







1. 多模态大模型发展趋势:
近年来,大型语言模型(LLMs)在文本处理领域取得了显著的进展,展现出强大的语言理解和生成能力。然而,现实世界的信息并非单一模态,而是以文本、图像、音频、视频等多种形式呈现。为了实现更强大的通用智能,模型需要能够理解和处理这些不同模态的信息。多模态大模型应运而生,它们通过融合视觉、听觉、文本等多种模态的信息,旨在实现更全面、更深刻的智能理解和交互。
当前,单模态大模型在处理超出其训练范围的任务时常常面临局限性。例如,一个仅接受文本训练的语言模型难以理解图像或视频的内容。多模态融合能够克服这些限制,使模型能够从不同模态的数据中学习互补信息,从而提升其在各种任务上的性能和泛化能力。未来,多模态大模型有望在人机交互、内容创作、智能助手、自动驾驶等领域发挥关键作用,实现更自然、更智能的应用体验.
2. 图文多模态大模型:
图文多模态大模型是当前研究最为活跃的领域之一,旨在让模型能够理解和关联图像与文本信息。
2.1 CLIP 模型:
CLIP (Contrastive Language-Image Pre-training) 是一个开创性的图文多模态模型,由 OpenAI 提出。其核心思想是通过对比学习,将图像和文本编码到同一个语义空间中。CLIP 在大规模的图像-文本对数据集上进行预训练,学习图像和文本之间的匹配关系。在预训练完成后,CLIP 展现出强大的 Zero-shot 图像分类和检索能力,即无需针对特定类别进行微调,就能识别和检索图像。CLIP 的优势在于其强大的跨模态语义理解能力和广泛的适用性,但其在细粒度图像理解方面可能存在一定的局限性。
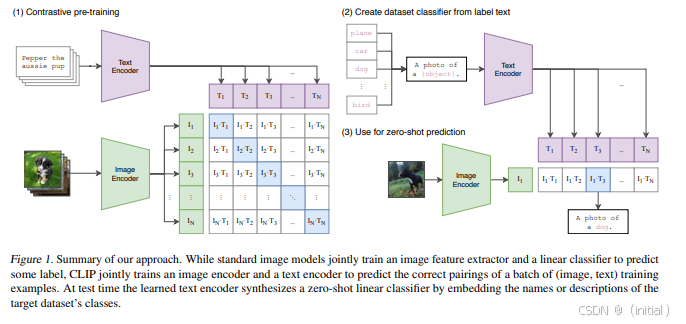
2.2 VisualBERT, UNITER, ViLBERT:
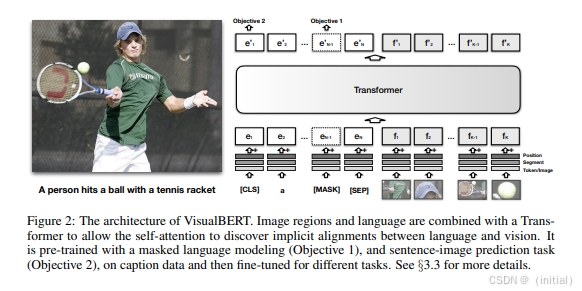
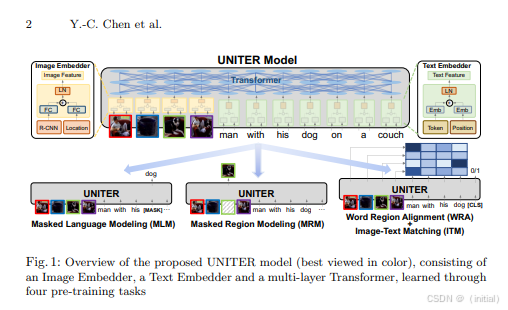
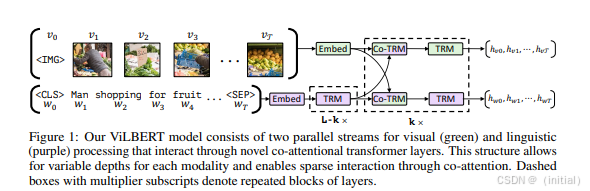
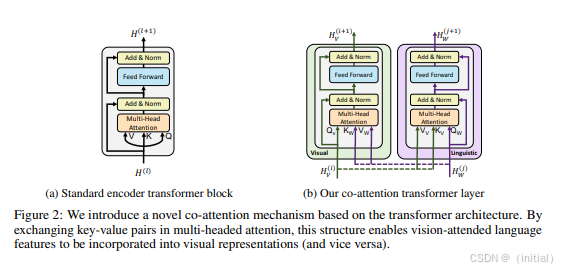
VisualBERT, UNITER, ViLBERT 等模型通过扩展 Transformer 架构来处理图像和文本等多模态信息。它们通常会利用预训练的视觉特征提取器(如 ResNet)来获取图像的特征表示,然后将图像特征和文本特征一起输入到 Transformer 模型中进行联合建模。这些模型的核心创新在于引入了跨模态注意力机制,使得模型能够学习图像和文本之间的复杂关系。例如,在视觉问答任务中,模型可以通过跨模态注意力机制关注图像中与问题相关的区域,从而更准确地回答问题。VisualBERT, UNITER, ViLBERT 等模型在视觉问答、图像描述等任务上取得了显著的成果。
VisualBERT
UNITER
ViLBERT
2.2.1 Mixture-of-Transformers:
作为一种基于 Transformer 架构的变体,Mixture-of-Transformers 模型将非嵌入层的模型参数按模态划分,这意味着模型的一部分参数专门用于处理文本,另一部分参数专门用于处理图像。然而,该模型仍然在整个输入序列上进行全局自注意力机制,从而实现跨模态的交互和理解。这种架构旨在提高模型处理特定模态信息的效率,并增强跨模态的关联能力。
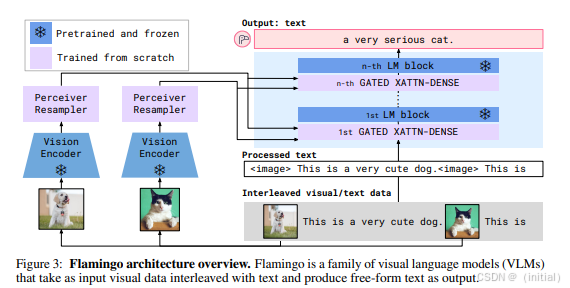
2.3 Flamingo, BLIP:
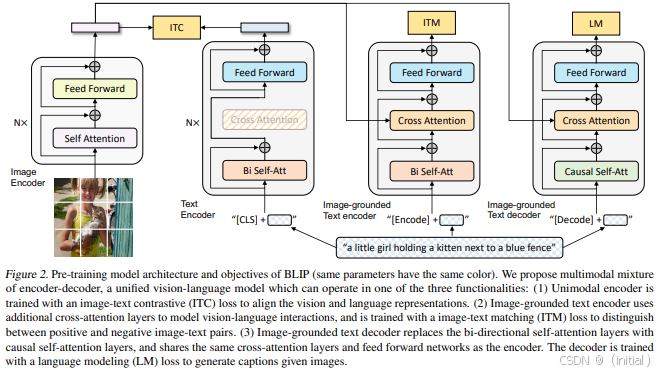
Flamingo 和 BLIP 等模型进一步提升了图文多模态大模型的 Few-shot Learning 和 Instruction Following 能力。它们通常采用更灵活的架构,能够接受任意组合的图像和文本输入,并根据给定的自然语言指令执行各种多模态任务,例如图像描述生成、视觉问答、图像编辑等。这些模型在仅有少量示例的情况下就能快速适应新的任务,展现出强大的泛化能力。BLIP (Bootstrapping Language-Image Pre-training) 通过引入一个额外的图像编码器和一个连接文本编码器和图像编码器的桥梁模块,有效地利用了大量的 noisy image-text 数据进行预训练。Flamingo 则通过在 Transformer 架构中引入 Perceiver Resampler 和 Gated Attention 等机制,实现了高效的多模态信息处理和上下文学习能力。
Flamingo
BLIP
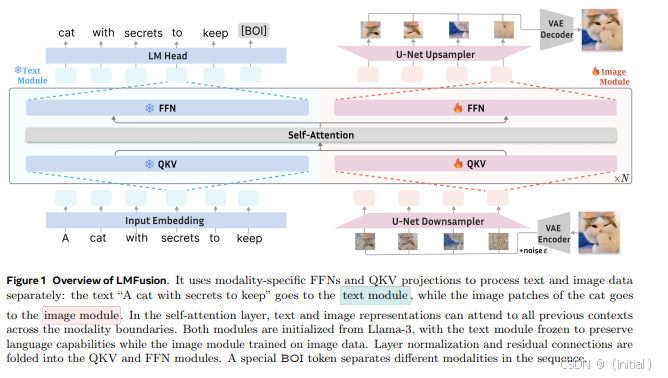
2.3.1 LMFusion:
这是一个利用 Llama-3 的权重处理文本,并引入额外的并行 Transformer 模块进行图像处理的图文多模态模型。LMFusion 的独特之处在于它能够理解和生成包含文本和图像任意序列的内容,为图文混合内容的理解和创作提供了新的可能性。
2.3.2 InternLM-XComposer(IXC):
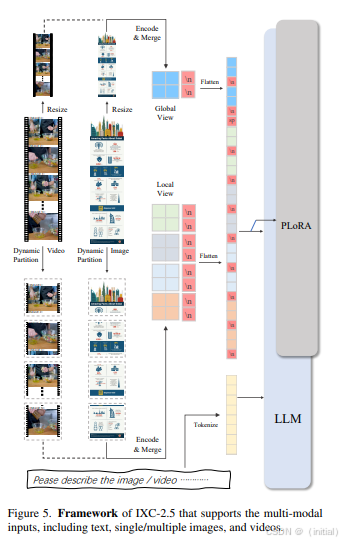
InternLM-XComposer 是上海人工智能实验室推出的一个多模态模型,在视觉编码、文本生成与多模态任务中表现出色。它通过图文交错组合等技术,实现了高效的图像定位与文本生成,在图像描述、视觉问答等任务上取得了领先水平。
2.4 基于混合专家(MoE)的图文模型:
2.4.1 DeepSeek-VL2:
DeepSeek-VL2 模型采用了混合专家 (MoE) 架构,通过动态平铺视觉编码策略处理不同宽高比的高分辨率图像,从而提升了模型对复杂视觉信息的处理能力。此外,该模型还利用多头潜在注意力机制的 DeepSeekMoE 模型,将键值缓存压缩为潜在向量,实现了高效的推理和高吞吐量,这对于实际应用具有重要意义。

2.4.2 Flex-MoE:
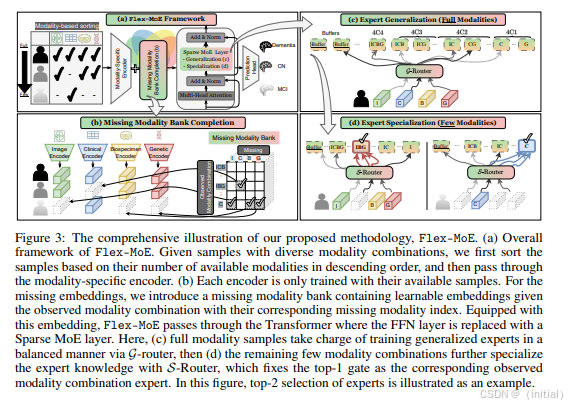
Flex-MoE 是另一种基于混合专家 (MoE) 架构的多模态模型。其创新之处在于引入了“缺失模态库”,使得模型可以灵活组合不同的模态输入,即使在某些模态数据缺失的情况下,模型也能够保持较好的鲁棒性。这种设计提高了模型在实际应用中的灵活性和可靠性。
2.5 基于分词器的图文模型:
2.5.1 TokenFlow:
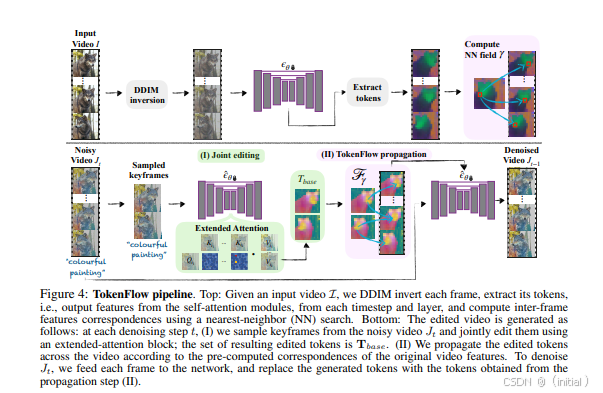
TokenFlow 模型通过采用双码本架构、共享映射机制、多尺度 VQ (Vector Quantization) 结构和多步采样策略,旨在解决多模态生成中语义信息和像素级细节之间的权衡问题。该模型能够同时获取高级的语义表示和细粒度的视觉特征,从而生成更符合人类期望的高质量图像和文本。
2.6 Emu3:基于下一个 Token 预测的多模态模型:
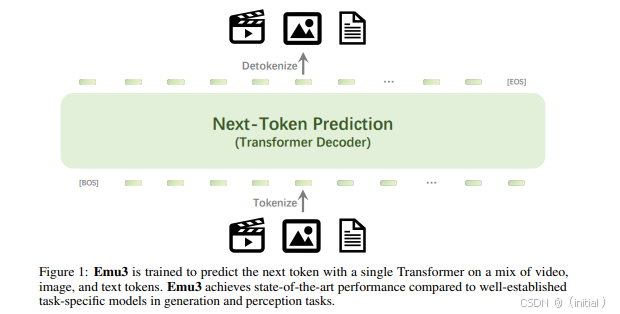
Emu3 是一个由字节跳动提出的多模态模型,其核心训练目标是基于下一个 token 预测任务。该模型通过将图像、文本和视频等不同模态的数据转化为离散的 token 序列,然后利用统一的 Transformer 架构进行训练。Emu3 在多模态生成(如文本生成图像、视频生成等)和感知(如图像分类、视频理解等)任务中都展示了卓越的性能,体现了通过统一的 token 表示和训练方式实现通用多模态智能的潜力。
3. 视频多模态大模型:
视频包含丰富的时空信息和动态变化,对模型的理解能力提出了更高的要求。
3.1 VideoBERT:
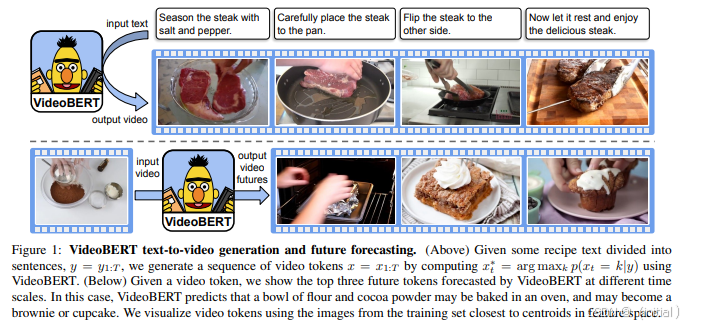
VideoBERT 是一个早期但具有代表性的视频多模态模型。它通过将视频帧和音频信息转化为离散的 tokens,然后利用 Transformer 模型学习视频的时空特征和多模态关联。VideoBERT 在视频理解、视频问答等任务上进行了成功的尝试,证明了将 Transformer 架构应用于视频处理的可行性。
3.2 ActBERT:
ActBERT 专注于理解视频中的动作和行为。它旨在建模视频中的主体、动作和环境之间的关系,从而实现对视频内容的更深层次理解。ActBERT 在视频行为识别、视频问答等任务上取得了良好的性能。
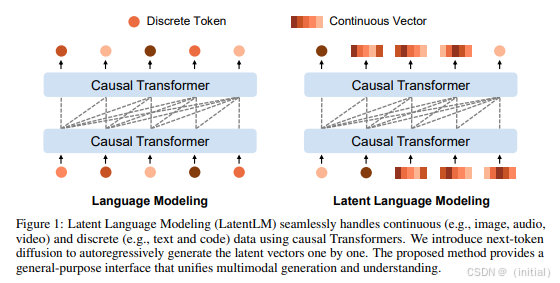
3.2.1 LatentLM:
作为一种基于扩散模型的多模态模型,LatentLM 不仅可以处理离散的文本和代码数据,也能够统一处理连续的图像、音频和视频数据。它使用因果 Transformer,并引入 next-token diffusion 来自回归地生成潜在向量,为多模态数据的统一建模和生成提供了一种新的思路。
3.2.2 Emu3:
前面已经介绍过,Emu3 也具备处理视频数据的能力,通过将视频转化为离散 token 进行训练,在视频理解和生成方面展现出强大的潜力。
4. 音频多模态大模型:
音频包含了语音、音乐等多种信息,对模型的感知和生成能力提出了挑战。
4.1 SpeechBERT:
SpeechBERT 旨在结合语音和文本信息进行语音理解。它通常会将语音信号转化为声学特征,并与文本信息一起输入到模型中进行联合训练,从而提升语音识别、语音翻译等任务的性能。

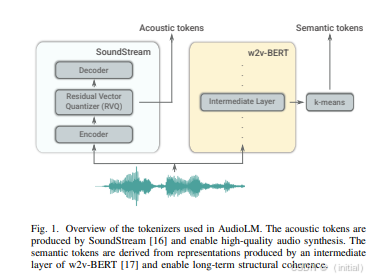
4.2 AudioLM:
AudioLM 是一个基于 Transformer 的音频生成模型,由 Google 提出。它通过学习大规模音频数据的潜在表示,实现了高质量的语音合成和音乐生成等功能。
4.2.1 LatentLM:
同样,LatentLM 也能够处理音频数据,为统一建模和生成不同类型的连续数据提供了可能性。
5. 多模态融合算法:
多模态融合算法是实现多模态大模型的核心技术,旨在有效地整合来自不同模态的信息。
5.1 Cross-modal Attention (跨模态注意力机制):
跨模态注意力机制允许模型在处理一种模态的信息时,能够关注到其他模态中与之相关的信息。例如,在视觉问答中,模型可以通过跨模态注意力机制关注图像中与问题相关的区域。
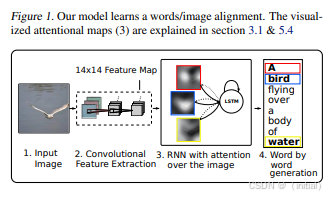
5.2 Multimodal Transformer (多模态 Transformer):
多模态 Transformer 架构通过修改标准的 Transformer 模型,使其能够直接处理来自不同模态的输入特征。这通常涉及到对输入表示、注意力机制或模型结构进行调整。VisualBERT, UNITER, ViLBERT上面有
5.2.1 模态对齐与交互技术:
除了注意力机制和 Transformer 架构,还有许多其他的模态对齐与交互技术,例如早期融合(Early Fusion,在输入层将不同模态的信息进行拼接或融合)、晚期融合(Late Fusion,在模型输出层对不同模态的预测结果进行融合)、中间层融合(Intermediate Fusion,在模型的中间层进行模态信息的交互和融合)。
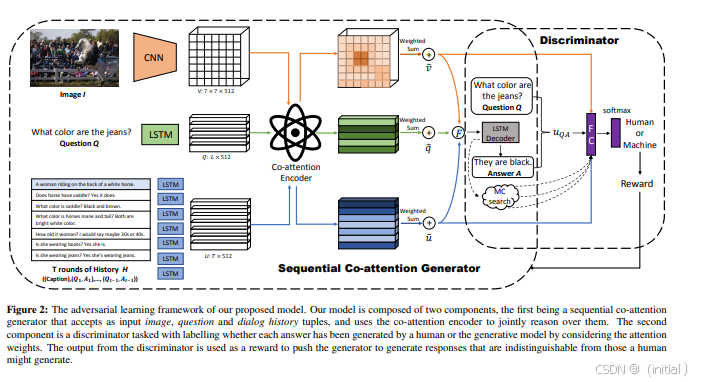
5.2.2 基于图神经网络的多模态融合方法:
在某些场景下,多模态数据之间存在复杂的关联结构,例如知识图谱中的实体和关系可以与图像、文本等模态相关联。利用图神经网络(GNNs)可以有效地捕捉这些关系,实现模态间高层次的语义关联推理,从而提升多模态模型的理解和推理能力。
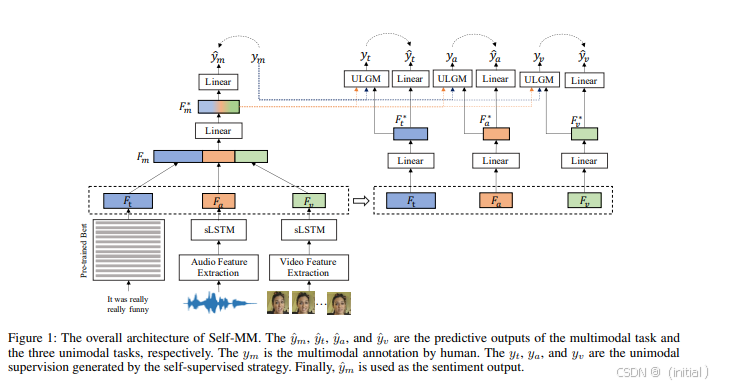
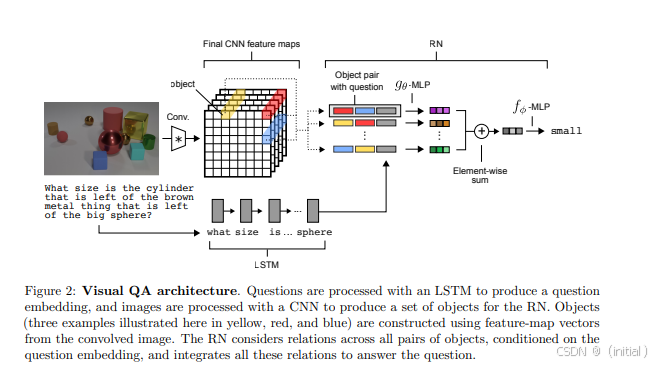
总结:
多模态大模型是人工智能领域的研究前沿,其目标是构建能够理解和处理多种模态信息的通用智能系统。本章介绍了当前一些具有代表性的前沿算法,涵盖了图文、视频和音频等多模态场景。这些算法在模型架构、训练方法和融合策略等方面进行了创新,不断推动着多模态大模型的发展,并在自动驾驶、智能助理、内容推荐系统等领域展现出广阔的应用前景。随着研究的深入,我们有理由相信,未来将出现更多更强大的多模态大模型,进一步拓展人工智能的应用边界。
内容同步在我的微信公众号: 智语Bot
参考文献:
- CLIP (Contrastive Language-Image Pre-training): Radford, A., Kim, J. W., Xu, C., Brockman, G., McLeavey, P., & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020. https://arxiv.org/abs/2103.00020
- VisualBERT: Li, L. H., Tan, X., Qin, P., Yang, J., Lu, Y., & Hu, Q. (2019). Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557. https://arxiv.org/abs/1908.03557
- UNITER (UNiversal Image-TExt Representation): Chen, Y. C., Li, L., Yu, L., Khandelwal, U., Rohrbach, M., & Bansal, M. (2020). Uniter: Universal image-text representation learning. arXiv preprint arXiv:1909.11740. https://arxiv.org/abs/1909.11740
- ViLBERT (Vision-and-Language BERT): Lu, J., Batra, D., Parikh, D., & Rohrbach, H. (2019). Vilbert: Pretraining task-agnostic visio-linguistic representations for vision-and-language tasks. arXiv preprint arXiv:1908.02265. https://arxiv.org/abs/1908.02265
- Flamingo: Alayrac, J. B., Donahue, J., Lucic, M., Vinyals, O., Hayes, J., Rodriguez Rivera, I., … & Irving, G. (2022). Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2203.15611. https://arxiv.org/abs/2204.14198
- BLIP (Bootstrapping Language-Image Pre-training): Li, J., Zhou, D., Xiong, C., & Hoi, S. C. H. (2022). Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. arXiv preprint arXiv:2201.05794. https://arxiv.org/abs/2201.12086
- LMFusion: Shi, W., Chen, J., Guo, L., Han, X., Zhang, D., Chen, S., … & Yu, L. (2024). LMFusion: Adapting Pretrained Language Models for Multimodal Generation. arXiv preprint arXiv:2412.13814. https://arxiv.org/abs/2412.15188
- InternLM-XComposer (IXC): Paper page: arXiv:2407.03320.
- DeepSeek-VL2: arXiv preprint arXiv:2412.10302.
- Flex-MoE: Code repository and information: .
- TokenFlow: Official implementation:
- Emu3:Next-Token Prediction is All You Need
- VideoBERT: Sun, Y., Cheng, A., Gan, Z., & Liu, L. (2019). Videobert: A joint model for video and language representation learning. arXiv preprint arXiv:1904.01766. https://arxiv.org/abs/1904.01766
- ActBERT: صدر, م., & Gavrilyuk, K. (2020). Actbert: Learning global-local video representations for video action recognition.
- Multimodal Latent Language Modeling with Next-Token Diffusion.
- SpeechBERT: An Audio-and-text Jointly Learned Language Model for End-to-end Spoken Question Answering
- AudioLM: Borsos, Z.,及团队. (2021). AudioLM: a Language Model for Audio Synthesis. arXiv preprint arXiv:2101.04643. https://arxiv.org/abs/2209.03143
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
- A simple neural network module for relational reasoning
- Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Sentiment Analysis




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











