







摘要: 大型语言模型(LLM)展现了惊人的生成能力,但其“一次性”生成模式往往导致输出中存在事实错误、逻辑缺陷或考虑不周之处。人类智能的特点在于反思、修正、讨论和协作,而赋予 AI 类似的能力,是提升其输出质量、鲁棒性和可靠性的关键。本文将深入探讨当前 AI 领域中旨在超越单次生成的几种前沿范式:递归优化、自我批判/修正、外部批判以及多智能体协作与辩论。我们将剖析这些机制的核心原理,追踪相关技术进展,分析面临的挑战,并展望通过迭代与集体智慧构建更强大、更值得信赖 AI 的未来机遇。
1. 引言:超越单次生成,追求卓越输出
大型语言模型(LLM)通常以一种“一步到位”的方式生成内容:接收输入,然后直接输出结果。虽然这种模式在许多任务上效率很高,但它也暴露了 LLM 的固有弱点。如同人类初稿往往需要修改润色一样,LLM 的单次输出可能包含事实性错误(幻觉)、逻辑不连贯、未能充分理解复杂指令的细微之处,或者缺乏深度和创造性。对于需要高度准确性、严谨逻辑或周全考虑的任务(如撰写科学报告、生成法律文件、制定商业策略),这种“一次性”模式的风险尤为突出。
相比之下,人类智慧的一个核心特征是迭代改进和社会协作。我们会反思自己的想法(自我批判),听取他人意见(外部批判),通过讨论和辩论来完善观点(协作)。能否将类似的机制赋予人工智能?这正是当前 AI 研究的一个激动人心的前沿方向。研究者们不再满足于 LLM 的单次表现,而是探索如何让 AI 具备“三思而后行”的能力:通过递归优化 (Recursive Optimization)、自我批判 (Self-Critique)、多模型/外部批判 (Multi-Model/External Critique) 以及多智能体协作 (Multi-Agent Collaboration) 等方式,对初始输出进行评估、反馈和修正,从而显著提升最终结果的质量、可靠性和深度。本文旨在深入探讨这些新兴范式的工作原理、最新进展、关键挑战及未来潜力。
2. 核心机制:让 AI 学会“三思而后行”
赋予 AI 迭代优化和协作能力主要通过以下几种核心机制实现:
-
机制一:自我批判与修正 (Self-Critique & Refinement)
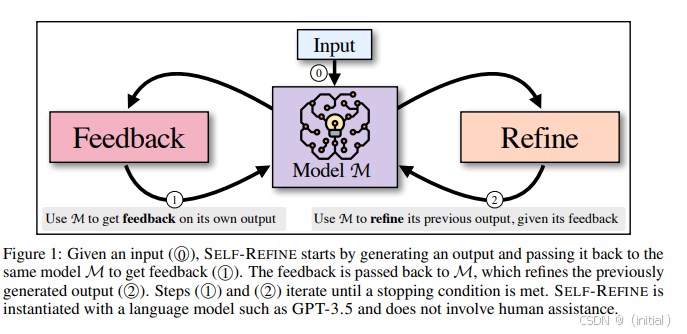
- 原理: 让 LLM 自己扮演“生成者”和“批判者”的双重角色。首先生成一个初步回答,然后通过特定的提示(Prompting)或内部机制引导它自我评估该回答的质量(例如,对照预设标准检查事实性、逻辑性、完整性),并根据评估结果自我修正。这个“生成-评估-修正”的循环可以重复多次,逐步提升输出质量。
- 代表性工作: Madaan 等人提出的 Self-Refine 框架 (Madaan et al., 2023) 系统地展示了如何通过迭代自反馈来改进各种任务的输出。Anthropic 的 Constitutional AI (Bai et al., 2022) 虽主要关注无害性,但其核心机制也包含 AI 基于原则进行自我批判和选择更优输出的过程。
-
机制二:外部批判与反馈 (External Critique & Feedback)
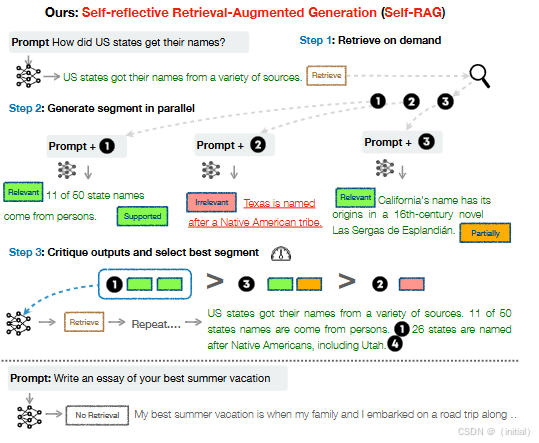
- 原理: 将“生成”与“批判”的角色分离,由一个或多个独立的实体(可以是另一个 LLM、专门训练的评估模型,甚至外部工具或人类)对生成者的输出进行评估,提供反馈,然后生成者根据反馈进行修改。
- 实现方式:
- LLM 作为评估者: 大量研究(如 Chiang et al., 2023)表明,LLM 本身可以被训练或通过提示引导,成为有效的自然语言任务评估器。
- RLHF 中的奖励模型: 在基于人类反馈的强化学习(RLHF)中,奖励模型本身就是一个典型的外部批判者,它学习人类偏好并为生成内容打分,指导 LLM 优化。

- 工具增强批判: 引入外部工具(如代码执行器、计算器、搜索引擎、事实核查数据库)进行客观验证,并将验证结果作为反馈。
-
机制三:多智能体协作与辩论 (Multi-Agent Collaboration & Debate)
-
原理: 更进一步,让多个 AI 智能体(通常是 LLM 实例)扮演不同的角色(例如,提议者、质疑者、不同视角的专家、裁判),通过模拟人类社会的讨论、辩论或协作过程来共同完成复杂任务或生成更高质量的综合性输出。
-
简化示例: 想象让两个 AI 协作写一段关于“气候变化影响”的文字。AI-A(提议者)先写初稿:“气候变化导致全球变暖。” AI-B(批判者/补充者)阅读后反馈:“这太笼统了,应该提及具体影响,比如海平面上升和极端天气。” AI-A 根据反馈修改:“气候变化导致全球变暖,显著影响包括海平面上升和更频繁的极端天气事件。” 这个简单的交互就体现了通过协作进行内容改进。
-
代表性工作:
-
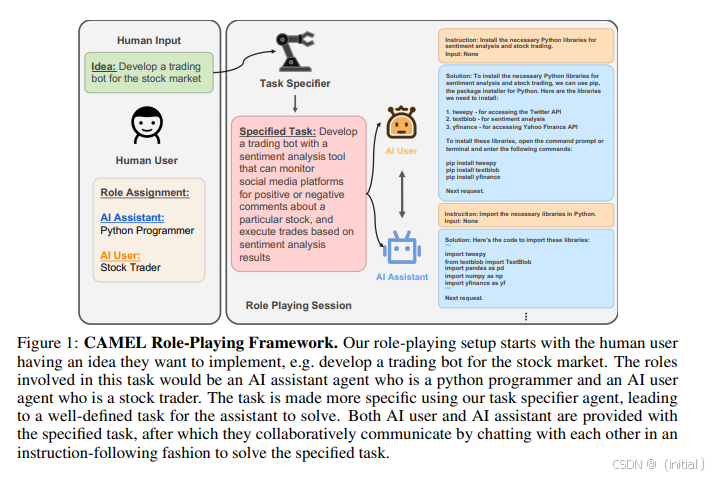
CAMEL (Li et al., 2023) 构建了交流型智能体社会,探索其在任务解决中的潜力。
-
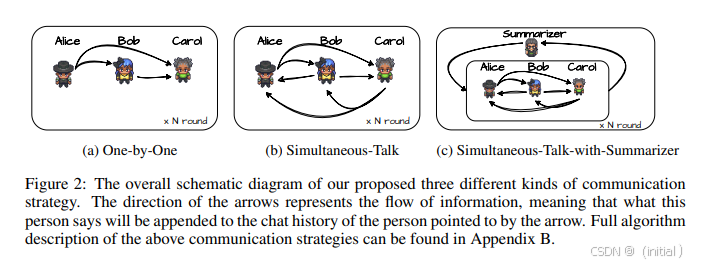
ChatEval (Chan et al., 2023) 利用多智能体辩论来进行更可靠的 LLM 评估,其思想也可启发生成过程。
-
MetaGPT (Hong et al., 2023) 则展示了多智能体协作在软件开发等复杂流程中的应用框架。
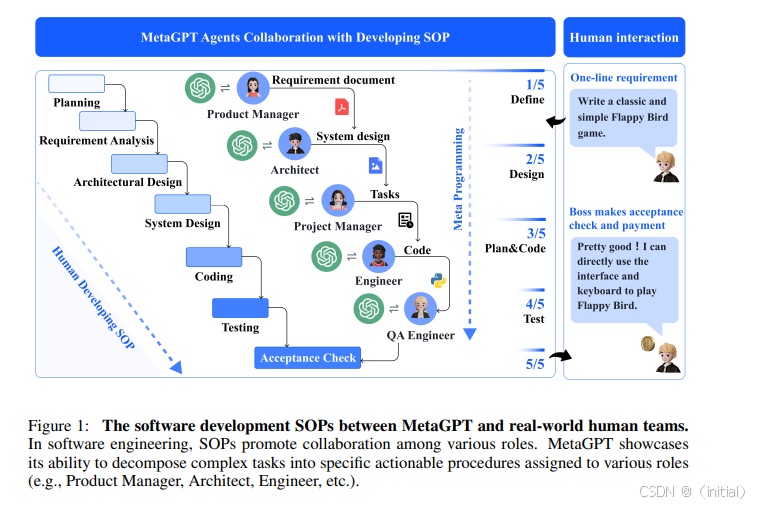
-
-
与 CoT/ToT 的联系: 虽然思维链 (Chain of Thought, CoT) (Wei et al., 2022) 和思维树 (Tree of Thoughts, ToT) (Yao et al., 2023) 主要关注改进单次生成的推理过程,但它们也体现了“生成中间步骤/多路径 -> 评估/选择”的思想,与迭代优化和评估选择有共通之处,尤其 ToT 明确包含了对不同思考路径的探索和评估。
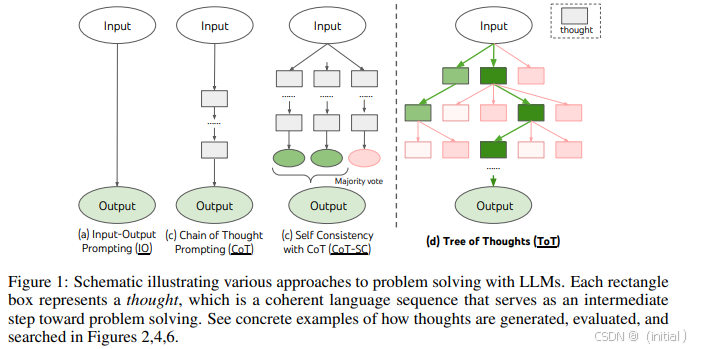
-
3. 前沿探索:迭代与协作的智能化演进
这些核心机制正在不断演进,变得更加智能和高效:
- 细粒度与多维度批判: 不再是笼统的好坏评价,而是发展出能够针对事实性、逻辑性、一致性、创造性、安全性、风格等多个维度进行细粒度评估和反馈的批判模型或提示策略。
- 自动化批判提示/标准生成: 研究如何让 AI 自动生成用于引导自我批判或请求外部批判的有效提示,甚至学习生成特定任务的评估标准(元学习思路)。
- 基于不确定性的自适应迭代: 让模型能够判断自身输出的置信度或不确定性,仅在必要时(如低置信度)触发批判和修正流程,从而提高效率,避免不必要的迭代。
- 更强大的工具增强批判: 将更多样、更专业的外部工具(如形式化验证器、领域知识库查询接口、物理模拟器)集成到批判环节,提供更客观、更深入的验证。
- 探索更优的迭代/协作策略: 研究超越简单线性迭代的更复杂结构,例如允许回溯和剪枝的树状/图状探索优化过程;或者设计更有效的多智能体交互协议和角色分配机制。
4. 挑战重重:通往自省协作之路
尽管前景广阔,但实现高效、可靠的 AI 迭代优化与协作仍面临诸多挑战:
- 评估标准的定义与学习: 如何设定全面、客观、且能被 AI 理解和执行的评估标准?特别是对于主观性较强(如创造性、风格)或需要深度领域知识的评估。
- 避免陷入局部最优或错误循环: 迭代过程可能收敛到并非全局最优的次优解,甚至可能因为错误的批判或反馈而在错误的方向上“越改越错”。
- 计算成本与效率: 多轮迭代、多个模型交互显著增加了计算资源消耗和时间延迟,如何在效果与效率之间取得平衡?
- 协作中的一致性与冲突解决: 在多智能体协作中,如何有效整合不同智能体的(可能冲突的)观点或产出,形成一致且高质量的最终结果?
- 可信度与安全性: 如何保证批判者(无论是 AI 还是外部工具)本身的可靠性和无偏性?如何防止恶意行为者利用协作机制进行攻击或操纵?整个过程的透明度和可解释性如何保障?
5. 创新机遇:智慧的阶梯
这些挑战反过来也指明了创新的方向:
- (框架创新) 新颖的多智能体协作框架与通信协议: 设计能够支持复杂任务、灵活角色分配、高效信息共享和冲突解决的协作框架。
- (算法创新) 高效、可靠的自我/相互批判与修正算法: 研发能够准确评估多维度质量、提供可操作反馈、并有效指导修正过程的算法,同时优化迭代效率(如智能停止条件)。
- (集成创新) 集成外部工具进行自动化验证与修正的系统: 构建能够无缝调用多样化外部工具进行事实核查、逻辑验证、代码测试等,并自动整合反馈进行修正的系统。
- (应用创新) 面向特定领域的协作式 AI 解决方案: 针对科学发现(如多智能体模拟实验、共同撰写论文)、软件工程(如结对编程、自动化测试与调试)、创意设计等复杂领域,开发定制化的迭代优化或协作 AI 系统。
- (可信度创新) 增强迭代与协作过程透明度和可控性的技术: 开发能够追踪决策过程、解释修正原因、允许用户干预和控制协作流程的技术,提升整体系统的可信赖性。
6. 结论与展望:迈向自我完善、值得信赖的 AI
让 AI 学会自我反思、接受批评、并与其他智能体协作,是超越当前 LLM 能力局限、迈向更高级人工智能的关键一步。递归优化、自我/外部批判以及多智能体协作等范式,正在推动 AI 从简单的“生成器”向能够进行“精炼”和“共创”的智能体转变。尽管在评估标准、效率、一致性和可信度等方面仍面临挑战,但其提升 AI 输出质量、鲁棒性和解决复杂问题能力的潜力是巨大的。未来的研究需要在算法设计、系统构建、人机交互以及伦理规范等多个层面持续努力,最终有望实现能够不断自我完善、在协作中涌现集体智慧、真正值得人类信赖的下一代人工智能系统。
参考文献 (示例格式)
- Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., … & Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073. (https://arxiv.org/abs/2212.08073)
- Chan, C. H., Wang, W., Lee, H. Y., & Yu, H. F. (2023). ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. arXiv preprint arXiv:2308.07201. (https://arxiv.org/abs/2308.07201)
- Chiang, T. L., Hsu, W. C., & Lee, H. Y. (2023). Can Large Language Models Be an Accurate Evaluator?. arXiv preprint arXiv:2307.13071. (https://arxiv.org/abs/2307.13071)
- Hong, S., Zheng, X., Chen, J., Cheng, Y., Zhang, C., Wang, Z., … & Cui, L. (2023). MetaGPT: Meta Programming for Multi-Agent Collaborative Framework. arXiv preprint arXiv:2308.00352. (https://arxiv.org/abs/2308.00352)
- Li, G., M G., Madaan, A., Connections, S., A D., H T., … & Zaharia, M. (2023). CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society. arXiv preprint arXiv:2303.17760. (https://arxiv.org/abs/2303.17760)
- Madaan, A., Tandon, N., Gupta, P., Hallinan, N., Gao, L., Wiegreffe, S., … & Yazdanbakhsh, A. (2023). Self-Refine: Iterative Refinement with Self-Feedback. arXiv preprint arXiv:2303.17651. (https://arxiv.org/abs/2303.17651)
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 6197-6209. (https://arxiv.org/abs/2201.11903)
- Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint arXiv:2305.10601. (https://arxiv.org/abs/2305.10601)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











