







目录
六、字典进阶版 - 嵌套字典(感觉太难的话,了解有个印象就好啦)
一、列表的基础写法
列表名=['内容','内容','内容','内容']
#例如班上有这5名同学 class1 = ['Joan', 'Bill', 'Niki', 'Mark', 'Mark']
可直接打印
print(class1)
#输出['Joan', 'Bill', 'Niki', 'Mark', 'Mark']【题目】
给出2个班级的名字,请找出两个班级相同学生的名字
#班级 class1 = ['Joan', 'Bill', 'Niki', 'Mark', 'Mark'] class2 = ['Tom', 'Linda', 'Bill']
#比较两个班的同学,查询是否有重名学生,如果有则输出重名的学生的名字
#设置class1和class2两个列表
class1 = ['Joan', 'Bill', 'Niki', 'Mark', 'Mark']
class2 = ['Tom', 'Linda', 'Bill']
#循环遍历class1,其中每个元素都与class2中的元素做比较
for name1 in class1:
for name2 in class2:
if name1 == name2: #如果相同
print(name1)#将该元素打印
#缺点:嵌套了2层for循环,(时间)复杂度较大并且
# 如果有个名字出现了2次,那么也会打印2次
# 该学生的名字。注意!因为嵌套的问题,2个for循环嵌套(数据结构里是有说的),时间复杂度会比较大,而且这个程序的逻辑是,检索相同的名字,所以如果一个班级里面有2个相同名字的话会打印2次,如果2个班级都有2个相同名字的学生(2+2)那么他会打印4次这个学生的名字
二、集合的基础写法
1、集合的创建
#创建集合的方式:
a = set()
b = {1, 2, 'abc'}
#注意如果创建空集合,要使用set(),而不是a={}
print(a) #输出set()
print(b) #输出{1,2,'abc'}
2、集合的特性
Ⅰ-【归一性】/【唯一性】
即:自动将重复的元素消除,保留不重复的元素。元素具有唯一性,也是说集合中不会出现重复的元素(意思一样的)
#如果打印的是有重复的元素,默认会将重复的元素进行归一化
c = {1, 2, 1, 1, 2}
print(c) #{1,2}
Ⅱ-【无序性】(并非所谓的简单无序)
即:元素顺序可能没有顺序可言,不像顺序表那样有顺序,不能用索引的方式访问,但可以使用遍历访问 (例一)
【重点来了!!!】无序并非真的一点规律都没有,集合可以插入数字和字符串,字符串是真的无序,而数字一定是从小到大排列的 (例二)
例一
a = 'abcde' #a为字符串
test = set(a) #需要注意的是,集合中的元素顺序可能与原字符串中的顺序不同
#因为集合是无序的,这就是无序性。
print(test)#输出{'c','e','d','a','b'}
例二 c={1,7,3,4,5,'TOM','CAT','I','Really','love','you'} print(c) #运行如下
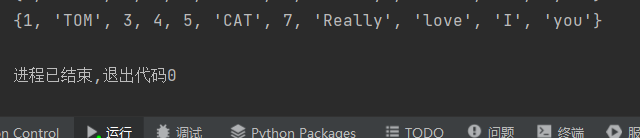
【集合无序的本质】关于这个无序的问题,他不是集合本身无序,而是存进集合时无序,一旦存进地址池的时候,顺序就固定了,验证这个问题:
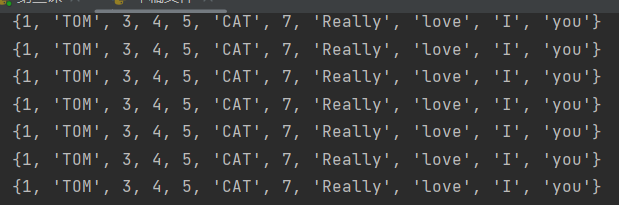
#只需要用循环验证即可 c={1,7,3,4,5,'TOM','CAT','I','Really','love','you'} for i in range(30): print(c) #证明存进地址的时候是固定的,只是存的时候无序,所以打印出来的时候顺序固定
三、列表的基础写法与列表转集合(set()函数)
列表与集合的方式相近,列表是以小括号[ ]括起来的,而集合是花括号{ },而set()函数就是将字符串转为集合
转为集合的函数:set()
b = [1,2,3] #b为列表 test = set(b) #test已经是集合了 print(b) #输出[1,2,3]--列表 print(test) #输出{1,2,3}--集合#注意!输出列表的时候是不带花括号的,与集合的输出不同
四、元组的基础写法与转集合(set()函数)
与上述不同的点在于,元组是用小括号括起来的,其他点都一样,了解即可
c = (1, 2, 'abc') #c为元组
print(c) #输出(1,2,'abc')
test = set(c)
print(test) #输出{1,2,'abc'}
五、字典的基础写法与字典被转换为集合的注意事项
1、【字典内容部分】
字典组成:由key和value组成,即item={ 'key1' : 'value1' , 'key2' : 'value' , ... }
即:key与其所对应的value值组成
d = {'a':1, 'b':2, 'c':3} #d为字典 print(d) #输出{'a':1, 'b':2, 'c':3} print(d.items()) #输出dict_items([('a', 1), ('b', 2), ('c', 3)]) print(d.keys()) #输出dict_keys(['a', 'b', 'c']) print(d.values()) #输出dict_values([1, 2, 3])#注意! 此处取的item、key、value的值均要带上s,即函数items()、keys()、values()
#一般用这些函数的时候可能是涉及:计算大小 、比较大小、嵌套字典取值 、
2、字典转换成集合的【注意事项】
d = {'a':1, 'b':2, 'c':3} #d为字典 print(d) #输出{'a':1, 'b':2, 'c':3} test = set(d) #用set()将d转为集合 print(test) #输出{'a','b','c'} #字典转为集合后,会将字典中的key添加至集合(比如a),value就被忽略了(比如a对应的1)#如果想取value值的话就用上面说的.values()函数就行,即:
test = set(d.values()) #用set()将d转为集合
print(test) #输出{1,2,3}
#如此即可取value值到集合了
六、字典进阶版 - 嵌套字典(感觉太难的话,了解有个印象就好啦)
顾名思义就是在字典里面再搞一个类似于字典的东西,为什么要搞嵌套字典呢,因为单层的字典只有一个key对应一个value数据,不讲太抽象↓↓↓
就比如一个班级的学生(key),只能写一个value(比如性别),那你根本不够写啊,众所周知!一个学生好歹有:【学号】、【性别】、【年龄】对吧?
所以value肯定一个不够用的嘛,就以成绩为例吧,期末考试义务教育主科分数:【语文】、【数学】、【英语】,将它们放进一个字典里(外加一个要求:获取第一名的名字)
#自己写的成绩放进字典里
student = {
'小明': {'语文': 90, '数学': 88, '英语': 76},
'小红': {'语文': 78, '数学': 68, '英语': 96},
'小亮': {'语文': 92, '数学': 78, '英语': 86}
}
def calc_score1(sutdent_val): #def是指自定义函数1
score_sum=sum(sutdent_val.values())
#sum()函数是计算括号内的分数得到总分,用.values()函数取字典内value值(先别纠结,先看下去)
return score_sum #用这个自定义函数的返回值是总分数
for name,val in student.items():
#定义name和val变量去遍历student表里的item项目,分别
#对应key和value,不加.items()是指遍历字典,加了是指遍历项目
sumval=calc_score1(val)
#调用自定义的函数代入val到括号计算总分(此时val是
#指字典里的value那一块,往val里面取学科)
print(f'{name}分数{sumval}') #输出同学的学科总分以上是计算总分,下面开始找出最大值对应的学生
# 计算总分最高的学生
height_score=max(calc_score1(val) for val in student.values())
#用max函数计算在自定义函数1中分数最高值(注意有参数val),条件是在stude
#nt.values()中(注意此处有参数),循环找到val代入到函数1中的最大值
height_score_student = next(name for name,val in student.items() if calc_score1(val)==height_score)
#用for找出在项目里总分等于最高分的学生,返回这些都是最高分的学生,用next输出一次第一个最高分的学生
#有个缺点是:如果有多个都是最高分的学生,就只会输出一个
#next()是一个内置函数,用于从迭代器中获取下一个项目,如果没有得再迭代会返回'No more elements',而不是StopIteration异常(停止迭代异常)#再次说明:next()是一个内置函数,用于从迭代器中获取下一个项目,如果没有得再迭代会返回'No more elements',而不是StopIteration异常(停止迭代异常)















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









