







1、第一层:数据层
layers {
name: "mnist"
type: DATA
data_param {
source: "mnist_train_lmdb"
backend: LMDB
batch_size: 64
scale: 0.00390625
}
top: "data"
top: "label"
}
2、第二层:卷积层
layers {
name: "conv1"
type: CONVOLUTION
blobs_lr: 1.
blobs_lr: 2.
convolution_param {
num_output: 20
kernelsize: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "data"
top: "conv1"
}这里的type就是CONVOLUTION了(好像type指定的属性都是大写的)。blobs_lr: 1. 就是指定weight的学习率的倍数,这里就是1.0了,后面的blobs_lr: 2. 就是指定bias学习率的倍数。num_output指定输出数据个数,kernelsize是指定卷积模板的大小,也就卷积核的矩阵大小。stride就是指定卷积的步长。weight_filler是指定weight初始化,其中type是指定初始化的方式,这里用的是xavier 算法(根据输入输出的神经元个数自动决定初始化的尺度)。下面的bias_filler是类似的,constant就是说指定为常数了,默认为0.然后bottom就是指定这一层的输入数据,显然就是数据层传来的那个data,top就是输出数据。
为什么这一层只有一个bottom,但是上一层的top 有两个呢?label跑哪儿去了?,继续往下看你就明白了。
3、pooling 层
layers {
name: "pool1"
type: POOLING
pooling_param {
kernel_size: 2
stride: 2
pool: MAX
}
bottom: "conv1"
top: "pool1"
}这里出现的新参数就是那个pool了。pooling_param就是设置这个pooling层的参数啦,pool的方式就是max pooling。值得一提的是这里的kernel_size和stride的设置,这里恰好就相等,所以所有的pooling都不会出现重叠,一般来说,kernel_size的尺寸不小于stride的。
4、中间可以多添加几个卷积、pool层
5、完全连接层
layers {
name: "ip1"
type: INNER_PRODUCT
blobs_lr: 1.
blobs_lr: 2.
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "pool2"
top: "ip1"
}
6、ReLU层
layers {
name: "relu1"
type: RELU
bottom: "ip1"
top: "ip1"
}
7、完全连接层
layers {
name: "ip2"
type: INNER_PRODUCT
blobs_lr: 1.
blobs_lr: 2.
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "ip1"
top: "ip2"
}
layers {
name: "loss"
type: SOFTMAX_LOSS
bottom: "ip2"
bottom: "label"
}
时间不早了,差不多模型建立就写这么多吧。希望大家积极留言,多多交流,共同进步。如果发现错误,一定要指出来哦!
———————————————————————2015. 2. 6更新————————————————————————————————
有个地方忘了说,就是在layer里面有个include参数,其中的phase参数是指定这一层是什么时候运行的,可以选择TRAIN,表示训练的时候运行,也可以选择TEST。
Caffe官网的说明文档
1. Vision Layers
1.1 卷积层(Convolution)
类型:CONVOLUTION
例子
layers { name: "conv1" type: CONVOLUTION bottom: "data" top: "conv1" blobs_lr: 1 # learning rate multiplier for the filters blobs_lr: 2 # learning rate multiplier for the biases weight_decay: 1 # weight decay multiplier for the filters weight_decay: 0 # weight decay multiplier for the biases convolution_param { num_output: 96 # learn 96 filters kernel_size: 11 # each filter is 11x11 stride: 4 # step 4 pixels between each filter application weight_filler { type: "gaussian" # initialize the filters from a Gaussian std: 0.01 # distribution with stdev 0.01 (default mean: 0) } bias_filler { type: "constant" # initialize the biases to zero (0) value: 0 } }}
blobs_lr: 学习率调整的参数,在上面的例子中设置权重学习率和运行中求解器给出的学习率一样,同时是偏置学习率为权重的两倍。
weight_decay:
卷积层的重要参数
必须参数:
num_output (c_o):过滤器的个数
kernel_size (or kernel_h and kernel_w):过滤器的大小
可选参数:
weight_filler [default type: 'constant' value: 0]:参数的初始化方法
bias_filler:偏置的初始化方法
bias_term [default true]:指定是否是否开启偏置项
pad (or pad_h and pad_w) [default 0]:指定在输入的每一边加上多少个像素
stride (or stride_h and stride_w) [default 1]:指定过滤器的步长
group (g) [default 1]: If g > 1, we restrict the connectivityof each filter to a subset of the input. Specifically, the input and outputchannels are separated into g groups, and the ith output group channels will beonly connected to the ith input group channels.
通过卷积后的大小变化:
输入:n * c_i * h_i * w_i
输出:n * c_o * h_o * w_o,其中h_o = (h_i + 2 * pad_h - kernel_h) /stride_h + 1,w_o通过同样的方法计算。
1.2 池化层(Pooling)
类型:POOLING
例子
layers { name: "pool1" type: POOLING bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 # pool over a 3x3 region stride: 2 # step two pixels (in the bottom blob) between pooling regions }}卷积层的重要参数
必需参数:
kernel_size (or kernel_h and kernel_w):过滤器的大小
可选参数:
pool [default MAX]:pooling的方法,目前有MAX, AVE, 和STOCHASTIC三种方法
pad (or pad_h and pad_w) [default 0]:指定在输入的每一遍加上多少个像素
stride (or stride_h and stride_w) [default1]:指定过滤器的步长
通过池化后的大小变化:
输入:n * c_i * h_i * w_i
输出:n * c_o * h_o * w_o,其中h_o = (h_i + 2 * pad_h - kernel_h) /stride_h + 1,w_o通过同样的方法计算。
1.3 Local Response Normalization (LRN)
类型:LRN
Local ResponseNormalization是对一个局部的输入区域进行的归一化(激活a被加一个归一化权重(分母部分)生成了新的激活b),有两种不同的形式,一种的输入区域为相邻的channels(cross channel LRN),另一种是为同一个channel内的空间区域(within channel LRN)
计算公式:对每一个输入除以
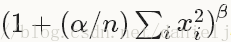
可选参数:
local_size [default 5]:对于cross channel LRN为需要求和的邻近channel的数量;对于within channel LRN为需要求和的空间区域的边长
alpha [default 1]:scaling参数
beta [default 5]:指数
norm_region [default ACROSS_CHANNELS]: 选择哪种LRN的方法ACROSS_CHANNELS 或者WITHIN_CHANNEL
2. Loss Layers
深度学习是通过最小化输出和目标的Loss来驱动学习。
2.1 Softmax
类型: SOFTMAX_LOSS2.2 Sum-of-Squares / Euclidean
类型: EUCLIDEAN_LOSS
2.3 Hinge / Margin
类型: HINGE_LOSS例子:
# L1 Normlayers { name: "loss" type: HINGE_LOSS bottom: "pred" bottom: "label"}# L2 Normlayers { name: "loss" type: HINGE_LOSS bottom: "pred" bottom: "label" top: "loss" hinge_loss_param { norm: L2 }}
可选参数:
norm [default L1]: 选择L1或者 L2范数
输入:
n * c * h * wPredictions
n * 1 * 1 * 1Labels
输出
1 * 1 * 1 * 1Computed Loss
2.4 Sigmoid Cross-Entropy
类型:SIGMOID_CROSS_ENTROPY_LOSS2.5 Infogain
类型:INFOGAIN_LOSS2.6 Accuracy and Top-k
类型:ACCURACY 用来计算输出和目标的正确率,事实上这不是一个loss,而且没有backward这一步。
3. 激励层(Activation / Neuron Layers)
一般来说,激励层是element-wise的操作,输入和输出的大小相同,一般情况下就是一个非线性函数。
3.1 ReLU / Rectified-Linear and Leaky-ReLU
类型: RELU例子:
layers { name: "relu1" type: RELU bottom: "conv1" top: "conv1"}
可选参数:
negative_slope [default 0]:指定输入值小于零时的输出。
ReLU是目前使用做多的激励函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),而一般为当x > 0时输出x,但x <= 0时输出negative_slope。RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3.2 Sigmoid
类型: SIGMOID例子:
layers { name: "encode1neuron" bottom: "encode1" top: "encode1neuron" type: SIGMOID}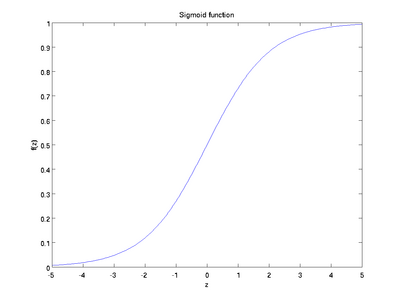
3.3 TanH / Hyperbolic Tangent
类型: TANH例子:
layers { name: "encode1neuron" bottom: "encode1" top: "encode1neuron" type: SIGMOID}
TANH层通过 tanh(x) 计算每一个输入x的输出,函数如下图。
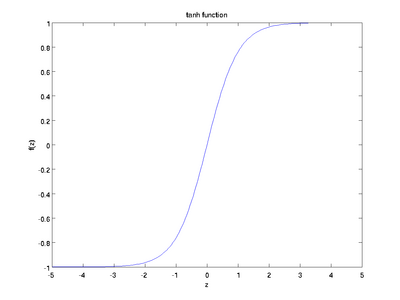
3.3 Absolute Value
类型: ABSVAL例子:
layers { name: "layer" bottom: "in" top: "out" type: ABSVAL}
3.4 Power
类型: POWER例子:
layers { name: "layer" bottom: "in" top: "out" type: POWER power_param { power: 1 scale: 1 shift: 0 }}POWER层通过 (shift + scale * x) ^ power计算每一个输入x的输出。
3.5 BNLL
类型: BNLL例子:
layers { name: "layer" bottom: "in" top: "out" type: BNLL}BNLL (binomial normal log likelihood) 层通过 log(1 + exp(x)) 计算每一个输入x的输出。
4. 数据层(Data Layers)
数据通过数据层进入Caffe,数据层在整个网络的底部。数据可以来自高效的数据库(LevelDB 或者 LMDB),直接来自内存。如果不追求高效性,可以以HDF5或者一般图像的格式从硬盘读取数据。
4.1 Database
类型:DATA
必须参数:
source:包含数据的目录名称
batch_size:一次处理的输入的数量
可选参数:
rand_skip:在开始的时候从输入中跳过这个数值,这在异步随机梯度下降(SGD)的时候非常有用
backend [default LEVELDB]: 选择使用 LEVELDB 或者 LMDB
4.2 In-Memory
类型: MEMORY_DATA 必需参数: batch_size, channels, height, width: 指定从内存读取数据的大小 The memory data layer reads data directly from memory, without copying it. In order to use it, one must call MemoryDataLayer::Reset (from C++) or Net.set_input_arrays (from Python) in order to specify a source of contiguous data (as 4D row major array), which is read one batch-sized chunk at a time.
4.3 HDF5 Input
类型: HDF5_DATA 必要参数: source:需要读取的文件名batch_size:一次处理的输入的数量
4.4 HDF5 Output
类型: HDF5_OUTPUT 必要参数: file_name: 输出的文件名HDF5的作用和这节中的其他的层不一样,它是把输入的blobs写到硬盘
4.5 Images
类型: IMAGE_DATA 必要参数: source: text文件的名字,每一行给出一张图片的文件名和label batch_size: 一个batch中图片的数量 可选参数: rand_skip: 在开始的时候从输入中跳过这个数值,这在异步随机梯度下降(SGD)的时候非常有用 shuffle [default false]new_height, new_width: 把所有的图像resize到这个大小
4.6 Windows
类型:WINDOW_DATA4.7 Dummy
类型:DUMMY_DATADummy 层用于development 和debugging。具体参数DummyDataParameter。
5. 一般层(Common Layers)
5.1 全连接层Inner Product
类型:INNER_PRODUCT 例子:layers { name: "fc8" type: INNER_PRODUCT blobs_lr: 1 # learning rate multiplier for the filters blobs_lr: 2 # learning rate multiplier for the biases weight_decay: 1 # weight decay multiplier for the filters weight_decay: 0 # weight decay multiplier for the biases inner_product_param { num_output: 1000 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } bottom: "fc7" top: "fc8"}必要参数:
num_output (c_o):过滤器的个数
可选参数:
weight_filler [default type: 'constant' value: 0]:参数的初始化方法
bias_filler:偏置的初始化方法
bias_term [default true]:指定是否是否开启偏置项
通过全连接层后的大小变化:
输入:n * c_i * h_i * w_i
输出:n * c_o * 1 *1
5.2 Splitting
类型:SPLIT Splitting层可以把一个输入blob分离成多个输出blobs。这个用在当需要把一个blob输入到多个输出层的时候。5.3 Flattening
类型:FLATTEN Flattening是把一个输入的大小为n * c * h * w变成一个简单的向量,其大小为 n * (c*h*w) * 1 * 1。5.4 Concatenation
类型:CONCAT 例子:layers { name: "concat" bottom: "in1" bottom: "in2" top: "out" type: CONCAT concat_param { concat_dim: 1 }}
可选参数:
concat_dim [default 1]:0代表链接num,1代表链接channels
通过全连接层后的大小变化:
输入:从1到K的每一个blob的大小n_i * c_i * h * w
输出:
如果concat_dim = 0: (n_1 + n_2 + ... + n_K) *c_1 * h * w,需要保证所有输入的c_i 相同。
如果concat_dim = 1: n_1 * (c_1 + c_2 + ... +c_K) * h * w,需要保证所有输入的n_i 相同。
通过Concatenation层,可以把多个的blobs链接成一个blob。
5.5 Slicing
The SLICE layer is a utility layer that slices an input layer to multiple output layers along a given dimension (currently num or channel only) with given slice indices.5.6 Elementwise Operations
类型:ELTWISE5.7 Argmax
类型:ARGMAX5.8 Softmax
类型:SOFTMAX5.9 Mean-Variance Normalization
类型:MVN
本文主要介绍深度学习框架caffe的介绍和入门级使用,以及caffe的python的一些使用说明和注意点,主要参考caffe官方文档。
目录
1、caffe简介
Caffe,全称Convolutional Architecture for Fast Feature Embedding,是一个计算CNN相关算法的框架。caffe是一个清晰,可读性高,快速的深度学习框架。作者是贾扬清,加州大学伯克利的ph.D。
2、模型训练
这里主要介绍caffe训练CNN的模型。官网给了一些入门的例子,以人脸识别数据为例,
2.1、数据准备
首先准备原始的训练数据和验证数据集,采用分类的方式训练CNN。我们的原始数据是按照类别放在一起,即facenet文件下是很多人,每个人一个文件夹,用于存放所以照片。之后处理成如下文件结构如下:
- train/ #存放训练数据
-n01440765/ #每个人一个文件夹
n01440765_1.jpg
...
- val/ #测试数据,放一起即可
n01440764_14.jpg
...
det_synset_words.txt # 存放了原始文件夹名与编码后文件夹名对应关系
synset.txt # 存放了所有的编码后文件夹名字
synset_words.txt # 存放了所有的编码后文件夹名及其对应的原文件夹名
train.txt # 存放训练数据路径以及对应的类别
test.txt # 存放测试数据路径以及对应的类别
val.txt # 存放验证数据路径以及对应的类别这里编码的好处是防止caffe无法识别原始文件名,而且需要把类别处理成整数型的数据。把原始图片处理成caffe待使用的数据。
更新于2015-11-6 增加数据预处理的脚本,数据预处理的主要思路就是把数据整理成你模型需要输入的格式和样式。
# -*- coding:utf-8 -*-
import os
import shutil
import numpy as np
base_dir = 'facedata/' # 原始数据路径
target_dir = 'facenet/' # 目标数据路径
# 把原始的文件名,更改为新的编码,这里可以随机设定
# 我们从n01440764开始计数,共计60000人(至少要大于类别数)
synset = ['n0'+str(1440764 + i) for i in xrange(6000)]
if os.path.exists(target_dir):
pass
else:
os.makedirs(target_dir)
metanames = []
label = -1
for sub_dir in os.listdir(base_dir):
# 如果样本数不足10,那么不记录该类
if len(os.listdir(base_dir + sub_dir)) < 10:
continue
else:
pass
label += 1
for name in os.listdir(base_dir + sub_dir):
metanames.append(str(label)+','+ sub_dir+','+name)
# 输出总的人数(类别数)
print 'number of metanames:', len(metanames), label+1
# 把数据乱序,选80%用于训练,20%用于测试(注意,为了尽可能的多训练数据,我们的val数据和test数据是相同的,其实是不需要一致)
np.random.seed(234)
np.random.shuffle(metanames)
# for train
totle_num = len(metanames)
train_num = int(totle_num*0.8)
test_num = totle_num - train_num
print 'number of metanames:', len(metanames)
print 'number of train:', train_num
f0 = open(target_dir+'train.txt', 'w')
labels = []
det_synset_words = set()
print 'prepare the trainning data...'
for meta in metanames[0:train_num]:
label,sub_dir0,name = meta.strip().split(',')
filename = base_dir + sub_dir0 + '/' + name
sub_dir = synset[int(label)]
det_synset_words.add((sub_dir, sub_dir0))
name = sub_dir + '_' + name.split('_')[1]
targetname = target_dir + 'train/' + sub_dir + '/' + name
if os.path.exists(target_dir + 'train/' + sub_dir):
pass
else:
os.makedirs(target_dir + 'train/' + sub_dir)
f0.write(sub_dir + '/' + name + ' ' + label)
f0.write('\n')
labels.append(label)
shutil.copy(filename, targetname)
f0.close()
# 记录 det_synset_words
f3 = open(target_dir+'det_synset_words.txt', 'w')
f3_2 = open(target_dir+'synset_words.txt', 'w')
det_synset_words = sorted(list(det_synset_words), key=lambda x:x[0])
for i in det_synset_words:
f3.write(' '.join(i) + '\n')
f3_2.write(' '.join(i) + '\n')
f3.close()
f3_2.close()
synset_word = []
for i in set(labels):
synset_word.append(synset[int(i)])
synset_word = sorted(synset_word)
f4 = open(target_dir+'synset.txt', 'w')
f4.write('\n'.join(synset_word))
f4.close()
# 输出实际训练的类别数
print 'num of classes for train: ', len(set(labels))
# 生成测试数据
f1 = open(target_dir+'val.txt','w')
f2 = open(target_dir+'test.txt','w')
if os.path.exists(target_dir + 'val/'):
pass
else:
os.makedirs(target_dir + 'val/')
labels = []
print 'prepare the testing data...'
for meta in metanames[train_num:train_num+test_num]:
label,sub_dir0,name = meta.strip().split(',')
filename = base_dir + sub_dir0 + '/' + name
sub_dir = synset[int(label)]
name = sub_dir + '_' + name.split('_')[1]
# targetname = target_dir + 'val/' + sub_dir + '/' + name
targetname = target_dir + 'val/' + name
f1.write(name + ' ' + label)
f1.write('\n')
f2.write(name + ' ' + '0')
f2.write('\n')
labels.append(label)
shutil.copy(filename, targetname)
f1.close()
f2.close()
print 'num of classes for test: ', len(set(labels))这个脚本主要是配合imagenet做的脚本,实际中有很多文件是不需要写入的。而Imagenet这么做的主要理由是在可视化的时候,可以直接看到name等信息。实际,在某些分类中,可能并不关心label的实际name。
在数据预处理完成之后,我们使用caffe提高的imagenet的数据生成脚creat_imgnet.sh本来生成训练数据,注意在caffe路径下使用sh命令,否则里面的一些引用路径会有报错,需要再配置路径。对于creat_imgnet.sh文件,需要注意路径的配置,这里列出一部分,其他的可以参照这些进行修改。主要如下:
EXAMPLE=facenet/face_256_256_31w_alax # 生成模型训练数据文化夹
TOOLS=build/tools # caffe的工具库,不用变
DATA=/home/face/facenet/ # python脚步处理后数据路径
TRAIN_DATA_ROOT=/home/face/facenet/train/ #待处理的训练数据
VAL_DATA_ROOT=/home/face/facenet/val/ # 带处理的验证数据
RESIZE_HEIGHT=256 # 把数据resize到模型输入需要的大小
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \ # 训练数据文件名
$EXAMPLE/face_train_lmdb # 生成训练数据,使用lmdb存储 之后使用imagenet下的make_imagenet_mean.sh生成均值数据,同样需要注意修改路径,以及在caffe路径下使用sh命令。
这里我们也可以自己写脚本生成caffe需要的格式类型。
更新与2015-11-6:增加levelDB的格式,这里的输入是三张照片,对应的是一个label的。类似于Triplet Loss的输入。注意:这里的三张照片是随机选取的,并没有完整的遍历所有的,而且生成的数量比较少。这个只是例子,需要自己改动来实现自己需要的脚本,比如多label的或者等等。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import division
from __future__ import print_function
import numpy as np
import caffe
import leveldb
import os
def deal_img(fpath):
image = caffe.io.load_image(fpath)
# Reshape image
image = image[:, :, (2, 1, 0)]
image = image.transpose((2, 0, 1))
image = image.astype(np.uint8, copy=False)
return image
def write_levelDB(dbname, images_lists):
db = leveldb.LevelDB(dbname, create_if_missing=True,
error_if_exists=True, write_buffer_size=268435456)
wb = leveldb.WriteBatch()
for count, pic in enumerate(images_lists):
f1, label1 = pic[0], pic[1] # data_pos
f2, label2 = pic[2], pic[3] # data_anc
f3, label3 = pic[4], pic[5] # data_neg
img1 = deal_img(f1)
img2 = deal_img(f2)
img3 = deal_img(f3)
image = np.vstack((img1, img2, img3))
label = label1
# Load image into datum object
db.Put('%08d_%s' % (count, file), datum.SerializeToString())
if count % 1000 == 0:
# Write batch of images to database
db.Write(wb)
del wb
wb = leveldb.WriteBatch()
print('Processed %i images.' % count)
if count % 1000 != 0:
# Write last batch of images
db.Write(wb)
print('Processed a total of %i images.' % count)
else:
print('Processed a total of %i images.' % count)
fpath = "/home/facenet/"
images_dic = {}
for n, name in enumerate(os.listdir(fpath)):
np.random.seed(1337)
pics = [os.path.join(fpath, name, i)
for i in os.listdir(os.path.join(fpath, name))]
np.random.shuffle(pics)
images_dic[n] = pics
images_list = []
num = len(images_dic.keys())
print(n, num)
for name, pics in images_dic.iteritems():
for i in xrange(len(pics)):
k = np.random.randint(0, num)
if k == name:
if k != 0:
k -= 1
else:
k += 1
others = images_dic[k]
other = others[np.random.randint(0, len(others))]
images_list.append([pics[i], name,
pics[i - 1], name,
other, k])
print("len of images_list", len(images_list))
np.random.seed(1337)
np.random.shuffle(images_list)
write_levelDB("data_train_leveldb/", images_list[2000:])
write_levelDB("data_test_leveldb/", images_list[0:2000])2.2、模型配置
在模型配置里,我们可以直接使用alex模型或者googlenet模型,他们提供了train_val.prototxt文件,这个文件主要用于配置训练模型,可以自定义层数以及每层的参数。尤其是对于卷积层的里参数,需要对CNN有一定的理解。这里不细说CNN模型,只考虑应用。在应用层面,需要注意的是数据层。在数据定义层,Caffe生成的数据分为2种格式:Lmdb和Leveldb。它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的速度比leveldb快10%至15%,更重要的是lmdb允许多种训练模型同时读取同一组数据集。需要注意的一些参数如下:
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "facenet/face_train_lmdb" # 训练数据路径
backend: LMDB # 值得数据格式
batch_size: 128 # batch数一般设置为8的倍数,训练比较快
}
# 数据变换层
transform_param {
crop_size: 227 # 数据cropsize是模型的真正输入大小
mean_file: "facenet/face_mean.binaryproto" # 均值数据路径
mirror: true
}
include: { phase: TRAIN }
}这里需要注意的另一个事情是,在分类层那里(在alex模型里,是fc8层的INNER_PRODUCT里的num_output),需要把默认的类别数改为你自己数据的训练类别数。
2.3、模型训练
如果对都没有啥问题,就可以训练模型了,使用梯度下降法。训练模型之前,我们需要定义solver文件,即solver.prototxt,在该文件里,指定迭代次数,是否使用GPU,以及保存中间模型的间隔次数、测试间隔等等。
net: "facenet/train_val.prototxt" #指定训练模型配置文件
test_iter: 1000
test_interval: 1000 # 每迭代1000次,进行一次测试(测试不要太频繁)
base_lr: 0.01 # 初始学习速率
lr_policy: "step" # 学习速率更新方式,每隔多少步更新,也可以使用poly或者constant等等方式
gamma: 0.1 # 学习速度衰减系数
stepsize: 100000 # 每迭代这个么次,新学习速率=学习速度乘以衰减系数gamma
display: 2000 # 每隔两千次打印一次结果
max_iter: 350000 # 训练一共迭代次数
momentum: 0.9 # momentum系数
snapshot_prefix: "facenet/" # 保持中间模型路径 之后在caffe目录下,使用imagenet模型提供的train.sh。这里建议把各个sh文件和训练数据以及均值文件放一起,配置文件和中间模型放在同一路径,置于sh文件下的子文件,这里可以很容易的知道一个模型是结果是采用了什么配置,避免混乱。train里的命令如下:
./build/tools/caffe train --solver=facenet/solver.prototxt -gpu 0
这里需要注意,我们可以指定gpu的id(如果存在多个GPU,可以指定具体的GPU)。另外一点,如果我们增加了数据,需要重新训练模型的话,我们可以在训练的时候,指定已训练好的模型来初始化新训练的模型,这样能够加快我们的训练速度。比如
./build/tools/caffe train --solver=facenet/solver.prototxt -gpu 0 -weights facenet/caffe_450000.caffemodel那么新训练的模型,不会随机初始化权重,而是更具已训练的caffe_450000.caffemodel来初始化参数。这个初始化参数需要注意,这两个模型是相同的,只是输入数据量增多了。
如果我们finetuning的模型与已经训练不同怎么办呢?比如最开始我训练的模型是150像素大小的,而现在想训练一个250像素的模型,那么我们需要修改新模型的训练配置文件,把数据层的名字更新一下,使得新模型和旧模型的名字不一样,之后指定weight就可以,它会默认根据caffe层相同的名字来使用旧模型来初始化新模型,但是必须保证参数是对应的。如果相同名字的层的参数个数不对应,会报错!
此外,我们训练的方式也有很多种。比如一开始用一个模型训练之后,新增的数据,我们可以合并已有的数据,重新训练新模型,也可以使用旧的模型进行finetuning。在caffe目录下,有一个example和model文件夹,里面有很多例子可以使用,在对应的例子下有readme文件,可以在细节上深入理解。比如我们要输入一对数据,这样的模型如何训练呢?只需要更新一下训练配置文件,可以参考examples/siamese下的例子。
3、模型使用
模型的使用方式,这里根据caffe提供的python接口来简单介绍一下,这些例子在python文件下,已经提供了一些包装好的接口。而且在example下提供了一些ipython notebook详细的介绍了各个模块的使用。这里需要注意,我们的deploy.prototxt文件里,开始有四个input_dim,第一个input_dim是指图片数。由于这个接口是参考了AlexNet模型,所以在python的classify类里有一个系数oversample,默认是True的,意味着在预测的时候会对原始图像crop,默认是crop10张图片。注意在官方给的例子里,是使用了crop,所以他的input_dim是10,正好对应一张照片,他的第四个通道是对应第四个crop图片的特征。一般我们会选择False。此外,需要注意input_dim也对应了net.blobs
‘blobname′
‘blobname′的照片数量维度。在net.predict([input_image])的时候,input_image可以是多张。如果输入张数和input_dim不一致,那么得到的net.blob里的特征数是与input_dim一致的,使得得到的特征与输入的特征无法一一对应。所以建议设置input_dim=2,一次输入两张照片,得到对应的两张照片的特征,用于比对。
此外,除了python的接口,caffe也提供命令行用于特征提取,这些都可以参考官方文档。















 4258
4258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









