







今天阅读一篇论文(Data Descriptor),这篇文章来自中国科学院地理科学与资源研究所团队,发表于 Scientific Data 期刊,题目为:
🌍 Annual 30 m land cover dataset on the Tibetan Plateau from 1990 to 2023
先附上原文链接:Annual 30 m land cover dataset on the Tibetan Plateau from 1990 to 2023 | Scientific Data
✨ 摘要(Abstract)
-
研究团队构建了一套时间跨度长达34年(1990–2023)、空间分辨率达30米的青藏高原土地覆盖年度数据集(TPLCD);
-
数据来源为Landsat系列卫星(L5/L7/L8),通过 Google Earth Engine(GEE)进行大规模处理;
-
在方法上,采用了LandTrendr算法提取高质量的时间序列训练样本,结合随机森林(Random Forest)分类器与时序平滑算法,显著提升了数据的稳定性与精度;
-
精度验证方面,使用了 Google Earth 影像人工解译 + 第三方权威数据集(如 Geo-Wiki、GLCVSS)验证,数据集的总体精度达到84.8%,Kappa系数达到0.78。
🧪方法(Methods)
✨研究区域:
青藏高原位于北纬 25°59′—40°1′、东经 67°40′—104°40′之间,地跨中国、印度、尼泊尔等 9 个国家,总面积 308 万平方公里,其中中国境内面积约 258 万平方公里,占总面积的 83.7% 。青藏高原平均海拔 4320 米左右,气候类型多样,气温和降水量总体由东南向西北递减,东南部气候温暖湿润,西北部较寒冷干燥,年平均气温-6~20℃,年平均降水量 20~4500 毫米。近几十年来,青藏高原面临着草原退化、栖息地丧失等一系列生态危机,开展连续、精准的土地覆盖监测尤为迫切,这对于捕捉细微的生态变化、及时预警潜在风险至关重要。
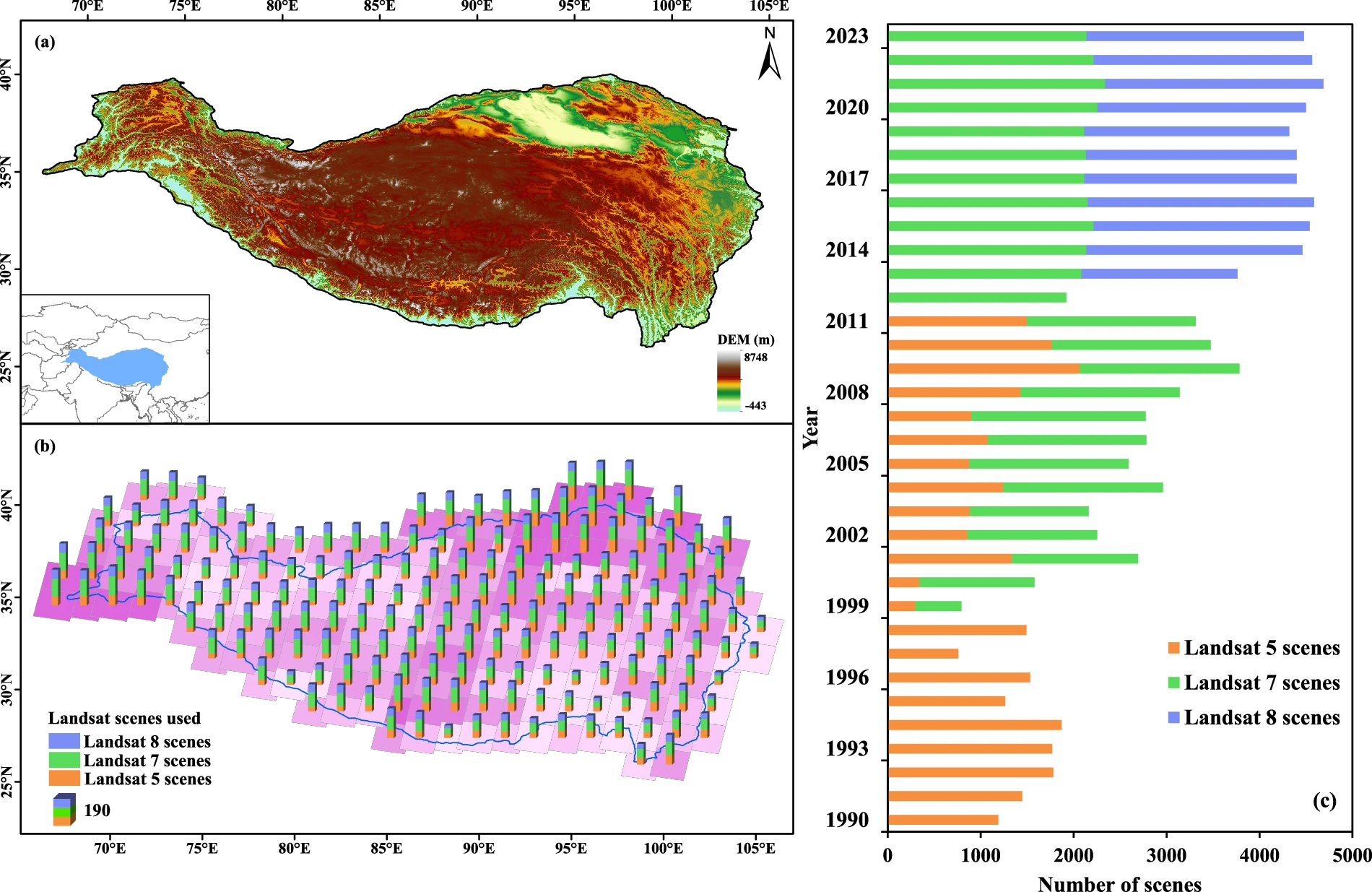
图1 研究区域(a)青藏高原的海拔(b)青藏高原使用的Landsat场景的地理分布(c)1990年至2023年每年青藏高原使用的Landsat场景数量
✨技术路线:
-
使用 GEE 平台进行云端处理,效率高;
-
用 LandTrendr 进行训练样本提取,省去人工选样难题;
-
引入了“时序滑动窗口”策略优化分类序列的一致性;
-
每年分类重复10次,取众数作为最终结果,减少随机性。
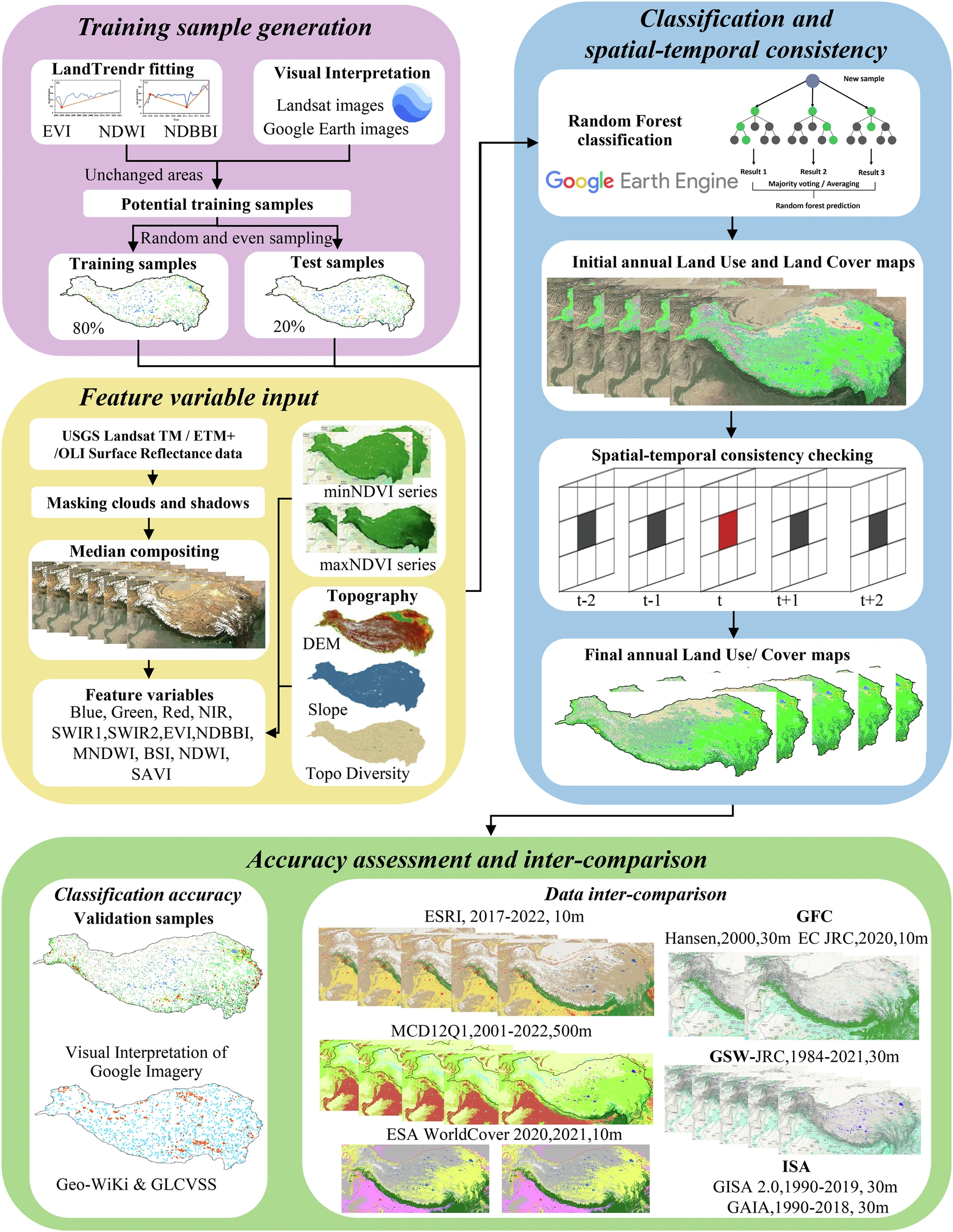
图2 技术路线图
✨数据处理:
-
使用Landsat 5, 7, 8 的地表反射率产品
-
云掩膜:CFMask方法
-
年度合成:用中值合成消除噪声
✨分类体系:
青藏高原主要以高寒草原覆盖,高寒草甸和高寒草原是其典型组成部分。研究构建了包含十大土地覆盖类型的分类系统:农田、森林、灌木丛、高寒草原、高寒草甸、水体、裸地、不透水面、湿地和冰雪。
✨特征变量构建:
他们用了 17 个特征变量,包括:
🌈 光谱指数(8个):
-
MNDWI(改进水体指数)
-
EVI(增强植被指数)
-
BSI(裸地指数)
-
SAVI(土壤调节植被指数)
-
NDBBI(建筑/裸地指数)
-
NDWI(水体指数)
-
maxNDVI(95分位)
-
minNDVI(5分位)
🏔️ 地形因子(3个):
-
DEM(海拔)
-
坡度(slope)
-
地形异质性(topographic diversity)
➕ 波段反射率(6个):
-
Landsat 6 个基础波段(B1-B6)
📚 可以借鉴的点:
-
加入 NDVI 的极值(max/min)可以增强时序变化的判断力;
-
NDWI + MNDWI 对区分水体/湿地非常关键;
-
DEM、坡度、地形多样性在高原/山区分类中非常有用;
-
将不同类型变量拼接成多维特征向量,用于分类训练。
✨训练样本提取与分类:
📍 通过LandTrendr算法选稳定区
-
LandTrendr 算法是一种时序分段算法,能识别变化趋势和稳定状态;
-
用于分析 NDWI、EVI、NDBBI 这三个指数的长期变化轨迹;
-
找到长期稳定未发生变化的像元,在这些地方提取训练样本;
-
这样能避免年份之间分类不一致的“漂移”问题。
🤖 分类方法:随机森林(RF)
-
使用 RF 分类器,构建200棵树(考虑 GEE 平台内存限制)
-
每年做 10次重复分类,然后取“众数”结果,提高鲁棒性
-
再加一道工序:用滑动窗口(长度为5年)进行时间一致性平滑处理
📚 可以借鉴的技术要点:
-
LandTrendr 在 GEE 上是现成可用的,可以自己跑试试看;
-
这个思路比“人工挑样本”更加系统和自动化,非常适合做长时间序列。
📈技术验证(Technical Validation)
作者通过三种方式全面评估了 TPLCD 数据的准确性:
| 验证方式 | 内容 |
|---|---|
| ① 自建验证集 | 人工解译7000个点,覆盖1990–2023 |
| ② 外部验证集 | Geo-Wiki 和 GLCVSS 样本数据 |
| ③ 与已有数据对比 | 与6种主流土地覆盖产品比较 |
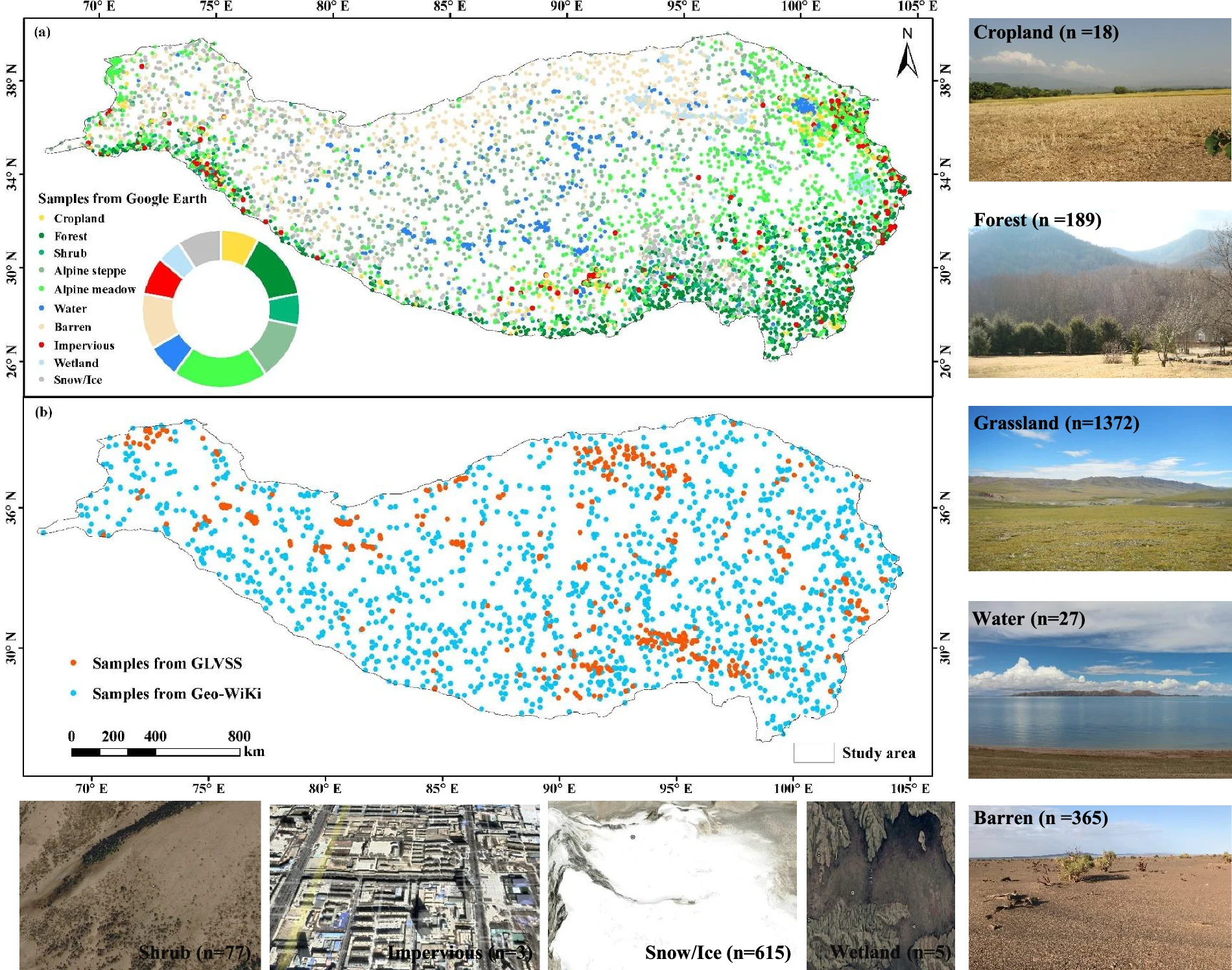
图3 TP验证样本空间分布。( a )参考Google Earth影像目视解译的样本;( b )来自Geo-wiki和GLVSS的样本,照片中标明了两个平台上各土地利用类型的样本数量。
✅ 1. 使用人工解译样本验证
📍 方法:
从整个青藏高原区域,随机抽取了 7000 个点,并结合 Google Earth 历史影像进行人工目视解译,为每个年份(共34年)提供“真值标签”。
📈 结果:
-
总体精度(OA):平均为 79.07%
-
Kappa系数:平均 0.76
-
精度随时间整体上升,说明分类模型在不断改进
📊 按地类的F1-score排序:
| 地类 | F1 值 |
|---|---|
| 森林 | 87.76% |
| 水体 | 86.54% |
| 城镇 | 85.59% |
| 湿地 | 83.24% |
| 高寒草原 | 79%左右 |
| 高寒草甸 | 78%左右 |
📌 可以注意的细节:
-
森林、水体、城镇类光谱差异大,分类效果好;
-
草地类因为时序曲线和光谱较接近,F1略低;
-
年度人工验证是非常耗时但高质量的工作,说明作者对数据很有信心。
✅ 2. 使用权威样本集进行验证
📚 a. Geo-Wiki 样本集验证(2000–2012)
-
样本数量:1667个点
-
来源:公共众包解译样本,标注置信度为“sure”
-
参考数据:Landsat/Google Earth历史影像
📈 验证结果:
-
平均 OA:86.31%
-
平均 Kappa:0.77
-
森林、草地、水体、裸地的分类精度最高
📚 b. GLCVSS 样本集验证(2013年以后)
-
样本数量:1005个点
-
来源:全球随机采样验证集
-
主要覆盖 2013–2023 年
📈 验证结果:
-
平均 OA:88.44%
-
平均 Kappa:0.81
-
草地、森林、水体、冰雪类分类表现稳定优异
📌 总结: 外部验证数据与作者人工样本验证结果基本一致,说明:
TPLCD 在多个时间段、多类样本、不同解译人员之间,都表现出良好的鲁棒性。
✅ 3. 与主流土地覆盖产品对比
作者选取了6个已有数据集,分别与TPLCD在共同年份和区域内进行对比,包括:
| 产品名称 | 分辨率 | 发布机构 |
|---|---|---|
| GLC_FCS30D | 30m | 国家遥感中心 |
| CLCD | 30m | 中科院遥感地球所 |
| MCD12Q1 | 500m | MODIS |
| ESA WorldCover | 10m | ESA |
| FROM-GLC30 | 30m | 清华大学 |
| ESRI 10m LC | 10m | ESRI/GHS |
📊 对比方法:
-
将各产品统一转为 IGBP 分类体系;
-
用年份重叠(如2020年)的分类图,统计不同地类的重叠精度;
-
用一致性(consistency)、F1-score、线性相关性(R²)进行综合评估。
📈 对比结论:
-
TPLCD 与其他数据集总体一致性较好;
-
其中与 GLC_FCS30D 和 CLCD 的一致性最高(因为都是Landsat 30m);
-
与 MCD12Q1 一致性较差(受限于500m分辨率);
-
与 ESA 10m 数据在森林、水体类一致性也较高;
-
城镇类在 ESRI 和 GAIA 产品之间差异较大 → 城镇扩张检测对分辨率要求更高。
综上所述,通过目视解译验证以及与第三方数据集的比对,TPLCD 展现出优于 MCD12Q1、ESA 的 GLC、CLCD、GLC_FCS30D 和 ESRI 的 GLC 的 OA 性能。TPLCD 的平均 OA 达到 84.8%,平均 Kappa 系数为 0.78。值得注意的是,TPLCD 提供了跨越 34 年(1990–2023 年)的连续时间序列,与 ESRI 的 GLC(2017 年至 2022 年)、ESA 的 GLC(2020 年至 2021 年)和 MCD12Q1(2001 年至 2022 年)相比,提供了更广泛的时间覆盖范围。
📥代码开源(Code availability)
-
✅ 全部数据(1990–2023,30米)已开源发布在 Zenodo平台,格式为 GeoTIFF;
-
✅ 分类代码也托管在 GEE 上,便于复现;
参考文献:
Li, S., Ge, Q., Sun, F. et al. Annual 30 m land cover dataset on the Tibetan Plateau from 1990 to 2023. Sci Data 12, 510 (2025). https://doi.org/10.1038/s41597-025-04759-6
数据下载地址:
Annual 30 m land cover dataset on the Tibetan Plateau from 1990 to 2023


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









