







目录
4.1、虚析构函数(Virtual destructors):
4.3、返回类型放松(Return types relaxation):
4.4、同时有重载(Overload)和覆盖(Override):
5.1、函数返回引用(Returning references):
5.2、Const reference parameters:
5.2.1、中间结果是const(Temporary values are const):
5.2.2、函数返回值有const(const in Function returns)
6.1、Constructions vs Assignment:
7.1、在对象上应用static(Static applied to objects):
8.1、静态成员变量(Static member variables):
8.2、静态成员函数(Static member functions):
9、运算符重载(Overloaded operators)——基本规则:
14.1、表达式参数(Expression parameters):
14.2、模板 × 继承(Template & Inheritance):
17.1、异常规范(Exception specifications):
17.3、构造函数内的异常(Failure in constructors):
19.1.1、其他的输入运算符(Other input operators):
19.2.1、其他的输出运算符(Other output operators):
19.4、Stream flags control formatting:
1、引用(Declaring reference):
C++提供了非常多的内存模型:
- 提供了许多存放对象的地方(堆栈、堆、全局数据区);
- 提供了许多可以访问对象的方式(直接“fully”那个对象、通过指针访问对象、通过引用访问对象)
这一章要讲的就是引用;
- 引用是C++中一种新的数据类型;
char i; //i is a character(i是一个字符) char* p = &i; //p is a pointer to a character char& r = i; //r is a reference to a character /*一般引用都需要在定义的时候给个初始值,以表明r是i的引用; 并且初始值得是一个可以作左值的东西*/ - 引用还有另外一个名字:alias(别名);
- 由上面两个名字可以看出:引用其实就是当我们需要用 i 的时候,我们可以用 r ;用 r 就是在用 i 。他们只是一个东西的两个名字;
- 基本语法:type& refname = name;
- 只有作为成员变量或者放在参数表里面才可以不用给初始值,其他都要给;
- const char& r = i; 表示无法通过 r 改变 i ;
- 与c不同,引用的这种“绑定”关系是不可变的;
int main() { int x = 1; int y = 2; int& r = x; //r是x的引用,绑定关系是永久的 r = y; //这句代码就只是纯粹的赋值,而不是将r转变为y的引用 } - 引用可以作左值("做左值"是"引用"的必要条件),所以返回引用的函数也可以作左值(我们知道返回基本类型的函数不能作左值);
#include <iostream> using namespace std; int x; int* f() { return &x; } int& g() { return x; //返回x的引用(没有提供引用名) } int& h(int& y) { //参数表中的引用可以不用给初始值,在调用时会用实参的值初始化引用 y++; //对引用的操作就是对被引用者的操作 cout << "in h() y = " << y << endl; return y; //return引用就是return被引用者,而函数返回类型还是引用,所以还是返回被引用者的引用 } int main() { int& i = x; int j = 0; double k = 0.0; *f() = 8; cout << "x=" << x << endl; g() = 16; //g函数返回x的引用,给引用赋值就是给x赋值 cout << "x=" << x << endl; h(i); //因为"引用"的出现,给函数传参就不一定只是传值了 cout << "x=" << x << endl; /*类似于h(i)这种看起来像传值调用但实际上是可以改变全局变量x的值的, 所以我们一定要去检查源代码*/ h(j) = 7; cout << "x=" << x << ", j = " << j << endl; /*给h传递引用或变量进去都是可以的,可以做引用的引用这种事情 int& a = x; int& b = a; 这一点指针无法做到:当参数要指针时就只能传地址不能传变量*/ //h(k); //ERROR:无法用"double"类型的值初始化"int &"类型的引用(非常量限定) return 0; }运行结果:

有一点要注意的是:由上面的代码我们可以看到当你定义int& h(int& x) {...}这样一个函数时,main里面可以直接h(i)调用;这个时候我们就不能再定义 int h(int x) {...}这样类型的函数了。否则h(i)调用就不明确了:

1.1、Pointer vs Reference:
Pointer:
- 可以为空;
- 指针独立于现有的对象;
- 一个指针可以指向不同的地址;
Reference:
- 不能为空,一定要有初始值;
- 依附于现有变量,是现有变量的一个“别名”;
- 引用的这种“绑定”关系是永久的;
C++里引用其实就是通过指针实现的(这一点无法验证,我们无法获取到引用的地址,实际上会得到被引用变量的地址,不过这并不妨碍我们理解引用的本质),引用本质上就是个const指针(int *const p,你可以理解为引用r实质上就是那个*p);设计“引用”这个东西出来是为了让代码少一点"*"号,使代码看上去简洁美观。(不过还是不要弄混了,引用在C++内部是通过指针实现,但这不代表引用变量的类型是指针;引用本身就是一种新的数据类型了)
Java则是以另一种方式解决这个问题:Java设计成只能通过指针去访问对象。正因为只有这一种访问对象的方式,所以Java可以把那个"*"号取消掉;然后对外宣称这不是指针,是“引用”。但实际上Java中的“引用”跟C++中的引用不是一回事,它更像C++中的指针。
1.2、一些引用限制(Restrictions):
- C++没有引用的引用(但编译器可能会帮你做到这点);
- &引用变量共享被引变量的内存,它是“别名”故理论上不分配内存;
- 被&引用的变量或表达式一定是分配了内存的有址左值;
- 由此可知,一个&引用变量不能引用自己;
- Visual Studio允许引用的引用,显然:"引用的引用"和"引用"和"被引用者"它们三个都是一个东西;
- 没有指向引用的指针;
-
int&* p; //illegal
-
- 但是可以有指针的引用;
-
int* p = &x; int*& r = p; //it's OK! - 这里补充一点:离变量名最近的那个符号,决定了它的基本类型。
-
- 没有引用的数组;
2、向上造型(Upcasting):
向上造型是将子类的引用或指针转变为父类的引用或指针的一种行为。也就是说如果B继承自A,那么你就可以在任何能够使用A的场合去使用B,B相比A多出来的那些东西可以当作不存在。
class student : public person {...}; //student继承自person student jack; //student对象jack person* pp = &jack; //it's Upcast person& pr = jack; //it's Upcast同时,在上半部分学习笔记中我们提到过“名字隐藏”,但如果你通过"pp"或者"pr"去调用函数时,实际上会调用父类的对应函数,也就不会有名字隐藏的问题出现。以下面这段代码为例:
#include <iostream> using namespace std; class A { public: A() {} void f() { cout << "A::f() with no parameter" << endl; } void f(int i) { cout << "A::f() with one parameter" << endl; } void f(int i,int j) { cout << "A::f() with two parameters" << endl; } void f(int i,int j,int k) { cout << "A::f() with three parameters" << endl; } }; class B : public A { public: void f(int i, int j) { cout << "B::f() with two parameters" << endl; } }; int main() { B b; int i = 0, j = 0, k = 0; A* p = &b; //Upcast,将b的引用交给了指向 A的对象 的指针p p->f(i); //调用父类的f函数 //b.f(i); //ERROR: Name hiding return 0; }运行结果:
不扯远了,回到向上造型本身:从内部结构上来说,子类的对象拥有父类对象的所有东西(包括私有和公共的);从实际内存存储上来说,存储B对象的那块内存里面确实存储了一整块A对象而且是放在那块内存顶部的,连A对象里面数据的排列顺序都是完全一致的。所以,B完全可以当作A来看待和使用。
以下面这段代码为例:

#include <iostream>
using namespace std;
class A {
public:
int i;
int j;
A() : i(1), j(2) {}
};
class B : public A {
private:
int k;
public:
B() : k(3) {}
int get_k() { return k; }
};
int main() {
A a;
B b;
int* p = (int*)&a; //将a的地址取出来强制类型转换为指向int的指针后交给指向int的指针p
cout << "a.i=" << a.i << ";" << "a.j=" << a.j << endl;
cout << "b.i=" << b.i << ";" << "b.j=" << b.j << ";" << "b.k=" << b.get_k() << endl << endl;
cout << "Sizeof(a) = " << sizeof(a) << " byte" << endl;
//a实际只存储着它的两个int变量,所以它大小是8(byte)
cout << "Sizeof(b) = " << sizeof(b) << " byte" << endl << endl;
//b存储着a的所有东西以及自己的int变量k,所以b的大小是12(byte)
*p = 10; //和C类似,C++在获取到地址之后也可以直接访问最底层的内存并做些修改
cout << "p=" << p << endl;
cout << "*p=" << *p << endl;
cout << "a.i=" << a.i << ";" << "a.j=" << a.j << endl << endl;
p = (int*)&b;
cout << "p=" << p << endl;
cout << "*p=" << *p << endl; //按顺序访问b的内存的每一个int看看b究竟是怎么个顺序存储它的数据的
p++;
cout << "*p=" << *p << endl;
p++;
cout << "*p=" << *p << endl; //通过指针就可以随心所欲直接访问b的private的k
*p = 30;
cout << "modify *p=" << *p << endl;
cout << "b.i=" << b.i << ";" << "b.j=" << b.j << ";" << "b.k=" << b.get_k() << endl;
return 0;
}运行结果: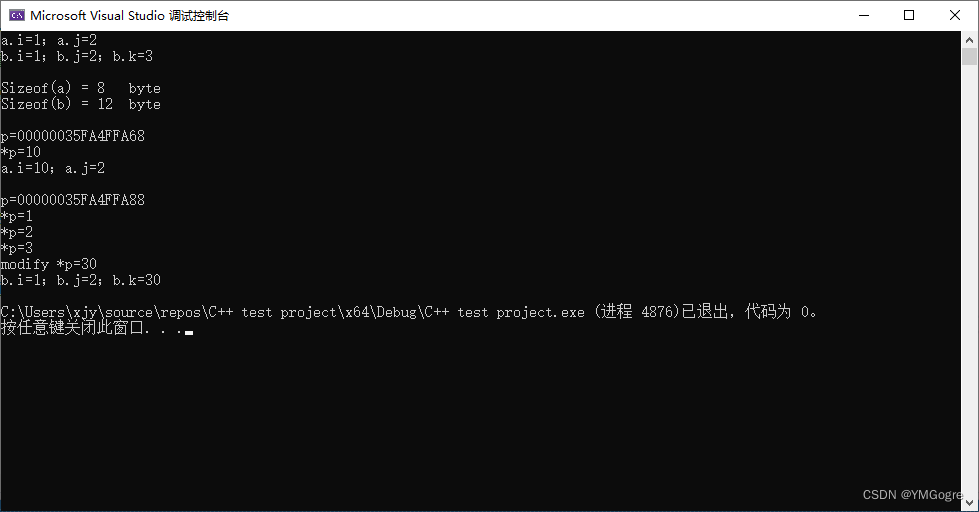
由上面代码可以看出:当我们获取到对象的指针时,可以直接通过指针看看对象里面是什么样的。b的大小是12(byte),也证明了在b(对象)里面是没有成员函数的,只有成员变量,这跟C语言中的结构体是一样的(实际上类的成员函数存放在代码段的)。
同时子类拥有父类的所有东西,连数据存储顺序都是一样的。以上面代码为例,不会说b的 k 是插在 i 和 j 中间存储的。所以b完全可以当作a来使用,但b还是b,不会因此真的变成a,只是我们把它看作是a了。

最后再提一点是:相反地,有向上造型也有向下造型,即把父类的对象当作子类的对象看待。但向下造型是有风险的!
3、多态性(Polymorphism):
现在我们要设计一个画图程序:
程序可以画三种不同的图形:矩形、圆形、椭圆。 他们拥有相同的数据:center(中心点坐标);可以做三种相同的操作:render(渲染图形)、move(移动图形)、resize(改变大小)。
为了实现上述要求,我们可以以一个类型来定义另一个类型:
- 一个ellipse是一种shape;
- 一个circle是一种特殊的ellipse;
- 一个rectangle是另外一种不同的shape;
- rectangle、circle、ellipse拥有一些共同的:属性(成员变量)和服务(成员函数);
- 但它们三个也不是完全相同的;
于是,它们构成了如下图所示的联系:
center 和 move() 只在Shape里面定义了,对大家来说center和move()要做的事情都是一样的,所以其他四个类里面就不需要再定义了;而不同图形的 render() 是不一样的,而且不同的图形类里面可能有自己的数据(比如Ellipse类有"长轴"、"短轴"数据),同时不同图形的render()和Shape的render()得是存在某种联系的。
下面来设计代码:


///Shape类
class XYPos {...}; //x,y point
class Shape{
public:
Shape();
virtual ~Shape(); //析构函数也用了virtual修饰
virtual void render();
/*"virtual"关键字意思是“虚的”,表示如果将来Shape类的子类里面重写了render(),
那么重写的render()跟这个render()是有联系的!!
这跟我们在“Name hiding”中提到的“子类中的print()函数跟父类中的print()函数是没有关系的”
是不一样的!!*/
void move(const XYPos&);
virtual void resize();
protected:
XYPos center;
};
///Ellipse类
class Ellipse : public Shape {
public:
Ellipse(float maj, float minr);
virtual void render();
/*will define own, "virtual"可以不加,因为只要一个类中某个函数是virtual的,
那么这个类的子子孙孙的那个函数都是virtual了,无论前面是否加了virtual修饰;
当然加上"virtual"是个好习惯,这样别人不用去翻祖先类就知道这个函数是virtual了*/
protected:
float major_axis, minor_axis //长轴和短轴
};
class Circle : public Ellipse {
public:
Circle(float radius) : Ellipse(radius, radius) {}
virtual void render();
};之所以搞得这么麻烦是为了实现如下面这个应用实例中的这样的render()函数:
void render(Shape* p) {
p->render(); //calls correct render function
} //for given Shape!
/*render函数接受一个Shape的指针作为输入,然后让指针指向的那个对象去做render
render函数是个通用函数,对任何Shape类的子类都是适用的(包括Shape自己),
也就是说这个render函数是用于将来的新出现的Shape的子类的对象。而现在,
我还不知道将来Shape还会有什么样的子类,但这个函数写在这里对将来Shape可能出现的子类也是通用的*/
void func() {
Ellipse ell(10, 20);
ell.render(); //调用Ellipse的render()
Circle circ(40);
circ.render(); //调用Circle的render()
render(&ell); //Upcast向上造型,但由于virtual的关系故不会调用父类中的render(),而是调用Ellipse自己的render()
render(&circ);
}- "virtual"是在告诉编译器当一个函数是virtual时,且对这个函数的调用如果是通过指针或引用的话,编译器就不能相信它一定是什么类型的。需要到运行时刻确定这个指针所指的那个对象到底是什么类型,再去调用那个类型的该函数;
- 而上面提到的这些事情,就称为“多态性”。对于上面的应用实例代码,p就是多态的,有的地方也称p为“多态对象”。因为p指向什么类型的对象,通过p做的动作就是那个类型的对象做的。p指向谁就变成谁的“形态”,故称p是“多态对象”。
由上面可知“多态性”是构筑在两件事情上的:
- 向上造型(Upcast);
render(Shape *p){ p->render(); } ... render(&ell); //仅看参数表里面的内容,其实就是"Shape *p = &ell",显然是Upcast- 动态绑定(Dynamic binding);
- 所谓绑定:是指调用时应该调用哪个函数
静态绑定:调用的函数是确定的(编译时刻就确定的);
动态绑定:需要到运行时刻才知道到底要调用哪个函数;
- 从另外一个角度来看,"void render(Shape* p)" p的类型是Shape的指针,这可以说是p的静态类型;同时p还有个动态类型是p当时指向的那个对象的类型。
4、多态的实现:
C++到底是怎样实现在运行时刻动态地绑定那个函数,在运行时刻知道p所指的那个对象到底是什么类型的继而去调用正确的函数的呢?又回到了上半部分学习笔记中的那句话:Bjame Sgoustrup 在1979年刚开始研发C++的时候,他的手段仅仅只有C,他是怎么用C语言来实现C++的多态性呢?而且实现方式也不会很复杂,毕竟C++的运行效率也是很高的,太复杂了效率就会低。
- 任何一个类如果有虚函数(virtual function),这个类的对象就会比正常的"大"一点。
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; }
};
int main()
{
A a;
a.f();
cout << "sizeof(a) = " << sizeof(a) << endl;
int* p = (int*)&a;
cout << "*p = " << *p << endl; //探查第一个int
p++;
cout << "*p = " << *p << endl; //探查第二个int
p++;
cout << "*p = " << *p << endl; //探查(如果有)第三个int
return 0;
}运行结果(x64编译):
运行结果(Win32编译): 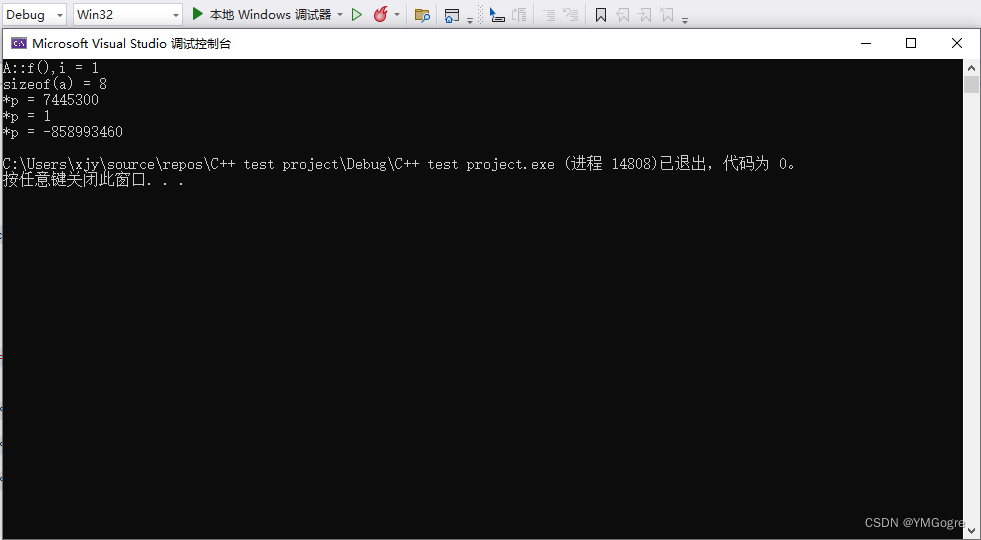
- 可以看到实际占用都不止4个字节了,以Win32运行结果为例:实际上 a 的成员变量 i 是存储在第二个int的。而第一个int大小的东西我们不知道是什么;
- 那个不知道是什么的东西其实是个指针,叫做"vptr"。所有有virtual的类的对象里面最顶部都会自动加上这个隐藏的"vptr",它指向一张表,表叫做"vtable"。

- vtable里面存放的是这个类的所有的virtual函数的地址。所以vtable是属于这个类的,所以这个类的所有的vptr的值都是一样的,这是可以验证的:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
};
int main()
{
A a;
A aa; //做两个对象出来
cout << "sizeof(a) = " << sizeof(a) << "byte" << endl;
cout << "sizeof(aa) = " << sizeof(aa) << "byte" << endl;
int* p = (int*)&a; //取a的地址出来强制类型转换为int型指针并交给int型指针p
cout << "*p(a) = " << *p << endl; //取第一个int出来
p = (int*)&aa;
cout << "*p(aa) = " << *p << endl; //同样取第一个int出来
return 0;
}运行结果(Win32编译):
- 另外我们还可以做一些“邪恶”的事情。我们知道 p 是 指向vtable的指针(就是vtable的地址) 的指针,所以 *p 表示指针所指的地方即vtable的地址,我们可以把 *p 交给另外一个指针x,那么x就会指向vtable,它们之间的关系如下图所示:
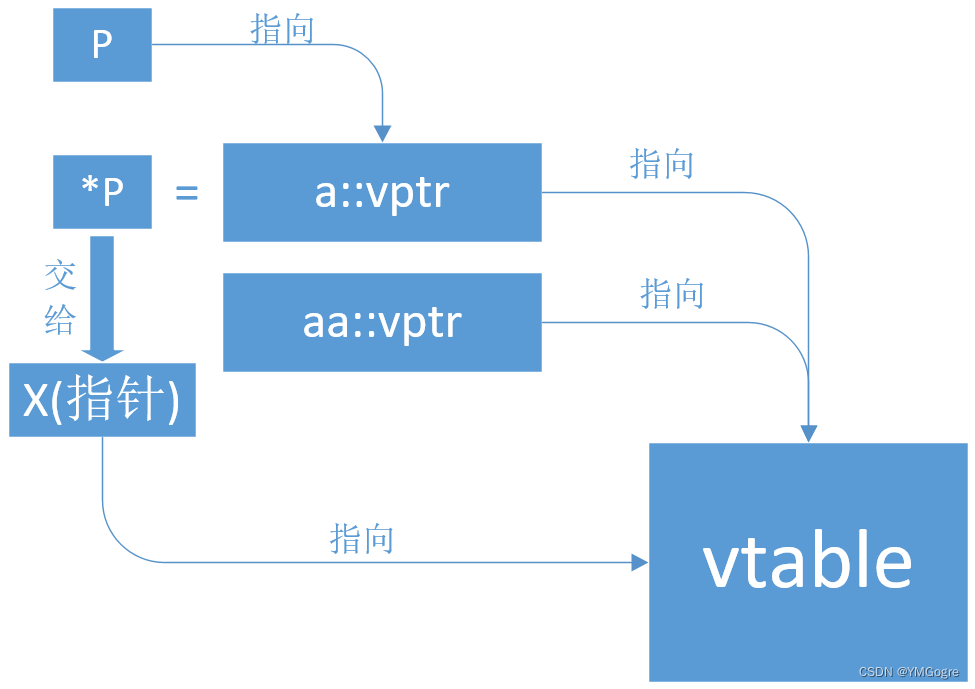
我们验证一下上面的关系:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
};
int main()
{
A a;
cout << "sizeof(a) = " << sizeof(a) << "byte" << endl;
int* p = (int*)&a;
cout << "*p(a) = " << *p << endl; //*p的内容是vtable的地址
int* x = (int*)*p;
cout << "x = " << x << endl; //x的内容应该也是vtable的地址
return 0;
}运行结果: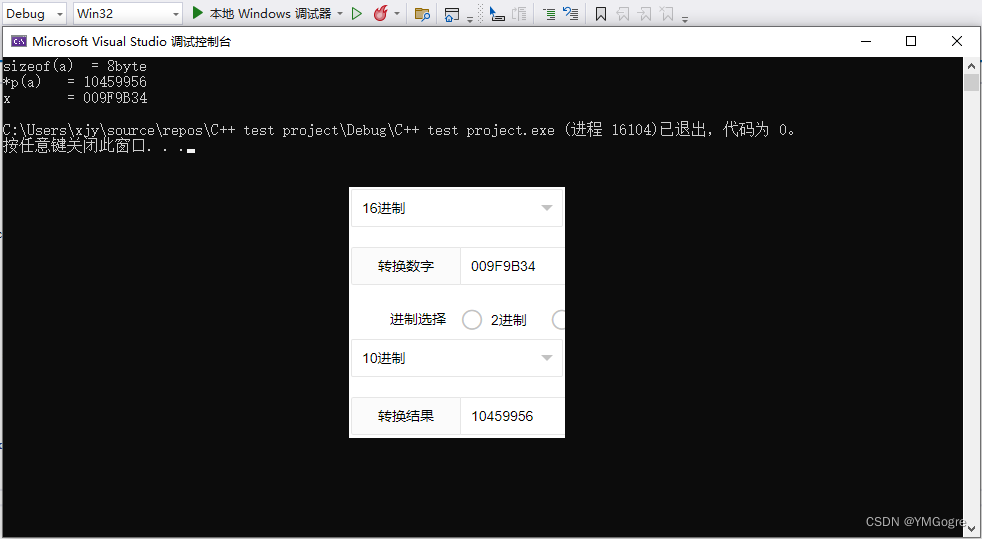
而我们要做的“邪恶”的事情就是既然拿到指针了,我们就可以通过*x看到vtable的内容了,现在我们尝试打印下vtable的第一个int(因为x是指向int的指针嘛):
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
};
int main()
{
A a;
cout << "sizeof(a) = " << sizeof(a) << "byte" << endl;
int* p = (int*)&a;
cout << "*p(a) = " << *p << endl;
int* x = (int*)*p;
cout << "*x = " << *x << endl;
return 0;
}运行结果(Win32编译): 
- 还有一点是上面我们提到过"一个有virtual函数的类的不同对象的vptr是指向同一个vtable的(也就是这个类的vtable)";而当这个类有子类的时候,子类的不同对象当然也会有vptr,但是它们会指向子类自己的vtable;而不是父类的vtable。

可以看到:子类Ellipse的vtable的结构跟父类是一样的(第一个是析构函数dtor()、第二个render()、第三个resize()),不过里面的值(地址)是不一样的。Ellipse的析构、render()是自己的;而它的resize()是Shape的,因为Ellipse没有写自己的resize()。不过析构是特别的,即便Ellipse没有写自己的析构,编译器也会给Ellipse制造一个析构出来,所以vtable里存的是Ellipse自己的析构。同样的,还有Ellipse的子类Circle:

通过上面那么大篇幅介绍的方式,我们终于摸清了C++实现动态绑定的方式: 只需要通过修改vtable表里的地址。当函数
void render(Shape* p) { p->render(); }中说"p->render()"的时候,实际发生的事情是让p所指的对象的第一个地址取出来,从该地址访问到了vtable,然后从vtable"+1"得到了那个 render() 的地址,然后调用那个地址上的 render() 函数就可以了。
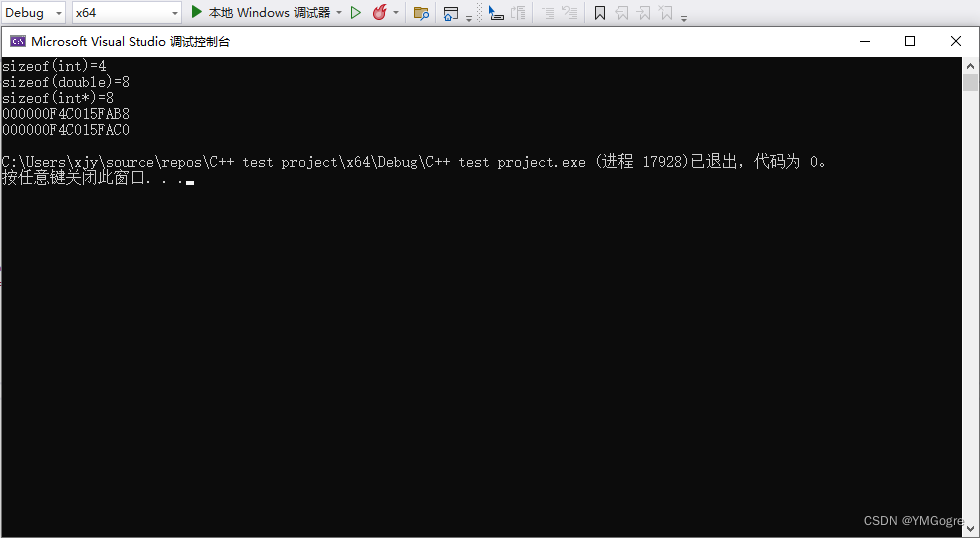
这里再展开讲讲"+1"的细节。现假设我们使用的是64位编译模式,那么64位编译模式下一个地址占用8字节,一个int占用4字节。现代计算机通常采用"按字节编址",也就是一个地址对应的内存单元是一个字节。这些内容可以通过下方的代码验证:
#include <iostream> using namespace std; int main() { double a; double* p = &a; cout << "sizeof(int)=" << sizeof(int) << endl; //获取int占用字节 cout << "sizeof(double)=" << sizeof(double) << endl; //获取double占用字节 cout << "sizeof(int*)=" << sizeof(int*) << endl; //获取指针(地址)占用字节 cout << p << endl; p++; //指针++ 对应 得到下一个double的地址(地址+8) cout << p << endl; return 0; }运行结果:
在之前我们都还没有提到过vptr和vtable的类型。
- vtable:vtable的类型可以表达为
uintptr_t*,表示vtable中每个元素类型都是uintptr_t;- vptr:vptr指向vtable,因此vptr的类型是
uintptr_t**,表示指针vtpr指向的类型是uintptr_t*;经验证64位编译模式下
uintptr_t、uintptr_t*和uintptr_t**都占用8个字节,所以同样的从vtable"+1"(代码层面的 指针 +1)对应地址"+8"(物理内存层面的 地址 +8)。
在上面我们把*p交给了int型指针x,若想要x指向那个 render() 函数,我们得让x"+?"呢?
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
virtual void g() { cout << "A::g(),i = " << i << endl; }
};
int main()
{
A a;
cout << "sizeof(a) = " << sizeof(a) << "byte" << endl;
int* p = (int*)&a;
int* x = (int*)*p;
cout << "sizeof(x) = " << sizeof(x) << endl;
cout << "sizeof(int) = " << sizeof(int) << endl;
return 0;
}运行结果(Win32编译): 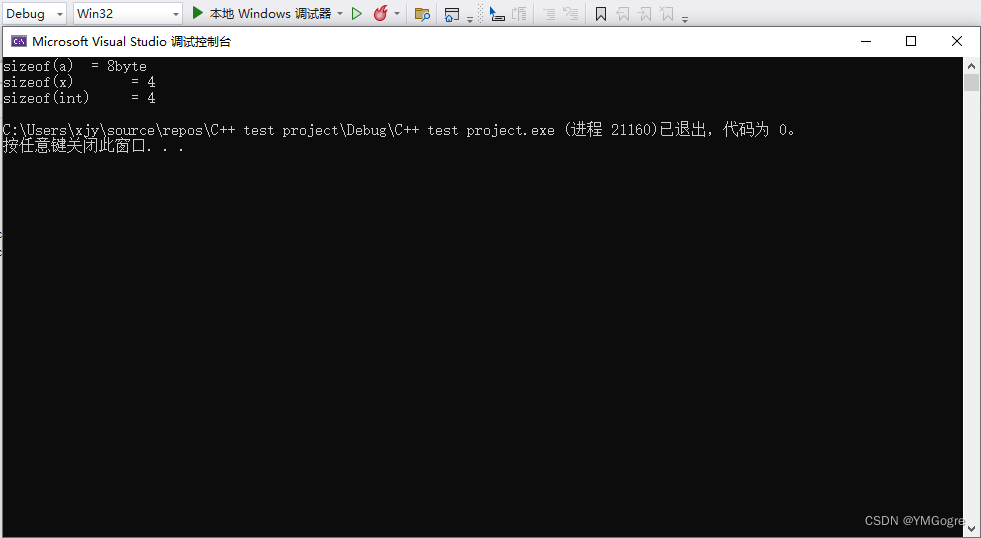
运行结果(x64编译): 
可以看到这种实现动态绑定的方式是高效的,程序在运行时刻根本无需知道对象的类型是什么,只是在顺着vptr找到了vtable,然后找到了应该调用的正确函数的地址而已。

在“多态性(Polymorphism)” 一章我们提到过," “动态绑定”是要通过指针或者引用调用virtual函数时才会去做的 ",那么我们不通过指针或者引用去调用virtual函数会怎么样呢?这一点我们展开来验证一下:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
};
class B : public A {
public:
int j;
B() : j(2) {}
virtual void f() { cout << "B::f(),j = " << j << endl; } //B重写了虚函数
};
int main()
{
A a;
B b;
A* p = &b; //Upcast but virtual
p->f(); //虽然向上造型了但是因为virtual存在还是会调用子类的f
a = b; //直接把b赋给a
a.f(); //通过a.f()到底是调用a的f还是b的f呢?
return 0;
}运行结果: 
显然,只有通过指针或者引用调用virtual函数时才会去“动态绑定”,通过"."去调用时并不会做这样的事情;
可是我们明明把b赋给a了呀!这一点好像被完全无视了?我们再修改下程序,这次让指针去调用virtual函数 f() :
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
};
class B : public A {
public:
int j;
B() : j(2) {}
virtual void f() { cout << "B::f(),j = " << j << endl; } //B重写了虚函数
};
int main()
{
A a;
B b;
A* p = &b; //Upcast but virtual
p->f(); //虽然向上造型了但是因为virtual存在还是会调用子类的f
a = b; //直接把b赋给a
p = &a; //这次我们通过指针去调用virtual函数,已知指针调用时会去做动态绑定的工作
p->f(); //那么这次又会调用a的f还是b的f呢?
return 0;
}运行结果: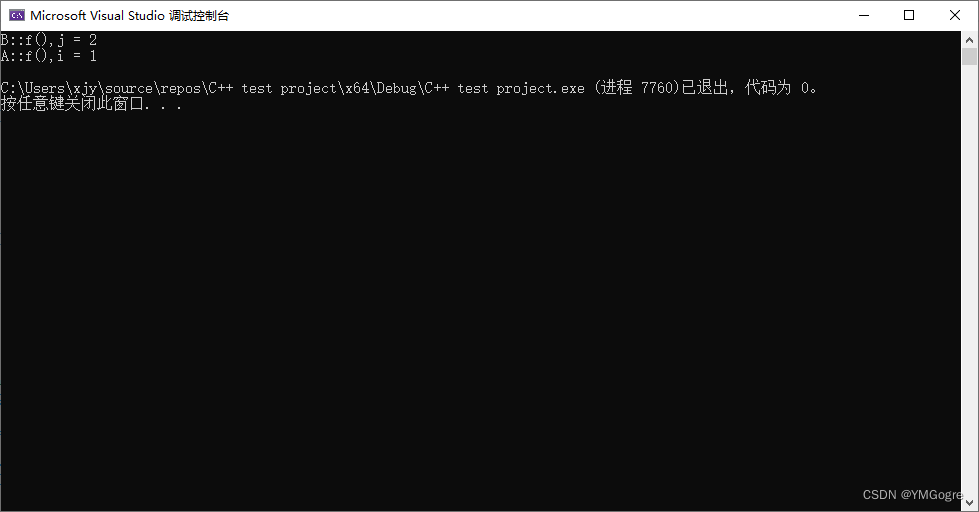
还是调用的a的f函数。为什么?
因为我们在做赋值操作(a = b;)时只是把b的值给了a(你可以试试在上面这段代码中B的构造函数里修改A的成员变量i的值,然后在赋值操作完成前后打印a.i,就能观察到b是把i的值赋过去了的),所以a还是a的;所以进行赋值操作时,b的区域是被“切掉”了的,只有符合a的那部分才会被赋值过去。而且在赋值过程中vptr是不传递的。所以自然调用的a的f函数。
如果是指针的赋值的话,那显然原本的a就被覆盖丢失了...(因为指针不代表任何事情嘛,指针就是一个地址而已)
A* a = new A(); B* b = new B(); a = b; a->f(); //B::f() is called当然我们还可以做更“邪恶”的事,比如vptr的赋值操作:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(1) {}
virtual void f() { cout << "A::f(),i = " << i << endl; } //A类有虚函数
};
class B : public A {
public:
int j;
B() : j(2) {}
virtual void f() { cout << "B::f(),j = " << j << endl; } //B重写了虚函数
};
int main()
{
A a;
B b;
A* p = &a; //把对象a的地址取出来交给指向A类对象的指针p
int* r = (int*)&a; //取出a的vptr交给指针r
int* t = (int*)&b; //取出b的vptr交给指针t
*r = *t; //直接把b的vptr赋给a的vptr
p->f(); //哇实在是太邪恶了
return 0;
}运行结果: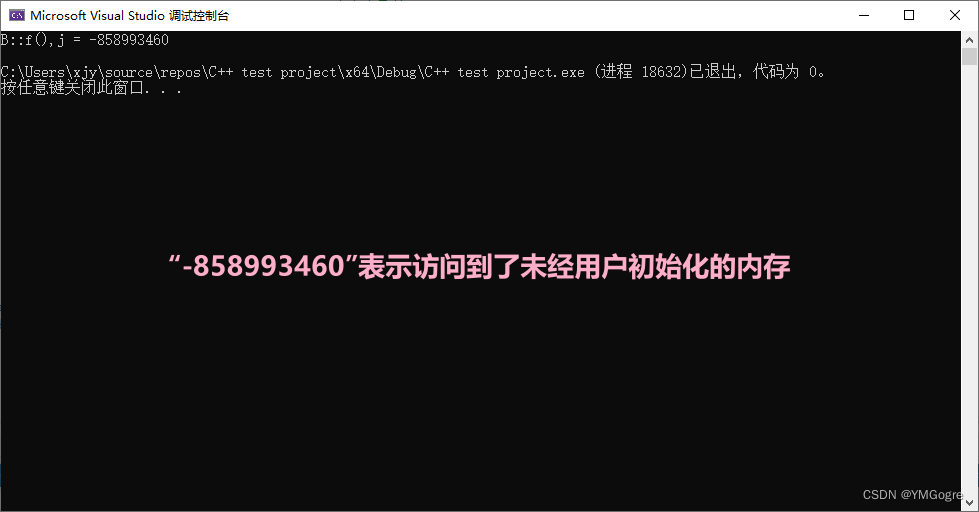
在调用b的f函数时要去找j,它就会去找对象a里面i的下面那块内存,而那块内存是不属于a的,所以会找到什么结果是未知的。对于上面的示例代码,程序访问到了未经用户初始化的内存。对vptr进行赋值时它们之间的关系如下图:
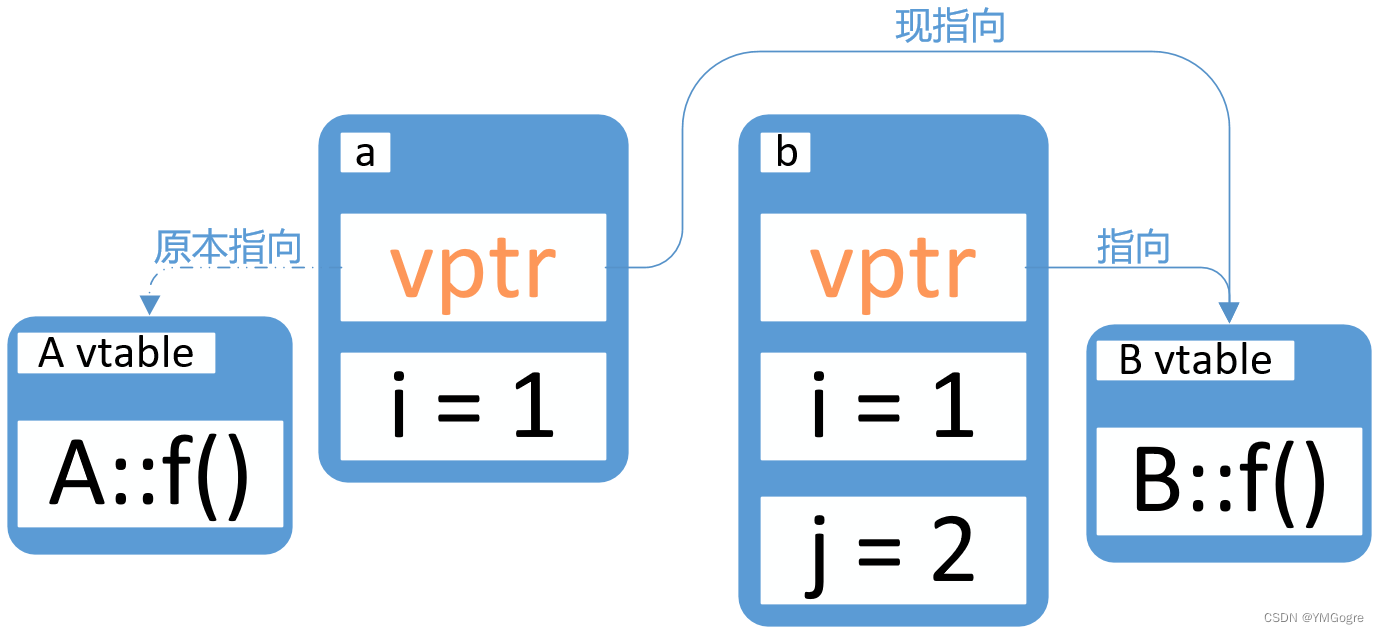
以上用的是指针的形式调用virtual函数,下面再补充一下用引用的形式去调用:
void func(Ellipse& elly) {
elly.render();
}
Circle circ(60F); //generate a circ object
func(circ); //Circle::render() is called4.1、虚析构函数(Virtual destructors):
在《多态性(Polymorphism)》一章中我们设计Shape类的代码里可以看到析构函数被设计为了虚函数,为什么要设计成virtual的?我们来看看下面这个代码:
Shape *p = new Ellipse(100.0F, 200.0F);
/*在学习《向上造型(Upcasting)》时我们说"person* pp = &jack;"是Upcast,
那上面这句代码是不是Upcast呢?
这也是Upcast,我们做了个Ellipse的对象交给了父类Shape的指针p:在上半部
分学习《new & delete》时提到过new作为一个运算符会返回分配给对象的地址,所
以这句代码还是向上造型,向上造型本质是:把子类对象当成父类对象用*/
...
delete p;我们知道:当delete p;时会自动调用析构函数,如果析构函数不是virtual的,意味着此时Shape的析构会被调用。所以,我们需要让析构函数是virtual的。
如果我们设计的类中有一个virtual函数,我们就必须把析构函数也设计成virtual的,这样可以避免可能出现的麻烦。这件事情的关键在于即便现在我们的类没有子类,我们也无法预知将来别人会怎么修改我们的程序。比如我们想象一下下面这种场景:
我们设计了一个类,类里面有一些virtual函数但析构函数不是virtual的。这个时候别人写了个新类继承自我们的这个类,他知道我们的类里有virtual函数所以选择Upcast以实现动态绑定。然后由于别人写的新类里面申请了一些资源,所以别人重写了我们的析构函数用于归还申请的资源(这一点在上半部分学习笔记中的《构造和析构(Constructor & Destructor)》中谈析构的用处时提到过)。而当别人new了一个他写的类的对象之后再去delete时,就像上面的代码那样,会去调用我们父类的析构,而显然我们的析构没有说要去还那些申请的资源。
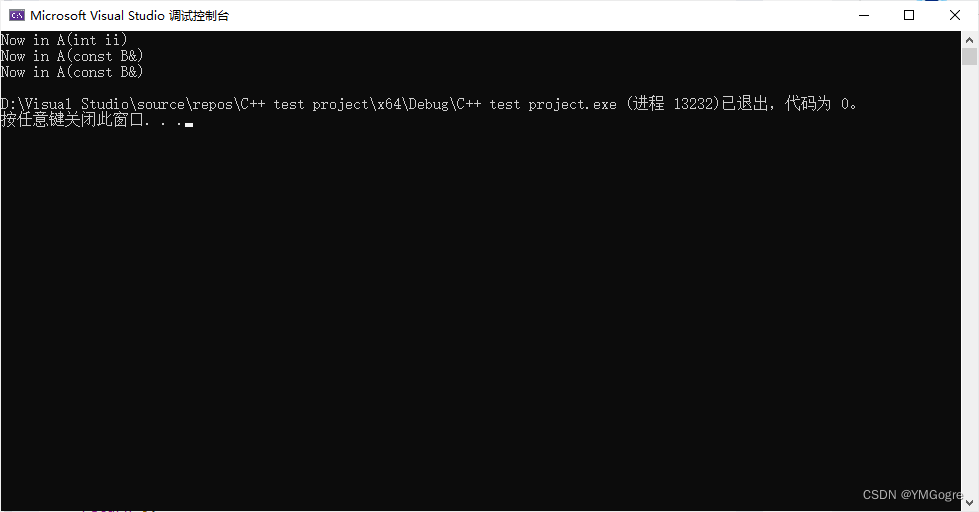
#include <iostream> using namespace std; class A { private: int i; public: A() : i(0) { } virtual void f() { cout << "A::f()" << endl; } //virtual f() ~A() { cout << "A::~A()" << endl; } }; class B : public A { public: virtual void f() { cout << "B::f()" << endl; } ~B() { cout << "B::~B()" << endl; } }; void f(A* p) { p->f(); } int main() { B b; /*b不是new出来的,在上半部分学习笔记《父类子类的关系》中我们说过: "退出时会先析构子类,再析构父类" 所以离开大括号范围时会先调用~B(),再调用~A()。*/ A* p = new B(); //Upcast p->f(); //but f() is virtual,所以动态绑定 f(&b); //也是Upcast but virtual,所以也会动态绑定 cout << endl << "Before delete p" << endl; delete p; //此时会调用~A()(这不是我们期望的结果) cout << "After delete p" << endl << endl; return 0; } //此时会调用~B()、~A()运行结果:

4.2、覆盖(Override):
如果父类和子类的两个函数是virtual的,名称相同,参数列表也相同。那它们构成一种关系叫做"Override"。中文可以称作“覆盖”、“覆写”、“重写”或者“改写”。还记得在上半部分学习笔记中的《名字隐藏(Name hiding)》里我们说"子类中的print()函数跟父类中的print()函数是其实是没有关系的",现在有了virtual,就构成了Override关系了。
在Override中如果我们想要调用父类的那个函数,可以这么写:
void Derived::func() { cout << "In Derived::func!" << endl; Base::func(); //call to base class }下面举一个可以运行的例子:
#include <iostream>
using namespace std;
class A {
public:
A() {}
virtual void f() { cout << "A::f()" << endl; }
};
class B : public A {
public:
virtual void f() {
cout << "Now in B::f(), I'm trying to call A::f():" << endl;
A::f();
}
};
void f(A* p) {
p->f();
}
int main() {
B b;
A* p = new B();
p->f();
f(&b);
delete p;
return 0;
} 运行结果: 
4.3、返回类型放松(Return types relaxation):
- 假如B继承自A;
- 那么C++允许B::f()返回A::f()返回类型的子类;
- 适用于指针和引用类型;
比如A::f()如果返回了一个A类自己的的指针,而且B::f()Override它了;那么B::f()就可以返回B类的指针;
class A {
public:
virtual A* f();
virtual A& g();
virtual A h();
};
class B : public A {
public:
virtual B* f(); //it's OK!
virtual B& g(); //it's OK!
virtual B h(); //ERROR! Only applies to pointer and reference types
};因为只有通过指针或者引用才构成Upcast关系嘛,才能够发生多态性(polymorphism)嘛。这点在之前多次提到过了。
4.4、同时有重载(Overload)和覆盖(Override):
现在父类中有一组virtual的重载(Overload)函数,如果你覆盖(Override)了其中一个,你就必须把所有的重载给覆盖掉,否则依然会发生名字隐藏那样的事情。
5、引用再研究:
在《引用(Declaring reference)》一章我们提到过"引用作为成员变量或者放在参数表里面才可以不用给初始值",而这其中当引用作为成员变量没有给初始值时我们就必须(也只能)在初始化列表里面给出初始值来。
class X { public: int& m_y; //现在还不知道将来构造X的对象时m_y要与谁建立引用关系,没有办法在声明时给初始值 X(int& a); //构造声明 }; X::X(int& a) : m_y(a) {} //构造定义我们就必须在初始化列表中建立引用关系,因为如果在大括号{}里面写"m_y = a;"那就是在赋值了(把a赋给m_y所“绑定”的那个变量)。比如下面这样:
class X { public: int& m_y; X(int& a); //构造声明 }; X::X(int& a) { m_y = a; } //构造定义

5.1、函数返回引用(Returning references):
同返回指针,函数也可以返回引用,而且也不能返回本地变量的引用;
#include <iostream>
using namespace std;
const int SIZE = 32;
double myarray[SIZE];
double& subscript(const int i) {
return myarray[i];
/*返回第i个元素变量,因为一般会在调用该函数的地方会将该变量“绑定”给别的reference
就像:
int f() {
...
}
int a = f();
这样,我们也可以:
int& f() {
...
}
int& a = f();
区别在于int a = f()只是在赋值,而int& a = f()是把f()返回的变量“绑定”给a了
*/
}
int main() {
for (int count = 0; count < SIZE; count++) {
myarray[count] = count + 1;
}
double& FirstElement = subscript(0);
//把返回值“绑定”给另外一个reference
double FirstElement_value = subscript(0);
/*把返回的「值」赋给了一个double变量(这个时候发生了"dereference")。
很容易理解:引用就是别名嘛,把"引用赋给变量"不就跟"把变量赋给变量"一样的嘛,
"i = j;"这种事不是经常做嘛,实际上就是传值嘛*/
cout << "FirstElement =" << FirstElement << endl;
cout << "FirstElement_value =" << FirstElement << endl << endl;
FirstElement_value = 3.1415926; //修改double变量对myarray数组没有影响
cout << "After modify double myarray[0] = " << myarray[0] << endl;
FirstElement = 2.7182818; //修改引用的值即修改被引用者的值
cout << "After modify double& myarray[0]= " << myarray[0] << endl;
}运行结果: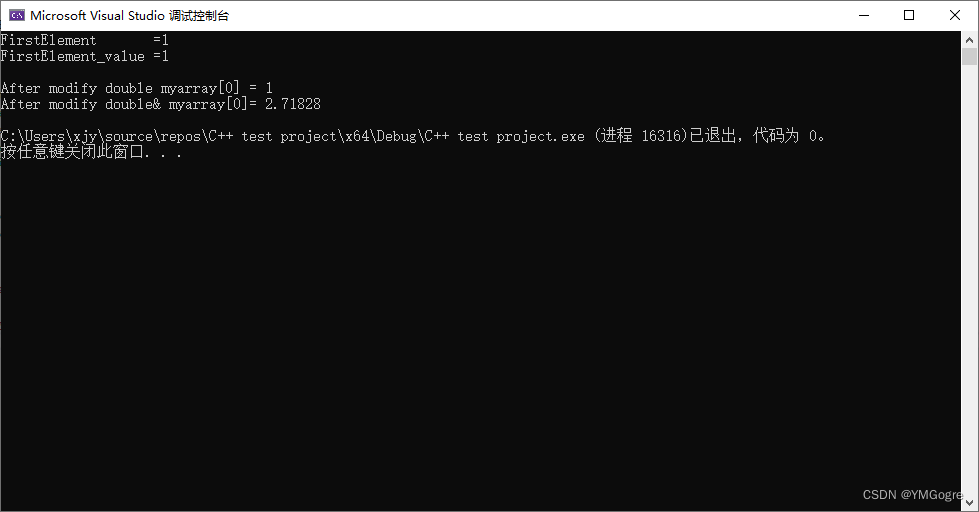
上面这段代码没有演示返回引用的函数作"左值"的情况,感兴趣的小伙伴可以自己试一试(比如subscript(7) = 2.58;)。因为函数返回reference,所以返回的reference可以作为变量来使用。
5.2、Const reference parameters:
在上半部分学习笔记的《Const》一章中我们说过:
"对一个函数传进传出整个对象时可能会造成很大的开销,往往更好的办法是传一个地址。但是传地址我们又会很不放心别人会不会通过指针修改我们的原始数据。这个时候,const修饰指针的作用就来了。我们在前面加上 const 表明我们以一个const的方式传一个对象进去,这样就可以保证我们的数据是安全的。"
现在我们有了引用(reference),我们可以选择用更好的reference,因为reference意味着我们就可以不用在那个函数里面用很多"*"号了,这也是C++开发工作中更推荐的。
5.2.1、中间结果是const(Temporary values are const):
我们先来看下下面这段代码:
void func(int &);
func (i * 3); //ERROR:无法将参数从"int"转换为"int &"
//我们都知道reference必须能做左值,显然i*3不能作左值,当然报错
还有种解释是编译器在编译时会生成下面这样的代码:
void func(int &);
const int tmp@ = i * 3; //编译器产生了const int的临时变量tmp@
func(tmp@); //因为tmp@是const,就不能传给int &(const不能作左值嘛)
那现在我们修改函数的参数为const reference parameter,试试看能不能把tmp@传进去:
#include <iostream>
using namespace std;
void f(const int& i)
{
cout << i << endl;
}
int main() {
int i = 3;
f(i * 3);
return 0;
}运行结果:
没有报错可以正常运行,验证了第二种解释。
5.2.2、函数返回值有const(const in Function returns)
- return by const value
—— 对于用户定义类型,这意味着“防止作为左值使用”(现代的编译器貌似不用加const都不能作左值了,详见下面的代码);
—— 对于内置的,它没有任何意义(就像int f(),我们都知道实质上返回的是值,而不是一个变量。值本来就不能作左值,const int f()就无意义了);
我们来测试一些返回用户定义类型的代码:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(0) {}
};
A f() {
A a;
return a;
}
int main() {
A b;
//f().i = 10; //ERROR:表达式必须是可修改的左值
/*上面这句代码理论上应该是行得通的,可能是Visual Studio的编译器现在不允许这种行为了吧*/
b.i = 20;
f() = b;
cout << "Now f().i = " << f().i << endl;
cout << "Now b.i = " << b.i << endl;
return 0;
}我的Visual Studio编译器版本: 
运行结果: 
哦哟,这很奇怪哦,我们明明做了f() = b;这件事,但是f().i好像没啥变化啊?是不是因为局部变量的关系呢?我们在上面代码的基础上加一些监测然后调试试一下:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(0) { cout << "Now in A::A()" << endl; }
~A() { cout << "Now in A::~A()" << endl; }
};
A f() {
A a;
cout << "After A a" << endl;
return a;
}
int main() {
A b;
cout << "After A b" << endl;
//f().i = 10; //ERROR:表达式必须是可修改的左值
/*上面这句代码理论上应该是行得通的,可能是Visual Studio的编译器现在不允许这种行为了吧*/
b.i = 20;
f() = b;
cout << "After f() = b;" << endl;
cout << "Now f().i = " << f().i << endl;
cout << "Now b.i = " << b.i << endl;
return 0;
}运行结果: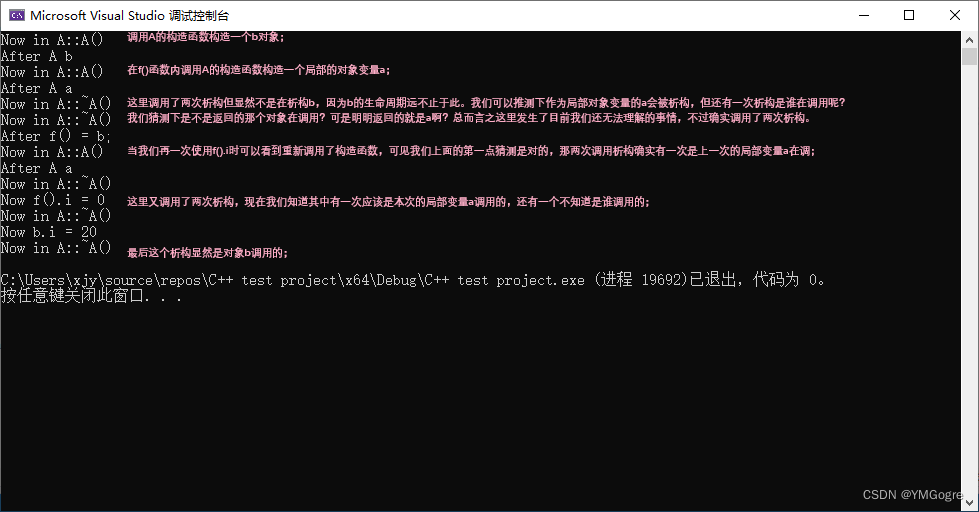
当然还是建议小伙伴将上面的代码复制到你的IDE中,然后在main函数入口处设置一个断点,逐步调试观察程序是如何一步一步运行的。就像下面这样:
2022-9-25
视频并不清晰哈,这里我只是想告诉你我在干啥。
当你一步步地调试时,你就可以发现:f()确实返回了一个对象,在return语句执行时会去析构局部变量a,所以这个时候显然返回的不是a对象本身了,现在我们推测函数返回的是一个a的"副本",而且此时我们并不知道这个"副本"变量的名字和地址。
然后程序继续执行"f() = b;"这句代码,此刻这个"副本"变量还没有被析构(通过调试过程看得出来),而显然我们没有办法去访问到这个返回的对象的任何东西,因为此时我们并不知道这个"副本"变量的名字和地址。换句话说,没有任何人知道"副本"在哪,没有人此刻掌握着"它"。
所以"它"就不存在了,"它"消失了。这句话好像有点哲学哈,我们可以理解为“当世界上没有任何一个人能够观察到你的存在时,你是否还真的存在于这个世界上呢?”Think about it!
所以在程序执行完"f() = b;"后,这个"副本"对象也被一起析构了,所以发生了我们目前还无法理解的"两次析构被调用"。
感兴趣的小伙伴可以构造一个A的对象来掌握返回的那个"副本"对象。这样就直到 掌握着那个"副本"的 对象的 生命周期结束才会调用析构了。比如"A c = f(); c = b;"。
这一段实际发生的事情涉及到马上要讲的《拷贝构造(Copy the structure)》,所以现在不理解也不必担心。
- return by const pointer or reference
—— 这取决于你期望使用你的类的人会拿着这个返回结果做啥
在5.1、函数返回引用(Returning references)小节开头我们就说"函数不能把本地变量作引用给返回",但其实我们可以尝试下做这种"邪恶"的事情的,编译器不会报错。
下面举一些返回引用的代码例子,这段代码推荐除main函数内的内容以外全部复制进你的IDE内,然后自行测试你能想象到的所有可能:
#include <iostream>
using namespace std;
class A {
public:
int i;
A() : i(0) { cout << "Now in A::A()" << endl; }
~A() { cout << "Now in A::~A()" << endl; }
};
int i; //全局变量i
int& f() {
return i; //返回全局变量的引用
}
int& ff() {
int a = i;
return a; //返回本地变量的引用
}
const int& g() {
return i; //返回全局变量的引用且是const的引用
}
A& h() {
A a;
return a; //返回本地对象变量的引用
}
A b; //全局对象变量b;
const A& m() {
return b; //返回全局对象变量的引用且是const的引用
}
int main() {
f() = 4; //我们知道引用和被引用者是一个东西嘛,所以这和 i = 4; 没有区别
int j = f(); //这和int j = i;没有区别
cout << "j=" << j << endl;
cout << "return of f() =" << f() << endl;
//和直接打印全局变量i没有区别,因为f()函数就是拿全局变量i的引用返回的;
ff() = 44;
/*但是返回本地变量的引用就有问题了,因为本地变量的生存周期只有函数内部,
所以这样的引用实际上是非法的,不过编译器仍然通过了*/
cout << "return of ff() =" << ff() << endl;
//作为一个不存在的变量的引用,它的值当然是不确定的
//g() = 5; //返回全局变量的引用是const时编译器则不允许修改其值了
h().i = 6;
//当然返回本地对象变量的引用也存在同样的问题,在退出h()函数时本地对象会被析构
cout << "h().i=" << h().i << endl;
/*这里是第二次调用h()了,看似我们是在返回h().i = 6; 的h().i,
实际上会重新构造本地对象,然后退出时析构;
而作为已经被析构掉的本地对象变量的引用,它的成员变量i的值同样是不确定的。
这个时候我们可能会问了:我们构造一个新的对象来掌握h()返回的那个引用呢?就像下面这样:*/
A aa = h();
aa.i = 66;
cout << "aa.i=" << aa.i << endl;
/*好像没有问题了哈?可h()显然是多余的呀,直接A aa; aa.i = 66;不就可以了吗?*/
//m().i = 7; //返回全局对象的引用则不能通过引用修改值
cout << "b.i=" << b.i << endl;
return 0;
}运行结果:
测试完了吗?那我做下总结吧:
- 如果函数返回在函数中创建的临时对象(别忘了一切事物皆是对象),则不要使用引用。因为当函数结束时,临时对象将消失,因此这种引用是非法的。这点我们在5.1小节《函数返回引用(Returning references)》开篇就提到了;
- 如果函数返回本地对象的引用我们还把它交给了另外一个引用时,这是非常非常危险的行为!!因为那个引用会成为不存在的对象的引用,引用指向的那块内存是没有人在使用的内存即"空闲内存",而空闲内存是随时都可能有人会用的!也就是说我们随时可能在不经意间使用该引用破坏了别人的内存!下面举一个简单例子:
#include <iostream> using namespace std; int& f() { int i; return i; } void g() { int j; cout << "&j =" << &j << endl; } int main() { int& r = f(); cout << "&r =" << &r << endl; g(); /*我们知道本地变量放在堆栈区(stack),f()执行完后它的本地变量i消失了; 而g()的本地变量j就会被存放在i刚刚存放的位置*/ return 0; }运行结果:
- 如果是全局对象作引用并返回时,const的作用和之前一样是告诉编译器"禁止用户使用返回的引用去修改其值";
- 以上三点在函数返回指针时也是一样的(在《引用(Declaring reference)》一章里我们说过"引用本质上就是个const指针(int *const p,可以理解为引用r就是那个*p)"嘛);

如果上面"return by const pointer or reference"讲过的内容还是不好理解的话,也不要钻牛角尖了。这件事情不要想麻烦了,归根结底就两件事:
- 函数肯定不能返回本地的对象嘛(不管是返回本地变量本身 or 本地变量作为引用并返回 or 本地变量的地址),这是非法的,这一点毋庸置疑,我们在5.1小节《函数返回引用(Returning references)》开篇就提到了;
- 如果是返回全局对象的引用或指针且是const的,那这就和我们之前理解的作用是一样的:都是在告诉编译器"禁止通过返回的这个引用或指针去改变全局对象的内容";
6、拷贝构造(Copy the structure):
我们做一个函数func(A a),函数的参数是一个A的对象(不是引用或指针哦)。然后我们构造一个A的对象aa,然后调用func时把aa给它......
void func(A a) {
cout << "a.i = " << a.i << endl;
}
...
A aa;
func(aa); //aa is copied into a现在我们都知道a是func里面的对象,和外面的aa是没有关系的,在调用时会直接把a拷贝一份到堆栈里。那么这个时候到底发生的是:
A a = aa; //初始化(Initialization)还是
a = aa; //赋值(Assignment)呢?在C++这两种有什么区别?(在C++这两件事会有很大区别的,这个往后学会逐渐了解的)
还记得在5.2.2、函数返回值有const小节发生了一件当时我们无法理解的事情吗:"调用了两次析构函数"。这其实还不算夸张的,下面来个更夸张的:
#include <iostream>
using namespace std;
static int ObjectCount = 0; //对象计数器
class A {
public:
A() {
ObjectCount++;
//在之前学习中我们知道每构造一个A的对象就会调用一次构造函数,所以我们让对象计数器++
cout << "Now in A::A(), ObjectCount = " << ObjectCount << endl;
}
~A() {
ObjectCount--;
cout << "Now in A::~A(), ObjectCount = " << ObjectCount << endl;
}
};
A func(A a) {
cout << "Now in func(A a)" << endl;
return a;
}
int main() {
A aa;
cout << "After construct aa" << endl << endl;
func(aa);
cout << "After func(aa)" << endl << endl;
A a = aa;
cout << "After A a = aa" << endl << endl;
return 0;
}运行结果:
可以看到对象计数器直接给弄成-3了,程序好像只调用了一次构造却调用了4次析构?因此我们居然好像"欠"了程序3个对象?而且"A a = aa;"这句代码好像没有构造就结束了?
先来研究"A a = aa;",我们先来看看如果加一个带参构造函数再来构造一些对象是否会正常调用构造函数:
#include <iostream>
using namespace std;
static int ObjectCount = 0;
class A {
public:
A() {
ObjectCount++;
cout << "Now in A::A(), ObjectCount = " << ObjectCount << endl;
}
A(int i) {
ObjectCount++;
cout << "Now in A::A(int i), ObjectCount = " << ObjectCount << endl;
}
A(const A& a) {
ObjectCount++;
cout << "Now in A::A(const A& a), ObjectCount = " << ObjectCount << endl;
}
~A() {
ObjectCount--;
cout << "Now in A::~A(), ObjectCount = " << ObjectCount << endl;
}
};
int main() {
A aa;
cout << "After construct a" << endl << endl;
A a = aa;
/*当a类只有默认构造函数的时候,我们知道这句代码好像没有正常去调用A的默认构造函数;
但现在我们有一个接受A的对象的const引用的带参构造函数,
(其实构造函数参数是A* a也可以,初始化就得换成A a = &aa;)
是否能够捕捉到A a = aa这个过程中的初始化呢?*/
cout << "After A a = aa" << endl << endl;
A b(10);
cout << "After A b(10)" << endl << endl;
A c = 20;
/*tips:在C++用圆括号或者等号初始化变量是等价的,也就是说这句等价于"A c(20)"
尽管这看起来像是在把一个整数赋给一个对象,类型不匹配不能就这么等起来;
但由于A有个要1个int的带参构造函数,所以这么写是可以的*/
cout << "After A c = 20" << endl << endl;
return 0;
}运行结果:
可以看到,通过新增一个接受A的对象的const引用的带参构造函数,我们成功捕获到了A a = aa;的初始化过程。在这基础上感兴趣的同学还可以把第一段代码里的func()加到第二段代码里去,你会发现func()也能正常调用相应的构造函数了:

以上内容了解完后我们可以做总结了:
如果你有一个构造函数的参数是自己类型的const引用,这种构造函数就会在我们用另外一个该类的对象来初始化某个该类的对象(比如A a = aa;还有仅看func()函数的参数表和调用时传的内容,其实发生的也是A a = aa;嘛)时被调用。这样的一个构造函数我们用一个特殊的名字——"拷贝构造",来称呼它。拷贝构造有如下特点:
- 形式唯一:
T ::T(const T&)
- 你可以使用自己写的拷贝构造函数来决定哪些要拷贝,哪些不用,或者完成一些特殊操作;
- 如果你没有提供拷贝构造,C++会自己提供一个,而且它会:
- 拷贝每一个成员(不是简单的一个字节by一个字节地拷贝);
(因为如果成员变量中有其他对象,它会让那个类的拷贝构造来拷贝那个对象)
- 拷贝每一个指针,当然引用也是;
- 正因为本章开始那段代码我们没有提供自己写的拷贝构造,C++会自己提供一个然后去构造;我们才会看到只调用了1次我们的默认构造函数却调用了4次析构。背后发生的事情就是程序还调用了3次自动提供的拷贝构造,只是我们当时不知道而已;
- 上面说自动提供的那个拷贝构造会去拷贝每一个指针,那显然新的对象里的指针会和老的对象里的指针是相同的,我们来验证一下这件事:
Person.h:
#ifndef __PERSON_H__
#define __PERSON_H__
class Person {
public:
char* name; //char* instead of string,为了方便访问放在public里了
Person(const char* s);
~Person();
};
#endif // !__PERSON_H__Person.cpp:
#include "Person.h"
#include <cstring>
//也可以写#include <string.h>,C++在cstring头文件里声明了以前C标准库里面的那些字符串函数
using namespace std;
Person::Person(const char* s) {
name = new char[::strlen(s) + 1];
::strcpy_s(name, ::strlen(s) + 1, s);
//第二个参数(缓冲区长度)要比strlen(s)多1,因为strlen()计算字符串长度是不包括结尾的'\0'的
}
Person::~Person() {
delete[] name; //array delete
}main.cpp:
#include <stdio.h>
#include "Person.h"
int main() {
Person p1("xjy");
Person p2(p1); //用p1初始化p2我们知道会拷贝构造
printf("p1.name=%p\n", p1.name); //得到p1.name的地址
printf("p2.name=%p\n", p2.name); //得到p2.name的地址
return 0;
}运行结果:
可以看到,指针确实是直接拷贝过来了,两个指针完全相同;还有一点是程序在执行完两个printf()函数后报错了,下面都没有代码了所以显然这是在析构时出错了。 这是因为在上半部分学习笔记《new & delete(动态地制造对象)》一章我们说过"不要连续两次用delete释放同一块空间",显然这里p1和p2释放的是同一块空间嘛。
- 这跟我们期望的是有偏差的,我们更期望的拷贝成下面这张图右边这样:

所以我们应该为Person类做一个的拷贝构造去取代自动提供的那个拷贝构造:
Person::Person(const Person& p) { //别忘了在.h里面声明下
name = new char[::strlen(p.name) + 1]; //分配内存
::strcpy_s(name, ::strlen(p.name) + 1, p.name); //拷贝
}添加上我们写的拷贝构造之后程序就可以正常运行了。
- 此外,当函数返回本地对象变量时,也会发生拷贝构造。比如我们有一个返回Person对象的函数f():
#include <stdio.h> #include "Person.h" Person f() { Person ip; //ip会正常调用默认构造函数,没啥问题 return ip; //关键在于f()函数退出时要不要产生一个临时对象@tmp } int main() { Person p = f(); /* p对象显然是被Person类的另外一个对象初始化的,所以这里毫无疑问会调用拷贝构造 但是这里也会有两种安排: 1. Person p = ip; 就用函数里面的那个ip构造了外面的p 2. Person @tmp = f(); Person p = @tmp; 这就涉及到了编译器怎么安排这件事了 */ return 0; }大部分情况下,编译器会在安全的前提下把不必要的拷贝给"优化"掉(optimize out),比如:
#include<iostream> using namespace std; class Person { public: Person(const char* s) { cout << "Now in Person::Person(const char* s)" << endl; } Person(const Person& person) { cout << "Now in Person::Person(const Person& person)" << endl; } ~Person() { cout << "Now in Person::~Person()" << endl; } }; Person nocopy_func(char* who) { return Person(who); /*f()函数内直接制造了一个Person的对象,没有在函数内使用且直接返回了该对象; 而且制造该对象也不是通过拷贝构造来制造的,而是通过 char* 来制造的。作为默认 内联函数编译器在编译时能够看到函数体;它会看到函数内的这个对象构造出来的目的 就只是为了传出去。那么编译器就会优化它*/ } int main() { char i[] = "who"; Person p = nocopy_func(i); /*编译器会直接优化掉拷贝构造,编译器会认为我们就是要拿"who"来构造外面的对象p*/ return 0; }运行结果:
极端一点的情况就像本章开头的那段演示代码的func()函数一样:
A func(A a) { cout << "Now in func(A a)" << endl; return a; } int main { A aa; ... func(aa); return 0; }在传参和返回的时候都会发生拷贝构造。

6.1、Constructions vs Assignment:
本章开篇我们讲"在C++里面初始化(Initialization)和赋值(Assignment)有很大不同",这一小节我们就详细说说。
- 初始化只能做一次,对对象来说,初始化就是构造(Construction)嘛,任何对象只能被构造一次。做完初始化后再进行的任何操作就不再是初始化了,而是赋值;
- A a = aa; //初始化,发生拷贝构造
- a = aa; //赋值
- 构造出来的对象就要被析构,所以每构造一个对象就要对应有一个析构;一旦被构造出来后,可以做很多次赋值;
6.2、string name:
在本章讲"编译器提供的拷贝构造会拷贝每一个指针"的时候,我们举了一个Person类例子里面有一个成员变量char* name,如果我们把它换成string name,string是C++里系统类库里用来表达字符串的类。准确来说:char*是C的字符串;string才是C++的字符串。
如果我们把name换成string类型的,那么我们就不需要写拷贝构造。我们回想下为什么char* name的时候要写拷贝构造:无非就是因为拷贝了指针,发生了两次delete,程序出错。现在类型换成string了,当然不会出现同样的问题了~
所以在C++里可以忘了char*,用string类以及它的函数来做事情,像拷贝就更简单了(直接用等号而不是strcpy了)。
6.3、本章小结:
拷贝构造使用准则:
- 通常情况下,如果你写了一个类,那还是为它添上一个拷贝构造,不要依赖编译器给的那个;
- 如果你真的不希望被拷贝,则声明一个私有的拷贝构造(初学者不建议尝试);
- 这样别人没法拷贝构造你的对象,同样意味着别人的函数参数不可能是你这种类型的对象本身,可以是指针或引用但就是不能是本身;
- Java没有拷贝构造这件事情;
7、静态对象(static object):
我们在学习C语言的时候就学习过static,static在C里面本就是个很复杂的东西,因为static关键字从C开始就被赋予了两种完全不同的"职责":
- Static storage:在固定地址分配一次内存,表示存储是持久的;
- Visibility of a name:内部链接,表示访问性受局限的;
到C++之后,这件事情变得更复杂了,因为C++多了成员变量和成员函数。先来一张概述图简单了解下C++里面static的用法:

7.1、在对象上应用static(Static applied to objects):
如果一个static的本地变量,它的类型是一个类的话,这个时候我们关心两件事情:
- 它在哪里;
- 它什么时候被构造(初始化);
我们知道对于一个普通的static本地变量,它会在第一次进入函数时被初始化;现在换作static的本地对象变量,那它依然应当是第一次进入函数时被构造(初始化)。好,那现在我们应该怎么用C来实现这件事情?毕竟C++的一切最终都可以变成C,所以,又双叒叕回到了上半部分学习笔记中的那句话:Bjame Sgoustrup 在1979年刚开始研发C++的时候,他的手段仅仅只有C。他是怎么用C语言来实现C++的静态对象呢?
要实现"只有第一次进入函数时被构造",我们能想到的最简单的方案就是需要一个标志来表明该对象被初始化过了。所以静态对象旁边应当伴随一个隐藏的(hidden)变量来作为标志。但以目前我们学过的内容来看,C++还没有这样一个现成的标志来表明是否得到初始化。最有可能实现这项功能的是vptr:在初始化前,vptr放的可能是乱糟糟的东西;初始化后里面的地址才有效。但我们又知道不是所有的类的对象都有vptr的。
Java就不需要这样一种标志变量,因为Java有别的机制可以保证没有得到初始化的内存是不会被别人拿到的;但我们知道C++的内存模型很复杂,我们有多种方式拿到一块没有初始化的内存。
既然讲到了"什么时候被构造"的问题,这里再补充一些tips:
- 条件构造
void f(int x) { if(x > 10) { static X my_X(x, x * 21); ... } ... } /* 1、static本地对象变量 my_X 只有在f()函数被调用并且x>10时会被构造; 2、持久存储; 3、如果没有被构造,就不会调用析构;且作为全局生存期的变量,析构会在程序结束时发生; */- 全局对象
#include "X.h" X global_x(12, 34); X global_x2(56, 78); /* 1、全局变量的构造发生在程序运行时刻、main()函数运行之前; 2、全局变量的析构发生在main()函数退出或者exit()调用的时候 (总之就是程序要结束的时候); 3、如果你的程序有多个.cpp文件,每个文件里都有一些全局变量, 那么这些全局变量并没有严格规定谁先初始化,谁后初始化;如果这个时候 你的程序的执行或者这些全局变量的初始化存在依赖关系,那就可能出问题。 */- 静态初始化依赖(Static Initialization Dependency)
- 针对上面说的初始化存在依赖关系,有一些解决方法:
- 别这么干;
- 如果逻辑上允许的话,可以把所有存在依赖关系的全局变量放到一个文件里面去,一个文件中的构造顺序是已知的;
- 甚至还可以采取Java的解决办法:Java没有全局变量,也就没有这么多破事儿了;
8、静态成员(static member):
static,对于C++这种OOP语言,同C一样意味着两件事:
- 被隐藏(Hidden);
- 持久存储(Persistent);
- Hidden:对于一个类的成员来说,这件事本来我们是用"private"、"public"这些访问限制来做的,所以对设计C++static成员的人来说这件任务其实已经结束了,而且有更好的方法实现。
- Persistent:对于传统的比如C语言,函数之间仍然存在的东西是持久存储的(比如全局的东西(包括全局变量和static本地变量)和malloc出来的东西);对于OOP语言,则是对象之间仍然存在的东西是持久存储的(比如全局的东西和不随着对象改变而改变的东西)。这一点还是需要借助static来做的;
- 如果一个类的成员是static的,作为成员那么它具有了"Hidden",当然它还是这个成员(遵循通常的访问规则),就是说如果你这个静态成员是public的,那么外面还是可以访问。同时通过static它成为了"Persistent",成为不依赖于某个对象而存在的东西。
8.1、静态成员变量(Static member variables):
- 静态成员变量在这个类的所有对象中都存在,都可以直接使用它,且静态成员变量在所有对象中的值是保持一致的;
- 静态成员变量不占用对象的内存,而是在所有对象之外开辟内存,即使不创建对象也可以访问(不依赖于某个对象而存在);
#include<iostream>
using namespace std;
class A {
private:
static int i; //静态成员变量i
public:
A() { i = 0; }
void set_i(int ii) { i = ii; } //有一个修改i的成员函数
void print() { cout << i << endl; } //有一个打印成员函数
};
class B {
private:
int i;
public:
B() { i = 0; }
void set_i(int ii) { i = ii; }
void print() { cout << i << endl; }
};
int main() {
cout << "sizeof(A) = " << sizeof(A) << endl;
/*sizeof(类名)得到的是该类型实体的大小(即该类的对象在存储器中所占据的字节大小),
所以就相当于sizeof(对象)了。同时C++标准规定类的大小不能为0,空类大小为1*/
cout << "sizeof(B) = " << sizeof(B) << endl;
A a, aa;
B b;
a.set_i(1);
aa.print();
return 0;
}给出了错误信息:
可以看到,又是Linker那边出问题了,说明编译这边通过了的,这是哪出问题了?
由C中函数的静态局部变量实际放在全局可推得C++类的静态成员变量实际上也在全局。在上半部分学习笔记《成员变量的秘密(field, parameters, local variables)》一章我们说"你写在类里面的成员变量都是声明,而不是定义"。比如我们声明一个全局变量:extern int i;这只是在告诉编译器:某个地方有个叫做 i 的东西,我不知道它在哪,它不在这里,我只是告诉你有这么一个叫做 i 的东西,将来Linker去帮我找出来。
同样,写在A里的静态成员变量 i ,也是在告诉编译器:我知道某个地方有个全局变量i ,它是我的成员变量,只有在我这个类里面可以访问它(因为我把它做成了private)。我同样不知道它在哪,因为我写在类里面只是个声明。就相当于在C里面写了句 extern 是一样的效果。
所以如果我们写了静态成员变量,我们一定要在某个.cpp文件里面写上(以上方代码为例):
int A::i;去定义这个静态成员变量(这个时候在全局数据区分配内存),否则Linker就找不到。那这个时候我们可能会问了,我们用
static int A::i;来定义可不可行呢?答案是不可以,因为从C的角度来说定义一个全局静态变量意味着"访问受限",表示 A 的这个 i 只有在这个.cpp文件里面才能被访问,这和类的静态成员的访问属性相违背。因为类的静态成员是可能在外部被访问的,所以这个static不能再加上去了。
还有一点是我们在 A 的构造函数里对静态成员变量做了赋值,而不能用初始化列表来做。因为静态成员变量只能在自己定义的地方做初始化,初始化列表只能对非静态成员做初始化。比如:
class A { private: static int i; public: //A() : i(0) {} //ERROR A() { i = 0; } }; int A::i = 10; //可以在定义的地方做初始化,但这里初始化没意义,因为会在调用构造函数时把i赋值为0了
从上面这些内容看来,C++实现静态成员变量的机制也并不复杂,没有通过啥复杂的触发或者消息通知机制实现,没有那么复杂。C++仅仅就是做了一个全局变量,然后这个全局变量是你类的成员,仅此而已。

8.2、静态成员函数(Static member functions):
- 在之前的学习中我们多次了解过"对象里面是没有成员函数的,只有成员变量,这跟C语言中的结构体是一样的(实际上类的成员函数存放在代码段的)"。可见,对于C++来说,所有的成员函数本来就是全局的,函数不跟着对象走,所以我们不必强调静态成员函数是全局的。但它同样还是通过static它成为了"Persistent",成为不依赖于某个对象而存在的东西。
- 静态成员函数跟普通成员函数的区别在于:
- 不依赖于某个对象而存在;
- 只能访问静态成员变量;
- 若静态成员函数要调其他成员函数,只能调用静态成员函数;
对上面的第二点"只能访问静态成员变量",我们展开讲一下:只能访问静态成员变量换种说法也就是不能访问非静态成员变量。这背后涉及到的点是:对于静态成员函数来说,它是没有那个隐藏参数(hidden parameter)"this"的。
我们都知道this的类型是调用那个成员函数的对象的指针,而静态成员函数又不依赖于某个对象而存在,这就导致了静态成员函数是无法传递隐藏参数给成员变量的,所以静态成员函数是没有this隐藏参数的,是不能访问非静态成员变量的。
至于为什么能访问静态成员变量,当然是因为静态成员变量也是不依赖于某个对象而存在的嘛,访问它根本不需要this(当然有this的成员函数还是可以通过this访问静态成员变量的)。
下面举一段代码来展示以上提到的点:
#include<iostream>
using namespace std;
class A {
private:
static int i; //静态成员变量i
int j; //非静态成员变量j
public:
A() : j(0) { i = 0; }
static void Staticfunc(int ii) { //静态成员函数
i = ii; //可以访问静态成员变量
//j = ii; //ERROR:非静态成员引用必须与特定对象相对
//print(); //ERROR:非静态成员引用必须与特定对象相对
}
void print() { cout << "i = " << this->i << endl; } //有this的成员函数还是可以通过this访问静态成员变量的
};
int A::i;
int main() {
A a;
a.Staticfunc(1); //可以通过对象调用静态成员函数
//A::print(); //ERROR:非静态成员引用必须与特定对象相对
A::Staticfunc(2); //静态成员函数不依赖于某个对象而存在,可以直接通过类名访问(静态成员变量也是如此)
a.print();
return 0;
}运行结果: 
9、运算符重载(Overloaded operators)——基本规则:
在C++中我们可以重载几乎所有的运算符(比如+、-、*、/),所谓重载即我们可以写函数去改变这些运算符的行为。当这些运算符要对我们定义的类的对象去做运算的时候,他可以不使用默认的运算功能而选择使用我们写的那个运算功能。这就叫"运算符重载"
- 我们先来看看C++中哪些运算符可以被重载,哪些不可以:


- 运算符重载的限制:
- 只有已经存在的运算符才能被重载(你不能自己创造一个运算符比如"**"说“啊我这表示"乘幂"运算”,这是不行的);
- 这个时候我们可能会想:在数学上我们一般用"^"表示"乘幂"(C/C++里"^"表示"异或"),那我们把"^"重载为"乘幂"可不可行呢?答案是可以的,但这就涉及到道德伦理上的问题了哈哈。大家看到"^"都会认为是"异或",但现在我们把它重载成"乘幂"运算了,这对别人阅读代码是不利的。
- 运算符必须在类(class)类型或枚举(enumeration)类型上被重载(也就是说重载后的运算符不再是对基本类型的变量做运算操作了;而是对类类型或者枚举类型的变量做操作);
- 运算符重载必须要:
- 维持原有操作数个数;
- 比如说"+"原本是二元运算符,那我们重载的"+"也得是二元运算符。
- 维持原有的优先级;
C++运算符优先级表 优先级 运算符 说明 结合性 1 :: 范围解析 自左向右 2 ++ -- 后缀自增/后缀自减 () 括号 [] 数组下标 . 成员选择(对象) -> 成员选择(指针) 3 ++ -- 前缀自增/前缀自减 自右向左 + - 一元取正/一元取负 ! ~ 逻辑非/按位取反 (type) 强制类型转换 * 解引用 & 取地址 sizeof 取对象占用字节数 new, new[] 动态内存分配/动态数组内存分配 delete, delete[] 动态内存释放/动态数组内存释放 4 .* ->* 在对象上通过指向成员的指针访问成员/在指针上通过指向成员的指针访问成员 自左向右 5 * / % 乘法/除法/取余 6 + - 加法/减法 7 << >> 按位左移/按位右移 8 < <= 小于/小于等于 > >= 大于/大于等于 9 == != 等于/不等于 10 & 按位与 11 ^ 按位异或 12 | 按位或 13 && 逻辑与 14 || 逻辑或 15 ?: 三目运算符 自右向左 16 = 赋值 += -= 相加后赋值/相减后赋值 *= /= %= 相乘后赋值/相除后赋值/取余后赋值 <<= >>= 按位左移赋值/按位右移赋值 &= ^= |= 按位 与/异或/或 运算后赋值 17 throw 抛出异常 18 , 逗号 自左向右
- 维持原有操作数个数;
- 只有已经存在的运算符才能被重载(你不能自己创造一个运算符比如"**"说“啊我这表示"乘幂"运算”,这是不行的);
- 我们前面说"重载运算符需要我们自己写函数去改变运算符的行为",那个函数其实就是个普通的函数,但是前面要加上关键字"operator",函数名是我们要重载的运算符的符号:
operator *(...) //重载乘号(*)运算符- 这样的一个函数可以是一个成员函数,比如:
const String String::operator +(const String& that); /*加法"+"原有两个操作数;而这个重载函数作为成员函数有一个隐藏参数"this", 再加上参数表里的"that"刚好也是两个操作数,符合运算符重载要求*/
- 也可以是一个全局函数(自由函数),比如:
const String operator +(const String& l, const String& r);
//作为全局函数参数列表里就得有两个参数了9.1、如何实现运算符重载:
- 作为成员函数:
- 不会在接收者(receiver)上做类型转换;
- 必须可以访问类的定义(必须获得那个类的代码才可能在那个类的代码基础上做修改,才能为它做出一个重载的运算符函数来);
#include <iostream> using namespace std; class Integer { private: int i; public: Integer(int n = 0) : i(n) { cout << "now in Integer:: Integer(),address is " << this << ", and i = " << i << endl; } ~Integer() { cout << "now in Integer::~Integer(),address is " << this << ", and i = " << this->i << endl; } const Integer operator+(const Integer& n) const { return Integer(i + n.i); //返回的由 this->i 加上 n.i 的值构造来的新的Integer的对象 } /*加法运算是不会修改两个算子的值的,所以我们重载的"对象加法"在理论上也是不会 去修改对象算子的值的。所以operator+函数的参数是个const的引用,同时函数本身也 被const修饰表示“我这个函数不会去动成员变量”(this是const)。此外函数作为Integer 的对象加法,返回的也是个新的Integer类的对象本身,而且返回值也加了const修饰以 避免作左值使用(普通的加法运算我们也没有拿来作左值吧,那样编译肯定报错;那我们 重载的加法运算在设计时也应当遵循这一点)*/ int print() { return i; } }; int main() { Integer x(1), y(5), z; /* Integer test = 7; //这是初始化,会直接用7构造test test = 7; //这是赋值,会用7构造出一个Integer的中间对象,然后做对象赋值,然后析构中间对象 再次强调了C++里初始化和赋值有很大不同 */ z = x + y; //x.operator+(y) cout << "z.i = " << z.print() << endl; //但是如果你没有用const修饰operator+函数的返回值的话那还是可以做这样的事的: //z = x + y = 10; /*首先z、x + y返回的对象跟整数10显然类型不一样,编译器会先用10来构造一个临时 对象(假设是@tmp,这个我们是看不到的);接着会进入我们写的运算符重载函数,在函 数return那儿构造一个返回的对象;然后做自右向左做赋值运算,运算完成后分别析构 掉operator+函数返回的那个对象以及临时对象@tmp。直到这时这句代码才整个执行完毕! 最后会得到z.i = 10。*/ return 0; }运行结果:

-
所谓"不会在接收者(receiver)上做类型转换",以上方代码为例:是指编译器发现"+"号的左边是一个Integer的对象(x),我们称运算符的左边那个算子叫"接收者(receiver)"。对于存在重载的运算符来说:它在整个运算事件中起到“决定用哪个运算功能来做本次运算”的作用!然后整个事件中跟需要的类型不匹配的算子就会在编译时被转换为需要的类型;而接收者(receiver)自己显然不会做类型转换。
z = x + y; //it's OK! 对象x决定了本次使用重载的"+" /*x.operator+(y);*/ z = x + 3; //it's OK! /*对象x决定了本次使用重载的"+",但x跟整数3显然类型不一样;此时编译器会先用3构造一 个Integer的匿名对象(因为Integer类刚好有这么一个接收1个int的构造函数,如果没有的 话那么这句代码就会报错),然后把这个匿名对象交给operator+(const Integer& n)重载 运算符函数去做"加"的运算,算完后赋给z。最后分别析构operator+函数返回的那个对象以 及用3构造的那个匿名对象*/ z = 3 + y; //ERROR:没有与这些操作数匹配的"+"运算符 /*整数3决定了本次使用系统的"+",但上面代码里没有提供将Integer对象y转变成整数的手 段,后面还会讲到我们其实可以做出这样一个手段来,使这句代码不会报错。 这个手段先简单透露一下:就是做出一个把你这个类的对象变成其他类型的对象的函数来*/ z = x + 3.14159; //warning:“参数”: 从“double”转换到“int”,可能丢失数据 /*这句同样可以运行,编译器会先将“double”转换成“int”,接着用转换后的int去构造一个 Integer的匿名对象,然后做"加"的运算,然后赋给z。不过就像warning中说的那样,可能 丢失数据*/ z = 3 + 3; //it's OK! /*整数3决定了本次使用系统的"+",所以编译器不会用这两个3去构造出Integer的匿名对象 后调用我们写的operator+函数,而是直接做整数加法;加完后等效于"z = 6;"。对象z决定 了赋值运算是对象赋值,所以编译器会用6构造一个Integer的匿名对象然后交给z嘛*/ Integer test = x + 3; //it's initialization not assignment! But there is no copy construct /* 1、用3构造一个Integer的匿名对象 2、进入operator+(const Integer& n)函数 3、在operator+函数return那构造返回的那个对象 4、将返回的对象交给了test 5、析构用3构造出来的那个匿名对象 6、结束 7、感兴趣的小伙伴可以把这句代码复制到上面可运行的代码段里测试 */ -
使用成员函数重载一元的运算符,那就不需要有参数了,比如重载"取负"运算符:
const Integer operator-() const { return Integer(-i); /*符合一般的取负思想:拿原本对象的值取负后产生新的对象输出 而不是直接对原本的对象取负,取负运算不改变算子的值的*/ } ... z = -x;
- 作为全局函数:
- 还是以重载"+"运算符为例:参数列表就需要两个参数了;
- 不再需要对类的访问了(不修改那个类的代码就能为它做出一个重载的运算符函数);
- 前提是能接触到类里面的成员(也许可以把全局函数设置为"friend");
class Integer { friend const Integer operator+ ( //在类里面声明为friend const Integer& lhs, const Integer& rhs); ... }; const Integer operator+ ( //作为friend可以访问成员变量i const Integer& lhs, const Integer& rhs) { return Integer( lhs.i + rhs.i ); } - 这个时候在两个参数上都可以做类型转换;
z = x + y; //it's OK! z = x + 3; //it's OK! z = 3 + y; //it's OK! /*虽然这个时候接收者(receiver)是整数3,但是编译器发现3 + y不能用 整数的加法来做,而且编译器还发现把3变成Integer的对象是可以做对象加 法的。于是编译器就会用那个重载的加法(可见编译器还是会尽力让代码能 跑起来的,哈哈)。*/ z = 3 + 3; //it's OK!
9.2、成员函数 or 全局函数?
- 一元(也称单目)运算符重载应该做成成员函数;
- = () [] -> ->* 这些运算符重载必须做成成员函数;
- 其他所有的二元运算符重载都做成全局函数;
10、运算符重载——原型(prototypes):
上一章讲了我们怎么去做出一个运算符重载函数来,接下来我们去关注另外的一些点:
- 既然函数是重载来的,那我们关心它的原型是怎样的;
- 我应该以什么样的方式传参数进去以及返回值出来;
- 一些特殊的运算符(比如赋值运算符=、数组下标运算符[])怎么做;
- 先说以什么样的方式传进传出:
- 我们在上一章说"运算符必须在类(class)类型或枚举(enumeration)类型上被重载;",然后只展开讲了类类型上做运算符重载。这个时候传进去的参数肯定是个对象,在《5.2、Const reference parameters》小节中我们说"对一个函数传进传出整个对象时推荐使用引用"。所以传进去参数的形式肯定是引用毋庸置疑了,然后再针对那个运算符会不会修改算子决定是否使用const修饰引用(比如 ++ -- += -= 都会修改算子,它们重载时传的参就不要使用const引用);
- 传出返回值时我们关心两点:
- 返回值会决定我们重载的运算符的运算结果是对算子本身做了修改并返回算子本身,还是做了个新的对象出来;
- 如果是做了新对象出来,那制造出来的那个新的对象是否可以做左值;
- 比如说赋值(a = 6)运算是修改了自己(a),所以重载的函数后面不能跟const;同时返回的也是自己;而且赋值的东西还可以继续被赋值(a = b = c = 1;我们知道返回基本类型的函数不能作左值),所以我们重载的函数只能返回一个引用,而且可以作左值。
- 又比如说数组下标(a[6])运算,这个运算结果是可以作左值嘛(a[6] = 1;),所以一定返回的是个引用。
- 还比如说逻辑运算(&& || !)和关系运算(> < == 等)都肯定返回一个布尔量(bool)。
- 接着我们来看看一些运算符原型:
- + - * / % ^ & | ~:
- const T poeratorX(const T& l, const T& r) const;
- ! && || < <= == >= >:
- bool operatorX(const T& l, const T& r) const;
- [ ]:
- T& T::operator[](int index);
- + - * / % ^ & | ~:
- ++ --(我们知道++ -- 有前缀后缀之分,我们重载时也需要让编译器能区分它们):
class Integer {
public:
const Integer& operator++(); //前缀++(prefix++)
const Integer operator++(int); //后缀++(postfix++)
const Integer& operator--(); //前缀--(prefix--)
const Integer operator--(int); //后缀--(postfix--)
...
};
/*
int参数的作用只是让编译器知道哪个是prefix,哪个是postfix;
int不会真的被传到函数里面去,不会真的起作用,只是为了让编译器能够区分,
编译器调用时会给它传0作为参数。
而我们看到一个返回的是引用,一个返回的是新对象:
1、++a我们知道返回的就是a加了以后的结果,也就是a当时的结果,
所以返回a的引用就可以了;而且是const( ++a = 6; 这是不行的)
2、a++返回的是加以前的结果,所以a++做完之后a已经不是a加1以前的
那个结果了,所以返回引用是没有用的;
我们写重载就要像下面这样:
*/
const Integer& Integer::operator++() {
*this += 1;
return *this; //*this对象的引用返回出去
}
const Integer Integer::operator++(int) {
Integer old(*this);
//*this是一个对象,用来初始化另一个对象我们知道会发生拷贝构造
++(*this); //使用前缀++实现后缀++
return old;
/*你只能return新的对象出去而不是引用,因为如果return本地变量的引用
我们都知道离开函数本地变量就不存在了*/
}- 类似于前后缀 ++ 实现,我们同样使用 == 来实现 != ;用 < 来实现 > >= <= :
//Integer.h
#ifndef __INTEGER_H__
#define __INTEGER_H__
class Integer {
private:
int i;
public:
bool operator==(const Integer& rhs) const;
bool operator!=(const Integer& rhs) const;
bool operator <(const Integer& rhs) const;
bool operator >(const Integer& rhs) const;
bool operator<=(const Integer& rhs) const;
bool operator>=(const Integer& rhs) const;
};
//重载为来判断不同对象间成员变量i是否相等
bool Integer::operator==(const Integer& rhs) const {
return i == rhs.i;
}
//通过 !(lhs == rhs) 实现 lhs != rhs
bool Integer::operator!=(const Integer& rhs) const {
return !(*this == rhs);
//在return时调用重载的operator == 函数
}
//重载为来判断lhs的i是否小于rhs的i
bool Integer::operator <(const Integer& rhs) const {
return i < rhs.i;
}
//通过 lhs < rhs 来实现 lhs > rhs
bool Integer::operator >(const Integer& rhs) const {
return rhs < *this;
}
//"小于等于"就是"不大于"嘛,对大于返回的结果取反即可
bool Integer::operator <=(const Integer& rhs) const {
return !(rhs < *this);
}
bool Integer::operator <=(const Integer& rhs) const {
return !(*this < rhs);
}
#endif我们看到实际上只有两个“函数原型”( == 的重载和 < 的重载),其他的重载都是通过调用他俩的重载实现的,为什么要这样做?
这是为了以后修改起来方便,在上半部分学习笔记开篇我们就说"尽量将自己的代码构筑在已有代码的基础上",这里其实也在做减少代码复用的工作。万一有一天我们要修改这些重载函数的行为时,我们只用改 == 的重载和 < 的重载就行了,其他的都是跟这俩联系在一起的(比如说某天我不想用重载的 < 比较成员变量i了,我想去比较另外一个成员变量j。那我只用修改重载的 < 就可以了)。
而且定义在头文件里的这些函数默认内联(Inline),我们也不必担心多次调用带来的性能损失,因为我们知道编译器不会真的去调用内联函数的。
- 数组下标运算([ ])原型我们已经知道了,接下来尝试重载它:
- 在《9.2、成员函数 or 全局函数?》小节我们说 [ ] 的重载必须做成成员函数;
- 根据原型我们知道重载函数的参数只有一个(single argument);
- 重载 [ ] 的场合一般是当我们的类是用来表达一种"容器"的概念时,我们可以通过下标访问类里面的东西(普通的通过下标访问对象数组中的某个对象不用重载都可以这么做了);
Vector v(100); //创建一个100大小的Vector对象 v[10] = 45; //通过下标访问里面的东西- 这样的一个 [ ] 一定返回的时成员类型的引用,所以可以拿来作左值;
//Vector.h
#ifndef __VECTOR_H__
#define __VECTOR_H__
class Vector { //Vector表现为一个"容器",里面装了个数组成员
private:
int m_size;
int* m_array;
public:
Vector(int size) : m_size(size) {
m_array = new int[size];
}
~Vector() { delete m_array; }
int& operator[](int index) { return m_array[index]; }
};
#endif // !__VECTOR_H__
11、运算符重载——赋值:
我们在《6.1、Constructions vs Assignment》小节强调过"初始化和赋值是有很大不同的",其中 a = aa; 是赋值,a和aa都是A类的一个对象。但如果我们想重载一个不同类的对象间的赋值呢?
#include <iostream> using namespace std; class B; class A { public: A(int i) { cout << "Now in A(int ii)" << endl; } A(const B&) { cout << "Now in A(const B&)" << endl; } }; class B { public: B() {} }; int main() { A a(0); B b; A aa = b; /*因为A类有一个接收B的对象的引用的拷贝构造, 所以这里会直接用b构造aa,而不会发生赋值操作*/ aa = b; //这里会先用b构造一个A类的中间对象来,然后赋给aa return 0; }运行结果:
我们在第9章和第10章都还没有重载过"赋值"(=)这个运算符,只是简单地提了一下它的重载应该做成什么样。"赋值"(=)这个运算符是特殊的,特殊的点在于:
- 如果我们没有提供赋值(=)的运算符重载,编译器会自动创建一个。自动创建的这个重载提供的是成员级别的赋值(memberwise assignment);
- 赋值(=)运算符重载:
- 必须是成员函数(《9.2、成员函数 or 全局函数?》小节说过);
- 如果你没有提供重载,编译器会自动创建一个;
- 这和我们在《6、拷贝构造》一章中说的那个自动创建的拷贝构造是一样的行为:都是成员级别上的赋值
- 应该对自我赋值进行检查(自己给自己赋值);
- 确保分配给所有的数据成员;
- 应该返回一个*this的引用(在《10、运算符重载——原型》一章中说过);
T& T::operator=(const T& rhs;) {
//check for self assignment
if (this != &rhs) {
//重载的赋值代码
}
return *this;
}为什么需要对自我赋值进行检查呢?自己给自己赋值看起来并不会有啥危险呐?我们来看看下面这种情况:
class A { char* p; A& operator=(const A& that) { delete p; /*不同对象的字符串大小可能不一样,在赋值时就要delete掉this.p; 然后开辟一个跟that.p一样大的新的空间放that.p,这样才能做字符串的赋值。*/ p = new char[strlen(that.p) + 1]; strcpy(p, that.p); return *this; } };如果这个时候 that 就是 this 的话,那 delete p; 就直接把 this 和 that 的 p 都delete掉了( this.p 和 that.p 是同一个东西嘛)。所以赋值(=)运算符重载的标准写法就得对自我赋值进行检查。
- 那什么时候需要重载赋值(=)运算符呢?
- 对于类来说如果里面有动态分配内存的东西,我们就需要写一个赋值(=)运算符的重载(和一个拷贝构造);如果没有动态分配内存的东西(没有指针)全都是成员对象,那么可以不写。
- 如果担心系统做的行为不正确,我们可以把赋值(=)运算符重载声明为private。但这代价很大,声明为private意味着我们的类的对象就不能被赋值了。
12、运算符重载——类型转换:
有的时候我们会做一些类用来表达值的(称之为value class):
- 表现为基本数据类型;
- 可以被函数传进传出;
- 通常需要能与其他类型做类型转换(比如我们自己写了个"分数"类,那分数显然是可以跟double类型做转换的);
那么这样的一种类一般就需要有重载的运算符(比如说我们写了一个"复数"类,复数有复数的加法,那我们需要提供operator+())。
- 一个"转换"运算符能够用于转换一个类的对象为:
- 另一个类的对象;
- 内置(built-in)类型;
- 编译器会执行隐式转换当我们使用:
- 单参数构造函数;
class B { public: B() {} }; class A { public: A(int i) {} A(const B&) {} }; void f(A) {} int main() { A a; B b; a = 1; //隐式类型转换 f(b); //隐式类型转换 return 0; } /*如果你不希望编译器自动去做这些隐式转换, 你可以在A类的单参数构造函数前面加上"explicit"(显示)关键词。 比如 explicit A(const B&) {} 这是在告诉编译器我这个构造函数只能作构造函数,不能用于自动转换类型 那调用f()函数就得改成 f(A(b)) */ - 隐式类型转换运算符;
- 单参数构造函数;
- 除此以外,我们还可以重载一个专用的类型转换函数:
- 函数会被自动调用;
- 返回类型和函数名相同(因此不需要提供返回类型了);
- 这样一个函数一定是把*this转变为目标类型,而不是把that转变成this什么什么的;当然函数得是const的,因为我们只是把this转换掉了,this本身并没有改,我们只是去做了个新的目标类型的对象出来。就像上面的代码执行完 f(b) 之后,b还是b嘛,它的类型并没有因此改变。
- X::operator T () const;
- 类型转换函数的重载形式一般是这样;
- 没有返回类型;
- 没有显式参数;
- 函数名就是目标类型;
- 编译器会用它来做 X 的对象到 T 的类型转换;
有了这个东西,我们可以再次整理下C++里的类型转换:
我们看到对于 T=>C 我们有两种方法可以实现,如果我们在代码里将这两种方法都提供出来了的话,那在编译器执行 T=>C 类型转换的时候就会报错。因为编译器不知道究竟要调用哪个去做类型转换,这两个方法是没有优先级一说的。
这个时候解决方案当然就是去掉其中一种类型转换方法了,我们在上面个就提供了一种简单方法就是对C类中接受T的对象的那个单参数拷贝构造添加"explicit"关键词修饰,告诉编译器我这个构造函数只能作构造函数,不能用于自动转换类型。

12.1、是否要使用自动类型转换?
- 一般来说,不要。有时候我们可能没有想要去做类型转换,但是编译器自动去做了,这可能带来某些问题。
- 尽量使用显式的类型转换函数,比如我们可以声明这样一个成员函数:
它就是个普通的成员函数,不会自动被调用,当我们需要把对象转成double的时候调用它就可以了。double toDouble() const;
13、模板(Template)Ⅰ:
现在我们要设计两个"列表"(list),一个用来放类型X;另一个用来放类型Y。那么显然这两个列表用的代码应该很相似(都是列表嘛),他们的唯一区别在于列表中存放的类型是不一样的。那么我们有几种方法来实现这两个列表:
- 我们期望X、Y有一个共同的基类(这也许是不可取的:比如X是苹果类,Y是榔头类,那它们的共同基类只能是"东西",显然它们没法归到一个合适的基类中);
- 克隆代码(笨办法,难以管理和维护代码,但可以保证类型是安全的);
- 先做一个没有类型的列表(比如做一个放"void*"类型的列表,然后你把X和Y的指针交给我都可以;但这样显然类型不安全。因为这样的列表可以放任何东西嘛,取出来的时候我们也不知道到底取出来的是X还是Y);
- 使用模板(template):
- 模板提供了另外一种重用代码的方式,这个时候"类型"(type)成为了模板的参数;
- 可以做 template class 或者 template function ;
- 准确来说是四种东西:
- class template:是一种模板,用于做出类,称为"类模板";
- template class:是一种用模板做出来的类,称为"模板类";
- function template:是一种模板,用于做出函数,称为"函数模板";
- template function:是一种用模板做出来的函数,称为"模板函数";
- 但是一般不会做这么严格的区分。实际上当我们说"类模板"和"模板类"的时候,可能说的是同一种东西:都指的是模板而不是用模板做出来的东西;
13.1、函数模板(function template):
比如我们用swap交换函数来做一个函数模板:
void swap( int x, int y ) { //swap函数
int temp = x;
x = y;
y = temp;
}
template < class T >
void swap( T& x, T& y ) { //swap函数模板
T temp = x;
x = y;
y = temp;
}
/*
1、template关键字表明这是模板,表示template关键字往下一行的东西就是template
(下一行如果是函数,那个函数就是template;如果是类,那个类就是template);
2、class T指定了参数化的类型名(可以是任何内置类型或者用户定义类型);
3、在模板内使用 T 作为类型名;
4、class是关键字,T不是,你可以换任何你喜欢的。就像int i和int j我们知道都是表示一个int;
5、参数类型class T可以代表:
· 函数的参数类型;
· 函数的返回类型;
· 在函数内声明变量;
*/使用模板就很简单了,就像调用普通函数那样就可以了
int i = 3; int j = 4;
swap(i, j); //使用显式int交换(因为我们提供了int的swap)
float m = 4.5; float n = 3.7;
swap(m, n); //使用实例化的模板函数做float交换
//(编译器会在我们调用时用模板做出模板函数来)
std::string s("Hello");
std::string t("World");
swap(s, t); //使用实例化的模板函数做std::string交换
swap(i, m); //ERROR:使用模板不会做类型转换(即便是隐式转换也不会做)编译器帮我们实例化模板函数时其实就是自动写了个重载嘛,编译器在我们使用模板过程中会遵循一些规则:
- 首先检查唯一函数匹配(就像 swap(i, j); );
- 如果没有再检查唯一函数模板匹配(就像 swap(m, n); 和 swap(s, t); );
- 然后去做重载;
- 还有一种情况是我们在函数模板内没有使用T,就需要通过显式类型调用模板:
template < class T >
void func( void ) { ... }
func<int>(); //type T is int
func<float>(); //type T is float
13.2、类模板(class template):
即类型参数化的类:
- 从被操作的类型中抽象操作;
- 定义潜在的无限的类集合;
- 迈向重用的另一步;
- 类模板中的每一个函数都是函数模板;
典型应用:容器类 Container class 。
先来看一下怎么写类模板:
template < class T >
class Vector {
//整个Vector是一个template,这是一个每一个元素都是T类型的"向量"容器
public:
Vector(int); //单参构造
~Vector(); //析构
Vector(const Vector&); //拷贝构造
Vector& operator=(const Vector&); //赋值运算符重载
T& operator[](int); //数组下标运算符重载,使用T的引用做函数返回类型
private:
T* m_elements; //使用T声明成员变量
int m_size;
};
template < class T >
Vector<T>::Vector(int size) : m_size(size) { //::解析符前面类的名称也要写成Vector<T>
m_elements = new T[m_size];
}
template < class T >
T& Vector<T>::operator[](int index) {
if(index < m_size && index >= 0) {
return m_elements[index];
}
else{
...
}
}使用类模板:
Vector<int> v1(100); //T是int类型,100是构造函数的参数
Vector<Complex> v2(256); //T是Complex类类型
v1[20] = 10;
v2[20] = v1[20];
/*如果定义了int=>Complex类型转换就可以这么做。
必须是Complex中有个接收一个int的构造函数,因为不会有int::operator Complex() const;*/14、模板(Template)Ⅱ:
我们来做一个排序函数(sort function)模板:
//冒泡排序
template < class T >
void sort (Vector<T>& arr) {
const size_t last = arr.size() - 1;
for(int i = 0; i < last; i++) {
for(int j = last; i < j; j--) {
if(arr[j] < arr[j - 1]) {
swap(arr[j], arr[j - 1]);
/*在13章的学习中我们知道Vector<T>::operator[]返回类型是T&,
所以这里是在做T的交换,而T是什么类型现在还没有定下来*/
}
}
}
}
/*可以看到sort本身就是个函数模板,而这个模板里还要用到swap模板实例化出来的swap函数
这里编译器会不会先去做出一个实例化的swap重载取决于编译器本身*/使用该模板:
Vector<int> vi(4); //Vector of int,并初始化对象vi
vi[0] = 4; vi[1] = 3; vi[2] = 7; vi[3] = 1;
sort(vi); //sort( Vector<int>& )
Vector<string> vs; //Vector of string
vs.push_back("Fred"); //这里只是举例哈,Vector类中没有提供push_back这个成员函数
vs.push_back("Wilma");
vs.push_back("Barney");
vs.push_back("Dino");
vs.push_back("Prince");
sort(vs); //sort( Vector<string>& )还有件小事需要注意的是:我们在sort函数模板中使用小于号(<)来实现冒泡排序,对于int、string这种系统类库中的类型都还是没啥问题的,但如果你要对自己定义的类型的对象做排序却没有在类里面提供小于(<)运算符重载的话,那么编译器会报错。
- 此外我们还可以有多个类型参数:
template< class Key, class Value > class HashTable { const Value& lookup(const Key&) const; void install(const Key&, const Value&); ... };
Vector< Vector< double * > > //Vector of Vector of double *这表示有一个Vector,这个Vector中每一个单元都是一个Vector;那个Vector中每一个单元都是一个double的指针。后面的两个大于号最好中间用空格隔开以跟"按位右移"(>>)运算符做区分。
Vector< int (*)(Vector<double>&, int)> //Vector of function pointer这表示有一个Vector,它当中每一个单元都是一个函数指针,函数指针指向的函数返回一个int,参数表包含两项:第一项是一个每个单元都是一个double的Vector的引用;第二项是一个int。
14.1、表达式参数(Expression parameters):
模板的参数可以有变化,可以接受其他类型的参数/变量。比如:
template < class T, int bounds = 100 >
//模板还可以有一个int类型的参数bounds,在模板内可以使用,而且我们给了它一个默认值是100
class FixedVector {
public:
FixedVector();
T& operator[](int);
private:
T elements[bounds]; //fixed size array!
};使用该模板:
FixedVector<int, 50> v1; //50个int的数组v1
FixedVector<int, 10*5> v2; //50个int的数组v2
FixedVector<int> v3; //100(默认)个int的数组v314.2、模板 × 继承(Template & Inheritance):
template < class A >
class Derived : public Base { ...这表示:"我们做了个类模板,将来这个类模板实际种下去的时候做出来的实际的类都是Base类的子类"。
(注:"种下去"/"种出来"都表示"用模板做一个实际的东西(类或者函数)出来的意思")
- 继承自模板类(通过模板种出来的实际的类)的类模板:
template < class B > class Derived : public List<A> { ... //继承自List of A //没有继承自模板的模板或者说是模板间不存在继承关系 - 继承自模板类(通过模板种出来的实际的类)的非模板(普通)类:
class SupervisorGroup : public List<Employee*> { ... //非模板类不能继承自模板 Non-template classes can inherit from templates
14.3、思考题
- 现在假设我们有一个类模板,我们用它种出了几个东西。比如:
FixedVector<int, 50> v1; //50个int的数组v1 FixedVector<int, 10*5> v2; //50个int的数组v2 FixedVector<int> v3; //100(默认)个int的数组v3现在提出问题:v1和v2我相信它们是同一个类型的,那v2和v3是同一个类型的吗?
假设我们现在有一个a.h文件,里面放了个函数模板f()。然后我们有两个.cpp文件中
#include "a.h"我们假设一个是b.cpp;一个是c.cpp。我们在b.cpp里种了个 f of int ;在c.cpp里同样种了个 f of int 。现在提出问题:这两个.cpp种了(生成了)几个 f of int 给我?编译会不会通过?
15、异常(Exception)的基本概念:
C++的"基本哲学"认为"你写的不好的代码不应该被运行",所以和C相比C++多了很多编译时刻的检查。但是也没有啥都能够在编译时刻做完的,总是有一些事情是发生在运行时刻的,这些事情是编译时刻无法预知的。所以,能够处理未来运行时刻的所以可能发生的情况是非常重要的。这就需要编程语言提供给我们一些手段让我们知道:"不正常的事情发生了"
比如我们要写一个读取文件内容到内存中的代码,大体上是通过以下几个步骤实现:
- 打开文件;
- 确定文件大小;
- 分配同样大小的内存空间;
- 把数据从文件读到内存中来;
- 关闭文件;
我们在C其实就做过文件读写的操作了。而且我们知道上面几个步骤中每一步在运行的时候都是有可能发生问题的,而且这些问题大多其实并不是程序的问题,是由外界的一些情况带来的问题。
比如我要打开一个文件,但是那个文件是不是真的存在呢?是不是正在被其他进程占用呢?又比如我们分配同样大小的内存空间时如果那个文件是一部4K Blue-ray电影有10多个G那么大,我们还能分配出同样大小的内存空间么?内存条还够用么?而且一般Windows平台下我们最多也就能够得到系统分配给我们的两个G的空间。这都不是我们代码的问题。
所以我们的程序中有没有去处理运行时刻的这些事情,有没有去应对所有可能发生的情况,是衡量程序"健壮性"的重要标准。
在C里面其实也有在尝试做这样的事情:C对文件的操作函数往往会有特殊的返回值用于判断操作是否执行成功,但往往我们都没有用起来这些返回值。所以其实我们可以在C的基础上做出这样一个"健壮"的程序来:能够知道运行时刻所有发生的事情并且做出相应的处理。我们可以写出下面这样的代码:
可以看到C语言程序"健壮性"的实现方式其实就是:我们去调用任何函数都要判断它的返回值,根据它的返回值来决定下一步动作。这是一种实现程序"健壮性"的方式,虽然它已经被现代的软件工程否定了(因为它把正常值和异常值放在一起了;而我们希望它们是分开的,是两个不同的功能)。但无论怎么说,这是一段好的代码,只是我们可以认为它过时了。
C++里面通过另外一种更好的机制实现程序的"健壮性"——异常:我们预料到有些事情在运行时刻会发生,但不是一定会发生,我们通过异常机制来处理。
于是,代码变成了下面这样:
try{ open the file; //我们把正常的事务逻辑放在一起; determine its size; //任何人一看这段代码就能明白我们要做什么样的一件事情; allocate that much memory; //五个步骤一目了然; read the file into memory; //然后我们把它们放在一个try的block里面; close the file; //表示我们来"尝试"着做这样一件事情; }catch( fileOpenFailed ) { do something; }catch( sizeDeterminationFailed ) { do something; }catch( memoryAllocationFailed ) { do something; }catch( readFailed ) { do something; }catch( fileCloseFailed ) { do something; } /*如果在做这五个步骤的过程中出现了什么问题, OK那我们就离开这五句话,离开这个try block; 根据后面的catch来决定采取什么样的行动。 这样的一种手段就叫做"异常机制"(exception), 实现对 运行过程当中可能出现的问题 的管理*/所谓异常机制,在某个时刻,当问题发生时,我们也许不知道该怎么解决(比方说文件打不开我们的程序能解决吗?不能;读文件读到一半失败了,我们的程序能采取什么措施使它能够读成功吗?也不能)。这些问题可能需要人为干预,也可能需要更高层的程序来做处理;但至少在目前我们这个程序中,在我们这五个步骤当中,我们不知道应该怎么做。
但是,我们唯一可以确定的是:我们不能让程序就这么悄无声息地继续运行下去了!比如打开文件失败了,那之后的步骤都是没有意义的;分配内存空间失败了,那之后读文件也是没有意义的。所以即便我们不知道该怎么解决也必须停下来!有别的人,在某个地方,他们必须要do something去解决这些问题,来告诉这个程序应该怎么做!这就是exception(异常)。
我们通常用异常来表达我们程序运行过程当中由于外界的因素而导致程序无法正常运行下去的那种情况。

15.1、Why exception?
- 显而易见的好处就是异常提供了清晰的错误处理代码,由上面两段代码我们能够清楚地感觉到异常机制把业务逻辑和错误处理分得很清楚:业务逻辑5句话,错误处理五个catch。任何人看那段代码都能一目了然;
16、异常的抛出与捕捉(throw & catch):
回到我们在《13.2、类模板》中用的那个类模板例子:
template < class T > class Vector { //整个Vector是一个template,这是一个每一个元素都是T类型的"向量"容器 public: Vector(int); //单参构造 ~Vector(); //析构 Vector(const Vector&); //拷贝构造 Vector& operator=(const Vector&); //赋值运算符重载 T& operator[](int); //数组下标运算符重载,使用T的引用做函数返回类型 private: T* m_elements; //使用T声明成员变量 int m_size; }; template < class T > T& Vector<T>::operator[](int index) { if(index < m_size && index >= 0) { return m_elements[index]; } else{ ... } }当时我们写T& Vector<T>::operator[](int index)函数里面的else里面没有写代码,其实我们知道里面应该写数组下标越界时候的代码。我们可以以下面几种方法来写:
- 不解决,直接返回随机的内存对象(这显然不能接受);
- return m_elements[index];
- 返回一个特殊的错误值(C语言里一般这么干,但这意味着我们需要去检查返回值);
if (index < 0 || index >= m_size) { T* error_marker = new T("some magic value"); return *error_marker; } return m_elements[index];- 一旦发现下标越界,直接退出;
if (index < 0 || index >= m_size) { exit(22); } return m_elements[index];- 优雅地退出;
assert (index >= 0 && index < m_size); /*assert的意思是"如果assert圆括号里面那个表达式是错的,程序就要退出, 然后输出“assert failed”"。但assert一般是用来表达我们程序本身的代码错 误,所以用在这也不合适。因为导致数组下标越界不见得是代码错误,有可能是 其他原因造成的*/ return m_elements[index];- 使用异常(excption);
- 当这种情况发生的时候,我们"抛出"一个异常。告诉更上层的程序说"我们这出问题了"。我们这边不能解决这个问题,因为你给我一个越界下标我怎么知道怎样处理才能让它有效?这得你来出面解决这个问题,告诉我你到底想怎么办。
因此,我们需要一个新的关键字——"throw" 扔:我们发现数组下标越界了,我们就“扔”出一个东西,告诉别人说“这里出问题了”。
那我们能够“扔”些啥呢?对于C++来说,能够扔的东西是没有限制的,什么原始类型、什么对象 巴拉巴拉都可以扔。但一般我们更倾向于“扔”一个对象,因为我们可以用对象来表达:
- 每个对象都会有一个类型,通过这个类型可以知道到底发生了什么异常(是数组越界还是发生了除以0呢之类的);
- 身为对象可以携带数据(data),可以告诉我们异常内部究竟发生了什么(导致异常发生的那个index到底是什么呢);
当外界拿到我们“扔”出去的这样一个对象时,就会知道我们这边内部究竟发生了什么(比如外界就会知道里面发生的是数组下标越界,并且越界的下标是-1)。
所以常见的处理代码是这样的形式:
template < class T >
T& Vector<T>::operator[](int index) {
if(index >= m_size || index < 0) {
throw VectorIndexError(index); //VectorIndexError e(index); throw e;
}
return m_elements[index]; //没有越界就直接返回
}- 我们“扔”出去的那个对象(比如VectorIndexError类的对象)存放在堆栈、堆、全局数据区当中的堆栈里(毕竟是生成的本地对象嘛;而有且仅有new出来的东西会在堆里;全局变量、静态本地变量、静态成员变量会在全局数据区里)。虽然我们知道本地变量退出函数就不存在了,但是这只是我们不再掌握它们的意思,不代表它们物理意义上真的不存在了;而throw在退出的过程中其实是会带着异常对象的地址退出去的,所以对外界来说也是可以拿到这个对象的。
- 一旦抛出一个异常,就意味着throw以下函数内的语句都不可能被执行了。首先程序先看抛出的异常处在什么大括号内,如果处在某个函数的某条语句的大括号内(比如上面代码中的if语句),那这条语句整体就相当于一个throw。然后他要再去看这条if语句处在什么大括号内,然后发现是函数,那这条if语句以下函数内的语句将不会被执行。随后程序会离开发生异常的函数,回到调用函数的地方。如此循环往复直至退出到在try block内调用的那个地方,那个调用的语句整体就相当于一个throw,它以下的整个try block内的语句将不会被执行。再然后程序去看后面的catch有没有能够"捕捉"到它的。比如我们有个catch后面的圆括号说“我这个catch捕捉的是VectorIndexError&”,那我们这个catch就能够捕捉它。于是我们就离开了try block进入了catch,去做这个catch里面的事情。做完之后就不回去了,就接着往下走了(直接去执行整个try语句下面的东西了)。
这段话建议搭配教学视频第37课时(08:19~14:16)观看,仅用文字很难表达清楚的。
简而言之就是:程序一旦发生异常,它就会沿着调用的那条"链"不断地退出去,直到找到能够处理该异常的try-catch语句,然后这个异常才会在那个地方得到处理。
16.1、try-catch语句的一些其他情况:
1、还有一种情况是try-catch语句形式大体跟上面15章里的那个try-catch语句一样的,但是我们在catch大括号内加了句“不带任何东西”的"throw",这表示catch语句要把刚刚自己捕捉的异常对象再扔出去,就像下方代码那样:
这样的话意味着整个try-catch语句相当于一个throw,然后程序要再去看这条try-catch语句处在什么大括号内,然后发现是函数,那这条try-catch语句以下函数内的语句将不会被执行。随后程序会离开发生异常的函数,回到调用函数的地方。同样的循环往复直至退出到更外层的能够处理该异常的try block内。
这称之为"异常的传播" (Exception propagate)。
void outer2() {
String err("exception caught");
try {
func();
} catch (VectorIndexError) {
cout << err;
throw; //传递异常
}
}
/*有的时候我们是需要在catch block内再throw一下的,
因为有可能我这个catch语句处理该异常的层级不够(我
能够知道一些事情发生了,我可以做一些记录和小小的调
整,但是我还需要让更高层次的程序来解决问题)*/2、此外还有种情况是我们写一个catch可以捕捉到所有的异常。那整个语句基本语法应该是下面这样:
void outer3() {
try {
outer2();
} catch (...) {
// ... catches ALL excptions! ... 能够捕捉到所有的异常!
cout << "The exception stops here!" << endl;
}
}
/*这里别搞错了,...三个点并不是省略号的意思啊,不是我代码偷懒哈哈
...三个点是C++里面的语法,表示这个catch是个"万能捕捉器",所有的异
常类型都能被它捕捉*/不过一旦使用了 "..." 同时也就意味着我们拿不到那个异常对象了,因此 "..." 并不是一种很好的选择,而是我们无计可施之时的最后一张“底牌”。
16.2、异常的应用场合:
其实异常机制最常用的地方就是"输入输出",这个"输入输出"不仅仅是指键盘显示器的输入输出,包括网络,包括各种各样的通信手段都是"输入输出"。在这个过程中很容易出现由于外部硬件带来的问题,而往往我们发现这些问题的地方是非常底层的代码,而底层的代码通常只做本职工作。所以这个时候就需要抛出异常来告诉更高层次的代码"这里出问题了",至于怎么处理就交给上层"大佬"解决就行了。
比如我们的程序在给远端传输数据过程中中断了,一般会是最底层的代码发现数据传输中断了。这个时候我们一般想法是弹出个对话框嘛,告诉用户数据传输中断了。但这个工作应该交给最底层的代码做吗?是由最底层的代码来弹出对话框吗?那显然不是,一般我们会让更高层次的代码(比如负责UI界面的代码)来弹出这个对话框。
所以如果让最底层的代码去处理这些异常往往会混淆中间的界限,我们需要有异常机制不断地把底下的问题传播到上层。然后寻找一个适当的时机,寻找一个适当的代码来做出适当的反应。
17、异常语句:
通过前两章的学习我们知道了异常语句通常是这样一种形式嘛:
try { ... } catch() { ... } catch() { ... } ...我们已经知道的是:try后面有一对大括号{ },括号内的事情是我们要去尝试着做的。然后try后面要跟着一系列的catch,catch的数量可多可少,但至少得有一个。
而仅仅看catch很像一个函数对吧,它的圆括号就像函数的参数表,并且圆括号里面的那个变量是可以在catch的大括号{ }内使用的。当然catch我们也可以在圆括号内写个...,表示我这个catch可以处理所有的异常。
当存在多个catch时,那我们肯定去找:
1、完全匹配的catch来捕捉异常;
2、当然也可能会去看子类的异常对象能不能被父类的catch给捕捉到;
3、当然还有可能直接找到 "..." 匹配捕捉所有的异常。
这三个捕捉手段没有优先级顺序一说,先被哪个catch给捕捉到完全是看你写try-catch语句时书写的catch顺序的(编译器会按你书写的顺序从头到尾查找每一个catch是否符合这三个手段中的任意一个,一旦符合了就直接捕捉)。
所以这个时候按照上面的说法:假设我们有一排catch,我们把父类的catch书写在了子类的catch前面或者我们在这一排catch的最开头来了个catch(...);那子类的catch或者catch(...)后面的那些catch永远不可能捕捉到异常嘛,那它们的存在是没有意义的,所以这个时候编译会通不过。
17.1、异常规范(Exception specifications):
C++还允许做这样的事情:
void abc(int a) : throw(MathErr, VectorIndexError, ....) {
...
}
- 这是在声明函数abc可能会引发哪些异常;
- 作为函数原型的一部分,throw圆括号内允许一到多个类,表示这个函数里头在运行时刻最多也只会抛出圆括号里面的那些类的异常;
- 这是不会在编译时刻检查的内容(编译器不会去检查你调用abc的函数有没有去处理它可能抛出的异常);
- 这一点对Java来说不一样,在Java里这是会在编译时刻要检查的内容;
- 它的作用是用来约束函数abc的行为的:如果在运行时刻抛出了期望之外的异常,那么它会给一个异常——叫做"unexpected";
- 如果仅给了throw,圆括号内没有任何内容,代表我们约束函数不会抛出任何异常;
- 而没有这种约束(没有throw)的普通函数,是可以抛出任何异常的;
17.2、Exception & new:
假如我们在try block去做了new的工作(在C里面我们使用malloc动态分配内存,如果内存不够,malloc会返回一个null);但是C++的new永远不会返回一个null,如果内存不够了是直接抛出异常,那个异常叫做 "bad_alloc()" ),就像这样:
void func() {
try {
while(1) {
char *p = new char[10000];
}
} catch(bad_alloc& e) {
...
}
}17.3、构造函数内的异常(Failure in constructors):
如果在构造函数内发生了异常,我们知道构造函数不是主动调用的,我们怎么告诉调用构造函数的那个人"这里出了异常"呢?构造函数又没有返回值,那我们还是只有去抛出一个异常了,我们没有别的方式再去通知外面了。
但是我们需要知道的是:这是有很大风险的行为!
- 如果我们抛出异常的话,就意味着这个对象的构造没有完成;而没有完成构造的对象它对应的析构是不会被调用的;
- 如果我们抛出异常的话,别人拿不到我们打算构造出来的对象(因为我们知道一旦抛出异常程序就停止了嘛,throw下面的语句都不可能被执行),于是如果是new出来的对象,我们拿不到对象的地址,delete也不会执行。但是那块内存已经分配了,于是那块内存成为了“内存垃圾”;
17.4、异常的抛出和捕捉形式:
我们在《1、引用》开头就说过C++的内存模型十分复杂,对于异常机制来说也是这样:
struct X {}; struct Y : public X {}; try { throw Y(); } catch(X x) { //is it X or Y? }我们在《4、多态的实现》那讲到"在赋值过程中vptr是不传递的"那就做过一次子类对象交给父类对象的事情了。上面的代码其实就是"子类的异常对象被父类的catch给捕捉到"嘛,throw出去的是堆栈里面的对象,catch接收的是对象本身,这种情况我们知道那会发生切片(slicing)那样的事。
try { throw new Y(); } catch(Y* p) { //完犊子, 忘了delete了... }如果catch接收的是一个指针(通常如果throw的时候是new了一个东西出来的话,那我们会用指针来catch它),但这样千万别忘了delete它。因为过了这个catch就没有人知道这个p是什么了,所以一定要去delete它,但这样就把事情搞复杂了嘛。
try { throw Y(); } catch(X& x) { ... }所以我们更倾向于throw出去的是堆栈里面的对象,catch接收的是对象的引用。作为一个引用不会发生拷贝构造,也不会发生slicing那样的事。
18、流(stream)的概念:
"流"是一种做"输入输出"的方式:
- 在C里面我们用过printf、scanf;
- 在C++里面我们用cout、cin;
在Unix系统中所有的输入输出设备都用文件的形式来表达,在Linux中更是做到了"一切皆文件"。这样无论外部设备是什么样的,以什么样的速度和方式输入输出,在抽象为文件后对于文件我们都会有统一的操作(open、close、read、write...)。
而C语言是Unix的编程语言,所以我们在C语言里看到了有printf、scanf、fopen、fclose等那一系列对文件的操作的东西。还有一点是文件是可以分为文本文件和二进制文件的,在C的学习当中我们可能更熟悉的是一些文本的输入和输出。
C++通过"流"的方式来做"输入输出",来做文件的操作。这是在C的基础上又往前迈进了一步。因为"流"的好处是提供更好的"类型安全"(像C一些比较老的编译器是完全不检查printf双引号里面的内容的),而且会更加的面向对象(printf和scanf肯定是不能输入输出用户定义类的对象的嘛)。
但"流"还是有缺点:1、比较啰嗦;2、通常会比较慢;
18.1、C VS C++:
- 在C++里C的那些stdio的操作仍然是可以做的(这个我们在之前的一些章节中已经接触过了);
- 虽然可以做,但C++里的stdio操作没有提供面向对象的特性的,没有各种可以重载的运算符的;
- 但是在C++里,我们就可以重载 inserter 和 extractor 这两个运算符;
- inserter( << ):用于把一个对象插入到一个输出流里面去的运算符;
- extractor( >> ):把对象从流里面解析出来的运算符;
18.2、什么是"流"?
"流"即是对一个设备的公共逻辑接口。
"流"有两个特点:1、单方向;2、一维;
这和C里面的文件操作不一样的:对C来说,文件就是一个随机存取文件(random access file),我们可以在文件内的任意位置开始读和写;而C++的"流"意味着"流过去了就没有了",有一句哲学说“人不能两次踏进同一条河流”,因为我们下一次踏进河流的时候上一次的河水已经"流"走了。C++里的"流"就和河流很相像,你把它读掉了,它就没有了;你写进去了,它就流下去了。你不可能在任意的地方去读和写。
我们先来看看标准库中有哪些流是我们可以用的:

18.3、流的操作(Stream operations):
在"流"上面我们能够做什么操作呢?18.1小节我们介绍了"流"的两个运算符,这里再补充一个 Manipulator :
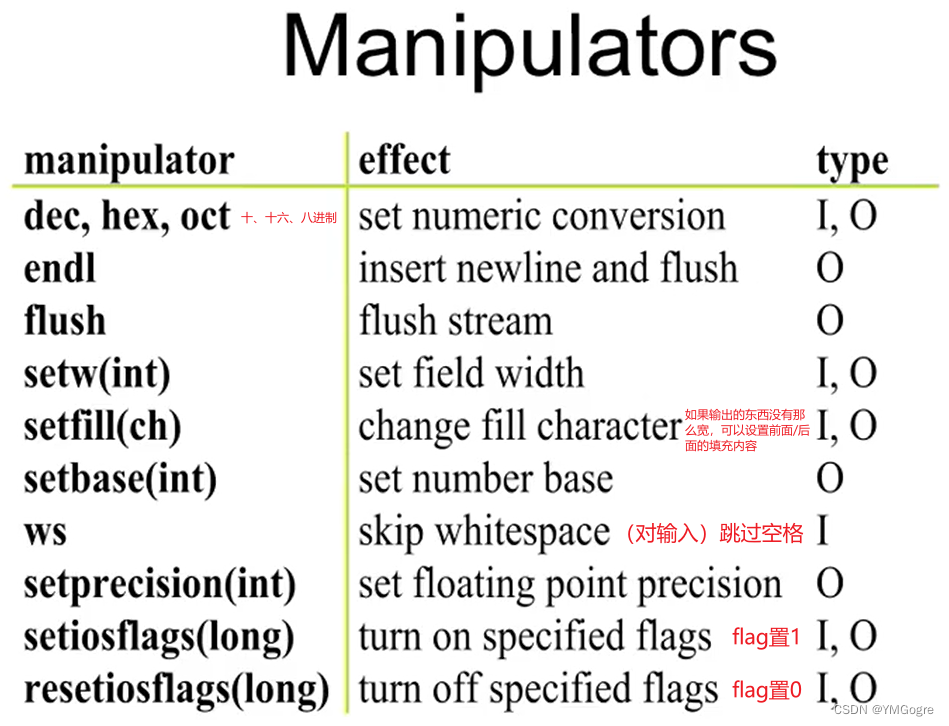
- Manipulator:用于改变流的状态(操纵流怎么样读,怎么样写的那些东西);
- 另外还有函数,在cin、cout这样的东西上面我们仍然是有函数可以去执行的;
18.4、流的种类:
- 文本流(Text streams):
- 处理 ASCII 文本;
- 文本文件的输入输出都需要经过解析(parse)或者格式化(format)的工作;
- 比如我们输入"1234",实际上我们输入的并不是"一千两百三十四"这个整数,我们在终端输入的其实是"1"、"2"、"3"、"4"这四个字符,然后这四个字符被系统类库中的某些程序"解析"成为"一千两百三十四",最后读到我们的变量里面的是"一千两百三十四"这个整数的二进制形式。
- 当我们输出的时候则是"格式化":我们有一个二进制的整数(对应十进制的1234),然后系统类库中的代码去把这个整数"格式化"为"1"、"2"、"3"、"4"这四个字符,然后输出到那个文本文件或者标准输出库里面去。
- 所以文本流执行的是一些字符转换操作;
- 二进制流(Binary streams)
- 真正的读写整数,对二进制数据操作;
- 没有字符转换操作啥的;
19、流的运算符(Stream operators):
C++的系统类库里预先定义了4个"流":
- cin
- 标准输入
- cout
- 标准输出
- cerr
- 标准错误 unbuffered error (debugging) output
- clog
- 标准日志 buffered error (debugging) output
19.1、>>(Extractors):
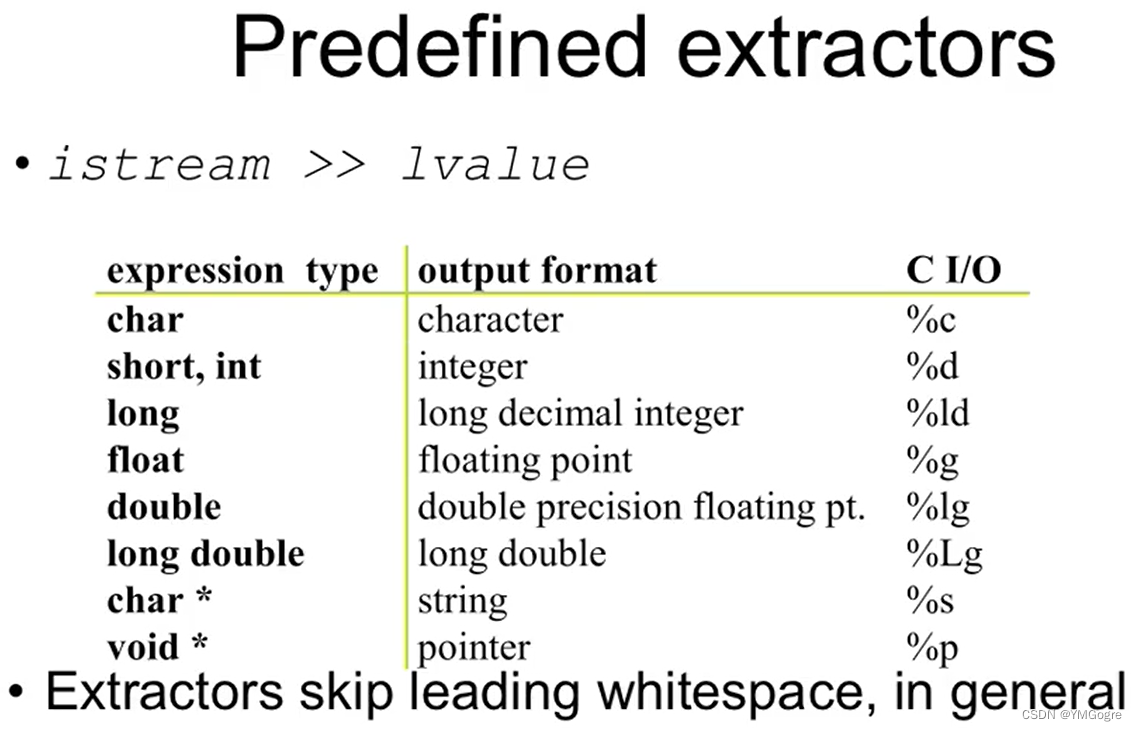
C++预先定义好了 istream 对 基本类型 的 >>(Predefined extractors),会根据我们提供的变量的类型来决定应该从文本里面"解析"一个什么样的东西出来给我们:
当然我们也可以自己重载一些 >> ,对自己定义的类型设计一个extractor,并且这样的一个extractor会做成一个全局函数:
- 它的第一个参数是一个 istream& ;
- 它的第二个参数是一个我们定义的类型的对象的引用;
- 它的返回值一定是一个 istream& ;
istream& operator>>(istream& is, T& obj) {
... //读取对象的特定代码
return is;
}
/*
第一个参数我们知道是接收者(receiver)(这个概念在《9.1、如何实
现运算符重载》小节介绍过)这个参数没有const。因为虽然我们只是去读这
个流,但是我们读到哪个位置了要变的嘛,所以我们其实是要去修改is的,所
以没有const。
而>>运算符是可以链接(chaining)起来的(cin >> a >> b >> c;),
所以返回的也是个istream的引用以接收istream对象的返回。
cin >> a >> b >> c; =====> ((cin >> a) >> b) >> c;
*/19.1.1、其他的输入运算符(Other input operators):
除了用 >> 以外,我们还可以使用函数,比如在cin上面使用get()函数来读东西:
int get() //返回int的get()函数
· 返回流中的下一个字符
· 如果没有剩余字符了返回EOF
· 函数是通过.的形式使用的
· 例如:把输入拷贝到输出流里面去
int ch;
while((ch = cin.get()) != EOF)
cout.put(ch);或者:
istream& get(char& ch) //get manipulator
· 把下一个字符放到参数里面去;
· manipulator意味着需要放在chaining里面用
· 返回 istream& 意味着可以和 >> 串着用,因为它们返回类型相同嘛
· 和int get();类似还有更多的就不详细介绍了,直接上图(它们都是istream类的成员函数):


19.2、<<(Inserters):
C++同样预先定义好了 基本类型 对 ostream 的 <<(Predefined inserters),所以对ostream我们可以插入以下这些类型的东西:

当然我们也可以自己重载一些 << ,对自己定义的类型设计一个inserter,并且这样的一个inserter同样会做成一个全局函数:
- 它的第一个参数是一个 ostream& ;
- 它的第二个参数是一个我们定义的类型的对象的引用;
- 它的返回值一定是一个 ostream& ;
ostream& operator<<(ostream& os, const T& obj) {
//这时候T& obj有const了,因为我只是要拿obj的值去往流里面去insert,我不会去改obj的值
... //写入对象的特定代码
return os;
}
/*
同样为了链接返回一个 ostream&
cout << a << b << c; =====> ((cout << a) << b) << c;
*/19.2.1、其他的输出运算符(Other output operators):
还是直接上图:

19.3、manipulator(操纵器):
- 在《18.3、流的操作》小节我们简单提了一下;
- manipulator用于修改"流"的状态;
#include <iomanip> Effects hold (usually)- 我们在学习最开始就接触过manipulator了,比如我们常用的 "endl" 就是一个manipulator;
在输出的时候我们会比较关心"格式化"(format)的问题(比如整数前面要不要补零,保留几位小数的问题;在输入的时候我们不太关心这些问题,因为这跟我们读进来的那个东西没什么关系)。这个时候我们就需要用到一些manipulator来控制输出的行为。比如我们想要读入用户输入的东西是16进制的,我们就可以先给它一个hex;我们想要规范输出的精度和宽度,都可以使用一些manipulator来控制,例如:
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
int n;
cout << "enter number in hexadecimal:" << flush; //flush是个manipulator
cin >> hex >> n; //hex是个manipulator
/*这里的hex并不是说我们要把用户输入的东西读到一个叫做"hex"的地方,
而是用manipulator来告诉cin,下一个东西是hex*/
cout << n << endl << endl;
cout << setprecision(2) << 1000.243 << endl;
/*setprecision(2)表示我们要求精度为2
(1000.243保留两位有效数字但本身是4位数了所以得到1e03可以保证两位的精度)*/
cout << setprecision(6) << 1000.243 << endl << endl;
cout << setw(20) << "OK!" << endl;
//setw(20)表示我们要求宽度为20("OK!"宽度为3,所以输出"OK!"前会先输出17个空格)
cout << "12345678901234567OK!" << endl;
return 0;
}运行结果:
- 我们可以使用的manipulator:
19.3.1、创建自己的manipulators:
我们可以定义自己的manipulators:
- 同样还是做成一个全局函数;
//输出流manipulator的框架
ostream& manip( ostream& out ) {
...
return out;
}
ostream& tab( ostream& out ) {
return out << '\t';
}
cout << "Hello" << tab << "World" << endl;19.4、Stream flags control formatting:
- 简要介绍下io的flag有哪些以及它们的作用:
如果小伙伴们是跟笔者一样控制工程相关专业的,那么对控制标志位一定不陌生,其实就是用一个一个bit来表达各个标志(flag)的状态。

- 设置flag的两种途径:用manipulator和用流成员函数:

20、STL简述:
STL(Standard Template Library)是ISO标准c++库的一部分,包含两种东西:
- 数据结构(data structure);
- 算法(algorithm);
为什么要去用STL呢?
答:现成的为什么不用?不要去做"重复造轮子"的事儿了。
官方点的回答:
- 减少开发时间;
- 增强代码可读性;
- 增强程序健壮性(STL的数据结构都是会自动增长的,不会有越界问题);
- 增强程序可移植性;
- 代码可维护;
- 简单;
既然是这么好的东西,那这个库里面有什么呢?
- 该库包含:
- 一个 “对”(Pair) 类(一个Pair表达两个东西之间的关系,可以是任何一对东西,int/int,int/char等等)
- 各种各样的容器:
- vector(可扩展的数组);
- deque(两端可扩展的数组);
- list(双向链表);
- sets and maps(数学意义上的集合 & 影射);
- 基本算法(排序算法sort、查找算法search等等,表现形式为函数模板);
- 库里面所有的标识符都在 std 命名空间,所有的标识符都是小写字母,没有大写字母的;
- STL的三部分:
- Containers 容器;
- Algorithms 算法;
- Iterators 迭代器(STL通用的遍历容器元素的方式);
- 主要用到的三种数据结构:
- map;
- 任何 key type,任何 value type
- 做映射
- vector;
- 与C的数组类似,但是可扩展
- list;
- 双向链表
- 举一个简单的使用vector的例子:

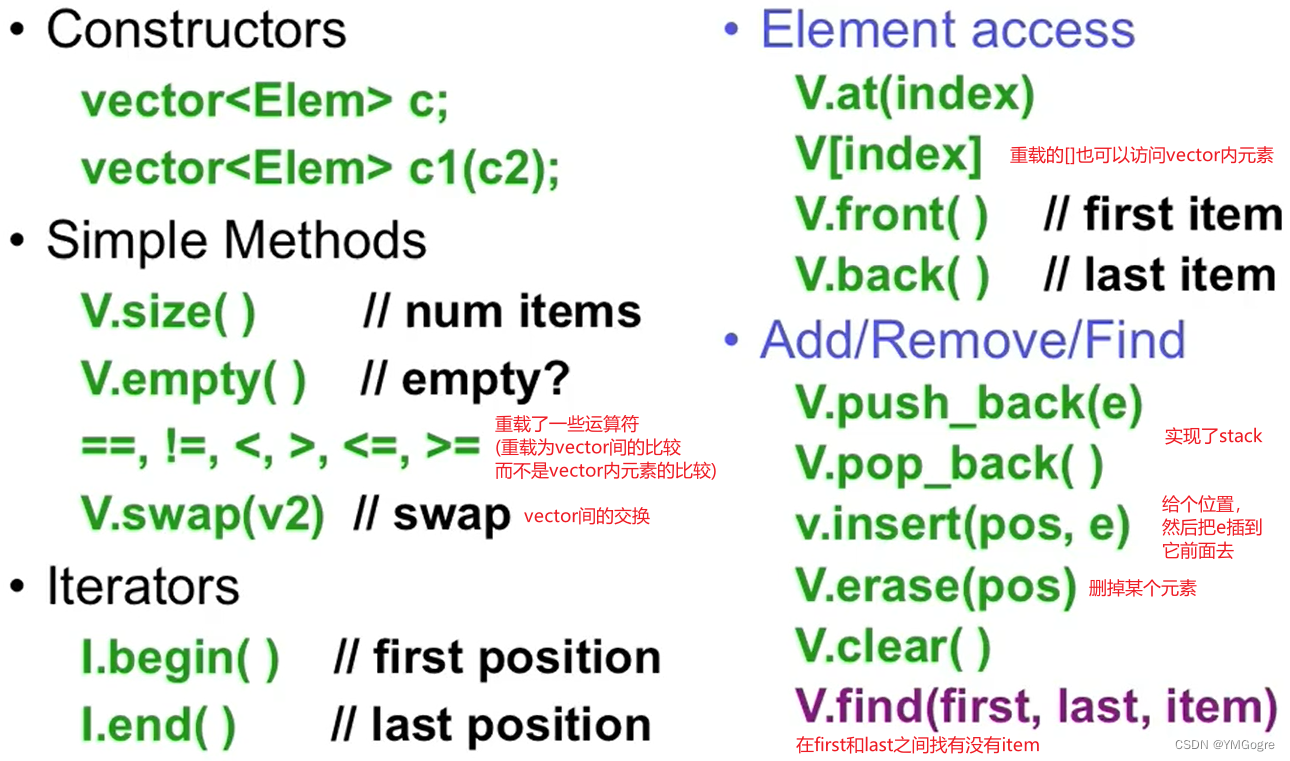
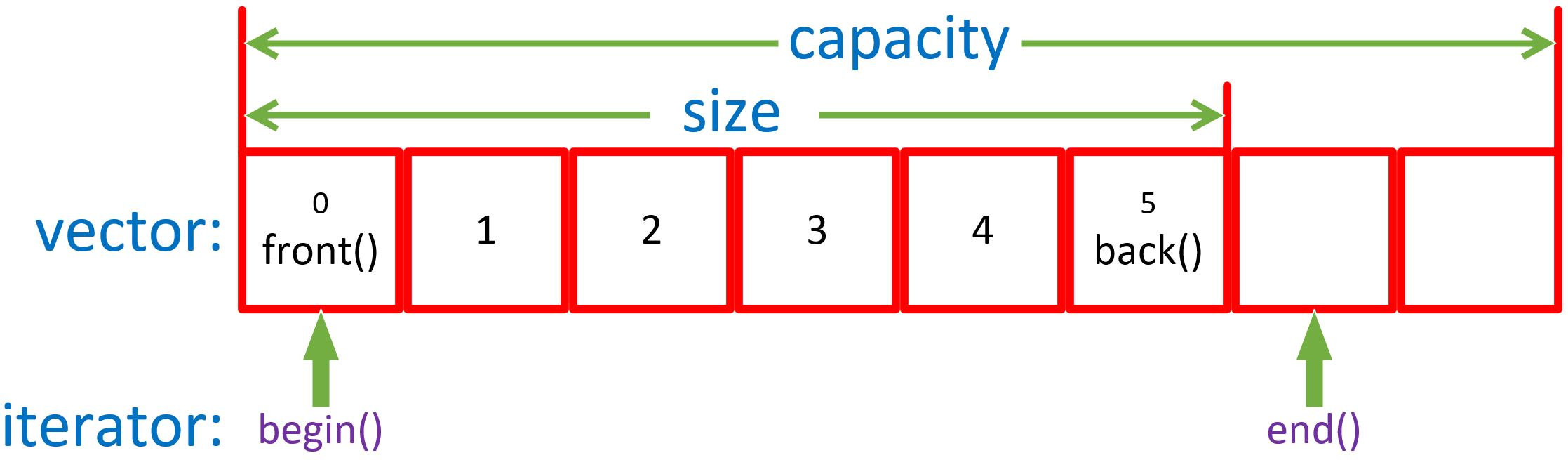
- vector的一些基本操作:
- vector::begin():返回一个迭代器,指向容器中的第一个元素;
- vector::end():返回一个迭代器,指向紧跟在容器中的最后一个元素之后的元素。故其不指向任何元素,不应被解引用(dereferenced,所谓“解引用”就是指去取指针所指向的值);
- vector::front():返回对容器中第一个元素的引用;
- vector::back():返回对容器中最后一个元素的引用;
下面是个简单图示帮助我们理解:
接下来简单讲讲删掉某个元素的方法 erase():如果我们定义了一个 vector<int> V 容器,那么 V.erase(pos) 方法原型为:
inline std::vector<int>::iterator erase(std::vector<int>::const_iterator _Where)
//还有个重载:
inline std::vector<int>::iterator erase(std::vector<int>::const_iterator _First, std::vector<int>::const_iterator _Last)可以看到,erase() 方法要求传入的参数得是一个迭代器(iterator),但我们能直接拿到的迭代器就只有 V.begin() 和 V.end(),这样我们就只能删除 V 的头部或尾部(让V.end() - 1即可)。那么,如何才能得到一个指向 vector 中间某一位置的迭代器从而使用 erase() 方法去删除指定元素呢?下面是一个代码例:
#include <iostream>
#include <vector>
using namespace std;
/// <summary>
/// 通过函数模板实现删除vector任意位置处的元素的操作(该函数并不完善,因为不会做越界检查)
/// </summary>
/// <typeparam name="T">参数化的类型名</typeparam>
/// <param name="vec">由参数化类型名定义的vector</param>
/// <param name="index">待删除位置下标</param>
template<typename T>
inline void RemoveAt(vector<T>& vec, size_t index)
{
vector<T>::iterator p = vec.begin();
for (int i = 0; i < index; i++)
{
p++;
}
vec.erase(p);
}
int main() {
vector<int> testVec;
for (int i = 0; i < 10; i++)
{
testVec.push_back(i);
}
cout << "testVec.size() = " << testVec.size() << endl;
cout << "testVec.capacity() = " << testVec.capacity() << endl;
vector<int>::iterator p;
for (p = testVec.begin(); p < testVec.end(); p++)
cout << *p << " ";
cout << endl;
RemoveAt(testVec, 7); //删除下标为7的位置处的元素
//可以看到,删除vector中间某一元素后,vector的大小会减一
cout << "After remove, testVec.size() = " << testVec.size() << endl;
//但vector的容量并不会改变
cout << "After remove, testVec.capacity() = " << testVec.capacity() << endl;
for (p = testVec.begin(); p < testVec.end(); p++)
cout << *p << " ";
cout << endl;
return 0;
}代码看完了吗?有没有拷贝到自己的开发环境里去试试效果呢😆?没拷的话还不急,因为笔者在这段代码里还留了个"坑",其实这个代码例是无法编译通过的!不过我们还是先看看能正确运行时的运行效果吧~

接下来来看看代码里留的那个"坑":上述直接编译后会给出如下错误:

双击错误后我们可以看到错误定位在函数模板中这句代码:

错误信息告诉我们:"表达式"后出现意外标记 "标识符"。这里的 "标识符" 指的就是代码中的那个 p;而 "表达式" 指的是代码中的 vector<T>::iterator。鼠标指针放在 p 上,可以看到提示窗口告诉我们 p 的类型是 "<error-type>"(错误类型)。这里我们就定位到错误的原因了:编译器没有意识到 vector<T>::iterator 是个类型,编译器会认为 iterator 只是 vector<T> 模板类里面的一个静态成员变量;或者是静态成员函数(由于 iterator 后面没有跟括号,所以排除这一选项)什么的。拿非类型的东西去定义一个变量显然是语法错误。
为了了解根本原因,我们还需要扩展另外一个概念 —— 依赖名和非依赖名:
vector<int>::iterator p; //非依赖名(non-dependent names)
vector<T>::iterator p; //依赖名(dependent names)
//依赖于模板参数的名称即依赖名所以,根本原因就是:对于用于模板定义的依赖模板参数的名称(以上文中的代码例来说就是 vector<T>::iterator 这个名称),只有在实例化的参数中存在这个类型名,或者这个名称前面使用了 typename 关键字修饰,编译器才会将这个名字当做是类型。除了以上两种情况,编译器不会将它视为类型。
解决办法也很简单 —— 使用 typename 关键字即可。这个关键字用于指出模板声明(或定义)中的依赖名称(dependent names)是类型名,而非变量名。所以我们把上文代码例中的函数模板内定义局部变量 p 的代码改为下面这样就可以正常编译运行啦:
typename vector<T>::iterator p = vec.begin();看完上面这些如果你还是感觉对这个错误或者 typename 关键字理解不深入,可以继续参考如下文章:
- 当然,还有个更简单的方法是使用 auto 关键字。这个关键字用于让编译器自行推导变量的类型,比如定义局部变量 p 的代码我们还可以这样写:
auto p = vec.begin();同样也可以正常编译运行。
20.1、list & map:
- list基本介绍:

- list应用实例:

- map示例程序:

21、结语:
学习笔记到这里就正式完结啦~希望看完的小伙伴能够有所收获!
本学习笔记作为面向对象程序设计以及C++入门的学习笔记已经足够了;不过"C++入门"代表我们仅仅只是迈进了门槛,想要在这条路上继续走下去需要学习的东西还有很多(决定好自己的方向,并以此制定学习路线;像基本的数据结构与算法、计算机网络、操作系统、Linux等等。不过笔者并非计算机专业的同学,在这里没有办法推荐一份比较详尽的学习路线)。
翁恺老师的视频课程发布于2013年,当时实行的C++标准还是C++11。而在那之后C++标准委员还在按照每三年发布一版的频率持续发布新的标准,到现在最新的标准相比于C++11已经多了许多新特性、新内容了。作为一个合格的程序员,紧跟时代是必要的。
我想说的是:“学习本就是一件枯燥乏味却又伴随一生的事情。很多时候我们并不是看到了希望才坚持;而是坚持后才会看到希望”
共勉















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









