







章节引导:在上一章,我们深入探索了 LlamaIndex 在构建高级 RAG 应用方面的强大能力,体验了其灵活的数据结构和多样的索引类型。本章,我们将转向另一个在 LLM 应用开发领域极具影响力的框架——LangChain。与 LlamaIndex 以数据为中心的设计理念不同,现代 LangChain 的核心驱动力是其强大的LCEL (LangChain Expression Language)。LCEL 强调通过声明式的、可组合的管道 (|) 来编排各种组件(Runnable),构建出灵活、透明且功能强大的应用。本章,我们将聚焦于如何淋漓尽致地运用 LCEL 来编排 LangChain 的各种 RAG 组件,实现诸如历史感知 RAG (Conversational RAG)、自查询检索 (Self-Querying Retriever) 等高级功能,并学习如何利用 RAGAs 等工具评估这些复杂 RAG 链的实际效果。准备好体验 LCEL 带来的编程乐趣吧!
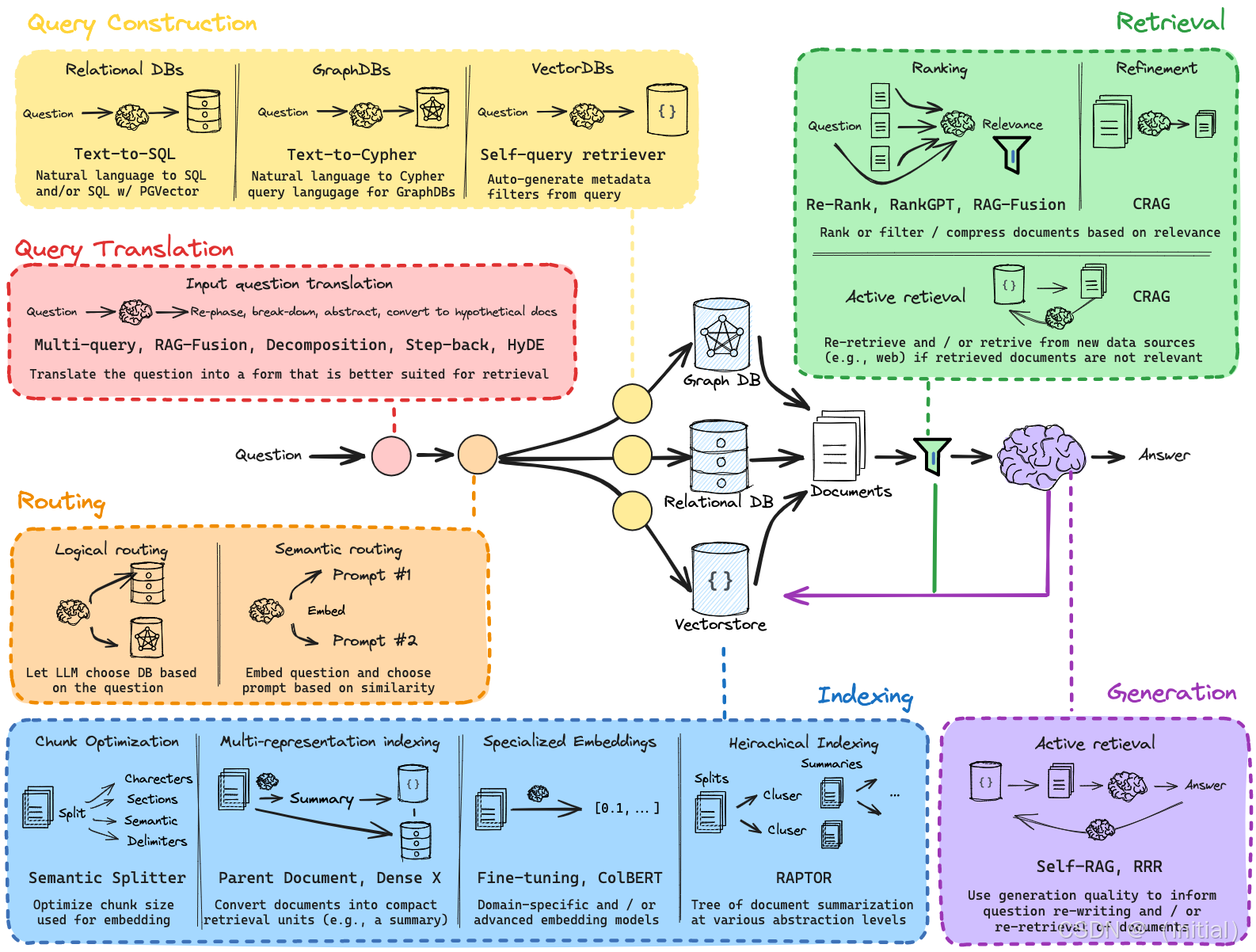
6.1 LCEL:LangChain RAG 的编排引擎
我们在第三章初识了 LCEL 在组合 Prompt 和 LLM 时的威力。在 RAG 场景下,LCEL 的编排能力得到了更全面的体现。可以说,LCEL 就是现代 LangChain RAG 应用的“操作系统”或“胶水语言”。
LCEL 核心思想回顾:
- 一切皆 Runnable: LangChain 的核心组件(LLM、ChatModel、PromptTemplate、Retriever、OutputParser、甚至自定义函数)都实现了
Runnable接口。 - 管道 (
|) 组合: 使用 Python 的|操作符可以将Runnable组件像管道一样连接起来,前一个组件的输出自动成为下一个组件的输入。 - 声明式与可组合: 代码即定义了数据流,清晰直观,易于修改和扩展。
LCEL 实现基础 RAG 链示例:
让我们看看如何用纯 LCEL 来表达一个基础的 RAG 流程:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_chroma.vectorstores import Chroma # Assuming Chroma from Ch4
import os
from dotenv import load_dotenv
load_dotenv()
# Assume OPENAI_API_KEY is set
# 1. 准备基础组件 (假设已有向量存储)
persist_directory = "./chroma_db_lc" # Use the same Chroma DB from Ch4/5
embedding_function = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=embedding_function,
collection_name="my_rag_collection" # Ensure collection name matches
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # Basic retriever
llm = ChatOpenAI(model="gpt-4o")
output_parser = StrOutputParser()
# 2. 定义 RAG Prompt 模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 3. 使用 LCEL 构建 RAG 链
# Helper function to format retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 定义 RAG 链 (核心部分)
rag_chain_from_docs = (
{
"context": lambda input: format_docs(input["documents"]), # Process retrieved docs
"question": lambda input: input["question"] # Pass through the question
}
| prompt
| llm
| output_parser
)
# 定义完整的数据处理流程
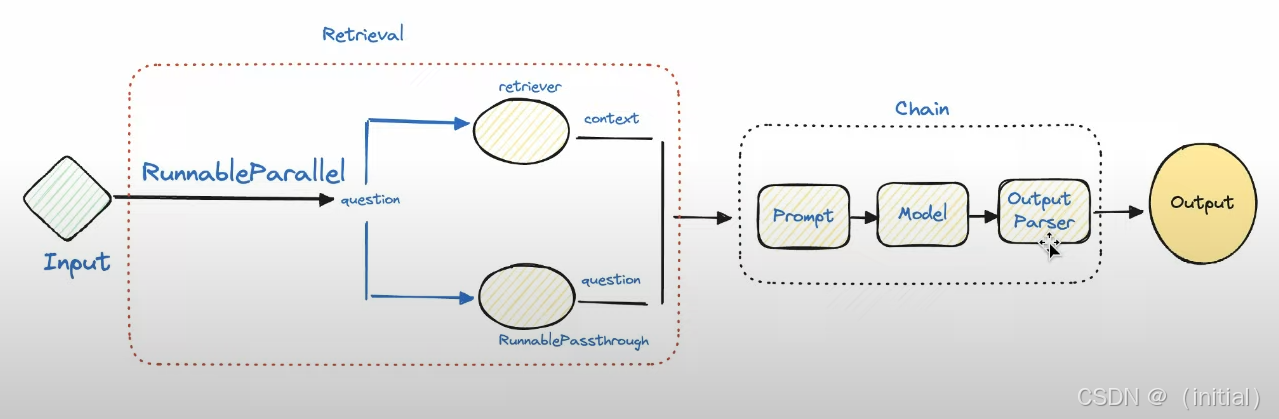
# RunnableParallel allows running retriever and passing question in parallel
# itemgetter('question') is equivalent to lambda input: input['question']
# RunnablePassthrough.assign adds the retrieved documents to the input dict for the next step
rag_chain = (
RunnableParallel(
{"documents": retriever, "question": RunnablePassthrough()} # Input is the question string
)
| RunnablePassthrough.assign( # Add formatted context for final prompt
context=lambda x: format_docs(x["documents"])
) # Optional: view intermediate context
| prompt # Use context and question
| llm
| output_parser
)
# 另一种更简洁的写法,直接组合
rag_chain_concise = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
# 4. 调用 RAG 链
question = "What is ChromaDB?"
try:
result = rag_chain_concise.invoke(question)
print("--- LCEL RAG Chain Result ---")
print(result)
# 查看中间步骤 (需要 LangSmith 或调试模式)
# from langchain.globals import set_debug
# set_debug(True)
# rag_chain_concise.invoke(question)
# set_debug(False)
except Exception as e:
print(f"Error invoking RAG chain: {e}")
LCEL 组件解析:
RunnableParallel: 允许并行执行多个Runnable,并将它们的输出收集到一个字典中。在这里,它并行地运行retriever(输入是问题字符串)和RunnablePassthrough(将原始问题字符串传递下去)。输出是{"documents": [...], "question": "..."}。RunnablePassthrough: 通常用于将输入原封不动地传递下去,或者与.assign()结合使用,向传递的字典中添加新的键值对。itemgetter(fromoperatormodule): 虽然上面例子用了lambda,但itemgetter('question')也是 LCEL 中常用的,用于从输入的字典中提取特定键的值。- Lambda Functions: LCEL 完美支持 Python 的 lambda 函数,可以方便地进行数据格式化(如
format_docs)或转换。 - 链式结构:
|操作符清晰地定义了数据如何在retriever,format_docs,prompt,llm,output_parser之间流动。
这个例子展示了 LCEL 如何将 RAG 的检索、格式化、Prompt 构建、LLM 调用、输出解析等步骤优雅地粘合在一起。
6.2 LangChain 的 Retriever 工具箱与 LCEL 集成
LangChain 提供了比基础 VectorStoreRetriever 更丰富的检索器(Retriever)组件,它们也都是 Runnable,可以轻松集成到 LCEL 链中。
常用高级 Retriever 概览:
MultiQueryRetriever: 当用户的原始查询可能不够精确或角度单一时,这个检索器会先让 LLM 根据原始查询生成多个不同角度的相似查询,然后分别用这些查询去执行基础检索,最后合并所有结果。这有助于提高召回率(Recall)。from langchain.retrievers.multi_query import MultiQueryRetriever # multi_query_retriever = MultiQueryRetriever.from_llm( # retriever=vectorstore.as_retriever(), llm=ChatOpenAI(temperature=0) # ) # # Now 'multi_query_retriever' can be used in an LCEL chainContextualCompressionRetriever: 基础检索器可能会返回包含大量无关信息的长文档块。这个检索器包装了另一个基础检索器,并在获取到文档后,使用一个DocumentCompressor对文档进行处理。压缩器可以是:LLMChainExtractor: 让 LLM 提取与查询相关的句子。EmbeddingsFilter: 过滤掉与查询嵌入相似度低于某个阈值的文档块。- 这有助于减少传递给最终 LLM 的上下文长度,降低噪声和成本。
from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import LLMChainExtractor, EmbeddingsFilter # compressor = LLMChainExtractor.from_llm(llm) # embeddings_filter = EmbeddingsFilter(embeddings=embedding_function, similarity_threshold=0.76) # compression_retriever = ContextualCompressionRetriever( # base_compressor=embeddings_filter, # or compressor # base_retriever=vectorstore.as_retriever() # ) # # Use 'compression_retriever' in LCELSelfQueryingRetriever: (本章实验重点) 能够让 LLM 分析用户的自然语言查询,自动提取元数据过滤条件,并结合语义搜索进行检索。ParentDocumentRetriever: 解决 RAG 中经典的 Chunk 大小问题。它允许你先将文档分割成较小的块进行索引(便于精确匹配),但在检索到这些小块后,返回包含它们的、更大的“父文档”块给 LLM。这让 LLM 能获得更完整的上下文。
LCEL 集成:
由于所有这些 Retriever 都遵循 Runnable 接口(通常接受字符串查询作为输入,输出 List[Document]),它们可以像基础 retriever 一样,直接用 | 操作符连接到 LCEL 链的其他部分(如 format_docs 函数)。
6.3 动手实验(一):构建历史感知的 RAG 链 (Conversational RAG)
挑战: 标准的 RAG 链是无状态的。如果用户进行多轮对话(“它是什么?” -> “那它和 X 有什么关系?”),后续轮次的查询需要结合之前的对话历史才能被正确理解和执行。
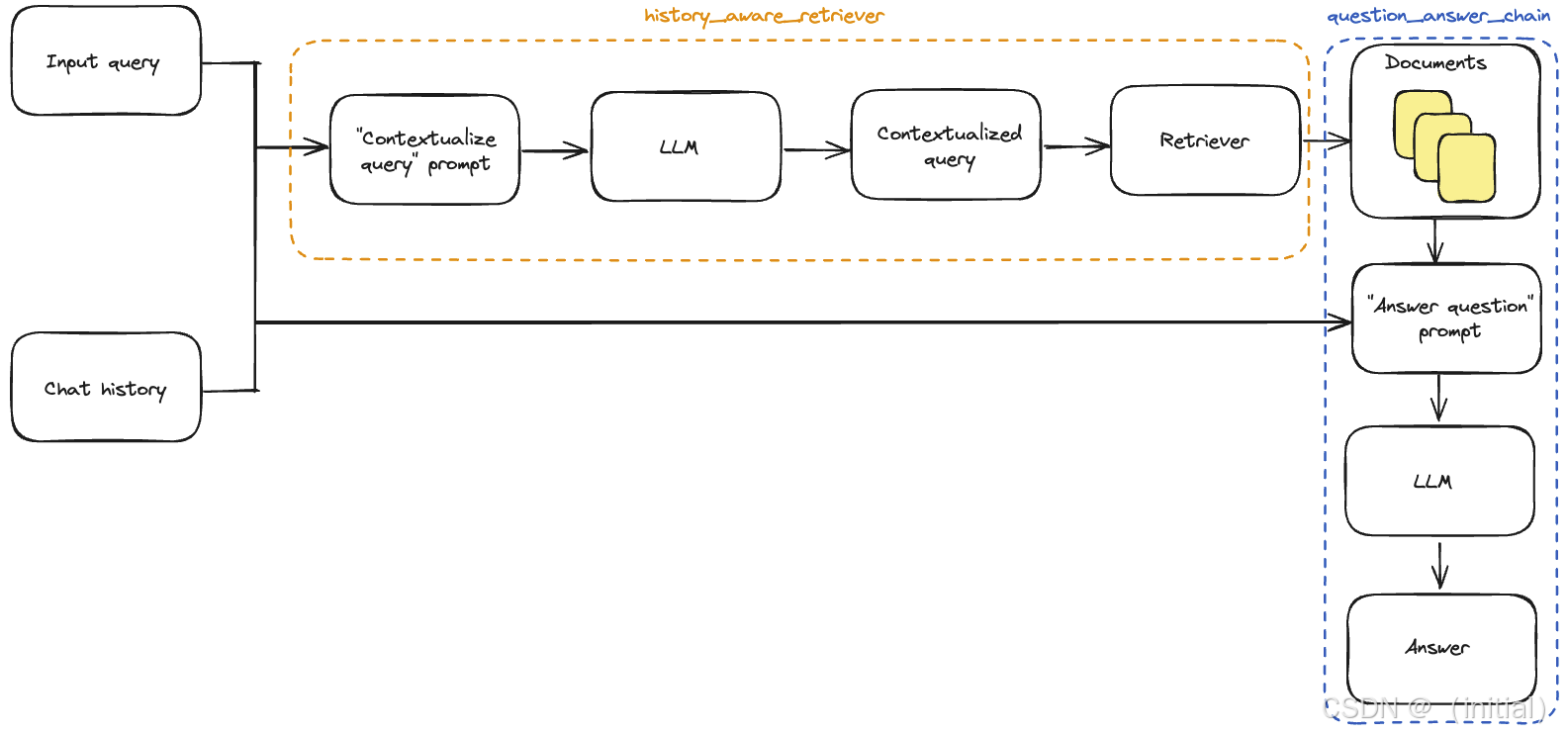
核心机制:
- 管理聊天历史: 需要存储对话的轮次信息(用户问题、AI 回答)。LangChain 提供了多种
Memory组件来处理,但也可以手动管理。 - 生成独立查询 (Condensing question): 在进行检索之前,需要结合当前的聊天历史和用户的新问题,生成一个独立的、包含所有必要上下文的查询语句。例如,将 (“X 是什么?”, “那它和 Y 的区别呢?”) 转换为 “X 和 Y 的区别是什么?”。这个步骤通常也由一个 LLM 完成。
- 执行 RAG: 使用这个独立查询去执行标准的 RAG 流程(检索相关文档 -> 生成答案)。
LCEL 实现:
LCEL 使得编排这个有状态的流程变得相对容易。
from langchain.memory import ChatMessageHistory # Simple in-memory history
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 1. 定义用于“压缩问题”的 Prompt 和 LLM
condense_question_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = ChatPromptTemplate.from_template(condense_question_template)
# 使用一个 LLM 来执行问题压缩
condense_llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo") # Can use a cheaper model
# 2. 定义回答问题的 RAG Prompt (复用之前的,但加入 chat_history placeholder)
answer_template = """Answer the question based only on the following context:
{context}
Chat History (for context, if helpful):
{chat_history}
Question: {question}
"""
ANSWER_PROMPT = ChatPromptTemplate.from_messages(
[
("system", answer_template),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"), # Note: this will be the *standalone* question
]
)
# 3. 复用之前的 retriever 和 format_docs 函数
# retriever = vectorstore.as_retriever(...)
# def format_docs(docs): ...
# 4. 定义最终答案生成链 (从上下文和 standalone 问题生成答案)
answer_chain = (
RunnablePassthrough.assign(context=lambda input: format_docs(input["documents"]))
| ANSWER_PROMPT
| ChatOpenAI(model="gpt-4o") # Use a capable model for final answer
| StrOutputParser()
)
# 5. 定义完整的对话 RAG 链 (结合问题压缩和 RAG 回答)
# 输入是 {"question": "...", "chat_history": [...]}
# 输出是 standalone_question
condense_chain = CONDENSE_QUESTION_PROMPT | condense_llm | StrOutputParser()
# 完整链: 先判断是否需要压缩问题,然后检索,最后生成答案
# 如果没有 history,直接用原始 question;否则,调用 condense_chain
from langchain_core.runnables import RunnableBranch
conversational_rag_chain = RunnableBranch(
# Condition: If chat_history exists and is not empty
(
lambda x: bool(x.get("chat_history")),
# True branch: Condense question first
RunnablePassthrough.assign(
standalone_question=condense_chain
) # Pass history and question to condense_chain
),
# False branch: No history, use original question as standalone
(
RunnablePassthrough.assign(standalone_question=lambda x: x["question"])
)
) | RunnableParallel(
# Retrieve documents based on the standalone_question
retrieved_documents = lambda x: retriever.invoke(x["standalone_question"]),
# Pass along other necessary info
standalone_question = lambda x: x["standalone_question"],
original_question = lambda x: x["question"],
chat_history = lambda x: x["chat_history"]
) | RunnablePassthrough.assign(
# Generate the final answer using retrieved docs and standalone question
answer = lambda x: answer_chain.invoke({
"documents": x["retrieved_documents"],
"question": x["standalone_question"],
"chat_history": x["chat_history"] # Pass history to final prompt if needed
})
)
# 6. 使用 RunnableWithMessageHistory 包装,自动管理历史
# 需要一个函数来获取 session history
demo_ephemeral_chat_history = ChatMessageHistory() # Simple in-memory store for demo
def get_session_history(session_id: str) -> ChatMessageHistory:
# In production, you'd fetch history based on session_id from a persistent store
return demo_ephemeral_chat_history
conversational_chain_with_history = RunnableWithMessageHistory(
conversational_rag_chain,
get_session_history,
input_messages_key="question", # User input goes here
history_messages_key="chat_history", # History is injected here
output_messages_key="answer", # The final 'answer' key from the chain is the output
)
# 7. 进行多轮对话测试
print("\n--- Testing Conversational RAG Chain ---")
print("Session ID: user123")
# First turn
print("\nTurn 1:")
input1 = "What is ChromaDB?"
config = {"configurable": {"session_id": "user123"}}
try:
response1 = conversational_chain_with_history.invoke({"question": input1}, config=config)
print(f"User: {input1}")
print(f"AI: {response1}") # Output is the value of 'answer' key
except Exception as e:
print(f"Error in turn 1: {e}")
# Second turn (follow-up question)
print("\nTurn 2:")
input2 = "Is it an open-source project?"
try:
response2 = conversational_chain_with_history.invoke({"question": input2}, config=config)
print(f"User: {input2}")
print(f"AI: {response2}")
except Exception as e:
print(f"Error in turn 2: {e}")
# 查看历史
print("\nChat History (user123):")
print(demo_ephemeral_chat_history.messages)
代码讲解与分析:
- 问题压缩 (Condensing): 我们定义了一个
condense_chain,它接收chat_history和question,然后调用 LLM 生成一个standalone_question。 - 答案生成 (Answering):
answer_chain接收documents(检索结果)、standalone_question和chat_history(可选,用于最终答案的上下文),然后生成最终答案。 - LCEL 编排:
RunnableBranch用于根据chat_history是否存在来决定是否运行condense_chain。RunnableParallel并行地运行检索器(使用standalone_question)并将所需信息(独立问题、原始问题、历史)传递下去。RunnablePassthrough.assign用于将中间结果(如standalone_question,retrieved_documents,answer)添加到传递的数据字典中。
- 状态管理 (
RunnableWithMessageHistory): 这是 LangChain 提供的一个非常方便的包装器。它自动处理了从get_session_history函数获取历史、将其注入到链的history_messages_key、运行核心链、然后将用户的输入 (input_messages_key) 和 AI 的输出 (output_messages_key) 保存回历史的过程。这极大地简化了对话状态的管理。
6.4 动手实验(二):实现自查询检索器 (Self-Querying Retriever)
挑战: 用户的问题常常包含隐含的过滤条件,如时间(“去年的报告”)、类别(“关于 AI 的文章”)、来源(“来自官方文档”)等。基础的向量检索无法直接利用这些信息。
工作原理:
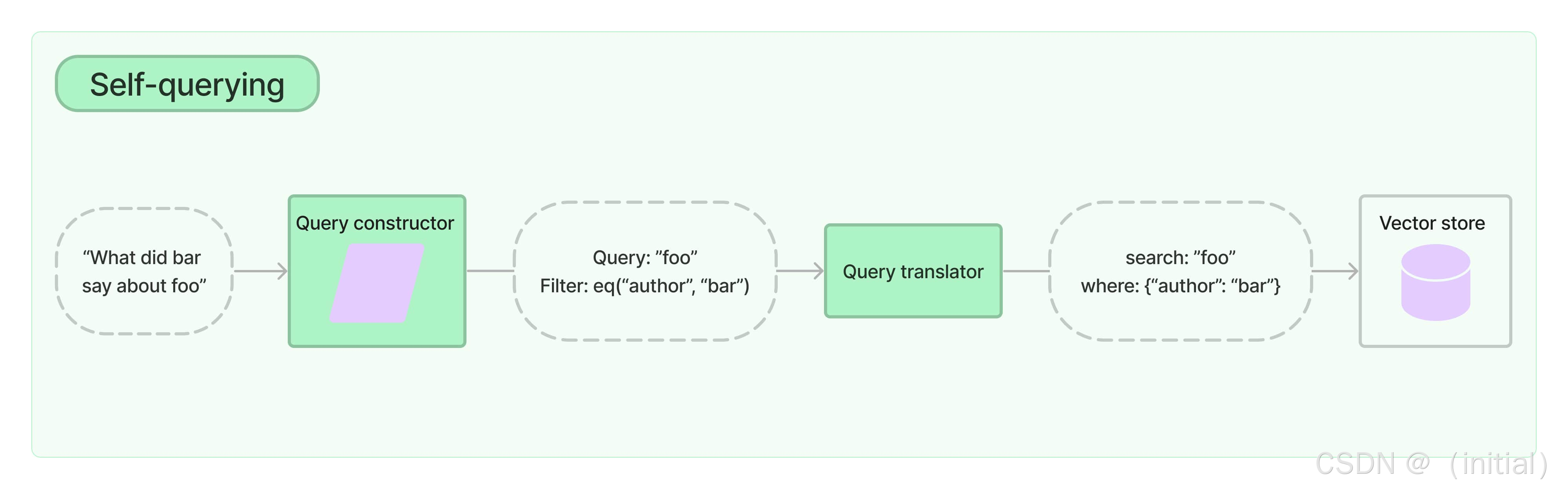
SelfQueryingRetriever 利用 LLM 的能力来弥补这一差距:
- 定义元数据结构 (Attribute Schema): 你需要清晰地告诉检索器你的文档元数据包含哪些字段、它们的类型以及描述(方便 LLM 理解)。
- LLM 解析查询: 当接收到自然语言查询时,检索器会内部调用一个 LLM。这个 LLM 的任务是:
- 识别查询中用于语义搜索的核心部分(Query)。
- 识别查询中隐含的元数据过滤条件,并将其转换为结构化的过滤器(Filter),通常使用 LangChain 的过滤器表达式语言(如比较器
eq,gt,lt和逻辑操作符and,or)。
- 执行查询: 检索器将解析出的结构化过滤器传递给底层向量存储的
filter参数,同时使用解析出的语义查询部分进行向量相似度搜索。最终只返回同时满足语义相似性和元数据过滤条件的文档。
代码实现与解读:
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
# 1. 定义元数据字段信息 (Attribute Schema)
# 这需要和你实际存储在向量数据库中的元数据字段匹配
metadata_field_info = [
AttributeInfo(
name="source",
description="The source document or website the chunk came from",
type="string",
),
AttributeInfo(
name="topic",
description="The main topic of the document chunk",
type="string", # Could be 'enum' if you have fixed topics
),
# Add more fields if your data has them, e.g., year, author, etc.
# AttributeInfo(name="year", description="The year the document was published", type="integer"),
]
document_content_description = "Content chunks about AI frameworks and vector databases"
# 2. 实例化 SelfQueryingRetriever
# 需要提供 LLM、向量存储 和 元数据信息
# LLM 用于将自然语言查询解析为结构化查询
query_llm = ChatOpenAI(temperature=0, model="gpt-4o") # Needs a capable LLM
self_query_retriever = SelfQueryRetriever.from_llm(
llm=query_llm,
vectorstore=vectorstore, # Use the same vectorstore from earlier
document_contents=document_content_description,
metadata_field_info=metadata_field_info,
verbose=True # Show the generated query structure
)
# 3. 执行带有过滤条件的自然语言查询
print("\n--- Testing Self-Querying Retriever ---")
query_with_filter = "What is ChromaDB according to the chroma_readme?"
# query_with_filter = "Tell me about frameworks from the langchain_doc"
# query_with_filter = "Information about databases published in 2024" # Needs 'year' metadata
try:
results_self_query = self_query_retriever.invoke(query_with_filter)
print(f"\nResults for query: '{query_with_filter}'")
if results_self_query:
for doc in results_self_query:
print(f"- {doc.page_content} (Metadata: {doc.metadata})")
else:
print("No documents found matching the self-query criteria.")
except Exception as e:
print(f"Error during self-query retrieval: {e}")
# Common errors: LLM failing to generate valid filter, metadata mismatch
代码解读:
- 我们首先定义了
metadata_field_info,精确描述了向量存储中文档元数据的每个字段(名称、描述、类型)。这是 Self-Querying 的关键,LLM 需要这些信息才能正确生成过滤器。 document_content_description帮助 LLM 理解文档的主要内容。SelfQueryingRetriever.from_llm创建检索器实例。我们传入了用于解析查询的 LLM、底层的向量存储对象以及元数据描述。- 设置
verbose=True非常重要,它会打印出 LLM 生成的结构化查询(包含query字符串和filter结构),让你能看到它是否正确理解了自然语言查询中的过滤条件。 - 调用
invoke方法传入自然语言查询。检索器内部会调用 LLM 生成结构化查询,然后执行过滤和向量搜索。
深入理解与讨论:
- 适用场景: 非常适合那些用户查询经常包含对特定属性(时间、类别、来源、作者等)进行筛选的 RAG 应用。
- 前提条件:
- 高质量、一致的元数据: 文档必须被打上准确、结构化的元数据标签,且
metadata_field_info必须与之精确匹配。 - 强大的 LLM: 用于解析查询的 LLM 需要足够智能,能够可靠地从自然语言中提取过滤条件并生成正确的过滤结构。GPT-4o 或类似级别的模型通常表现更好。
- 高质量、一致的元数据: 文档必须被打上准确、结构化的元数据标签,且
- 潜在风险:
- 错误过滤: LLM 可能误解查询,生成错误的过滤条件,导致检索不到正确结果或返回不相关结果。
- 性能开销: 每次查询都需要额外调用一次 LLM 来生成结构化查询,增加了延迟和成本。
- 复杂查询: 对于过于复杂或模糊的过滤条件,LLM 可能难以处理。
Self-Querying 是一个强大的功能,但在生产中使用需要充分测试其在你的特定数据和查询模式下的鲁棒性。
6.5 LangChain RAG 评估实战 (结合 RAGAs)
构建了高级 RAG 链后,评估其效果至关重要。RAGAs 是一个流行的开源库,专门用于评估 RAG 管道的各个方面,无需人工标注的“标准答案”(Ground Truth),尽管有标准答案会更好。
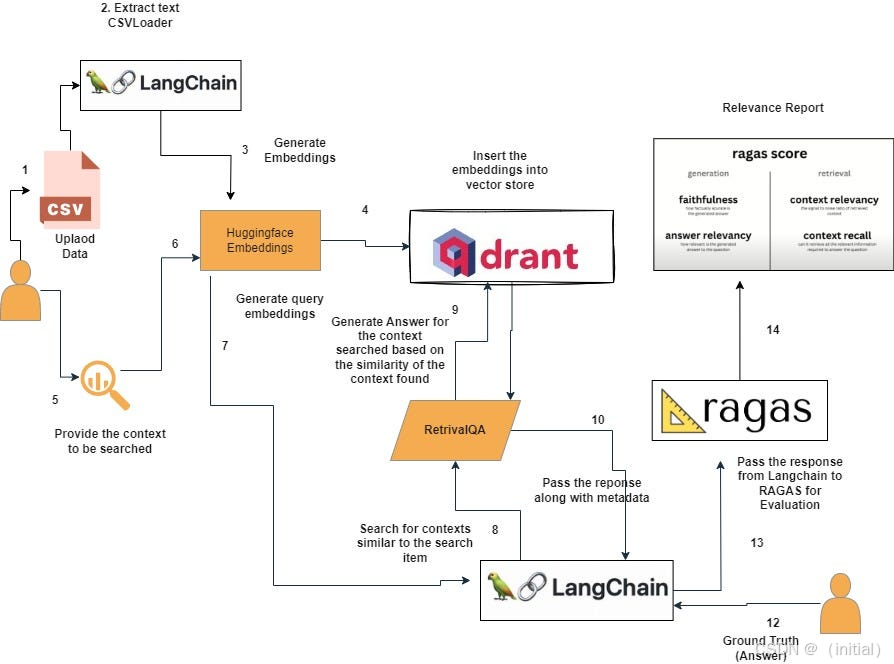
实践:评估本章构建的 RAG 链
假设我们想评估历史感知 RAG 链和自查询 RAG。
-
准备评估数据集:
- 对于历史感知 RAG:需要包含多轮对话的问题序列。例如:
[{"question": "What is X?"}, {"question": "How does it compare to Y?"}]。还需要提供每次查询实际检索到的上下文 (contexts) 和生成的答案 (answer)。 - 对于自查询 RAG:需要包含带有隐含过滤条件的查询。例如:
"Tell me about database articles"。同样需要提供检索到的上下文和生成的答案。 - (可选)提供标准答案 (
ground_truth) 以进行更全面的评估。
- 对于历史感知 RAG:需要包含多轮对话的问题序列。例如:
-
运行 RAG 链生成结果: 使用你的 RAG 链处理评估数据集中的问题,记录下每个问题对应的
question,contexts(list of retrieved document strings),answer。 -
使用 RAGAs 进行评估:
# 需要安装 ragas[openai] 或 ragas[litellm] 等
# pip install ragas pandas datasets litellm # Example using litellm
# 假设你已经运行了 RAG 链并收集了结果,存储在 pandas DataFrame 或 Hugging Face Dataset 中
# Example structure:
# data = {
# 'question': ["What is ChromaDB?", "Is it open-source?"], # Example for conversational
# # Contexts needs to be List[str] for each question
# 'contexts': [
# ["ChromaDB is an open-source embedding database...", "It's easy to run locally."],
# ["Yes, ChromaDB is licensed under Apache 2.0."]
# ],
# 'answer': [
# "ChromaDB is an open source database for embeddings that is easy to run locally.",
# "Yes, ChromaDB is an open-source project under the Apache 2.0 license."
# ],
# # 'ground_truth': ["ChromaDB is an open-source database...", "Yes, it is open source."] # Optional
# }
# from datasets import Dataset
# eval_dataset = Dataset.from_dict(data)
from ragas import evaluate
from ragas.metrics import (
faithfulness, # Answer grounded in context?
answer_relevancy, # Answer relevant to question?
context_precision, # Signal-to-noise ratio in context?
context_recall, # Able to retrieve all necessary info?
# For Conversational RAG, RAGAs might have specific metrics or you adapt these
)
# 假设 eval_dataset 已经准备好
# RAGAs 评估需要调用 LLM (默认 OpenAI gpt-3.5-turbo-16k) 和 Embeddings
# 确保相关 API Key 已设置
print("\n--- Evaluating RAG pipeline using RAGAs ---")
try:
# 选择评估指标
metrics_to_evaluate = [
faithfulness,
answer_relevancy,
context_precision,
context_recall,
]
# 如果有 ground_truth, 可以加入 answer_semantic_similarity, answer_correctness 等
# 运行评估
# result = evaluate(
# eval_dataset,
# metrics=metrics_to_evaluate,
# # llm=..., # Can specify custom LLM/Embeddings if needed
# # embeddings=...
# )
# print("\nRAGAs Evaluation Results:")
# print(result)
# eval_df = result.to_pandas()
# print(eval_df.head())
print("RAGAs evaluation code commented out for brevity. Uncomment and run with your data.")
except Exception as e:
print(f"Error during RAGAs evaluation: {e}")
解读评估结果:
faithfulness: 评估答案是否完全基于提供的上下文,衡量“幻觉”程度。answer_relevancy: 评估答案与问题的相关性。context_precision: 评估检索到的上下文中,真正与答案生成相关的部分的比例(信噪比)。context_recall: 评估检索到的上下文是否包含了回答问题所需的所有必要信息。
分析这些指标可以帮助我们发现 RAG 链的瓶颈。例如:
faithfulness低 -> LLM 可能在“自由发挥”,未充分利用上下文。answer_relevancy低 -> 可能检索到的上下文不相关,或 LLM 未理解问题。context_precision低 -> Retriever 返回了太多无关信息,增加了 LLM 处理难度和成本。context_recall低 -> Retriever 未能找到所有必要的上下文信息。
针对性地优化 Retriever 配置、Prompt 或 LLM 选择,然后重新评估,形成闭环。
6.6 章节总结、对比与展望
在本章中,我们深入体验了 LangChain 利用其核心 LCEL 构建高级 RAG 应用的强大能力。
-
核心优势总结: 我们看到 LCEL 如何像胶水一样将各种 RAG 组件(Retriever, Prompt, LLM, Parser, Memory)流畅地粘合在一起,形成清晰、可组合、可扩展的 RAG 链。LangChain 提供了丰富的内置组件,LCEL 则赋予了开发者极大的灵活性来编排它们。
-
关键技术回顾: 我们掌握了:
- 使用 LCEL 构建 RAG 链的核心模式。
- LangChain 的多种高级 Retriever 组件(MultiQuery, ContextualCompression, SelfQuerying)。
- 如何利用 LCEL 和 Memory 实现历史感知的 RAG (Conversational RAG)。
- 如何配置和使用 Self-Querying Retriever 处理带隐含过滤条件的查询。
- 使用 RAGAs 对 RAG 链进行量化评估的方法。
-
对比 LangChain 与 LlamaIndex (Ch5):
- 设计哲学: LangChain (LCEL) 更强调链式组合 (Chaining/Piping) 和
Runnable接口的统一性,代码风格接近函数式编程的数据流。LlamaIndex 更偏向数据中心 (Data-centric),围绕Node、多样的Index结构和可配置的QueryEngine构建,面向对象风格更明显。 - 实现方式: 对于类似功能(如带 Reranker 的 RAG),LangChain 使用 LCEL 管道组合
Retriever和NodePostprocessor(Runnable),LlamaIndex 则通过配置RetrieverQueryEngine的node_postprocessors参数。实现方式不同,但都能达到目的。 - 易用性与灵活性: LCEL 对于熟悉函数式编程和 Python 迭代器/生成器的开发者可能更直观、更灵活(易于插入自定义函数)。LlamaIndex 的面向对象接口和更封装的
QueryEngine可能对某些开发者更易于上手,其丰富的内置索引类型是其独特优势。 - 优缺点: LangChain (LCEL) 极度灵活,与 Python 生态结合紧密,但构建复杂链时可能需要开发者对数据流有更清晰的理解。LlamaIndex 在索引结构和针对 RAG 的优化(如响应合成模式)方面可能更专注、更深入,但其 API 迭代较快曾是痛点(v0.10 后趋于稳定)。
- 选型: 两者都是优秀的框架。选择哪个(或组合使用)取决于项目需求、团队偏好以及对特定高级功能(如 LlamaIndex 的 KG Index 或 LangChain 的 Agent 工具)的需求。
- 设计哲学: LangChain (LCEL) 更强调链式组合 (Chaining/Piping) 和
-
连接未来: RAG 是构建知识增强型 LLM 应用(包括 Agent)的关键技术。无论是 LangChain 还是 LlamaIndex 构建 RAG 的能力,都将成为下一模块——智能核心 Agent——的重要知识来源和工具支撑。Agent 需要检索信息来做决策或回答问题,我们本章和上一章构建的 RAG 链或检索器将直接服务于 Agent。准备好进入更智能的 Agent 世界吧!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











