







章节引导:在第四章,我们成功搭建了 RAG 的基础数据管道,掌握了向量化、存储和基础检索的核心技能。然而,基础检索往往只是起点。为了应对更复杂的查询、提升答案质量、处理不同类型的数据关系,我们需要更强大的工具和策略。本章,我们将深入第一个主流 RAG 框架——LlamaIndex。LlamaIndex 以其灵活的、以数据为中心的设计理念,以及对多样化索引结构和可组合查询管道的强大支持而闻名。我们将重温其核心架构(这次着眼于其如何支撑高级功能),重点探索其超越基础向量搜索的高级索引技术与检索策略,并通过两个核心动手实验——构建融合重排序与查询转换的复杂查询管道,以及实践强大的图增强 RAG (KG-RAG)——来掌握构建更智能、更有效 RAG 应用的关键技能。
重要提示:LlamaIndex API 版本说明
LlamaIndex 框架发展迅速,其 API 经历过较快的迭代。本章及后续相关章节的示例代码将基于 LlamaIndex v0.10.x 及更高版本 的现代 API 结构。这些版本主要使用全局llama_index.core.Settings对象进行核心组件(如 LLM、嵌入模型)的配置,取代了旧版本中常用的ServiceContext。如果你在其他地方看到使用ServiceContext的旧代码,请注意其 API 可能与本章有所不同。
5.1 LlamaIndex 架构再探:为高级 RAG 而设计
我们在第四章接触了 LlamaIndex 的 VectorStore 接口。现在,我们需要更深入地理解其设计哲学,特别是那些使其能够支持高级 RAG 策略的架构元素: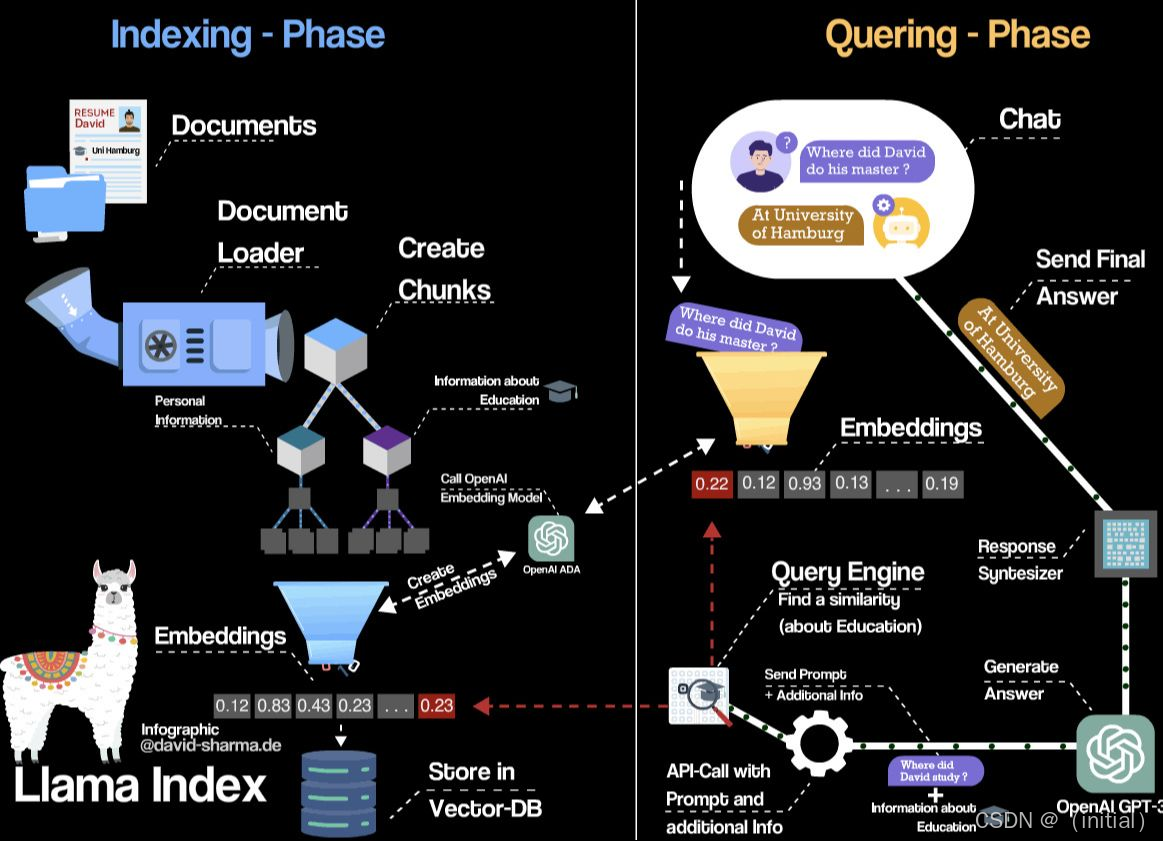
Document与Node: LlamaIndex 的核心数据单元是Node对象。一个Document可以被解析成多个Node。重要的是,Node对象不仅包含文本块 (text) 和元数据 (metadata),还可以包含关系 (relationships),如PREVIOUS/NEXT(指向相邻节点)、PARENT/CHILD(指向来源文档或子节点),这为构建更复杂的索引结构(如树状索引、图谱索引)奠定了基础。BaseIndex抽象: LlamaIndex 不局限于向量索引。它定义了一个BaseIndex抽象类,可以派生出各种不同类型的索引实现,如我们稍后会看到的SummaryIndex,TreeIndex,KeywordTableIndex,KnowledgeGraphIndex,当然也包括基础的VectorStoreIndex。这种设计提供了极大的灵活性。BaseRetriever: 检索器负责根据查询从索引中获取相关的Node。LlamaIndex 提供了多种内置检索器,也允许自定义检索逻辑。- 查询流程 (
retrieve->synthesize): LlamaIndex 的查询通常分为两步:- Retrieve: 使用
Retriever从索引中获取最相关的Node列表。 - Synthesize: 使用
ResponseSynthesizer将检索到的Node(上下文)和原始查询组合起来,交给 LLM 生成最终的响应。LlamaIndex 提供了不同的响应合成模式(如refine,compact,tree_summarize)。
- Retrieve: 使用
StorageContext: 方便地管理索引、向量存储、文档存储等的持久化和加载。Settings(代替旧版ServiceContext): 这是现代 LlamaIndex 中用于统一配置全局 LLM (Settings.llm)、嵌入模型 (Settings.embed_model)、分块大小 (Settings.chunk_size)、分块重叠 (Settings.chunk_overlap) 等核心组件和参数的方式。它使得配置更集中、代码更简洁。
理解这些组件及其交互方式,特别是 Node 的关系和全局 Settings 的配置作用,是掌握 LlamaIndex 高级功能的关键。它的设计允许你像搭乐高一样组合不同的索引、检索器、响应合成器以及各种转换步骤,构建出强大的自定义 RAG 管道。
5.2 LlamaIndex 高级索引与检索策略详解
LlamaIndex 的强大之处在于它远不止提供向量搜索。
超越基础向量索引
SummaryIndex(原ListIndex): 将所有Node视为一个列表。查询时,它会(可选地)遍历列表中的每个节点,并让 LLM 根据查询提炼答案。适用于对一系列文档进行摘要式回答或需要遍历所有上下文的场景。TreeIndex: 将Node构建成一个层级摘要树。根节点是所有叶子节点摘要的摘要,以此类推。查询时,可以从根节点开始,根据查询内容智能地向下导航到最相关的分支和叶子节点。适合需要自顶向下查询或概括性理解的场景。KeywordTableIndex: 从每个Node中提取关键词,并构建一个关键词到节点的映射表。查询时,提取查询中的关键词,直接查找包含这些关键词的节点。适合需要基于关键词精确查找的场景,可以与向量索引结合使用。KnowledgeGraphIndex: (本章实验重点)利用 LLM 从文本中提取实体 (Entities) 和关系 (Relations),构建成一个知识图谱(三元组:主语-谓语-宾语)。查询时,可以直接查询图谱中的实体信息或它们之间的关系。非常适合需要理解实体关系的问题。
讨论:选择哪种索引取决于你的数据特点和主要查询类型。通常,
VectorStoreIndex是起点,但结合其他索引类型(如关键词或图谱)往往能获得更好的效果。
增强检索效果的策略
仅仅改变索引类型有时还不够,优化检索过程本身同样重要:
- 查询转换 (Query Transformations):
- 目的: 改进原始的用户查询,使其对底层检索系统(尤其是向量嵌入)更友好。
- 示例:
-
HyDE(Hypothetical Document Embeddings): 让 LLM 先为查询生成一个假想的“完美答案文档”,然后使用这个假想文档的嵌入向量去进行检索。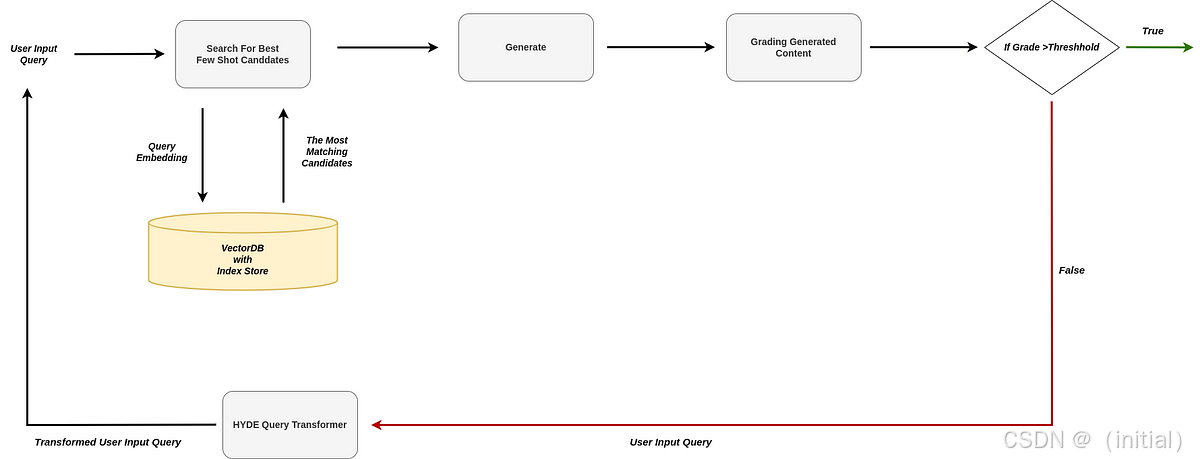
-
MultiStep Query: 将复杂问题分解为多个子问题,依次执行并综合结果。
-
- LlamaIndex 提供了
QueryTransform模块来实现这些转换。
- 重排序 (Re-ranking):
-
目的: 初步检索(如向量相似度)返回的 Top-K 结果可能并不都是最相关的,或者排序不理想。重排序使用更精确但计算成本更高的模型(如 Cross-Encoder 或专有 API 如 Cohere Rerank)对初步结果进行重新打分和排序,将最优质的文档推到最前面,再交给 LLM 生成答案。

-
LlamaIndex 提供了
SentenceTransformerRerank,CohereRerank等集成。
-
- 多路/融合检索 (Advanced Retrieval / Fusion):
-
目的: 结合不同检索策略(如向量搜索 + 关键词搜索 + 图谱搜索)或从多个不同索引中检索,然后将各路结果智能地融合起来,取长补短。
-
示例: Reciprocal Rank Fusion (RRF) 是一种常用的融合算法。
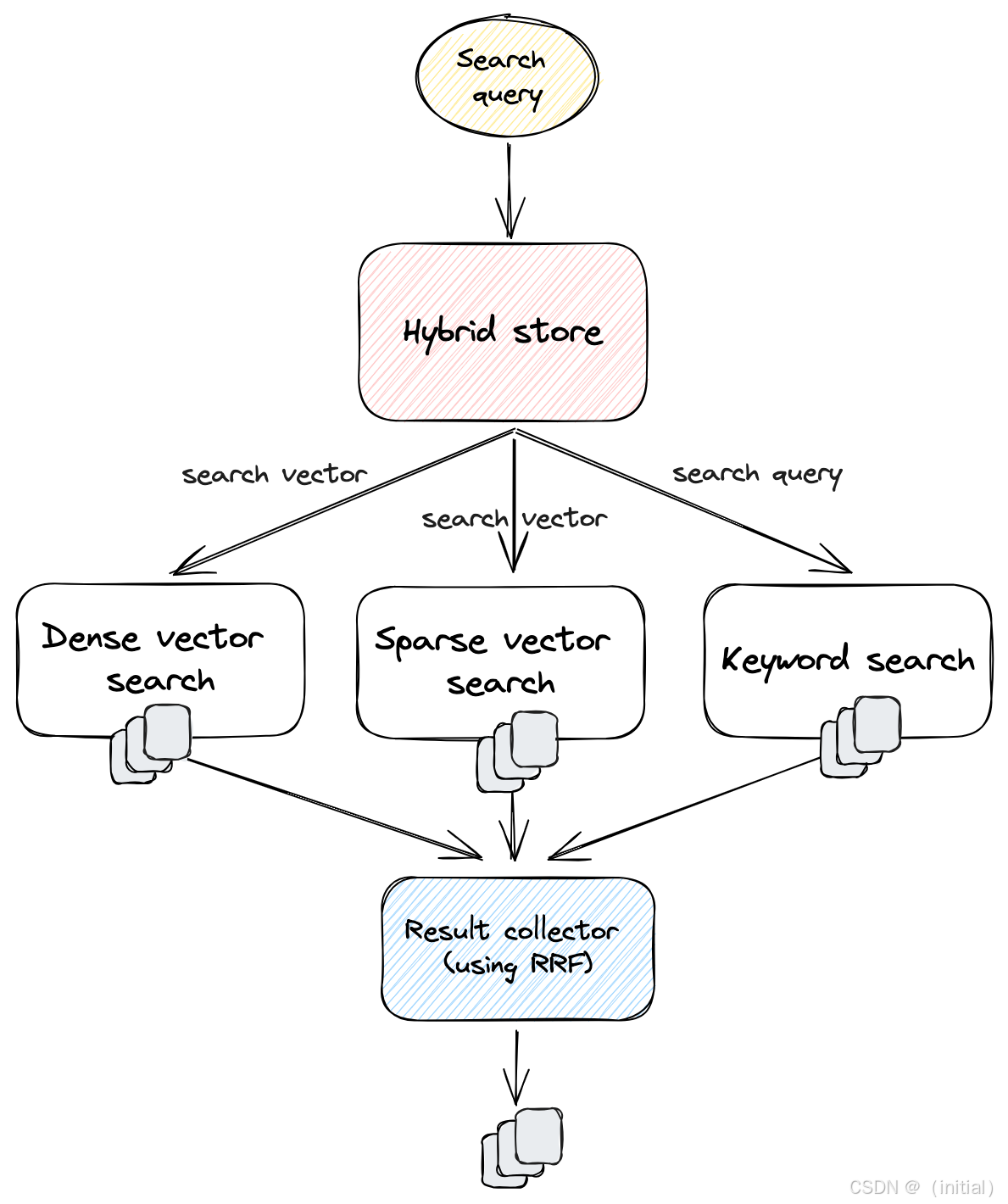
-
LlamaIndex 的
RouterRetriever或自定义检索器可以实现这类策略。
-
5.3 动手实验(一):构建融合重排序与查询转换的 RAG 查询管道
目标:实践如何组合 LlamaIndex 组件构建超越简单检索的 RAG 流程,并提升检索效果。
场景: 基础向量搜索效果不佳,我们将通过 HyDE 查询转换和 Cohere Rerank 来优化。
前置准备: 确保已安装相应库 (llama-index, llama-index-embeddings-openai, llama-index-llms-openai, llama-index-postprocessor-cohere-rerank 等),并在 .env 中设置好 OPENAI_API_KEY 和 COHERE_API_KEY。
代码实现
import os
from dotenv import load_dotenv
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
Settings, # Import Settings
QueryBundle,
PromptTemplate
)
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.postprocessor import CohereRerank
from llama_index.llms.openai import OpenAI # Import specific LLM
from llama_index.embeddings.openai import OpenAIEmbedding # Import specific Embedding
# 加载环境变量
load_dotenv()
# --- 1. 配置全局 Settings (Modern LlamaIndex way) ---
# 确保 API keys 在环境变量中
try:
# 使用性能较好的模型,也可选用 gpt-3.5-turbo 降低成本
Settings.llm = OpenAI(model="gpt-4o")
# 使用 OpenAI 的 embedding 模型
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
# Settings.chunk_size = 512 # 可以设置其他全局参数
print("Global Settings configured with OpenAI models.")
except Exception as e:
print(f"Error configuring global Settings (check API keys?): {e}")
exit()
# --- 2. 加载数据和构建基础索引 ---
# 确保当前目录下有 data 文件夹,并包含示例文本文件
data_dir = "data"
try:
if not os.path.exists(data_dir):
os.makedirs(data_dir)
print(f"Created directory: {data_dir}")
# 创建一些简单的示例文件
with open(os.path.join(data_dir, "doc1.txt"), "w", encoding="utf-8") as f:
f.write("LlamaIndex helps build LLM applications over custom data.")
with open(os.path.join(data_dir, "doc2.txt"), "w", encoding="utf-8") as f:
f.write("Retrieval-Augmented Generation (RAG) combines retrieval with generation.")
with open(os.path.join(data_dir, "doc3.txt"), "w", encoding="utf-8") as f:
f.write("Advanced RAG techniques include query transformation and re-ranking.")
print("Created sample files in data directory.")
except OSError as e:
print(f"Error creating data directory or files: {e}")
exit()
print(f"Loading documents from: {data_dir}")
documents = SimpleDirectoryReader(data_dir).load_data()
print(f"Loaded {len(documents)} documents.")
# 创建索引,将隐式使用 Settings.embed_model
print("Creating VectorStoreIndex...")
index = VectorStoreIndex.from_documents(documents)
print("VectorStoreIndex created using global Settings.")
# --- 3. 基础检索器 ---
# 定义基础检索器,初步检索 5 个最相似的节点
base_retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
print("Base retriever configured.")
# --- 4. 配置重排序器 ---
# 需要 Cohere API Key 存储在环境变量 COHERE_API_KEY 中
cohere_api_key = os.getenv("COHERE_API_KEY")
reranker = None # 初始化为 None
if not cohere_api_key:
print("Warning: COHERE_API_KEY not found in .env. Skipping Cohere Rerank configuration.")
else:
try:
# 配置 Cohere Rerank,重排序后取前 2 个
reranker = CohereRerank(api_key=cohere_api_key, top_n=2)
print("CohereRerank configured.")
except Exception as e:
print(f"Error configuring CohereRerank (is the key valid?): {e}")
# 如果配置失败,也确保 reranker 为 None
# --- 5. 构建带重排序的查询引擎 ---
# 查询引擎将隐式使用 Settings.llm 进行响应合成
# node_postprocessors 列表用于应用重排序器
query_engine_with_rerank = RetrieverQueryEngine.from_args(
retriever=base_retriever,
node_postprocessors=[reranker] if reranker else [] # 仅在 reranker 配置成功时添加
)
print("QueryEngine with Rerank configured (Reranker included if API key was found).")
# --- 6. 实现 HyDE 查询转换 ---
# 定义生成假设性文档的 Prompt
hyde_prompt_str = """\
Please write a brief, hypothetical answer to the following question. \
This answer should be plausible and contain keywords relevant to the question.
Question: {query_str}
Hypothetical Answer:"""
hyde_prompt = PromptTemplate(hyde_prompt_str)
# 可以使用成本较低的模型来执行 HyDE
try:
hyde_llm = OpenAI(model="gpt-3.5-turbo")
except Exception as e:
print(f"Could not initialize LLM for HyDE (check OpenAI key?): {e}")
hyde_llm = None # Mark as unavailable
def generate_hypothetical_document(query_str):
"""Generates a hypothetical document using HyDE."""
if not hyde_llm:
print("HyDE LLM not available, cannot generate hypothetical document.")
return None
print("Generating hypothetical document for HyDE...")
try:
response = hyde_llm.complete(hyde_prompt.format(query_str=query_str))
print("HyDE document generated.")
return response.text
except Exception as e:
print(f"Error during HyDE document generation: {e}")
return None
# --- 7. 演示查询 ---
query_str = "What are advanced RAG methods?"
print(f"\n{'='*20} Querying Begins {'='*20}")
print(f"Original Query: {query_str}")
# 基础查询引擎 (使用全局 Settings.llm)
print("\n--- Running Base Query Engine ---")
try:
base_query_engine = index.as_query_engine(similarity_top_k=2)
response_base = base_query_engine.query(query_str)
print("\nResponse (Base):")
print(response_base)
print("\nSource Nodes (Base):")
for node in response_base.source_nodes:
print(f"- Score: {node.score:.4f}, Text: {node.text[:100]}...")
except Exception as e:
print(f"Error during Base Query: {e}")
# 带重排序的查询 (如果 reranker 可用)
print("\n--- Running Query Engine with Rerank (if available) ---")
if reranker:
try:
response_rerank = query_engine_with_rerank.query(query_str)
print("\nResponse (Reranked):")
print(response_rerank)
print("\nSource Nodes (Reranked - Top 2 after reranking):")
for node in response_rerank.source_nodes:
# Cohere Rerank score is a relevance score (higher is better)
print(f"- Rerank Score: {node.score:.4f}, Text: {node.text[:100]}...")
except Exception as e:
print(f"Error during Reranked Query: {e}")
else:
print("Skipping Reranked query as Cohere Reranker is not configured.")
# HyDE + Rerank (手动组合演示)
print("\n--- Running HyDE + Rerank (if available) ---")
hypothetical_doc = generate_hypothetical_document(query_str)
if hypothetical_doc:
print(f"Hypothetical Document (preview): {hypothetical_doc[:100]}...")
# 获取假设文档的嵌入向量
try:
hyde_embedding_vector = Settings.embed_model.get_text_embedding(hypothetical_doc)
# 使用 QueryBundle: 包含原始查询文本和自定义嵌入
hyde_query_bundle = QueryBundle(query_str=query_str, embedding=hyde_embedding_vector)
print(f"Retrieving using HyDE embedding for query: '{hyde_query_bundle.query_str}'")
# Retriever 现在可以直接接受 QueryBundle
retrieved_nodes_hyde = base_retriever.retrieve(hyde_query_bundle)
print(f"Retrieved {len(retrieved_nodes_hyde)} nodes using HyDE.")
# 应用重排序 (如果可用)
if reranker:
# Reranker 需要原始查询文本进行相关性判断
reranked_nodes_hyde = reranker.postprocess_nodes(retrieved_nodes_hyde, query_bundle=QueryBundle(query_str))
print(f"Applied Cohere Rerank to HyDE results. Nodes after rerank: {len(reranked_nodes_hyde)}")
else:
reranked_nodes_hyde = retrieved_nodes_hyde[:2] # 回退策略:取前两个
print("Using top 2 HyDE results (no reranker).")
# 手动合成响应 (使用全局 Settings.llm)
from llama_index.core.response_synthesizers import get_response_synthesizer
response_synthesizer = get_response_synthesizer() # 获取默认合成器
print("Synthesizing final response for HyDE + Rerank...")
try:
response_hyde_rerank = response_synthesizer.synthesize(
query=query_str, # 使用原始查询进行合成
nodes=reranked_nodes_hyde
)
print("\nResponse (HyDE + Reranked):")
print(response_hyde_rerank)
print("\nSource Nodes (HyDE + Reranked):")
for node in reranked_nodes_hyde:
# Score here might be from initial retrieval or reranker if available
print(f"- Score: {node.score:.4f}, Text: {node.text[:100]}...")
except Exception as e:
print(f"Error during HyDE response synthesis: {e}")
except Exception as e:
print(f"Error during HyDE embedding or retrieval: {e}")
else:
print("Skipping HyDE + Rerank as hypothetical document generation failed.")
print(f"\n{'='*20} Querying Ends {'='*20}")
逐步代码讲解与分析:
- 全局
Settings: 我们在代码开头通过Settings.llm = ...和Settings.embed_model = ...配置了全局使用的 LLM 和嵌入模型。这使得后续创建索引和查询引擎时无需重复传入这些参数。 - 基础检索 (Base): 直接调用
index.as_query_engine,结果完全依赖向量相似度。 - 重排序 (Reranked): 通过
RetrieverQueryEngine.from_args的node_postprocessors参数加入了CohereRerank。重排序器在检索之后、响应合成之前介入,对初步检索到的节点进行二次排序,理论上能将最相关的节点排在前面。注意 Cohere 返回的分数是相关性分数(越高越好),不同于向量距离。 - HyDE + 重排序:
- 使用一个(通常成本较低的)LLM 根据
hyde_prompt生成了一个针对原始查询的假设性答案。 - 获取这个假设性答案的嵌入向量。
- 关键: 使用
QueryBundle将原始查询文本和假设性文档的嵌入向量打包。这非常重要,因为检索应该基于更能代表答案语义的嵌入,但后续的重排序和答案生成应该基于用户实际提出的问题。 - 使用
base_retriever.retrieve(hyde_query_bundle)进行检索。 - 对检索结果应用
CohereRerank(如果可用)。 - 最后,使用默认的
ResponseSynthesizer,传入原始查询文本和经过 HyDE 检索及重排序的节点来生成最终答案。
- 使用一个(通常成本较低的)LLM 根据
- 效果对比: 运行代码并仔细比较三种方式的最终回答 (
response) 和引用的源节点 (source_nodes)。关注点:答案是否更准确、更贴切?引用的源节点是否更相关,排序是否更合理?
效果评估初步:
要量化对比这些策略的效果,可以使用 LlamaIndex 的评估模块。例如,定义一组(问题,理想答案)对,然后使用 ResponseEvaluator(评估生成答案的质量,如相关性 RelevancyEvaluator、忠实度 FaithfulnessEvaluator)和 RetrievalEvaluator(评估检索节点的质量,如 HitRate、MRR)来比较不同查询管道(基础 vs. Rerank vs. HyDE+Rerank)的得分。这将提供客观数据来证明高级策略的价值。
5.4 动手实验(二):图增强 RAG (KG-RAG) 深度实践
目标:掌握 LlamaIndex 构建和查询知识图谱索引的能力,处理需要理解实体关系的问题。
核心价值与适用场景:
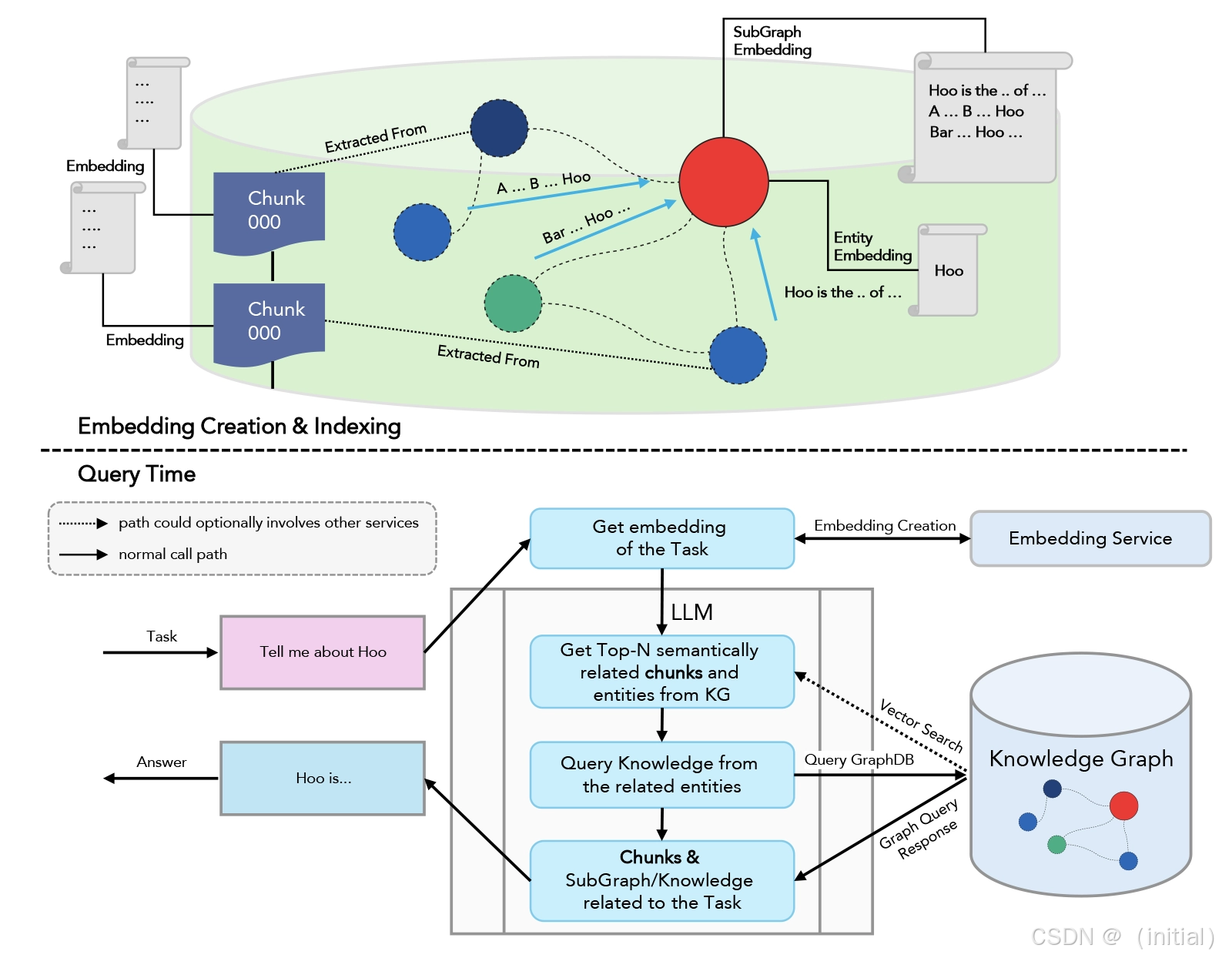
向量 RAG 擅长语义相似性搜索,但对于需要理解实体间明确关系的问题(如“A 公司收购了谁?”、“B 药物影响什么疾病?”)可能效果不佳。KG-RAG 通过构建知识图谱((主语, 谓语, 宾语) 三元组),可以直接查询这些结构化关系,提供更精确的答案。它特别适用于问答系统、领域知识探索、复杂关系推理等场景。
索引构建:
LlamaIndex 的 KnowledgeGraphIndex 可以利用 LLM 自动从文本中提取三元组来构建图谱。
from llama_index.core import SimpleDirectoryReader, KnowledgeGraphIndex
from llama_index.core.graph_stores import SimpleGraphStore # 使用内存图存储
from llama_index.core import StorageContext
# 确保 Settings.llm 和 Settings.embed_model 已在全局配置好
# 1. 准备包含实体和关系的数据
# 创建 data_kg 目录并放入文件
kg_data_dir = "data_kg"
try:
if not os.path.exists(kg_data_dir):
os.makedirs(kg_data_dir)
print(f"Created directory: {kg_data_dir}")
# 创建示例文件
with open(os.path.join(kg_data_dir, "company_info.txt"), "w", encoding="utf-8") as f:
f.write("Alpha Corp acquired Beta Inc in 2023. Charlie founded Alpha Corp. Beta Inc developed the innovative Zeta product.")
with open(os.path.join(kg_data_dir, "product_info.txt"), "w", encoding="utf-8") as f:
f.write("The Zeta product uses advanced AI algorithms.")
print(f"Created sample files in {kg_data_dir}")
except OSError as e:
print(f"Error creating {kg_data_dir} directory or files: {e}")
exit()
print(f"Loading documents from: {kg_data_dir}")
kg_documents = SimpleDirectoryReader(kg_data_dir).load_data()
print(f"Loaded {len(kg_documents)} documents for KG.")
# 2. 配置图存储 (使用内存版)
graph_store = SimpleGraphStore()
storage_context_kg = StorageContext.from_defaults(graph_store=graph_store)
print("Configured SimpleGraphStore.")
# 3. 构建知识图谱索引
# 将隐式使用 Settings.llm 进行三元组提取
# include_embeddings=True 会同时使用 Settings.embed_model 为实体创建嵌入
print("\n--- Building Knowledge Graph Index (this may take a moment)... ---")
try:
kg_index = KnowledgeGraphIndex.from_documents(
kg_documents,
max_triplets_per_chunk=10, # 控制每次 LLM 调用的提取粒度
storage_context=storage_context_kg,
include_embeddings=True, # 同时为实体节点创建嵌入,支持混合搜索
show_progress=True, # 显示构建进度
)
print("Knowledge Graph Index built successfully.")
# 可以查看提取了多少三元组
# num_triplets = len(graph_store.get_all_triplets())
# print(f"Extracted {num_triplets} triplets.")
except Exception as e:
print(f"Error building Knowledge Graph Index: {e}")
exit()
# (可选) 持久化图谱 - 对于大型图谱建议持久化
# persist_path = "./kg_graph_store.json"
# try:
# graph_store.persist(persist_path=persist_path)
# print(f"KG graph store persisted to: {persist_path}")
# # 加载: graph_store = SimpleGraphStore.from_persist_path(persist_path)
# except Exception as e:
# print(f"Error persisting graph store: {e}")
查询实现:
构建好索引后,可以创建查询引擎来查询图谱。
# 4. 创建 KG 查询引擎
# 查询引擎将隐式使用 Settings.llm 进行响应合成
print("\n--- Creating KG Query Engine ---")
try:
kg_query_engine = kg_index.as_query_engine(
include_text=False, # 优先使用图谱关系,不直接检索原始文本块
response_mode="tree_summarize", # 适合从多个三元组总结答案
embedding_mode="hybrid", # 结合 KG 查找和实体嵌入查找
similarity_top_k=3, # 混合模式下,向量查找的 K 值
verbose=True # 打印内部的图谱查询语句 (很有用!)
)
print("KG Query Engine created.")
except Exception as e:
print(f"Error creating KG Query Engine: {e}")
exit()
# 5. 执行查询
queries = [
"Tell me about Alpha Corp's acquisitions.",
"Who founded Alpha Corp?",
"What product did the company acquired by Alpha Corp develop?" # 更复杂的关系查询
]
for query in queries:
print(f"\n--- Querying KG: '{query}' ---")
try:
response_kg = kg_query_engine.query(query)
print("\nKG Response:")
print(response_kg)
# (可选) 打印检索到的三元组(通常 verbose=True 已经显示)
# if response_kg.metadata and "kg_rel_map" in response_kg.metadata:
# print("\nRetrieved triplets structure (from metadata):")
# print(response_kg.metadata["kg_rel_map"])
except Exception as e:
print(f"Error during KG query: {e}")
逐步代码讲解:
- 我们准备了包含明确实体和关系的文本数据。
- 使用
SimpleGraphStore在内存中存储图谱。 - 调用
KnowledgeGraphIndex.from_documents构建索引。这一步 LlamaIndex 会调用在Settings.llm中配置的 LLM,让它读取文本块并提取 (主体, 谓词, 客体) 形式的三元组。max_triplets_per_chunk影响 LLM 每次处理的文本量和可能提取的三元组数量。设置include_embeddings=True会让 LlamaIndex 同时使用Settings.embed_model为图谱中的实体(主体和客体)创建向量嵌入,这对于embedding_mode="hybrid"查询模式至关重要。 - 创建查询引擎时:
include_text=False表明我们主要想依赖图谱的结构化信息,而不是原始文本的语义相似性(尽管混合模式下会用到文本)。embedding_mode="hybrid"是一个强大的选项。它允许查询引擎首先利用向量嵌入找到与查询在语义上相关的实体(即使查询词与实体名称不完全匹配),然后基于这些实体在图谱中查找关系。verbose=True强烈推荐使用,它会显示 LlamaIndex 内部如何将你的自然语言查询转换为底层的图谱查询语句(可能是类似 Cypher 的语句或是内部的查询逻辑),这有助于理解其工作原理和调试。
- 执行查询,观察 LlamaIndex 如何利用图谱结构来回答直接的关系问题(如收购、创始人),甚至是一些需要简单推理的复杂问题。
架构图示:
5.5 LlamaIndex RAG 生产部署考量
将基于 LlamaIndex 构建的 RAG 应用推向生产,需要考虑以下关键点:
- 索引管理:
- 持久化与加载: 使用
storage_context.persist()和load_index_from_storage()处理大型索引的存取。选择合适的持久化路径和存储后端。 - 增量更新: 研究 LlamaIndex 提供的
index.insert()、index.update_ref_doc()、index.delete_ref_doc()等方法,了解如何高效地更新索引以反映数据的变化,避免频繁全量重建。注意,增量更新的支持程度可能因索引类型和底层向量存储而异。
- 持久化与加载: 使用
- 服务部署:
- API 封装: 使用 FastAPI 或其他 Python Web 框架将
QueryEngine.query()或Retriever.retrieve()封装成标准的 REST API 接口。 - 容器化: 利用 Docker 将 LlamaIndex 应用、所有 Python 依赖、可能的本地模型和配置文件打包成镜像,实现环境一致性,简化部署和扩展(如使用 Kubernetes)。
- API 封装: 使用 FastAPI 或其他 Python Web 框架将
- 可观测性 (Observability):
- 日志记录: 在代码关键路径(如数据加载、索引构建、查询处理、LLM 调用)添加详细的日志。
- 追踪 (Tracing): 集成分布式追踪工具(如 Langfuse, Arize AI, OpenTelemetry, LangSmith),可视化整个 RAG 请求的处理流程,定位性能瓶颈和错误。
- 监控 (Monitoring): 监控服务的关键指标,如 QPS (每秒查询数)、请求延迟、错误率、CPU/内存使用率、LLM API 调用次数和 Token 消耗。
- 性能与成本:
- 延迟优化: 分析复杂查询管道中各个环节的耗时(检索、重排序、多次 LLM 调用),进行针对性优化(如使用更快的嵌入/LLM 模型、优化索引参数、并行处理、缓存)。
- 成本控制: 精确追踪 LLM API(用于索引构建、查询转换、响应合成等)和向量数据库(存储、查询、数据传输)的费用。选择性价比合适的模型和服务层级。实现缓存策略减少重复计算或 API 调用。
- 依赖管理: LlamaIndex 及其丰富的集成库 (
llama-index-*) 可能引入复杂的依赖关系。推荐使用poetry或pip-tools等现代 Python 包管理工具来锁定依赖版本,确保环境的可复现性。
5.6 章节总结与关键技术回顾
本章我们深入探索了 LlamaIndex 在构建高级 RAG 应用方面的强大能力。
-
核心优势总结: 我们体会到 LlamaIndex 灵活的数据抽象 (
Node与关系)、多样的索引类型(超越向量)、以及可组合的查询管道设计是其核心优势,使其能够构建出功能强大且高度定制化的 RAG 系统。 -
关键技术回顾: 我们学习并实践了:
- 多种高级索引的概念(
Summary,Tree,Keyword,KnowledgeGraph)及其适用场景。 - 增强检索效果的高级策略:查询转换 (HyDE) 和重排序 (Reranker)。
- 构建复杂查询管道的方法,组合检索、重排序等步骤。
- 利用
KnowledgeGraphIndex实现图增强 RAG (KG-RAG),处理需要理解实体关系的问题。
- 多种高级索引的概念(
-
对比与连接:
- 与第四章对比: 本章引入的高级索引技术和检索策略,显著提升了 RAG 处理复杂查询、保证结果质量和处理结构化关系的能力,远超第四章基础的向量检索。
- 展望第六章: 我们已经看到了 LlamaIndex 构建高级 RAG 的一种方式,其特点在于丰富的索引结构和模块化组件。下一章,我们将转向另一个重要框架——LangChain。我们将学习 LangChain 如何利用其核心的 LCEL (LangChain Expression Language) 来编排和实现类似(及不同)的高级 RAG 策略(例如历史感知的 RAG、能自主生成过滤条件的自查询检索器等)。对比 LlamaIndex 和 LangChain 在设计哲学(数据中心 vs. 链式组合)、实现方式和易用性上的异同,将有助于我们更全面地理解现代 RAG 框架生态,并为特定场景做出更合适的选型。
内容同步在gzh:智语Bot



















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











