




 本文详细介绍了计算机如何通过字符编码显示文字,从位、字节的基础概念到ASCII、ISO-8859-1、GB2312、BIG5、GBK、Unicode等编码方式,探讨了字节顺序、BOM以及大端和小端的概念,旨在帮助读者全面理解字符编码的原理和应用。
本文详细介绍了计算机如何通过字符编码显示文字,从位、字节的基础概念到ASCII、ISO-8859-1、GB2312、BIG5、GBK、Unicode等编码方式,探讨了字节顺序、BOM以及大端和小端的概念,旨在帮助读者全面理解字符编码的原理和应用。
文章目录
计算机如何显示文字
计算机是以二进制的形式保存/处理数据,不管我们使用键盘输入还是让计算机去读取一个文本文件,计算机得到的原始内容是一些二进制数据,当需要对这些二进制数据进行显示时,计算机会依照某种翻译机制/编码方式,取到这些二进制序列所表示的每个文字的轮廓描述(点阵或矢量图),知道了轮廓,计算机便可以将二进制序列所表示的实际的文字形状显示到屏幕。
编码
我们知道,计算机所有的信息最终都表示为一个二进制的字符串,每个二进制位(bit)有0和1两种状态。假设字符A对应的二进制为01000010(这个随便编的),存储时,将此二进制串存入计算机;读取时,再将01000010还原成字符A。那么存储时,A到底应该对应01000010,还是10000000、11110101?这个时候就需要一个规则,这个规则可以将字符映射到唯一一种状态(二进制字符串),这就是编码。
最早出现的编码规则是ASCII编码,在ASCII编码中,字符A既不对应01000010,也不对应1000 0000、11110101,而是对应01000001(不要问为什么,这是规则)。

概念理解
位(Bit )
数据存储的最小单位(即0或1),简称为b,也可称为比特
字节(Byte )
存储空间的基本计量单位,是一个8位的存储单元,取值范围是0-255,1Byte = 8bit
字节顺序
多字节的值在内存中的存储顺序,通常有大端(Big Endian)、小端(Little Endian)两种字节顺序。
BOM (Byte Order Mark)
字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标记文件采用哪种合适的编码;
UCS编码中有个‘Zero Width No-break Space/零宽无间断间隔’字符, 它的编码是FEFF,UCS规范我们在传输字节流前,先传输字符‘Zero Width No-break Space’,这样如果接收者收到FEFF,就表明这个字节流是Big-Endian,如果收到FFFE,就表明这个字节流是Little-Endian;
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式,字符‘Zero Width No-break Space’的UTF-8编码是EF BB BF,如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了;Windows采用BOM来标记文本文件的编码方式;
| 编码 | 表示(16进制) | 表示(10进制) |
|---|---|---|
| UTF-8 | EF BB BF | 289 187 191 |
| UTF-16(大端序) | FE FF | 254 255 |
| UTF-16(小端序) | FF FE | 255 254 |
大端(Big Endian)和小端(Little Endian)
将高序字节存储在起始位置/内存低地址处(高位编址)——大端
将低序字节存储在起始位置/内存低地址处(低位编址)——小端
例如:
00000001 00000010 #二进制表示 十六进制0x0102
00000001 00000010 #地址(低—>高)大端
00000010 00000001 #地址(低—>高)小端
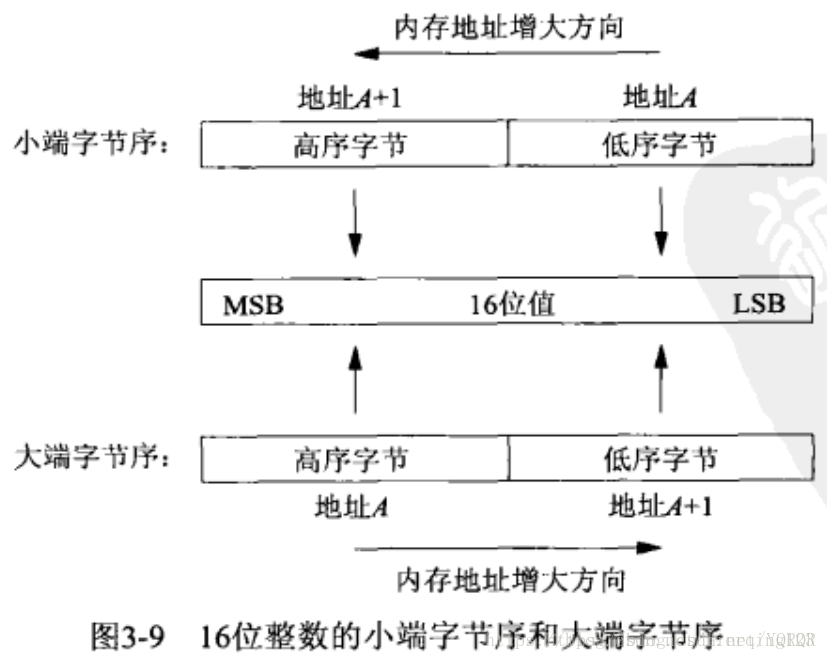
图中顶部标明内存增长方向从右向左,底部标明内存增长从左向右,同时标明最高有效位(most significant bit,MSB)是这个16位值最左边的一位,最低有效位(least significant bit,LSB)是这个16位值得最右边一位。术语大端/小端表示多个字节值的大端/小端存储着该值的起始地址。
字符(character)
字符是指计算机中使用的字母、数字、字、符号;取值范围不定。例如在UTF-8编码中,一个中文字符存储需要3-4个字节,一个英文字符存储需要1个字节;
字符集(character set)
多个字符的集合,其中规定好了一系列字符与二进制序列之间的关系;每个字符集包含的字符个数不同;由于时间、地域、语言种类等原因,形成了多套应用于不同场合、语言的字符集;
常见字符集:ASCII、ISO-8859-1、GB2312、BIG5、GBK、Unicode等;
字符编码
字符集规定好了字符与二进制序列之间的对应关系,但不代表计算机就要按照字符对应的二进制序列将二进制直接存储。有时候我们按照一定的规则,将字符的码元再次处理,以更加适应计算机存储、网络传输的需要。
所以字符编码便是规定了如何编码、存储这些字符的二进制序列;
世界上存在着多种编码方式,同一个二进制数字可以被解释为不同的符号。因此要打开一个文件,必须知道它的编码方式。用错误的编码方式会出现乱码。
可以理解为字符集是一种协议,字符编码是对字符的一种实现;也就意味着同一字符集可能有不同的编码方式;当然最直接的编码方式便是直接使用字符对应的二进制序列;这就导致字符集跟字符编码看起来像一个东西;
比如Unicode字符集的实现方式有:UTF-8,UTF-16,UTF-32
ASCII
American Standard Code for Information Interchange 美国信息互换标准编码,是单字节编码,共规定了128个字符的编码,这128个符号只占用了一个字节(8bit)的后7位,最前面的一位规定为0。
ISO-8859-1
由ISO组织制定,扩展了ASCII码。
是单字节编码,最多能表示256个字符;
GB2312
GB2312对所收录字符进行了分区处理,共94个区,每区94位,共8836(94*94)个码位,这种表示方式也称为区位码。
GB2312是双字节编码,其中高字节表示区,低字节表示位。总共编码的中文个数6763(3755+3008),这些汉字只是使用频率较高,最常用的汉字。有些汉字并没有编码进GB2312,于是出现了GBK。
01-09区 收录除汉字外的682个字符,有164个空位(9 * 94 - 682)。
10-15区 为空白区,没有使用。
16-55区 收录3755个一级汉字(简体),按拼音排序。
56-87区 收录3008个二级汉字(简体),按部首/笔画排序。
88-94区 为空白区,没有使用。
BIG5
BIG5是双字节编码,使用两个字节表示一个字符。是繁体中文字符集编码标准;共收录13060个中文;
BIG5编码与GBK编码没有什么关系
GBK
GBK编码扩展了GB2312,完全兼容GB2312,但不兼容BIG5。如果使用GB2312编码,使用GBK解码是完全正常的。但如果使用BIG5编码,使用GBK解码会出现乱码。
GBK是双字节编码,能表示21003个汉字。问题是如果一方使用GBK编码,一方使用BIG5编码,就会出现乱码问题,所有需要有一套全球通用的统一的编码,即Unicode.
Unicode
Unicode字符集,规定了字符对应的码点,并没有指定如何存储。
Unicode表包含了从000000—10FFFF的码位范围,它将码空间分为17个平面,从00-10(16进制,最高两位)即从0-16(10进制),每个平面有65536个码点(2^16),其中最重要的是第一个Unicode平面(码位0000-FFFF),包含了最常用的字符,该平面也成为基本多语言平面(Basic Multilingual Plane)BMP。
根据存储方式的不用出现了不同的编码方案。Unicode编码方案主要有两条主线UCS和UTF。
UCS(Universal Character Set)
通用字符集
UCS-2
定长字节,固定使用2个字节进行编码,从0000 — FFFF的码位范围,对应第一个Unicode平面,采用BOM(Byte Order Mark)机制。该机制作用如下:
- 确定字节流采用的大端序还是小端序;
- 确定字节流的Unicode编码方案;
UCS-4
定长字节,固定使用4个字节进行编码,采用BOM机制;
UTF
Unicode Transformation Format
是Unicode字符集的实现形式,是一种存储和传输格式;
UTF-8
UTF-8是一种变长的编码方式,使用1—4个字节进行编码,
是互联网上使用最广的一种Unicode的实现方式,
Unicode码点转换UTF-8编码的规则
- 对于单字节字符,字符的第一位设为0,后面七位为这个符号的unicode码。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10,剩下的没有提及的二进制位,全部为这个符号的Unicode码。不足的填0。
| Unicode符号范围 | UTF-8编码方式 |
|---|---|
| (十六进制) (十进制) | (二进制) |
| 0000 0000-0000 007F (0-127) | 0xxxxxxx |
| 0000 0080-0000 07FF (128-2047) | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF (2048-65535) | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF (65536-1114111) | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8编码的优势
- 是Unicdoe的实现形式,适应全球所有的字符;
- 没有字节序的概念,不要考虑大小端,特别适用于字符串的网络数据传输;
- UTF-8完全兼容ASCII;
- 对于非英文页面,不用考虑各种乱码问题;
- 前缀码
- 能让程序员很方便遍历出问题的代码,保持能显示部分最大化;所有非前缀码字节编码在这种场合下最后的结果是必须丢弃从出错点到结尾的所有编码,无论是GB码还是Unicode/UTF-16
- 容易解析
- 容错性
- 易于传输;
- 节省存储空间;
UTF-8为什么不需要BOM机制
因为UTF-8编码中,自身已经带了控制信息,如110xxxxx,10xxxxxx,10xxxxxx其中110就起到了控制作用
UTF-16
UTF-16使用2/4个字节编码,也是Uniocde的一种具体的编码实现;
Unicode码点转换UTF-16编码的规则
- 若Unicide码点在第一平面中(BMP)中,则使用2个字节进行编码
- 若Unicide码点在其他平面(辅助平面),则使用4个字节进行编码


















 57万+
57万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









