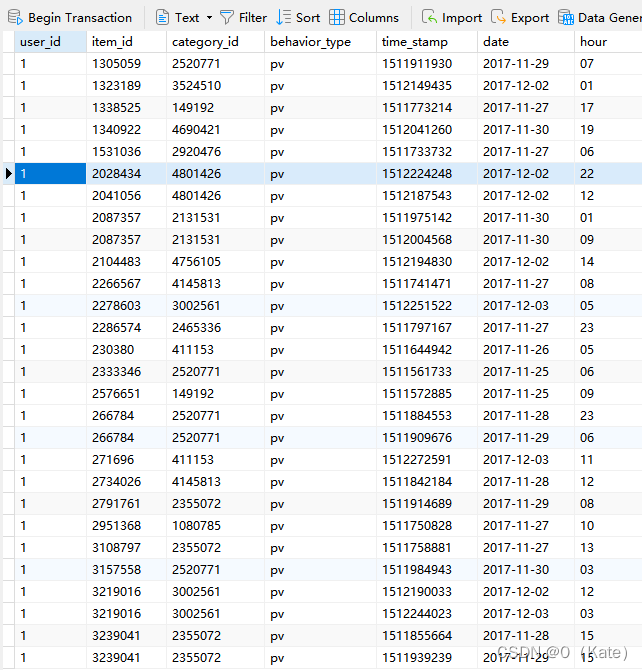
3.4 转换时间格式

3.5 过滤异常值
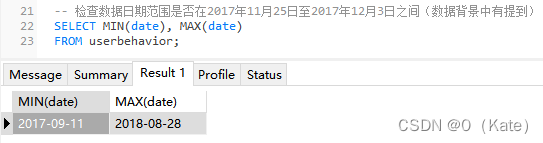
剔除异常值
 共剔除511条异常值
共剔除511条异常值
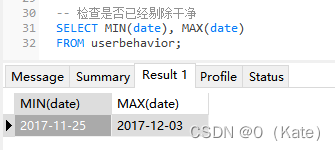
然后再检查一遍看数据是否已经剔除干净
四、数据分析
4.1 基于用户行为漏斗模型分析用户行为
4.1.1 了解用户行为整体情况
4.1.1.1 常见数据指标统计
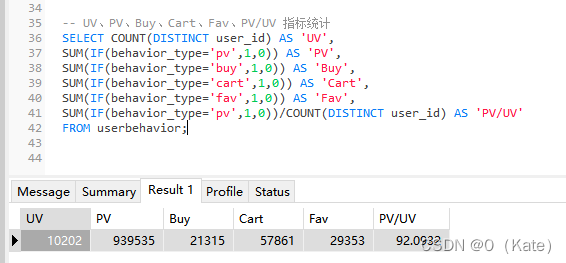
独立访客总数(UV):10202
页面总访问量(PV):939535
统计区间平均每人页面访问量(PV/UV):约为92
4.1.1.2 留存率
① 用户次日、3日、5日、7日留存人数
首先查询第一日活跃用户数,同时建立一个新表用来存放留存数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









