







引言
随着我们一步步构建出越来越复杂的 AI Agent,赋予它们高级工具和更智能的策略,一个至关重要的问题浮出水面:我们如何知道这些 Agent 是否真的有效、可靠?当它们行为不符合预期时,我们又该如何诊断和修复问题?在 Agent 被部署到真实世界后,我们又该如何持续监控它们的表现?本章,我们将深入探讨 Agent 开发与运维生命周期中不可或缺的三个支柱:评估 (Evaluation)、调试 (Debugging) 和 可观测性 (Observability)。掌握这些方法、工具和实践,是确保我们构建的 Agent 不仅功能强大,而且稳定、可信、高效的关键。
10.1 Agent 评估的挑战与复杂性
首先,我们需要认识到评估 AI Agent 并非易事。其挑战源于 Agent 的固有特性:
- 开放域任务: 许多 Agent 需要在无法预先穷举所有情况的开放环境中工作。
- 多步骤交互: Agent 的决策通常涉及一系列相互依赖的思考、行动和观察步骤,单一指标难以衡量整体效果。
- 对环境的依赖性: Agent 的表现可能高度依赖于其与之交互的外部工具、API 或动态变化的在线环境。
- 结果的多样性与非确定性: 对于同一个任务,可能有多种可接受的解决方案路径和最终结果,且 LLM 的输出本身就带有一定的随机性。
这些复杂性意味着我们需要一套更全面、更细致的评估方法论。
10.2 设计有效的评估策略
面对评估的复杂性,仅仅罗列指标是不够的,我们需要制定清晰的评估策略:
- 评估目标设定: 评估的第一步是明确:对于这个特定的 Agent,什么是“成功”? 是任务完成率?是用户满意度?是成本效率?还是安全性?需要根据 Agent 的应用场景和预期目标,定义清晰、可衡量的成功标准。
- 方法组合选择: 没有万能的评估方法。一个有效的策略通常需要组合使用多种方法:
- 早期开发阶段: 可以利用自动化基准(10.4)进行快速迭代和比较不同设计的效果。
- 接近部署阶段: 人工评估(10.5)变得至关重要,以捕捉自动化指标无法衡量的细微差别,如结果质量、交互自然度、安全性等。
- 上线后: 在线 A/B 测试和持续的可观测性数据(10.7)可以提供最真实的性能反馈。
- 成本与效益权衡: 评估是有成本的——需要时间、人力、计算资源,甚至 API 调用费用。我们需要在评估的覆盖度、深度与可行性、成本之间做出明智的权衡。
10.3 核心评估指标体系
一个全面的评估体系应涵盖多个维度:
- 任务完成度:
- 成功率 (Success Rate): Agent 成功完成指定任务的比例。
- 目标达成度 (Goal Achievement): 衡量 Agent 最终输出在多大程度上满足了初始目标。
- 结果质量 (Quality Score): 对 Agent 输出结果的质量进行评分(通常需要人工评估)。
- 效率指标:
- 步数 (Number of Steps): 完成任务所需的思考-行动循环次数。
- 时间消耗 (Latency): 端到端的响应时间或完成任务的总时间。
- LLM 调用次数 & Token 消耗: 直接关系到运行成本。
- 成本 (Cost): API 调用费用、计算资源费用等。
- 鲁棒性指标 (Robustness): Agent 在面对输入扰动、环境噪声或工具临时失效等情况下的表现稳定性。
- 安全性与对齐指标 (Safety & Alignment):
- 是否遵循了预设的指令和约束(Guardrails)。
- 是否避免了生成有害、不当或偏见性内容。
- 其行为和决策过程是否符合人类的价值观和预期。
- 工具使用与规划指标:
- 工具选择准确率: 是否选择了最合适的工具来完成子任务。
- 工具调用成功率: 工具执行是否成功,有无异常。
- 工具参数准确性: 传递给工具的参数是否正确。
- 规划合理性与效率: 生成的计划步骤是否逻辑清晰、有效且没有冗余。
10.4 自动化评估平台与基准:快速迭代与横向比较
为了实现快速、可重复的评估,并方便比较不同 Agent 或模型的效果,社区开发了多种自动化评估平台和基准。了解这些主流基准有助于我们选择合适的工具来衡量 Agent 的特定能力:
-
AgentBench: 一个由清华大学等机构推出的综合性评估框架,旨在全面评估 LLM 作为 Agent 在多种不同环境和任务中的表现。它涵盖了操作系统交互、数据库查询、知识图谱推理、数字卡牌游戏、网页浏览等多种复杂场景,是目前衡量 Agent 通用能力的重要基准之一。
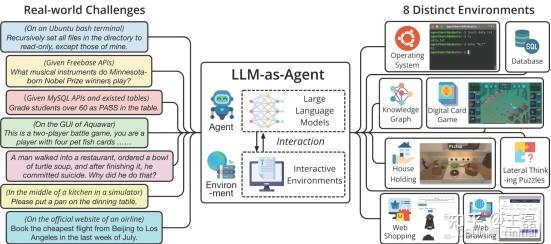
-
ToolBench: 同样来自清华大学等机构,专注于评估 Agent 使用真实世界 API 工具的能力。它构建了一个包含数千个真实 API 的庞大工具集,并设计了需要 Agent 进行复杂规划、选择合适 API 并正确调用以完成特定指令的任务。这对于需要与外部服务大量交互的 Agent 评估非常有价值。
-
WebArena: 一个基于真实网站构建的、可复现的 Web Agent 评估环境。Agent 需要在模拟浏览器环境中,与如购物网站、论坛、项目管理工具等真实网站进行交互,完成信息查找、内容创建、在线预订等贴近实际应用的复杂任务,是评估 Agent 网页自主导航和操作能力的有力工具。
-
SuperCLUE-Agent: 针对中文语言环境的 Agent 评估需求,SuperCLUE 推出了 SuperCLUE-Agent 榜单。它不仅评估模型的基础能力,更聚焦于 Agent 在中文语境下的规划、工具使用和任务解决能力。该榜单通常包含更贴合中文用户习惯和场景的任务,并提供公开排名,方便横向比较不同 Agent 在中文环境下的表现。
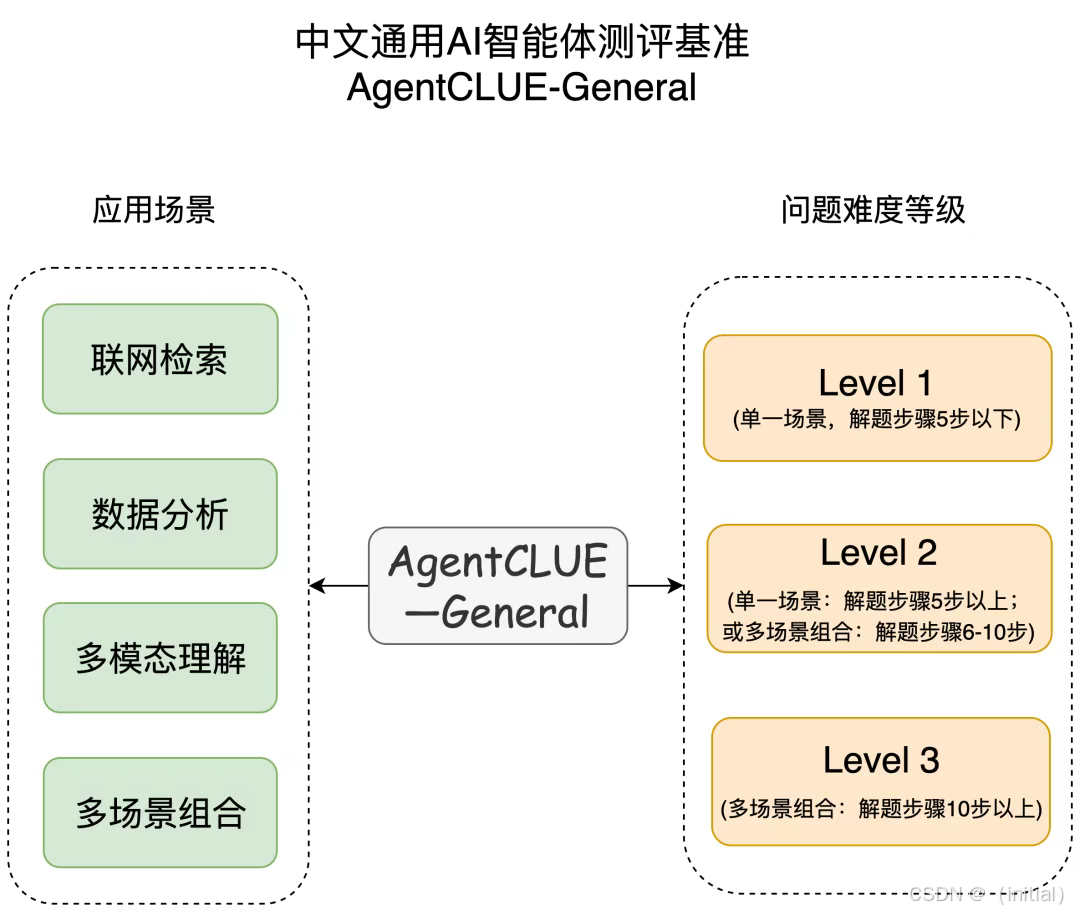
-
PaperBench: 这是一个专门为评估大型语言模型(LLMs)作为科学研究助手(Autonomous Agents for Scientific Literature)而设计的基准。它侧重于衡量 Agent 在处理科学文献方面的能力,例如:查找相关论文、总结论文核心贡献、比较不同论文的方法论、综合多篇论文的信息等。PaperBench 对于评估 Agent 在知识密集型、需要深度理解和信息综合能力的科研场景下的表现非常有意义。
选择与局限性:
选择哪个或哪些基准进行评估,取决于你最关心 Agent 的哪方面能力(通用性、工具使用、Web 交互、中文处理等)。需要注意的是,这些自动化基准虽然对于快速迭代、比较相对性能非常有用,但它们通常基于预设的任务和环境,可能无法完全反映 Agent 在真实、动态、开放世界中的全部表现。因此,自动化评估通常需要与人工评估(见下一节)相结合。
10.5 人工评估方法:弥补自动化之不足
由于 Agent 行为的复杂性和评估标准的主观性,人工评估是不可或缺的一环:
- 用户研究与可用性测试: 让真实用户与 Agent 交互,收集关于易用性、满意度、任务完成流畅度的反馈。
- 专家打分与评估: 由领域专家根据预定义的详细评估标准(Rubrics),对 Agent 的输出质量、推理过程、安全性等进行打分。
- A/B 测试与偏好判断: 将两个不同版本(例如,使用不同模型或 Prompt)的 Agent 同时呈现给用户,让用户选择更偏好的一个。
- 红队测试 (Red Teaming): 模拟恶意用户或极端场景,主动寻找 Agent 的漏洞、安全风险或可能产生有害输出的情况。
10.6 调试复杂 Agent 行为:工具、技术与思维
当 Agent 行为不符合预期时,调试是找出问题根源的关键。调试复杂 Agent 比调试传统软件更具挑战性。
可视化追踪工具:
像 LangSmith、Helicone、Phoenix/Arize 等工具是调试 Agent 的利器。它们能够帮助我们:
- 追踪完整的 Agent 执行轨迹: 清晰展示 Thought -> Action -> Observation 的每一步。
- 检查 LLM 调用详情: 查看发送给 LLM 的完整 Prompt、LLM 的原始响应、Token 消耗、耗时等。
- 监控工具使用: 查看 Agent 调用了哪个工具、传入了什么参数、工具返回了什么结果。
核心调试技术:
除了可视化工具,一些基础的调试技术仍然适用:
- 详细日志分析 (Logging): 在代码中记录关键信息点,用于事后分析。
- 中间步骤验证与断点: 检查 Agent 在关键步骤的内部状态或输出是否符合预期,模拟“断点”调试。
- 单元测试: 测试单个工具或 Agent 内部的某个模块(如 Prompt 生成逻辑)是否按预期工作。
- 集成测试: 测试 Agent 各个组件(LLM、工具、Memory)之间的交互是否顺畅。
调试工作流与思维模式:
掌握正确的调试思维同样重要:
- 回溯追踪 (Traceback): 从观察到的失败结果(如错误答案、异常行为)出发,利用追踪工具沿着执行链反向追溯,检查每一步的输入、输出和决策,定位问题首次出现的环节。
- 问题隔离 (Isolation): 有系统地缩小问题范围。问自己:是 LLM 理解错了指令吗? 是 Prompt 设计有歧义或引导错误吗? 是 工具本身出错了,还是 Agent 错误地使用了工具? 是 规划逻辑本身存在缺陷吗? 还是外部环境因素(如 API 不可用)导致的?尝试单独测试可疑组件。
- 复现与简化 (Reproduction & Simplification): 首先要能稳定地复现问题。然后,尝试简化导致问题的输入、环境或 Agent 配置,去除无关变量,更容易定位核心原因。
调试图相关行为的要点:
如果 Agent 使用了知识图谱工具,调试时需要特别关注:
- 检查生成的图查询语句的语法和意图是否正确。
- 验证知识图谱返回结果的准确性和相关性。
- 如果 Agent 基于图结构进行推理,需理解其图遍历或推理路径是否符合逻辑。
10.7 可观测性 (Observability) 实践:实时洞察 Agent 行为
可观测性关注的是在 Agent 运行时持续收集数据,以实时了解其状态、性能和行为,这对于生产环境中的 Agent 至关重要。它的目标是构建全面的监控系统,以实时了解 Agent 在运行时的表现、发现潜在问题并收集改进数据。这通常建立在三大支柱之上:
追踪 (Tracing):
- 记录完整的端到端任务执行链(用户输入 -> Thought -> Action -> Observation -> … -> 最终输出)。
- 包含每次 LLM 调用的详细信息(使用的模型、完整 Prompt、原始响应、耗时、Token 消耗)。
- 包含每次工具调用的详细信息(工具名称、输入参数、输出结果、耗时、成功/失败状态)。
- 记录 Agent 内部状态的关键变化(如 Memory 更新)。
日志 (Logging):
- 记录比追踪更细节、更灵活的信息。
- 例如:详细的 Prompt 构建过程、LLM 返回的原始文本(可能包含反思、中间思考)、工具执行的详细日志、遇到的各种错误(如 Prompt 格式错误、API 超时、输出解析失败)、自我反思步骤的具体内容等。
指标 (Metrics):
- 对追踪和日志数据进行聚合,形成可量化、可监控的指标。常见的关键指标包括:
- 业务指标: 任务成功率、特定目标的达成率、用户满意度评分(如果可收集)。
- 性能指标: 端到端请求延迟(平均值、P95、P99)、LLM 调用平均延迟、工具调用平均延迟。
- 成本指标: 平均 Token 消耗(Prompt Tokens + Completion Tokens)、单位任务的 API 调用费用。
- 错误率: Agent 执行失败率、工具调用失败率、输出解析错误率、特定类型异常(如幻觉、安全违规)的发生频率。
- 图相关指标: (若使用图)如图查询成功率、图查询平均延迟、返回结果的相关性或准确率(如果能建立自动判断机制)。
总结与展望
在本章中,我们系统地探讨了确保 AI Agent 可靠与高效的三大支柱:评估、调试与可观测性。我们了解了评估的挑战、策略、指标和方法(包括了 AgentBench, ToolBench, WebArena, SuperCLUE-Agent 等自动化基准以及 OpenAI 的评估实践);掌握了调试复杂 Agent 行为的工具、技术和思维模式;并学习了如何通过可观测性实践来实时洞察 Agent 的运行时表现。

理解这三者并非孤立存在,而是形成了一个持续改进的闭环至关重要。可观测性提供运行时的原始数据,这些数据用于评估 Agent 的实际表现和发现潜在问题;评估的结果(无论是自动化基准分数还是人工反馈)指明了需要调试的方向和优先级;调试修复问题后,又需要通过可观测性来监控改进效果,并进行新一轮的评估。正是这个闭环驱动着 Agent 不断迭代优化。
随着 Agent 技术的飞速发展,评估、调试和可观测性技术也在不断演进。未来,我们可以期待更智能、更自动化的评估基准;更强大的、能够理解 Agent 内部状态的可视化调试工具;以及对 Agent 安全性、对齐和伦理方面更深入、更细致的监控与评估方法。负责任地开发和部署 Agent,离不开在这些领域的持续投入和创新。
内容同步在gzh:智语Bot




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











